RS232 data distribution
Hello, new to Labview!
I am trying to split a stream of bytes coming to read VISA, these values are given for 3 probes but they gathered to read the values at the same time.
the flow is like this ABCABCABCABC...
Advice please?
Hi sveirq,
you do not use StringSubset in your image. You convert your string in an array of U8 and divide by another array (constant). Don't know what you want to achieve this way...
You really need assistance in the use of StringSubset?

Tags: NI Software
Similar Questions
-
I can collect data from a hygrometer in a text file using the RS232 port with the following T75.2F:H17.0% format, these data are collected using a data logger software. I was wondering if I can collect this data for later analysis using Dasylab. Any help is appreciated.
The setting below causes the error. Change for the second selection, output values of all channels.
-
I'm trying to change the example VI for RS232 read for recording data. Basically, by train to save my gauge measure reading data with time stamp. My VI updated the record data, but it records only the last value before I stopped the program, while I want them to keep reading and recording data until I stop. I don't know where I am going wrong. I enclose my VI with this post. could someone help me please.
Never mind, just understand what I was doing wrong. The folder creation function was in the loop so each interval he formulated a new file, accidental on the precedent thus earasing all previous data, but the data from the last point.
-
Hello
I use RS232 to get an OPTICA dew point sensor data. Whenever I run my program labview (attached file) it gives me the data but not the complete data. Sometimes, I'm a part of the data in call 1 and the rest of the data in 2 cal. Sometimes I don't have LMA data only once, and sometimes none at all. But when I run the program in EXECUTION mode to highlight I data in appropriate and complete order.
Is there a problem with the labview program? or my instrument is not able to answer the call at the time!
Any solution to this problem will be highly appreciated

Thank you
Ford
My first guess is that you do not wait long enough for the instrument to respond. You have enabled endpoint character but then you make a VISA to the Serial Port bytes. Do one or the other.
In addition, get rid of the structure of the sequence. It doesn't do anything.
-
Fragmentation of the distribution of system and database data
Hi all
I'm working on a scenario (University), with the fragmentation of a central database. A company has regional offices, i.e. (England, Wales, Scotland) and each regional office has different combinations of areas of activities. They currently have a central database in their seat and my task is to "design a data distribution system. Regime that means something like the horizontal fragmentation / portrait? Also can someone point me to a specific example of the Oracle of creating a fragmented table? I tried to search online and found the keyword ' partition by ", but not much with the exception of database that links - but I think that it is more concerned with the mark than to actually create the fragments.
Thank you very much for your time>
I would like to create a Db (or data access system) for each region that contains the data for this region - only, for example in Wales has that one sector of activity must therefore only the entered information and used for staff in this area. Instead of completely replicating the entire DB in each regional office, I want to create the smallest region specific "fragments" of the central office DB.Regions should combine once a month for pay, etc., but the idea is to distribute the data locally. My task is to find the best solution for the scenario, put in balance the advantages and disadvantages
>
The simplest solution is what I suggested in my first answer.Use the central DB. Partition of the table as your sample; by region. RLS (row-level security) allows you to restrict the regions to their own data.
Only a single "Central" table has ALL data regions; It is only in the partitions.
The only real issue is that the regions will have access as a remote central DB. This isn't really a problem in this day and age. The largest companies have data centers and local regions or offices do not have their own DB.
In my humble OPINION the replication should be AVOIDED unless it is absolutely necessary.
-
Cannot retrieve data package POR_CUSTOM_PKG requisition lines. CUSTOM_VALIDATE_REQ_DIST
Description of the problem
---------------------------------------------------
We need to validate the data Distribution and inspiring that we will return the error by the respective line. But the number of line is not in the list of parameters of the POR_CUSTOM_PKG procedure. CUSTOM_VALIDATE_REQ_DIST. So we thought of bypass line number by querying the table po_requisition_lines_all from the parent_req_line_id. But unfortunately the motion throws no found exception data if the records of the associated line are seen for the backend.
Ask for your help to get the line number of this procedure POR_CUSTOM_PKG command. CUSTOM_VALIDATE_REQ_DIST
Hello
It's just for information that the problem is solved for me using the code below.
Start
Select parent_req_line_id in the double l_line_id_1;
Select requisition_line_id, line_num in l_line_id, l_line_num
of po_requisition_lines_all
where requisition_line_id = l_line_id_1;
exception when others then
null;
end;
-
Hello world
I am relatively limited user... DASYlab 11, Basic. I try to read some RS232 data and create patches of several variables related to a Jet engine. (It is a hobby project, not for professional use or profits.)
I read the RS232 data, it seems fine with the input module. I also use a temporary virtual RS232 input terminal so that my spreadsheet DASYlab to debug. I'm then parsing the data in 4 channels and display the results on a digital display. So far, things seem to work well. The problem is when I take the data from the output of the module to display and input it in a Y/t diagram it does not appear on the diagram of Y/t. I put a copy of a screenshot on dropbox here...
https://DL.dropbox.com/u/89576457/screen%20Shot%202012-12-02%20at%209.58.52%20PM.PNG
I tried to run another entry in the Y/t diagram with success everything as a test of the analog input of my sound card. Which is working very well...
I'm a stream feeding the RS232 port on every 3 seconds. I can increase the speed of advance. So far, the data appear on the digital display as it should and even on the Y/t module input lines, but I don't get any trace of data.
Any ideas on what I can do wrong?
Any help would be greatly appreciated. Introduce a hobby have to do with the plot of the data in real time for an aircraft engine... not for professional use or profit.
Dave
Thank you so much CJ... Got his job!
Now her enough top!
Dave
-
Several Applications using UDP Multicast Open (read only) on the same port
Hi all
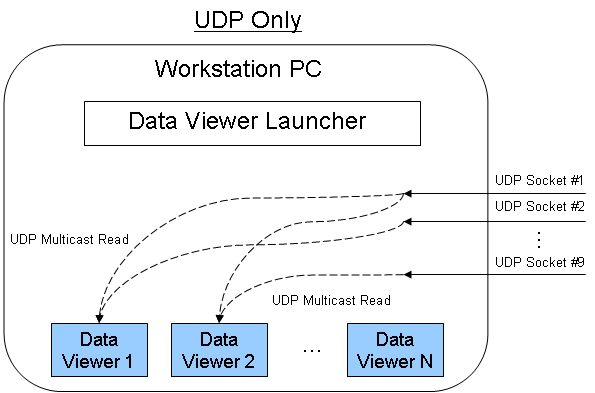
Currently, I am trying to build a system that has the following architecture:
RF Server = "1-9 A/D '-> «UDP Multicast (write-only) 1-9"»
Workstation operator = "QTY (N) Data Display Apps all need independently to access one of the 9 UDP multicasts at a time.
Essentially, I have 9 items of antenna that all digitized and distributed via UDP separate multicast address and port. On the receive side I need to be able to have the N number of data display applications where everyone can select the antenna element he wants to get data from. My current goal for N is 7 and the worst case for the data rate is 3.75 MSps IQ rates on each display.
My question is whether or not it is possible to have several "UDP Multicast Open (read only)" on the same port but one by application Data Display? Also, are there limitations with this.
On my local machine I tried a bit with the example 'UDP Multicast Sender.vi' and "UDP Multicast Reciever.vi". I created a "UDP Multicast Reciever2.vi" as another application that listens on the same port/Multicast address as the original receiver. No errors are thrown when you run the receivers and both receivers get the data string sent by the sender at the same time. Can I send data/a. 'PC'-> 'Router Ethernet'-> 'PC with receiver UDP N' reliable evidence? If so, that's fine, because it would be relatively easy to implement. BTW, I do not fear with occasional loss of data what is happening with UDP.
If this does not work, I am also curious to know which deals with data deduplication. For example, two applications by subscribing to the same Multicast address and port does the router send two copies (which increases network traffic)? Or, the Windows operating system get a single UDP packet to the port and replicate in two independent applications?
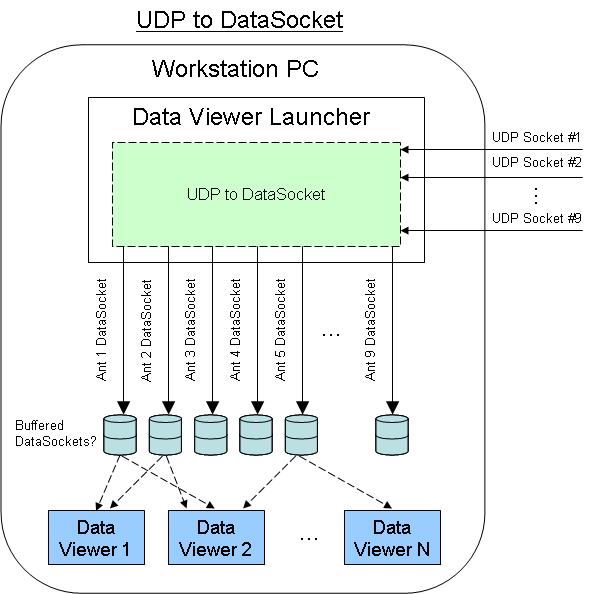
Below (or attached) are the two methods I thought. If multiple readers of UDP does not work so I thought I'd do a DataSocket "Data Distribution layer" between the incoming UDP sockets and display data on the workstation applications. This would add a bit of memory/processor to the PC workstation, but I know the DataSocket server of NOR can handle a sender unique multiple receiver architecture.
Thank you
Tim S.
Hi Tim,.
The number of concurrent applications, get data on the same port UDP will probably be a limitation of the OS as well. If I had to guess, I would say that 7 of the applications should work correctly. In fact, the memory/CPU bottlenecks are probably the limit on how many simultaneous readers we have, especially since the capablities of PC hardware differ from one computer to the other. I doubt that the OS has a strict limit.
-
Hello my friends!
I m working with pic 16f877A, and I want to do (rs232) data acquisition in labview!
I want to read adc 0 to 5V and view it on a chart.
I m using an example of mikroC:
/*
* Project name:
ADC_USART (data transfer on serial port ADC)
* Copyright:
(c) 2005 Mikroelektronika.
* Description:
The code performs a conversion of AD and send the results (upper part 8 bits) through the
USART.
* Test configuration:
MCU: PIC16F877A
Dev.Board: EasyPIC3
Oscillator: HS, 08.0000 MHz
Post modules: -.
SW: mikroC v6.0
* NOTES:
None.
*/temp_res short unsigned;
Sub main() {}
USART_Init (9600); Initialize USART (9600 baud, 1 stop bit...Select Vref and analog, to be able to use ADC_Read
ADCON1 = 0; All pins of porta as analogous, VDD as Vref
TRISA = 0XFF; PORTA came{}
Reading ADC results and send the high byte via USART
temp_res = ADC_Read (2) > 2.
USART_Write (temp_res);
} while (1); endless loop
}I know that in terminal mikroC, I can see data communication, but I Don t have any instance on labview to work!
can anyone show me any example labview or, as well as a better pic program?
Thank you very mutch.
jimboli wrote:
I know that in terminal mikroC, I can see data communication, but I Don t have any instance on labview to work!
can anyone show me any example labview or, as well as a better pic program?
You searched by examples? NEITHER comes with examples of serial port. Since you send just a single byte of data, you need to configure the serial port to disable the stop character and set playback VISA to read as a single byte. For example Cory gave, this means a fake of wiring at the entrance to "Activate the tank of termination" and a 1 wiring at the entrance to the VISA reading "number of bytes. I also suggest using a waveform instead of a graph chart. In this way, that you don't need e shift register or build the Array function.
-
Temperature controller gives wrong powerup configuration after communicating with RS-232
Hello
I was working with a temperature controller Programmable of Lakeshore 330 using the LabVIEW drivers downloaded from the pilot site OR. My goal was to implement a continuous of RS232 data acquisition. I initially thought of using code similar to that used in another sensor (a pressure sensor that acquires data from RS232 continuously). Unfortunately, I kept this vi in the vi even because the I am developing. When executing the vi, I got error by the pressure transducer, which is possible because the two transducers are trying to communicate by using the same serial port. After this, my temperature Lakeshore 330 controller always turn on in a bad configuration. I can't change the input string. Also, in temperature measurement, the two numbers after that the comma is missing. For example, instead of 21.43 is just showing 21.
Anyone know what's happened here? I restarted the Lakeshore several times, always without change. Is it possible that the command of erroneous entry on the Lake spoiled the setting somehow? It is possible to return to the original factory puts. I'm getting desperate.
I appreciate deeply all help and suggestions.
Thanks in advance
Zch
It is really not a problem of LabVIEW, but a user error.
All I can say is that you read the manual for the controller of Lakeshore. They are either going to have a few steps that you can use to reconfigure using the controls in the Panel before, or perhaps their own software to help set it up. Also look at regardless of the Protocol that they use for serial communication. Compare that to what you were trying to do with peripheral pressure can tell you how you may have accidentally changed the configuration of controllers mixed Lakeshore when you got their code and serial ports.
-
12 c to Oracle business intelligence: is it really effective?
Hi experts,
I am Manager of the Business Intelligence service in a society. We use SAP BI4.1 SP3 and an Oracle 11 g server.
We have big questions about our various requests.
We are interesting in the migration to Oracle 12 c data and functionality "in memory".
But the one is commercial viewpoint, as "it's magic, you will have a x 100 improvement, you'll have to create tables to agregate.
I'm not sure it's that the real (but if it is, that would be great).
My data warehouse volume is 7.
The biggest volume of tables are 600 GB (+ key or index volume).
(1) if I use Oracle 12 c with all the features of 'magic', can I expect a big improvement in queries?
(2) if so, is there a lot of "tuning" on the database? is easy for a DBA?
(3) to use the "in memory" function, can put ALL my data warehouse in memory? (as with the HANA database)
(4) If Yes, thanks to compression, the amount of memory do I need on my server database?
(5) is there with oracle 12 c 'column 'store technology (as in SYSBASE)?
Thanks in advance for your advice and answers
A. Drieux wrote:
(1) if I use Oracle 12 c with all the features of 'magic', can I expect a big improvement in queries?
(2) if so, is there a lot of "tuning" on the database? is easy for a DBA?
(3) to use the "in memory" function, can put ALL my data warehouse in memory? (as with the HANA database)
(4) If Yes, thanks to compression, the amount of memory do I need on my server database?
(5) is there with oracle 12 c 'column 'store technology (as in SYSBASE)?
(1) overall characteristics of the 'magic' allow you to identify the data that you need very quickly. If you do a lot of processing of this optimal subset, then you'll be running to the 'normal' intensive speed from there.
(2) not a lot of development, provided the database is pretty well designed in the first place and you did something that works directly ON the privileged Oracle infrastructure - for example the use of the digital yyyymmdd is an obstacle to Oracle which has a very good knowledge of optimization through its date types.
(3) technically, you could - although according to your paritioning and requirements of how you use the data you can be choosy if you can't get your hands on enough memory.
(4) very hard to say - patterns in the data distribution make such a difference in the degree of compressibility, and there's always trade in the meantime CPU compression and decompression and compression level. Store column in Oracle memory running at one of the lowest degrees of compression allows for example of filtered data without decompression that can allow selection of data extremely fast at the cost of increased memory use.
Yes 5)- and it works in pieces of 1 MB, so that (for example) 30 000 lines could be compressed into a piece of 1 MB with a few pieces of metadata of 64 k which record critical summary information about the piece of 1 MB, enabling a request completely ignore a piece of 1 MB, as the metadata shows that there will all the relevant data in the block.
Concerning
Jonathan Lewis
-
Identification and drops the unused index - index of key foreign - 11g R2
Hi team,
In our application, table main source have nearly 55 M records and this table have almost 15 foreign key columns. He y 5 foreign key columns that reference 5 very small tables (max 10 lines for each table) where the child tables ever updated or removed, it's very static data.
so we thought to remove the foreign key index, in order to expedite the DML operations on the source table.
It's the right option... ?
Please guide me on the right track, please...
Thank you
RAM
Almosty certainly right, but there are a number of things to be wary of:
(a) you can't update the keys to reference table (parent) deliberately, but some application codes (typically a form generated) can use a generic statement to update the line and include 'id of the game {its original value} =' as part of the update. It is always updated the parent key even if it does not change, and he closed the child table.
(b) you have an example where 99.9999% of one of the columns has a single value and the other 0.0001% of the data is shared between the remaining values of 9 parent - this could be useful as a path index even if you do not need to protect against the problem of blocking foreign. In this case you need to constrauct a histogram on the column for that the optimizer can see the extreme data distribution.
Options
(a) If you are confident that the parent tables never see no DML so you can move them to a separate tablespace that you do read-only (older versions of Oracle) or make read-only tables (12 c)
(b) you can disable locking on the child table - it always helps to have implicit mode 2 and mode 3 locks (which will not appear in the lock of v$), but stop a parent update to acquire mode 4 it would be necessary for the child if something tries to update or delete the parent key. There are however some behavior buggy serious around this area, and I don't know if it was fixed yet: https://jonathanlewis.wordpress.com/2010/02/15/lock-horror/
ADDENDUM: If almost all the data of a column contains the same, then you can consider using a null to represent this value. Otherwise, you could play with index based on a function (changing the code of the application accordingly) to create an index that contains only the values 'rare' rather than having an index that held an entry for each row in a table. This approach would also avoid the need for a histogram. Something like the folllowing (although the example is not a perfect match for your requirement): https://jonathanlewis.wordpress.com/2014/04/02/tweaking/
Concerning
Jonathan Lewis
-
Determine the maximum use of the processor for a virtual computer in the custom user interface
I want to determine the maximum use of the processor for a virtual computer in the custom user interface. How can I do this?
If I use a supermetric, there is no kind of attribute under CPU called "maximum use.
Certainly, you get points for a long question! Although to be fair, it's probably my fault to feed you so much information to digest at once.
1. I would say you can do two ways visually. Use the operations > detail view for 'normal ranges' use the upper limit of the normal range as your typical max. You want an absolute peak, add the metric of a graph or observe that highlight high and low watermarks.
2. There are a lot of ways to display data, but if you want to display a single metric over a period of time, we could use the following widgets [on top of my head]:
Top - N analysis
Weather map
Analysis of distribution of data
Among these, I think of your desire for a "peak". Who you want real value, which eliminates the weather map. Then, I think that the concept of a 'Summit' and what is the best thing, I think that the 95th percentile... then I came with the widget of data distribution. The decision is ultimately yours given your particular use case.
3. you can have it apply to several virtual machines - it's just a widget capable of being an independent provider or receiving widget (metrics, DO NOT choose to select resources). Each resource/metric will add to the widget and you can remove them if you like after it is added. You can certainly all the time you visit... It is date and time standard options you have in all the other widgets chart. With the widget data distribution, you want as much time as possible to get an accurate histogram of the cycles of workload.
4. This is similar to the question above. You can certainly add parameters of individual resource or a DM that summarizes or AVG groups of resources. And as above, the delay is configurable, along with the other graph widgets.
5. it's part of Q4 - you can sumN or avgN up to any number of resources with a SM, then discovers that SM in the widget of data distribution. When I said container, I mean an application, group resource pool... all that acts as a container parent within the vCOps.
6. that's correct, SMs calc using data collected last points... aka single period of time. When you are referring to the longest period, I gave you a few examples of the attributes that are composed of several periods of time which are calculated and created by the adapter for VMware vCenter behvaior. In this case, you have the GVA 15 min CPU 1.5; These specific simple mobile GVA can be specific OR a copy using SMs. Next, you will have the chance is to find a way to distribute what you need through a widget [at that time].
7. the distribution of data is not for export, it is for Visual functions. If you want the data in CSV, just use a typical chart of metrics and export to a csv and calc your own pics, avg, 95th, whatever.
8. This is a bit of a mix of all your questions, put in place.
You are right, if you added those 3 VMs, then calc was the 95th of the AVG. Like Q7, you would not export the data of the distribution of data because the raw data points are not - you do not pass the metric to a metric graphics standard and export via csv.
Take advantage of...
-
Your linux desktop that works well with the fuser unit - is - it?
I don't know anyone who runs linux on Fusion guest is aware that everything in 3D acceleration works (at least in Ubuntu) window of vmware Fusion to unity mode works not by 3D. And that since all popular linux distributions moves to 3D desktop computers we are practically forced to stop or mode full screen.
My question is: someone found a good 2D for linux desktop computer that works with the fuser mode, and is also an up-to-date distribution?
There are a few suggestions on an old net http://communities.VMware.com/message/2139647#2139647 to use With Mate Mint, but who had serious problems for me.
I'm looking for basically two things.
First of all the possibility to use the window of the unit mode.
Second, the possibility of placing several editable launch icons in a home/toolbar etc station in Linux comments so I can open two different documents side by side, very quickly (which was another failure of Mate).
Specifically, I'm eager to open two sets of accounts in Gnucash. This worked wonderfully in Ubuntu 10.04, and while it is tempting to return 10.04 reached EOL in April 2013 - he is also packing a old version of Gnucash that I'm used to using.
(btw a different alternative, using the OSX of Gnucash package: works, but the heartbreaking text is horrible, that is why the desire to run in a Linux VM.) MacPorts/Fink is also out because it takes so long to compile whenever there is an update. Want a binary).
Any suggestions?
Confirmed to work with xubuntu 14.04. Note, you need to install vmware tools and restart the virtual machine for this to work.
-
Table partitioning/indexing strategy
Hello
I have a data warehouse containing medical data. Normally, we develop queries against a small number of patients (e.g. where patient_id < 100) and adjust upward to run on a greater number (usually the entire base of 26 000 patients least some due to exclusion criteria).
The largest table contains about 200 million lines, and I'm working on the question of whether I can change the partitioning and indexing in order to improve the performance of queries.
The table contains 'patient_id', 'visit_id', 'item_id', 'chart_time', 'value' and 'valuenum' column and a variety of other columns that are rarely used. The id id columns are integers, pointrefers to the type of value is saved and value (varchar2) and valuenum (number) contain the data. chart_time is a "timestamp with time zone '.
Currently, there are clues on patient_id, visit_id and item_id and a composite index on (visit_id, itemid). There is no partitioning for the moment.
1. is the current index redundent? that is visit_id, item_id and composite (visit_id, item_id) do I need?
2. we started to run queries of time based for specific patients. that is, we want data for specific items, for a specific set of visits, in the first day. An index on (visit_id, chart_time, item_id) would help with that?
3. the table of patient_id partitioning help? We "never" queries between patient and therefore the data of each patient are independent. The database is running on 2 raid controllers, one for data, one for the index, perhaps it would be better to put half of patients on a single controller, and the other half on the other?
Thank you
Dan ScottHello
1. the index on visit_id sounds redundant as it is the main column in the composite index (visit_id, itemid).
2. added chart_time to the composite index could be useful that the pair of columns (visit_id, item_id) is not quite selective. You must put in place a realistic model of your data distribution, choose some queries that you intend to run often watch their performance. It is not possible to predict performance in function purely thereotical reasoning.
3 bear partitioning functions: maintenance of data (for example truncating, deleting or moving old partitions) and eliminating the irrelevant data in queries (partition size). You imagine you having to truncate, delete, or move a partition that is defined by a range of patient_id? Probably not. Can you imagine the need to restrict your query to a certain range of patient_id? Unlikely. That answers your question.Best regards
Nikolai
{kind=link}
Maybe you are looking for
-
Why my download window opens with each download?
My job requires me to do a lot of downloading of images and other files. But these days, whenever I download something, a download window will appear. I don't mean download on a window (as before), but rather of several windows. So if I were to downl
-
Hello My computer is TouchSmart600 - 1200. I rarely before used the DVD/CD drive. Now it doesn't work at all. It does not read any disk. When I go to computer then select this drive, it says "put in a disc. Regardless of the disc, I put, he neve
-
How to set the orientation of the screen
Hello I don't have the time to support portrait and landscape for my application now... :-( I used the trick, like y = 601 to hide things. (I know the visible property, but for the same reason, do not use it) But I realized that if the playbook turns
-
How can I configure a hardware bypass road in a catalyst 6500 using IDSM2? ... not only a software workaround!
-
Get the current location of the user.
I want to create an application in which the current position of the user should be displayed. Can someone tell me the logic (connection only part) If cannot tell the code...