Split the string of specific character in cfscript
Hi I want to split string (7 <>2, 3 6 0.6 <><>) by the individual (<>) of characters and store it in the table.. .as c# code:
dataList whwre =<>7 2, 3 6 0.6 <><>
String [] wordsStrings = Regex.Split (dataList, "<>");
You want to use the function ListToArray in ColdFusion. Treat the <> as a list separator. The important part here is setting the last argument true, for the argument of multiCharacterDelimiter .
dataList = ' 7<>2, 3<>6<>0.6;
wordsStrings = listToArray (dataList, "<>", false, true);
Tags: ColdFusion
Similar Questions
-
Oracle regular expressions - splits the string into words for
Hello
Nice day!
My requirement is to split the string into words.
So I need to identify the new line character and the semicolon (;), comma and space like terminator for string entry.
Please note that I am currently embedded blank and the comma as separator, as shown below.
Select regexp_substr('test)
TO
string in words, "([^, [: blanc:]] +) (', 1, 1) double;"How to integrate the semicolons and line break characters in regular expression Oracle?
Please notify.
Thanks and greetings
Sree
This has nothing to do with REGEXP. Is SQL * more parser does not not a semicolon at the end of the line:
SQL > select ' testto, mm\;
ERROR:
ORA-01756: city not properly finished chainSQL >
Just break the chain:
SQL > select regexp_substr ('testto, mm\;' |) '
2 string into words
3 \w+',1,level ',') of double
4. connect by level<= regexp_count('testto,mm\;'="" ||="">
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;' |') STRINGIN
--------------------------------------
Testto
mm
string
in
WordsSQL >
Or modify SQL * more the character of endpoints:
SQL > set sqlterm.
SQL > select regexp_substr ('testto, mm\;)
2 string into words
3 \w+',1,level ',') of double
4. connect by level<=>
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;) STRINGINTOWO
--------------------------------------
Testto
mm
string
in
WordsSQL >
SY.
-
splits the string into 3 parts
Hello
I have a requirement to split the string into 3 different room example inf.ethz.ch should be subdivided into inf ethz ch in 3 different column
We have table called email within this column contains all identification of email we need to divide email with dot (.) in different columns and display please suggest how to implement in the query
Thank you
Sudhir
Use REGEXP_SUBSTR:
SQL > with t as (select ' inf.ethz.ch' double txt)
2 Select regexp_substr (txt,'[^.] +') part_1,.
3 regexp_substr (txt,'[^.] +', 1, 2) part_2,.
4 regexp_substr (txt,'[^.] +' 1, 3) part_3
5 t
6.BY PARTY PA
--- ---- --
INF ethz chSQL >
Or you can use SUBSTR + Instr.
SY.
-
Concatenate and split the string
Hi all
Is there some how we can split the string like this "1 | ~ | Diego | Maradona | ~ | Footballer | The Argentina.
in the table of 3 elements: '1', ' Diego | Maradona', ' football '. The Argentina.
Here is my code
and put it is:public static void main(String args[]){ System.out.println("========USE SPLIT========== " ); String data = "1 |~| Diego|Maradona |~| Footballer|Argentina"; String[] items = data.split(" |~| "); for (String item : items) { System.out.println("item = " + item); } StringTokenizer tok = new StringTokenizer(data," |~| "); System.out.println("========USE TOKENIZER========== " ); while(tok.hasMoreElements()){ System.out.println("item = " + tok.nextToken()); } }
= USE SPLIT =.
Item = 1
Item = |
Item = |
Item = Diego | Maradona
Item = |
Item = |
Item = football | Argentina
= USE TOKENIZE =.
Item = 1
Item = Diego
Item = Maradona
Item = footballer
Item = Argentina
Published by: mycoffee on February 1, 2011 06:49Split() takes a regular expression. ' | ' has a special meaning in regular expressions.
Try to use
" \\|~\\| "as the argument of split()
-
splits the string into documents
Hello
I did a query (see regexp) that split a string into records. The problem with the query is the separate in the subquery. Otherwise, it returns millions of records where I expect less than a thousand.
Meanwhile, I found an other solution (see xmlsequence), but this statement returns the message "ORA-03113: end of file on the communication channel.
Please advice.
regexp:
xmlsequence:SELECT smp.sample_id FROM ( SELECT sa.sample_id, sau.u_box_code, sau.u_box_position FROM lims_sys.sdg sd, lims_sys.sdg_user sdu, lims_sys.sample sa, lims_sys.sample_user sau WHERE sd.sdg_id = sdu.sdg_id AND sd.sdg_id = sa.sdg_id AND sa.sample_id = sau.sample_id AND sau.u_padded_out = 'F' AND sdu.u_client_type = decode('#Client#','-1',sdu.u_client_type,'#Client#') AND sdu.u_crop_group = decode('#Crop#','-1',sdu.u_crop_group,'#Crop#') AND sdu.u_year_of_sample_delivery = decode('#Year#',-1,sdu.u_year_of_sample_delivery,'#Year#') AND sdu.u_week_of_processing = decode('#Week#',-1,sdu.u_week_of_processing,'#Week#') AND sd.status IN ('V','P','C') ) smp, ( SELECT distinct box_code, regexp_substr(box_pos,'[^,]+',1,level) box_pos FROM ( SELECT p.name box_code, substr(p.description,instr(p.description, 'NP=') + 3) box_pos FROM lims_sys.plate_template pt, lims_sys.plate p, lims_sys.plate_user pu WHERE pt.plate_template_id = p.plate_template_id AND p.plate_id = pu.plate_id AND pt.name = 'Box96' AND p.status IN ('V','P','C') AND p.description like '%NP=%' AND pu.u_client_type = decode('#Client#','-1',pu.u_client_type,'#Client#') AND pu.u_crop_group = decode('#Crop#','-1',pu.u_crop_group,'#Crop#') AND pu.u_year = decode('#Year#',-1,pu.u_year,'#Year#') AND pu.u_week = decode('#Week#',-1,pu.u_week,'#Week#') ) connect by level <= length(box_pos) - length(replace(box_pos,',')) + 1 ) box WHERE smp.u_box_code = box.box_code AND smp.u_box_position = box.box_posSELECT smp.sample_id FROM ( SELECT sa.sample_id, sau.u_box_code, sau.u_box_position FROM lims_sys.sdg sd, lims_sys.sdg_user sdu, lims_sys.sample sa, lims_sys.sample_user sau WHERE sd.sdg_id = sdu.sdg_id AND sd.sdg_id = sa.sdg_id AND sa.sample_id = sau.sample_id AND sau.u_padded_out = 'F' AND sdu.u_client_type = decode('#Client#','-1',sdu.u_client_type,'#Client#') AND sdu.u_crop_group = decode('#Crop#','-1',sdu.u_crop_group,'#Crop#') AND sdu.u_year_of_sample_delivery = decode('#Year#',-1,sdu.u_year_of_sample_delivery,'#Year#') AND sdu.u_week_of_processing = decode('#Week#',-1,sdu.u_week_of_processing,'#Week#') AND sd.status IN ('V','P','C') ) smp, ( SELECT box_code, trim(x.column_value.extract('e/text()')) box_pos FROM ( SELECT p.name box_code, substr(p.description,instr(p.description, 'NP=') + 3) box_pos FROM lims_sys.plate_template pt, lims_sys.plate p, lims_sys.plate_user pu WHERE pt.plate_template_id = p.plate_template_id AND p.plate_id = pu.plate_id AND pt.name = 'Box96' AND p.status IN ('V','P','C') AND p.description like '%NP=%' AND pu.u_client_type = decode('#Client#','-1',pu.u_client_type,'#Client#') AND pu.u_crop_group = decode('#Crop#','-1',pu.u_crop_group,'#Crop#') AND pu.u_year = decode('#Year#',-1,pu.u_year,'#Year#') AND pu.u_week = decode('#Week#',-1,pu.u_week,'#Week#') ) t, table (xmlsequence(xmltype('<e><e>' || replace(t.box_pos,',','</e><e>')|| '</e></e>').extract('e/e'))) x ) box WHERE smp.u_box_code = box.box_codeHello
When 'LEVEL '.<= x"="" is="" the="" only="" connect="" by="" condition,="" then="" you="" should="" be="" using="" a="" table="" that="" has="" only="" one="" row,="" like="">
You can generate a Table of counters (a result set, in fact) who has all the integers that you need and then join one.
The next thread is an example:
I don't don't want to mark in plsql -
SQL / PLSQL to split the string into pieces
Hi all
I have a problem of data conversion from the name of one table to another structure.
for example
SQL > desc names
Name Null? Type
----------------------------------------- -------- ----------------------------
TITLE VARCHAR2 (5)
FNAME VARCHAR2 (20)
LNAME VARCHAR2 (20)
SQL > Data desc
Name Null? Type
----------------------------------------- -------- ----------------------------
FULLNAME VARCHAR2 (50)
Insert in data values ("SIR I HAVE ONE NAME PARTICULARLY LONG INDEED");
Insert in the data values ("MINE IS EVEN MORE, ENOUGH RIDICULEMENT so IN FACT");
Essentially, I need to divide these names long, stored in the 1 field, in the above 3 fields. The trickiest part is however I want to do it in such a way so that if the 1st part of the name fits the 1 5 char field I want to do, otherwise I would divide between 2 fields - once again without splitting a string. The reason behind this is that application will automatically put a space between each field when they appear and I would avoid gaps in the names if possible.
This baffled me a little if any help would be seriously great... it might not even be a go-er, as it might be too uneconomic with the amount of available space, but I would give it a shot.
Thank you!
AdamHi, Adam.
Use regular expressions:
INSERT INTO names (title, fname, lname) SELECT RTRIM (REGEXP_SUBSTR ( fullname , '^.{1,5} ' ) ) , REGEXP_REPLACE ( fullname , '(^.{1,5} )?' || -- \1 = optional 1-5-letter word(s) '(.{1,20})' || -- \2 = 1-20 letters '(( .*)|$)' -- \3-\4 = space (plus anything) or end , '\2' ) , REGEXP_REPLACE ( fullname , '(^.{1,5} )?' || -- \1 = optional 1-5-letter word(s) '(.{1,20}( |$))' || -- \2-\3 = 1-20 letters and space or end '(.{1,20})?' || -- \4 = 0-20 letters '(( .*)|$)' -- \5 = space (plus anything) or end , '\4' ) FROM data_table -- data is not a good name ;Published by: Frank Kulash, August 18, 2009 11:13
Revised to manage long single word fullname -
Hello
I have string like below, and I want to divide and insert the numbers in another column.
Example of
---------------
test012345
ABC] 9876
Output should be as below so that once I am able to split can insert into 2 separate table columns
test 012345
ABC] 9876
Try this
with t as
(
Select 'test012345' c all the double union
[Select ' abc] 9876' double
)
Select col1, col2 regexp_replace(c,'[^[:digit:]]') t regexp_replace(c,'[[:digit:]]')
COL1 COL2
---------- ----------
test 012345
ABC] 9876
2 selected lines.
-
Splits the string after the complete word
Hello world
I have a dynamic text that is shown completely if it has less then 280 characters. When more characters then 280 I shows the first 280 and after that I just put 3 points «...» ». Now, my question was whether it is possible to display the 3 points after the last full word after these 280 characters.
Example today: 'it's just an examp... "(the word cuts)
Example of how it should be: "it is just an example." (watch the whole word pieces around the suite)
Thanks in advance!If this one won't, try this one:
http://www.cflib.org/UDF/abbreviate"Shortens a string to roughly the length indicated, no stripping
tags, ensuring that the end is not cutting a word in half and adding a
character of the selection at the end."Azadi Saryev
SABAI - Dee.com
http://www.SABAI-Dee.com/ -
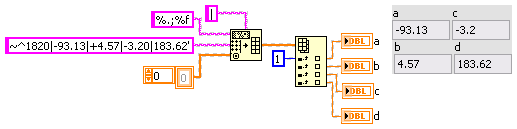
Hello
I get data like ~^1820|-93.13|+4.57|-3.20 | 183,62'
any value assigned something like height, angle, etc...
I want to divide this string could someone please help me how to do this.
I would like in a similar. 1820
a = 93.13
b = + 4.57
c =-3.20
d = 183.62
Thank you much in advance.
With the best wishes,
Ankit.
Hi Pierre,.
use SpreadsheetStringToArray:
-
Need help to split the string into two fields
Can someone share your thoughts by dividing the prod_info string below into two fields
For example:-TABLE of PROD
SOURCE TABLE
SNO PROD_INFO 1 20 OZ SIMILAC 2 HW PRO 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EE 12 KG 9 KK 11111 10 ZZ ABC FAC 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. EXPECTED RESULTS
SNO PROD_INFO PROD_VAL 1 SIMILAC 20 OZ 2 HW PDR 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EA 12 KG 9 KK 11111 10 AEC ABC ZZ 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. with
as Prod
(select 1 sno, "SIMILAC 20 OZ" prod_info of all the double union)
Select 2, 'HW PDR 10' from dual union all
Select 3, 'REX 10 OZ' from dual union all
Select option 4, "AAA 10' from dual union all
Select 5, "BBB 2000"of the dual union all
Select 6, 'CCC 10 LBS' double union all
Select 7, 'DDD 2021' from dual union all
Select 8, 'EE 12 KG' from dual union all
Select 9, 'KK 11111' Union double all the
choose 10, "ZZ ABC FAC 11' from dual union all
Select 11, 'CC DD RKW 12 OZ' from dual union all
Order 12, '12KJ LB 12' double
)
Select sno,
(prod_info regexp_substr(prod_info,'^((\d*|\w*)[^[:digit:]].*) \d',1,1,null,1).
regexp_substr (prod_info,' prod_value (\d+.*)$',1,1,null,1))
Prod
SNO PROD_INFO PROD_VALUE 1 SIMILAC 20 OZ 2 HW PDR 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EA 12 KG 9 KK 11111 10 AEC ABC ZZ 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. Concerning
Etbin
-
Splits the string into two columns to dashboard
Hi all
I got thisworking
decode (SUBSTR (ADDR2_ATTR_1, 1, INSTR(ADDR2_ATTR_1,'-')-1), '9999', NULL, (SUBSTR (ADDR2_ATTR_1, 1, INSTR(ADDR2_ATTR_1,'-')-1))),
decode (SUBSTR (ADDR2_ATTR_1, INSTR (ADDR2_ATTR_1,'-') + 1), '9999', NULL, (SUBSTR (ADDR2_ATTR_1, INSTR(ADDR2_ATTR_1,'-') + 1)))
but the results were a little different.
It came as
Col1 for 8-10 have come beauiful... .but however Col2 data should be in K1 and transferred to Col2
Col1 Col2
< null > 10
< null > 33
8 10
Any guidance is appreciated.Personally, I like the cases, but another way using the DECODE method...
WITH t AS (SELECT '8-10' str FROM DUAL UNION ALL SELECT '163' FROM DUAL UNION ALL SELECT '789' FROM DUAL) SELECT str col1, DECODE (NVL2 (NULLIF (INSTR (str, '-'), 0), 99999, 0),99999, SUBSTR (str, 1, INSTR (str, '-', 1) - 1),str) col2, DECODE (NVL2 (NULLIF (INSTR (str, '-'), 0), 99999, 0),99999, SUBSTR (str, INSTR (str, '-', 1) + 1),NULL) col3 FROM t;Simplified:
------WITH t AS (SELECT '8-10' str FROM DUAL UNION ALL SELECT '163' FROM DUAL UNION ALL SELECT '789' FROM DUAL) SELECT str col1, DECODE (SIGN (INSTR (str, '-')),1, SUBSTR (str, 1, INSTR (str, '-', 1) - 1),str) col2, DECODE (SIGN (INSTR (str, '-')),1, SUBSTR (str, INSTR (str, '-', 1) + 1), NULL) col3 FROM t;OUTPUT:
COL1 COL2 COL3 8-10 8 10 163 163 789 789See you soon,.
Manik.Published by: adding a simplified version
-
Splits the string into two columns
Can someone please help me the following
I want to divide into two columns URL and ID /cfd/abc.html,/night/aaa/Page1,/can/MLP/Page2|107
Result must be
Temporary table
< font color = "red" > URL < / police > < font color = 'blue' > ID < / make >
< font color = "red" > /cfd/abc.html < / police > < font color = "blue" > 107 < / make >
< font color = "red" > / night/aaa/page 1 < / police > < font color = "blue" > 107 < / make >
< font color = "red" > / can/MLP/Page2 < / police > < font color = "blue" > 107 < / make >
There can be N number of comma separated URLs, but there will be only 1 separate ID which is the vertical bar (|)Try this,
SQL> WITH T 2 AS (SELECT '/cfd/abc.html,/night/aaa/Page1,/can/MLP/Page2|107 ' str FROM DUAL UNION ALL 3 SELECT '/cfd/def.html,/bbbb/bbbb/Page1,/lll/MLP/Page3|108 ' str FROM DUAL) 4 SELECT REGEXP_SUBSTR ( str, '[^,|]+', 1, lvl) URL, 5 REGEXP_SUBSTR ( str, '[^|]+', 1, 2) ID 6 FROM T, 7 (SELECT LEVEL lvl 8 FROM (SELECT MAX (LENGTH (REGEXP_REPLACE ( str, '[^,]'))) mx FROM T) 9 CONNECT BY LEVEL <= mx + 1) 10 WHERE Lvl - 1 <= LENGTH (REGEXP_REPLACE ( str, '[^,]+')) 11 order by id,lvl; URL ID -------------------------------------------------- ------------------------------------------------- /cfd/abc.html 107 /night/aaa/Page1 107 /can/MLP/Page2 107 /cfd/def.html 108 /bbbb/bbbb/Page1 108 /lll/MLP/Page3 108 6 rows selected. SQL>G.
-
Hi Experts,
My Version of Oracle:
I'll get a few values as * 120_12_14 * as my entry.BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - Production PL/SQL Release 11.1.0.7.0 - Production CORE 11.1.0.7.0 Production TNS for 32-bit Windows: Version 11.1.0.7.0 - Production NLSRTL Version 11.1.0.7.0 - Production 5 rows selected.
I need to separate the values based on the separator (_) and to insert each value in a separate column.
For Ex:
I even have STR2TBL installed in my database and I am worry here, is it possible to do it in a single SQL statement without with LOOP.Input :- 120_12_14 Required Process :- INSERT INTO TABLE1(A,B,C) VALUES(120,12,14);
Examples:SELECT SUBSTR(COLUMN_VALUE,0,INSTR(COLUMN_VALUE,'_')-1) FIRST_VALUE, SUBSTR(COLUMN_VALUE,INSTR(COLUMN_VALUE,'_')+1) SECOND_VALUE FROM TABLE(STR2TBL(TRIM('1000_17.87_0,1001_10_0,10405_0_1'))); FIRST_VALUE SECOND_VALUE ----------- ----------- 1000 17.87_0 1001 10_0 10405 0_1 3 rows selected.
Any Suggestions,*Desired Output:* FIRST_VALUE SECOND_VALUE THIRD_VALUE ----------- ----------- ----------- 1000 17.87 0 1001 10 0 10405 0 1 3 rows selected.
Thank you
Dharan V
Edited by: DharanV may 7, 2010 11:52
Fixed the delimiterYou mentioned that you are sure there will always be three parts. In this case you are very close already. Simply replace your selection with the below list.
SQL> with t as 2 ( select '1000_17.87_0' column_value from dual union all 3 select '1001_10_0' from dual union all 4 select '10405_0_1' from dual 5 ) 6 select substr(column_value,0,instr(column_value,'_')-1) first_value 7 , substr(column_value,instr(column_value,'_')+1,instr(column_value,'_',1,2)-instr(column_value,'_')-1) second_value 8 , substr(column_value,instr(column_value,'_',1,2)+1) third_value 9 from t 10 / FIRST_VALUE SECOND_VALUE THIRD_VALUE ------------ ------------ ------------ 1000 17.87 0 1001 10 0 10405 0 1 3 rows selected.Kind regards
Rob. -
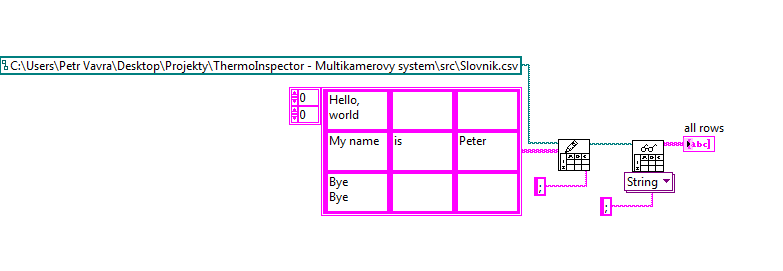
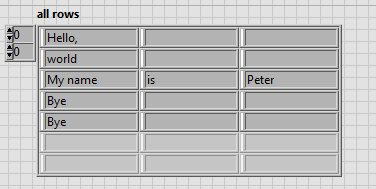
Save and load the string table
Hello
is possible except an array of channel with multiple line of text file and load new file to table with the same size of array?
Because when I use the code in the picture, initialized array is 3 x 3 but after save and load file is table 5 x 3.
If is an option how to save this table in the file into 3 x 3 table and charge back of file as a 3 x 3 table?
Thank your for any suggestion,.
Petr
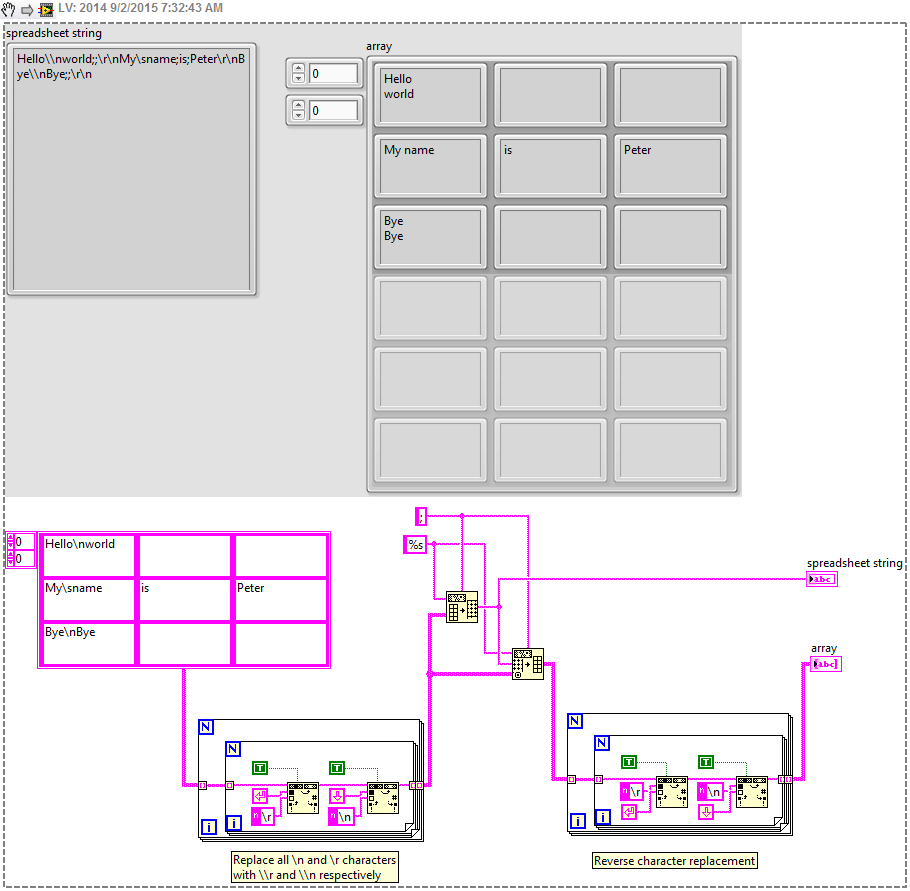
Your code is loaded in 5 x 3 is because two of your cells have newline characters (\n). The reading of the worksheet VI use return or line break characters and your delimiter to figure out how to split the string into an array.
A solution might be to replace all characters from end of line with something else, and then reinsert it after reading of the worksheet.
It can do what you want, even if it's a bit bulky. It's a little confusing if you don't understand "------" string formatting, but it essntially replaces all '\r' and '\n' with '\\r' and '\\n', including the conversion of the worksheet does not read as an end of line character.
-
divide the string and replace the token
Hi all
I have a field called "FreeText" that contains data that is more or less according to the following format.
"1 NEWTON/ISAACSIR WITHOUT DAIRY AND PEANUT PREFER ONE REGIME FRUITS"
It contains the name of a text followed by someone. I want to this tokenized by using space as the delimiter and the first token can separate from the rest of it. The expected output would be two columns containing.
"1 NEWTON/ISAACSIR" and the second column
"NO DAIRY AND NO PEANUT PREFER ONE REGIME FRUITS."
Thanks and greetings
CrusoeReplace with your channel:
It splits the string for 2 values separated by the character of the first found SPACE.WITH abc AS (SELECT '1NEWTON/ISAACSIR NO DAIRY PRODUCTS AND NO PEANUTS PREFERS A FRUIT ONLY DIET' A FROM dual) SELECT SUBSTR(A,1,INSTR(a,' ',1)-1) , SUBSTR(A,INSTR(a,' ',1)+1 , LENGTH(a)) FROM abcPublished by: AJ99 on July 1, 2009 11:09
Maybe you are looking for
-
Leopard Snow Leopard Mail Inbox
I'll have to manual transfer of files from a G4 Mini under Leopard 10.5.8 on a Mini Intel Snow Leopard 10.6.8. I copied my Leopard user (folder) files on an external drive of the mini old and now have the drive mounted on the new mini. From there I
-
I made my largest site and how can keep the same size for all other sites?
I did the 2 larger site and how to keep the same size for all pages when I re - open the web browser?
-
I CAN'T TURN ON MY IPAD?
-
problems after windows update fingerprint reader
After installing the recent updates to XP (I think that service pk 3) my Microsoft Fingerprint Reader is no longer works.i done a system restore to get it working again, but now I need the help of updates
-
Multiple procedures to draft store
WARNING * I always try to learn Labview as much as I can through tutorials and various other modules. My coding can therefore still not very effective as it should. WARNING *. First of all, I'm using Labview 2014. My question is, if I can run severa