Through tunnels of automatic indexation to write data files?
Hello
I use neither-controller to control a servo and position and torque data collection. I want to write data to the TDMS files.
Recently, I learned about the design of producer/consumer model and I thought it would be a good approach to ensure that writing the files didn't slow down my timed loop of data collection.
However, I also realized that my program seems to work well if I wire the data that I collect the tunnels of automatic indexation. Can I use a structure that executes only after the entire collection of data is made to write the charts that I built to TDMS files.
Is there a reason that would make the last method against? Can the tunnels of idexing auto slow my loop enough to concern him? I collect only about 5,000 points of data for each channel.
See you soon,.
Kenny
In my opinion, the main consideration is timing. If you use consumers/producers, you essentially make writing while the data collection process is "pending" the next item to collect. It should be the case that the consumption will be faster than production, so at any time, 99% of the data are already written, Yes (perhish forbid!) if the program crashes, you already have most of the data on the disk. fo
Alternatively, you can use the tunnels and send an array of 5000 points (from the tunnel exit) for the writing process. This requires it to be rather than parallel series - no writing occurs until all the 5000 points are generated, and the writing process, instead of is almost as soon as it starts, takes 5000 times longer (more or less).
The series is 'simpler', especially for a beginner. The producer/consumer, if you understand the design model, would be my preference.
BS
Tags: NI Software
Similar Questions
-
Automatic extension of a data file with the complete file system
We are working on a database of Oracle10g 10.2.0.4 on HP - UX 11.31 (Itanium |) PA - RISC)
We would create our database by activating the automatic Extension of our data files
(defining the maximum size limit or unlimited)
Our question is:
What happens to the database in the event of complete file system when one of the data files should be automatically extended?
The extended data file has become corrupted or the db cease its activity?
MarcoNo data corruption should occur. If Oracle is trying to develop, OS it will send the message that it is not possible. That's all.
-
Re-create all indexes on new data files
Hello
on FSCN 9.2 on Win 2008
We'll re-create all indexes (belonging to sysadm) in the new data files.
-Are there any script or utility to do this?
-can you offer me any scenario?
Otherwise, I think only of:
0-extract DDL for all areas of storage and index.
1-drop tablesapces
2 Create tablespaces (by the DBMS_GETDLL script ('TABLESPACE'...)
3 re-create all indexes (by the DBMS_GETDLL script ('INDEX',...))
4 rebuild all indexes.
Any idea?
Thank you.
of 786997.1
There is no trace of PeopleTools that stores the name of the tablespace for the index.
Here's how to work the tablespaces.
There is a table called PSDDLMODEL where we store the information of DOF model for index and table creation, among other things. DDL models contain a template with replaceable parameters. One of the parameters in the create index Oracle is a field called INDEXSPC. This field by default is PSINDEX.
If you wish to override this value, you can go in the App Designer, open a folder, select Tools-> data Administrations-> select Index to edit the index and then select modify DDL, then select change the setting for the Create Index and Create Unique Index model. This replaces PSINDEX for this record. The name of the underlying table is PSIDXDDLPARM.
If you want to change the default PSINDEX to something else, go to the utilities Menu and use DOF model by default and change the PSINDEX to something else. Once you change this setting, the next time that you create the index, it will be created in the tablespace.
If you create an index in a different tablespace outside PeopleSoft, we have no knowledge of this and do not update our tables in order to take into account where he currently resides. Once you have updated the default template and replaced the records you want to replace, you can make a Data Mover, followed of a Data Mover import export and the index will be created as they have been redefined. Or you can just do a SQL Create Index and re-create all of them.
-
Tunnel of automatic indexing problem
I have a data acquisition program that uses an Auto-Indexed Tunnel in a loop to process and display data in a table 1 d. The program behaves strangely with the first value in the array (the point where the program worked, in a few seconds). 13 other values in the table all correct update, but the value of time always shows approximately the same number. The loop is scheduled to update the front values once per second. If I use a table outside of the loop Index block For to get the value of time out of the matrix, I get the correct value for time increments upward by about a second each time that the loop runs.
So basically, when the value of time is passed through the auto-index Tunnel, its output fluctuates up and down a few tenths of seconds each time the loop is executed (remaining to a single value... usually about 90, even if it changes each time I run), instead of starting with 0 and increases with time as the summer running program.
I'm under LabVIEW 8.5.1
Thank you
Sam
Because I have no data acquisition installed, I can not tell what is the size of the array is, but if it is greater than 14, the later elements overwrite time because 0 is also the default value. For safety, I add another case (empty) (e.g. - 1) and make it the default.
A lot of things very unwise, for example in the dataHCC.vi 'calculate', you add an empty array in the table. This really does not something useful, right?
-
How to write data files with dot-delimited values in the output interface
Hello
We are looking for the value below with. bounded by the
JANUARY 12, 14; MTS; 12,3400
14 JANUARY 14; MTS; 124,3442
14 JANUARY 14; MTS; 4,3400
14 FEBRUARY 14; HDB DKK; 3446
14 FEBRUARY 14; HDB DKK STREET; 346,3446
14 FEBRUARY 14; TEST; 346,3446
February 16, 14; DKK Til CHF; 1406
I used to_char utl file. but no luck.
UTL_FILE.put_line (x_id, x1.dato |) ';' || x 1 .valuta_fra_og_til | ';' || To_char (x 1. Kurs, '999999D9999'));
Can you please on it.
Try:
To_char (x 1. Kurs, '999999D9999','NLS_NUMERIC_CHARACTERS = ".,"')
-
When OMF add the data file in the tablespace
Hi friends,
We use oracle 11.2 with CMS (oracle managed file) for the database on the linux platform. the parameter - DB_CREATE_FILE_DEST had been set. at the present time, we received a message from global warming this tablespace criterion is 85% full.
According to the document of the oracle, OMF auto will add a data file in the tablespace tast. more than a week, I do not see any data file has been added by OMF.
I want to know when OMF adds the data file in the tablespace? 85% or 95% or some (parameter) setting this action?
Thank you
newdba
OMF does not automatically add a new data file. You must explicitly add a new data file with the ALTER TABLESPACE ADD DATAFILE command tbsname.
What is OMF is to provide a Unique name and a default size (100 MB) for the data file. That is why the ALTER TABLESPACE... Command ADD DATAFILE that you run didn't need to specify the file size or file name.
Hemant K Collette
-
What happens if AUTOEXTEND is turned on and the data file reaches the limit?
Hello
I m using Oracle 11 g. I created a tablespace by using the following command:
CREATE TABLESPACE MYTABLESPACE
DATAFILE '< PATH > '.
SIZE 1 G AUTOEXTEND ON MEASUREMENT OF LOCAL MANAGEMENT AUTOALLOCATE;
The data file is almost full. The question is: given that AUTOEXTEND is enabled, a new data file will automatically create the original data file reaches the limit? (data file is PETIT_FICHIER)
I would appreciate your help.
Thank you998043 wrote:
HelloI m using Oracle 11 g. I created a tablespace by using the following command:
CREATE TABLESPACE MYTABLESPACE
DATAFILE ''.
SIZE 1 G AUTOEXTEND ON MEASUREMENT OF LOCAL MANAGEMENT AUTOALLOCATE;The data file is almost full. The question is: given that AUTOEXTEND is enabled, a new data file will automatically create the original data file reaches the limit? (data file is PETIT_FICHIER)
I would appreciate your help.
Thank you
File stops growing & error is thrown.
-
Cache buffers DB, file Cache Redo, DBWR, LGWR and log and data files
Hi all Experts,
I m very sory for taking your time to a matter of very basic level. in fact, in my mind, I have a confusion about the DB buffer cache and the cache of log buffers
My question is in the DB buffer cache are three types of dirty, pinned and free i-e data. and in Sales, they are all changed data data and are willing to empty in DBRW. and then he write data files.
but again bufers also works for the CDC and all the changed data is temporaryliy chacheed bufers redo and the LGWR writes in the log files. and these data can be data are committed or not. and when the log switch is held, then it writes data to data files commited
My question is that if a log file may have committed data type and stop and when a log switch takes place then only the data are committed are transferred to datafiles, then where are the data no go?
If dirty pads also contain modified data so wath is the diffrence between the bufers and data log data incorrect.
I know that this can be funny. but I m maybe wrong abot the concept. Please correct my concept about this
Thank you very much
Kind regardsuser12024849 wrote:
Hi all Experts,I m very sory for taking your time to a matter of very basic level. in fact, in my mind, I have a confusion about the DB buffer cache and the cache of log buffers
The first thing we do not mention this newspaper stamp in the log buffer cache. It won't make a difference to even call it that, but you should stick with the term normally used.
My question is in the DB buffer cache are three types of dirty, pinned and free i-e data.
Correction, it is the States of the buffer. These aren't the types. A buffer can be available in all of these three States. Also, note even when you would select a buffer, his first PIN before it can be given to you. Apart from this, there is a type more State called instant capture buffer aka CR (coherent reading) buffer that is created when a select query arrives for a buffer inconsitent.
and in Sales, they are all changed data data and are willing to empty in DBRW. and then he write data files.
Yes, that's correct.
but again bufers also works for the CDC and all the changed data is temporaryliy chacheed bufers redo and the LGWR writes in the log files. and these data can be data are committed or not.
That is partially right. The buffer which is written by DBWR in the data file is a full buffer while in the log buffer, it is not the entire block that is copied. Oracle enters the log buffer called vector of change . It's actually the representation of this change that you made in the data block. It is the internal representation of the change that is copied into the log block and is much smaller in size. The size of the buffer of paper compared to the buffer cache is much smaller. What you mentioned about the writing of written data room again or not committed is correct. His transactional change that needs to be protected and therefore is almost always written in the restore log file by progression of the LGWR.
and when the log switch is held, then it writes data to data files commited
Fake! To the command log, Checkpoint is triggered and if I'm wrong, its called point of control of thread . This causes DBWR write buffers dirty this thread in the data file regardless of whether or not they are committed.
>
My question is that if a log file may have committed data type and stop and when a log switch takes place then only the data are committed are transferred to datafiles, then where are the data no go?
As I explained, it is not only the validated data are written to the file data but committed and not committed is written.
If dirty pads also contain modified data so wath is the diffrence between the bufers and data log data incorrect.
Read my response above where I explained the difference.
I know that this can be funny. but I m maybe wrong abot the concept. Please correct my concept about this
No sound is not funny, but make sure that you mix in anything else and understand the concept that he told you. Assuming that before understanding can cause serious disasters by getting the concepts clearly.
Thank you very much
HTH
Aman... -
Automatic indexation shows that partial data
Hello world
Please see the attachment. I added notes where the data are reported missing. I know this has something to do with automatic indexing and I spent a bit of time to read about it and try different things, but I really need help now please.
Thank you!
-
DASYLab how to write data to a file every 15 minutes
Hi all
I use dasylab and datashuttle/3000 to record data. What I want to do is to write data to a file every 15 minutes. I use the milti-file, which can write data to the file diffenret, but how do I control the timing, as the journal data every 15 minutes automatically.
The other problem is that I use FFT analysis of the frequency spectrum. How can I determine the value of frequency where the peaks that happens.
Thank you
Write less data in the file that you have collected requires the reduction of certain data.
There are three techniques to consider.
With an average or an average of block - both reduce the data by using a function of averaging, defined in the module. To accomplish the reduction of data, choose block or RHM mode in the dialog box properties, and then enter the number of samples/data values that you want to reach on average.
Average - when you reduce the data, you also should reblock data using the block length of the change in the output parameter. For example if you enjoy at 100 samples/second with a block size of 64, the average module configured on average, more than 10 samples will take 10 times longer to fill a block. The initial block represent 0.64 seconds, the output block represent 6.4 seconds at a sampling rate of 10 samples/second. If you change the size of output in one block, the program remains sensitive.
Average block - average values in a block against each subsequent block, where the average is based position. The first samples are averaged, all second samples are average... etc. The output is a block of data, where each position has been averaged over the previous blocks. This is how you will be an average data FFT or histogram, for example, because the x-axis has been transformed in Hz or bins.
Second technique - separate module. This allows to reduce the data and the effective sampling rate jumping blocks or samples. For example, to reduce the data in 1000 samples / second to 100 samples per second, configure the module to keep a sample, jumping 9, keep one, jumping 9, etc. If you configure to skip blocks, you will not reduce the sampling frequency, but will reduce the overall amount of data in a single block 9, for example. It is appropriate for the FFT data or histogram, for example, to have the context of the correct data.
Finally, you can use a relay and a synchronization module module to control. For example, to reduce a sample data every 15 seconds, configure a generator module of TTL pulses for a cycle of 15 seconds of time. Connect it to a Combi trigger module and configure it to trigger on rising and stop the outbreak directly, with a trigger value after 1. The trigger output connects to the X of the relay command input.
In addition to these techniques, you can change the third technique to allow a variable duration using a combination of other modules.
Many of these techniques are covered in the help-tutorial-Quickstart, as the data reduction is one of the most frequently asked questions.
In regards to the FFT... use the module of statistical values in order to obtain the Maximum and the Max Position. The Position of Max will be the value of the frequency associated with the Maximum value. The output of the statistics module is a single sample per block. Look at the different FFT sample installed in the worksheet calculation/examples folder.
-
global variable functional to read and write data from and to the parallel loops
Hello!
Here is the following situation: I have 3 parallel while loops. I have the fire at the same time. The first loop reads the data from GPIB instruments. Second readers PID powered analog output card (software waveform static timed, cc. Update 3 seconds interval) with DAQmx features. The third argument stores the data in the case of certain conditions to the PDM file.
I create a functional global variable (FGV) with write and read options containing the measured data (30 double CC in cluster). So when I get a new reading of the GPIB loop, I put the new values in the FGV.
In parallel loops, I read the FGV when necessary. I know that, I just create a race condition, because when one of the loops reads or writes data in the FGV, no other loops can access, while they hold their race until the loop of winner completed his reading or writing on it.
In my case, it is not a problem of losing data measured, and also a few short drapes in some loops are okey. (data measured, including the temperature values, used in the loop of PID and the loop to save file, the system also has constants for a significant period, is not a problem if the PID loop reads sometimes on values previous to the FGV in case if he won the race)
What is a "barbarian way" to make such a code? (later, I want to give a good GUI to my code, so probably I would have to use some sort of event management,...)
If you recommend something more elegant, please give me some links where I can learn more.
I started to read and learn to try to expand my little knowledge in LabView, but to me, it seems I can find examples really pro and documents (http://expressionflow.com/2007/10/01/labview-queued-state-machine-architecture/ , http://forums.ni.com/t5/LabVIEW/Community-Nugget-2009-03-13-An-Event-based-messageing-framework/m-p/... ) and really simple, but not in the "middle range". This forum and other sources of NEITHER are really good, but I want to swim in a huge "info-ocean", without guidance...

I'm after course 1 Core and Core 2, do you know that some free educational material that is based on these? (to say something 'intermediary'...)
Thank you very much!
I would use queues instead of a FGV in this particular case.
A driving force that would provide a signal saying that the data is ready, you can change your FGV readme... And maybe have an array of clusters to hold values more waiting to be read, etc... Things get complicated...
A queue however will do nicely. You may have an understanding of producer/consumer. You will need to do maybe not this 3rd loop. If install you a state machine, which has (among other States): wait for the data (that is where the queue is read), writing to a file, disk PID.
Your state of inactivity would be the "waiting for data".
The PID is dependent on the data? Otherwise it must operate its own, and Yes, you may have a loop for it. Should run at a different rate from the loop reading data, you may have a different queue or other means for transmitting data to this loop.
Another tip would be to define the State of PID as the default state and check for new data at regular intervals, thus reducing to 2 loops (producer / consumer). The new data would be shared on the wires using a shift register.
There are many tricks. However, I would not recommend using a basic FGV as your solution. An Action Engine, would be okay if it includes a mechanism to flag what data has been read (ie index, etc) or once the data has been read, it is deleted from the AE.
There are many ways to implement a solution, you just have to pick the right one that will avoid loosing data. -
Automatic indexation 2D array in the loop For - what is happening?
I found many sources dealing 1 d tables in a loop For or a While loop, using automatic indexing, but nothing on the tables of higher order.
I work with a program that feeds a 2D array in a loop (see table). From what I see, it looks like this the results of automatic indexing in a 1 d, the first column of table 2-D table.
This is the expected behavior, and it would hold true for arrays of higher order, table 3D for example?
Is it possible to refer to the second column rather than the first?
wildcatherder wrote:
I found many sources dealing 1 d tables in a loop For or a While loop, using automatic indexing, but nothing on the tables of higher order.
I work with a program that feeds a 2D array in a loop (see table). From what I see, it looks like this the results of automatic indexing in a 1 d, the first column of table 2-D table.
N ° it auto-index through a line at a time table. You will get a 1 d table which consists of all of the columns that make up each row in each iteration.
This is the expected behavior, and it would hold true for arrays of higher order, table 3D for example?
Yes. Automatic indexing on a 3D Board will give you a table on each iteration of each page 2D.
Is it possible to refer to the second column rather than the first? This question applies once you understand the first response.
-
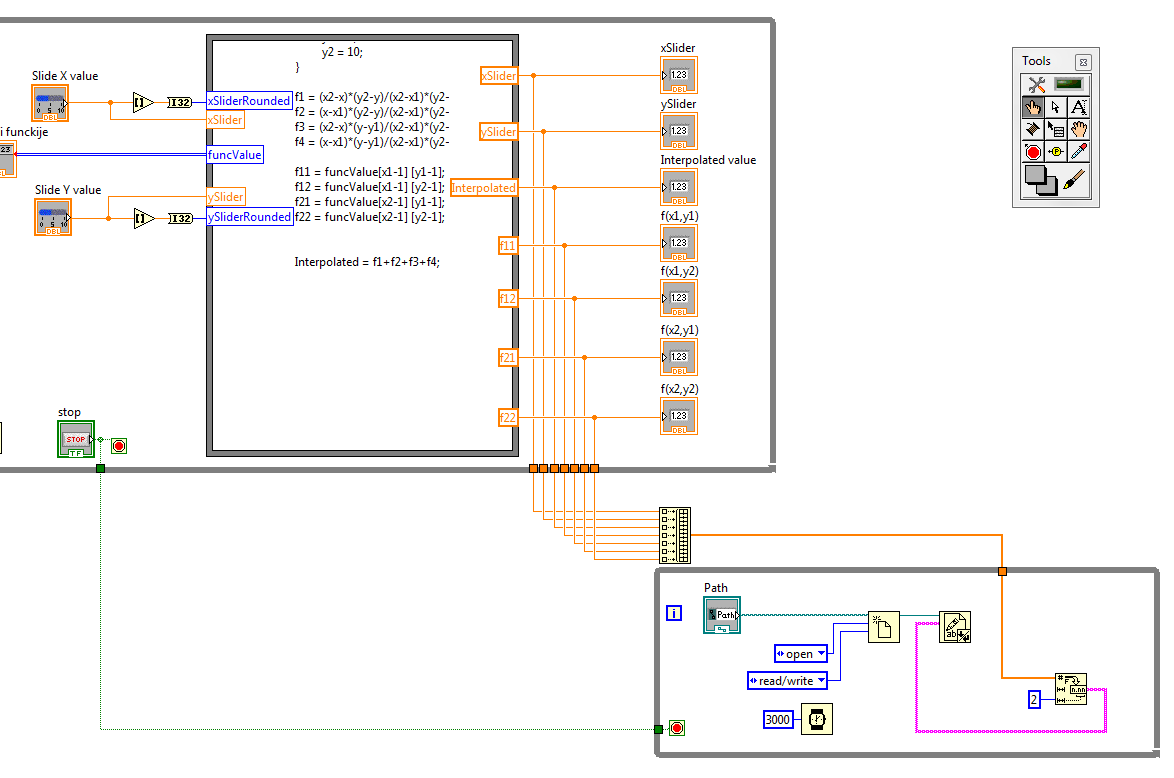
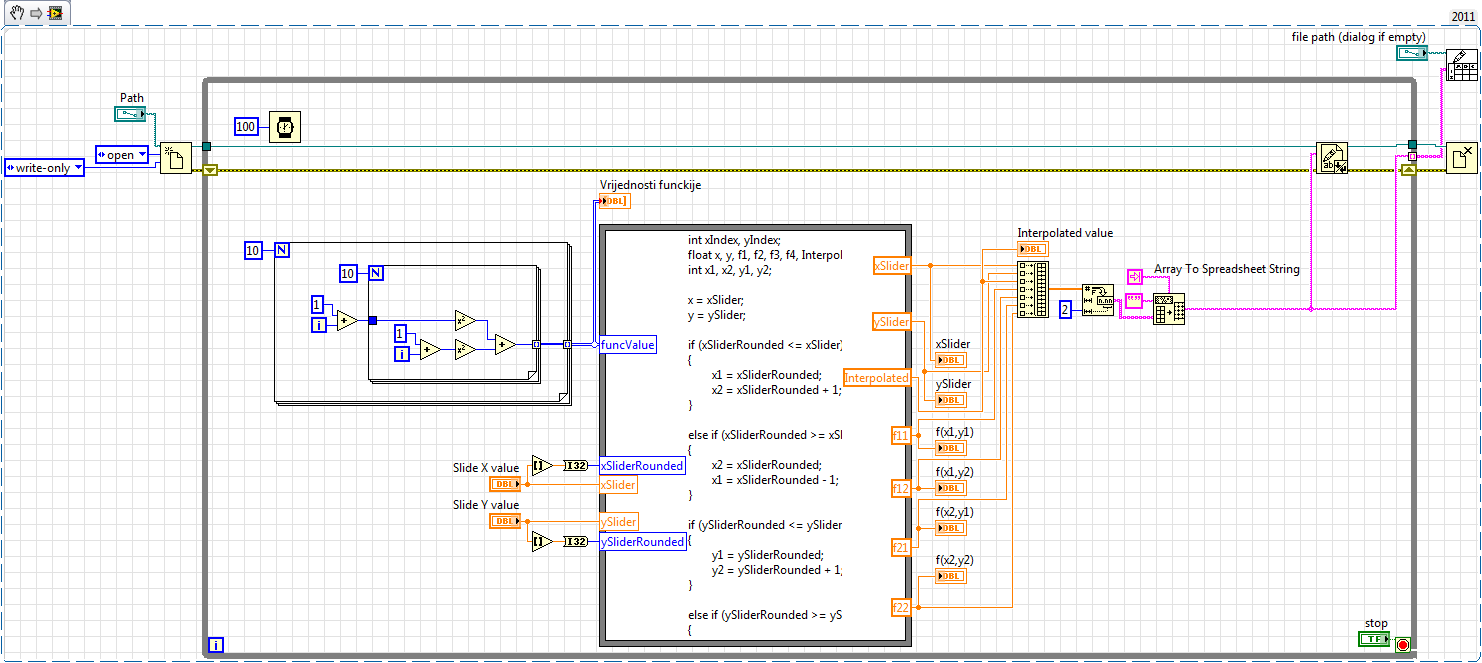
How constantly write data in a txt file
Hello
first of all, sorry for the bad English, but I have a problem to write data continuously to the txt file... I have a chart 2D with values based 2 sliders (sliders values) and some functions I want to interpolate the value by using the bilinear method... and after that the value of the sliders, interpolated value and the value of the closest points, I want to write to a file txt... for every 2-3 seconds perhaps, it would be ideal to be formatted as ::
x y f f1 f2 f3 f4
.. .. .. . .. . .. ... . ..
... ... .. ... ... ... ...but... first of all I have a problem with writing data, because every time he deletes old data and simply write a new and it is not horizontal... I am very very new to this (it's obvious) and any help will be very grateful

Thank youDiane beat me to it, I made a few changes to your code, so I'll post it anyway.
As proposed, please go through the tutorials.
I added an entry to the worksheet at the end node just to show it can be done at the end so. Table of building on a while loop is not very efficient memory, but it's just to show you what can be done. If you plan to go this route, initialize an array and use the subset to the table replace.
All the best.
-
Automatic indexing does not as soon as the first element of the array.
Hello
I have a state machine that uses automatic indexing in most of his State to write the registry to set the part for some test. When the state machine reaches the section 'Now playing' (the fourth State, second battery sequence) I have a picture of two equal elements related to looping for to write the required registers for this specific test. When I enter the current state read the the first address is the second element of the array which is '1' location and not the first address that must be '0 '. I closed the program and restarted LabVIEW but I always get the second element in this loop that maintain the form part works correctly and I get an error because the first element turns on the chip. Is there something I'm not see when it comes to self that he would keep from starting at the first element of indexing? Please take a look and let me know what I can do wrong. I have attached the main program and the print loop results screens and test probe. Any help will be great. It worked last week.
I don't see no problem at all when I copy the loop in an another VI in order to run it. Your jpg shows nothing on the values of the probe.
-
Read file, reformat the data, write new file
Oracle 11g PL/SQL.
I have a need to read an existing file, reformat the drive and write to a new file format.
My solution has been to read the file using utl_file and store it in an array of procedure1. There is a column of data to hold 1000 bytes of data for each line of the file.
Then in procedure2, read the data through a cursor column, with a certain logic and fill in the fields of a record type object by using the function substr on the data column. The type of record object has about 80 columns, all TANK types. The OUT of procedure2 parameter would be the type of record object.
Then in procedure3, record object would be the parameter, and this recording would be used to write the new line of the file. The problem I see now is that I can't convert the object record type a TANK in order to write the file. So that would mean that I have to reference each of the 80 columns once again in procedure 3 and concatenate each for the parameter buffer utl_file.put_file.
I don't want to assign values for columns of 80 exit more than once because that makes the code very long and detailed, so I thought that I assign values to the time in the record object, then pass the record object to the write file procedure.
I'm looking for suggestions on a better design, or have I missed some very basic code design?
Thank you.
Thanks for all the great suggestions.
The original file is from a COBOL program. What I ended up doing was reference and readability, I have defined/filled all fields of provision of COBOL in my program and then concatenated fields during the construction of the output string. It's a bit verbose, since the 80s fields appear twice, but the code is clear and easy to understand for support purposes.
Thanks again for all the thoughtful suggestions.
Maybe you are looking for
-
Validity of the certificate of security on a Web site
I am looking for help on the validity and security of a Web site.The page in question is the one that opens when you click the 'Start' button on this page: https://www.gov.UK/send-VAT-return When you press the "Start now" button a new tab opens and b
-
Satellite L300 - I forgot my BIOS password
So basically I forgot my BIOS password.When I try to enter in BIOS it asks for password and I don t knowledge. I really need cos I'm trying to install windows and I need to change the parameters of the hard disk to install it so I don't get the defec
-
HP ENVY 17-j137l: how hp 17-j137l with intel core i7-4710mq overclock?
I just bought a new HP ENVY 17-j137l with the following specifications: CPU: Intel Core i7-4710 mq 2.5 Ghz up to 3.5 with Turbo boost. GPU: Intel HD 4600 400 Mhz integrated graphics up to 1.4 Ghz RAM: 12 GB How can I increase my performance cpu/gpu f
-
How can I re install vista windows home on my pc.
I want to wipe the drive and re install. but I have no disk can be done online or can I get the disc to down load online
-
RV180W add the access point with itinerant support
I have a client with a RV180w the latest firmware running. We currently use the router as a router and provide wireless access. We want to add a wireless coverage and I'm interested in our options. We have a network unifying ethernet that we could