Regular Expressions of Drivng me crazy!
Oracle Version 11 GR 2
Scripts of test data
CREATE TABLE REGEX_TEST
(ID NUMBER 4,
VARCHAR2 (50) COMMENTS
);
Insert into REGEX_TEST (ID, COMMENTS) values (1, "< Little Red Riding Hood > #title");
Insert into REGEX_TEST (ID, COMMENTS) values (2, "#title < Little Red Riding Hood > #publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (3, ' #title < Little Red Riding Hood > #publisher < Penguin > #pages < 30 > ");
Congratulations to Frank Kulash to provide the following SQL to clean the field of comments only properly marked the text in the field
Properly tagged text is defined as
Start by #.
then nameOfHashTag
then < valueOfHashTag >
The number or name of hashtags is variable and is not known at design time
The Frank provided SQL is (with a slight mod)
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
| Source language |
|---|
FIRST QUESTION: I understand the [^ #. * <] * component - search for zero or more occurrences of anything that is not a # tracking of zero or more characters, then a < and I understand the () sets a capturing group, but I don't understand how it works - 1 is probably a reference to the Group?
Now, I add a few more - lines to see how he treats badly marked text that is
void <>
text that is not marked
text is not enclosed by sharp hooks
Insert into REGEX_TEST (ID, COMMENTS) values ('4, #title <>");
Insert into REGEX_TEST (ID, COMMENTS) values (5, "#title <>#publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (6, "#title < Little Red Riding Hood > text that isn't marked < Penguin > #publisher");
Insert into REGEX_TEST (ID, COMMENTS) values (7, "#title oops I forgot #publisher < Penguin > rafters").
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
| Source language |
|---|
SECOND QUESTION: Is there any way I can specify that the <>cannot be empty - I played a bit with the +? but impossible to get what I want. Similarly, the latter (without text no sharp hooks)-I guess this would be impossible because you don't know if it was wong, until you have met the # next date you would be somehow to follow back and ignore the whole group.
I learned two things in this
1. regular expressions are extremely powerful
2. but they will drive you crazy?
Once again thanks a lot for the help
BTW - I managed to do what I had to do it using a lot of PL/SQL code, but not very fast!
Hello
So, you want only the substrings that are well-formed attribute/value pairs (attribute or value may be missing). You want to ignore anything in the comments that is not part of a well-formed pair.
It is not very difficult to get a single well-formed pair. The problem is that there is no good way to say 'everything that is not part of a well-formed pair '. One solution is to extract from each pair trained well on a separate line and then re - combine them into a single string by id, like this:
WITH split_data AS
(
SELECT id
comments
REGEXP_SUBSTR (comments,
, '#' || -sign #.
'[^<]+' || ="" --="" 1="" or="" more="" of="" any="" characters="" except="">
'<' || ="" --=""><>
'[^>]+' || -1 or several characters any except >
'>' -- > sign
1
LEVEL
) AS well_formed_pair
LEVEL AS pair_num
OF regex_test
([LEVEL CONNECTION <= regexp_count="" (comments,=""> <> <[^>] + > ')
AND PRIOR id = id
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT id
commented THAT the original
LISTAGG (well_formed_pair) WITHIN GROUP (ORDER BY pair_num)
THAT cleaned
OF split_data
GROUP BY id, comments
ORDER BY id
;
The 2nd argument of REGEXP_SUBSTR above is actually the same as the 2nd argument of REGEXP_COUNT. I wrote one of them in a more detailed form, hoping to make it clear what happens if has been done. You can write an expression so be it.
The result is just what you asked:
ID CLEANED ORIGINAL
--- ---------------------------------------- ---------------------------------
1 #title#title
2 #title
#publisher #title #pu
blisher
3 #title
#publisher #title #pu
#pages<30> blisher #pages<30>
4 #title<>
5 #title<>#publisher
#publisher
6 #title
#title #pu text
is not marked #publisherblisher
7 #title oops I forgot that the rafters whoops # #title forgotten angle br
Editorackets #publisher
Tags: Database
Similar Questions
-
When a string of characters, I'm interested, is buried in an e-mail, I would find these emails. It seems that as the code needed to find an email is already in place, it would take very little effort/code/support added to extend the search capabilities of more effectively, as it is available in spreadsheets.
This particular forum has these capabilities, suggesting that users find useful installation.
Are there reasons preventing these facilities being added to T/B? I find that the ability would frequently help me in search of my email.
FiltaQuilla both Expression search/GmailUI provide functionality, specifically the regular expressions.
FiltaQuilla aims to improve the message filters and has a useful side effect in improving the CTRL + SHIFT + f find. Research of expression increases the QuickFilter bar. Or rather weird global research assistance, but I work around this by using a Saved Search folder, where you use a dialog similar to the message filters and can make use of the enhancements offered by one of these modules.
-
The z570 has not a regular Express card slot (only a mini one)?
The z570 has not a regular Express card slot (only a mini one)?
Hi KiteEye and welcome to the community,
It doesn't have an Express card slot.
The small slot located is a memory card reader.
Dave
-
According to the link below, TS supports regular expressions. Can anyone provide an example where to write regular expressions?
I might be easier to do via a plug-in of .net, but TS permitting, I might go with it.
http://zone.NI.com/reference/en-XX/help/370052N-01/tsref/infotopics/find_regular_expressions/
Hello
Yes, there is a member of the PropertyObject.Search, but the result is search results, so I wonder how to use in the execution sequence?
What a simple solution using only 4 lines in Exression statement to realize this split and trim?
Concerning
Jürgen
-
Problem on regular expressions
Hi all
I'm working on a project that require me to separate the following examples:
+ 0, + 0.0000 E1, - 4.33 + E1, - 4.222 + E1, - 6.33 + E2, - 6.55 + E2
What I need is the final four results separately:
-4.33 + E1.
-4.222 + E1,
-6.33_E2,
-6.55 + E2.
I'm totally cool regular expression. Any help is appreciated!
Thank you
+ Kunsheng
Hi, Kunsheng
Good evening exercise to learn regular expressions...
For example, quick and dirty:

I have the strong feeling that something's wrong here (I guess in ([0-9] + [1-9] +)), but in any case the above code is just starting point for you.
Andrey.
-
Use matching of regular expressions to search for parentheses
Hi all
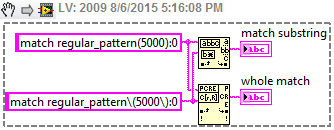
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Regular expression matching receives only two digit in brackets
Hello
I use the regular expression of the correspondence with the following expression. It is only able to get all the numbers that are not mere numbers. I want to retrieve all the values which lie between >< in="" the="" string="" and="" create="" an="">
Then
182 2 would be output
182
2
Any help would be appreciated. I've attached what I have so far. Right now I still have the >< and="" it="" can="" only="" grab="" numbers="" that="" are="" not="" single="">
Use (>.) [ ^(<>)]*)< *="" instead="" of="">
-
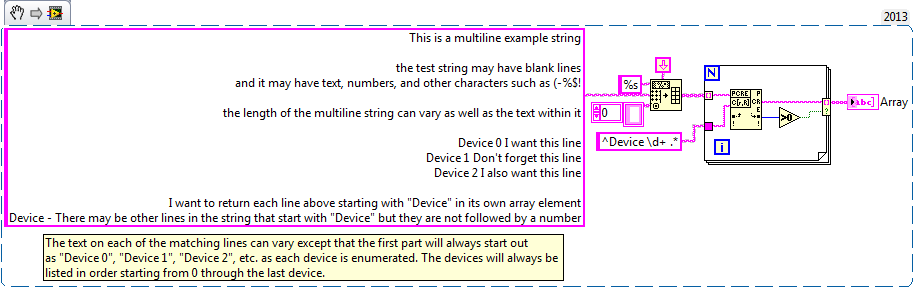
Multiline - Regular Expression Match string
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
regular expression for something that does not have a fixed sequence
Hello
Just having a little trouble with a regular expression. I have an input string and I want to find something that is not this string, so
Input = Hello
Match = Hello
Football game? = False
Entry = Hello1
Match = Hello
Football game? = False
Input = Hello
Match = goodbye
Football game? = True
As I thought that I understood it, to enter as a regular expression in the regular Expression.vi of Match would be ~ (Hello).
If I understand as well, I can't do this by using the match pattern.
Maybe you good people can correct me. Thank you!
-
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions?
For example, if I have a XML string as
Power supply error has occurred.
Sorensen SGA166/188 and I am interested in the tag method to retry only, I could write a regular expression something like
.*
.* to parse the string inside the tag.
kc64 wrote:
For example, if I have a string like
My email address is [email protected]. Please no spamming not me.
and I am interested in the domain name of the email only address, I could write a regular expression something like
@(\w)*\. (com: net | org)
to parse the string 'gmail '.
Forgive me if I am away from base, but I'm flying blind at the moment (not LV to test what I say). You can add to the power of a regular expression using submatches or capture groups. The regular expression you wrote will grab (I think) @gmail.com for the entire game. Let's say you want to get 'gmail' without a second function call. You can do the first group of a little dishonest selection by moving the * inside the parentheses. Then, on the BD pull down on the bottom of the function of regular expression matching to expose a variable number of submatches (both should be in this case). The first should be 'gmail '. The second one should be "com."
In summary, @(\w*)\.) (com: net | org) should give you gmail in the first submatch. Of course, my Perl is a little rusty and LV cannot apply in the same way.
-
What would be the regular expression to extract the "LEDsOnFront" of the string "FELIX-TestModules-LEDsOnFront - VIT.vit" (price not included)?
Looking for whatever text is between FELIX-TestModules - and - VIT.vit? If so, try using the Scan of string with a 'PUME-TestModules-%[^-]-VIT.vit' format specifier
-
regular expression or string (nevermind) format
Resolved,
I can use the string to a fractional number!
Hello
I have an array of strings in a multicolumn list box 2D, and I want to check if each value is a valid number, numbers can be one and can have negative values. Anyone know what regular expression, I need to check it out, or there at - it a still better way?
Best regards
Thijs
solved!
-
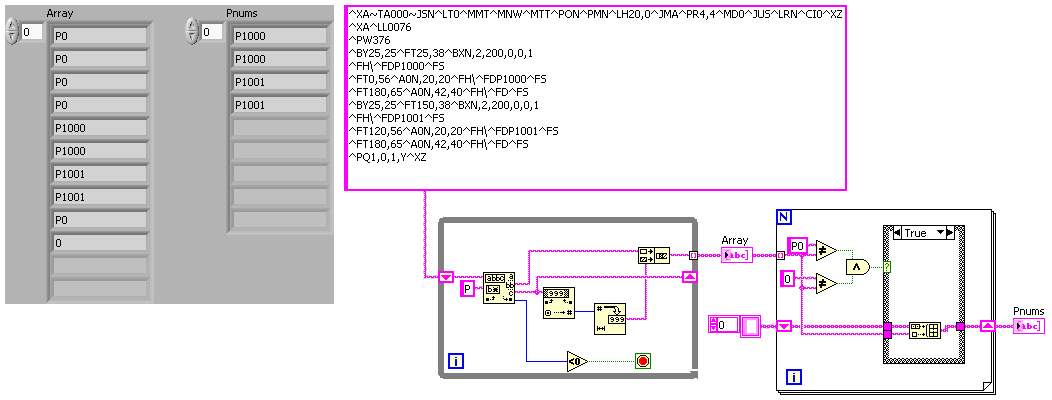
Hello
I have a string I want to use a regular expression to avoid a cascade of matching patterns, but I can't seem to make it work.
The string:
^ XA ~ TA000 ~ JSN ^ LT0 ^ TEM ^ MNW ^ MTT ^ PON ^ PMN ^ LH20, 0 ^ JMA ^ PR4, 4 ^ MD0 ^ JUICE ^ LRN ^ CI0 ^ XZ
^ XA ^ LL0076
^ PW376
^ 25, 25 ^ FT25, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1000 ^ FS
↑ FT0, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1000 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
^ 25, 25 ^ FT150, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1001 ^ FS
↑ FT120, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1001 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
↑ PQ1, 0, 1, O ^ XZI want to get out there is one instance of:
P1000
P1001
In this example. The numbered part will be different for the other channels, like P4567, PA34554, etc. He will never vary from P or PA. The section number can be 4 or 5 digits.
Each of these appear twice in the chain.
The regular expression, I tried to use is:
\^FD*\^FS
and then I was going to eliminate duplicates.
And now my brain doesn't give up.

Tay
This vi retrieves all P followed by numeric characters. You need to change to include AP
-
Search for a string using "Game Plan" or "Regular Expression to Match."
Hello
I would use the 'game plan' or the vi "Expression regular game" simply because the products that provide these vi. The result that interests me is the substring 'after '. I want to be able to specify a "substring" and get everything after the substring of the input string. However, I'm getting all confused and/or watered upward when it comes to "regular expressions". Is there a way to create a "regular expression" which acts as a 'substring' to find within the input string?
The substring is a path of partial directory that contains a colon, backslashes, etc. which are part of a directory path. If some how the "regular expression" entry must ingnore all special characters and simply to understand if the substring in the string entry and give me 'all things' after the substring in the output of 'after the string.
Use Regular Expression Match instead of match pattern; It's better.
-
Looking for the character "$" in a regular expression
I try to use the vi "Regular Expression to Match", but what I'm trying to find is a dollar sign followed by a space.
Using the slash codes allows me to specify a whitespace character (\s) but I can't find how to specify the $.
I tried \x24 and \36 try hex and decimal ASCII representations, but no luck, I tried to put the $ hooks - but which doesn't work either.
Everything I try, the $ is interpreted as a command rather than the search term.
I used to use model game (legacy code) and the search term "$\s*$ ' worked - now need to use regex that I need to feed in some other matches this regex only can do - except for the dollar (if only I worked in the good old UK £!)
Any ideas out there?
Thank you
I think that we must work...
\\$\s[\n\r]
seems to do the trick

Maybe you are looking for
-
Satellite 2410-504 does not start after you remove RAM module
Hello I need assistance or advice. I have a portable Satellite 2410-504 and I was looking for to increase the memory, I am a Novice with computers, I decided to remove the Module that is already in place (to see if I was capable of employment) After
-
Pavilion g7: administrator password
OK so when I turn on my HP laptop it says enter the administrator password or power on password, I just do it 3 times then he said disabled system [71526115] is there a way to fix this?
-
Use custom that sorts and types of lines in groups
I need to create a synthesis in DIAdem report. I have provided the raw data of another person. The data are organized in time. There are essentially 3 types of different lines that contain completely different data. What I would do is to separate the
-
I have a new 6600 HP all-in-one. I can't find the instructions for the settings of the scanner for example. resolution, rather than send it to etc. Not in the manual, not on the screen.
-
Drivers Dell 370 Bluetooth for Windows 10
I have Dell Studio 1555 and looking for the drivers of Dell 370 Bluetooth Mini Card Windows 10. BT is not detected in W10 and Device Manager shows no odd entries. I tried to install the drivers from the Dell website, but they cannot be installed even