Table of index between the limits
Hi all
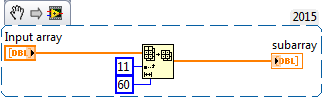
I have a byte array that I need to extract information.
I need to extract 60 cells in the table, so using the index function to form a table under is not pretty (wiring in 60 constants). Is there another way to do this? i.e. to inex between limits?
Thank you
Richard.
You can use a subset of the table, where you need feed the starting index and length you need
Tags: NI Software
Similar Questions
-
Move Tables an index to the new storage facilities
Hello
I have two tables IEFSENCY_TAB and IEFSENCY_IDX, first areas contain tables and the second is the index.
The IEFSENCY_TAB, I have to separate 3 DASC, DSUBEX and tables DOBJ who has 57 MB and 4 GB, 9 GB, new storage spaces.
These tables have the following index on the IEFSENCY_IDX tablespace:
DASCI2, DASCI3 table DASC.
DOBJI1, DOBJI2, DOBJI3, DOBJI4 of DOBJ table
DSUBEXI1, DSUBEXI2, DSUBEXI3 in table DSUBEX.
Can I use the its sql following to move tables to the new tablespace:
on the case of DOBJ, for example:
ALTER table DOBJ move tablespace IEFSENCY_TAB2;
ALTER index rebuild tablespace IEFSENCY_IDX2 DOBJI1;
ALTER index rebuild tablespace IEFSENCY_IDX2 DOBJI2;
ALTER index rebuild tablespace IEFSENCY_IDX2 DOBJI3;
ALTER index rebuild tablespace IEFSENCY_IDX2 DOBJI4;
Hello
I did the following:
SQL > create tablespace IEFSENCY_TAB2
2 datafile 'L:\DataENCY\tabENCY_SUB.dbf '.
3 size M 100
4 extent management local uniform size 1 M;
Created tablespace.
SQL >
SQL > create tablespace IEFSENCY_IDX2
2 datafile 'L:\DataENCY\idxENCY_SUB.dbf '.
3 size M 100
4 extent management local uniform size 1 M;
Created tablespace.
SQL > alter system table. DSUBEX move tablespace IEFSENCY_TAB2;
Modified table.
SQL > alter the indexing system. DSUBEXI1 reconstruction tablespace IEFSENCY_IDX2;
The index is modified.
SQL > alter the indexing system. DSUBEXI2 reconstruction tablespace IEFSENCY_IDX2;
The index is modified.
SQL > alter the indexing system. DSUBEXI3 reconstruction tablespace IEFSENCY_IDX2;
change the indexing system. DSUBEXI3 reconstruction tablespace IEFSENCY_IDX2
*
ERROR on line 1:
ORA-01652: unable to extend segment temp of 128 in tablespace IEFSENCY_IDX2
How can I solve this error?
Thank you
BEA.
ORA-01652: unable to extend segment temp of 128 in tablespace IEFSENCY_IDX2
Published by: user641364 on 17-Apr-2009 05:22
Well, I did add the new data file in the IEFSENCY_IDX2 tablespace, I guess I should calculate the size of the index to rebuild
Published by: user641364 on 17-Apr-2009 05:57This is exactly the solution. Consider defining new storage pamateres if you like to shrink space
-
How to create a table with spaces between the lines...
Hello
I use jdev 11.1.1.6 and I need to insert spaces between the lines. How this can be done?
Thank you and best regards,
Tarun AgrawalHello
I'm sorry to forget on the spacer. You must use css like mentioned AP.
Arun-
-
The cache/pin layout tables and indexes - Howto?
Hi all
I touched upon a request by a seller of BEDS to do something I'm not terribly familiar with... they want to "hide" or "pin" a table and an index in memory.
I was looking and saw something to the effect of making the Table1
ALTER TABLE Table1 in CACHE;
However, the seller has been mention some examples that seem to indicate the creation of a pool of Dungeon (a pool of buffers separate cache?).. and then doing something like
ALTER TABLE Table1 STORAGE (USER_TABLES KEEP)
Can someone give me an idea as to the difference between these two concepts... links on how do, etc.?
Thanks in advance!
CayenneHello
There are 'rules' to pin the tables and indexes. The Oracle documentation states:
"A good candidate for a segment in the pool of the DUNGEON is a segment that is smaller than 10% of the size of the DEFAULT buffer pool and has suffered at least 1% of the total i/o in the system."
Here are the rules that I use:
-Cache tables & indexes where the table is low)<50 blocks)="" and="" the="" table="" experiences="" frequent="" full-table="">
-Cache objects that use more than 10% of the size of the data buffer.
Here is the script I use to automate the assignment of the tables in the pool of DUNGEON.
ATTENTION: This script is not for beginners:
http://www.rampant-books.com/t_oracle_keep_pool_assignment.htm
I hope this helps...
Donald K. Burleson
Oracle Press author
Author of "Oracle Tuning: the definitive reference".
http://www.rampant-books.com/book_2005_1_awr_proactive_tuning.htm -
Please see my table
No I haven't added some data in the table. My problem is that it does not index between the query.create table DATE_TEST ( ID VARCHAR2(6) not null, ID_DESC VARCHAR2(250), START_DATE DATE, END_DATE DATE ); -- Create/Recreate primary, unique and foreign key constraints alter table DATE_TEST add constraint DATE_TEST_PK primary key (ID); -- Create/Recreate indexes create index DATE_TEST_IDX1 on DATE_TEST (END_DATE)); create index DATE_TEST_IDX2 on DATE_TEST (START_DATE);
Why it does not index and what are the other solutions for thisEXPLAIN PLAN FOR SELECT * FROM DATE_TEST WHERE start_date between to_date('01/01/2012','DD/MM/YYYY') AND to_date('31/12/2012','DD/MM/YYYY') OR end_date between to_date('01/01/2012','DD/MM/YYYY') AND to_date('31/12/2012','DD/MM/YYYY') 2 / Explained SQL> SELECT * FROM TABLE( DBMS_XPLAN.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 4189439861 ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 954 | 139K| 7 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| DATE_TEST | 954 | 139K| 7 (0)| 00:00:01 | ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("START_DATE">=TO_DATE(' 2012-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "START_DATE"<=TO_DATE(' 2012-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss') OR "END_DATE">=TO_DATE(' 2012-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:s Note ----- PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- - dynamic sampling used for this statement (level=2) 21 rows selectedYour query does not take the index because the cost of FTS is lower than that of the index analysis...
You could put a TIP if you want to force the use of the index - which is NOT ADVISED.
-
Change the color of track between the sliders?
I tried to figure this out, but nothing helped. Here's what I would do:
I use the cursors on a XY trace to read information only between the sliders for additional data (made with property nodes and base Subvi I wrote to print the table of points between the sliders). It works very well. What I want to do (i.e. my boss
 ) is to have the color of the line between the change of cursors by a different color than the rest of the data track. I tried a few things from property node, but nothing worked. Anyone has a suggestion (if that is even possible)? Thanks in advance.
) is to have the color of the line between the change of cursors by a different color than the rest of the data track. I tried a few things from property node, but nothing worked. Anyone has a suggestion (if that is even possible)? Thanks in advance.Since you have already recovered the data of interest, the hardest part is done.
You now need to split the existing parcel into two unique parcels.
The first will be as many points as the complete data set, but all the points that are not inbetween the sliders will be replaced by "NaN" so that they don't draw.
The second will be similar, but the values of interest will be replaced by NaN.
When the two are drawn using different colors, you will get what you want.
You may need to fidle ot a bit on the edges if the boss wants it looks like the plot connects and keep in mind, the first plot is "high".
Ben
-
I'm looking for Custom table and index
Hi Hussein;
I want to find tables and indexes in the APPS schema. All custom tables and index begins with ZZ...
I try to type this query, but its bring many record a lot, where I am not mistaken. And can not find the query for custom index.
Select a.table_name, a.owner, d.CREATED
from all_tables an inner join dba_objects d on
a.OWNER = d.OWNER
where table_name like '% ZZ' and 'a.OWNER =' APPS
Thanks for the tipsHello
You do not have to join, ask just DBA_OBJECTS (where type_objet = 'TABLE' and object_name like '% ZZ') or (where object_type = 'TABLE' and OWNER = "CUSTOM SCHEMA"). If you follow the standards of customization, custom tables/index should exist under the custom schema (and not under APPS schema).
Kind regards
Hussein -
What is the preferred means of data transmission in the associative array of the nested table record vs
Choose between Nested Tables and associative arrays
The two nested tables and associative arrays (formerly index - by tables) use similar index notation, but they have different characteristics when it comes to persistence and ease of passing parameters.
Nested tables can be stored in a column of data, but can of associative arrays. Nested tables can simplify the SQL operations where you would normally join a single-column table with a larger table.
Associative arrays are appropriate for relatively small lookup tables where the collection can be constructed in memory whenever a procedure is called or a package is initialized. They are good for the collection of the information volume is unknown beforehand, because there is no fixed limit on their size. Their index values are more flexible, as associative array indices can be negative, can be no sequential and can use values of string instead of numbers.
PL/SQL automatically converts between the bays of the host and the associative arrays that use values of digital keys. The most effective way to move the collections to and from the database server is to implement data values in associative arrays, and then use these associative arrays with erections in bulk (the
FORALLstatement orBULKCOLLECTclause).With the help of documents and Collections of PL/SQL
Read this:
-
Cannot create indexes on the flow table
Hello
I'm new to ODI.
The problem is that during the execution of an interface, I get the error of the "IKM Oracle Dimension to slow variation"
The command in step "Create unique index on the flow table:
creating index < % = odiRef.getTable ("L", "INT_NAME", "A") % > idx
on < % = odiRef.getTable ("L", "INT_NAME", "A") % > (< % = odiRef.getColList ("", "[column]", ",", "", "SCD_NK") % >)
< % = odiRef.getUserExit ("FLOW_TABLE_OPTIONS") % >
generate the following statement which lacks the name of the column between the (_)
Create index I$ _MYTABLE_idx
I have $_MYTABLE)
NOLOGGING
The result is that the interface fails with the error 936: 42000: java.sql.SQLException: ORA-00936: lack of expression caused by the previous command wrong.
Please, can you help me?
Thank you very much
Angelo
Hello
I'm really really sorry! I just realized that you are working on the SCD. Basically, you are looking for all the column mapped as SCD_NK (key to slowly change natural Dimensions) insofar as shown here
IF you need to read this
Let me know.
-
Findout incompatibility records between the two tables.
I need help on findout the unmatched records between two different tables.
Each table has a + 42Crores Records.
The type of data (Char) are the same for the two tables but datalength is different between a table and the table B.
Indexes are created on the two tables on the required fields
There is no Geom data exists on the two tables.
For example:
A Table: =.
Number of records + 42Crores
Rating: TOLD char (20)
Table B: =.
Number of records + 42Crores
Field: TOLD Char (16)
I took individual accounts, there are number of difference is 3868 only, with respect to the count (*) selection.
I ran the query "Select TOLD OF A LESS SELECT TOLD OF B", but I don't have the answer.
Please let me know how to solve the problem.The variable length char shouldn't be a problem...
You just need to ensure that the first table has more lines than the second, if the problem persists You ' l I hide it, and then use a column alias...Let know us...
-
sorting table, how to get the new index of the last value?
Hi all!
I use a Subvi, which adds a cluter of the parameters to an array and then sort this table by one of the parameters in clusters.
It works very well, with examples, that I found in this forum

but now, I would like to know if it is possible to obtain at the end of the new cluster index first added.
See attached VI
Thank you
You take the size of the table and insert the new element to this level is anything other than the table of construction and a simple construction would do that.
In your question, I assume you're asking on the index of the item that you inserted after the sorting of the table, right? In this case, you can compare the cluster element that you introduce to the initial with the cluster table you get after a sorting of the table. This will give you the index of the item that you insert at the start.
-
Search index of the secuence valuation until you reach a constant value table...
Hello
I have an arry of secuence RR values (its peak at the time of peak of ECG wave is seconds). I know that the added value of the paintings is the total time of sample data.
I would like to separate in different charts in the representation of every hour of recorded data.
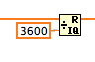
I need to get a way to get the index where the number of added values are-online 3600 s (1 h).
So that I can know the index of the arrays values to get the correct index in chart 1 h values, another index for another hour for an another graph,... so until you get the hourly chart several data can show.
I hope you understand me.
Best regards.
Modulo division is performed by the function Quotient & remains on the digital palette.
Work with tables and data DBL or integer types.
When I use the method that Mike designed, in my view, the VI sometimes lacks a time transition. This happens with the simulated data that I generate because it is possible that the rest is different from zero. For example, this can happen if the accumulated sum is 3599.4 s and the next RR interval is 1.3 s. Which gives the following sum = 3600.7 s. The conversion by multiples of the amounts of 3599 and 3601. The remains are 3599 and 1 after modulo division. None are exactly equal to zero.
I've changed this option to use DBL and then look the big negative transition. The minimum value may be with the largest range of RR in the data. However, there is always a great transition close to 3600 to near zero.
Lynn
-
Hello
I have a loop 'for' which can take different number of iterations according to the number of measures that the user wants to do.
Inside this loop, I'm auto-indexation four different 1 d arrays. This means that the size of the tables will be different in the different phases of the execution of the program (the size will equal the number of measures).
My question is: the auto-indexation of the tables with different sizes will affect the performance of the program? I think it slows down my Vi...
Thank you very much.
My first thought is that the compiler to the LabVIEW actually removes the Matlab node because the outputs are not used. Once you son upward, LabVIEW must then call Matlab and wait for it to run. I know from experience, the call of Matlab to run the script is SLOW. I also recommend to do the math in native LabVIEW.
-
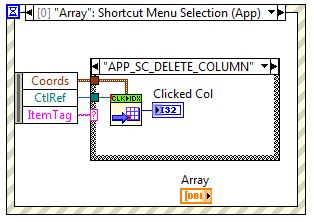
Get the index of the column of table removed
Is there a way to get the index of the column in a 2D table that has been deleted? In my application, the user has the possibility to use the right click option 'remove a column' on a 2D picture, but I would like to use this information to remove the same column in a different table programmatically. Is this possible?
There is a file published in the documents of the community that refers to a location in a sheet of the user has clicked. Use it like the image below.
https://decibel.NI.com/content/docs/doc-22434
-
Clear on how the table of Index OpenG works with a 2D Arrray
Hello
I don't understand how to use the undex OpenG table with a table entry 2D. I joined the contest help window, said that aid
"For 2D tables, connect the clues and indices 0 1 entries to specify the items you want.
So what does really mean? I wired the vi as requested and the vi always puts a 1 d table. So are the lines of entries in table two indexes and columns or what?
I am sure that you send in your line indices table and the table of the column indices and get out of your table 1 d of elements.
(i.e. rank table [1,5,7] and table column [4,8,10] gives you a table 1 d elements (1,4), (5.8), (7.10))
Maybe you are looking for
-
Why a trail shaded in an album of my friends?
Why a track appears dimmed in an album of my friends, and what that means? iTunes can play the track if you click on it, but if it comes after another track iTunes jump it! I have the latest version of iTunes.
-
How can I disable the printed confirmation email?
It is a 'feature' cute, but I don't need more junk emails!
-
I'm looking for 'Windows install cleanup utility' for Vista Home Pro 64-bit
-
get the status of 4500 printer wireless hp envy line after changing the wireless router.
I use 8.1 window and I want to HP 4500-e printer all in one and all a works very well. My wireless router was going bad, so I replaced it. After the installation of the new router and get all my computers and devices (including the hp 4500 wireless p
-
cleaning windows rigstry and temporary internet files
Hi guys * today im bought a new Professional edition ccleaner and it offer to a registry clean then advise you that while I have a bad history with Advanced systemcare?