Table optimizatioin of construction
I suspect that my table/matrix construction begins to inhibit data collection. I'm currently collecting spatial data of the image. To collect spatial data of the pannel (gui) before I am establishing data of bad coordinate of a XY Chart with a background image. The sub vi reportoire start tent to prepare the Cartesian coordinates to set motion in the scene.
How can I accumulate more effectively X, Y/horizontal, vertical/coordinate/pixel location etc. information of a given image. In this vi I try to do it by building a table with data from bad. The Zth deminsion can be moved.
Thank you very much
I changed to aray of writing in a file which I think works well. A bit of trouble with my table zth but resolved question.
Tags: NI Software
Similar Questions
-
External table-> fetch location?
With the help of Oracle 10.2.0.5
An external table is a construction that gives me access SQL to a file.
Is it possible to know the name of the file somehow inside to select? Like to add a column with the name of the file?
example of Pseudo
The result might look like this:CREATE TABLE EXT_DUMMY ( "RECORDTYPE" VARCHAR2(100 BYTE), "COL1" VARCHAR2(100 BYTE), "COL2" VARCHAR2(100 BYTE), "FILE" VARCHAR2(100 BYTE) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_LOADER DEFAULT DIRECTORY "IMPORT_BAD_FILE" ACCESS PARAMETERS ( records delimited BY newline FIELDS TERMINATED BY ';' MISSING FIELD VALUES ARE NULL ( RECORDTYPE CHAR , COL1 CHAR , COL2 CHAR , FILE CHAR FILLER ) ) LOCATION ( 'Testfile1.txt, Testfile2.txt' ) ) reject limit 10 ;
I would like to know what file is read a certain rank. Maybe I missed an option in the documentation. In this example, I have two different files as the source for the external table.RECORDTYPE COL1 COL2 FILE SAMPLE DUMMY DUMMY Testfile1.txt SAMPLE DUMMY1 DUMMY Testfile1.txt SAMPLE DUMMY2 DUMMY Testfile1.txt SAMPLE DUMMY3 DUMMY Testfile1.txt SAMPLE DUMMY1 DUMMY1 Testfile2.txt SAMPLE DUMMY1 DUMMY2 Testfile2.txt SAMPLE DUMMY2 DUMMY1 Testfile2.txt
Another use case could be that:
If I enable a user to switch the external table to a different file
. How do know us which file is read during the select on the table? When UserA's select, perhaps UserB just modified the location before that selection has been started. That's why UserA reads in a different file than expected.alter table EXT_DUMMY location ('Testfile3.txt' )
Published by: Sven w. on May 26, 2011 16:48
Published by: Sven w. on May 26, 2011 16:51
Published by: Sven w. on May 26, 2011 17:11Hi Sven,
I don't know how much we can rely on that, but we will consider the following:
create table test_xt ( rec_id number , message varchar2(100) ) organization external ( default directory test_dir access parameters ( records delimited by newline fields terminated by ';' ) location ( 'marc5.txt' , 'test1.csv' , 'test2.csv' , 'test3.csv' ) );I always thought that the ROWID doesn't hold much meaning for an external table, but...
SQL> select t.rowid 2 , dump(t.rowid) as rowid_dump 3 , regexp_substr(dump(t.rowid,10,9,1),'\d+$') as file# 4 , t.* 5 from test_xt t 6 ; ROWID ROWID_DUMP FILE# REC_ID MESSAGE ------------------ --------------------------------------------------------- ------ ---------- ------------------------------- (AADVyAAAAAAAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,0,0,0,0,0,0,0,0,0 0 1 this is a line from marc5.txt (AADVyAAAAAAAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,0,0,0,0,0,0,0,0,33 0 2 this is a line from marc5.txt (AADVyAAAAAAAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,0,0,0,0,0,0,0,0,66 0 3 this is a line from marc5.txt (AADVyAAAAAAAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,0,0,0,0,0,0,0,0,99 0 4 this is a line from marc5.txt (AADVyAAAAAEAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,1,0,0,0,0,0,0,0,0 1 1 this is a line from test1.csv (AADVyAAAAAEAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,1,0,0,0,0,0,0,0,33 1 2 this is a line from test1.csv (AADVyAAAAAEAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,1,0,0,0,0,0,0,0,66 1 3 this is a line from test1.csv (AADVyAAAAAEAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,1,0,0,0,0,0,0,0,99 1 4 this is a line from test1.csv (AADVyAAAAAIAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,2,0,0,0,0,0,0,0,0 2 1 this is a line from test2.csv (AADVyAAAAAIAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,2,0,0,0,0,0,0,0,33 2 2 this is a line from test2.csv (AADVyAAAAAIAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,2,0,0,0,0,0,0,0,66 2 3 this is a line from test2.csv (AADVyAAAAAMAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,3,0,0,0,0,0,0,0,0 3 1 this is a line from test3.csv (AADVyAAAAAMAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,3,0,0,0,0,0,0,0,33 3 2 this is a line from test3.csv (AADVyAAAAAMAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,3,0,0,0,0,0,0,0,66 3 3 this is a line from test3.csv (AADVyAAAAAMAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,3,0,0,0,0,0,0,0,99 3 4 this is a line from test3.csv (AADVyAAAAAMAAAAAA Typ=208 Len=17: 4,0,0,213,200,0,0,0,3,0,0,0,0,0,0,0,132 3 5 this is a line from test3.csv 16 rows selectedThen with a join to EXTERNAL_LOCATION$:
SQL> with ext_loc as ( 2 select position-1 as pos 3 , name as filename 4 from sys.external_location$ 5 where obj# = ( select object_id 6 from user_objects 7 where object_name = 'TEST_XT' ) 8 ) 9 select x.filename, 10 t.* 11 from test_xt t 12 join ext_loc x on x.pos = to_number(regexp_substr(dump(t.rowid,10,9,1),'\d+$')) 13 ; FILENAME REC_ID MESSAGE ------------ -------- -------------------------------- marc5.txt 1 this is a line from marc5.txt marc5.txt 2 this is a line from marc5.txt marc5.txt 3 this is a line from marc5.txt marc5.txt 4 this is a line from marc5.txt test1.csv 1 this is a line from test1.csv test1.csv 2 this is a line from test1.csv test1.csv 3 this is a line from test1.csv test1.csv 4 this is a line from test1.csv test2.csv 1 this is a line from test2.csv test2.csv 2 this is a line from test2.csv test2.csv 3 this is a line from test2.csv test3.csv 1 this is a line from test3.csv test3.csv 2 this is a line from test3.csv test3.csv 3 this is a line from test3.csv test3.csv 4 this is a line from test3.csv test3.csv 5 this is a line from test3.csvSeems to work... assuming that the files are always read in the order specified by the LOCATION parameter and the ID generated actually means what I think it means.
-
Is it possible to have a button that will insert a line of table rather than add at the end?
I have a button Add line that works correctly using addinstance, but I would like to have the line button Add at the end of each line, if a user can insert a line in the middle of the existing/fiilled of lines. Is this possible? I would like to be able to do this using Formcalc because that's what my script in the form currently complies.
Hello
Yes, it is possible, but actually doing just that the script is to add a new line at the end of the table AND then move the line to the appropriate position.
See examples here: http://assure.ly/gk8Q7a. Table 5 is a Table object, while table 6 is constructed using subforms. In both cases, the Index number is a button, which adds a line below the existing one clicked.
See who helps me to,.
Niall
-
Implementation of dumps for several table
Hello
Is it possible to configure the < dumps-plan > element or implement dumps to get data from multiple
table. Currently the sample xml and dumps in the tutorial is configured to a single table.
Thank you
-TrapaniHi Thiru,
As Rob mentioned, you can implement dumps to do just about anything you want: do a join between tables, run several queries for data from multiple tables or even access non-base data system, such as an existing system or a web service to retrieve the data. Consistency really cares how you implement your cache store and where you get the data, as long as you return a single object to the load method, which must be inserted in the cache the cache store is set up for (or in the case of loadAll, many objects in a map).
However, what I didn't understand not your question is if you want to load the data of several related tables to create a single object (an aggregate in DDD terminology), or if you want to create different entity objects based on the data in each table and put them all in the cache. Normally, you should have a cache by entity type, while the latter is discouraged until you know exactly why you do and are recommended to create a separate for each entity type cache and use different cache stores for them. Otherwise, you will encounter issues if you try to index your cache or run queries on it, because these characteristics depend on the schema of compatible entry.
However, if you load an aggregate, you can decide to store the entire aggregate object in a single cache, in which case you will probably eventually query several tables related to construct an instance of an aggregate, or you may decide to store root cluster in its own cache, and separate the low related entities in caches, once again a cache by entity type. The choice should really depend on the size of small entities within an aggregate and access model data, so it is difficult to provide general guidance. However, if you do not end up storing weak entities in separate caches, it is usually advantageous to use the key association to ensure that they are located in the same partition as their aggregate root.
Kind regards
ALEKS -
not enough memory to complete the operation
I looked in the forums for "memory to complete operation" error and despite the advice that I found, the error always happens.
I'm using LabVIEW 2012 to try to constantly monitor our system, recording temperature, power, etc. vs time (values obtained by acquisition of data USB-6008). The data being saved to file, is every 60 seconds using a small table (no problem here). Allocation of memory time/sleeves typical LabVIEW is about 180 MB (4 GB of RAM on computer).
The issue that I feel is related to our wish to display these data on a chart for long periods of time. The current iteration of the code works as follows.
(1) we have 2 XY charts with 2 slots of each.
(2) for each parcel, I'm initialization of clusters of berries of 2 100 000 (XY pairs) that are related to the shift registers. I know it's bigger that can be displayed on a chart, but I am currently more concerned with reducing the number of data copies.
(3) every 10th data point is added in the tables using one up Bundle/Unbundle element with a 'subset of table replace. " In other words, there are about 8640 points per day. (One day is the shortest duration usually read)
(4) for the two traces on a XY Chart, two groups are combined in a table (using the table to build). I think that's my problem here. Since every time I update the charts that LabVIEW must allocate memory for the 4 XY plots. (I'm correct here?)
Decimating the additional data during research on several days will reduce the amount written in the plots. However, this creates copies of data. It is useful in this case?
Instead of initializing 4 groups (1 for each plot) and combining in the tables later, it would be better to initialize the array of clusters of berries (2 lots per chart) and update the data by "index / unbundle / replace the subset of table / bundle replace table subset" series of operations?
Nothing obviously bad jumps to my, but this could be why it works for days sometimes. A few things to try:
(1) the section where you overwrite the oldest 3600 data points and rotate tables has code to initialize a new table. I propose this initialization outside the loop to make sure that only do you it once. You could always simply replace the elements in the table with a value of NaN.
(2) I would try to get rid of the build tables as you pointed out. Initialize these berries outside the loop and replace components as appropriate.
(3) build you tables of Irr and time according to the table of the construction and reset them once / day. You can try those external booting as well.
(4) If a problem occurs and the file write crashes your queue can fill. The dequeue item is already waiting for data before it does anything, so I don't think you need the delay in the same loop. This could help the dequeue catch up if the queue is large. You can use a vi Get Queue Status to display the number of items in the queue on the screen. As long as it is not hidden by the error message it could give you an idea if the queue is the cause of your error. You can also access the queue size to see if it develops.
(5) If your data acquisition loop error handling is not good, a mistake it can cause the loop to run as fast as possible. If you have added the 1000ms wait just to show that this is not a gourmet loop, so this could easily be the cause. I do not think that the Renault USB are very reliable, so try to use a days may run into this error.
I hope that it becomes at least you said in the right direction. My bet is on #5

-
I want to just combine all three signals can display in the chart, how to do? (Not of three separate signals)
Well, double click on Convert of Dynamic Data and choose ' 1 D array of scalars - automatic"for all three. Then, right click on the table of the construction and make sure you that concatenate entry is checked.
-
How to read the txt file that has words in between?
Hi all
I'm using Labview 8.2.
I would like to read a text file. I have given (after whenever he was on average more than 100 waveforms) several times recorded on the file. The idea is to further improve the SNR in post processing by averaging once again the data (which was on average about 100 wave forms).
I can get LabView to save the data in the file several times, then it keeps joins.
The problem is to read data from labview, so I can on average now again. The problem is the labview separates data sets with the following:
"Channel 1".
9925 samples
Date 28/10/2008
Time 17:16:11.638363
X_Dimension time
X 0 - 3.0125000000000013E - 3
Delta_X 2.500000E - 6
"End_of_Header."Then when I read it, he sees only the first set of data.
Can someone tell me please how to read all the datasets under labview?
I am attaching the file I want to read 'acquiredwaveform.txt' and the VI base (really basic btw) to play the file.
Thank you
This seems to be a standard LVM-file. You can read segments of different data using the VI Express LVM loop (make sure that the file retains its extension .lvm). I modified your example to show this.
Note that my example is quite inefficient. Table of primitive construction causes a massive memory copy whenever it is used, and you would be probably better on average that you read in. I made this way to make it more obvious how read segments of a file LVM. In the process, I noticed that you have a good amount of phase jitter (zoom in on the graph of all the three waveforms). With an average simple will make you smear on your waveforms. You can either fix the problem in hardware (recommended) or phase shift your data so it lines up before on average. If you need help with it, let us know.
-
problem with timing cRio and FPGA
Hello
I develop software for measure the position of a device using some quadrature encoders.
What I do uses the FPGA interface to acquire the position, then send usign real number of the meter to a host pc to create a data file. In the RT environment, I create a table with the position and the time that is acquired and using shared variables I send the array to the host PC.
But I have a problem with the sync. The sampling time is unstable, I use a timed loop to control sampling but after some acquisitions, data sampling period begins to increase, as you can see in the image of attachment file. In the attached picture, I used a period of 250us and after some time gets twice and 3 times longer before you clean the table and begin to create a new table, during the period in 250us again. so the problem is that I should get a stable period in 250us instead of these steps in growing period
You use the table of construction to add new data points? I suggest to use the function "Initialize the array" and "replace the array element. It will reduce the time it takes from the table of the construction.
I can't open your code as I have LabVIEW 2010.
-
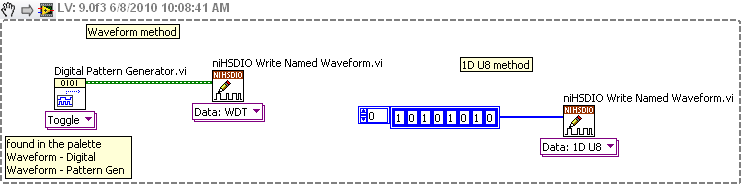
How to generate signals using NI - HSDIO.
Hello
I need to create two signals different pulse square. I don't know how to set their frequencies, number of cycles and FRP using NOR-HSDIO.
Thank you!!
You must create a set of data to send to the HSDIO. It only builds what you send to it. Suppose you want to produce a square on one channel wave. Implement the HSDIO for right channel, trigger, timing, etc. Look at the function HSDIO write nominated Waveform. It says name of waveform, but you can use the polymorphic selector (the area under the function) to select other types of data outside of the waveform, i.e. a table 1 d of numeric (U32, U16, etc.). You must create an arry of data that would be akin to a square wave. Or you could use the input waveform and create a square wave.
The simplest is the waveform because Labview waveform generator functions available. See the image below. If you want to use table 1 d, construct you a table or alternation of 1 and 0 to produce a square wave. The image below is only a partial code. Need to add the rest of the installation HSDIO functions.
-
Order that SQL Developer Modeler generates objects in DDL download
Little annoying question... When I have an existing data model that includes all of my table definitions and ALSO my package definitions, I try to make a DDL download and load it into an instance of Oracle 11g and get an error on a procedure declaration does not have a column type.
What I see is when I open the prepared ddl script, the package is created until the table is under construction. Is it possible I can tell SQL Developer Data Modeler to build like objects together (table, then sequences and then triggers and packages and procedures/functions?
SQL Developer Data model version 4.1.3 Oracle database 11g r2...
Thank you
Tony Miller
Los Alamos, NMHi Tony,.
Data Modeler generates at the beginning of the Package definitions in the DDL file, so that they appear before the objects such as Tables, views, and triggers that may refer to them.
And the Package body are generated at the end, so that they can refer to Tables and views.
Unfortunately there is no option to change the sequence of generation.
In general, the Data Modeler takes dependencies between objects into account to generate the DDL file objects in a proper order.
However, it does not detect the dependencies TYPE %. I connected an enhancement request to add to its dependency checking (22581821).
Kind regards
David
-
Hi all
If we are given two berries sorting, X and Y and X has a big enough buffer at the end of stay there.
How can merge us Y X in a sorted order.
X = (1,4,7,8)
Y = (2,5,6)
output: 1,2,4,5,6,7,8
Thank you
Rambeau
This is a table... so a table is a construction that has a number of elements.
The presentation of an array is can be done like this:
SELECT listagg (COLUMN_VALUE, ',') WITHIN GROUP (ORDER BY COLUMN_VALUE)
IN my_string
table (z);
sys.dbms_output.put_line (my_string);
HTH
-
In fact, what is a constraint?
Why the necessary constraints?
And what are the different types of constraints available in Oracle SQL?
Published by: Tejaswi.B on January 11, 2011 12:39 AMConstraints of 'forcing' the data values that you will allow to be in your database.
Once defined/declared, the DBMS will uphold them.In the perspective of theory of database, constraints can be classified as follows.
-Constraints attribute (column).
Here are the constraints that limit the unique values of a column.
For example: gender equality must be male or female.
SQL CHECK construction can be used to implement this kind of constraints.-Tuple (row / column camps) constraints.
Here are the constraints that limit the combinations of values in two or more columns (in the same row).
For example: presidents should earn a salary that is more than 8,000.
SQL CHECK construction can be used to implement this kind of constraints.-Table constraints (multi line).
Here are the constraints that limit the combinations of lines in a single table.
For example: impossible to have more than one president in the emp table.
The construction of the SQL STATEMENT can be used to implement this kind of constraints.
However: this construction is not taken in charge or delivered by any provider of DBMS (Oracle included).
We have special syntax for certain subclasses of table constraints that occur frequently in database designs: especially the KEYS (primary/unique).-Database constraints (multi table).
Here are the constraints that limit the combinations of lines between two or more tables.
For example: The Sales department can use trainers.
The construction of the SQL STATEMENT can be used to implement this kind of constraints.
Is not yet available...
We have special syntax for frequently occurring subclass of database constraints: the foreign key.In a perspective on database constraints are ideally implemented within the DBMS.
-Of declaratively when possible.
-Procedurally otherwise. It comes to generate triggers to enforce them.
(or using tricks with materialized views and the function index for special cases). -
My table Table have this construction:
NAME TYPE
IDENT_NR NOT NULL VARCHAR2 (40)
DATE NOT NULL
TIME NOT NULL NUMBER 4
.
.
Is what I want to select the last time on the last day:
Select ident_nr,
substr (LPAD (Time, 4, 0), 1, 2). substr (LPAD (Time, 4, 0), 3, 2) time.
to_date (date, 'dd.mm.yyyy') date
of v_scans_all
If date between to_date ('20.12.2010 ',' JJ.) MM YYYY') and last_day (to_date ("'21.12.2010', ' dd.mm.yyyy"))
and ident_nr = '00340434121154000033'
Group ident_nr, date, time;
The result is:
DATE OF IDENT_NR TIME
---------------------------------------- ---- --------
00340434121154000033 0705 20.12.10
00340434121154000033 0706 20.12.10
00340434121154000033 0712 21.12.10
1609 00340434121154000033 21.12.10
I only need the last test (21.12.10 / 1609), because this is really the last event. It must be something like a combination of Date and time. Any idea?
Thank you very much. Joerg
Edited by: user5116754 the 21.12.2010 12:07
Edited by: user5116754 the 21.12.2010 12:11Hello
user5116754 wrote:
Thank you for quick help.
Unfortunately, I have no possibility to change the version of the client. I work here for only a short project :(It's ridiculous! The upgrade is something that needs to be done; not to do so is a breach of your work now, it will have lasting benefits after this short project is completed, and it only takes a few minutes.
So my question is: is there an option to combine the fields "reference" and "time" in order to get the last scan event?
What is wrong witht the online solution view I posted earlier?
as:
Max(Datum||) Zeit)Almost; you would need to put in the form of reference so that it sorts correctly (for example, January comes before February, even if 'J' comes after 'F')
You also need to format time, so that it sorts correctly (for example, the 959 comes before 1000, even if 9 'comes after 1').MAX ( TO_CHAR (datum, 'YYYYMMDD HH24MISS') -- Assuming datum is always in the Common Era || TO_CHAR (zeit, '9999') -- Assuming zeit >= 0 )But you still have the problem of how to get the ident_nr linked to the final value. I don't see how to convert a different type of data reference and time will help you.
.. .or is it possible to format a date in a number consecutively (.. .as Excel...)
Yes, you can convert it to a single NUMBER. Depending on what you want, you can call TO_NUMBER results in "TO_CHAR... | To_char... ", as stated above. It will be more work for no purpose.
-
Cell borders are not displayed in firefox
I have a table (actually several different pages) nested within an editable region on a page based on templates. Cell borders are set to black 1 px on 2 tables and 1 background color of px on 4 tables. In IE7, the tables display correctly with all cells bordered. In Firefox and Opera, show that the external borders of the table. The construction of the painting is necessary because it is really the data that should be displayed as a table. However, the model, is a nested table.
Unfortunately the site is not powered, so I can't show you what is happening. I would be grateful for any input on this problem.
BarbaraThanks for the help. I solved my problem by guess and check method. The table borders were applied in the properties area. When I went back and replaced by CSS formatting, all lines are displayed.
The moral of this story is 'Use CSS!'
Barbara
-
Construction of a 2D on a 2D table array
Hello
I have a problem in the construction of table 2D. Currently, I have a 2 x 3 2D chart. I would build a table to 2 x 6.
Example [1 2 3 and [7 8 9 [1 2 3 7 8 9
[[4 5 6] 1 2 3] 4 5 6 1 2 3]
I tried to use inserts the table but its actually not seems to work because I place the index finger at the col 3, during the insertion of the second table 2D. I wonder I have a reached for a table of 2 x 6. I appreciated if someone could help me? Thank you very much.
Here's a solution, I came with.
I don't know if it's the best/worst way to go, but it does the trick


Maybe you are looking for
-
Satellite C650D - specifications of the WiFi chip and webcam
Hello does anyone have full specification 15.6 notebook hw Satellite C650D with AMD E-350 Fussion? I need to know what chip webcam and wifi chip is on the Board.
-
This is the next line of the notice of incorrect application: Cookie: KHcl0EuY7AKSMgfvHl7J5E7hPtK=GHTVLUGh5zG6ks5hQWppXUzKMtAShup_fASN8YQad3cnqeDew0f_tkIm3U_5XpNp-wxqAdKqenee2IrN; cookie_check=yes; consumer_display=USER_HOMEPAGE%3d2%26USER_TARGETPAGE
-
When I download an exe file, I want it to work not be saved, how can I do this?
I click a link to install a program (.exe file). Only option of Firefox is to save the file. I want to be invited for a Run/Save option (same as IE).
-
Who can call my number online?
I live in the South, New Zealand island. The nearest major city in the South Island is: Christchurch and I can buy an online starting with the prefix 03 number. Can people from other parts of my country call me on my number online, for example from A
-
Equium A100 - 027 Vista: the screen goes black for just 1 second
I was wondering if anyone here can tell me what is the problem with my laptop. That's all new Toshiba Equium A100-027. Quite often, my screen will turn black for just a second, and then it will return to normal again. I changed my power settings, so