SPARQL query using varying paths
HelloI have a chart in Oracle I like to do query using Jena 2.6.4 and OracleJenaAdaptor 11.2.0.3
IND:123: ind:124 hasA
IND:124: ind:125 Hilmi
IND:125: hasC ind:126
IND:123: coward ind:127
Is there a way to build a sparql query to return all the ind: without 'hard-conding"the full property name? Something in these lines (note that this query doesn't really work).
Select *.
where {ind:123 (: has *) +? x}
Thank you.
Hello
If you have created a virtual model before, then will do the following. Note that I am assuming that the virtual model is created based on two 'my_asset', 'my_model' models and modules OWLPRIME.
Piece attached attachment = Attachment.createInstance (new String() {"my_model"},
(New String() {"OWLPRIME"}, InferenceMaintenanceMode.UPDATE_WHEN_COMMIT, QueryOptions.ALLOW_QUERY_INVALID_AND_DUP).
Chart GraphOracleSem = new GraphOracleSem (oracle, "my_asset", room attached, true);
graph.performInference ();
Thank you
Zhe
Tags: Database
Similar Questions
-
Why a parallel query use direct path read?
I think because the cache must Access pads, lock and lock on buffer block if parallel query do not reading of the direct path, parallel queries will be affected by the serialization as the latch and oracle .so lock mechanism choose direct path read to avoid what he.
that someone has a good idea?
Published by: Jeremiah on December 8, 2008 07:52Jinyu wrote:
I think because the cache must Access pads, lock and lock on buffer block if parallel query do not reading of the direct path, parallel queries will be affected by the serialization as the latch and oracle .so lock mechanism choose direct path read to avoid what he.Jinyu,
actually, Yes, I think that's it. The parallel query is designed to scan very much, because the load of communication between processes and maintenance/commissioning the parallel slave makes inefficient operation for small segments.
So I guess that the assumption is that the segment to analyze is probably very large, the fraction of the blocks in the buffer cache is very low compared to the blocks to scan and so the fresh reduction General read directly blocks without moving through all the questions of serialization of the buffer cache should prevail on the issue of blocks "unbuffered" and save the buffer for objects cache more benefit from development caching.
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/ -
XPath query using DONKEY with AIR3.9 for iOS app
We build an app for iOS using AIR 3.9 where we load and parse the xml document so that we can read the path of images and download stuff on iOS device. To resolve this issue, we found a solution using XCode via DONKEY where query using XPath such as 'PerformXPathQuery', 'PerformXMLXPathQuery', 'xmlReadMemory"etc.. The code runs and when build Simulator itself on mac computer. But when we're packing DONKEY with AIR 3.9, it gives the error that says that: -.
Error occurred during the application of packaging:
For architecture armv7 httpd Undefined symbols:
"_xmlReadMemory", referenced from:
_PerformXMLXPathQuery in libnet.example.download.a (ExampleLib.o)
LD: symbol not found armv7 architecture
Compilation failed during execution: ld64
I tried connecting binary with libraries such as 'libxml2.dylib', 'libxml2.2.dylib' and libz.dylib + added header files libXML to the header in the build properties search path, but had no help.
our AIR 3.9 platform xml looks like: -.
" < platform xmlns =" http://ns.Adobe.com/air/extension/3.9 ">
< > 4.0.0 sdkVersion < / sdkVersion >
< linkerOptions >
< option > - ios_version_min 4.2 < / option >
< option > - frame UIKit < / option >
< option > - framework Foundation < / option >
< option > - framework CoreText < / option >
< / linkerOptions >
< / platform >
can anyone suggest where we are going wrong!
Thanks in advance
Found the solution, it was missing the framework connects to the xPath library in platform.xml
follow the instuctions from the link below: -.
http://forums.Adobe.com/thread/1037904
Thanks to the adobe team
-
How to use the path generated by a star to guide the robot to move?
I now know how to use a star planning on Voronoi path and I can run this program successfully. \
However, my problem now is how I can use the path data (generated by the planning algorithm * path) to guide the robot rolling along this path? Well, I guess I can get a set of points (denoted by x and there contact information) of the path and use those points to guide the robot?
can someone please help?
Thank you very much
You must only post the question once.
-
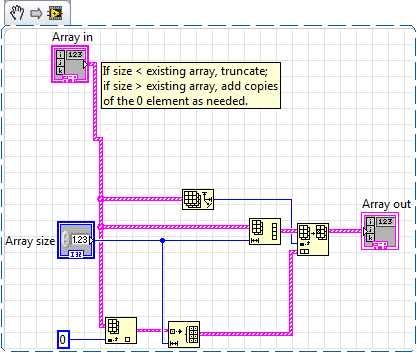
Using variants to adjust an array of clusters by program
I try to use variants to build a polymorphous VI to replace four (at time of writing) separate subVIs that are essentially identical, except for the base type of the array. Each takes in an array of 1 d of the bunches and it resizes with the following code:
Looking through my reference book, I found the non-listed (in the palette) VariantDataType directory (* \vi.lib\Utility\VariantDataType) and have tried to use a combination of them to do the following:
1. take an array of variant-isee cluster in.
2 convert the variant by program in table cluster, based on the information coded in the Variant.
3 perform the operation of resizing table as shown above.
4 convert the output into a Variant array and the power indicator.
Attached are the two VI and a group of example commands I use. I'm running out of ideas; any tips?
With the help of LabVIEW 2009.
In fact, I found an even better method. You go to file > new, make a polymorphic VI and load instances of the various similar screws into the Poly VI.
Here is the final result.
-
Windows 7 won't remember the last used file path
So to this question, take the Gmail. If you enter an email and want to attach a file, you click on join and Win 7 by default on the desktop, from which you access the folder you need. It's very good... for the first time. However, while she is supposed to be smart enough to be REMEMBER this location next time. NOPE. Win 7 keeps by default on the desktop, even if you attach a file and then IMMEDIATELY try to attach to another.
Is there a solution for this?
* original title - Windows 7 won't remember the last used file path. Very frustrating *.
It is not a particular problem with Windows 7, but the Internet browser. We remember is no longer default path of Internet Explorer with the introduction of sandboxing Protected Mode. Even Windows XP, using the results of this sandbox layout in this behavior.
Your temporary solution is to use another browser, such as Google Chrome. In the meantime, your comments that you want to have the ability to remember the last folder used in the browser is important in the future development of the browser. Leave your comments here, please: https://connect.microsoft.com/site/sitehome.aspx?SiteID=136 -
How to insert photoshop image with a work/clipping path in illustrator using the path?
How to place an image in Illustrator using the clipping/work path created in Photoshop?
I have a .jpg of an object on a background image. This image has a clipping path that écrêtera the background of the image. I could clip the outside background (in Photoshop) and save the image as a file .psd with a transparent background, and then insert the .psd file in Illustrator... it's easy. What I can't understand is to place the image (bottom) .jpg and use clipping path Photoshop be clipping path in Illustrator. In this way, I can take this clipping path and use it as a layer of gloss spot for production. I work on a Macbook Pro and CC2014. Thank you.
But you can export the path separately in Illustrator, then he get married to the JPEG placed as a clipping mask.
In traces of Photoshop Panel, target the path, and then choose file > export > traces to Illustrator...
He'll write a .ai file. Open and select all (it's a quick and easy way to 'see' the path because Photoshop it will export with no border or background, leaving mostly 'invisible' on the artboard Illustrator).
Then you can copy it to the collage at the top of your JPEG placed. Position them as you like, select this option and the JPEG format, then choose object > clipping mask > make...
-
Query using progressive relaxation take more time for execution
HI gurus,
I'm creating a query using the context and the progressive relaxation index
I had started using progressive relaxation after obtaining the forum entries {: identifier of the thread = 2333942}. With the help of progressive relaxation takes more than 7 seconds for each request. Is there a way we can improve the query performance?
create table test_sh4 (text1 clob,text2 clob,text3 clob); begin ctx_ddl.create_preference ('nd_mcd', 'multi_column_datastore'); ctx_ddl.set_attribute ('nd_mcd', 'columns', 'replace (text1, '' '', '''') nd1, text1 text1, replace (text2, '' '', '''') nd2, text2 text2'); ctx_ddl.create_preference ('test_lex1', 'basic_lexer'); ctx_ddl.set_attribute ('test_lex1', 'whitespace', '/\|-_+'); ctx_ddl.create_section_group ('test_sg', 'basic_section_group'); ctx_ddl.add_field_section ('test_sg', 'text1', 'text1', true); ctx_ddl.add_field_section ('test_sg', 'nd1', 'nd1', true); ctx_ddl.add_field_section ('test_sg', 'text2', 'text2', true); ctx_ddl.add_field_section ('test_sg', 'nd2', 'nd2', true); end; create index IX_test_sh4 on test_sh4 (text3) indextype is ctxsys.context parameters ('datastore nd_mcd lexer test_lex1 section group test_sg') ; alter index IX_test_sh4 REBUILD PARAMETERS ('REPLACE SYNC (ON COMMIT)') ;-- sync index on every commit. SELECT SCORE(1) score,t.* FROM test_sh4 t WHERE CONTAINS (text3, ' <query> <textquery> <progression> <seq>{GIFT GRILL STAPLES CARD} within text1</seq> <seq>{GIFTGRILLSTAPLESCARD} within nd1</seq> <seq>{GIFT GRILL STAPLES CARD} within text2</seq> <seq>{GIFTGRILLSTAPLESCARD} within nd2</seq> <seq>((%GIFT% and %GRILL% and %STAPLES% and %CARD%)) within text1</seq> <seq>((%GIFT% and %GRILL% and %STAPLES% and %CARD%)) within text2</seq> <seq>((%GIFT% and %GRILL% and %STAPLES%) or (%GRILL% and %STAPLES% and %CARD%) or (%GIFT% and %STAPLES% and %CARD%) or (%GIFT% and %GRILL% and %CARD%)) within text1</seq> <seq>((%GIFT% and %GRILL% and %STAPLES%) or (%GRILL% and %STAPLES% and %CARD%) or (%GIFT% and %STAPLES% and %CARD%) or (%GIFT% and %GRILL% and %CARD%)) within text2</seq> <seq>((%STAPLES% and %CARD%) or (%GIFT% and %GRILL%) or (%GRILL% and %CARD%) or (%GIFT% and %CARD%) or (%GIFT% and %STAPLES%) or (%GRILL% and %STAPLES%)) within text1</seq> <seq>((%STAPLES% and %CARD%) or (%GIFT% and %GRILL%) or (%GRILL% and %CARD%) or (%GIFT% and %CARD%) or (%GIFT% and %STAPLES%) or (%GRILL% and %STAPLES%)) within text2</seq> <seq>((%GIFT% , %GRILL% , %STAPLES% , %CARD%)) within text1</seq> <seq>((%GIFT% , %GRILL% , %STAPLES% , %CARD%)) within text2</seq> <seq>((!GIFT and !GRILL and !STAPLES and !CARD)) within text1</seq> <seq>((!GIFT and !GRILL and !STAPLES and !CARD)) within text2</seq> <seq>((!GIFT and !GRILL and !STAPLES) or (!GRILL and !STAPLES and !CARD) or (!GIFT and !STAPLES and !CARD) or (!GIFT and !GRILL and !CARD)) within text1</seq> <seq>((!GIFT and !GRILL and !STAPLES) or (!GRILL and !STAPLES and !CARD) or (!GIFT and !STAPLES and !CARD) or (!GIFT and !GRILL and !CARD)) within text2</seq> <seq>((!STAPLES and !CARD) or (!GIFT and !GRILL) or (!GRILL and !CARD) or (!GIFT and !CARD) or (!GIFT and !STAPLES) or (!GRILL and !STAPLES)) within text1</seq> <seq>((!STAPLES and !CARD) or (!GIFT and !GRILL) or (!GRILL and !CARD) or (!GIFT and !CARD) or (!GIFT and !STAPLES) or (!GRILL and !STAPLES)) within text2</seq> <seq>((!GIFT , !GRILL , !STAPLES , !CARD)) within text1</seq> <seq>((!GIFT , !GRILL , !STAPLES , !CARD)) within text2</seq> <seq>((?GIFT and ?GRILL and ?STAPLES and ?CARD)) within text1</seq> <seq>((?GIFT and ?GRILL and ?STAPLES and ?CARD)) within text2</seq> <seq>((?GIFT and ?GRILL and ?STAPLES) or (?GRILL and ?STAPLES and ?CARD) or (?GIFT and ?STAPLES and ?CARD) or (?GIFT and ?GRILL and ?CARD)) within text1</seq> <seq>((?GIFT and ?GRILL and ?STAPLES) or (?GRILL and ?STAPLES and ?CARD) or (?GIFT and ?STAPLES and ?CARD) or (?GIFT and ?GRILL and ?CARD)) within text2</seq> <seq>((?STAPLES and ?CARD) or (?GIFT and ?GRILL) or (?GRILL and ?CARD) or (?GIFT and ?CARD) or (?GIFT and ?STAPLES) or (?GRILL and ?STAPLES)) within text1</seq> <seq>((?STAPLES and ?CARD) or (?GIFT and ?GRILL) or (?GRILL and ?CARD) or (?GIFT and ?CARD) or (?GIFT and ?STAPLES) or (?GRILL and ?STAPLES)) within text2</seq> <seq>((?GIFT , ?GRILL , ?STAPLES , ?CARD)) within text1</seq> <seq>((?GIFT , ?GRILL , ?STAPLES , ?CARD)) within text2</seq> </progression> </textquery> <score datatype="FLOAT" algorithm="default"/> </query>',1) >0 ORDER BY score(1) DESCProgressive relaxation works best when you select only a limited number of lines. If you retrieve ALL the rows that satisfy the query, then every step of easing should run without worrying.
If you collect - say - the first 10 results, then if the first step in the relaxation gives 10 results so there is no need to execute the next step (actually, due to the internal buffering, which won't be exactly true but he is theoretically correct).
The easiest way to proceed is to reformulate the query in the form
SELECT * FROM)
(Score select (1) SCORE, t.* FROM test_sh4 t WHERE CONTAINS (Text3, '))
...
)
WHERE ROWNUM<=>You have discovered that wildcards don't work too well, unless you use SUBSTRING_INDEX. I encourage you to avoid completely if possible, or push down much lower in the progressive relaxation. Usually, GIFT % is a useful term (matches GIFTS, GIFTED, etc.), DON % is generally more effective.
There are a lot of steps in your progressive relaxation. It you want to reduce the number of steps, you can change:
((GIFT and percent of the GRID and STAPLES % and CARD %)) in Text1
((GIFT and percent of the GRID and STAPLES % and CARD %)) in Text2 TO
((CADEAU % et % de la GRILLE et AGRAFES % et CARTE %) * 2) within Text1 ACCUM ((GIFT and percent of the GRID and STAPLES % and CARD %)) in Text2 I don't know if it would have performance benefits - but it is worth trying to see.
-
How do you use relative paths in ColdFusion?
I'm having a problem that I can not wrap my head around. I have 4 sites all reside under C:\ColdFusion9\wwwroot\websites\. Unfortunately, when I use relative paths, he always navigates to wwwroot instead of from this record Web sites. I want to make sure I can use relative paths which are always calculated in the folder root of Web sites instead of the ColdFusion wwwroot folder.
I had a temporary difficulty just to create a mapping in the CF Administartor. Although, this became a problem because I had to change it whenever I worked on another Web site. In addition, it would work properly if I used a relative as path (/ documents). Instead, it only works if I did a relative as path (. / documents).
Can someone help me solve this problem? I spent so much time to try things it's not even funny.
I'm using the CF9 Developer Edition with Dreamweaver CS4.
CF built-in web server only supports a virtual server for each instance of CF, so you should change it whenever you want to work on a separate site, or create a separate instance of CF using the Instance Manager in CF administrator You won't have a Instance Manager available, given that you have chosen the 'standalone' CF during installation version. If you have reinstalled CF to use the JRun multiserver option, you can install multiple instances of CF and each would have a port separated (8300, 8301, etc.). However, consuming also considerably more resources on your computer.
The best solution for this is usually to install an external web server, IIS or Apache and use it with your single instance see IIS is a component of Windows, so the version of IIS, you can use is limited by the version of Windows you are using. If you do not have Windows XP, you will be able to use IIS to run several virtual servers. Apache won't work regardless of your OS, but can be a little more difficult to set up.
Dave Watts, CTO, Fig Leaf Software
-
Hierarchical Oracle query help needed - path between the crux of two brothers and sisters
I want to find the path between two nodes of oracle hierarchical Table.
Consider the following case-
NodeId - ParentId
=============
1 > > > > > > 0
2 > > > > > > 1
3 > > > > > > 2
4 > > > > > > 3
5 > > > > > > 0
6 > > > > > > 5
Here I want to query the database table that if there is a path between nodes 3 and 5?
The previous query you provided work upwards to the root node.
Here is my expected result, 3-> 2-> 1-> 0-> 5
Yet once if I have a query in the table to get the path between 1 and 3, I want to get out of the way - next
1-> 2-> 3
Therefore, the query works in both cases. Where ADI root can act as an intermediate or no node.
Can you please guide me how I can get it?
Thank you.Hello
user13276471 wrote:
I want to find the path between two nodes of oracle hierarchical Table.Consider the following case-
NodeId - ParentId
=============
1 >>>>>> 0
2 >>>>>> 1
3 >>>>>> 2
4 >>>>>> 3
5 >>>>>> 0
6 >>>>>> 5
Here I want to query the database table that if there is a path between nodes 3 and 5?
The previous queryWhat application is this? If you're referering to another thread, then post a link, such as {message identifier: = 10769125}
you provided work upwards to the root node.
Here is my expected result, 3--> 2--> 1--> 0--> 5
Yet once if I have a query in the table to get the path between 1 and 3, I want to get out of the way - next
1--> 2--> 3Therefore, the query works in both cases. Where ADI root can act as an intermediate or no node.
Can you please guide me how I can get it?
I think you want something like this:
WITH bottom_up_from_src AS ( SELECT nodeid , parentid FROM table_x START WITH nodeid = :src_nodeid CONNECT BY nodeid = PRIOR parentid ) , bottom_up_from_dst AS ( SELECT * FROM bottom_up_from_src UNION ALL SELECT parentid AS nodeid , nodeid AS parentid FROM table_x WHERE nodeid NOT IN ( SELECT nodeid FROM bottom_up_from_src ) START WITH nodeid = :dst_nodeid CONNECT BY nodeid = PRIOR parentid ) SELECT :src_nodeid || SYS_CONNECT_BY_PATH (parentid, '-->') AS display_path FROM bottom_up_from_dst WHERE parentid = :dst_nodeid START WITH nodeid = :src_nodeid CONNECT BY nodeid = PRIOR parentid ;This will show how you can get it from: src_nodeid at dst_nodeid, moving to the top or to the bottom of a hierarchy at a time step. This will work regardless of the fact that
- : src_nodeid is the ancestor of the: dst_nodeid, or
- : src_nodeid is a descendant of: dst_nodeid, or
- both: src_nodeid and: dst_nodeid are the descendants of another node (e.g. 0).
- : src_nodeid is the ancestor of the: dst_nodeid, or
I hope that answers your question.
If not, post a small example data (CREATE TABLE and only relevant columns, INSERT statements) and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data.
Always say what version of Oracle you are using (for example, 11.2.0.2.0). It is always important, but particularly so with CONNECT BY queries, because each version since Oracle 7 had significant improvements in this area.
See the FAQ forum {message identifier: = 9360002}
Problem with SaveAs function using random paths.
The installation program:
Part 1) I have a script to the folder level that allows me to exercise a SaveAs function within forms. I'm doing this as a way to save the document quietly in the background. The effect is that the file is replaced with a copy of itself. The script is:
var mySaveAs = app.trustedFunction (function (oDoc, cPath, cFlName)
{
app.beginPriv ();
cPath = cPath.replace(/([^\/])$ /, ' $1 / ');
try {}
oDoc.saveAs (cPath + cFlName);
} catch (e) {}
App.Alert ("error during save it");
}
app.endPriv ();
});
Part 2) of my documents, I have to check by calling the function below:
function runSave()
{if (typeof (mySaveAs) == 'function') {}
var pathArray = this.path.split("/"); "
var myFileName = pathArray [pathArray.length - 1];
cPath var = this.path.slice(0,myFileName);
mySaveAs (this, cPath, myFileName);
} else {}
App.Alert ("Missing Save Function\n" + "Please contact forms administrator");
}
}
Part 3) I have several large forms that use automatic recording to call save work according to a time interval of 5 minutes, using:
app.setInterval (runSave (), 300000);
The problem:
Part 1) automatic backup function works very well and it works silently in the background. However, I started having problems when I open two forms at the same time. If, for example, I have a form of an open folder and open a form from a second folder, the save feature will sometimes save the active document in its original folder (as expected, crashing and creating an automatic registration) or sometimes save to original folder of the second document. This leaves me a copy update (automatic check) of the document in the right folder, and a copy not updated in the original folder. This seems to vary on what document I opened finally or document that is currently active. Although I can't find the right combination.
It's like thinking what is to confuse the "this.path.
Part 2) worse, if two documents have the same name, as is often the case with these forms, any incorrect saving deposit causes a crash of the second document and data loss.
Part 3) makes it maddening, as sometimes happens when no record or the second second document is open. Instead, damaging it saves the active document in a recently viewed folder. For example, I'm going to open a local folder and open a Word doc, close the file and the doc, go to another folder in a different root (a folder in network), open the form and automatically saves it on the local computer in the folder with the Word doc. So now not only do I have a copy not updated in my folder, I have no idea where the updated copy was actually saved to until I met some time later.
Part 4) once again, worse still, the previously viewed folder could happen which contains a document with the same name, and that the document is crushed by the automatic backup. I have no idea that the form was crushed until I sometimes open a little later and see that it contains a completely different form data.
What is happening and how it stop?
Adobe Acrobat X Pro on a PC.
The code for this tutorial is unfortunately wasn't working, I discovered recently.
This is my own personal code for a trust saveAs method. Note that it takes 2 parameters, not 3.
safeSaveAs = {app.trustPropagatorFunction (function (doc, vPath)}
app.beginPriv ();
doc.saveAs({cPath:vPath});)
app.endPriv ();
});
myTrustedSaveAs = {app.trustedFunction (function (doc, vPath)}
app.beginPriv ();
safeSaveAs (doc, vPath);
app.endPriv ();
});
You call it like this:
myTrustedSaveAs (this, "/ c/temp/test.pdf");
Using relative path to file/ftp adapter
Hi allHow to have a relative path for the file / ftp adapter operation in/out?
Example: Consider $ORA_HOME = / home/oracle-> this environment variable can be different on different machines
I want to drop a file in $ORA_HOME/Folder1/Folder2 (or query to a file).
< partnerLinkBinding name = "FTP" >
< property name = "wsdlLocation" > FTP.wsdl < / property >
< property name = 'out_dir' type = "LogicalDirectory" >what I write here? < / property >
< property name = "retryInterval" > 60 < / property >
< / partnerLinkBinding >
If I can't configure this in the section "links" partner or agent link activation, otherwise, how to achieve this?
I use version 10.1.3. *.
Thanks in advance.
Roshan.
You can achieve by using the deployment scripts if the directory evolves based on the environment
If you want to change running you can use the properties of jca to set using the variables during execution.
Kind regards
Ajay
query for the path of the hierarchy of the child to the parent for a child key given by the user
CREATE TABLE EMP_ID
(
HEAD_ID NUMBER(4),
TAIL_ID NUMBER(4),
NAME VARCHAR2(20 )
)
Insert into EMP_ID Values (1011, 1008, 'C11');
Insert into EMP_ID Values (1008, 1003, 'C8');
Insert into EMP_ID Values (1012, 1003, 'C12');
Insert into EMP_ID Values (1020, 1003, 'C20');
Insert into EMP_ID Values (1025, 1003, 'C25');
Insert into EMP_ID Values (1015, 1012, 'C15');
Insert into EMP_ID Values (1012, 1005, 'C12');
Insert into EMP_ID Values (1005, 1017, 'C5');
COMMIT;If choose the head_id as 1012 and 1017 as tail_id
It should cross the path shaped tail to print the path as shown below
c12/c5/c17/c12Here is the hierarchy as shown below
1015
1012
1005
1017Rede,
Is that what you want?
CREATE TABLE EMP_ID
(
HEAD_ID NUMBER(4),
TAIL_ID NUMBER(4),
NAME VARCHAR2(20 )
);
Insert into EMP_ID Values (1011, 1008, 'C11');
Insert into EMP_ID Values (1008, 1003, 'C8');
Insert into EMP_ID Values (1012, 1003, 'C12');
Insert into EMP_ID Values (1020, 1003, 'C20');
Insert into EMP_ID Values (1025, 1003, 'C25');
Insert into EMP_ID Values (1015, 1012, 'C15');
Insert into EMP_ID Values (1012, 1005, 'C12');
Insert into EMP_ID Values (1005, 1017, 'C5');
Insert into EMP_ID Values (1017, 1012, 'C17'); ---- ==== This was missing in your setup example
COMMIT;
QUERY and OUTPUT
SELECT *
FROM (
select
connect_by_iscycle as CYC
,dt.head_id
,dt.tail_id
,sys_connect_by_path
( dt.name
,'/'
) AS EMP_PATH
from emp_id dt
start with dt.head_id = 1012
connect by NOCYCLE dt.head_id= prior dt.tail_id)
;
CYC HEAD_ID TAIL_ID EMP_PATH
0 1012 1003 /C12
0 1012 1005 /C12
0 1005 1017 /C12/C5
1 1017 1012 /C12/C5/C17
0 1012 1003 /C12/C5/C17/C12
If you want just the printed path
SELECT *
FROM (
select
max(sys_connect_by_path
( dt.name
,'/'
)) AS EMP_PATH
from emp_id dt
start with dt.head_id = 1012
connect by NOCYCLE dt.head_id= prior dt.tail_id)
;
/C12/C5/C17/C12
pre
Sudhakar B.
Reg: Hierarchical query (using connection by)
Hi allI got the result with the hierarchical query in the form:
* / qxxh *.
* / qxxh/jxobcbg *.
* / qxxh/jxobcbg/n00wcp4 *.
* / qxxh/jxobcbg/n00wcp4 / 000263 x *.
* / qxxh/jxobcbg/n00wcp4 / x 000263 / p0263 *.
* / qxxh/jxxocbg *.
* / qxxh/jxxocbg/n00voc1 *.
* / qxxh/jxxocbg/n00voc1 / x 000589 *.
* / qxxh/jxxocbg/n00voc1 / x 000589 / p0589 *.
* / qxxh/jxuwxxh *.
* / qxxh/jxuwxxh/n00xpxf *.
* / qxxh, jxuwxxh, n00xpxf, m00bxpl *.
* / qxxh/jxuwxxh/n00xpxf/m00bxpl / 000522 x *.
* / qxxh/jxuwxxh/n00xpxf/m00bxpl / 000522 x / p0522 *.
Here, I want to select only the maximum path. Here I used "SYS_CONNECT_BY_PATH.
Please let meknow how to do this?
Thanks in advance.
Published by: udeffcv on December 9, 2009 22:03
udeffcv wrote:
Hi all
I got the result with the hierarchical query in the form:
* / qxxh *.
* / qxxh/jxobcbg *.
* / qxxh/jxobcbg/n00wcp4 *.
* / qxxh/jxobcbg/n00wcp4 / 000263 x *.
* / qxxh/jxobcbg/n00wcp4 / x 000263 / p0263 *.
* / qxxh/jxxocbg *.
* / qxxh/jxxocbg/n00voc1 *.
* / qxxh/jxxocbg/n00voc1 / x 000589 *.
* / qxxh/jxxocbg/n00voc1 / x 000589 / p0589 *.
* / qxxh/jxuwxxh *.
* / qxxh/jxuwxxh/n00xpxf *.
* / qxxh, jxuwxxh, n00xpxf, m00bxpl *.
* / qxxh/jxuwxxh/n00xpxf/m00bxpl / 000522 x *.
* / qxxh/jxuwxxh/n00xpxf/m00bxpl / 000522 x / p0522 *.Here, I want to select only the maximum path. Here I used "SYS_CONNECT_BY_PATH.
Please let meknow how to do this?
Thanks in advance.Published by: udeffcv on December 9, 2009 22:03
What do you mean by maximum path? is this...
* / qxxh/jxobcbg/n00wcp4 / x 000263 / p0263 *.
* / qxxh/jxxocbg/n00voc1 / x 000589 / p0589 *.
* / qxxh/jxuwxxh/n00xpxf/m00bxpl / 000522 x / p0522 *.
is it child nodes?
so, you would like to see
Column nickname... CONNECT_BY_ISLEAF example, you can find it in the link below
http://download.Oracle.com/docs/CD/B14117_01/server.101/b10759/pseudocolumns001.htm#sthref670
Ravi Kumar
Automatically record by using build path
Hey everybody.
I bet there is a simple solution to my problem. But for the life of me I can't find it.
I have this VI which measures pressure. It works brilliantly, but I when I want to record the data of the product VI I specify a file name with a control of the chain, if I did not it pushes me to write. It would not be a problem except for the fact that he must save the data quite often and I can't always stay around the computer during its operation. So I wrote a code that automatically creates a single string (not shown in the picture), but when I join this channel to build the terminal path string that I request writing a file name instead.
In short: I want my VI to automatically create a file with the name of a single file (for example. "Timestamp_Operator_type_of_measurement_measurement_number")
All thoughts, I tried to change the options for the control of trajectory, but it doesn't seem to work.
Thanks in advance
Atamsih
26/11/2012 11:14 63rd txt the file name is not valid, you cannot use of settlers on a file name, if replace you them with hyphens, you should be ok
did not show here a solution yet by the way
Maybe you are looking for
-
Hello Since update IOS to 10.0.01, Apple's music search is no longer loads, or travel or for you. I just get the rotation drive and a "loading" message Anyone else having a similar problem or work around for this? Thank you
-
How can I connect my Airport time capsule to the nbn optus
I just got the NBN Optus connected and time capsule doesn't seem to work, can anyone advice on how to connect. I connected to a modem (Sagem Fast 38640op) with cable but the mac does not expect a return to the top
-
Could not load file or Assembly runtime being more recent than currently loaded run time
I've recently upgraded to TestStand 2010 and Visual Studio 2010 TestStand 4.2.1 and Visual Studio 2008. I now get the following error in the analysis of the sequence for all calls to my .net dll. "Step"My_StepType"not loadable module. Could not load
-
HP 3100 printer prints do not email
My printer does not print a bill of my sat. provider, it will print to the scanter but not e-mail?
-
Low volume compared to my original Video Clip
I just got my new 8 GB Clip more this week after using my original 2 GB Clip for 2 years and love it. Unfortunately, I noticed that the volume of the Clip Plus is a little lower than my video. I have done all the stuff with the control panel and the