Replace the newline character
Dear all,
Please help me with a query that replace the newline with null characters.
Suppose that I have a field test string and value in it's...
testString ="Hello, this is Yvon
->->-> (Average gap newline character should be replaced by NULL)
It is also Jean Louis"
Please, help me with a query to achieve the highest case talk.
Thanks and greetings
Yvon Das
Not sure you understand... maybe something like that?
SQL > select ' Hello, this is Yvon
2 it is also Yvon ' double.
"HELLO, THISISMONOJTHISISALSOMONOJ.
-----------------------------------------
Hello, this is Yvon
It is also Yvon
SQL > select replace ("Hello, this is Yvon
2 it is also Yvon ', chr (10), null)
3 double;
REPLACE ("HELLO THISISMONOJTHISISALSOMONO")
----------------------------------------
Hello, this is Jean Louis is also Jean-Louis
SQL >
Tags: Database
Similar Questions
-
manage the CLOB data delimited by tabs with the newline character
Hi all
I have a table with a column of type CLOB data where my data are delimited by tabs. For the new line I Chr (10) as the separator between the lines. Someone knows how to handle this character in order to select these data in separate lines.
Here is the example:
create table xx_test1(col1 clob); insert into xx_test1 values (TO_CLOB('1'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'300'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'119'||chr(9)||'229'||chr(9)||'340'||chr(9)||'450'||chr(9)||'560'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''|| chr(10) || '2'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'10'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'120'||chr(9)||'230'||chr(9)||'341'||chr(9)||'451'||chr(9)||'561'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''));I'll try this one, but it does not work. The last column is not correct and it returns the value of the next line and also does not continue to the end (I presume it's due to the position of the character hardcoded in regexp_substr). Any ideas how to handle?
WITH c_file_imp_data AS (SELECT dbms_lob.substr(col1, 32767, 1) src FROM xx_test1) SELECT --regexp_subsr is finding the position of the x occcurrance of a tab delimitter to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 1), chr(9))), --RECORD_ID to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 2), chr(9))), --BILL_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 3), chr(9))), -- BILL_TO_LOCATION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 4), chr(9))), -- SHIP_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 5), chr(9))), -- SHIP_TO_LOCATION, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 6), chr(9)), -- CURRENCY, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 7), chr(9)), 'DD-MON-YYYY'), -- GL_DATE, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 8), chr(9)), 'DD-MON-YYYY'), -- TRANSACTION_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 9), chr(9)), -- TRANSACTION_TYPE_NAME, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 10), chr(9)), -- TRANSACTION_SOURCE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 11), chr(9)), -- TERMS, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 12), chr(9)), 'DD-MON-YYYY'), -- DUE_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 13), chr(9)), -- PAYMENT_METHOD, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 14), chr(9))), -- SALESREP_NUMBER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 15), chr(9)), -- ITEM, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 16), chr(9)), -- DESCRIPTION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 17), chr(9))), -- QUANTITY, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 18), chr(9))), -- UNIT_SELLING_PRICE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 19), chr(9)), -- UNIT_OF_MEASURE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 20), chr(9)), -- WAREHOUSE, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 21), chr(9))), -- TAX_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 22), chr(9)), -- TAX_CODE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 23), chr(9)), -- GL_ACCOUNT_STRING, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 24), chr(9))), -- CURRENCY_EXCHANGE_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 25), chr(9)), -- LINE_TRX_DFF_CONTEXT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 26), chr(9)), -- LINE_TRANSACTION_FIELD1, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 27), chr(9)), -- LINE_TRANSACTION_FIELD2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 28), chr(9)), -- LINE_TRANSACTION_FIELD3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 29), chr(9)), -- LINE_TRANSACTION_FIELD4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 30), chr(9)), -- LINE_TRANSACTION_FIELD5, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 31), chr(9)), -- LINE_TRANSACTION_FIELD6, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 32), chr(9)), -- LINE_TRANSACTION_FIELD7, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 33), chr(9)), -- LINE_TRANSACTION_FIELD8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 34), chr(9)), -- LINE_TRANSACTION_FIELD9, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 35), chr(9)), -- LINE_TRANSACTION_FIELD10, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 36), chr(9)), -- LINE_TRANSACTION_FIELD11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 37), chr(9)), -- LINE_TRANSACTION_FIELD12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 38), chr(9)), -- LINE_TRANSACTION_FIELD13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 39), chr(9)), -- LINE_TRANSACTION_FIELD14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 40), chr(9)), -- LINE_TRANSACTION_FIELD15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 41), chr(9)), -- INV_LINE_INFO_DFF_CONT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 42), chr(9)), -- NO_ANIMALS, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 43), chr(9)), -- MX_WEIGHT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 44), chr(9)), -- MX_SLAUGHTER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 45), chr(9)), -- REBILLED, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 46), chr(9)), -- NON_STAT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 47), chr(9)), -- ATTRIBUTE12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 48), chr(9)), -- ATTRIBUTE13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 49), chr(9)), -- ATTRIBUTE14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 50), chr(9)), -- ATTRIBUTE15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 51), chr(9)), -- ATTRIBUTE8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 52), chr(9)), -- ATTRIBUTE11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 53), chr(9)), -- ATTRIBUTE2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 54), chr(9)), -- ATTRIBUTE3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 55), chr(9)), -- ATTRIBUTE4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 56), chr(9)) -- ATTRIBUTE9 FROM c_file_imp_data
Oracle DB version: 12 c
Thanks in advance,
Alex
with
xx_test1 as
(select TO_CLOB ('1' |)) Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 300'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 119' | Chr (9) | ' 229'. Chr (9) | ' 340' | Chr (9) | "450 | Chr (9) | ' 560' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (10) | '2'|| Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 10'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 120'. Chr (9) | ' 230'. Chr (9) | ' 341'. Chr (9) | ' 451' | Chr (9) | "561' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ") the_clob
of the double
)
Select x.lne
of xx_test1 t.
XMLTable ('/ a/b ')
from xmltype ('' |) Replace (t.the_clob, Chr (10),''): '')
path of ESA varchar2 columns (4000) '.'
) x
ESA 1 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 15 300 each ZZU PL Imported bills 119 229 340 450 560 Franchise COGS 12 13 14 15 Y 10 0 2 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 10 15 imported bills each PL ZZU 120 230 341 451 561 Franchise COGS 12 13 14 15 Y 10 0 It seems that you know how to do the rest
Concerning
Etbin
-
any easier way to replace the last character in a string?
That's what I got:
and I am enough fan of it. It's ugly and it's long.select SUBSTR('tjgb005dy_01_31_08',1,LENGTH('tjgb005dy_01_31_08')-1)||'1' from dual; -- tjgb005dy_01_31_01
so, I wonder if you have better ideas?
Thank youEven easier:
select regexp_replace('tjgb005dy_01_31_08','.$','1') from dual; -
Replace the 100 pages with Lorem Ipsum?
OK really puzzled
I have 100 pages in Word of the text, and I need to replace the Lorem Ipsum text.
Plan was to import text into InDesign, keep the styles, so forth and so
But how would we go about replacing all the Lorem Ipsum text, while retaining the text, character for character, line for line, Word for Word, style?
(this plan is to export the text to RTF to word and copy and paste the copy into Word)
An operation what strange
You can not easily replace the text character by character. Word by Word, however, was quite fun exercise.
This script retains the original formatting, but replace the frame selected by your standard Lorem text (threaded) content. As a side effect, all signs of punctuation is also retained - which is caused by the replacement of words objects. Perhaps you meant, maybe it isn't.
(Save it as "ScrambleTextToLorum.jsx" in your scripts folder; select the first block of text to loremize, double-click the script is running.) Wait a little.)
if (app.selection.length != 1 || app.selection[0].constructor.name != "TextFrame") { alert ("Ground. Pull up. Ground. Pull up."); exit(0); } // Save selection targetStory = app.selection[0].parentStory.texts[0]; // Make a Lorem frame loremFrame = app.activeDocument.textFrames.add(); loremFrame.geometricBounds = [ "0mm","0mm", "200mm", "200mm" ]; loremFrame.insertionPoints[0].appliedFont = "Times New Roman"; loremFrame.insertionPoints[0].pointSize = 8; loremFrame.contents = TextFrameContents.PLACEHOLDER_TEXT; sourceStory = loremFrame.texts[0]; // Grab its words sourceWords = sourceStory.words.everyItem().contents; // .. and kill the placeholder loremFrame.remove(0); // Replace one word at a time. Start at the end. sourceWord = 0; destWord = 0; while (destWord < targetStory.words.length) { targetStory.words[destWord].contents = sourceWords[sourceWord]; destWord++; sourceWord++; if (sourceWord >= sourceWords.length) sourceWord = 0; } alert ("Safe landing. Have a nice day."); -
delete the last character of line break
How can I remove the newline character from the end of a string? (Note: there are several line break characters in the string). Thank you!This may or may not work, but it is worth it.
If (right (Votrechaine, 1) is 10)
Votrechaine = left (Votrechaine, 1, len (yourstring)-1); -
InDesign CC Grep find/replace to replace the character of space per paragraph (fly)
Hello InDesigners,
I'm trying to clean up a 99 page document. In the file, titles of chapters, in capital letters, followed by a space, which is then followed with text more uppercase there. This always occurs at the beginning of a paragraph.
I'm trying to target the space character that appears just after the number of chapter and Exchange to a number (fly).
For example:
CHAPTER 22 SUNDAY UNDERGROUND
I want the Grep to change this as follows:
CHAPTER 22
SUNDAY UNDERGROUND
I know that to do this job, I need to use positive look behind and positive Look Ahead, at first, I just tried to isolate CHAPTER 22 using the following:
^ \u{2,}\s\d+
It worked. However, as soon as I cut and paste into P.L.B., find/replace says that it does not match.
(?<=^\u{2,}\s\d+)\s
The culprit seems to be the comma that comes just after the number 2. If I take, I get a match, but just not the one I wanted.
Why P.L.B. does not accept the comma as part of the range in my definition grep?
(FYI, I prefer to use wildcards with a specified scope, rather than literal text).
It is indeed the comma, and the reason why it does not work because the flavor of InDesign's GREP does not allow a variable length argument in its lookbehinds. And the construction "has {x, y}" indicates a variable length.
"Chapter" only you know how many characters to uppercase, and even the exact text, you can use
(?<=^CHAPTER>
the first chapters to a number, then
(?<=^CHAPTER>
for the rest. In your version of InDesign, I guess there is also a possible solution with the fairly new \K "forget - me" operator but I have not yet enough experience with that. It should look like this:
^ \u{2,}\s\d+\K\s
but you will have to experiment a bit to see how to work with the replacement string.
In addition, you should only use the name of "fly" for a character that looks like this: "¶". The code that you insert will call it a 'return' or 'paragraph return. Initially, I took your question literally, and it sounded as if you were after this result: "CHAPTER 22 ¶ SUNDAY UNDERGROUND"
-
How to remove the newline from the query output?
Hello
How to remove the newline from the query output?
have tried to replace select (column_name, Chr (10), ' ') from table_name.
Published by: GreenHorn 11 Sep, 2008 12:53 AMPlease consider, that windows uses a sequence of chr13 | Chr (10) Unix uses only a single character CHR (10).
The new line characters may depend on the operating system.You might consider with:
Replace (replace (column_name, Chr (13) |)) CHR (10), ' '), CHR (10),' ')
Hartmut
Published by: hartmutm on 11.09.2008 01:32
-
Lose the first character in the e-mail address
When I go to enter an e-mail address, I start typing the address in the required field. When I type '@', the first character of my e-mail address disappears from the input field. For example, I type 'jstewart' and when I type the symbol @, the letter 'j' disappears. This happens on all websites and happened the last 2-3 months approximately. Someone has an idea what is the cause?
In the menu bar, you select
Change ▹ Substitutions
and uncheck all the options. Test. If the problem is resolved, you can experiment with the reactivation of some options to isolate further the cause. You can change text replacements tab in the keyboard preferences window text.
-
replace the uniqueness and leave those in expressions
Hello
I'm looking for beautiful and elegant solution to my problem. Let's say I have a string "e + exp (e)". I want to replace all 'e' by '1', except for "exp". I tried to use regular expressions, but I failed an hour later... The solution should be able to resolve things like replace "a" to "r (a)" without changing the rand. Basically, I need to replace the uniqueness without replacing those words or phrases.
Any ideas?
No time for elegance now, just brute force. I would touch the string with spaces at each end to remove end cases and then look for the character surrounded by non-alphabetiques characters.
-
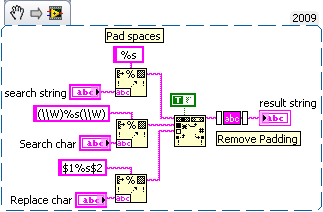
Search and replace, unadulterated second character?
I'm doing a VI that communicates with an external device via a protocol consisting of images. I made a couple of subVIs that put these images together as hexadecimal strings which are then converted into numbers and passed to the device. The protocol uses an escape character to avoid sending a constant BOF or EOF at the wrong time. I did a Subvi, which is supposed to do this by using the search and replace. Initially, it looks quite elegant, but it has a fatal flaw, if one of the characters it is supposed to hide is written on the edge of a byte, it will always be replaced.
Example:
11 01 00 CE 0D 05 08 EA
is replaced by
11 01 00 05 08 EA 0D E7
C0, C1, 7 d are the characters to replace, the 7 d is the escape character.
Now I wonder, is it possible to do a search and replace function search only every second character in a string?
Hi Tzench,
Why you do not work with numbers of converts? It should be easier (and safer) to replace some U8 values instead of search (errors) & replace in a string...
You should also be careful when you give examples. So in your example, the "hex" number is separated by spaces, search & replace should not create problems with "byte-border '!
-
Find and replace the string function replaces line breaks when I only replaced spaces?
I need to replace all instances of a space or a series of spaces to a line with commas (or tabs) multi string so I can throw in a worksheet.
I use the regular expression [\s]+ and it works, but it is also to replace the end of lines (\r\n) too.
How can I replace the spaces but leave the end of the lines intact?
Right-click on the search string and to take '-' code display. Enter the space character (\s) correctly - you \\s right now.
-
Changes in Word, when I enter a character or letter, it deletes the next character
original title: change in Word
I was to edit a multiple page document. So far, if I add or change a character, he just replaced what I typed. All of a sudden, when I enter a character or letter, it deletes the next character. I lose words or letters. How to get back to editing without erasing it?
Press ENTER on your keyboard. See http://en.wikipedia.org/wiki/Insert_keyif you happen to have Word 2007 (or 2010) see http://help.lockergnome.com/office/Insert-key-work--ftopict1003194.html or http://www.technize.com/how-to-enable-insert-key-in-microsoft-word-2007-word-2010/
-
Failed to retrieve after replacing the hard drive on my DV6
I replaced the hard drive on my DV6. Insert the recovery discs, I had done and went through the process. At the end it rebooted and was told that he failed. Says to put 1 recovery disc in and try again, but just a loop even message.
Hello
Assuming that it's just a problem with the recovery media, here's another solution, you can try.
Before you try the following, make sure that you can always read the character product activation key 25 on your label Windows COA (5 blocks of 5 alphanumeric games).
An example of a COA label can be seen here.
You can create a Windows 7 installation disc yourself using another PC - just download the good Disk Image ( this must be the same version that originally came with your laptop - it is listed as Windows 7 Home Premium ) from the link below and use an app like ImgBurn ( Note: you can deselect additional software offerings when you install ImgBurn) to burn the ISO correctly on a blank DVD - a guide on the use of ImgBurn to write an ISO on a disc is here. The source of the Windows Image is Digital River.
Windows 7 Home Premium 64 bit SP1.
Use the disk to perform the installation, enter the activation key of Windows on the label of the COA at the request and once the installation is complete, use ' 'phone Method' described in detail in the link below to activate the operating system -this made method supported by Microsoft and is popular with people who want to just have a new installation of Windows 7 without additional software load normally comes with OEM installations.
http://www.kodyaz.com/articles/how-to-activate-Windows-7-by-phone.aspx
All pilots additional and the software, you may need can be found here.
Kind regards
DP - K
-
DV6-6119wm: HP Pavilion dv6-6119wm - replace the hard drive with a hard drive from a laptop Gateway
OK (deep breath). I have a dilemma, and I hope that you all can help me.
First of all, the HP laptop in question is a dv6-6119wm QE069UA #ABA, Windows 7 Home Premium.
A month ago, it began overheating and then blue screened on me with a fan error. I ran it while I was getting this error, which was a mistake, because according to me, he has finally caused the hard drive failure after enforcement of reset factory several times. But I'm getting ahead.
I replaced the fan and the heatsink myself. Another factory reset. Downloaded and installed all the updates of windows. Ran great for like a week with the exception of the fault 1 hard disk when I ran the Start Up Test.
Then when I restarted yesterday... He's dead, so he is dead. Apparently, the hard drive failed completely and comes only a black screen telling me it cannot start.
So, I have this other model of Gateway laptop, NV55C26u which has stopped charging. I had to put it away and don't worry. I got out the hard drive and tried HP successfully. ! Sorta.
It considers that the HP is a gateway and as a result, none of the drivers are there for all the good stuffs HP. It cannot connect to the internet and does not recognize the USB flash drive. (I had downloaded all the drivers on another laptop and put them on a pious flash drive I could convince the hard drive it's HP again). Another hard drive WILL work in the dv6, and I had no errors on startup it upward.
I have no recovery discs or store bought Windows 7, all came with the laptop preinstalled. But I don't have my key to the label.
Then what should I do? I'm not exactly tech savvy, I know just enough to be dangerous haha, but I tend to go glassy when things get too technical. I thought I could get something Microsoft to reinstall my Windows but I guess they closed this path down a few months ago.
I have access to 2 other laptops, both HP. A QE304UA of Pavilion G7 #ABA with Windows 7 Home Premium and a HP 250 G2 Portable F7V84UT #ABAwith Windows 7 Professional.
So basically in order to encapsulate this novel to the top, which can do here to fix my dv6? How can I convince this other HDD HP rather than Gateway? I can create something from one of these other HP laptops? Download something somewhere? I don't want to have to buy Windows again. I love this phone and need her in my life as a game.
Please help me

You must do a clean install of Windows on them. The hard drive has drivers for completely different material. Too bad that you did not have your drive to retrieve the value. It would restore the hard drive to HP with all the drivers/software installed. It would depend if the hard disk is at least the same capacity or larger than the original. Recovery discs are reluctant to a smaller capacity hard drive.
You can order recovery Medai for about $16:
==================================
If you can read the Microsoft Windows 7 of 25-character license key, you can download a Windows 7 ISO file to burn to a DVD or USB flash drive. The version must match that's installed on your PC as shown on the sticker COST Microsoft fixed on the bottom of the laptop. Like Windows Home Premium.
Links to downloads of Windows 7 ISO files: -
recovery after replacing the hard drive - pavillion dv6 notebook
Hello
I'm about to replace a defective hard drive on my pc, but I'm not sure how to continue the process of windows recovery. I was wondering if I need to contact HP for recovery set despite the fact that I have a recovery disk (D :) on my laptop. I replace the local hard drive (c :)) and I was wondering if the recovery on my pc drive is enough to drive the recovery process?)
Thanks for your help,
Hello
The recovery is actually just a partition on the same physical drive as your operating system, so when the HARD drive is replaced, it will be gone, however there are two options available.
1. you can order a set of replacement recovery disks using the link below - it will reinstall the operating system, all the drivers, and almost all of the original software (the exception being often tests of MS Office). They will also recreate all of the original scores, including the recovery Partition D.
2 another option that you might consider is to create your own Windows 7 installation disc.
Before you try the following, make sure that you can always read the character product activation key 25 on your label Windows COA (5 blocks of 5 alphanumeric games).
An example of a COA label can be seen here.
You can create a Windows 7 installation disc yourself using another PC - just download the correct disk Image ( must be the same version that originally came with your laptop - IE Home Premium, professional etc. ) from the link below and use an app like ImgBurn ( Note: you can deselect additional software during installation of ImgBurn offerings) to burn the ISO correctly on a blank DVD - a guide on the use of ImgBurn to write an ISO to a disc is here. The source of the Windows Image is Digital River.
Windows 7 sp1-iso-official-32-bit-and-64-bit
Use the disk to perform the installation, enter the activation key of Windows on the label of the COA at the request and once the installation is complete, use ' 'phone Method' described in detail in the link below to activate the operating system -this made method supported by Microsoft and is popular with people who want to just have a new installation of Windows 7 without additional software load normally comes with OEM installations.
http://www.kodyaz.com/articles/how-to-activate-Windows-7-by-phone.aspx
You may need, additional drivers and software are in entering either the complete model number or product of your series dv6 notebook no here.
Best regards
DP - K
Maybe you are looking for
-
IPhoto albums - surplus to remove
I always use IPhoto as opposed to Photo - are all just more easy. Problem is the best way to clean unwanted or surplus photos. Over the years, thousands of photos are uploaded and I usually sort the best of them in Albums. Now - years later - my ha
-
My phone is detected with Malware Android.Malware.Agent
Our safety engineer told me that there is a Malware Android.Malware.Agent detected on my phone and need to contact the seller for more details. Y does it can someone help me understand what I should do next? Thanks in advance!
-
Generation of pulses using NOR-PXI-5421 FGen
Hello Sir/Madam, Question: We use the Funktiongenerator NOR-PXI-5421 and just want to generate a pulse, because it can be done in almost all cheap Funktiongenerator. Unfortunately, I can't find a way to tell the Funktiongenerator to generate a pulse.
-
Syystem is slow. Commissioning and usage. First thing erro file for license bombar.scc.ext reading?
-
Hard drive not recognized on the computer after the upgrade to Vista
I just upgraded to vista a my ext hdd does not come in computer how to install human and format the hard drive?