The difference between targeted source vs trust reconciliation?
Hello!Can someone explain to me in one "for the fate of the mannequins in a way" or "for example" what is the difference between
Trusted source reconciliation and reconciliation of targeted resources?
I found this explanation on the Oracle, but I still do not understand the difference:
Reconciliation of targeted resources:
occurs when the audit criteria make up the demand for resources or change access real insurance of resources put into service or lack thereof in a query ad hoc bases.
Reconciliation of reliable source:
occurs when the audit criteria is close to a main point of truth, validation of the status of the access of resources against the policy of the company.
Thank you very much
http://download.Oracle.com/docs/CD/E11223_01/doc.910/e11217/processes.htm#sthref78
Confidence:
In this case if no match is found then it will create the user to IOM.
Suppose that the user with Userid JMD1 is at AD but not with IOM. When we execute AD Trusted Recon, then it will search JMD1 in IOM. If it does not find any user with username JMD1 in IOM then it will create the user to IOM.
Target:
It cannot create a user of IOM, but it can make the link between IOM and the AD users.
You can check this link in the resources of any user profile.
Assume that JMD1 is in AD, but not with IOM. When we run target Recon for AD. Then he will not find any user with username JMD1 in IOM so he won't do anything. This is called the orphan account.
Now JMD1 resided at the IOM as well as in the AD. Then it will create a link between IOM and the AD users. Just go to IOM JMD1 resource profile. You can see that ANNOUNCEMENT will be in the State enabled for this user. He manages the account not the identity.
Tags: Fusion Middleware
Similar Questions
-
What is the difference between full and progressive reconciliation?
Hi gurus,
I'm new to IOM can someone tell me the difference between these two? Thanks in advance.http://download.Oracle.com/docs/CD/E10391_01/doc.910/e10374/dployconfig.htm
-
Hi Expert,
First of all, thanks for reading my question...
I am new to HFM and need help with writing a rule to assign the difference between the end of the period (EOMRate) and (AVGRate) average for foreign translation account currency (FCTRS):
Requirements of the rule:
1. go to the base to all entities that are non-AUD (Parent entity is denominated in AUD)
2. work on the difference between EOMRate and AVGRate rates
3 multiply the difference with the account of profit after tax (IE PAT)
4. this amount should be included in the account of FCTRS (IE 9115)
Rule I wrote, who dislikes the HFM:
If HS. Entity.IsBase("","") = True and HS. Value.Member <>'AUD' then
HS. Exp ' a 9115 # = a #PAT * difference ("AVGRate", "EOMRate").
End If
AVGRate and EOMRate that I'm looking rates in C2. This rule gave a certain number of attempts, but without success. Would appreciate expert you worldwide HFM...
Thanking you in advance.
The f
Hi Jeff,
I think you need to use the sub translate and do some additional calculations.
You can start by adding the translation of this rule in the sub and the system will calculate the difference: HS. TRANS 'movement of the target, Source movement, EOMRate, AVGRate. For the rest of the needs, just adapt the above rule...
Kind regards
Thanos
-
In the settings of Firefox 33.0 (I use Ubuntu 14.04, but the functionality is the same for Windows 7) there are two ways to delete cookies when firefox closes. Or at least, there seems to be.
Is first the cookies keep until firefox is closed
Second is to check the box for clear history of firefox closing and in the settings check cookies.
What is the difference between these two options?
I usually have two configuration but I noticed that a connection was not save for td canada trust EasyWeb, even though I have an exception set for it. Now I unchecked to remove cookies by disabling the history on close and connection records correctly.
This connection allows to save 7 cookes under easyweb.td.com and 10 cookies under td.com and I have exceptions defined for both. If I clear the history when closing and include cookies, half of the td.com cookies disappeared when I close firefox and re - open. The same is true if I'm not the exception.
So currently I can't find a way to keep all cookies if I clear the cookie history when firefox closes. What is the difference with this option?
When you change the default cookie 'to life' of "keep until: they expire" to "keep until the: I close Firefox", Firefox changes all persistent cookies that sites set session cookies. To allow a site to place a persistent cookie, you need to make an exception (site permission).
When you turn on the story to stop compensation and include cookies, running a completely separate process that doesn't doesn't pay attention to the duration of cookie or exceptions (permissions site). There just nukes all.
Note that some cookies could survive if they are encoded in the history file of your session of compensation at the stop, a Firefox uses to restore your tabs and windows from last session. I have not tested.
-
What is the difference between REFin and PPSin? Can I use the PXI-5652 to synchronize USRPs?
Hello world!
I'm working on a project I want to synchronize 8 USRPs (USRP 2920) as receivers. And it seems that PXI-5652 has a connector REF, so I decide to use it as the reference of the USRPs 8 clock. But I don't know how to connect the PPSin, and in fact I'm confused of the difference between the REFin and PPSin.
Thank you!
Jay_c salvation,
In short,.
REF is the terminal for the device USRP to accept a signal from external reference frequency (10 Mhz).
PPS is the terminal for the device USRP to accept a signal from external time source base clock (1 pulse per second)
You can see this whitepaper for a detailed description of MIMO system about 8 * 8.
Please refer to the section "time and frequency" for information specific to your question.
http://www.NI.com/white-paper/14311/en/
I'm not sure whether you can use the specifically 5652 signal generator for your application.
-
What is the difference between Foglight JavaEE and Foglight JMX monitoring?
Hello
I have a plan to monitor the 6.1.0.17 WebSphere Application Server (32 bit) and 7.0.0.5 (64-bit)
But I understand not all Foglight for JavaEE and Foglight for JMX.
Foglight for JavaEE or Foglight for JMX is able to monitor WebSphere?
What is the difference between Foglight JavaEE and Foglight JMX monitoring?
Thanks in advance
Jeans
Just to add to the excellent answers already posted.
We have 2 agents which allows you to monitor Java:
1. a JavaEE agent that runs inside the JAVA virtual machine and the information of both JMX and instrumentation.
This Agent will give you JMX information like information of JVM (use of the bunch, son etc.), of the Application and server availability information and other information of JMX/PMI (connections pools, pools of ejb, servlets, jsp, JCA and more).
Java EE & # 039agent also gives you information of the instrumentation - RFA count and response time, exceptional output and timeout information, distribution of queries (App/DB, component technology, server, application failure), object tracking, transaction flow and stransactional between servers and data sources) and ask traces (the ability to see the trees of the RFA at the method level to know where things are slow/stuck).
2 JMX agent is running outside the JVM but can run on the same computer or on a remote computer, this agent requires access active, JMX. This agent gives you information JVM, availability server/applications, as well as some data as the application server published using JMX (pools of connections, JCA, EJB, servlets, etc.). The JMX agent also gives you the ability to see a list of the mbeans, get the data they expose (javaEE agent gets only a predefined list (same list that is used as a template for the application servers in the JMX agent)).
Hope this helps
Golan
-
What is the difference between Unicast RPF and Reverse Path Forwarding?
I am confused between Unicast RPF and Reverse Path Forwarding function.
What is the difference between Unicast RPF and Reverse Path Forwarding?
Because they have all two please check the address of the source of each package before sending it to the destination too?
Reverse Path Forwarding is used only when the network want to build a tree shared multicast communication and then we must use Unicast RPF after creation of the shared tree?
The mechanism of the RPF is mainly used to ensure no loop of routing traffic.
As you probably already read, it does by ensuring that his route to the source address of a packet received is accessible via the same interface that the packet is entered in the. Think of the notion of "root port" in STP. all root ports are similar to the root, sunflower follow the Sun. Therefore, it is naturally a loop prevention mechanism.
With multicast traffic, it is quite likely to create multiple loops of routing the nature of 'destination' traffic. For this reason, using a mechanism as the RPF to ensure you are on the "road to the root" (to say) to the source originating multicast traffic. Otherwise if you're not then you either receive this traffic route in a loop, or a suboptimal path.
uRPF works essentially the same way, except that it is done for unicast traffic instead. Now with unicast traffic your flow is from a source and directs to a single destination. Given that, as the fact that you are using a dynamic routing algorithm (which allows to select the path to a destination), you can have loops of your network for unicast traffic flow routing; of course there may be exceptions to pitfalls of configuration route redistribution.
However RPF when it is applied to traffic unicast can add another advantage, and it's verification IP source. That's why we can use it as a security mechanism to ensure that data are from where it is supposed to come.
On the limit of the L2, you then have mechanisms such as guard source IP to ensure that the correct host is not usurpation of their IP address.
By analogy RPF can be used for checking at source for multicast traffic, and it is intrinsically that however, the most important role is so that it can be used to guarantee without loop routing of multicast traffic.
I hope that helped clear things upwards and not confused you any more with all this.
-
Hello
I see under files in IOM. I exported and checked the content, both are different.
(1) /metadata/iam-features-ldap-sync/LDAPUser.xml
(2) / db/LDAPUser
What is the difference between these two files and what the purpose of each?
All entries would be useful.
Thank you
You can open both files and check the contents easily.
(1) the /metadata/iam-features-ldap-sync/LDAPUser.xml contains Provisioning of the related necessary inputs to the configuration of the LDAP synchronization:
string fake >
Web site Web site (2) related areas of reconciliation involved in the LDAP synchronization:
-
What is the difference between Facelets and JSP XML document?
Hello
When you create a new page, in the dialog box "Create a JSF Page" it is a choice called 'Type of Document' to select "Facelets" or "the JSP XML".
May be he one please tell me what is the difference between them. And what should I choose if I want to include ajax code in my page.
Thanks in advance
Facelets creates a facelets page
JSP creates a JSP page
Facelets - is default and the official display for JSF, compact JSP pages Manager has been used to view JSF pages but don't bear all component Facelets comes in picture under open source APACHE license. It supprts all components used by JSF (Java Server Faces) user interface.
Facelets has been developed by Jacob Hookom in 2005.
If you create a Facelets fragment in taskflow bounded, taskflow must be abandoned in a JSF (the parent page) page not in the .jspx (JSP XML) page.
If you try to deposit in the JSP XML page-
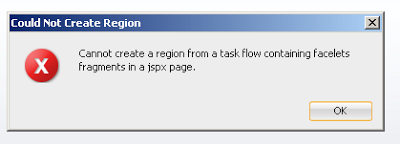
JSP, XML - jspx is Variant XML of the JSP (Java Server Pages) to support XML document. The JSP XML fragments are used in ADF inorder to support the XML document and more powerful techniques of page validation.
If you create xml jsp fragments in taskflow bounded, taskflow must be abandoned in a JSP XML (.jspx) (the parent page) page not in the JSF page.
-
What is the difference between making a site inactive and end provider, provider dating site?
Hello
There are 3 ways to make a provider site unavailable for use in R12?
Accounts payable Manager > search provider, and then click address book
(1) click the button remove
2) click on "Update" and change the status to "inactive."
3) click on 'Manage the Sites' and fixed the date passed in 'inactive Date '.
What is the difference between them and what are the advantages and disadvantages of each.
Kind regards
Mindy
Pros to delete: If there were human errors while accessing a supplier Site and if they are to be discarded then you can use this option. By example, bad provider Siite imported sources via interfaces or data conversion.
Cons to delete: Auditors will be unhappy because the record is no more.
Pros from inactive: Consider a scenario in which a provider of on-site audit has arrived and the audit found non-compliance with the operations of the Site to a specific provider. In such a case, that your company has decided to not not to create one more (or business) transactions with the Site Supplier up to what the provider meets the policies agreed contractual and accounts gives a green signal. And this is where you use 'inactive' for simply inactivate the vendor Site and then reactivate after passing a second check.
Cons of idle: You not save the date to which it has been inactivated. However the database captures the "last_update_date" column (which is not useful unless you have activated the check feature).
Pros inactive Date: Consider a scenario in which your provider had a warehouse in Auckland. But now they have closed the warehouse and moved to China. In this case, you always want to maintain previous transactions in the system, as well as from the point of view of the audit after inactivating you add some comments here. This is where the functionality of 'inactive date' will be very convenient in which you show clearly in the system when the site became inactive (and the reason for this action).
I hope this helps.
Concerning
Kamal Khan
www.AclNZ.com
-
What is the difference between pls_integer index and index of directory for a collection?
Hi all
I have a bit of difficulty understanding the difference between pls_integer and directory when you declare a collection...
Is not so much pls_integer than the supposed to be the same in 10g and 11g?
My problem is that I've declared a collection in a procedure with directory and by record type, it takes 10 seconds to process. (IE TYPE test_table IS the TABLE OF test % rowtype directory INDEX ;))
However, the same procedure with the declared collection with index of pls_integer, take only 1 second to process. (IE TYPE test_table IS the TABLE OF test % rowtype INDEX BY PLS_INTEGER ;))
Any help would be welcome.
Thank you.
MichaelR wrote:
I don't understand when say you not to use DML in a LOOP and use sql only. Can you please give me an example?
I usually of code like this:
- I'm looped slider
- Update table_name
- the value of col1 = i.rec1
- where col2 = i.rec2;
- end loop;
This approach is incorrect.
All SQL is parsed and executed as SQL cursors. There is no such thing as use SQL or cursor.
A cursor is a "compiled SQL program. Source SQL that has been analyzed in a cursor executable code. When you retrieve the cursor, you push the button the cursor or program execution. It finds a row and return lines. He's on a break. You get the rows returned, these processes and then click the button run the cursor using fetch. Until the cursor/program finds no additional data (or he faces a snapshot too old for example, where it can not rebuild a coherent reading to find the next set of lines).
A cursor is and has never been a set of cached data in memory that you are recovering from.
Take a look at your code. You use a slider/program to retrieve data from the database. For each row in the cursor returned, you call another slider/program and pass this line as input data.
It's slow. Data line moves a cursor to your PL/SQL code, and then again from your PL/SQL code to another cursor.
A single slider that makes the reading (the SELECTION cursor) part and the part of writing (the slider to UPDATE), requires no PL/SQL to read and write the parts together.
How to write this unique SQL cursor? You can use:
UPDATE (SELECT... Of... JOIN THE... WHERE...) SET...
You can use the MERGE statement. Or maybe just a statement UPDATE simple vanilla.
What is the problem of a conceptual, performance and scalability point of view, is the approach that you have indicated above. That approach will ALWAYS be slower than just SQL. This approach cannot scale.
The mantra of performance for Oracle is simple: Maximise SQL . Minimize the PL/SQL.
Use the SQL language correctly and properly. Do not what SQL is designed to do, in PL/SQL.
-
The differences between CAT and table TAB
1. What is the difference between cat and TAB?
2. why TAB does not exist in dict?
3. that the same situation for cat and TAB?
Thanks a lot for your answer kindly.
sys@ORCL > cat desc
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
TABLE_NAME NOT NULL VARCHAR2 (30)
TABLE_TYPE VARCHAR2 (11)
sys@ORCL > tab desc
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
TNOM NOT NULL VARCHAR2 (30)
TABTYPE VARCHAR2 (7)
NUMBER OF CLUSTERID
sys@ORCL > select * dict where table_name = "CAT";
TABLE_NAME COMMENTS
---------- -----------------------------------
Synonym of cat for USER_CATALOG
sys@ORCL > select * dict where table_name = 'USER_CATALOG ';
TABLE_NAME COMMENTS
-------------------- -----------------------------------------------------------------
USER_CATALOG Tables, views, synonyms, and sequences belonged to the userYou've posted enough to know that, for each position, you will need to provide your version of Oracle 4-digit (SELECT * FROM V$ VERSION)
>
1. What is the difference between cat and TAB?
2. why TAB does not exist in dict?
3. that the same situation for cat and TAB?
>
1, 2, 3 - TAB has been deprecated then don't use it.Definitioni of base for those located in the reference database
http://docs.Oracle.com/CD/B28359_01/server.111/b28320/statviews_2127.htm#sthref1535
>
CATCAT is a synonym for USER_CATALOG.
. . .
USER_CATALOGUSER_CATALOG lists all the tables, views, clusters, synonyms, and sequences belonged to the current user. Its columns are the same as those of "ALL_CATALOG".
. . .
DICTDICT is a DICTIONARY.
. . .
DICTIONARYDICTIONARY contains descriptions of data dictionary tables and views.
. . .
TABTAB is included for compatibility. Oracle recommends that you do not use this view.
>
TAB has been deprecated. He looks like the cat because it shows the USER objects, but it does not show the sequences, like the cat.If you look at the source code for the views TAB and USER_CATALOG you can see the differences. This code is copyrighted by Oracle Corporation, all rights reserved.
/* Formatted on 1/1/2013 8:50:07 AM (QP5 v5.115.810.9015) */ CREATE OR REPLACE FORCE VIEW SYS.TAB ( TNAME, TABTYPE, CLUSTERID ) AS SELECT o.name, DECODE (o.type#, 2, 'TABLE', 3, 'CLUSTER', 4, 'VIEW', 5, 'SYNONYM'), t.tab# FROM sys.tab$ t, sys."_CURRENT_EDITION_OBJ" o WHERE o.owner# = USERENV ('SCHEMAID') AND o.type# >= 2 AND o.type# <= 5 AND o.linkname IS NULL AND o.obj# = t.obj#(+); . . . /* Formatted on 1/1/2013 8:54:45 AM (QP5 v5.115.810.9015) */ CREATE OR REPLACE FORCE VIEW SYS.USER_CATALOG ( TABLE_NAME, TABLE_TYPE ) AS SELECT o.name, DECODE (o.type#, 0, 'NEXT OBJECT', 1, 'INDEX', 2, 'TABLE', 3, 'CLUSTER', 4, 'VIEW', 5, 'SYNONYM', 6, 'SEQUENCE', 'UNDEFINED') FROM sys."_CURRENT_EDITION_OBJ" o WHERE o.owner# = USERENV ('SCHEMAID') AND ( (o.type# IN (4, 5, 6)) OR (o.type# = 2 /* tables, excluding iot - overflow and nested tables */ AND NOT EXISTS (SELECT NULL FROM sys.tab$ t WHERE t.obj# = o.obj# AND (BITAND (t.property, 512) = 512 OR BITAND (t.property, 8192) = 8192)))) AND o.linkname IS NULL; -
What is the difference between cloning and Coverting a Virtual Machine
Hello
I'm starting to learn more about vmware. My organization is already a VMware/Vsphere infrastructure, I am trying to familiarize myself with various aspects of VMware, so I wanted to know what is the difference between a virtual machine cloning and to convert a virtual machine using Vconverter?
They both end up giving double a VM, or is there a difference between the two?
Thanks in advance.
Cloning can be done with the virtual machine or not. P2V requires the source runs and you must install the converter.
-
What is the difference between these commands
Oracle 11.2.0.1
Windows 7
Please tell me what are the differences between these two commands:
RMAN/RMAN@ORCL catalog RMAN
Catalog RMAN target scott/tiger RMAN/RMAN@ORCL
Here the user scott is too have DBA role. Recovery catalog owner is rman. I wish to test backup and restore, as well as the above command must be used.
To develop.
Thank you.user12050217 wrote:
Oracle 11.2.0.1
Windows 7Please tell me what are the differences between these two commands:
RMAN/RMAN@ORCL catalog RMAN
This is happening to you the recovery catalog database but not connect to the target database. So you must issue a further statement while connected to RMAN to connect to the target database. Here the user RMAN is the catalog name of the owner.
Catalog RMAN target scott/tiger RMAN/RMAN@ORCL
You try to connect to the database target db user RMAN catalog as user Scott.
Here the user scott is too have DBA role. Recovery catalog owner is rman. I wish to test backup and restore, as well as the above command must be used.
The backup will be done using the Sysdba role, not with the DBA role. So you must still issue the command to connect to the target db. In the 2nd order you establish this connection and in 1, you must take another step for him.
To develop.
Its developed already in the backup and restore reference guide. Read it,
http://docs.Oracle.com/CD/E11882_01/backup.112/e10642/TOC.htmAman...
-
Try to explain the difference between a DPS application and a coded / from scratch app.
Guys, I need help. I'm writing a guide for my clients regarding the DPS. I want to include some information on the differences between a DPS App and a code app. Any of you have ever had to explain that, and if you have, what did you say?
The most obvious difference is that a DPS app is what you get InDesign and a coded app, you must have a coder. But what are the feature differences? As I am not a coder and do not have access to the resources of coding, I'm at a loss.
Thank you
Karen
They are large enough.
In short, the DPS is a solution or a framework that allows non-technical people to create content for use on multiple platforms, with various limitations by platform. Especially there sense for Magazines and newspapers as a platform target, with a few exceptions.
For example, DPS does not access the hardware device API, such as the cameras of the device, the GPS or accelerometer. Limits of the DPS depending on also what license you buy, for example, if they are a client of the company, they would be able to build a showcase custom, which is not available in the Pro licenses or simple editing.

Maybe you are looking for
-
There is no forthcoming toolbar when replying to or sending mail so impossible to click on SEND
Can't send or reply to emails. the WRITING box, but there is no option to SEND, SAVE, or something with the post after was written.
-
Satellite A30: overheating maybe?
Hello. I had a problem with my satellite SA30-303. When I run certain applications, such as WinDVD Creator and more recently, the online game Lineage 2 and a few others, my pc just stops completely, after an increase of "noise" coming from the ventil
-
Bsod Windows Update. Can't even use a boot disk.
Like most of us is windows update has been trashing systems xp and vista by the thousands. I can't enter safe mode and I can't start the recovery console. I will be pulling my hard drive, connecting to another PC and manually start deleting files. Th
-
HP Officejet 6600: How to enlarge the copy of the document with HP Officejet 6600
Extension of copy
-
How can I return IE10 to release IE9
The hotel PMS system we have does not support IE10 how can I return to IE9?