Splits the string into two columns
Can someone please help me the followingI want to divide into two columns URL and ID /cfd/abc.html,/night/aaa/Page1,/can/MLP/Page2|107
Result must be
Temporary table
< font color = "red" > URL < / police > < font color = 'blue' > ID < / make >
< font color = "red" > /cfd/abc.html < / police > < font color = "blue" > 107 < / make >
< font color = "red" > / night/aaa/page 1 < / police > < font color = "blue" > 107 < / make >
< font color = "red" > / can/MLP/Page2 < / police > < font color = "blue" > 107 < / make >
There can be N number of comma separated URLs, but there will be only 1 separate ID which is the vertical bar (|)
Try this,
SQL> WITH T
2 AS (SELECT '/cfd/abc.html,/night/aaa/Page1,/can/MLP/Page2|107 ' str FROM DUAL UNION ALL
3 SELECT '/cfd/def.html,/bbbb/bbbb/Page1,/lll/MLP/Page3|108 ' str FROM DUAL)
4 SELECT REGEXP_SUBSTR ( str, '[^,|]+', 1, lvl) URL,
5 REGEXP_SUBSTR ( str, '[^|]+', 1, 2) ID
6 FROM T,
7 (SELECT LEVEL lvl
8 FROM (SELECT MAX (LENGTH (REGEXP_REPLACE ( str, '[^,]'))) mx FROM T)
9 CONNECT BY LEVEL <= mx + 1)
10 WHERE Lvl - 1 <= LENGTH (REGEXP_REPLACE ( str, '[^,]+'))
11 order by id,lvl;
URL ID
-------------------------------------------------- -------------------------------------------------
/cfd/abc.html 107
/night/aaa/Page1 107
/can/MLP/Page2 107
/cfd/def.html 108
/bbbb/bbbb/Page1 108
/lll/MLP/Page3 108
6 rows selected.
SQL>
G.
Tags: Database
Similar Questions
-
Splits the string into two columns to dashboard
Hi all
I got thisworking
decode (SUBSTR (ADDR2_ATTR_1, 1, INSTR(ADDR2_ATTR_1,'-')-1), '9999', NULL, (SUBSTR (ADDR2_ATTR_1, 1, INSTR(ADDR2_ATTR_1,'-')-1))),
decode (SUBSTR (ADDR2_ATTR_1, INSTR (ADDR2_ATTR_1,'-') + 1), '9999', NULL, (SUBSTR (ADDR2_ATTR_1, INSTR(ADDR2_ATTR_1,'-') + 1)))
but the results were a little different.
It came as
Col1 for 8-10 have come beauiful... .but however Col2 data should be in K1 and transferred to Col2
Col1 Col2
< null > 10
< null > 33
8 10
Any guidance is appreciated.Personally, I like the cases, but another way using the DECODE method...
WITH t AS (SELECT '8-10' str FROM DUAL UNION ALL SELECT '163' FROM DUAL UNION ALL SELECT '789' FROM DUAL) SELECT str col1, DECODE (NVL2 (NULLIF (INSTR (str, '-'), 0), 99999, 0),99999, SUBSTR (str, 1, INSTR (str, '-', 1) - 1),str) col2, DECODE (NVL2 (NULLIF (INSTR (str, '-'), 0), 99999, 0),99999, SUBSTR (str, INSTR (str, '-', 1) + 1),NULL) col3 FROM t;Simplified:
------WITH t AS (SELECT '8-10' str FROM DUAL UNION ALL SELECT '163' FROM DUAL UNION ALL SELECT '789' FROM DUAL) SELECT str col1, DECODE (SIGN (INSTR (str, '-')),1, SUBSTR (str, 1, INSTR (str, '-', 1) - 1),str) col2, DECODE (SIGN (INSTR (str, '-')),1, SUBSTR (str, INSTR (str, '-', 1) + 1), NULL) col3 FROM t;OUTPUT:
COL1 COL2 COL3 8-10 8 10 163 163 789 789See you soon,.
Manik.Published by: adding a simplified version
-
Need help to split the string into two fields
Can someone share your thoughts by dividing the prod_info string below into two fields
For example:-TABLE of PROD
SOURCE TABLE
SNO PROD_INFO 1 20 OZ SIMILAC 2 HW PRO 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EE 12 KG 9 KK 11111 10 ZZ ABC FAC 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. EXPECTED RESULTS
SNO PROD_INFO PROD_VAL 1 SIMILAC 20 OZ 2 HW PDR 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EA 12 KG 9 KK 11111 10 AEC ABC ZZ 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. with
as Prod
(select 1 sno, "SIMILAC 20 OZ" prod_info of all the double union)
Select 2, 'HW PDR 10' from dual union all
Select 3, 'REX 10 OZ' from dual union all
Select option 4, "AAA 10' from dual union all
Select 5, "BBB 2000"of the dual union all
Select 6, 'CCC 10 LBS' double union all
Select 7, 'DDD 2021' from dual union all
Select 8, 'EE 12 KG' from dual union all
Select 9, 'KK 11111' Union double all the
choose 10, "ZZ ABC FAC 11' from dual union all
Select 11, 'CC DD RKW 12 OZ' from dual union all
Order 12, '12KJ LB 12' double
)
Select sno,
(prod_info regexp_substr(prod_info,'^((\d*|\w*)[^[:digit:]].*) \d',1,1,null,1).
regexp_substr (prod_info,' prod_value (\d+.*)$',1,1,null,1))
Prod
SNO PROD_INFO PROD_VALUE 1 SIMILAC 20 OZ 2 HW PDR 10 3 REX 10 OZ 4 AAA 10 5 BBB 2000 6 CCC 10 LB 7 DDD 2021 8 EA 12 KG 9 KK 11111 10 AEC ABC ZZ 11 11 RKW DD CC 12 OZ 12 12KJ 12 LBS. Concerning
Etbin
-
splits the string into 3 parts
Hello
I have a requirement to split the string into 3 different room example inf.ethz.ch should be subdivided into inf ethz ch in 3 different column
We have table called email within this column contains all identification of email we need to divide email with dot (.) in different columns and display please suggest how to implement in the query
Thank you
Sudhir
Use REGEXP_SUBSTR:
SQL > with t as (select ' inf.ethz.ch' double txt)
2 Select regexp_substr (txt,'[^.] +') part_1,.
3 regexp_substr (txt,'[^.] +', 1, 2) part_2,.
4 regexp_substr (txt,'[^.] +' 1, 3) part_3
5 t
6.BY PARTY PA
--- ---- --
INF ethz chSQL >
Or you can use SUBSTR + Instr.
SY.
-
Oracle regular expressions - splits the string into words for
Hello
Nice day!
My requirement is to split the string into words.
So I need to identify the new line character and the semicolon (;), comma and space like terminator for string entry.
Please note that I am currently embedded blank and the comma as separator, as shown below.
Select regexp_substr('test)
TO
string in words, "([^, [: blanc:]] +) (', 1, 1) double;"How to integrate the semicolons and line break characters in regular expression Oracle?
Please notify.
Thanks and greetings
Sree
This has nothing to do with REGEXP. Is SQL * more parser does not not a semicolon at the end of the line:
SQL > select ' testto, mm\;
ERROR:
ORA-01756: city not properly finished chainSQL >
Just break the chain:
SQL > select regexp_substr ('testto, mm\;' |) '
2 string into words
3 \w+',1,level ',') of double
4. connect by level<= regexp_count('testto,mm\;'="" ||="">
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;' |') STRINGIN
--------------------------------------
Testto
mm
string
in
WordsSQL >
Or modify SQL * more the character of endpoints:
SQL > set sqlterm.
SQL > select regexp_substr ('testto, mm\;)
2 string into words
3 \w+',1,level ',') of double
4. connect by level<=>
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;) STRINGINTOWO
--------------------------------------
Testto
mm
string
in
WordsSQL >
SY.
-
splits the string into documents
Hello
I did a query (see regexp) that split a string into records. The problem with the query is the separate in the subquery. Otherwise, it returns millions of records where I expect less than a thousand.
Meanwhile, I found an other solution (see xmlsequence), but this statement returns the message "ORA-03113: end of file on the communication channel.
Please advice.
regexp:
xmlsequence:SELECT smp.sample_id FROM ( SELECT sa.sample_id, sau.u_box_code, sau.u_box_position FROM lims_sys.sdg sd, lims_sys.sdg_user sdu, lims_sys.sample sa, lims_sys.sample_user sau WHERE sd.sdg_id = sdu.sdg_id AND sd.sdg_id = sa.sdg_id AND sa.sample_id = sau.sample_id AND sau.u_padded_out = 'F' AND sdu.u_client_type = decode('#Client#','-1',sdu.u_client_type,'#Client#') AND sdu.u_crop_group = decode('#Crop#','-1',sdu.u_crop_group,'#Crop#') AND sdu.u_year_of_sample_delivery = decode('#Year#',-1,sdu.u_year_of_sample_delivery,'#Year#') AND sdu.u_week_of_processing = decode('#Week#',-1,sdu.u_week_of_processing,'#Week#') AND sd.status IN ('V','P','C') ) smp, ( SELECT distinct box_code, regexp_substr(box_pos,'[^,]+',1,level) box_pos FROM ( SELECT p.name box_code, substr(p.description,instr(p.description, 'NP=') + 3) box_pos FROM lims_sys.plate_template pt, lims_sys.plate p, lims_sys.plate_user pu WHERE pt.plate_template_id = p.plate_template_id AND p.plate_id = pu.plate_id AND pt.name = 'Box96' AND p.status IN ('V','P','C') AND p.description like '%NP=%' AND pu.u_client_type = decode('#Client#','-1',pu.u_client_type,'#Client#') AND pu.u_crop_group = decode('#Crop#','-1',pu.u_crop_group,'#Crop#') AND pu.u_year = decode('#Year#',-1,pu.u_year,'#Year#') AND pu.u_week = decode('#Week#',-1,pu.u_week,'#Week#') ) connect by level <= length(box_pos) - length(replace(box_pos,',')) + 1 ) box WHERE smp.u_box_code = box.box_code AND smp.u_box_position = box.box_posSELECT smp.sample_id FROM ( SELECT sa.sample_id, sau.u_box_code, sau.u_box_position FROM lims_sys.sdg sd, lims_sys.sdg_user sdu, lims_sys.sample sa, lims_sys.sample_user sau WHERE sd.sdg_id = sdu.sdg_id AND sd.sdg_id = sa.sdg_id AND sa.sample_id = sau.sample_id AND sau.u_padded_out = 'F' AND sdu.u_client_type = decode('#Client#','-1',sdu.u_client_type,'#Client#') AND sdu.u_crop_group = decode('#Crop#','-1',sdu.u_crop_group,'#Crop#') AND sdu.u_year_of_sample_delivery = decode('#Year#',-1,sdu.u_year_of_sample_delivery,'#Year#') AND sdu.u_week_of_processing = decode('#Week#',-1,sdu.u_week_of_processing,'#Week#') AND sd.status IN ('V','P','C') ) smp, ( SELECT box_code, trim(x.column_value.extract('e/text()')) box_pos FROM ( SELECT p.name box_code, substr(p.description,instr(p.description, 'NP=') + 3) box_pos FROM lims_sys.plate_template pt, lims_sys.plate p, lims_sys.plate_user pu WHERE pt.plate_template_id = p.plate_template_id AND p.plate_id = pu.plate_id AND pt.name = 'Box96' AND p.status IN ('V','P','C') AND p.description like '%NP=%' AND pu.u_client_type = decode('#Client#','-1',pu.u_client_type,'#Client#') AND pu.u_crop_group = decode('#Crop#','-1',pu.u_crop_group,'#Crop#') AND pu.u_year = decode('#Year#',-1,pu.u_year,'#Year#') AND pu.u_week = decode('#Week#',-1,pu.u_week,'#Week#') ) t, table (xmlsequence(xmltype('<e><e>' || replace(t.box_pos,',','</e><e>')|| '</e></e>').extract('e/e'))) x ) box WHERE smp.u_box_code = box.box_codeHello
When 'LEVEL '.<= x"="" is="" the="" only="" connect="" by="" condition,="" then="" you="" should="" be="" using="" a="" table="" that="" has="" only="" one="" row,="" like="">
You can generate a Table of counters (a result set, in fact) who has all the integers that you need and then join one.
The next thread is an example:
I don't don't want to mark in plsql -
Parse the string into two double
Hello everyone, once again
I'm taking a string of numbers that can be anywhere from - 999999.999999 to + 999999.99999 and separate them into two double rooms. For example, if a user entry - 10000, 10000 - two doubles would be-10000 and-10000. If the user has entered - 10.11111- + 20.00111 he got out - 10.11111 and 20.00111. The VI "Extract the numbers" did perfectly, but I need a way to return the results in two double rooms instead of an array of doubles. I also results to return all the digits after the decimal point for reasons of precision. I use this code within one of my States in a state machine and the driver I use only accepts double rooms.
The code of "Extract the numbers" VI is attached. Thank you all!
Hi buickgn,
When your code works, you should only use IndexArray on outputs. If not, try this one:

-
SQL / PLSQL to split the string into pieces
Hi all
I have a problem of data conversion from the name of one table to another structure.
for example
SQL > desc names
Name Null? Type
----------------------------------------- -------- ----------------------------
TITLE VARCHAR2 (5)
FNAME VARCHAR2 (20)
LNAME VARCHAR2 (20)
SQL > Data desc
Name Null? Type
----------------------------------------- -------- ----------------------------
FULLNAME VARCHAR2 (50)
Insert in data values ("SIR I HAVE ONE NAME PARTICULARLY LONG INDEED");
Insert in the data values ("MINE IS EVEN MORE, ENOUGH RIDICULEMENT so IN FACT");
Essentially, I need to divide these names long, stored in the 1 field, in the above 3 fields. The trickiest part is however I want to do it in such a way so that if the 1st part of the name fits the 1 5 char field I want to do, otherwise I would divide between 2 fields - once again without splitting a string. The reason behind this is that application will automatically put a space between each field when they appear and I would avoid gaps in the names if possible.
This baffled me a little if any help would be seriously great... it might not even be a go-er, as it might be too uneconomic with the amount of available space, but I would give it a shot.
Thank you!
AdamHi, Adam.
Use regular expressions:
INSERT INTO names (title, fname, lname) SELECT RTRIM (REGEXP_SUBSTR ( fullname , '^.{1,5} ' ) ) , REGEXP_REPLACE ( fullname , '(^.{1,5} )?' || -- \1 = optional 1-5-letter word(s) '(.{1,20})' || -- \2 = 1-20 letters '(( .*)|$)' -- \3-\4 = space (plus anything) or end , '\2' ) , REGEXP_REPLACE ( fullname , '(^.{1,5} )?' || -- \1 = optional 1-5-letter word(s) '(.{1,20}( |$))' || -- \2-\3 = 1-20 letters and space or end '(.{1,20})?' || -- \4 = 0-20 letters '(( .*)|$)' -- \5 = space (plus anything) or end , '\4' ) FROM data_table -- data is not a good name ;Published by: Frank Kulash, August 18, 2009 11:13
Revised to manage long single word fullname -
I am Brazilian and I use Adobe Acrobat Reader DC a lot. I would suggest an implementation of features present in the PC, I missed a lot of things on Android, which is 'New window' or something like that, like split the screen into two parts in order to see the two different parts of the same file.
For smartphones, its use is restricted, but for tablets, it can be really useful, because it allows the display of two distinct points of the same file,
I have reduced considerably the use of paper using this application, however, I need to navigate the file always pick up a few points seen earlier, which causes a lot of discomfort compared to printed documents.
This is a suggestion, but I would like it to be considered.
Thank you for your request. We have taken note of the same and must try to integrate it into one of our future releases.
Thank you.
-
Split a string into lines {< string1 >} | {< string2 >}
I implemented the Oracle text search in my database. Now I have this query
Select ctx_thes.syn ('RED', 'MY_THESAURUS') of double;
the output is displayed as
{RED} | {MIXTURE OF RED} | {TABLE RED} | {RED}
and I want to get the words in separate lines, i.e.
Red
Mixture of Red
Red table
Red wine
How to split the string into lines?
SELECT * FROM ( SELECT DISTINCT REGEXP_SUBSTR ('{RED}|{RED BLEND}|{RED TABLE}|{RED WINE}', '({)([A-Z]+ *[A-Z]*)(})', 1, LEVEL, 'i', 2) val FROM DUAL CONNECT BY LEVEL <= REGEXP_COUNT ( '{RED}|{RED BLEND}|{RED TABLE}|{RED WINE}', '|') + 1) WHERE val IS NOT NULL; -
How to split a string into columns
Hi all
Have a strings like this, where the delimiter is
Thanks in advance10:00 | x1 | 2 | RO | P | Con ausilio | y1 10:10 | x2 | 1 | RO | | | y2 10:20 |x3 | 3 | | | | y3 10:30 |x4 | 3 | RO | N | Con aiuto | y4 10:40 |x5 | 1 | RO | | | y5 how can I break it up into columns, for example, the first char(before first pipe) insert in first variable, then, after first pipe, second characters in a other column ans so on col1 := '10:00'; col2 := 'x1'; col3 := '2'; col4:= 'RO'; col5 := 'P'; col6 := ' Con ausilio '; col7 := 'y1'; col1 := '10:10'; col2 := 'x2'; .. and so onHello
If you want to split the string str into 7 columns :
SELECT TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 1)) AS col1 , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 2)) AS col2 , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 3)) AS col3 ... , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 7)) AS col7 FROM table_x ;If you want to split it inot 7 variables :
col1 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 1)); col2 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 2)); col3 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 3)); ... col7 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 7)); -
How to split a string into several substrings parent using a delimiter
Hello
I am forced to split a string into several substrings parent using a delimiter.
And insert these substrings in variuou of the columns of a table in a row.
For example. The sting is: ABC * DEF * GHI * JKH *.
where ' *' is the separator.
Desired output:
Col1 Col2 Col3 Col4 Col5
------- -------- -------- ------- ---------
JKH GHI ABC DEF (null)
Could you please guide me how can I achieve this.
Thank you
Bogoss
Hello Salim,
Leave the thread for reference... got this excerpt:
with t as
(
Select "c: its: hgfd:1:23" Str
)
Select
REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 1, null, 1) col1
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 2, null, 1) col2
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 3, null, 1) col3
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 4, null, 1) col4
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 5, null, 1) col5
t;
This code snippet works well, but for the fixed columns. Here are 5 predefined columns.
But I need to have a logic that I can browse the string any No.. sometimes.
For example. If I get 3 secondary channels of the parent chain... I need to insert into 3 columns.
And if I get 6 strings under... I need to insert into 6 columns.
Could you please help me develop a logic like that.
I use Oracle database 10g.
And the data are currently being collected on external table... but I can store in a variable or a column of a database table.
Thank you
Bogoss
-
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
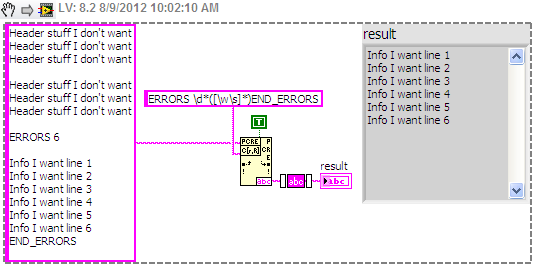
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
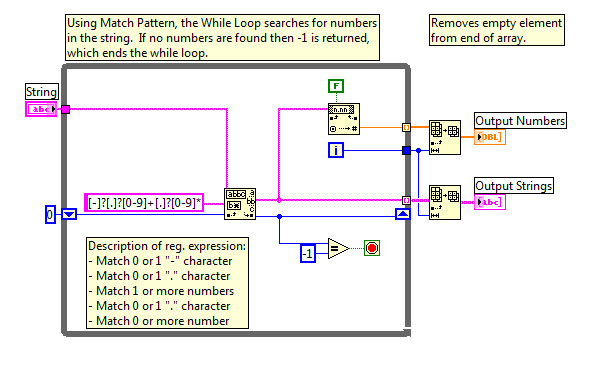
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
Divide the line into several columns
Hi all
I have a question where I want to divide the line into multiple columns based on the delimiter ' |'.
Staging of Table structure: People_STG, I have people in it.
Create table People_STG(col1 varchar2(4000));
Insert into People_STG(Emp_id|) User name | FirstName. LastName. JobTitle | hire_date | Location_id)
SELECT REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 1) EMP_ID, REGEXP_SUBSTR ( COL1, '[^|]+', 1, 2) USERNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 3) FIRSTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 4) LASTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 5) JOBTITLE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 6) HIRE_DATE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 7) LOCATION_ID FROM PEOPLE_STG WHERE length(regexp_replace(COL1, '[^|]', '')) = 14;
But I am facing a problem here, as in some lines, function is null, but when I run the above query, it is not recognizing the empty element and inserting Hire_date values of function and location_id in Hire_date where function is null.
for example: 1 | akash51 | Akaksh | C | 22/11/14 | 15
Here the function is null, so when I run top to divide query it will insert 11/22/14 in the function column and 15 in Hire_Date.
Please need help on this one.
Oracle Version: 11.2 g
Thanks in advance,
Akash.
There are different techniques to cope with this. Is a simple...
SQL > ed
A written file afiedt.buf1 with t as (select 1 | akash51 |) Akaksh | C | 22/11/14 | 15' as col1 of union double all the
2 Select 2 | akash52 | Akaksh | C | Jobs jobs | 23/11/14 | 15' of the double
3 )
4 --
5. end of test data
6 --
7 select trim (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 1)) EMP_ID,.
8 toppings (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 2)) USERNAME,.
9 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 3)) FIRSTNAME,
10 pads (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 4)) LASTNAME,.
11 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 5)) JOBTITLE,.
12 pads (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 6)) HIRE_DATE,.
13 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 7)) location_id
14 * from (select replace (col1, ' |)) ',' | as col1 of t)
SQL > /.EMP_ID USERNAME FIRSTNAME LASTNAME, JOBTITLE HIRE_DATE LOCATION_I
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 akash51 Akaksh C 22/11/14 15
2 akash52 Akaksh C Job 23/11/14 15 -
Two tables provided, how you retrieve the values in two columns using values in a column (the pass get values. If col. A is not null values and get the pass. B if col. A is null)?
Guessing
Select nvl (x.col_a, y.col_b) the_column
from table_1 x,.
table_2 y
where x.pk = y.pk
Concerning
Etbin
Maybe you are looking for
-
Im trying to sign out of itunes, I already changed my icloud account but it is still asking for my old
-
Satellite P300-1 year - Touchpad problem with AC adapter / CC
I have a laptop Satellite P300-1 year and from the beginning (two weeks)I have a touchpad problem: it will not immediately responsive and the pointer shakes when pressing the key. Very often, it freezes for only one or two seconds. It's VERY annoying
-
forgotten password for computer laptop mini210 CL-1018
I forgot my password and can't get a password request, I have no f1 through f11 keys any help would be great, thanks
-
Windows XP, freezing to log on to the screen.
I have a Dell dimension 4700 running Windows XP Home Edition. Like delay, start the system freeze, sometimes even if I'm on the Internet, but here lately it doesn't let me pass the logon screen at the start up. Any suggestions would be helpful. I'd s
-
Quick Books 2008 pro does not work on my windows Vista
Why my Quick Books pro 2008 not working correctly on my windows Vista?