pivot - data line to the columns to condition
create table t_a (identification number);insert into t_a values (1);
insert into t_a values (2);
insert into t_a values (3);
insert into t_a values (4);
insert into t_a values (5);
create table t_b (identification number, name varchar2 (100), val varchar2 (100));
insert into t_b values (1, 'A', 'Yahoo');
insert into t_b values (1, 'B', 'BBB');
insert into t_b values (1, 'C', 'CCC');
insert into t_b values (1,'d ","DDDD"");
insert into t_b values (2, 'A', ' 2 Yahoo' ");
insert into t_b values (2, 'B', 'FD');
insert into t_b values (4, 'C', 'test');
insert into t_b values (5, 'A', 'Yahoo 5');
I could only get the list of IDS of t_a column and table name with the values 'A' and 'B' columns can
result must be-
ID | A | B
1. Yahoo | BBB
2. Yahoo 2 | FDS
3.
4.
5. Yahoo 5 |
Thanks in advance
Hello
Of course, you can do it.
Outer-sign up for t_a, to ensure that all the 5s IDs appear:
SELECT t_a.id
, MAX (CASE WHEN t_b.name = 'A' THEN t_b.val END) AS a
, MAX (CASE WHEN t_b.name = 'B' THEN t_b.val END) AS b
FROM t_a
LEFT OUTER JOIN t_b ON t_a.id = t_b.id
GROUP BY t_a.id
ORDER BY t_a.id;
Thanks for posting the sample data: which helps a lot!
You may have noticed that this site compresses the spaces by default. When you want to post something where the spacing is important (like your results), and then type the 6 characters:
{code}
(small letters only, inside curly braces) before and after the section of text formatted to preserve spacing.
Tags: Database
Similar Questions
-
lines to the column and summation
Hi everyone, I am using oracle 10g consider the following data:
WITH the data as {}
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 123.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 111.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 666.23 amount OF the dual UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 888.23 amount OF the double UNION
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 333.23 amount OF the dual UNION ALL
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 222.23 amount OF double UNION ALL
SELECT mntrid "XTR3", "CCC" ctid, ' hi tech 3 ' description, code 'PC', 777.23 amount OF double
}
I would like secret lines at column and add the amounts. my output should be like this
MNTRID CTID DESCRIPTION MAIN PC PAYROLL
XTR AAA hi tech 234,46 1554.46
XTR2 BBB Hi tech2 555.46
CCC XTR3 Hi Tech 3 777.23
what I do is converting lines to the column and the display of the sum. for example, for mntrid = XTR I get the sum of all MAIN lines and the lines all PAY and PC.
Since there is no line of PC for XTR I display null.
can someone help me write a query that displays the output in oracle 10g above?
Hello
elmasduro wrote:
It's great Frank. Thank you very much.
I have a request. What happens if I want to add total main grad, wages, the pc? How would I do that.
output
Total general AFFID CTID DESCRIPTION MAIN PAY PC
XTR AAA hi tech 234.46 1554,46 1788.92
XTR2 BBB Hi tech2 555,46 555.46
CCC XTR3 Hi Tech 3 777,23 777.23
It's just plain old garden-variety SUM:
SELECT Mntrid
ctid
Description
, SUM (CASE WHEN code = "MAIN" THEN rise END) AS main
, SUM (CASE code WHEN = "SALARY" THEN rise END) AS pay
, SUM (CASE WHEN code = 'PC', THEN rise END) AS pc
, The SUM of (amount) AS grand_total-* NEW *.
FROM the data
GROUP BY mntrid
ctid
Description
;
-
lines to the column for large number of files
my version of the database is 10 gr 2
I want to transfer the lines to the column... .i have seen examples of small no records, but how can it be done if there are more the 1,000 records in a table...?
Here is the example of data I'd like to change to column
SQL> / NE RAISED CLEARED RTTS_NO RING --------------- ------------------------------ ------------------------------ -------------- ----------------------------------------------------------------------------------- 10100000-1LU 22-FEB-2011 22:01:04/28-FEB-20 22-FEB-2011 22:12:27/28-FEB-20 SR-10/ ER-16/ CR-25/ CR-29/ CR-26/ RIDM-1/ NER5/ CR-31/ RiC600-1 11 01:25:22/ 11 02:40:06/ 10100000-2LU 01-FEB-2011 12:15:58/06-FEB-20 05-FEB-2011 10:05:48/06-FEB-20 RIMESH/ RiC342-1/ 101/10R#10/ RiC558-1/ RiC608-1 11 07:00:53/18-FEB-2011 22:04: 11 10:49:18/18-FEB-2011 22:15: 56/19-FEB-2011 10:36:12/19-FEB 17/19-FEB-2011 10:41:35/19-FEB -2011 11:03:13/19-FEB-2011 11: -2011 11:08:18/19-FEB-2011 11: 16:14/28-FEB-2011 01:25:22/ 21:35/28-FEB-2011 02:40:13/ 10100000-3LU 19-FEB-2011 20:18:31/22-FEB-20 19-FEB-2011 20:19:32/22-FEB-20 INR-1/ ISR-1 11 21:37:32/22-FEB-2011 22:01: 11 21:48:06/22-FEB-2011 22:12: 35/22-FEB-2011 22:20:03/28-FEB 05/22-FEB-2011 22:25:14/28-FEB -2011 01:25:23/ -2011 02:40:20/ 10100000/10MU 06-FEB-2011 07:00:23/19-FEB-20 06-FEB-2011 10:47:13/19-FEB-20 101/IR#10 11 11:01:50/19-FEB-2011 11:17: 11 11:07:33/19-FEB-2011 11:21: 58/28-FEB-2011 02:39:11/01-FEB 30/28-FEB-2011 04:10:56/05-FEB -2011 12:16:21/18-FEB-2011 22: -2011 10:06:10/18-FEB-2011 22: 03:27/ 13:50/ 10100000/11MU 01-FEB-2011 08:48:45/22-FEB-20 02-FEB-2011 13:15:17/22-FEB-20 1456129/ 101IR11 RIMESH 11 21:59:28/22-FEB-2011 22:21: 11 22:08:49/22-FEB-2011 22:24: 52/01-FEB-2011 08:35:46/ 27/01-FEB-2011 08:38:42/ 10100000/12MU 22-FEB-2011 21:35:34/22-FEB-20 22-FEB-2011 21:45:00/22-FEB-20 101IR12 KuSMW4-1 11 22:00:04/22-FEB-2011 22:21: 11 22:08:21/22-FEB-2011 22:22: 23/28-FEB-2011 02:39:53/ 26/28-FEB-2011 02:41:07/ 10100000/13MU 22-FEB-2011 21:35:54/22-FEB-20 22-FEB-2011 21:42:58/22-FEB-20 LD MESH 11 22:21:55/22-FEB-2011 22:00: 11 22:24:52/22-FEB-2011 22:10:could you do something like that?
with t as (select '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised , '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared from dual union select '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' from dual ) select * from( select NE, regexp_substr( raised,'[^/]+',1,1) raised, regexp_substr( cleared,'[^/]+',1,1) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,2) , regexp_substr( cleared,'[^/]+',1,2) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,3) , regexp_substr( cleared,'[^/]+',1,3) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,4) , regexp_substr( cleared,'[^/]+',1,4) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,5) , regexp_substr( cleared,'[^/]+',1,5) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,6) , regexp_substr( cleared,'[^/]+',1,6) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,7) , regexp_substr( cleared,'[^/]+',1,7) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,8) , regexp_substr( cleared,'[^/]+',1,8) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,9) , regexp_substr( cleared,'[^/]+',1,9) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,10) , regexp_substr( cleared,'[^/]+',1,10) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,11) , regexp_substr( cleared,'[^/]+',1,11) cleared from t ) where nvl(raised,cleared) is not null order by neNE RAISED CLEARED 10100000-1LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:06 10100000-1LU 22-FEB-2011 22:01:04 22-FEB-2011 22:12:27 10100000-2LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:13 10100000-2LU 19-FEB-2011 10:36:12 19-FEB-2011 10:41:35 10100000-2LU 19-FEB-2011 11:03:13 19-FEB-2011 11:08:18 10100000-2LU 19-FEB-2011 11:16:14 19-FEB-2011 11:21:35 10100000-2LU 06-FEB-2011 07:00:53 06-FEB-2011 10:49:18 10100000-2LU 01-FEB-2011 12:15:58 05-FEB-2011 10:05:48 10100000-2LU 18-FEB-2011 22:04:56 18-FEB-2011 22:15:17You should be able to do without all these unions using a connection by but I can't quite make it work
the following does not work, but perhaps someone can answer.select NE, regexp_substr( raised,'[^/]+',1,level) raised, regexp_substr( cleared,'[^/]+',1,level) cleared from t connect by prior NE = NE and regexp_substr( raised,'[^/]+',1,level) = prior regexp_substr( raised,'[^/]+',1,level + 1)Published by: pollywog on March 29, 2011 09:38
Here it is with the type clause that gets rid of all unions.
WITH t AS (SELECT '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised, '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared FROM DUAL UNION SELECT '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' FROM DUAL) SELECT * FROM (SELECT NE, raised, cleared FROM t MODEL RETURN UPDATED ROWS PARTITION BY (NE) DIMENSION BY (0 d) MEASURES (raised, cleared) RULES ITERATE (1000) UNTIL raised[ITERATION_NUMBER] IS NULL (raised [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (raised[0], '[^/]+', 1, ITERATION_NUMBER + 1), cleared [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (cleared[0], '[^/]+', 1, ITERATION_NUMBER + 1))) WHERE raised IS NOT NULL ORDER BY NEPublished by: pollywog on March 29, 2011 10:34
-
Hi all, I have two tables with data as described below.
what I want to do is to join these two tables and get the values of the table Details
and fill in the data table in the columns that are null. Data table must remain with one
line.
WITH the data AS
(
SELECT "a34" id, "pat smith" name, 234 compid, NULL returned, NULL, NULL prod FROM dual UNION all
SELECT "a35" id name "case jon", dual 543 compid, NULL, NULL, NULL FROM prod revenue business
)
Details such AS
(
SELECT "a34' id code 'craft', 123 idvalue FROM double UNION all
SELECT "a34' id, 'rev' code, 456 idvalue FROM double UNION all
SELECT "a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT "a35' id code 'craft', 294 idvalue FROM double UNION all
SELECT "a35' id, 'rev' code, 546 idvalue FROM double UNION all
SELECT "a35' id, 'product' code, 654 double idvalue
)
the output of this query should be
ID name compid prod turnover
A34 pat smith 234 123 456 789
A35 case jon 543 294 546 654
can someone help write a query that gives me not the above result? Thank youThis gives a shot:
WITH data AS ( SELECT 'a34' id, 'pat smith' name, 234 compid, NULL business, NULL revenue, NULL prod FROM dual UNION all SELECT 'a35' id, 'jon case' name, 543 compid, NULL business, NULL revenue, NULL prod FROM dual ), details AS ( SELECT 'a34' id, 'business' code, 123 idvalue FROM dual UNION all SELECT 'a34' id, 'rev' code, 456 idvalue FROM dual UNION all SELECT 'a34' id, 'product' code, 789 idvalue FROM dual UNION all SELECT 'a35' id, 'business' code, 294 idvalue FROM dual UNION all SELECT 'a35' id, 'rev' code, 546 idvalue FROM dual UNION all SELECT 'a35' id, 'product' code, 654 idvalue FROM dual ), unpivot_details AS ( SELECT ID , MAX(DECODE(CODE,'business',IDVALUE)) AS BUSINESS , MAX(DECODE(CODE,'rev',IDVALUE)) AS REVENUE , MAX(DECODE(CODE,'product',IDVALUE)) AS PROD FROM DETAILS GROUP BY ID ) SELECT DATA.ID , NAME , COMPID , NVL(DATA.BUSINESS,UD.BUSINESS) AS BUSINESS , NVL(DATA.REVENUE,UD.REVENUE) AS REVENUE , NVL(DATA.PROD,UD.PROD) AS PROD FROM DATA JOIN unpivot_details UD ON DATA.ID = UD.IDI did take your DETAILS and UNPIVOT table data turning rows of columns. I used this result to join the DATA table. Once the tables were joined, I used the function NVL will only display the DETAILS table data if the data in the DATA table is NULL.
If you have more values of 'code', you will need to add them manually to the UNPIVOT_DETAILS view.
HTH!
-
APEX do not allow to change the lines of the columns that are the primary key?
I have pictures:
http://img508.imageshack.us/my.php?image=21269582oe8.jpg
Book (id_book - 'Primary key', title, year); book_author (id_author id_book - 'Primary key', - 'Primary key'); author (id_author - "Primary key", name)
I created a new page-> Form-> form of 'author' table because I want to add new authors, modification and deletion. During the creation of this page, I have chosen column 'id_author' as '1 primary key column' and everything is OK (I can't edit the 'id_author' column - this column is autoincrement and I can change the 'name' column).
BUT I also created a new page-> Form-> table for table "book_author" because I like to write numbers like id_book and id_author, change and remove them (so add relations between tables: book, book_author and author). During the creation of this page, I have chosen column 'id_book' as '1 primary key column' and 'id_author' as 'column primary key 2'. And on the Web site, I can't edit these fields. And I can not add also new line because I see in each new line: (null).
http://img444.imageshack.us/my.php?image=11324615yk9.jpg
APEX do not allow to change the lines of the columns that are the primary key? It's stupid... What can I do?
Edited by: user10731158 2008-12-20 11:40Column unique and not meaningful if you ever want to update. In the case of your example, you need to add an ID column in the intersection of book_author table. Honestly, I was so blown away (and pleasantly surprised) by the absence of rebuttal and the "thx" I advanced and set up an example of how I would define the book_author table:
create table book_author (id varchar2(32), book_id varchar2(32), author_id varchar2(32), modified_on date, modified_by varchar2(255), constraint book_author_pk primary key (id), constraint book_auth_book_fk foreign key (book_id) references books(id), constraint book_auth_author_fk foreign key (author_id) references authors(id) ) / create unique index book_author_uq on book_author (book_id,author_id) / create or replace trigger biu_book_author before insert or update on book_author for each row begin if inserting then :new.id := sys_guid(); end if; modified_on := sysdate; modified_by := nvl(v('APP_USER'),user); end; /Good luck
Tyler -
How to query start a new line in the column?
How to query start a new line in the column?
Exam
SELECT ID, username | host name, details of xxx;
on the 2 column, I need result below:
Username ID | hostname in detail
1 user1 xxxxxx
host1
2 user2 xxxxxx
host2
Kind regards
SuradechSomething like that?
SQL> WITH tbl AS (SELECT 1 id,'user1' uname,'xxx' dtl,'host1' hname FROM DUAL UNION ALL 2 SELECT 2 id,'user2' uname,'yyy' dtl,'host2' hname FROM DUAL UNION ALL 3 SELECT 3 id,'user3' uname,'zzz' dtl,'host3' hname FROM DUAL 4 ) 5 SELECT id,uname||dtl||chr(10)||hname FROM tbl; ID UNAME||DTL||CH ---------- -------------- 1 user1xxx host1 2 user2yyy host2 3 user3zzz host3 -
change the data type of the columns
Oracle 10g version.
I have a table with 150 columns.
I would like to change the data type of the columns in my table to varchar.
Do we have a query for this task?
Thank you.Not knowing yet what you meet John:
If your table is empty, you can use the datadictionary to generate a statement and run the query to a file that makes the DDL using dynamic SQL or spool and run that...
Example:
MHO%xe> create table bla (col1 number, col2 number); Tabel is aangemaakt. MHO%xe> select column_name, data_type from user_tab_columns where table_name = 'BLA'; COLUMN_NAME DATA_TYPE ------------------------------ --------------------------------------------------------------------- COL1 NUMBER COL2 NUMBER MHO%xe> declare 2 l_sql varchar2(4000); 3 l_sep varchar2(1); 4 begin 5 l_sql := 'alter table BLA modify ('||chr(10); 6 for rec in ( select column_name from user_tab_columns where table_name = 'BLA') 7 loop 8 l_sql := l_sql||l_sep||' '||rec.column_name||' varchar2(50)'||chr(10); 9 l_sep := ','; 10 end loop; 11 -- 12 dbms_output.put_line(l_sql||' )'); 13 -- 14 execute immediate l_sql||' )'; 15 -- 16 end; 17 / alter table BLA modify ( COL1 varchar2(50) , COL2 varchar2(50) ) PL/SQL-procedure is geslaagd. MHO%xe> select column_name, data_type from user_tab_columns where table_name = 'BLA'; COLUMN_NAME DATA_TYPE ------------------------------ --------------------------------------------------------------------- COL1 VARCHAR2 COL2 VARCHAR2 -
y at - it Systemtable of the data types of the column?
Is QUESTION 1 Systemtable of the data types of the column?
_________________________________________________________________
QUESTION2
IF REGEXP_SUBSTR (p_datatype, "[''!" [¤ % & / =? *; >: <]') IS NOT NULL
We say: you can not write that! » ¤ % & / = ? ' ^ * ; >: <-each of each example ">".
How can I say... you can NOT write PENIS, NIPPLES, hole word "NIPPLES".
__________________________________________________________________
Published by: user619226 on 19-sep-2008 01:15Do you mean something like this...
SQL> ed Wrote file afiedt.buf 1 declare 2 v_txt VARCHAR2(200) := 'FRED,JOE'; 3 begin 4 IF regexp_like(v_txt, '^[[:alnum:]]*$') THEN 5 dbms_output.put_line('Text is OK as it contains just a word'); 6 ELSE 7 dbms_output.put_line('Text is not OK. Must only contain a single word'); 8 END IF; 9* end; SQL> / Text is not OK. Must only contain a single word PL/SQL procedure successfully completed. SQL> ed Wrote file afiedt.buf 1 declare 2 v_txt VARCHAR2(200) := 'FRED'; 3 begin 4 IF regexp_like(v_txt, '^[[:alnum:]]*$') THEN 5 dbms_output.put_line('Text is OK as it contains just a word'); 6 ELSE 7 dbms_output.put_line('Text is not OK. Must only contain a single word'); 8 END IF; 9* end; SQL> / Text is OK as it contains just a word PL/SQL procedure successfully completed. SQL> ed Wrote file afiedt.buf 1 declare 2 v_txt VARCHAR2(200) := 'FRED JOE'; 3 begin 4 IF regexp_like(v_txt, '^[[:alnum:]]*$') THEN 5 dbms_output.put_line('Text is OK as it contains just a word'); 6 ELSE 7 dbms_output.put_line('Text is not OK. Must only contain a single word'); 8 END IF; 9* end; SQL> / Text is not OK. Must only contain a single word PL/SQL procedure successfully completed. SQL> -
whole line on the value of conditional formatting
Hello, I'm a numbers file where I have a few lines filled with values and when a specific cell will fill with a X in the entire line must be indicated in bold.
A B C D
01/01/16 operation 1 1,500,00 X (line entire "BOLD")
01/12/16 my 500.00 X (line entire "BOLD") operation
18/02/16 your 300.00 (not FAT)
How can I do?
Hello Gian,
Conditional highlighting depends on comparing the contents of the cell to be highlighted a fixed value or the value in another cell. To highlight an entire line, using a change in the style of text, you need to highlight every cell in the row.
This means that you must provide something to compare the value in each cell. The simplest is to provide a second cell in which the value of the cell to be highlighted is copied on the condition that triggers the highlight.

In the table above, the formula set out in the table below is entered in cell F2, and then filled up to the 5 row and full right of column J.
The result is that IF the cell in this row of column D contains an X, the contents of the cell for this cell is copied in this cell, otherwise, this cell contains a string NULL.
Each cell in columns A through E is the same conditional highlight rule:
When the text (A2)
is (the same as the text in) F2
A2 "BOLD" text
Select cells A2 - E5, Set up the rule for cell A2 and do not "preserve row" or "preserve the column.
Columns F to J can be hidden.
Kind regards
Barry
-
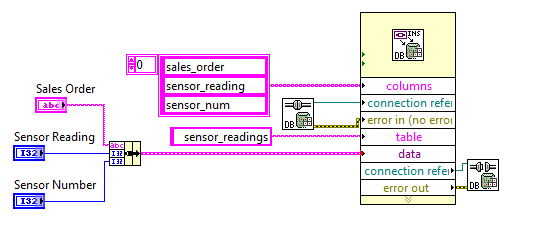
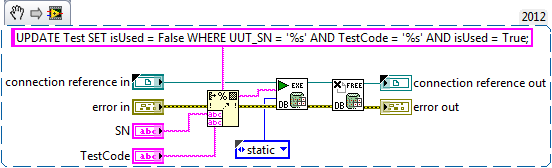
Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
-
Disable the previous dating date picker in the column in a table
can someone please help.
on the date column in a table, need to disable previous dates.
Current functionality. But when the validation page gets updated and the user is able to select earlier dates.
To restrict the datePicker for new lines changed the URL of the button 'Add Row '.
javascript:myAddRow();In the page edit, I added this to "Javascript > function and Variable global statement.
function myAddRow(){ apex.widget.tabular.addRow();$("td[headers='DETAIL_DATE'] input:last").datepicker("option","changeMonth",false).datepicker("option","minDate",$v("P2_MASTER_MONTH_MINDATE")).datepicker("option","maxDate",$v("P2_MASTER_MONTH_MAXDATE")); };w/u/p: nani5048/test/test
App 92603 5 page
Thank you
Nani
I created a dynamic action
the loading of the page
$("td [en-têtes = 'STATUS_DATE'] entrée")
. DatePicker ("option", "minDate", $v ("P5_MASTER_MONTH_MINDATE"));
as well as the global javascript function
function myAddRow() {}
apex.widget.tabular.addRow ();
$("td [en-têtes = 'STATUS_DATE'] entrée")
. DatePicker ("option", "minDate", $v ("P5_MASTER_MONTH_MINDATE"));
}
-
adding data lines and multiple columns with a form
I need to add multiple data rows and columns to a database using a form online and don't know what would be the best method of data entry and of insertion.
The data should look like this:
COLUMN1 COLUMN2
var1, var1
var2 var2
var3 var3
etc...
When you create the form do I create individual text fields for each var or would it be better to have a text field where they list the data. I don't know where to start.
Any advice would be great.You can use line numbers in your domain names to associate the columns for a particular record. For example, suppose you want 5 rows enter the last names and first names:
First name:
First name:
This will give you a series of areas such as lname1, lname2, fname2, $fname1, etc.
In your form, you can also include a hidden field to indicate the number of lines.
When you process the form, you loop again to insert each line:
INSERT INTO mytable (name, first name)
VALUES ("#Form ["lname"& onerow] #") ',' #Form ["Pnom" & onerow] #')
-
Hello
I am train to write a procedure where I would spend the table as a parameter name and then the code would determine it is column names, and then he would insert records in each column depending on the data type. could someone help me with this.
Thank you
SM
Hello
Perhaps you need to dummy data just for the table.
Here is my exercise
create or replace procedure generate_rows(p_table_name varchar2, p_count number) is -- function insert_statement(p_table_name varchar2) return clob is l_columns clob; l_expressions clob; l_sql clob default 'insert into p_table_name (l_columns) select l_expressions from dual connect by level <= :p_count'; begin select -- l_columns listagg(lower(column_name), ',') within group (order by column_id), -- l_expressions listagg( case when data_type = 'DATE' then 'sysdate' when data_type like 'TIMESTAMP%' then 'systimestamp' when data_type = 'NUMBER' then replace('dbms_random.value(1,max)', 'max', nvl(data_precision - data_scale, data_length) ) when data_type = 'VARCHAR2' then replace(q'|dbms_random.string('a',data_length)|', 'data_length', data_length ) else 'NULL' end, ',') within group (order by column_id) into l_columns, l_expressions from user_tab_columns where table_name = upper(p_table_name); -- l_sql := replace(replace(replace(l_sql, 'p_table_name', p_table_name), 'l_columns', l_columns), 'l_expressions', l_expressions); -- debug dbms_output.put_line(l_sql); -- return l_sql; end; begin execute immediate insert_statement(p_table_name) using p_count; end; / -- test create table mytable( id number(4,0), txt varchar2(10), tstz timestamp with time zone, dt date, xml clob ) ; set serveroutput on exec generate_rows('mytable', 10); select id, txt from mytable ; drop procedure generate_rows ; drop table mytable purge ; Procedure GENERATE_ROWS compiled Table MYTABLE created. PL/SQL procedure successfully completed. insert into mytable (id,txt,tstz,dt,xml) select dbms_random.value(1,4),dbms_random.string('a',10),systimestamp,sysdate,NULL from dual connect by level <= :p_count ID TXT ---------- ---------- 3 WnSbyiZRkC 2 UddzkhktLf 1 zwfWigHxUp 2 VlUMPHHotN 3 adGCKDeokj 3 CKAHGfuHAY 2 pqsHrVeHwF 3 FypZMVshxs 3 WtbsJPHMDC 3 TlxYoKbuWp 10 rows selected Procedure GENERATE_ROWS dropped. Table MYTABLE dropped.and here is the vision of Tom Kyte for the same https://asktom.oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:2151576678914
Edit: to improve my code, it must use p_count as bind as Tom.
-
Display of the data without knowing the columns.
Hello
I want to display data AS that OF EMP TABLE USING plsql.
7499 "ALLEN SALESMAN" 7698 ' 20 / 02/1981 ' 1600, 300, 30
Without knowing the column emp TABLE I want to display data.i have tried, but does NOT...
DECLARE
CURSOR c1 IS SELECT * from all_tab_columns WHERE table_naMe = 'EMP ';
CURSOR c2 IS SELECT * FROM emp;
v_column_name varchar (200);
BEGIN
I'm IN c1 LOOP
FOR j IN LOOP c2
v_column_name: = 'j' | i.column_name;
dbms_output.put_line (v_column_name);
END LOOP;
END LOOP;
END;
Kind regards
John
Hi John,.
Maybe this can help you:
create or replace procedure prc_show_rows ( table_in varchar2 ) is CURSOR c1 IS SELECT * FROM all_tab_columns WHERE table_name = upper (table_in); type table_output is table of varchar2(32000); -- this can be a problem with large rows work table_output; v_statement varchar2(2000); BEGIN -- v_statement := 'select '; -- FOR j IN c1 LOOP v_statement := v_statement || j.column_name || ' || '' '' || '; -- may be you need some more formatting with appropriate to_char clauses END LOOP; -- v_statement := rtrim ( v_statement, ' |''') || ' from ' || table_in; -- dbms_output.put_line ( v_statement ); -- not necessary, only for testing -- execute immediate v_statement bulk collect INTO work; -- for i in 1..work.COUNT loop dbms_output.put_line(work(i)); end loop; END; / exec prc_show_rows ( 'emp'); exec prc_show_rows ( 'dept');concerning
Kay -
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you.Column does not have the property to escape. It is part of the output text.
Something like
Arun-

Maybe you are looking for
-
Since upgrading to FF 29.01 random existing tabs will be open to pages days and weeks, even if these specific site pages were deleted from the history. Forex, an article from ZDNet Six clicks continued to appear - with its history of Page-return outd
-
Internet LAN conection problem when power is connected - Satellite M70
Hello I recenetly bought a satellite M70 - 360. For some reason, internet connection (LAN) only works when the computer is running from the battery to the moment where you plug in the AC adapter, it is cut (you can also hear that there is some type o
-
Support of Sony BDP-S360 current FW bit BD
I just updated my firmware to 11.4.011 which was published on 10/02/2011 and almost every disc I put in the drive I am presented with an "Invalid" message on the player and the 'unknown' on the screen. I was confuse up-to-date firmware would take car
-
How to upgrade LR 6.4 to 6.6 desktop on MAC version?
I bought a desktop version of LR 6.11 as an integral part of the creative suite 6 - installed on MAC OSx 10.11.5 (15F34) "El Capitan."Update 6.11 LR LR 6.4 using the application manager was not a problem, but now the application manager is disabled.S
-
JUST DOWNLOADED FREE TRIAL AND IT USUALLY OPEN TO ALL.
someone has any ideas >?