PL/SQL implementation of algorithm of backpack without terminals?
Hello world
I am currently working on an algorithm to find the best possible combination according to a lower cost for > = necessary quantity (it's much a similar to a backpack boundless algorithm). For example, if 100 pieces are necessary since the given pool stores (see the data in the table below), I have to come up with a best possible combination. So, in this example, the best choice would be to pull the store_id (A, B, C). I'm currently experimenting with a limited record set 20 who, according to my approach (ie the brute force) who would SELECT (POWER (2.20)) FROM DUAL; 1048576 * 20 iterations and it takes more than 30 seconds using pure PL/SQL. Some information more I play a few checks to see if one store has a required amount then choose the store and out else make a comparison of cross join assuring that the store_id even are not attached then finally if nothing bothers me the quantity required then I'll for a brute force approach. If there is a best way to short circuit the third stage or all have a similar problem and came up with a BETTER solution, please let me know. He could help me and probably many others (SQL approach is available but not PL/SQL). I tried to look for something similar online but has never been able to find any implementation of PL/SQL of the algorithm of bag backpack.
store_id available_qty cost_per_unit
| A | 43 | 1.93 |
| B | 34 | 2.01 |
| C | 27 | 2.12 |
| D | 24 | 2.18 |
| E | 24 | 2.18 |
| F | 24 | 2.18 |
Table script and insert above instructions
DROP TABLE available_qty;
CREATE TABLE available_qty (store_id VARCHAR2 (1) PRIMARY KEY,)
available_qty NUMBER,
cost_per_unit NUMBER);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES ('A',
43,
1.93);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES ('B',
34,
2.01);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES ('C',
37 M
2.12);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES (',)
24,
2.18);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES ('E',
24,
2.18);
INSERT INTO available_qty)
store_id,
available_qty,
cost_per_unit)
VALUES ('F',
24,
2.18);
COMMIT;
The package that I put in place (I took ideas from multiple sources and come to this, just so that everyone knows)
CREATE or REPLACE PACKAGE get_available_qty
IS
TYPE available_qty_typ IS RECORD (store_id VARCHAR2 (1))
available_qty NUMBER,
cost_per_unit NUMBER,
best_combo_flag VARCHAR2 (1));
TYPE available_qty_nt IS TABLE OF THE available_qty_typ;
TYPE available_qty_aat IS TABLE OF THE available_qty_typ
INDEX BY PLS_INTEGER;
FUNCTION get_best_combo (p_qty_required NUMBER)
RETURN available_qty_nt
IN PIPELINE;
END;
/
CREATE or REPLACE PACKAGE get_available_qty BODY
AS
FUNCTION get_best_combo (p_qty_required NUMBER)
RETURN available_qty_nt
PIPELINED
IS
get_available_qty_nt get_available_qty.available_qty_nt
: = get_available_qty.available_qty_nt ();
-Local subprogramme
FUNCTION get_required_qty
RETURN available_qty_nt
IS
v_qty NUMBER: = 0;
v_cost_per_unit NUMBER: = 0;
V_cost_per_unit1 NUMBER: = 0;
v_best_store_id VARCHAR2 (4000) DEFAULT NULL;
v_best_store_id_combo VARCHAR2 (4000);
is_qty_available BOOLEAN DEFAULT FALSE;
is_first_run BOOLEAN DEFAULT TRUE;
v_assign_store_id_flag DBMS_UTILITY.uncl_array;
v_table_length directory.
-Local subprogramme nested
FUNCTION return_null
RETURN available_qty_nt
IS
BEGIN
get_available_qty_nt. Delete;
RETURN get_available_qty_nt;
END;
BEGIN
SELECT aq.*,
"N' best_combo_flag
LOOSE COLLECTION get_available_qty_nt
Of available_qty aq;
FOR indx IN 1... get_available_qty_nt. COUNTING LOOP
v_qty: = v_qty + get_available_qty_nt (indx) .available_qty;
END LOOP;
-If the total available quantity is less than the required quantity can return null
IF v_qty > = p_qty_required THEN
is_qty_available: = TRUE;
ON THE OTHER
get_available_qty_nt: = return_null();
END IF;
-The sub condition will run when the available quantity > = necessary quantity
IF is_qty_available THEN
-Check if any single store has available!
FOR rec IN 1... get_available_qty_nt. COUNTING LOOP
IF get_available_qty_nt (rec) .available_qty > = p_qty_required THEN
IF (v_cost_per_unit > get_available_qty_nt (rec) .cost_per_unit) THEN
v_cost_per_unit: = .cost_per_unit get_available_qty_nt (CRE);
v_best_store_id_combo: = .store_id get_available_qty_nt (CRE);
ELSIF (v_cost_per_unit = 0) THEN
v_cost_per_unit: = .cost_per_unit get_available_qty_nt (CRE);
v_best_store_id_combo: = .store_id get_available_qty_nt (CRE);
END IF;
END IF;
END LOOP;
-Reset local variables
IF v_best_store_id_combo IS NOT NULL THEN
is_qty_available: = FALSE;
ON THE OTHER
v_cost_per_unit: = 0;
v_best_store_id_combo: = NULL;
END IF;
-If above condition does not then execute a combination of Cartesian product comparison
IF is_qty_available THEN
BECAUSE me in 1... get_available_qty_nt. COUNTING LOOP
v_qty: = 0;
v_cost_per_unit1: = 0;
FOR j IN 1... get_available_qty_nt. COUNTING LOOP
IF (get_available_qty_nt (i) .store_id! = get_available_qty_nt (j) .store_id) THEN
v_qty: = get_available_qty_nt (i) .available_qty
+ get_available_qty_nt (j) .available_qty;
v_cost_per_unit1: = get_available_qty_nt (i) .cost_per_unit
+ get_available_qty_nt (j) .cost_per_unit;
IF v_qty > = p_qty_required THEN
IF (v_cost_per_unit! = 0)
AND v_cost_per_unit1 < v_cost_per_unit) THEN
v_cost_per_unit: = v_cost_per_unit1;
v_best_store_id_combo: = get_available_qty_nt (i) .store_id
|| ','
|| get_available_qty_nt (j) .store_id;
ELSIF v_cost_per_unit = 0 THEN
v_cost_per_unit: = v_cost_per_unit1;
v_best_store_id_combo: = get_available_qty_nt (i) .store_id
|| ','
|| get_available_qty_nt (j) .store_id;
END IF;
END IF;
END IF;
END LOOP;
END LOOP;
-Reset local variables
IF v_best_store_id_combo IS NOT NULL THEN
is_qty_available: = FALSE;
ON THE OTHER
v_cost_per_unit: = 0;
v_cost_per_unit1: = 0;
v_best_store_id_combo: = NULL;
END IF;
-Carry out all possible combinations (Brute Force approach)
IF is_qty_available THEN
BECAUSE me in 1... POWER (2, get_available_qty_nt.) (COUNT) - 1 LOOP
v_qty: = 0;
v_best_store_id: = NULL;
v_cost_per_unit: = 0;
FOR j IN 1.get_available_qty_nt. COUNTING LOOP
IF BITAND (i, POWER (2, j - 1))! = 0 THEN
v_qty: = v_qty + get_available_qty_nt (j) .available_qty;
v_best_store_id: = v_best_store_id | get_available_qty_nt (j) .store_id | ',';
v_cost_per_unit: = (v_cost_per_unit + get_available_qty_nt (j) .cost_per_unit);
END IF;
END LOOP;
IF (v_qty > = p_qty_required) THEN
IF is_first_run THEN
v_cost_per_unit1: = v_cost_per_unit;
is_first_run: = FALSE;
END IF;
IF (v_cost_per_unit < = v_cost_per_unit1) THEN
v_best_store_id_combo: = RTRIM (v_best_store_id, ",");
v_cost_per_unit1: = v_cost_per_unit;
END IF;
END IF;
END LOOP;
END IF;
END IF;
END IF;
-Make a list for the allocation of the Pavilion
DBMS_UTILITY.comma_to_table (list = > v_best_store_id_combo,)
Many = > v_table_length,
tab = > v_assign_store_id_flag);
FOR k in 1... v_assign_store_id_flag. COUNTING LOOP
FOR l IN 1... get_available_qty_nt. COUNTING LOOP
IF get_available_qty_nt (l) .store_id = v_assign_store_id_flag (k) THEN
get_available_qty_nt (l) .best_combo_flag: = 'Y ';
END IF;
END LOOP;
END LOOP;
RETURN get_available_qty_nt;
END;
BEGIN
get_available_qty_nt: = get_required_qty();
BECAUSE me in 1... get_available_qty_nt. COUNTING LOOP
PIPE ROW (get_available_qty_nt (i));
END LOOP;
RETURN;
END;
END get_available_qty;
-When you call the function, it returns the result back with indicators updated for stores with the most profitable combination!
SELECT *.
TABLE (get_available_qty.get_best_combo (100))
ORDER BY best_combo_flag DESC;
The best combination for 100 items stores are marked "Y".
store_id available_qty cost_per_unit best_combo_flag
| A | 43 | 1.93 | THERE |
| B | 34 | 2.01 | THERE |
| C | 27 | 2.12 | THERE |
| D | 24 | 2.18 | N |
| E | 24 | 2.18 | N |
| F | 24 | 2.18 | N |
SELECT *.
TABLE (get_available_qty.get_best_combo (70))
ORDER BY best_combo_flag DESC;
The best combination of store that will make up 70 or more items are marked "Y".
store_id available_qty cost_per_unit best_combo_flag
| A | 43 | 1.93 | THERE |
| B | 34 | 2.01 | THERE |
| E | 24 | 2.18 | N |
| D | 24 | 2.18 | N |
| F | 24 | 2.18 | N |
| C | 27 | 2.12 | N |
Sorry, this seems to be a problem trivial backpack to me, since the 'size' different weighted units is the same.
Then you can simply use a greedy algorithm, taking the cheaper units first.
This could easily be done using analytical functions.
The magic number here is 100. It can be replaced by a parameter or variable binding.
To make it more unambigous in two stores have the same costs, you can extend the order by the analytical function with the value.
Select
store_id
available_qty
cost_per_unit
case
When nvl (sum (available_qty) (cost_per_unit order
lines between unlimited and 1 preceding)
0)
< 100="" then="">
another "n".
end best_combo_flag
of available_qty
order of cost_per_unit, store_id
STORE_ID AVAILABLE_QTY COST_PER_UNIT BEST_COMBO_FLAG A 43 1.93 THERE B 34 2.01 THERE C 27 2.12 THERE F 24 2.18 N D 24 2.18 N E 24 2.18 N
Post edited by: chris227
Tags: Database
Similar Questions
-
Hi, I tried to figure out how to extract data from my SQL Server databases and reading messages and to do some tests with examples, I can get data connection type in my SQL server, but so far nothing helps. Is it possible to get data from a SQL Server database without using the database connectivity Toolkit? and if so, how? are there whitepapers and/or examples of this? So far, I can't find something that works. Thank you.
Jesse - what is your reason for not using the database connectivity Toolkit? It is by far the best way to recover the data.
-
Implementation of the updated code without having to restart the Simulator?
I use Eclipse 3.5.1 with the plug-in of the BlackBerry Java 1.1.1 with the BlackBerry Java SDK 5.0.0.14.
Running the BlackBerry Simulator works very well. However when I update my code and try to run or debug him again once I get the following error:
"BlackBerry debugging session is already active. BlackBerry that a debugging session can be active at a given time. »
If I close the Simulator, then I can run the updated as expected in a new Simulator code. However this slows me down because I have to wait 60 + seconds for the Simulator load to make my updated code can run.
Is it possible to update the currently running program without restarting the Simulator?
Debugs faster with a physical device?
Thank you
Drew
No, at the 2009 BlackBerry Developer Conference they have demonstrated that the code of Hot-Swap, GUI Builder and cross-platform support using Eclipse and says that these features would come out of 2010 (from what I remember; GUI Builder-early 2010 but in another post, one of the devs RIM said they aim for mid-2010, Hot-Swap and cross-platform would be mid-2010). Patience and it will come... wish just time would go faster.
-
Please: sql script to remove all users without objects on all databases
Hi *.
I need a big help each of you please.
I have many users who is not more work in our society. Some who receive objects are locked. There are a lot of users and many database servers. And it's that long to finish this work.
That the why I need your help to give me Scripts anyone who falls all users who have not all objects in all databases on all the oracle Server.
Und other to import all users of all users who still get items in a table. And I guess to do before Friday 03 July 09.
Thank you very much in advance
Sincerely your
Ora_Genie>
Vincent wrote:
to give you all the users with no object.To simplify can run the script generated by
>Hi Michaels,
This may not work
SQL> Create user michaels identified by michaels 2 / User created SQL> SELECT 'drop user ' || owner || ' cascade;' stmt 2 FROM all_objects 3 Group BY owner 4 Having Count(*) = 0; STMT -------------------------------------------------Maybe this,.
SELECT 'drop user ' || a.username || ' cascade;' stmt FROM all_users a , all_objects b WHERE a.username = b.owner(+) AND b.owner Is Null Group BY a.usernameKind regards
Christian BalzPublished by: Christian Balz 07/02/2009 11:18
-
Implementation of the synchronization steps without using batch or parallel processing sequences
We use a model of customized integrated process based on sequential process model.
I have to call the Synchronization Manager in order to use the steps of synchronization when you do not use batch or models of parallel process?
All operations (locks, Rendezvous, Notifications, queues, etc.) and the steps of synchronization works in any model or a model, with the exception of the synchronization of the lot.
If you need batch synchronization, your model must use synchronization > advanced > step type specification of batch processing to specify what threads are in the batch. Since you are not from the model of batch processing, I doubt that you have to worry about this.
-
need to insert a node before a node without terminals in a variable
Hello
I have a script something like this, I have a variable x that contains an xml underneath, where the un_node1 and the un_node2 are endless. I want to insert a new node (which is also un_node2) just before the 1st un_node2. basically the new node that I have to insert should be the first un_node2 boundless.
Can you please help me do this? I'm doing it in one of the streams in OSB.
I tried to use an action insert to do this by having the xpath like:. / *: un_node [1]. But it does not work with a validation failure saying "."
< r: var_root >
< name r: un_node1 = "xxx" >
< r: value >... < / r: value >
< / r: un_node1 >< name r: un_node1 = "yyy" >
< r: value >... < / r: value >
< / r: un_node1 >
< name r: un_node1 = "zzz" >
< r: value >... < / r: value >
< / r: un_node1 >< name r: un_node2 = "aaa" >
< r: value >... < / r: value >
< / r: un_node2 >
< name r: un_node2 = "bbb" >
< r: value >... < / r: value >
< / r: un_node2 >
< name r: un_node2 = "ccc" >
< r: value >... < / r: value >
< / r: un_node2 >
< / r: var_root >Whatever the XQ is valid if it says nowhere?
. / *: un_node [1]
It should be
. / *: un_node2 [1]
or, perhaps, even (sometimes it makes a difference, but I don't remember if it's the one case, sorry):
(. / *: un_node2) [1]
Vlad
< signature="" link="" removed="" by="" moderator,="" as="" per="" the="" otn="">FAQ >
-
In good company the child elements of the element without terminals are not visible.
Hi all
Jdev version 11.1.1.7.0
I am facing a company in good standing question...
Scenario: I create approval Service (BPEL) with flow of human labor and the Bunises rule.
I'm assingning HW participating using the rule based (HW and BR connection).
Problem is:
Shema has element 'unbounded '.
< name of item = "ExpenseItem" maxOccurs = "unbounded" >
< complexType >
<>sequence
< element name = "ItemID" type = "string" / >
< element name = "ItemName" type = "string" / >
< element name = "ItemPrpjectID" type = "string" / >
< element name = "ItemStatus" type = "string" / >
< / sequence >
< / complexType >
< / item >
Whenever I have create a Busines to configure rules.
ExpenseItem rules setting up the child elements are not visible. But those who are required to configure rules.
If you can help solve me would be useful.
What is a behavior bedault of the BR? If yes how can I do this?
Thank you
David
Solution found:
Click on set of rules that you have created.
Expand rule in there.
Select the Advanced mode and mode tree, and then click OK.
Select the root task, click insert pattren and create pattren based on unrelated element (here actually destiny)
Once you create pattren, will be elements of access under item boundless for the configuration of business rules. -
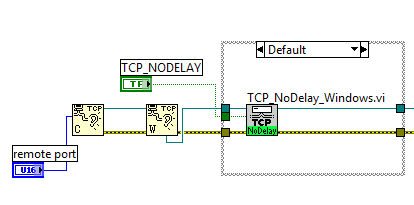
Nagle algorithm affecting TCP listening
I have two LabVIEW applications communicate with each other over TCP for a monitor streams data to a receiver. Ideally, I'd like my monitor, that generates the data, to listen to a TCP connection and then send data via this connection when my receiver connects to it. When I structure my code in this manner, I find that I get peak latencies of ~ 500ms (!).
I came across the following knowledge base article functions use LabVIEW TCP Nagle Algorith? and initially found no speed upward.
When I reorganized my code so that the receiver has acted as a listener and my monitor connected to the port of receivers and IP, then the TCP function without delay worked as announced.
There experience with disabling the Nagle algorithm on a listening port, for example like this?
I wish that my application of monitoring to act as a passive monitor other applications that can connect to.
I found the question once I started to do a test project to illustrate the problem.
My receiver application was configured as a state machine waiting in line and there was a bug where read occaisionally would not wait it on the TCP protocol. It resembled a bottleneck on the side sending. When I changed between the two implementations I removed the bug without knowing what actually look as if the issue was with how I disable the Nagle algorithm.
Everything seems to work fine now!
-
CF9, IIS7 and SQL Server 2008 R2 - recommendations
Hello ladies and gentlemen,
I've been task (in a short period of time), to place a CF site built by another group (and by selecting an Oracle DB), on IIS7 using SQL Server 2008 R2 and CF9 without CF Builder.
I did a little research (but not enough) and found contradictory answers as you install CF9 on the same box that IIS7 and others say place CF9 on your PC (logic). I have the Adobe Press books for CF9 however they reference CF Builder (don't have) and Dreamweaver CS5 not (have). I'll add that the last time I used CF was CF5. My hat went to Adobe for all the major improvements.My question: where, in your opinion can I find a good 'How to' source to make this all come together?
Thank you!
JoDigitalThe ColdFusion server documentation says you really all what you need to know, and it's pretty concise. I recommend to only start there.
You install CF on your IIS server for your production environment. This is the standard approach 99 + % of the time. There are two alternative approaches: distributed mode and reverse proxy configuration, but unless you have very specific requirements (usually related to security) you can safely of these approaches ignore.
Generator of CF and Dreamweaver are tools of development. You don't have to worry of allowing them to set up your production environment. Individual developers can use CF Builder, Dreamweaver (or really any other text editor) installed on their own workstation to write scripts that can be deployed in a test environment or development. Independent developers can also install CF on their own workstation, if they want to test locally - it's a fairly common thing to do. But none of this has nothing to do with the implementation of your production environment, really.
None of these things have really changed that much since the CF 5 either. As with CF 5, you install CF on your production web server, and you can also install it locally for development.
If you switch from Oracle to SQL Server, this is something separate, which will require that you change things on your database and in your existing code base CF.
Dave Watts, CTO, Fig Leaf Software
-
The Marching squares algorithm
Hi all
I have a question about the marching squares algorithm to construct contours based on values in a 2D grid.
I tried to implement this algorithm in LabVIEW but I failed again as I still can't wrap my head around the algorithm.
My question was if it is previously written code of the marching squares algorithm? I also have my attempt to implement the algorithm VI attached if that's any help.
My attempt is based on the information I've read on the Marching Squares algorithm wikipedia page (http://en.wikipedia.org/wiki/Marching_squares)
Thank you
Lucien
What about the contour line.vi ?
http://forums.NI.com/T5/LabVIEW/temperature-surface-graph/m-p/2689661#M799633
Kind regards
Alex -
Algorithm of PID in 'PID and Fuzzy Logic Toolkit' and 'real time Module ".
Hi all
I am recently using LabVIEW 2011 and 2011 real time Module. My application requires the PID control.
Now, I have a problem. In the manual for "And Fuzzy Logic Toolkit PID", Chapter 2 "algorithm PID" it indicates non-interactive algorithm (also called the ideal algorithm, Standard or ISA) be used in all the screws of PID in the Toolbox. It seems that Yes from source code. However, in Chapter 3, "Using the PID software" arrays of calculation of PID parameters based on method of Ziegler-Nichols, which was developed for the interactive algorithm (also called the series, the real classic algorithm). D action has been included in the scheme of control, the settings may be different for the two algorithms. In fact, Cohen Coons and adjustment PID Lambda rules can be used for the algorithm used by the box tool with no conversion.
In addition, there is a PID function block comes with the real time Module, and I know not what PID algorithm it uses. Can someone help me?
Thank you in advance.
Su
In the "and Fuzzy Logic PID Toolkit, we use the University structure to implement all algorithms. Tuning techniques we show on the manual to express the original work and we try to keep the same as you would look at the literature. However, in our implementation of autotuning internally converted to the structure used by our algorithms to keep compatibility with our own implementation.
If you use an external source, you can use the Conversion.vi of Structure PID to change University, parallel or series of parameters in one used by our algorithm.
The PID included with the real time module is a 'copy' of our algorithm, and they have the same settings and behavior. The only advantage to use this function block, you have access to the parameters through variables.
Hope this helps...
-
Circle quick algorithm (Bresenham?) drawing to transform circular Hough
I worked on a circular Hough transformation algorithm for circle detection and I am interested in finding ways to make a little more efficient. At high level, I implement some queueing of client/producer model between the data collection and analysis/filtering, but I think that the circle of operation for the accumulation of Hough of drawing could use some breaking in. That's where I'd love help from you, the experienced programmers of LabVIEW.
I used simple trigonometry draw pixels with some angular resolution, but I think using a circle drawing algorithm as the algorithm of circle in the middle (variation of Bresenham circle) is probably smarter in the end. The abomination of hidious of LabVIEW script I created for her, however, is not complete as quickly as I had hoped. I followed the C code written here: http://members.chello.at/~easyfilter/bresenham.html
You can find the attached VI. It takes in a matrix of pixels in an image binary (0 to 255), with the edges and draw circles centered on each pixel 255 with the given radius. "Drawn" circles are simply a list of coordinates, the output array. Anyone have any suggestions on how to improve this VI? Or maybe even some input to the notion of transformation of Hough set?
Hi Vekkuli!
I have, but a few recommendations for this function. Mind you, this is just my point of view, there could be more advantageous alternatives.
- For the calculation of the pixel when you used the formula nodes. I think it's a little overdosed because it's only in addition/subtraction, so you can just do that in LabVIEW.
- When collecting the coordinates, try to avoid using registers at offset and table build to add new items in each iteration. Because arrays are dynamic data types, this causes the compiler to allocate a new, bigger memory, copy the entire table with the new elements, and then free the old memory. Do what each iteration is quite a Devourer of performance. A better approach would be to use indexing or concatenation of tunnels.
- Borrowing tunnels of indexing to collect data also added, advantage to the outer loop (the iterate over all pixels) paralellizable, which could be a big performance increase, assuming a multi-core PC.
- You can get a possible increase in speed by drawing octants instead of quadrants, creating 8 points at each iteration.
I also tried my hand to implement this algorithm that creates a circle, here is the result:
On the transformation of Hough, there are examples of LabVIEW implementation, made at the University of Texas. You will find them here.
I hope this helps.
Kind regards:
Andrew Valko
NOR Hungary
-
How to move to Windows 10 without knowing the password admin for Windows 7?
Try to upgrade to Windows 10 but the upgrade program requires the Windows 7 Administrator password. He had not used in years and forgot it. Kim Komando recommended the implementation of user account separated without administrative privileges to security assistance and I did several years ago. What should I do now? Help?
Hello
We are sorry for the inconvenience, and we understand the frustration when things don't go the way they're supposed to.
If you forget the administrator password, and you do not have a password reset disk or another administrator account, you will not be able to reset the password. If there is no other user account on the computer, you will not be able to connect to Windows and you will need to re - install Windows.
Ref: what to do if you forget your Windows password
Now, in order to perform a custom installation of Windows 7, you must first download the ISO image from the link below.
Download Windows 7 Disk Images (ISO files)
Note: A custom installation doesn't keep your programs, files or settings. Backup your current Windows installation. Because you will make important changes on your computer, you should always back up before doing so. It is strongly recommended.
Write to us with the status updated on the specific issue of the account. If you would like more information, we would be happy to help you.
Thank you.
-
Original title: uac
How can I disable the popup control in the user account that appears on my desktop to allow or reject the changes when I open a program without changing my user account settings.
You want should not do that. These pop-up UAC is there to ensure the interaction of the user before executing a command or program. Disabling, allows even unwanted programs (= malware, viruses, Trojans) go ahead and implement themselves on your system without being noticed.
-
Clarification of the SQL query in 2 day + Guide APEX
I worked through the Oracle Database Express Edition 2 day + Application Express Developer's Guide, and try to decipher the SQL query in Chapter 4 (building your app).
The code is:
SELECT d.DEPARTMENT_ID,
d.DEPARTMENT_NAME,
(select count (*) from oehr_employees where department_id = d.department_id)
"Number of employees", he said.
substr (e.first_name, 1, 1) |'. ' || Select 'Name Manager',
c.COUNTRY_NAME 'place '.
OEHR_DEPARTMENTS d,
E OEHR_EMPLOYEES
OEHR_LOCATIONS l,
C OEHR_COUNTRIES
WHERE d.LOCATION_ID = l.LOCATION_ID
AND l.COUNTRY_ID = c.COUNTRY_ID
AND e.department_id = d.DEPARTMENT_ID
AND d.manager_id = e.employee_id
AND instr (superior (d.department_name), superior (nvl (:P2_REPORT_SEARCH,d.department_name))) > 0)
I don't know exactly what is happening in the last line. I think I understand what the different functions but I'm not clear on the use of the: P2_REPORT_SEARCH string.
What does this string? This code simply checking that d.department_name isn't NA?
I have SQL experience but am not very familiar with the Oracle PL/SQL implementation. Can someone please give me a brief breakdown that check is doing in the context of the overall query? The application seems to work even if the conditional statement is not included.
Thank you.
2899145 wrote:
Thanks for the reply. I apologize if the information I added was incomplete. The code came from the day 2 + Application Express (version 4.2) Developer Guide.
In the section 'your own Application of 4 Buuilding' https://docs.oracle.com/cd/E37097_01/doc.42/e35122/build_app.htm#TDPAX04000 , they describe the creation of a report
page that includes the "manager_id" and 'location_id '. The SQL query, I pasted above extracted from the data in other tables to substitute the real 'name of the Manager' and 'rent '.
for the corresponding ID values. It makes sense, and the part of the SQL query that explicitly doing this makes sense.
However, given that the document is a guide for the development of the APEX, I guess the command:
AND instr (upper (d.department_name), upper (nvl (:P2_REPORT_SEARCH,d.department_name))) > 0
done something valuable, and I do not recognize what is exactly the value.
From a practical point of view why would I need to include this conditional statement? Which only added to the application?
Looking at the guide in question, it is clear that the
AND instr(upper(d.department_name),upper(nvl(:P2_REPORT_SEARCH,d.department_name)))>0
the line is completely unnecessary in the context of this tutorial, and it can be removed. The search in the tutorial app page is implemented by using a report filter interactive rather than a P2_REPORT_SEARCH element, which does not seem to exist at all. (It's a quirk of the APEX that bind variable references to non-existent items are replaced with NULL silently rather than exceptions). I thought that perhaps it would be legacy code a version of the tutorial prior to the introduction of interactive reports at the APEX 3.1, but I can't find explicit instructions to create such an element of filter in the 3.0 tutorial. I guess it must have been automatically generated by the application wizard when you create a standard report page.
If you do not want to see the effect he would have (as described in the post above), leave it in the source report, add a text element of P2_REPORT_SEARCH, and a button "submit" on page 2 and experimenting to find different values of the element and clicking on the submit button...


Maybe you are looking for
-
In "Add or remove programs' done 'change '?
I am trying to run Combofix and it want me to have the updated Recovery Console which I think has something to do with "Service Pack 2, 3.0" I tried the update section, but it says that everything is up to date. So I chose change in Add or remove pr
-
How to make a copy of win xp serv pack 3 disc
Original title: How can I get a copy of win xp serv pack I'm under win xp ser pack 3 and I need to set some files to run the internal CD-ROM. It appears about 6 times saying these files need fixing but not using the disc that I bought with my compute
-
I can't download the Visual form photo my camera to my pc
I need help. The image is available for download but not the video images. Why?
-
Xperia M4 E2303 Aqua - problem with SD card.
Hello Recently I bought the Aqua M4 on a contract with a mobile phone service provider Vodafone, but the main problem I had with the phone is that the microSD card slot is malfunctioning and it glitched my phone which is very boring and useless... Th
-
Hi guys I'm new and will try to do the best I can I have a HP Pavilion a6110n PC with all original material. Motherboard: M2N68 - LA CPU:Athlon 64 X 2 (B) 4400 My cpu is dead so I had to switch to a new processor, the problem is that I don't have hig