Reg: Generating range values
Hi Experts,
I'm struggling to resolve this issue for the moment quite sometimes, but not luck...
Sample data :
with t as)
Select 1 id, 'D1005-D1009"dual UNION ALL val
Select 2 id, val "K3630-K3633" of the double
)
Expected o/p :
1 D1005
1 D1006
1 D1007
D1008 1
1 D1009
2 K3630
2 K3631
2 K3632
2 K3633
My test :
with t as)
-Select 1 id, 'D1005-D1009"dual UNION ALL val
Select 2 id, val "K3630-K3633" of the double
)
Select
ID,
-substr(val,1,1) prefix,
-pos instr(val,'-'),
-ltrim (substr (val, 1, instr(val,'-')-1), substr (val, 1, 1)) s_str,.
-ltrim (substr (val, instr(val,'-') + 1), substr (val, 1, 1)) e_str,.
substr (Val, 1, 1) | (ltrim (substr (val, 1, instr(val,'-')-1), substr (val, 1, 1)) + level - 1) vals
t
connect by level < = (ltrim (substr (val, instr(val,'-') + 1), substr (val, 1, 1))-ltrim (substr (val, 1, instr(val,'-')-1), substr (val, 1, 1))) + 1
;
| 2 | K3630 |
| 2 | K3631 |
| 2 | K3632 |
| 2 | K3633 |
I guess something like NOCYCLE clause can be useful... search...
Pointers?
Thank you
-Nordine
(on Oracle 11.2.0.4.0)
This should be faster than the approach CONNECT-larger sets of data:
select /*+ no_xml_query_rewrite */
t.id
, substr(t.val, 1, 1) || to_char(x.val, 'fm0999') as val
from test_range t
, xmltable(
'for $i in xs:integer(substring(substring-before($range, "-"), 2))
to xs:integer(substring(substring-after($range, "-"), 2))
return $i'
passing t.val as "range"
columns val number path '.'
) x ;
create table test_range (id integer, val varchar2(12)); insert into test_range select level, chr(64+level)||'0000-'||chr(64+level)||'9999' from dual connect by level <= 26;
SQL> WITH got_nums AS
2 (
3 SELECT id
4 , SUBSTR (val, 1, 1) AS prefix
5 , TO_NUMBER ( SUBSTR ( val
6 , 2
7 , INSTR (val, '-') -2
8 )
9 ) AS low_num
10 , TO_NUMBER ( SUBSTR ( val
11 , INSTR (val, '-') + 2
12 )
13 ) AS high_num
14 FROM test_range t
15 )
16 SELECT id
17 , prefix || TO_CHAR (low_num + LEVEL - 1, 'fm0999') AS vals
18 FROM got_nums
19 CONNECT BY LEVEL <= high_num + 1 - low_num
20 AND PRIOR id = id
21 AND PRIOR SYS_GUID () IS NOT NULL
22 ;
260000 rows selected.
Elapsed: 00:00:11.71
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets
0 physical reads
0 redo size
6171324 bytes sent via SQL*Net to client
191215 bytes received via SQL*Net from client
17335 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
260000 rows processed
SQL>
SQL> select /*+ no_xml_query_rewrite */
2 t.id
3 , substr(t.val, 1, 1) || to_char(x.val, 'fm0999') as val
4 from test_range t
5 , xmltable(
6 'for $i in xs:integer(substring(substring-before($range, "-"), 2))
7 to xs:integer(substring(substring-after($range, "-"), 2))
8 return $i'
9 passing t.val as "range"
10 columns val number path '.'
11 ) x ;
260000 rows selected.
Elapsed: 00:00:02.99
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
32 consistent gets
0 physical reads
0 redo size
6171323 bytes sent via SQL*Net to client
191215 bytes received via SQL*Net from client
17335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
260000 rows processed
Tags: Database
Similar Questions
-
Reg: Generate random integers:
Hi Experts,
Sorry to resurrect my old thread -
As Frank Kulash suggested (his last message to above thread):
As you have probably noticed, the results of discrimination 1 and 9. That's because the numbers were being rounded up or down to produce integers from 1 through 9 numbers, but none were being rounded to produce 1 and no figures have been rounded down to produce 9. A good way to use the TOWER would be
ROUND (dbms_random.value (.5, 9.5))But surprisingly, I get even the values 1 and 9 to the query below:
SELECT ROUND (Dbms_Random.Value (1.9))
OF the double
CONNECT BY LEVEL < = 100;
Can any body please confirm the behavior?
-Nordine
(Oracle Database 11 g Enterprise Edition Release 11.2.0.3.0 - 64 bit Production)
In order to avoid discrimination against 1 and 9 as values.
If you have dbms_random.value (1.9) it can only generate 1.0000 to 8.9999 values.
The tour will convert 1.00000 - 1.49999 1 and will convert 1, 5 - 2.49999 2 and so on
until the conversion of 8.5 to 8.9999 to 9.
As you can easily see, there are more likely to get one than a one and more likely to get
a 8 to 9.
If you use 0.5 to 9.5 in your random value that stop the discrimination against 1 and 9, because now
you will get 0.5 to 1.49999 is converted to 1, etc.. The same range as 1, 5 - 2.49999 etc.
-
Adding a Partition of lower range value
Hi Experts,
If you have created a table like:
CREATE TABLE RANGE_PART_T
(IDENTIFICATION NUMBER,
EMP_NAME VARCHAR2 (20).
USE VARCHAR2 (20).
HIREDATE DATE
)
ALLOW THE MOVEMENT OF THE LINE
partition by range (ID)
(
partition P1 values less than (40),
partition P2 values less than (80),
partition P3 values less than (160),
partition P4 values less than (240)
);
I miss two partitions:
Partition with value less than (120) and partition with value less than (200).
How is it possible to add the partition with the lower range without a drop/recreate the table.
SQL > ALTER TABLE RANGE_PART_T
2 ADD PARTITION P5 VALUES LESS THAN (120);
ADD PARTITION P5 VALUES LESS THAN (120)
*
ERROR on line 2:
ORA-14074: partition bound must gather greater than that of the last partition
Use following statement more your partition table. for example
ALTER table RANGE_PART_T split partition P3 (120) (P6 partition, partition P3);
-
Impossible to get Min, Max and median of the values in the date range values
Hello
I had a requirement as to show the data of each charge group of wise men as '< 100' ' 100-199 "" 200-299 "" 300-399 "400-499, 500-599 600-699 700-799 800-899 900-999 > = 1000 '"»
With the query be able to get the count between the beach and the total below. But impossible to get the Min and Max values for this range. For example if the County < 100 is 3 then in these 3, the lowest value is need to display in the min. Idem for Max column also.
In the light of the median value on these values.
Thanks in advance.
Requirement is as below:
State < 100 100-199, 200-299 300-399 400-499, 500-599 600-699 700-799 800-899 900-999 > = 1000 Min Total median Max
AK 1 2 0 4 1 4 4 35 35 4 1 $25 $85 850 $1,200
AL 0 0 2 27 10 17 35 2 2 35 0 $103 100-$1 500 750
* "QUERY ' * '"
WITH t AS
(SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 67 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 78 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 34 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 4 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 15 VALUE FROM DUAL
UNION ALL
SELECT "AZ" State, FROM DUAL VALUE 6
UNION ALL
SELECT "AZ" State, 123 FROM DUAL VALUE
UNION ALL
SELECT "AZ" State, 123 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 120 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 456 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 11 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 24 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 34 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 87 DUAL FROM VALUE
UNION ALL
SELECT 'MY' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 234 DUAL FROM VALUE
UNION ALL
SELECT 'MY' State, 789 FROM DUAL VALUE
UNION ALL
SELECT "HD" State, VALUE FROM DUAL 54321).
-End of test data
AS T1
(SELECT State,
NVL (COUNT (DECODE (VALUE, 0, 0)), 0) '< 100 ',.
NVL (COUNT (DECODE (VALUE, 1, 1)), 0) '100-199.
NVL (COUNT (DECODE (VALUE, 2, 2)), 0) '200-299.
NVL (COUNT (DECODE (VALUE, 3, 3)), 0) '300-399.
NVL (COUNT (DECODE (VALUE, 4, 4)), 0) '400-499.
NVL (COUNT (DECODE (VALUE, 5, 5)), 0) '500-599,'
NVL (COUNT (DECODE (VALUE, 6, 6)), 0) '600-699.
NVL (COUNT (DECODE (VALUE, 7, 7)), 0) '700-799.
NVL (COUNT (DECODE (VALUE, 8, 8)), 0) '800-899.
NVL (COUNT (DECODE (VALUE, 9, 9)), 0) '900-999. "
NVL (COUNT (DECODE (VALUE, 10, 10)), 0) ' > = 1000.
(SELECT STATE,
CASE
WHAT VALUE < 100 THEN 0
WHAT A VALUE BETWEEN 100 AND 199 THEN 1
WHAT VALUE BETWEEN 200 AND 299, THEN 2
WHAT VALUE BETWEEN 300 AND 399 THEN 3
WHAT VALUE BETWEEN 400 AND 499 THEN 4
WHAT VALUE BETWEEN 500 AND 599 5 THEN
WHAT VALUE BETWEEN 600 AND 699 6 THEN
WHAT VALUE BETWEEN 700 AND 799 THEN 7
WHAT VALUE BETWEEN 800 AND 899 8 THEN
WHAT VALUE FROM 900 TO 999 9 THEN
WHAT VALUE > = 10 THEN 1000
END
VALUE
T)
GROUP BY State)
SELECTION STATE,
"< 100."
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
"> = 1000."
'< 100 '.
+ "100-199.
+ "200-299.
+ '300-399.
+ '400-499.
+ "500-599.
+ '600-699.
+ "700-799.
+ "800-899.
+ '900-999 ".
+ ' > = 1000.
in total,.
less ("< 100",)
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
("> = 1000 ') min_val,.
largest ("< 100",)
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
("> = 1000 ') max_val
FROM t1
/Why not keep it simple?
WITH t AS (SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 67 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 23 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 78 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 34 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 4 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 15 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 6 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 123 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 123 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 23 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 120 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 456 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 11 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 24 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 34 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 87 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 23 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 234 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 789 VALUE FROM DUAL UNION ALL SELECT 'MH' state, 54321 VALUE FROM DUAL) SELECT state , NVL( COUNT( case when VALUE < 100 then 0 end ), 0 ) "<100" , NVL( COUNT( case when VALUE between 100 and 199 then 0 end ), 0 ) "100-199" , NVL( COUNT( case when VALUE between 200 and 299 then 0 end ), 0 ) "200-299" , NVL( COUNT( case when VALUE between 300 and 399 then 0 end ), 0 ) "300-399" , NVL( COUNT( case when VALUE between 400 and 499 then 0 end ), 0 ) "400-499" , NVL( COUNT( case when VALUE between 500 and 599 then 0 end ), 0 ) "500-599" , NVL( COUNT( case when VALUE between 600 and 699 then 0 end ), 0 ) "600-699" , NVL( COUNT( case when VALUE between 700 and 799 then 0 end ), 0 ) "700-799" , NVL( COUNT( case when VALUE between 800 and 899 then 0 end ), 0 ) "800-899" , NVL( COUNT( case when VALUE between 900 and 999 then 0 end ), 0 ) "900-999" , NVL( COUNT( case when VALUE >= 1000 then 0 end ), 0 ) ">=100" , count( value ) "total" , min( VALUE ) "min" , max( VALUE ) "max" , avg( VALUE ) "avg" , median( value ) "median" from t group by state -
Package to generate random values, based on a model
I need to generate thousands of test strings based on a template (LLNNNNLL, where L stands for letter and N represents the numbers).
I was able to create, on a table, any useful combination: the next step is to get that 'good' a few tickets.
My problem is that using the following syntax I get tickets with "close to" number... just because I created using a sequence
I mean: AB1001CD, AC1003CB, BB1002AD...SELECT TICKET_CODE FROM TICKET_WELL SAMPLE (1) WHERE OWNER = 'OWNER_NAME' AND rownum < 10;
while I need to get these tickets: AB1001CD, AC4667CD, SD8592GD etc...
First question: is there a like DBMS_RANDOM package that accepts as input a boss so I can simply replace MY package to create the TICKET_WELL table?
Second: Is there another way (right) to select a table trying to get the lines in a random order?
Third: If both answers are not... is there a way to mix the rows of a table to another?
Any suggestions are welcome.
Thank you
MarcoHere's a function I hit upwards to generate a randon number, based on an input mask.
create or replace function random_string( p_mask in varchar2) return varchar2 as v_random_number integer; v_random_letter varchar2(1); v_mask varchar2(20) := p_mask; v_character varchar2(1); v_random_string varchar2(20); begin for i in 1 .. length(v_mask) loop if substr(v_mask,i,1) = 'L' Then v_random_number := dbms_random.value(1,26); v_character := chr(64+v_random_number); elsif substr(v_mask,i,1) = 'N' then v_random_number := dbms_random.value(0,9); v_character := v_random_number; end if; v_random_string := v_random_string||v_character; end loop; return v_random_string; end;To select lines in a random order, you need to store the random number with a column, for example rowno and create an index on rowno.
create table random_rows (rowno number, random_string varchar2(20) );then to get a random line, you can use
declare v_rowno integer; -- must be integer begin v_rowno := dbms_random.value(1, v_rows_in_table); select random_string into v_random_string from random_rows where rowno := v_rowno; end;You can also replace the random line of the next generated random_string.
The only thing is that you can not guarantee that the random_string is unique,
If you need a unique index on the column of random_string, and he tries to insert a duplicate, you should try to insert another random number; -
How to generate a value of 0 if the table does not value contain?
Hello
I have a nice select gives me these results:
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:01 36.6 01/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:02 63.4 02/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:03 73.2 03/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:04 78.6 04/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:05 98.8 05/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:06 2008-06-30.4
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:07 23.8 07/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:08 70.8 08/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:09 14 2008-09
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:10 60.4 10/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:11 46 11/2008
You see, the month 12 is missing, because no data exists in the table. OK, that's normal.
But I want to display the result 0 even if nothing in the table for the month 12. The result would be:
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:01 36.6 01/2008
etc...
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:11 46 11/2008
f? p =: 2::GET_DETAIL_REPORT:NO:P2_VALUE:12 0 2008-11
I know that I have to generate a list of values for each month and join them.
Could you please help me this?select add_months(to_date('01'||:P2_DATE_DEBUT, 'mm/yyyy'), level-1) dt from dual connect by level <= 12
It's nice select I already have.
Kind regardsSELECT 'f?p=&APP_ID.:2:&SESSION.:GET_DETAIL_REPORT:NO::P2_VALUE:' || TO_CHAR(TRUNC(date1, 'MM'), 'MM') LINK, To_CHAR(TRUNC(DATE1, 'MM'), 'MM/YYYY') valeur, sum(valeur) "Cumul" FROM PL_MF_JOUR WHERE cle = :P2_DEPT AND DATE1 BETWEEN to_date('01/01' || :P2_DATE_DEBUT || ' 00:00:00', 'DD/MM/YYYY HH24:MI:SS') AND to_date('01/01' || :P2_DATE_DEBUT || ' 23:59:59', 'DD/MM/YYYY HH24:MI:SS') +364 GROUP BY TRUNC(DATE1, 'MM') ORDER BY TRUNC(DATE1, 'MM')
Christian
PS: your help is very appreciated every time, thank you.You need to generate your calendar of 12 months and then left outer join with it.
Something like:
WITH dts as (select to_date('01/'to_char(rownum,'fm99')||'/'||:P2_DATE_DEBUT,'DD/MM/YYYY') as dt from dual connect by rownum <= 12) SELECT 'f?p=&APP_ID.:2:&SESSION.:GET_DETAIL_REPORT:NO::P2_VALUE:' || TO_CHAR(dt, 'MM') LINK, TO_CHAR(dt, 'MM/YYYY') valeur, sum(valeur) "Cumul" FROM dts LEFT OUTER JOIN PL_MF_JOUR ON (dt = TRUNC(DATE1,'MM') AND cle = :P2_DEPT AND DATE1 BETWEEN to_date('01/01' || :P2_DATE_DEBUT || ' 00:00:00', 'DD/MM/YYYY HH24:MI:SS') AND to_date('01/01' || :P2_DATE_DEBUT || ' 23:59:59', 'DD/MM/YYYY HH24:MI:SS')+364 ) GROUP BY dt ORDER BY dtNB. Untested (obviously)
-
Reg: Retrieve the value by default-
Hi Experts,
Need help with writing a query.
Table "Tab_2" a column 'c3' which checks its value from the values in the column "c1" "tab_1" and therefore from value of the column "c2".
But if a value of c3 is not present in the column tab_1 "c1", "c2" value "DX" should by default.
Please find below the scripts Create & Insert:
Here's the query where I'm stuck:create table tab_1( c1 varchar2(200Char), c2 varchar2(200Char) ); create table tab_2( c3 varchar2(200Char), c4 varchar2(200Char) ); insert into tab_1 values('104,113,146,165','1x'); insert into tab_1 values('204,213,246,265','2x'); insert into tab_1 values('304,313,346,365','3x'); insert into tab_1 values('default','dx'); commit; insert into tab_2 values('146',null); insert into tab_2 values('265',null); insert into tab_2 values('333',null); commit;
Please let me know if any clarification is needed.SQL> with x1 as 2 ( 3 select 4 REGEXP_SUBSTR(c1,'[^,]+',1,level) id1, 5 c2 6 from tab_1 7 connect by level <= length(translate(c1,'~0123456789','~'))+1 8 and prior c1 = c1 9 and prior sys_guid() is not null 10 and c1 != 'default' 11 ) 12 select 13 id1, c2, c3 14 from x1 RIGHT OUTER JOIN tab_2 15 on (x1.id1 = tab_2.c3); ID1 C2 C3 ---------- ---------- ---------- 146 1x 146 265 2x 265 333
-NordineAnother way... without the generation of line
SQL> select t2.c3,nvl(t1.c2,tx.c2) c2 2 from tab_2 t2 3 left outer join 4 tab_1 t1 5 on (','||t1.c1||',' like '%,'||t2.c3||',%') 6 join 7 (select c2 from tab_1 where c1 = 'default') tx 8 on(1=1); C3 C2 ---------- ---------- 146 1x 265 2x 333 dx -
generate the value of the column according to the conditions
statement to generate the selection inputsBANNER Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production PL/SQL Release 11.2.0.3.0 - Production CORE 11.2.0.3.0 Production TNS for HPUX: Version 11.2.0.3.0 - Production NLSRTL Version 11.2.0.3.0 - Production
entryWITH t AS ( SELECT 1 job_request_id, 1 original_job_request_id, mod(level,3) +1 sequence_cd, CHR (LEVEL + 100) value_txt, NULL new_sequence_cd FROM DUAL CONNECT BY LEVEL < 6), t1 AS ( SELECT 2 job_request_id, 1 original_job_request_id, mod(LEVEL,2) + 1 sequence_cd, CHR (LEVEL + 110) value_txt, NULL FROM DUAL CONNECT BY LEVEL < 10), t2 AS ( SELECT 3 job_request_id, 3 original_job_request_id, mod(LEVEL,3) + 7 sequence_cd, CHR (LEVEL + 95) value_txt, NULL FROM DUAL CONNECT BY LEVEL < 9), t3 AS ( SELECT 4 job_request_id, 3 original_job_request_id, mod(LEVEL,2) + 1 sequence_cd, CHR (LEVEL + 95) value_txt, NULL FROM DUAL CONNECT BY LEVEL < 7), t4 AS ( SELECT 7 job_request_id, 3 original_job_request_id, mod(LEVEL,2) + 1 sequence_cd, CHR (LEVEL + 92) value_txt, NULL FROM DUAL CONNECT BY LEVEL < 4), mytable AS (SELECT * FROM t UNION ALL SELECT * FROM t1 UNION ALL SELECT * FROM t2 UNION ALL SELECT * FROM t3 UNION ALL SELECT * FROM t4) SELECT * FROM mytable order by job_request_id, original_job_request_id, sequence_cd;
expected resultsJOB_REQUEST_ID ORIGINAL_JOB_REQUEST_ID SEQUENCE_CD VALUE_TXT NEW_SEQUENCE_CD 1 1 1 g 1 1 2 h 1 1 2 e 1 1 3 i 1 1 3 f 2 1 1 v 2 1 1 p 2 1 1 r 2 1 1 t 2 1 2 u 2 1 2 q 2 1 2 o 2 1 2 s 2 1 2 w 3 3 7 b 3 3 7 e 3 3 8 ` 3 3 8 f 3 3 8 c 3 3 9 d 3 3 9 a 3 3 9 g 4 3 1 e 4 3 1 c 4 3 1 a 4 3 2 b 4 3 2 ` 4 3 2 d 7 3 1 ^ 7 3 2 ] 7 3 2 _
my attempt to explain.JOB_REQUEST_ID ORIGINAL_JOB_REQUEST_ID SEQUENCE_CD VALUE_TXT NEW_SEQUENCE_CD 1 1 1 g 1 1 1 2 h 2 1 1 2 e 2 1 1 3 i 3 1 1 3 f 3 2 1 1 v 4 2 1 1 p 4 2 1 1 r 4 2 1 1 t 4 2 1 2 u 5 2 1 2 q 5 2 1 2 o 5 2 1 2 s 5 2 1 2 w 5 3 3 7 b 7 3 3 7 e 7 3 3 8 ` 8 3 3 8 f 8 3 3 8 c 8 3 3 9 d 9 3 3 9 a 9 3 3 9 g 9 4 3 1 e 10 4 3 1 c 10 4 3 1 a 10 4 3 2 b 11 4 3 2 ` 11 4 3 2 d 11 7 3 1 ^ 12 7 3 2 ] 13 7 3 2 _ 13
If the job request id = id of the new cd of sequence = sequence cd original job application
When the employment application IDS are higher than the original increment the new cd of sequence with respect to the maximum of the original work request id sequence cd.
I hope that the expected results will clarify.Hello
It looks like you want DENSE_RANK, except that you want to ignore the numbers (for example, 6 in this example) when necessary so that new_sequence_cd > = sequence_cd.
With the help of analytical functions:
WITH got_drank AS ( SELECT m.* , DENSE_RANK () OVER ( ORDER BY job_request_id , original_job_request_id , sequence_cd ) AS drank FROM mytable m ) SELECT job_request_id , original_job_request_id , sequence_cd , value_txt , drank + MAX ( sequence_cd - drank ) OVER ( ORDER BY job_request_id , original_job_request_id , sequence_cd ) AS new_sequence_cd FROM got_drank ORDER BY job_request_id , original_job_request_id , sequence_cd ;You can also use the MODEL.
If you have a new_sequence_cd column in a table, one you want to fill, use the query in a MERGE statement above.
-
Homepage which generates field values
Good afternoon
I have a form that, whereby I have 1 field that updates several fields.For example an employee name:
I want to have 1 field by which the employee meets sound. He then filled other fields with the same string value.
The thing is I want to control where the user can fill in his name and lock the other fields that copy this value.
Basically, I'm having 1 page where an employee updates its information. Based on this input, it automatically fills the 10 pages of boxes that need this information. The thing is, I want those 10 pages of boxes must be blocked so I can direct the user to a central page where it reads the instructions.I know I can duplicate fields where updating will be updated all: I don't want that. I want a box that updates all: If the user tries to bypass the home page, it may not be updated.
Create a second field (name it differently your entry field, IE "EmployeeNameCalc"), set it to 'Read only' and that's the value calculation custom calculation script:
Event.Value = this.getField("EmployeeNameEntryField").value
(Change the name to match the name of your input field).
Duplicate this field wherever you want to specify this value, but does not allow the user to update.
-
How to generate a value of variable "fast"? Only possible with dbms_outpu
Suppose I have defined a variable in a script from SQLplus and want it output in a quick statement.
How can I do?
The following does NOT work:
accept myvar prompt "enter value ="
prompt & myvar
Here, I am invited again a second time.
What can I do else?
Is dbms_output.put_line (...) the only way?
PeterSQL> accept myvar prompt 'Enter value=' Enter value=222 SQL> prompt you entered &myvar you entered 222Max
http://oracleitalia.WordPress.com -
Query generates duplicate values in successive lines. I can null out them?
I have had very good success (thanks to Andy) to obtain detailed responses to my questions posted, and I wonder if there is a way in a region report join query that produces lines with duplicate values, I cannot suppress (replace) printing of duplicate values in successive lines. In the event that I managed to turn the question into a mess unintelligible (one of my specialities), let me give an example:
We try institutions undergraduate that an applicant has participated in the list and display information on release dates, gpa and major (s) / according to decision-making. The problem is that there may be several major (s) / minor (s) for a given undergraduate institution, so the following is produced by the query:
Knox College hard 01/02 01/06 4,00 knitting
Knox College hard 01/02 01/06 4,00 cloth repair
Advanced University 02/06 01/08 3.75 Clothing Design
Really advanced U 02/08 01/09 4,00 sportswear
Really advanced U 02/08 01/09 4,00 basketball burlap
I want it to look like this:
Knox College hard 01/02 01/06 4,00 knitting
Tissue repair
Advanced University 02/06 01/08 3.75 Clothing Design
Really advanced U 02/08 01/09 4,00 sportswear
Burlap tennis shoe
* (Edit) Please note that the repair of fabric and lines tennis shoe repair should be positioned properly in a table, but unfortunately had space here for a reason suppresed any. *
Under the tuteage of Andy, I would say the answer is probably javascript one loop in the DOM, you are looking for the innerHTML of specific TDs in the table, but I want to confirm that, or Apex provides it a box I can check which will produce the same results? Thanks to the guy to advance and sorry for all the questions. We were charged to use Apex for our next project and learn it using it, as the training budget is non-existent this year. I love ;) unfunded mandates
Phil
Published by: Phil McDermott on August 13, 2009 09:34Hi Phil,
JavaScript is useful, because the feature break column in the report attributes (which would be my first choice if poss).
If you need to go beyond 3 columns, I would say something in the SQL statement itself. This means that the sort would probably have to be controlled, but it is doable.
This is a pretty old thread on the subject: Re: grouping reports (non-interactive) -with an example here: [http://htmldb.oracle.com/pls/otn/f?p=33642:112] (I used a custom template for the report, but you don't need to go that far!)
This uses the features of LAG in SQL to compare the values on line for values on the line before - ability to compare these values allows you to determine which ones to show or hide.
Andy
-
Source text generated by current value - Expression?
I write an expression to control the sourceText of a text layer based on the length of another layer of text. Part of the feature is to only update the current text of the layer, if there is a pretty big change in length. Is there a way to access the current value of the text layer that was generated by the expression? value and sourceText.text pointing to the text on the text layer, not the generated layer.
Here's my expression
function calc(prevValue) { var textLength = thisComp.layer(1).text.sourceText.length; var perc = thisComp.layer(2).text.animator("Animator 1").selector("Range Selector 1").start; var newValue = 140 - Math.floor(textLength * perc / 100); return (parseInt(prevValue) - newValue) < 10 ? prevValue : newValue; } //Need to pass the previously generated text value here...how do you access it? calc(text.sourceText);Could not find any way to access in the expression references.
Thoughts?
Calvin
I think it's one of those cases where you will need to loop through all the previous images to restore the value of the expression + through the previous image.
Dan.
-
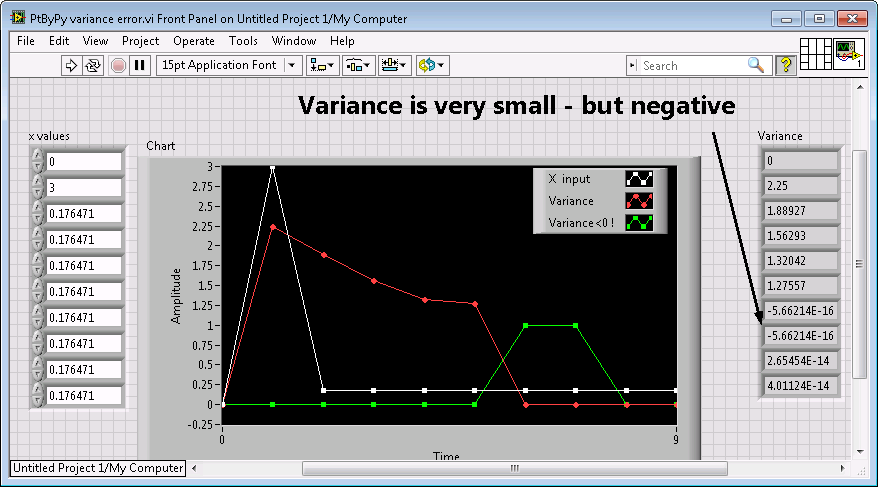
'Variance PtByPt.vi' generates values of negative values for some input
With certain sequences of input values the Gap PtByPt.vi can generate negative values. It is because of the precision in calculations.
Because it is very common to calculate the gap by taking the square root of the variance, this behavior can take you by surprise because the result will be Nan and not almost 0 you expect. According to the data, this may be frequent or very frequent. In general, a nuisance to debug.
The remedy is simple: take the Abs() before the square root value. A vi that demonstrates the case is attached.
I would suggest to include this correction (or similar) in the "Variance PtByPt.vi' because it gives rise to unexpected and hard to find errors.
By definition - variance cannot be negative.
CAR 446514 discussed in this thread has been corrected in LabVIEW 2014. For a more complete list of bugs fixed in LabVIEW 2014, see 2014 LabVIEW bugfixes. You can download a copy of LabVIEW 2014 evaluation at http://www.ni.com/trylabview/ or if you have a previous version of LabVIEW installed and an active subscription to SSP, you will be able to download the latest version of LabVIEW through NI Update Service.
Kind regards
Jeff Peacock
Product Support Engineer | LabVIEW R & D | National Instruments | Certified LabVIEW Architect
-
Duplicate values generated by an Oracle sequence
Hello
Since a few days we are facing a weird problem in our application where the sequences seem to be generating duplicate values. Previously I thought is this is not possible, but now it seems to be a problem. Here are the details:
Select * from v$ version;
Oracle Database 11 g Enterprise Edition Release 11.2.0.2.0 - 64 bit Production
PL/SQL Release 11.2.0.2.0 - Production
CORE Production 11.2.0.2.0
AMT for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
We use to insert it into a table column of the last sequence value that is of course the primary key of the table column. Today, we received a violation of unique constraint on the column of the primary key (which is driven by the sequence). Below is the last value of the PK column
SELECT MAX(PCCURVEDETAILID) OF T_PC_CURVE_DETAILS;
162636
and below, was the last value in the sequence that has been less than the PK column
SELECT S_PCCURVEDETAILS. NEXTVAL FROM DUAL;
162631
Then we checked the data of the user_sequences and found the next sequence value (LAST_NUMBER) to be 162645 which was greater than the current value of the sequence:
Select * de user_sequences one où a.sequence_name as "S_PCCURVEDETAILS" ;
SEQUENCE_NAME
MIN_VALUE
MAX_VALUE
INCREMENT_BY
CYCLE_FLAG
ORDER_FLAG
CACHE_SIZE
LAST_NUMBER
S_PCCURVEDETAILS
1
1E + 27
1
N
N
20
162645
I then modified the nocache sequence:
change sequence S_PCCURVEDETAILS NoCache ;
Select * de user_sequences one où a.sequence_name as "S_PCCURVEDETAILS" ;
SEQUENCE_NAME
MIN_VALUE
MAX_VALUE
INCREMENT_BY
CYCLE_FLAG
ORDER_FLAG
CACHE_SIZE
LAST_NUMBER
S_PCCURVEDETAILS
1
1E + 27
1
N
N
0
162633
SELECT S_PCCURVEDETAILS. NEXTVAL FROM DUAL;
162632
We also face the same type of problem of violation of primary key to another sequence-driven table, a few days before.
In our code, I also checked that the primary key in the table value is inserted using only the value of the sequence.
Can anyone please suggest any reason this issue for
Concerning
Deepak
I faced a similar problem about 3 years ago. Here's the story, suddenly in my UAT environment a job that inserts data in some tables began to throw exceptions of primary key violation. After investigation, I found that the sequence is x, but the primary key for the table is x + y. investigation more - DBA moved all production data without even notifying the application support team.
Morale - pretty obvious
-
Generate values for automatic fields
Dear gurus,
I want to generate automatic value for each field in the form, as for example in the course of field OLM code or any field in any application how can I fill with automatic generated value each time as sequence concatenated with some characters?
Thank youVisit this link
http://apps2fusion.com/apps/14-FWK/195-OA-framework-R12-extension-exampleThank you
Maybe you are looking for
-
An error in this Applescript that I can't understand
Hi, I searched some forums and found this script below which I modified. It works great except for a single statement: runScript If = 1 then number error -128 I want the script to do is, when a USB drive is mounted and is in the ignoredVolumes as "US
-
Cannot reorganize or delete 10 iOS apps
Hello! I have iPhone 6s and after installing iOs 10 I can't organize or remove apps, they will not even jiggle. Help, please.
-
It never happened until a couple of days and I knowingly did nothing to put it. I also just now uninstalled and reinstalled Firefox but that did not help anything. My internet explore and all other applications work fine. Only in Firefox now automati
-
Re: Satellite L850 - BIOS update problem
Hello I have problem with my laptop Toshiba Satellite L850 (PSKDLA-0C900R). When upgrading the BIOS to 6.1, there was windows pop up with error "Flash process will end!Current platform have secure start capability, it must provide the location of sto
-
I have a laptop HP DV6-6120us, bought less than 3 months ago. My validity sensor HP Simple pass suddenly stopped working. I looked in my device manager in the control panel and located the biometric device such as validity sensors (WBF) (PID = 0018).