the sum of the column lines based on distinct values of column B
Hi allHere is my xml
rowset <>
< ROW >
< ORDER_NO > 103-4385509 < / ORDER_NO >
< SITE_NO > 103 < / SITE_NO >
< ORDER_ID > 4385509 < / ORDER_ID >
< CUSTOMER_ID > 2676832 < / CUSTOMER_ID >
< TAX_AMOUNT >.33 < / TAX_AMOUNT >
< CREATED_DATE > 20/08/2010 < / CREATED_DATE >
< USER_CREATED > TSDAL671 < / USER_CREATED >
< Delivery_Method > CARRY OUT STORE < / Delivery_Method >
< Entered_By > TSDAL671 < / Entered_By >
< SKU_NO > 321182 < / SKU_NO >
< NAME_TEXT > MGR_OVERRIDE < / NAME_TEXT >
< > 319 ATTRIBUTE_ID < / ATTRIBUTE_ID >
Override < ATTRIBUTE_VALUE > done < / ATTRIBUTE_VALUE >
< DETAIL_SEQ_NO > 1 < / DETAIL_SEQ_NO >
< / ROW >
< ROW >
< ORDER_NO > 103-4385509 < / ORDER_NO >
< SITE_NO > 103 < / SITE_NO >
< ORDER_ID > 4385509 < / ORDER_ID >
< CUSTOMER_ID > 2676832 < / CUSTOMER_ID >
< TAX_AMOUNT >.33 < / TAX_AMOUNT >
< CREATED_DATE > 20/08/2010 < / CREATED_DATE >
< USER_CREATED > TSDAL671 < / USER_CREATED >
< Delivery_Method > CARRY OUT STORE < / Delivery_Method >
< Entered_By > TSDAL671 < / Entered_By >
< SKU_NO > 321182 < / SKU_NO >
< NAME_TEXT > OEDTL_TAX_INFO < / NAME_TEXT >
< > 314 ATTRIBUTE_ID < / ATTRIBUTE_ID >
< ATTRIBUTE_VALUE > 441130760 | 441130760 | 441130760 | 1. 1. 1. 20100820 | 2676832 | 2. SPARE PARTS | < / ATTRIBUTE_VALUE >
< DETAIL_SEQ_NO > 1 < / DETAIL_SEQ_NO >
< / ROW >
< ROW >
< ORDER_NO > 103-4385509 < / ORDER_NO >
< SITE_NO > 103 < / SITE_NO >
< ORDER_ID > 4385509 < / ORDER_ID >
< CUSTOMER_ID > 2676832 < / CUSTOMER_ID >
< TAX_AMOUNT >.18 < / TAX_AMOUNT >
< CREATED_DATE > 20/08/2010 < / CREATED_DATE >
< USER_CREATED > TSDAL671 < / USER_CREATED >
< Delivery_Method > CARRY OUT STORE < / Delivery_Method >
< Entered_By > TSDAL671 < / Entered_By >
< SKU_NO > 412679 < / SKU_NO >
< NAME_TEXT > OEDTL_TAX_INFO < / NAME_TEXT >
< > 314 ATTRIBUTE_ID < / ATTRIBUTE_ID >
< ATTRIBUTE_VALUE > 441130760 | 441130760 | 441130760 | 1. 1. 1. 20100820 | 2676832 | 2. 0035 | < / ATTRIBUTE_VALUE >
< DETAIL_SEQ_NO > 2 < / DETAIL_SEQ_NO >
< / ROW >
I have to display 3 lines but all the sum of TAX_AMOUNT grouped by ORDER_ID, I need sum for 2 records based on the distinct value of DETAIL_SEQ
so my output should be something like below
ORDER_ID | TAX_AMOUNT | DETAIL_SEQ | ATTRIBUTE_ID
-----------------------------------------------------------------------------
4385509 | 0.33 | 1. 319
4385509 | 0.33 | 1. 314
4385509 | 0.18 | 2. 314
--------------------------------------
SUM = 0.51
------------------------------------------
Note: I can't make separate in the sql attribute_id is different for the same DETAIL_SEQ_NO.
I tired to do <? sum ([xdoxslt:distinct_values (current - group () / DETAIL_SEQ_NO)] / TAX_AMOUNT)? >
It did not work.
Can someone help me please!
Thanks in advance!
This syntax will not work.
A method to do so.
Tags: Business Intelligence
Similar Questions
-
How to merge values into a line, based on distinct values in another column
I have a table like
updatedby updateddate text
Approval John 1st May 2009 1 added file
Approval of John 1 May 2009 2 added file
May 2, 2009 1 deleted David approval form
I need the text column values to be concatenated and displayed for unique (updatedby updateddate) records. The output is something like
updatedby updateddate text
Approval of May 1, 2009 John save further approval 1 sheet, 2 added
May 2, 2009 1 deleted David approval form
I had planned to do it using PLSQL. Is there a way to achieve this in SQl...? Please suggestSQL> ed Wrote file afiedt.buf 1 with t as (select 'John' as updatedby, to_date('01-May-2009','DD-MON-YYYY') as updateddate, 'Approval record 1 added' as text from dual union all 2 select 'John', to_date('01-May-2009','DD-MON-YYYY'), 'Approval record 2 added' from dual union all 3 select 'David', to_date('02-May-2009','DD-MON-YYYY'), 'Approval record 1 removed' from dual) 4 -- END OF SAMPLE DATA 5 -- 6 select updatedby, updateddate, ltrim(sys_connect_by_path(text,','),',') as text 7 from ( 8 select updatedby, updateddate, text, row_number() over (partition by updatedby, updateddate order by text) as rn 9 from t 10 ) 11 where connect_by_isleaf = 1 12 connect by rn = prior rn+1 and updatedby = prior updatedby and updateddate = prior updateddate 13 start with rn = 1 14* order by 2 SQL> / UPDAT UPDATEDDA TEXT ----- --------- ---------------------------------------------------------------------------------------------------- John 01-MAY-09 Approval record 1 added,Approval record 2 added David 02-MAY-09 Approval record 1 removed SQL>Edited by: BluShadow May 21, 2009 12:37
Argh! hair to the pole by SY -
State of color lines based on a value in the same row
I would like to color report lines based on a value in the same row.
For bolting with the table 'EMP ':
I would like job = MANAGER and Red work = CLERK to be green etc etc.
The other example I found was the possibility of a single color either the nail or the default color.
I'm looking for a way to do multiple colors.Hello
In the model line, you can use #1 #, 2 # #, etc. to indicate where a field in the report should be released. It doesn't have to be clear - that is to say, you can use it in style tags if you wish.
So take a query such as:
SELECT EMPNO, ENAME, DEPTNO, DECODE(DEPTNO, 10, 'green', 20, 'red', 30, 'cyan', 'white') BG_COLOUR FROM EMPYou get the column 1 = empno, 2 = ename, 3 = deptno and 4 = bg_colour. In the model line, you can then do:
Before defining lines (implements the table):
<table> <tr><td>ID</td><td>Name</td><td>Dept</td></tr>After setting (farm table) lines:
</table>Model 1 (used for all lines) line:
<tr style="background-color:#4#;"><td>#1#</td><td>#2#</td><td>#3#</td></tr>Then, for each row, the color that has been calculated by using the DECODE function is used in the style tag for color the background of the whole line.
How to determine the colors, it's you. I used DECODE here, but you can use a field on the DEPT table to hold and use it in your SQL statement.
Andy
-
Follow-up - how can I order lines based on a value from column to HFR
As discussed in my question on queries Top, I have a column that I ordered highest to lowest on a report.
I have now, thanks to mballo, have a column of row (still hidden) as well as the column that contains the values. I have 25 rows. My use of the Rank ([M, 1:25].ifNN(-1), descending) provides values but no order.
How can I get the lines sorted by the values in a particular column, then the first line has the highest value and the rest in descending order?
JIn the property sheet of grid, there is an option "comes out" about 1/2 at the bottom of the page. Once activated it will bring up a window that allows you to apply the sorting. You can take specific lines or all the rows and then apply that based on a column. Or vice versa.
-
How to view the line of sql to the horizontal format based on a value.
I want to display data to the user in horizontal form based on a column value. Here is the table structure and insert. Also, I've included output expected.
If the pricemethod is "Guess", I want the value next to the price (price_real, price_guess), it will be based on the code, sellernumber and selldate.
create table TEMP_HORI ( CODE VARCHAR2(30), PRICE NUMBER(20,10), SELLDATE DATE, SELLERNUMBER NUMBER(10), PRICEMETHOD VARCHAR2(15) ); insert into temp_hori (CODE, PRICE, SELLDATE, SELLERNUMBER, PRICEMETHOD) values ('ABCD', 100.0000000000, to_date('01-10-2014', 'dd-mm-yyyy'), 100, 'Real'); insert into temp_hori (CODE, PRICE, SELLDATE, SELLERNUMBER, PRICEMETHOD) values ('ABCD', 90.0000000000, to_date('01-10-2014', 'dd-mm-yyyy'), 100, 'Guess'); insert into temp_hori (CODE, PRICE, SELLDATE, SELLERNUMBER, PRICEMETHOD) values ('ABCD', 101.0000000000, to_date('01-10-2014', 'dd-mm-yyyy'), 299, 'Real'); insert into temp_hori (CODE, PRICE, SELLDATE, SELLERNUMBER, PRICEMETHOD) values ('ABCD', 109.0000000000, to_date('01-10-2014', 'dd-mm-yyyy'), 500, 'Real');Real:
CODE PRICE SELLDATE SELLERNUMBER PRICEMETHOD ABCD 100.0000000000 01/10/2014 100 Real ABCD 90.0000000000 01/10/2014 100 Guess ABCD 101.0000000000 01/10/2014 299 Real ABCD 109.0000000000 01/10/2014 500 Real Expected:
CODE PRICE_REAL PRICE_GUESS SELLDATE SELLERNUMBER ABCD 100.0000000000 90.0000000000 01/10/2014 100 ABCD 101.0000000000 01/10/2014 299 ABCD 109.0000000000 01/10/2014 500 Hello
This is called swivel and here's a way to do it:
SELECT code
, SUM (CASE pricemethod WHEN 'Real' price THEN END) AS price_real
SUM (CASE pricemethod when 'Guess' THEN price END) AS price_guess
selldate
sellernumber
OF temp_hori
Code of GROUP BY, selldate, sellernumber
ORDER BY code, selldate, sellernumber
;
From Oracle 11, you can also use the SELECT... PIVOT function, but it does not really help to this particular problem.
I guess just the role of the code and selldate in this problem. It is difficult to say when all the rows in the data of the sample has the same value.
Want you all sellnumbers aligned in column 1, or do you want some further to the left than others that you have posted? If the latter, is this 1 column or 2 separate columns? How do you decide which column the sellnumber appears?
For more info on pivots, see the FAQ of the Forum:
-
Remove the duplicate line based on master e-mail
Hello
I have a request below that displays the records in doubles because of the tips white space I like how ignore and get a single record.
Select
SEPARATE
MASTER_EMAIL "E-mail account"
"Name",
Last_name "Last Name."
Decode (company_name, NULL, Domain, company_name) "society."
JOB_FUNCTION "Title."
Ligne_adresse_1 "address."
"CITY."
"STATE."
'COUNTRY ', HE SAID.
"Zip, ZIP
PHONE_NUMBER "phone."
FAX_NUMBER "Fax."
CREATED_DATE "created Date."
FIELD,
MASTER_FLAG,
location_company_name
of master_email_users
where
MASTER_EMAIL AS ' [email protected] % %'
Thank you
Sudhir
What I feel is best to remove the white space in the data itself by refreshing the records where we have and making sure that no future records cannot have white space while getting inserted.
This helps us to avoid additional functions to use in recovery.
-
Web Forms: Deleting line based on the value of a specific column
Hello
I have an online form in which I want to apply delete missing on the ranks, but only on the value of the first column. So, if the first column is #missing I want the deleted row, even if the columns are given in it.
Is it possible to do this?
I'm on ver 11.1.2.2 Hyperion Planning
Shehzad
Published by: shehzad k on January 24, 2013 11:51Unfortunately, no. There is no way to add the delete line based SOLELY on the existence of a value in the first column. It would be nice to see some of the more advanced features "conditional delete", we en flies over to the planning of the entry forms.
You can do the "clumsy" things with data validations where you gray - out ranks in view of the existence of a value in a particular cell, however while this might SUGGEST that the user should not enter data in a particular line, it would not PREVENT to do so.
We have seen many improvements in form lately with the introduction of data validations. I hope the momentum continues.
-Jake
-
concatenation of lines having the same value of the column
Hi all
I was struck with a situation, please find the example in the following table
create table test (varchar2 (20) Column1, Column2 varchar2 (20), Column3 varchar2 (20))
Insert test values ('A1', 'x 1', 's1');
Insert test values ('A1', 'x 1', 's2');
Insert test values ('A1', 'x 1', 's4');
Insert test values ('A1', 'x 2', 's1');
Insert test values ('A1', 'x 2', 's2');
Insert test values ('A1', 'x 2', 's3');
so finally the teable looks like this
Column1 - Column2 - Column3
A1-----------------------x1------------------------s1
A1-----------------------x1------------------------s2
A1-----------------------x1------------------------s4
A1-----------------------x2------------------------s1
A1-----------------------x2------------------------s2
A1-----------------------x2------------------------s3
so now I want the o/p, based on common values for i.e Column2 Column3
Column1 - Column2 - Column3
A1-----------------------x1,x2-------------------s1,s2
A1-----------------------x1------------------------s4
A1-----------------------x2------------------------s3
How this could be achieved, any help would be appreciated
Thank you
SimiYou can use wm_concat... but are not documented in 10g
SELECT column1, column2 , wm_concat(column3) FROM (SELECT column1 , wm_concat(column2) column2, MAX(column3) column3 FROM test GROUP BY column1, column3 ) GROUP BY column1, column2;Ravi Kumar
-
How to better master with this model s/n, sides IN and OUT in the same line.
Hi all!
I'm just facing some old historical table where, to the transaction recorded in the same line, something like:
column name
==============
ref_no,
x_id,
product_id,
product_amt,
-* IN part
in_flag-(IN)
in_customer,
in_address,
-* PORTION
out_flag-(OUT)
out_customer,
out_address
Nice shipping biz where we can have the two sides met in the same line, they have same value for IN and OUT_flag = actual values 'IN' and 'OUT', woou!
I really expect to have this table in different model where a line is an entry, probably with PK = ref_no + in_out_flag.
But it looks like I can do anything on this design, and now I choose upong xactions request entry and EXIT, IN/OUT fixing portions on a common part with the UNION. This, the only way I can see how to solve this problem, or I'm not right? And I need to pack all in the stored procedure.
Appreciate your comments how to do this, I'm really new to Oracle, however have some exp.
And comments about these models db as well! -).
Best
TRI don't understand what problem needs to be solved.
What criteria an independent observer would conclude that a correct solution has been posted.
Published by: sb92075 on September 11, 2010 17:19
-
Outer join or a function of the level line
Hi all
I have a question which involves five tables T1, R1, R2, R3, and R4. T1 is an operating table, while R1, R2, R3, and R4 are tables of references (tables parent, with the foreign keys defined in T1). Table T1 contains always referenced data R2 and R1. BUT table T1 can sometimes contain NULL for R3 and R4.
Now my question is simple;
Should I use an OUTER Join for R3 and R4 in the query? as
< code >
Select T1.col1, R1.col2, R2.col2, R3.col2, R4.col2
T1, R1, R2, R3, R4
where T1.col2 = R1.col1
and T1.col3 = R2.col1
and T1.col4 = R3.col1 (+)
and T1.col5 = R4.col1 (+)
< code >
OR
Can I use level functions online for R3 and R4, as
< code >
Select T1.col1, R1.col2, R2.col2,
(Select R3.col2 in R3 where R3.col1 = T1.col4),
(Select R4.col2 in R4 where R4.col1 = T1.col5)
T1, R1, R2
where T1.col2 = R1.col1
and T1.col3 = R2.col1
< code >
Which approach is better and why?
Records in T1 = 2 000 000
R1 = 1000 records
Records in R2 = 300
Records in R3 = 1800
Records in R4 = 200
Please note that all foreign keys are indexed, there are primary keys for all the tables in R
Thank you
QQ.According to the 'official' documentation the outer join should be the by far best choice, because I still think the Oracle documentation says that the subquery will be executed for each row of the main query.
But the Oracle execution engine is a lot smarter (I think from Oracle 8i) and offers a "Value for the filter" feature supposedly which also applies to the "scalar subqueries" you are talking about to (but only if the subquery is considered to be deterministic, i.e. returns always the same value for the same input value of the main request).
Basically, this Treaty optimization the subquery as a function of an input value (the link to the main request) and an output value (the result of the query) and maintains a hash table in memory of pairs of input/output value. The size of the changes table in memory from one version to the other, I think in 9i, it is set by default to 256 entries but in 10g, it is limited in size and therefore the number of entries depends on the size of the values to store.
The effectiveness of this optimization of memory-search in the table depends on certain factors such as the number of pairs of distinct value, the order of the incoming values and collisions in the table which can be occur according to hash values.
Jonathan Lewis has an in-depth coverage of these mechanism in its "cost-based Oracle: Fundamentals" book.
To make a long story short, since your tables R3 and R4 are relatively low, you might want to give a chance, because these optimizations could work very well in your particular case, but unfortunately the real result is simply unpredictable due to the above constraints, including the order of the incoming values.
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/ -
How not to show duplicate lines, based on a field
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Hello
I have a query that looks like some scripts that did not stand on a given date compared to what ran the same day about a week ago. We want to include the start_datetime and the end_datetime but when I add it to the select statement, it evokes all instances of jobs that run several times during the day. Is it possible to exclude the extra lines based on the field of script_name?
SELECT instances.script_name, instances.instance_name, REGEXP_REPLACE(master.description, chr(49814), -- em-dash '-') description --instances.start_datetime FROM xxcar.xxcar_abat_instances Instances, xxcar.xxcar_abatch_master Master WHERE 1 = 1 AND TRUNC(start_datetime) = TRUNC(TO_DATE(:p_StartDate, 'YYYY/MM/DD HH24:MI:SS')) - (:p_NumOfWeeks * 7) AND Instances.SCRIPT_NAME = Master.SCRIPT_NAME (+) MINUS SELECT script_name, instance_name, NULL --NULL FROM xxcar.xxcar_abat_instances WHERE 1 = 1 AND TRUNC(start_datetime) = TRUNC(TO_DATE(:p_StartDate, 'YYYY/MM/DD HH24:MI:SS'))LESS performs a set operation - remove lines from the first series that exactly match the second set.
When you add columns to the first series, you want a smaller filter - try a NOT IN multi-column:
To remove several courses, to regroup and get min/maxSELECT instances.script_name, instances.instance_name, REGEXP_REPLACE(master.description, chr(49814), -- em-dash '-') description, min(instances.start_datetime) start_datetime, min(instances.end_datetime) end_datetime FROM xxcar.xxcar_abat_instances Instances, xxcar.xxcar_abatch_master Master WHERE 1 = 1 AND TRUNC(start_datetime) = TRUNC(TO_DATE(:p_StartDate, 'YYYY/MM/DD HH24:MI:SS')) - (:p_NumOfWeeks * 7) AND Instances.SCRIPT_NAME = Master.SCRIPT_NAME (+) AND (script_name, instance_name) NOT IN ( SELECT script_name, instance_name FROM xxcar.xxcar_abat_instances WHERE 1 = 1 AND TRUNC(start_datetime) = TRUNC(TO_DATE(:p_StartDate, 'YYYY/MM/DD HH24:MI:SS')) ) group by instances.script_name, instances.instance_name, master.descriptionYou do not give the definitions of table and query schemas in him, therefore I don't test it.
Kind regards
David -
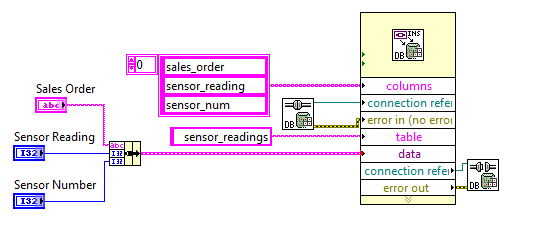
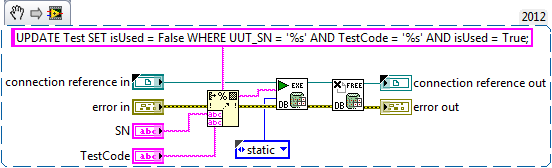
Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
-
change the color of line based on the value of column 5 Apex in the classic report
Version of the apex 5.0.0.00.31
Standard universal theme
Page theme default template
Classic report
Foldable report template
Hello
I know this question has been asked several times here, but I'm working on 5 Apex and need to know the correct way to do it in this version.
I need to change the color of the text of the entire line (no background color) based on the value in one of the columns of the classic report. I have just two conditions, if the value of column = Yes, color should be red, otherwise it must be green.
I am new to jscript and css, so appreciate if someone can tell me the solution with steps.
I have already checked this link that changes the value of the column, need to do something similar to the whole line.
https://tylermuth.WordPress.com/2007/12/01/conditional-column-formatting-in-apex/
Hi coolmaddy007-Oracle,.
Here's an example set up on the apex.oracle.com according to the specifications you gave: https://apex.oracle.com/pls/apex/f?p=35467:1
Version of the apex 5.0.0.00.31
Standard universal theme
Page theme default template
Classic report
Foldable report template
Here is how it is done:
Create a dynamic action with the following specifications:
Name: Give the appropriate name
Event: After refresh
Selection type: region
Region: select your region classic report
Condition: No strings attached
Action: Run the JavaScript Code
Fire on loading the Page: Yes
Code:
$('td[headers="JOB"]').each(function() { if ( $(this).text() === 'MANAGER' ) { $(this).closest('tr').find('td').css({"color":"red"}); } if ( $(this).text() === 'SALESMAN' ) { $(this).closest('tr').find('td').css({"color":"green"}); } if ( $(this).text() === 'CLERK' ) { $(this).closest('tr').find('td').css({"color":"blue"}); } });NOTE: Download the selector appropriate for your knowledge $('td[headers="JOB"]') case using firebug/browser development tools.
Items concerned: leave blank.
PS: Changed the example to change the color of text instead of the background color.
I hope this helps!
Kind regards
Kiran
-
Generating lines based on the value of the column?
Hi all
I would like to know if there is a function that can help me in creating lines based on a column value and, if so, which. I'm on version 11.2.0.3.0
for example, I have these data in the table:
ID O A C
1 5 3 5
2 9 2 3
Where ID is an identifier unique record and column C contains the number of records, I would have returned for this ID. In this example, the folder with the ID 1 would be repeated 5 times and the folder with the id 2 would be repeated 3 times. The result would look like this:
ID O A C
1 5 3 5
1 5 3 5
1 5 3 5
1 5 3 5
1 5 3 5
2 9 2 3
2 9 2 3
2 9 2 3
Column C contains the number of repetitions Records and is defined as a positive integer > = 1.
Of course, in real life, the table contains (at this time) 41 M number of records and the value of C can vary between 1 and 554, hardcode on the example above values is not possible.
Any pointers in the right direction are much appreciated.
Kind regards
LennertSQL> ed Wrote file afiedt.buf 1 with t as (select 1 as id, 5 as c from dual union all 2 select 2, 3 from dual) 3 -- 4 select id, c 5 from t 6 connect by level <= c 7 and id = prior id 8* and prior sys_guid() is not null SQL> / ID C ---------- ---------- 1 5 1 5 1 5 1 5 1 5 2 3 2 3 2 3 8 rows selected. -
How to highlight the line of the ADF table based on the value of the column?
Hi all
I use jdev 10.1.3.4. I want to highlight a table row or a cell based on the value of the column.
Lets say, I have a table emp with column empid, empname and sal. I want to emphasize the lines that have sal = 10000.
How can I achieve this? Please help me with this.
Thank you
AbhijitHello
You want to highlight the lines? or set a different color for the lines? If it's the second, you can set the inline style based on the salary. (+ Edit: well, never mind, both are same :)) +)
Something like
If you want the entire line to be a different color, you have 2 options.
1. define the same style inline for all columns in the table (good if you want to do only for a single table).
2. create a style class and apply the styleclass based on the value of sal (preferably if you want the same behavior in all of your application).Arun-
Published by: joel Ramamoorthy, October 23, 2009 16:56
Maybe you are looking for
-
HP Pavilion dv6 Notebook PC Series # 5CH1120D58 Product # LH592TA #ABA I forgot my password what do I do
-
I feel an unusual power down on my PC.
Recently, my computer stops suddenly while running PC games such as Resident Evil 5, Borderlands and Fallout 3. My PC has system requirements to run all the programs very beautifully. System AMD Athlon 64 X 2 Dual Core processor 4400 + 2.30 GHz 3 GB
-
loss of quality massive when you import pictures to my computer
Hello! I imported my photos of the camera for the first time to my computer, I got a Macbook Pro 13 "retina. I've lived a MASSIVE quality loss in my photos. Not only photos taken with the phone camera way worse (front and rear camera) look, but espec
-
After that my computer froze recently, when he finally returned, the display was completely on the side. Fortunately, I have a separate keyboard because I set the computer on the desk as an open book on the end to see properly. How can I get it bac
-
I need help to find where to get them and install the updated Windows script error. I have problems to install a scanner on my computer (Vista) Hp HP and HP help says I need to install the updated Windows script error before they go further.