Ranking on consecutive dates
Hi guys,.
I've been struggling with this for a few days already and I tried to implement different solutions, that I was able to get the internet search and apply some learned approeaches from this forum on similar questions, but perhaps than if I put that question here someone knows exactly how best to manage :
So, I have a table like this:
with payments as
(
select '1' as ID, '20130331' as DateR, 'Not_paid' as Status from dual
union
select '1' as ID, '20130430' as DateR, 'Paid' as Status from dual
union
select '1' as ID, '20130531' as DateR, 'Not_paid' as Status from dual
union
select '2' as ID, '20130331' as DateR, 'Not_paid' as Status from dual
union
select '2' as ID, '20130430' as DateR, 'Not_paid' as Status from dual
union
select '3' as ID, '20130331' as DateR, 'Paid' as Status from dual
union
select '3' as ID, '20130430' as DateR, 'Paid' as Status from dual
union
select '3' as ID, '20130531' as DateR, 'Paid' as Status from dual
)
And I try to get the amount of the current row when of a user. Now it begins to count whenever the previous payments had been paid or it s the first payment.
I tried to get dense rank, that gives me output:
select ID, dater, status, dense_rank() over (partition by ID, status order by dater asc) rnk from payments
But I need to get something like this:
ID DATER STATUS RNK
1 20130331 Not_paid 1
1 20130430 Paid 1
1 20130531 Not_Paid 1
2 20130331 Not_paid 1
2 20130430 Not_paid 2
3 20130331 Paid 1
3 20130430 Paid 2
3 20130531 Paid 3
Such as if I want to get the max (rank) to check how the defaults a user has currently I get this ID has 1 unpayment, ID 2 two consecutive unpayments, and ID 3 0 unpayments. This is because I have to take into account the user as brewed on the fourth consecutive non-payment.
Hello
Here's one way:
WITH got_grp_num AS
(
SELECT p
ROW_NUMBER () OVER (PARTITION BY ID.
ORDER BY date
)
-ROW_NUMBER () OVER (PARTITION BY id, status)
ORDER BY date
) AS grp_num
PAYMENTS p
)
SELECT id, date, status
, ROW_NUMBER () OVER (PARTITION BY id, status, grp_num)
ORDER BY date
) AS rnk
OF got_grp_num
ORDER BY id, date
;
For an explanation of the technique of Difference sets used here, see
https://forums.Oracle.com/forums/thread.jspa?threadID=2302781 and/or
https://forums.Oracle.com/forums/thread.jspa?threadID=2303591
Moreover, store date information in a column of sting is simply asking for trouble. Use a DATE column.
Tags: Database
Similar Questions
-
Consecutive date grouping and find the largest number of consecutive group
Hi all
I have given dates and I want to find the largest number of consecutive dates
WIN_DATE_DATA
2015-09-22
2015-09-23
2015-09-27
2015-09-28
2015-09-29
2015-09-30
2015-10-1
In this example, there are 2 group of consecutive dates
Group 1
2015-09-22
2015-09-23
Group 2
2015-09-27
2015-09-28
2015-09-29
2015-09-30
2015-10-1
The OUTPUT should 5 which is the largest grouping of consecutive number.
Thanks in advance for the help!
Please take a look at the Community document: 101 PL/SQL: grouping sequence ranges (method Tabibitosan)
will allow you to do.
-
The highest sum of the values in any 3 consecutive dates.
Hello
Given
create table test (colamt COMP, coldate date);
Insert test values (10, sysdate + 1);
Insert test values (20, sysdate-1);
Insert test values (5, sysdate-5);
Insert test values (25, sysdate);
Insert test values (35, sysdate-11);
Insert test values (10, sysdate + 1);
Insert test values (1, sysdate-1);
Insert test values (5, sysdate-2);
Insert test values (20, sysdate-3);
Insert test values (10, sysdate-4);
commit;
SQL > select * from test by coldate;
COLAMT COLDATE
---------- ---------
35 19 MARCH 15
5 25 MARCH 15
10 26 MARCH 15
20 MARCH 27, 15
5 MARCH 28, 15
20 MARCH 29, 15
1 MARCH 29, 15
25 MARCH 30, 15
10 MARCH 31, 15
10 MARCH 31, 15
I need to find the highest sum of colamt for the whole period of 3 days.
In this case, it's 50, for the first 3 lines, 19 to March 26.
(In the real world, I need to know the amount the highest recovery archived how many bytes were generated for consecutive periods of 3 size my FRA v$ archived_log)
I'm just a DBA and scratch my head to the analytical functions available for me. : ()
Hello
To display the best total of 3 rows and the date range when the total highest has been reached:
WITH got_total_colamt AS
(
SELECT coldate
SUM (colamt) OVER (ORDER BY coldate
LINES BETWEEN 2 PRIOR
AND CURRENT ROW
) AS total_colamt
, LAG (coldate, 2)
COURSES (ORDER BY coldate
) AS start_coldate
OF the test
)
got_rnk AS
(
SELECT coldate, total_colamt, start_coldate
, EVALUATE () OVER (ORDER BY total_colamt DESC) AS rnk
OF got_total_colamt
)
SELECT total_colamt
start_coldate
coldate AS end_coldate
OF got_rnk
WHERE rnk = 1
;
Output:
TOTAL_COLAMT START_COLDA END_COLDATE
------------ ----------- -----------
50 19 March 2015 March 26, 2015
If you do not need to display the dates, the above query can be shortened a little.
Etbin showed how to get 3 days in response #1, usinng the analytical SUM function totals. The analytic RANK function, estimated above, which of the totals is higher (or, in the event of a tie, lines 2 or more have the largest number). Because you cannot nest analytic functions, the analytical SUM function should be called in a separate subquery before calling the analytic RANK function. Since the analytical functions are calculated after the WHERE clause has been applied, you cannot use in a WHERE clause. That is why RANK is compuuted in another subquery and its results used in the WHERE clause of the main query.
-
A group of consecutive dates to get some absences (days, hours, minutes) and incidents
Hello
I'm trying to calculate and history of lack of list based on the details of lack follows.
Here is what I got: (sorry for the dotted lines between the two, I put it just to format the data)
EMP_ID - WORK_DT - PM - REASON - PAID
=====-----=======------===-=====-- -- ====
123---06/01/2009---8.0---malades---PAYE
123---07/01/2009---8.0---malades---PAYE
123---08/01/2009---8.0---malades---PAYE
123---09/01/2009---8.0---malades---PAYE
123---16/01/2009---8.0---FMLA EMP - paid
123---17/02/2009---8.0---malades---PAYE
123---18/02/2009---8.0---malades---PAYE
123---30/03/2009---8.0---jure - paid
123---21/05/2009---4.0---malades---PAYE
123---22/05/2009---4.0---malades---PAYE
123---03/07/2009---8.0---malades---PAYE
123---25/08/2009---8.0---FMLA EMP - paid
123---26/08/2009---4.5---FMLA EMP - paid
123---21/09/2009---8.0---malades---non paid
123---22/09/2009---8.0---malades---non paid
I need to consolidate absences consecutive full day (8 hours) and show Start_dt, End_Dt, and also to calculate the duration of the absence in days, hours, min. If there is lack of half day (single or consecutive) is not followed by 8 hours, then they should be considered as a new incident (5/21 and 5/22). If the absence of half-day is followed by the absence of all day while they should be grouped together (8/25 and 8/26).
So for the data mentioned above the result should look like:
EMP_ID - START_DT - END_DT - DAYS - HOURS - minutes - INCIDENT - REASON - PAID
===---====== ---- ====== -- === - ==== - === - ====== - ====== -- -- =======
123 4 06/01/2009-01/09/2009 - 0---0---1 - disease - paid
123-16/01/2009 1-16/01/2009 - 0---0---2 - FMLA EMP - paid
123 2 17/02/2009-02/18/2009 - 0---0---3 - disease - paid
123 03/30/2009 1-30/03/2009 - 0---0---4 - Jury service - paid
123 21/05/2009 0 - 21/05/2009 - 4---0---5 - disease - paid
123 22/05/2009 0 - 22/05/2009 - 4---0---6 - disease - paid
123 03/07/2009 1-2009-03-07 - 0---0---7 - disease - paid
123-25/08/2009 1-08/26/2009 - 4-30-8 - EMP - paid FMLA
123 21/09/2009-22/09/2009-2-0-0-9 - disease - unpaid
I am able to group them to gether and get start_dt, end_dt and total days, hours as well as incident to help
Work_Dt - Row_Number() over (order of MIN (Work_Dt) and)
Row_Number() (order MIN (Work_Dt)
but it includes absences consecutive half-day (5/21 and 5/22) together as a single incident that should be considered as separate incidents. any idea or help in this case will be a great help.
Thank youStéphane wrote:
I'm trying to calculate and history of lack of list based on the details of lack follows.
As promised:
with t as ( select 123 EMP_ID,to_date('01/06/2009','mm/dd/yyyy') WORK_DT,8.0 HRS,'Sick' REASON,'Paid' PAID from dual union all select 123,to_date('01/07/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('01/08/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('01/09/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('01/16/2009','mm/dd/yyyy'),8.0,'FMLA EMP','Paid' from dual union all select 123,to_date('02/17/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('02/18/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('03/30/2009','mm/dd/yyyy'),8.0,'Jury Service','Paid' from dual union all select 123,to_date('05/21/2009','mm/dd/yyyy'),4.0,'Sick','Paid' from dual union all select 123,to_date('05/22/2009','mm/dd/yyyy'),4.0,'Sick','Paid' from dual union all select 123,to_date('07/03/2009','mm/dd/yyyy'),8.0,'Sick','Paid' from dual union all select 123,to_date('08/25/2009','mm/dd/yyyy'),8.0,'FMLA EMP','Paid' from dual union all select 123,to_date('08/26/2009','mm/dd/yyyy'),4.5,'FMLA EMP','Paid' from dual union all select 123,to_date('09/21/2009','mm/dd/yyyy'),8.0,'Sick','Unpaid' from dual union all select 123,to_date('09/22/2009','mm/dd/yyyy'),8.0,'Sick','Unpaid' from dual ) select EMP_ID, MIN(WORK_DT) START_DT, MAX(WORK_DT) END_DT, TRUNC(SUM(HRS) / 8) DAYS, TRUNC(MOD(SUM(HRS),8)) HOURS, MOD(SUM(HRS),1) * 60 MINs, INCIDENT, REASON, PAID from ( select EMP_ID, WORK_DT, HRS, REASON, PAID, sum(start_of_incident) over(partition by EMP_ID order by WORK_DT) INCIDENT from ( select t.*, case when lag(WORK_DT,1,WORK_DT) over(partition by EMP_ID order by WORK_DT) = WORK_DT - 1 and lag(HRS,1,8) over(partition by EMP_ID order by WORK_DT) = 8 and lag(REASON,1,REASON) over(partition by EMP_ID order by WORK_DT) = REASON and lag(PAID,1,PAID) over(partition by EMP_ID order by WORK_DT) = PAID then 0 else 1 end start_of_incident from t ) ) group by EMP_ID, INCIDENT, REASON, PAID order by EMP_ID, INCIDENT / EMP_ID START_DT END_DT DAYS HOURS MINS INCIDENT REASON PAID ---------- ---------- ---------- ---------- ---------- ---------- ---------- ------------ ------ 123 01/06/2009 01/09/2009 4 0 0 1 Sick Paid 123 01/16/2009 01/16/2009 1 0 0 2 FMLA EMP Paid 123 02/17/2009 02/18/2009 2 0 0 3 Sick Paid 123 03/30/2009 03/30/2009 1 0 0 4 Jury Service Paid 123 05/21/2009 05/21/2009 0 4 0 5 Sick Paid 123 05/22/2009 05/22/2009 0 4 0 6 Sick Paid 123 07/03/2009 07/03/2009 1 0 0 7 Sick Paid 123 08/25/2009 08/26/2009 1 4 30 8 FMLA EMP Paid 123 09/21/2009 09/22/2009 2 0 0 9 Sick Unpaid 9 rows selected. SQL>SY.
-
Identify the 3 consecutive dates
I have a table with the columns Participant_Id and a Call_Date. My requirement is to check this table every day and determine the Participant ID who acquired records with 3 consecutive Call_Date values in a line. If they do, I'll update a flag on another column table with "Y" (yes). If this isn't the case, I'll put it with "n" (no).
Is there a good way to identify it using PL - SQL?It can probably be simplified, but something like
SQL> ed Wrote file afiedt.buf 1 with x as ( 2 select 1 participant_id, date '2009-03-01' call_date 3 from dual 4 union all 5 select 2 participant_id, date '2009-03-01' call_date 6 from dual 7 union all 8 select 1 participant_id, date '2009-03-02' call_date 9 from dual 10 union all 11 select 2 participant_id, date '2009-03-02' call_date 12 from dual 13 union all 14 select 1 participant_id, date '2009-03-03' call_date 15 from dual 16 union all 17 select 2 participant_id, date '2009-03-04' call_date 18 from dual 19 union all 20 select 1 participant_id, date '2009-03-06' call_date 21 from dual 22 union all 23 select 2 participant_id, date '2009-03-08' call_date 24 from dual 25 ) 26 select participant_id, 27 (CASE WHEN call_date IS NOT NULL 28 THEN 'Y' 29 ELSE 'N' 30 END) y_n_flag 31 from (select participant_id, call_date 32 from (select participant_id, 33 call_date, 34 lag(call_date,1) over (partition by participant_id 35 order by call_date) prior _call_date, 36 lag(call_date,2) over (partition by participant_id 37 order by call_date) prev_ call_date 38 from x) 39 where call_date = prior_call_date + 1 40 and call_date = prev_call_date + 2 ) 41 right outer join 42 (select distinct participant_id 43 from x) 44* using (participant_id) SQL> / PARTICIPANT_ID Y -------------- - 1 Y 2 Nseems to work.
Justin
-
In the results of query with consecutive Dates
I have a table like this:
volume of queue data_date
01/09/01 2324, 353
01/09/03 2324, 34
2324 01/09/04 43
2325 01/09/01 53
01/09/02 2325, 66
I want to have output like this:
volume of queue data_date
01/09/01 2324, 353
* 2324 01/09/02 0 *.
01/09/03 2324, 34
2324 01/09/04 43
2325 01/09/01 53
01/09/02 2325, 66
Note the filled in date 01/09/02.
What I'm doing now is using a function table in select pipeline than iteratates the date of the execution of a statement range for each date and make a current output. A little slow, but faster than the old solution below.
I also define operations using a single query that contains trade unions and disadvantages. This has proved to be slow.
The only thing I have not tried is to have a stored proc popuate the value 0 for the missing date.
Is there another way to do that is effective?
I use a 10g database, but soon the data will be brought to a 11g.Welcome to the forums!
I would say that one of the best ways on the latest versions of Oracle using the PARTITION OUTER JOIN.
See the following link for examples/explanation: partition outer join in oracle 10 g
-
variable sharing, missing data, the timestamp even for two consecutively given
Hello
I have a problem with missing data when I read a published network shared variable.
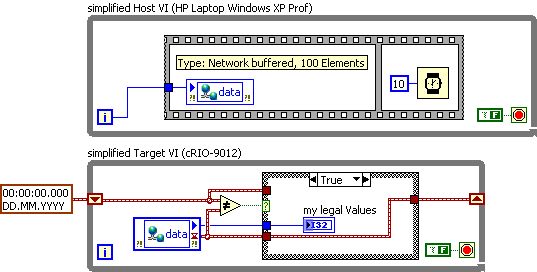
Host VI:
In a host of VI on my laptop (HP with Windows XP Prof.) I write data to the shared Variable 'data '. Between two consecutively write operations is a minimum milliseconds of wait time. I use it because I want to make sure that the time stamp of each new value of data is different then a preview (variables shared the resolution is 1 ms)
VI target:
the VI target cRIO-9012 bed only of new data in the way that it compares the timestamp of a new value with the time stamp of the last value on a device in real time.
Problem:
rarely, I'm missing a data point (sometimes everything works fine for several hours, transfer thousands of data correctly above all of a sudden failure occurs). With a workaround, I'm able to catch the missing data. I discovered that the missing data have the timestamp exactly the same, then the last point of data read, is so ignored in my data 'legal '.
To summarize, the missed value is written to the variable shared host, but ignores the target because its timestamp is wrong, respectively the same as the last value, despite the host waits for a minimum of 10 milliseconds each time before writing a new value.
Note:
The shared Variable is hosted on the laptop and configured using buffering.
The example is simple only to display the function of principle, in real time, I also use a handshake and I guarantee that there is no sub - positive and negative.
Simplified example:
Question:
Anyone has an idea why two consecutively data can have the same timestamp?
Where timestamping (evil) Finally comes (System?)?
What would be a possible solution (for the moment with shared Variables)?
-> I tried to work around the problem with the clusters where each data gets a unique ID. It works but it is slower that comparing the timestamps and I could get performance problems.
It would change anything when I animate the shared on the RT System Variable?
Thanks for your help
Concerning
Reto



This problem has been resolved in LabVIEW 2010. You can see other bugs corrections in theReadme of LabVIEW 2010.
-
Remove the last 35 days of a table data
Hello
I had a table to n days of data. I need to remove the last 35 days of data. My table has consecutive dates i.e. There were no load weekend or holidays...
(1) Using INTERVAL command can simply calculate the difference. So it won't work.
(2) I can use RANK to find the sequence. Is there a better way to write a logic to delete?.
concerning
KVB
PurveshK,
I think you have the right idea. Just get the ID of the innermost query.
This should be quite effective, especially if there is an index on the date.
drop table t;
create table t:
Select trunc (sysdate) - level * 2 double dt connect by level<=>
delete t
where rowid in)
Select rn
de)
Select the rowid rn, dense_rank() over (order by dt desc) dr
t
)
where dr<=>
);
Post edited by: StewAshton:
Furthermore, the date field must be NOT NULL for the index be used - or even add WHERE DATE IS NOT NULL to the innermost query.
-
acquisition of data and processes in FPGA
Hello!
In FPGA, I am trying to acquire analog data (0 ~ 10V) with a specific time clock rising edge of each digital pulse encoder.
I went to get the data on the front, but I don't know how I'd keep th and i + 1 th data.
(Frequency of data is less than 250 kHz)
I have the cRIO-9074, NI 9411 (encode), NOR 9205 (module I),
data
1st, 2nd data, data 3rd 4th 5th 6th 7th... I-1 th, I e, i + 1-th... 1200 e (approx.)
I need every sum of two consecutive data data 1st + 2nd, 2nd + 3rd, 3rd + 4th, l - 1 e + i Thess,... th + (i + 1-th)... 1199 th + 1200 e (about)
On the process of two consecutive sum.
[i - 1 e + i th] / [a value] + [the other i e amount of different data acquisition] = 1199 set of data (up to 1200 th data)
and then
all data across data (data from 1199) will be worth.
Thank you very much!
All tips are welcome!
Sincerely,
Hyo
Looks like a simple feedback node will do the trick.

-
The following response was posted by Frank Kulash back in Oct 2010 response number 774064. Its solution properly back the correct personal ID and the name of the medication. However, my question is as follows. Can it be twisted to bring also the first date of filling?
WITH got_month_num AS (
SELECT DISTINCT name , drug_name , MONTHS_BETWEEN (TRUNC (SYSDATE, 'MONTH') , TRUNC (fill_date, 'MONTH') ) AS month_num Of table_x -- WHERE ... -No filtering goes here )
, got_group_num AS (
SELECT name , drug_name , ROW_NUMBER () (PARTITION BY NAME , drug_name ORDER BY month_num ) - month_num AS group_num Of got_month_num )
SELECT DISTINCT name, drug_name Of got_group_num GROUP BY name, drug_name, group_num HAVING COUNT (*) > = 3 ORDER BY name, drug_name ;
Hello
64a51ebf-6635-47dc-9c7a-f6e5d1b5a34c wrote:
Frank - Here is the link to the original post. Thank you.
Thank you. Now that I can test it, I see that I forgot a MIN nested:
WITH got_month_num AS
(
SELECT name, drug_name
MONTHS_BETWEEN (TRUNC (SYSDATE, 'MONTH'),
, TRUNC (fill_date, 'MONTH')
) AS month_num
MIN (fill_date) AS min_fill_date
FROM table_x
-WHERE... - no filtering is going here
GROUP BY name, drug_name
, TRUNC (fill_date, 'MONTH')
)
got_group_num AS
(
SELECT name, drug_name, min_fill_date
ROW_NUMBER () (PARTITION BY NAME, drug_name
ORDER BY month_num
) - month_num AS group_num
OF got_month_num
)
SELECT DISTINCT name, drug_name
, MIN (MIN (min_fill_date))
(PARTITION BY NAME, drug_name)
AS first_fill_date
OF got_group_num
GROUP BY name, drug_name, group_num
HAVING COUNT (*) > = 3
ORDER BY name, drug_name
;
What are the results you want from these sample data? The query above produces:
NAME DRUG_NAME FIRST_FILL_
-------------------- ---------- -----------
John Doe DrugX may 1, 2010
As the FAQ forum:
Re: 2. How can I ask a question in the forums?
said, always give your version of Oracle. If you have Oracle version 12 (output in 2013, after the other thread), the MATCH_RECOGNIZE might be a better way to do it.
-
By comparing the Dates in a group of data (different lines)
I have a requirement where I have to compare dates in a dataset for each employee. The data looks like this:
WITH test_data AS
(SELECT the '1' AS pk, '5900' AS emp_id, '5' AS rec_id, to_date('01-JAN-2014') AS rec_date FROM dual
UNION ALL
SELECT '2', '5900', '5', to_date('01-FEB-2014') FROM dual
UNION ALL
SELECT '3', '5900', '5', to_date('01-MAR-2014') FROM dual
UNION ALL
SELECT '4', '5900', '5', to_date('01-JAN-2014') FROM dual
UNION ALL
SELECT '5', '5900', '6', to_date('06-JAN-2014') FROM dual
UNION ALL
SELECT '6', '5900', '6', NULL FROM dual
UNION ALL
SELECT '7', '5900', '6', to_date('01-JUL-2014') FROM dual
UNION ALL
SELECT '8', '5900', '7', to_date('29-JAN-2014') FROM dual
UNION ALL
SELECT '9', '5900', '7', to_date('29-SEP-2014') FROM dual
UNION ALL
SELECT '10', '5900', '7', to_date('01-OCT-2014') FROM dual
UNION ALL
SELECT '11', '8595', '5', to_date('01-SEP-2014') FROM dual
UNION ALL
SELECT '12', '8595', '6', to_date('05-SEP-2014') FROM dual
UNION ALL
SELECT '13', '8595', '7', to_date('30-SEP-2014') FROM dual
UNION ALL
SELECT '14', '8595', '7', NULL FROM dual
)
REC_ID column is composed of 3 different types of records, which must satisfy this requirement:
REC_ID 5 acts as point of departure, and REC_ID 6 must have a REC_DATE within 7 days of REC_ID 5 REC_ID 7 must have a REC_DATE within 30 days of REC_ID 6.
- If the requirements are any record in REC_ID 5 acts like zero day or the starting point;
- Any record in REC_ID 6 must be within 7 days of the date of REC_ID 5;
- Any record in REC_ID 7 must be within 30 days from 6 REC_ID.
My results:
Expected results - satisfactory records
EMP_ID
DATE_1
DATE_2
DATE_3
5900
1 January 14
6 January 14
29 January 14
8595
1 sep-14
5 sep-14
30 sep-14
I don't know how to compare dates in a dataset that are on different lines. I thought using self-joins, query using the window as rank (), factoring functions, but I'm stuck pretty quickly.
I appreciate all help. Thank you!
Aqua
Hello
AquaNX4 wrote:
WOW odie_63: it would be a blessing if I was... but unfortunately, I'm on 10 gr 2. That would have been great!
I'm stuck (mentally) to the fact that there is an amount without discernment of records in the base table for each type of REC_ID.
Some employees have 5 folders for REC_ID, 10 REC_ID 6 and 7 for REC_ID 7, which leaves me confused in how many self-joins I should do, or if it is at all possible. I did a lot of arithmetic of dates with the data on the same line and certain ranks () functions for data residing on different lines, but this 1 seems to confuse me...
I ran 1 self-join as below to see what it looks like and it confused me even more because I know the timestamp of the arithmetic in where clause still will not produce data as I want... I am now trying another way...
SELECT td2.rec_id,
TD2.emp_id,
TD2.rec_date
Of
test_data2 td2
LEFT JOIN test_data td1 ON td1.emp_id = td2.emp_id
It's a good start.
You want an inner join, however, not an outer join, not you? Outer join means "include td2 lines if they have data in the corresponding TD1". If I understand the question, you are only interested in cases where it is matching data.
Here's a way to do it:
WITH joined_data AS
(
SELECT d5.emp_id
d5.rec_date LIKE date_1
d6.rec_date AS date_2
d7.rec_date AS date_3
ROW_NUMBER () OVER (PARTITION BY d5.emp_id
ORDER BY d5.rec_date
d6.rec_date
d7.rec_date
) AS r_num
OF test_data d5
JOIN test_data d6 ON d6.emp_id = d5.emp_id
AND d6.rec_date > = d5.rec_date
AND d6.rec_date<= d5.rec_date="" +="">
JOIN test_data d7 ON d7.emp_id = d6.emp_id
AND d7.rec_date > = d6.rec_date
AND d7.rec_date<= d6.rec_date="" +="">
WHERE d5.rec_id = '5'
AND d6.rec_id = "6"
AND d7.rec_id = "7"
)
SELECT emp_id, date_1, date_2, date_3
OF joined_data
WHERE r_num = 1
;
The subquery joined_data find all combinations of rows that meet the criteria. We want to only 1 line by emp_id, so I used ROW_NUMBER assign unique r_nums (starting at 1) to all lines with the same emp_id and then, in the main query, rejected all but the 1st row.
Knapen had a good idea, but it won't work for all cases. There may be situations where the only combination of rows that meet the criteria does not use the MIN or MAX of dates of one (or several).
-
Rank of computed column is not work
Hello PL/SQL gurus and experts.
I use Oracle Database 11 g Enterprise Edition Release 11.2.0.1.0 - 64-bit Production version
I have table-drop table t3; create table t3(Pat_NM,Hospital,Test_Range,Total,LyTotal) as select 'Andy','Batra','> 10 Mph','20000','20000' from dual union all select 'Andy','Fortis','1-3 Mph','24500','20000' from dual union all select 'Andy','Max','5-10 Mph','10600','20000' from dual union all select 'Andy','Max','5-10 Mph','22500','20000' from dual union all select 'Andy','Aashiana','5-10 Mph','110600','20000' from dual union all select 'Andy','Amar','5-10 Mph','34800','20000' from dual union all select 'Andy','Max','5-10 Mph','600','20000' from dual union all select 'Andy','Columbia','< 1 Mph','27700','20000' from dual union all select 'Andy','Nimhans','< 1 Mph','50000','20000' from dual union all select 'Andy','Meenam','< 1 Mph','11000','20000' from dual union all select 'Andy','Meeran','5-10 Mph','24625','20000' from dual union all select 'Andy','Mnagamani','> 10 Mph','12000','20000' from dual union all select 'Andy','Murari','> 10 Mph','20600','20000' from dual union all select 'Andy','Triveni','5-10 Mph','16500','20000' from dual union all select 'Cindy','Batra','5-10 Mph','14700','20000' from dual union all select 'Cindy','Max','< 1 Mph','170000','20000' from dual union all select 'Cindy','Apollo Medical Centre','> 10 Mph','19000','20000' from dual union all select 'Cindy','MLal','1-3 Mph','22600','20000' from dual union all select 'Cindy','Columbia','< 1 Mph','28900','20000' from dual union all select 'Cindy','Asian','1-3 Mph','27900','20000' from dual union all select 'Cindy','Mahagun','< 1 Mph','28700','20000' from dual union all select 'Cindy','Manipal','< 1 Mph','29040','20000' from dual union all select 'Cindy','Prestige','< 1 Mph','12700','20000' from dual union all select 'Cindy','A.G.M.','< 1 Mph','97800','20000' from dual union all select 'Cindy','Shobha','< 1 Mph','700','20000' from dual union all select 'Cindy','Aashiana','5-10 Mph','23450','20000' from dual union all select 'Cindy','Amar','1-3 Mph','21325','20000' from dual union all select 'Cindy','Childs Trust','5-10 Mph','22775','20000' from dual union all select 'Cindy','Crescent ','< 1 Mph','20025','20000' from dual;
I have an Anlzd rank as this logic folloing calculation-
Ranking ((Cy Yr Tot *Factor-Prev Yr Tot) /Prev year Tot)and it does not correct-
Currently I use the following DML-
select Pat_NM, decode(grouping(Test_Range), 0, Test_Range, 'Total') "Test Range", Hospital, SUM (Total) "Total", SUM (AnlzdTotal) "Anlzd Total", SUM (LyTotal) "Last Yr Total", decode(grouping(Test_Range), 0, max(rank), null) Rank, decode(grouping(Test_Range), 0, max(lyrank), null) "Anlzd Rank" from (Select Pat_NM, Hospital, Test_Range, SUM (Total) Total, SUM (AnlzdTot) AnlzdTotal, SUM (LyTotal) LyTotal, DENSE_RANK () OVER (PARTITION BY test_range || pat_nm ORDER BY SUM (LyTotal) DESC) AS LYRANK, DENSE_RANK () OVER (PARTITION BY test_range || pat_nm ORDER BY SUM (Total) DESC) AS RANK, ROW_NUMBER () OVER (PARTITION BY test_range || pat_nm ORDER BY SUM (Total) DESC) AS rk from ( SELECT Pat_NM, Hospital, Test_Range, SUM (Total) Total, SUM (LyTotal) LyTotal, sum (Total) *1.85 AnlzdTot, (sum (Total * 1.85 - LyTotal)/nullif(sum(LyTotal),0)) AnlzdTotRank FROM t3 GROUP BY Pat_NM, Hospital, Test_Range ) group by Pat_NM, Hospital, Test_Range) group by grouping sets((Pat_NM, Test_Range,Hospital),()) order by Pat_NM,Test_Range, Rank;
Output data, I'm getting-
PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Andy 1-3 Mph Fortis 24500 45325 20000 1 1 Andy 5-10 Mph Aashiana 110600 204610 20000 1 2 Andy 5-10 Mph Amar 34800 64380 20000 2 2 Andy 5-10 Mph Max 33700 62345 60000 3 1 Andy 5-10 Mph Meeran 24625 45556.25 20000 4 2 Andy 5-10 Mph Triveni 16500 30525 20000 5 2 Andy < 1 Mph Nimhans 50000 92500 20000 1 1 Andy < 1 Mph Columbia 27700 51245 20000 2 1 Andy < 1 Mph Meenam 11000 20350 20000 3 1 Andy > 10 Mph Murari 20600 38110 20000 1 1 Andy > 10 Mph Batra 20000 37000 20000 2 1 PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Andy > 10 Mph Mnagamani 12000 22200 20000 3 1 Cindy 1-3 Mph Asian 27900 51615 20000 1 1 Cindy 1-3 Mph MLal 22600 41810 20000 2 1 Cindy 1-3 Mph Amar 21325 39451.25 20000 3 1 Cindy 5-10 Mph Aashiana 23450 43382.5 20000 1 1 Cindy 5-10 Mph Childs Trust 22775 42133.75 20000 2 1 Cindy 5-10 Mph Batra 14700 27195 20000 3 1 Cindy < 1 Mph Max 170000 314500 20000 1 1 Cindy < 1 Mph A.G.M. 97800 180930 20000 2 1 Cindy < 1 Mph Manipal 29040 53724 20000 3 1 Cindy < 1 Mph Columbia 28900 53465 20000 4 1 PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Cindy < 1 Mph Mahagun 28700 53095 20000 5 1 Cindy < 1 Mph Crescent 20025 37046.25 20000 6 1 Cindy < 1 Mph Prestige 12700 23495 20000 7 1 Cindy < 1 Mph Shobha 700 1295 20000 8 1 Cindy > 10 Mph Apollo Medical Centre 19000 35150 20000 1 1 Total 925640 1712434 580000
I want to - data
PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Andy 1-3 Mph Fortis 24500 45325 20000 1 1 Andy 5-10 Mph Aashiana 110600 204610 20000 1 1 Andy 5-10 Mph Amar 34800 64380 20000 2 2 Andy 5-10 Mph Max 33700 62345 60000 3 5 Andy 5-10 Mph Meeran 24625 45556.25 20000 4 3 Andy 5-10 Mph Triveni 16500 30525 20000 5 4 Andy < 1 Mph Nimhans 50000 92500 20000 1 1 Andy < 1 Mph Columbia 27700 51245 20000 2 2 Andy < 1 Mph Meenam 11000 20350 20000 3 3 Andy > 10 Mph Murari 20600 38110 20000 1 1 Andy > 10 Mph Batra 20000 37000 20000 2 2 PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Andy > 10 Mph Mnagamani 12000 22200 20000 3 3 Cindy 1-3 Mph Asian 27900 51615 20000 1 1 Cindy 1-3 Mph MLal 22600 41810 20000 2 2 Cindy 1-3 Mph Amar 21325 39451.25 20000 3 3 Cindy 5-10 Mph Aashiana 23450 43382.5 20000 1 1 Cindy 5-10 Mph Childs Trust 22775 42133.75 20000 2 2 Cindy 5-10 Mph Batra 14700 27195 20000 3 3 Cindy < 1 Mph Max 170000 314500 20000 1 1 Cindy < 1 Mph A.G.M. 97800 180930 20000 2 2 Cindy < 1 Mph Manipal 29040 53724 20000 3 3 Cindy < 1 Mph Columbia 28900 53465 20000 4 4 PAT_N Test Ran HOSPITAL Total Anlzd Total Last Yr Total RANK Anlzd Rank ----- -------- --------------------- ---------- ----------- ------------- ---------- ---------- Cindy < 1 Mph Mahagun 28700 53095 20000 5 5 Cindy < 1 Mph Crescent 20025 37046.25 20000 6 6 Cindy < 1 Mph Prestige 12700 23495 20000 7 7 Cindy < 1 Mph Shobha 700 1295 20000 8 8 Cindy > 10 Mph Apollo Medical Centre 19000 35150 20000 1 9 Total 925640 1712434 580000
Thanks in advance for all your efforts, time and valuable feedback.
Thanks for the comments FrankKulash, I checked that it was due to the "last nulls' to be added in the following lines.
DENSE_RANK)
COURSES (PARTITION BY test_range | pat_nm ORDER OF SUM (LyTotal) / / DESC nulls last)
AS LYRANK,
DENSE_RANK)
COURSES (PARTITION BY test_range | pat_nm ORDER OF SUM (Total) / / DESC nulls last)
IN THE RANK,.
DENSE_RANK)
COURSES (PARTITION BY test_range | pat_nm ORDER OF SUM (AnlzdTotRank) / / DESC nulls last)
AS ANLZDRANK,
ROW_NUMBER)
COURSES (PARTITION BY test_range | pat_nm ORDER OF SUM (Total) / / DESC)
AS rk
-
How to calculate cumulative data
Hello
I need output like this.
Percent frequency percent Cumulative Cumulative frequency
4468 0.91 0.91 4468
21092 4.31 25560 5.23
57818 11.82 83378 17.05
I use Oracle 9i.
My data of output like that and I need to write the query for 3 columns (frequency, percent, the cumulative frequency and cumulative percentage)
1: the formula for the frequency column data is the sum of (dd + cc + mc_cc_mc).
1: the formula for the percentage column data is (frequency/amount of cumulative frequency) * 100
2: is the formula for the cumulative frequency column data (data of the cumulative frequency column of)
3: is the formula for the cumulative percentage column data (data for the cumulative percentage column of)
What should be the analytical function and how to write the query. Please find the sample of data and table script.
CREATE TABLE all_lony)
CampNO varchar2 (20).
DD INTEGER,
CC INTEGER,
MC, INTEGER,
cc_mc INTEGER
);
insert into all_lony (campno, dd, cc, mc, cc_mc)
values (36,156,1320,445,2547);
insert into all_lony (campno, dd, cc, mc, cc_mc)
values (40,233,19711,263,885);
=============
Please find my query below
SELECT campno
|| ','
|| DM
|| ','
|| CC
|| ','
|| MC
|| ','
|| cc_mc
|| ','
|| frequency
|| ','
|| by
||','
|| cumulative_fr
||','
|| AMOUNT (per) OVER (ORDER BY by LINES UNBOUNDED PRECEDING)
FROM (SELECT campno q3.campno, q3.dm, q3.cc, q3.mc, q3.cc_mc,
Q3. Frequency, q3.cumulative_fr,
(q3. Frequency / SUM (q3.cumulative_fr)) * 100
(Q2.campno SELECT campno, SUM (q2.dm) dm, SUM (q2.cc) cc,)
SUM (q2.mc) mc, SUM (q2.cc_mc) cc_mc,
(SUM (NVL (q2.dm, 0)))
+ NVL (q2.cc, 0)
+ NVL (q2.mc, 0)
+ NVL (q2.cc_mc, 0)
)
) the frequency,.
SUM (SUM (NVL (q2.dm, 0)))
+ NVL (q2.cc, 0)
+ NVL (q2.mc, 0)
+ NVL (q2.cc_mc, 0)
)
) ON (ORDER OF the SOMME (NVL (q2.dm, 0)))
+ NVL (q2.cc, 0)
+ NVL (q2.mc, 0)
+ NVL (q2.cc_mc, 0)
() THE UNBOUNDED PRECEDING LINES)
cumulative_fr
of all_lony
Q2 Q1)
GROUP BY q3.campno) q3
GROUP BY campno, dm, cc, mc, cc_mc, frequency, cumulative_fr)
Just check the query and let me knowHello
Everything is given. Each column formula is given...thriugh this we can get all the required result. The query is not working properly thats the issue and thats why i posted this whole senario.I don't think that everything is given. You gave:
select * from all_lony CAMPNO DD CC MC CC_MC 36 156 1320 445 2547 40 233 19711 263 885And you want to:
Frequency Percent Cumulative Frequency Cumulative percent 4468 0.91 4468 0.91 21092 4.31 25560 5.23 57818 11.82 83378 17.05First of all, you want 3 rows where we start with 2. I don't see anyway to generate the 3rd rank on 2 data.
With the following simple query, I get the frequency and the Cumulative_freqency.select campno ,dd + cc + mc + cc_mc Frequency ,sum(dd + cc + mc + cc_mc ) over (order by campno) Cumulative_freqency from all_lony CAMPNO FREQUENCY CUMULATIVE_FREQENCY -------------------- --------- ------------------- 36 4468 4468 40 21092 25560As you can see that your formula for the frequency is not give the result that you want.
1: the formula for the frequency column data is the sum of (dd + cc + mc_cc_mc).
This should be:
1: the formula for the frequency column data is dd + cc + mc_cc_mc.Now the percentage formula
1: the formula for the percentage column data is (frequency/amount of cumulative frequency) * 100I think you mean
1: the formula for the percentage column data is (frequency / cumulative frequency) * 100But this does not 0.91 or 4.31 as in your result set.
Then please explain in a simple furmula with the sample values you have given the way in which we can calculate the percentage column.
The cumulative percentage column follows out of the percentage column.Then explain how to get the 3rd rank.
Kind regards
Peter
-
DB: 11.1.0.7
I have a table and there column date without time information. I would like to recover missing consecutive dates over 2 days.
For example.
Select * from xyz
place date
1 05/10/2011
1 04/10/2011
1 01/10/2011
1 30/09/2011
1 27/09/2011
2 04/10/2011
2 01/10/2011
2 30/09/2011
3 04/10/2011
3 01/10/2011
3 30/09/2011
3 29/09/2011
3 26/09/2011
3 25/09/2011
Looking out be as below.
Place missing Date
1 04/10/2011
1 30/09/2011
2 04/10/2011
3 04/10/2011
3 29/09/2011
Any suggestion?This gives a shot:
SELECT location , dt FROM ( SELECT location , dt , dt - LAG(dt) OVER (PARTITION BY location ORDER BY dt) AS diff FROM xyz ) WHERE diff > 2 ORDER BY 1, 2 DESC -
Hello
I am new to the migration.
Can anyone please explain terms like kick off, build, mini - data warehouse etc.
Any help is greately appreciated.
Thank youOn the topic of migration of the system database and/or demand on storage, datamarts, OLAP,...?
I do not work in this area, so I didn't keep track of the good sites for this topic, but Oracle has manuals on storage and Oracle developed for stores which you can do refers to.
Definitions of concepts for warehouse, Datamark, etc...
http://download.Oracle.com/docs/CD/B19306_01/server.102/b14220/bus_intl.htm#sthref2460Guide to data warehouse
http://OTN.Oracle.com/pls/db102/ranked?Word=data+warehouse+guide&PartNo=b14223Tim Gorman has a few items/scripts that may be of interest
http://www.EvDBT.comHTH - Mark D Powell.
Maybe you are looking for
-
iCloud Photo - need more disk space on my MacBook
This is my first post, so I sorry if it's really obvious, but I have some don't search online but cannot find an answer to my problem. I hope you guys can help. Ok. Here's my problem. My Macbook Pro has a 250 GB hard drive and is now complete. I noti
-
Choose scanner or scanner officejet Sprout
Sprout scan KO from win10 update. OfficeJet 6500 has more unusable scanner. Is it possible to choose?
-
Printing from Android at HP6520
I loaded HP eprint app on Samsung galaxy 10.1 and printed on a printer to my son's House. When I try to print on my printer, it recognizes the printer and its IP address, but the 'print' button is faded and unresponsive. The printer works wirelessly
-
Lower the resolution of the screen
Hello! Got a game for my children and I need to lower the resolution to 640 x 480. My slider in display settings only goes down to 800 x 600. Is their a way around it. Game will let me play otherwise. Thank you
-
Assistant of vision > Labview ploblem of EMERGENCY!
I'm on the senior project for my studies at the Bachelor's degree. and my project is to create a direction for FANUC robot to take something using a CCD camera. My problem is when I transfer my WILL to the labview module using create function Labview