Search in the journal table
Hello
I'm looking in a logging table (T1)
(a) the early line for each 'name '.
(b) these names without any entry in the table of logging. Possible names are defined in table T2.
I have a solution (see below), but I think that there must be a more adequate.
Any help is appreciated.
Thanks, Hans
Here are the definitions of table;
CREATE TABLE 'T1' ('NAME' VARCHAR2 (20 BYTE) 'INFO', DATE 'LOG_DATE', 'STATUS' VARCHAR2(20 BYTE), VARCHAR2 (20 BYTE));
CREATE TABLE 'T2' (VARCHAR2 (20 BYTE) 'NAME');
And some test values
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values ('A', '0', to_date ('14.12.2015 12:09:51 ',' DD.)) MM YYYY HH24:MI:SS'), ' (INFO A 0');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values ('A', '1', to_date ('14.12.2015 12:10:16 ',' DD.)) MM YYYY HH24:MI:SS'), ' (INFO A 1');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values (' B ', 1', to_date ('14.12.2015 12:10:38 ',' DD.) ") MM YYYY HH24:MI:SS'),'INFO B 1');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values (' B ', ' 0', to_date ('14.12.2015 12:11 ',' DD.) ") MM YYYY HH24:MI:SS'),'INFO B 0');
Insert into T2 (NAME) values ('A');
Insert into T2 (NAME) values ('B');
Insert into T2 (NAME) values ('C');
My solution:
with a (too)
Select t1.name, max (log_date) MaxLogDate from T1 group by name
),
b like)
Select t1.name, t1.status, t1.log_date, t1.info
Of
a, t1
where
T1. Name = B.SID and
T1.log_date = a.MaxLogDate)
Select t2.name, b.log_date, b.status
b outer join t2 on t2.NAME = b.name right
b.name order;
What gives these results:
| 'NAME '. | "LOG_DATE. | 'STATUS '. | |
| « A » | "14.12.2015 12:10:16. | « 1 » | |
| « B » | "14.12.2015 12:11. | « 0 » | |
| « C » | "" | "" |
using the rank function
Select t2.name, t.log_date, t.status
de)
SELECT t1.name, t1.log_date, t1.status, row_number () over (partition by t1.name t1.log_date desc order) rn
from t1
) t
join right t2 on t2.name = t.nom and t.rn = 1
order of t2.name
Tags: Database
Similar Questions
-
Non riesco a generare I trigger by the journal tables
Buonasera,
utilizzavo tables version 4.1.1 di Data model e riuscivo a generare I trigger by the newspaper, pero utilizzava sempre he nome di table "emp2."
Nelle note della versione 4.1.2 release it era scritto che he bug era stato solved, pero adesso non riesco più a generare I trigger by the journal tables.
You can help?
Grazie
Davide
Hello Davide,.
you are able to run the generation of 'test' as he explained here Oracle SQL Developer Data Modeler 4.1 user - defined DDL generation using transformation scripts
Do you have a location in "preferences > Data Modeler"-"types of default system directory" - If there is a defined directory it can DM puts the script from that directory - scripts are in the file - dr_custom_scripts.xml. "»
If you have not changed the scripts distributed with Data Modeler (or add new ones) so you can copy this file in the directory datamodeler\datamodeler\types of DM 4.1.2 installation to the directory defined in the preferences.
In fact the problem in 4.1.1 DM was in the script itself always putting this 'EMP2' name in the definition of the trigger - line 66 should be modified in order to obtain valid results:
old line 66:
"WE DELETE emp2 for each line \n" +
new line 66:
"WE DELETE" + lname + ' for each line \n"+"
Philippe
-
How to make simple "search" on the object Table or VARRAY?
I do a simple bulk collect into a local table type and need a way to determine whether an item exists in this type of local table inside an if condition. I can't understand the syntax. Here is the code:
DECLARE
type emp_roles is table of the varchar2 (10);
v_emp_roles emp_roles;
BEGIN
-Determine the role of the current employee
Select ef.emp_function_code bulk collect
in v_emp_roles
of emplyee_function ef
where ef.emp_no = 1234;
If 'HOMEMRKT' in (v_emp_roles) then
null;
elsif "IMMIGRAT" then in (v_emp_roles)
null;
"INVENTOR" elsif then in (v_emp_roles)
null;
elsif 'TEMPHOUS' in (v_emp_roles) then
null;
end if;
Any ideas how to proceed?
Thank you'Member ':
DECLARE type emp_roles is table of varchar2(10); v_emp_roles emp_roles; BEGIN select * bulk collect into v_emp_roles from table(sys.ku$_vcnt('IMMIGRAT','TEMPHOUS')); if 'HOMEMRKT' member of (v_emp_roles) then dbms_output.put_line('HOMEMRKT'); end if; if 'IMMIGRAT' member of (v_emp_roles) then dbms_output.put_line('IMMIGRAT'); end if; if 'INVENTOR' member of (v_emp_roles) then dbms_output.put_line('INVENTOR'); end if; if 'TEMPHOUS' member of (v_emp_roles) then dbms_output.put_line('TEMPHOUS'); end if; end;Best regards
Sayan Malakshinov -
Hello
I have a table that contains the following information
RowID Asset Version TYPE
1A 1 345 PPS
B2 2 345 pps
A3 3 345 pps
F4 1 321 ppp
G5 2 321 ppp
H6 333 1 pps
I need a query for the version the most up-to-date assets
The final result after the query should be:
A3 3 345 pps
G5 2 321 ppp
H6 333 1 pps
Help pleaseSELECT asset, MAX (VERSION), TYPE FROM ur_table GROUP BY asset, TYPE -
How does binds to the Dimension Tables.
Hi all
One explains how the ROW_WID of the table dimension and the related column in the fact table is filled with the same values in different mapping?
Consider if we want to develop a new fact and dimension tables, how do I apply for the ROW_WID and the join between the fact and dimension.
Thanks in advance.
Concerning
VishwanathHello
Essentially in BI dims applications all are first populated and each dim table has a column of wid row outside the primary key (datasourceid + integration id) combination. If you open a seeded map and you will see this line wid column is filled using a reusable sequence generator transformation. Then every time u run this mapping the Feds line change...
Now go to the facts... as a normal rule in ETL u run the facts after all the dimensions... If you open any map done planting you can observe all the facts has an associated wid the dims, he joined to... so if a fact joins 3 If stump so there will be 3 Feds associated with each dim. The Feds are again filled with a search on the dimension table and line extraction wid bad ID the Sun. If u get wid of the dimension row in the column of wid the fact... Please let me know if you hv questionsRegarding
VINET -
Search for the nearest value table
IM wondering if its possible to find a 1 d table worth, if it is not found, then find the nearest match. IM using the 'double' data type and I need at least an accuracy of 4 decimal point in the research.
For now, im rounding decimal values to the nearest integers from you, but it is not effective at all. Im getting a lot of unwanted split in the plot. I need to be able to search for the decimal points. I found this function "About Equals.VI" starting from a previous thread. Even that uses the concept of the rounding.
I enclose 3 screws "0.8 & 0.4.VI" are that I created, rounding decimals nearest digit.
The "approximately equal" is the one I found online.
The 3rd is I try to mess with what I can find as close a match.
Y at - it a trick to work around this problem?
Thank you
Eureka
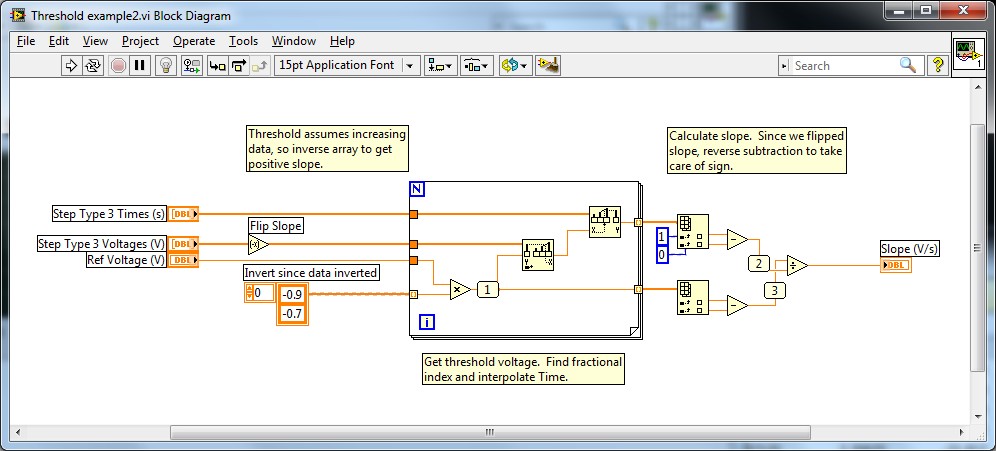
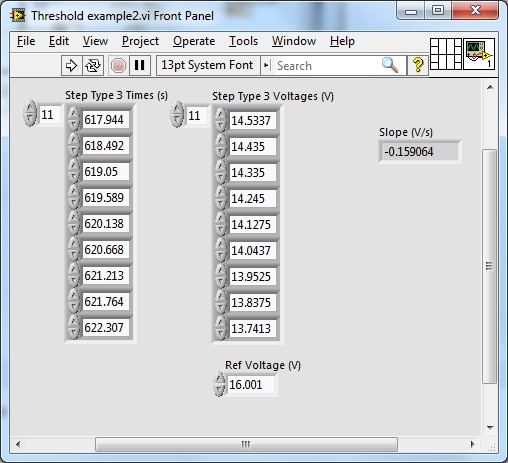
This VI uses the first type of step 3 in your data. Since you said that you can get the data, you can drop the in VI.
At the end where I calculate the slope, you can use a linear adjustment if you have full or professional LabVIEW.
-
View the journal does not display not database tables
Hello experts,
It is perhaps a silly question to some people, but I have a weird situation: so, I ran my obi report online. the data appear to be not correct. So, I went to view journal catch of the statement and execute it in the comic book. However, when I click on view log, I see is the overall, I don't see the 'WITH SAWITHO' where I can copy the statement with alias tables and check the database. I know well as shown log levels. I reloaded the data, stored and forever.
Anyone know what could be the reason why I do not see this statement? Help, please
OK, log level 5 is fine for SQL (the request is recorded from 2).
Do you see the query if you check in nqquery.log?
You say front cover, but what of the BI server cache? This isn't a front cover.
Have you tried clicking on the Refresh button on the top menu right?
At least you see the physical query for other reports?
Your newspaper said anything else? (or it's just empty after the SQL logic?)
Really read every single line to see what is happening, the journal is very talkative, he says everything in general.
-
Search in the af Date field: table does not
Hello
12.1.3 Jdev
In my application, there are 6 pages. 3 of them have table with search and sort active areas. All parts of the table have the date field.
When the page is loaded, the search for the Date field does not work (no popup the calendar will). When all action happens on the page, the search option is missing for the date field.
When the page loads:

When you press on enter in the search field in the Date column:

Interestingly, this is one of those 3 pages has a tabbed region. This problem occurs only in the first tab, same functionality in other tabs work fine.
I have tried to create another project and tried to reproduce the problem. But not able to replicate.
What could be the problem? I don't know what to check?
I tried to create a new page without using the customTemplate and just tried to add not only one table. That also had the same problem.
Let me know if I need to provide any other details.
See you soon
AJ
You can try to remove facets TestDate column filter and see if that makes a difference.
Also try to replace java.sql.Timestamp by oracle.jbo.domain.Timestamp
Dario
-
Overview of the printing table of formulas
Overview of the printing table of formulas
I have a very simple question, you would think.
In the Pages, I added a simple table. Several simple formulas are added to this table. Now, if you select one of these cells that contain a formula, all of the cell that are involved in this formula is colored. See attachment.
No I want to print my full, showing the colors of these formulas. Just check t if everything is included in these formulas. Seems very simple, if I can't find the (characters)? option, I can't find the answer to this question here again...
Does anyone now if and how do?
It would be great!
Thank you, Joep

Hi Joep,
When you print, the selected cells are deselected. The colors will not display.
The only thing I can suggest is to place a screen shot in a document of numbers (Menu > insert > choose...)
In another journal (tab) or any other document and print that.
Kind regards
Ian.
-
Firefox 4 ignoring the property table (< td > < table >)
I'm working on the upgrade of the https://addons.mozilla.org/en-US/firefox/addon/156940/ for Firefox 4 compatibility extension.
Essentially extensions improves the site by adding a few query fields that are locked in the format "table > < td > <. There is no problem up to FF 3.6.9. But at 4 FF, it ignores the < td > < table > properties.
But it works with any questions on the latest versions of chrome and safari
This is because the code is wrong.
You're lucky it works in Firefox 3.6, but Firefox 4.0 is more strict.You try to add items TD to the innerHTML of an another TD element and it does not work.
<td id="navSearchBar" class="navSearchBar">Search</td>
You need to add < table > < / table > around code.
This code should work:
if (lsa[0] == "jp") { searchTxt = "<table><td style=\"font-weight:bold; font-size:13px; padding-right:5px;\"><span style=\"float:left; width:28px;\">" + searchTxt + "</span></td>"; } else { searchTxt = "<table><td style=\"font-weight:bold; font-size:13px; padding-right:5px;\">" + searchTxt + "</td>"; } if (lsa[0] != "ca") { searchTxt += "<td style=\"padding-left:3px;\"><select id=\"p_76\" name=\"p_76\"><option value=''>Any<option value='1'>Prime<option value='1-'>Free</select></td>"; } searchTxt += "<td style=\"padding-left:3px;\"><select id=\"pct-off\" name=\"pct-off\"><option value=''>0-100% <option value='10-'>10% <option value='20-'>20% <option value='30-'>30% <option value='40-'>40% <option value='50-'>50% <option value='60-'>60% <option value='70-'>70% <option value='80-'>80% <option value='90-'>90%</select></td></table>"; searchObj.innerHTML = searchTxt;(corrected the text that got deleted by a previous edition)
-
Hey all,.
I have a really strange behavior here. I'm using LabView 8.5. I open a white VI and try to use the function "initialize the array.
No matter where and how I find (using search functions, or by accessing the 7.x-> table-> table initialize function), when I drag and drop it off at my VI, what I get is "Array Index" instead!
Even when I hover over the icon table inside the palette is initialized, with aid switched on (Ctrl + H), what I see is the help page for table of Index. It's as if somehow the index table replaced function Initialize array entirely, with the exception of the simple icon in the palette...
I tried to restart Labview and my computer nothing works.
Someone at - he never experience a similar problem? that means, one different function other than for being created. I have attached a screenshot.
Thank you
-Anne Marie
Thanks for your replies.
My palette is screwed a bit isn't it? Most likely because the installation I chose a bunch of older versions in favor... and I regret it now.
Funny enough, during the search in the functions that it only brings me version 7.x of functions of table etc... but I can manually find the standard in my palette, and of course, version 8.5 standard functions seem to work...
I need to finally do an install of cean, but for now, it's all good!
Thank you
Anne Marie
-
Using data from the control table
Hello
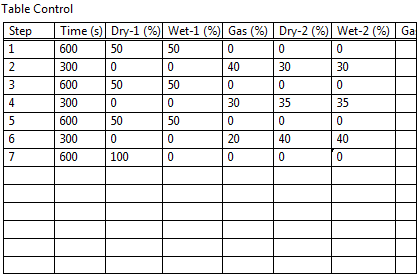
I would like to use the data entered in a table to automate volume/sequence of airflow for a test Chamber. As shown in the screenshot of control table, the first column indicates the number of iterations by elements of array in a series of tests and the second data column specifies the length of each line sequence. Entries in the other columns are specific to different valves and specify values set required in the flow meter.
I guess my question is how can I index/assign each column of the table such that the data to exploit the respective valves are obtained in subsequent iterations all acquire simultaneously with data from other components in the order? While I recognize that the solution may be very simple, I searched on through various examples and messages on the tables and the tables without knocking on a solution. The attached .vi allows me to be a part of the series of tests.
Best regards
Callisto
Hi Callisto,
If I understand your question then the solution is actually quite simple. The important point to keep in min is the fact that the Table control can actually be treated as an array of string. You can then use all the traditional table manipulation tools and techniques to manipulate your data as you wish. For example, use the Array Index function to retrieve specific columns and then if you want to spend the individual elements in a column in a loop, wire the table until the loop and ensure that indexing is enabled. If you then want to use these data elements to control your test application, you can convert a portion of the resulting string in more useful to digital.
All these concepts are illustrated in the attached VI. I hope this helps, but let me know if you have any other questions.
Best regards
Christian Hartshorne
NIUK
-
Poor search performance clustered with table of singles (100 k)
In a data entry project, I created a data type to store regular data. I have a cluster (see photo) which consists of a name, StringData, Numericaldata and ArrayOfSinglesData (predefined 100points k). Thus, every piece of data can be a scalar string, scalar number or an array of numbers.
I then do a picture of this for all of my variables, maybe 150 or more.
Works well, but the performance when adding new data (search for the exact name) is pretty poor. Very high CPU and many even page faults for the slow connection like 1 to 10 times per second.
The entrance to the data add method is an array of (stringname, DataString). So for each new data I loop over all the variables, find the one with the correct name string and add new data (replce the scalar chain and the number, add to arrayOfSingles).
Given that I have 150 variable, as I thought a linear search should be ok, but probably the program moves also around 100 k singles for each comparison, or it's my idea at least.
Can you suggest which is a good thing to do to improve performance?
I added a search binary smarter, but it was necessary to sort variables, and since I have two names for each variable (called internal and external) that I use when you add, it helped only for half of the research.
If I find the time I would like to divide the cluster so that all ArrayOfSingles are separated, but maybe you can tell me immediately if it is useful?
(Labview, 2012sp1)
Like Gerds link watch I suppose you're looping in the table looking for your name?
I just tested, and using DVR to extract only the ID and grabbing then a single element are fast enough. I will attach my test so you can try it for yourself.
/Y
-
What would the most effective way in labview to explore an array of 1 d 0 and 1 and store indexes side 1 is as a new line in a 2d array? For example, I have an array of 0 0 0 0 1 1 1 0 1 1 0, resulting 2d table will look like this:
4 5 6
8 9
where these numbers represent the index of the adjacent 1.
Help with this is appreciated.
A few problems.
Change your meter and line numbering of dual representation, I32 or another type of integer. This is probably why you stuck in a loop of the search for zero. Rounding errors in double can lead to inequalities between the numbers you might otherwise consider the same thing.
You have localitite. You have a condition of critical competition for the number of lines in the real case of the structure of the case. You want the number of rows, incremented by 1, or at the first 2 - D array index page? As it is now, there is no control over which no comes first. Eliminate all local variables. Replace them with wires and start using shift registers to manage values between iterations of the loop.
Another problem is your loop stops when your account equals the number of items in the table. Your count begins as zero. It seems that the number is incremented at each iteration of the loop. Finally, your account will equal the number of items in the table and the loop exits. But all the other codes in this iteration will still occur. If you have a table of 5 elements, your indices range from 0 to 4. But your account is now 5. The loop stops when the iteration has been completed, but now you are trying to index the element 5 (which doesn't exist) and also item 6 (5 + 1) that does not also exist. In fact, you will have the problem in the previous iteration because there is no element 5 (4 + 1).
Another problem is the way in which you are using insert into the table. If you start with an empty table and try to insert into a table in a different row or column outside 0, you get nothing. Or if you have 4 lines and you try to insert in line 5 or higher, nothing is added. Insertion in the table is the wrong function to use probably 95% of the time. You should use table to build.
Why do you have a business structure in the false case puts a real, and in the real deal puts a fake? It's a Rube Goldberg. It doesn't cause a problem, but it's just useless code. Just wire the comparison to stop and put on a NOT operator. If you change the status of the loop continues if it is true, you can eliminate the not! as well. In addition, rather than add a 1 to a number, there are a + 1 increment operator in the digital palette. (A little less code means a little cleaner diagram). In addition, you don't need two separate functions of the Index table. You can use one and resize it down. If wire you the County in the top, the bottom (that you just added in developing the service) will give you the index after counting.)
I don't have your global variable. (Where are the data coming from?) VI another?) If you can replace this world with a constant matrix with some typical data, it would give us something to work with.
-
DBwalker reports [invalid time format] in the Configuration table
Unit 4.0.5. Clean install with restoration of DIRT. DBwalker was executed before restoring with 0 error, now it reports the following:
From the controls of general system *.
Check the LastModifiedTime column for all of the entries in the Configuration table
problem of format of Date/time of 0: (Error) in the Configuration table:-2147467259 (format of time not valid [Microsoft] [ODBC SQL Server driver]). See the LastTimeModified column for all entries in the Configuration table for the correct format.
***********
You will see other reports of this here - the stamp of date/time Configuration table is only used for failover (i.e. If systems can keep these parameters in harmony in all of boxes). If you use integrated security, and get this, then there is a problem. If you do not use this security, then there is nothing to worry about here.
You can manually update the LastModifiedTime column for the rows in this table if you want to go further without worrying about the error. See the release notes for this bug for more details:
http://www.Cisco.com/cgi-bin/support/Bugtool/onebug.pl?BugID=CSCef60341&submit=search



Maybe you are looking for
-
How can I regester for mozilla support?
Asking the above question, it gave me a chance to enroll. So, I'm fixed. But other FF33 news may have the same problem. It looks like a control that is not the opportunity to register with the log in page or somewhere on the home page. When I clicked
-
I want to put my whole music library in the cloud and let iTunes go here so I can free up hard drive space. Is this possible?
-
Are the system OneLink + Docking for ThinkPad P40 Yoga able to load the computer as you can with the station Dock for ThinkPad S540?
-
Hello I use sbrio 9607. I connect the NI 9234 module to sbrio by jury NI 9697 CTMR which has two slots. The problem is I don't need a second slot and slot increases the size and volume. (1) is there a version of unique slot 9697 OR? (2) is there a wa
-
Server Performance Advisor 3.1 booting is not with the target server
I had an installation of SQL Express 2014 SP1 on a server completely updated 2012 R2 where I installed the 3.1 SPA and I can't seem to connect to my AD server. When installing in my LAB, I got it work without problems, but in the production environme