understand the buffer behavior
Hello
I'm developing an application with c ++ which uses a voltage of anaolg entry. I develop with a simulated device usb-6210.
on a slow computer, I get an error 200279 memory buffer for which I found lots of useful information already. I am trying to understand the behavior of the buffer by comparing a slow and a fast machine. Please see the following picture:
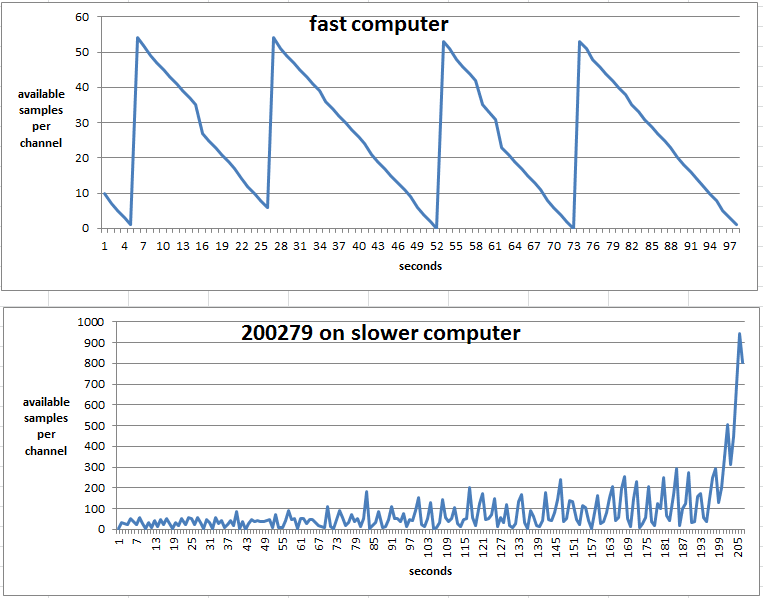
I collect samples available in the buffer of each second with DAQmxGetReadAvailSampPerChan. the same exact version of my app works on both computers.
my questions are:
(a) how is it buffer behaving this way in the picture above? a 200279 never happens on the fast computer.
(b) in the diagram below you can see the available samples accumulate while returning to zero every two seconds. Why is this, and can somehow avoid this?
Thank you!
Hi dan,.
Thanks for you answer. Yes, I use continuous data acquisition and then I draw the data on the screen. I solved the crash on the slower computer by putting in place a ring buffer. I used to have a buffer that has been in constant growth, makes additional communal memory. the slower machine has less memory than the young, so I guess it is slowed down when less and less memory was freely available.
I think the same thing would have happened on the fast computer, but it could take hours (4 times more memory), so I don't know about you.
the tips in the above chart every 20 seconds remain a mystery but not so important.
Welcome,
mael15
Tags: NI Hardware
Similar Questions
-
Copies of unexpected CR in the buffer cache
Hello
While trying to understand the mechanisms of the Oracle buffer cache, I ran a little experiment and observed an unexpected result. I believe that my expectation was wrong, and I would be so grateful, if someone could explain to me what I misunderstood.
From what I understand, a copy of coherent reading (CR) of a buffer in the cache is created, when the old content of a buffer to be read, for example to ignore changes made by a transaction not yet committed when you query a table. I also thought, that copies of CR in the buffer cache can be reused by subsequent queries requiring a roll back image of the corresponding block.
Now, I ran the following experiment on a DB of 10.2 or slowed down.
1. I create a BC_TEST table (in a non-SAMS tablespace)
-> V$ BH shows an A buffer with XCUR status for this table - V$ BH. COURSE number is 4, which indicates a segment according to various sources on the internet header.
2 session 1 inserts a row into the table (and not valid)
-> Now V$ BH shows 8 pads with XCUR status attached to the BC_TEST table. I think it's the blocks of a certain extent be allocated to the table (I expected as a block of data to load into the cache in addition to the header that was already there in step 1). There are still buffers with CLASS A # = 4 of step 1, a buffer B with XCUR and CLASS status # = 1, which indicates a block of data, according to various sources on the internet, and other 6 blocks with FREE status and CLASS # = 14 (this value is decoded differently in different sources on the internet).
3 session 2 emits a ' select * from bc_test ".
-> V$ BH shows 2 extra buffers with CR and the same FILE status #/ BLOCK # as buffer B in step 2. I understand that it compatible read copy needs to be done to undo the uncommitted changes in step 2 - However, I do not understand why * 2 * these copies are created.
Note: with a slight variation of the experience, if I don't "select * from bc_test" in Session 2 between step 1 and 2, and then then I only get CR 1 copy in step 3 (I expect).
4 session 2 issues "select * from bc_test"new"
-> V$ BH presents yet another extra stamp with CR and the same FILE status #/ BLOCK # as buffer B step 2 (i.e. 3 these buffers in total). Here I don't understand, why the request cannot reuse the CR copy already created in step 3 (which already shows B buffer without changes to the transaction not posted in step 2).
5 session 2 questions repeatedly ' select * from bc_test "new"
--> The number of buffers with CR and the same FILE status #/ BLOCK # as buffer B step 2 increases by one with each additional request up to a total of 5. After that, the number of these buffers remains constant after additional queries. However various session statistics 2 ("consistent gets", "Blocks created CR", "the consistent changes", "data blocks consistent reads - undo records applied," "no work - gets consistent reading") suggests, that session 2 continues to generate copies of current reading with each "select * of bc_test" (are the buffers in the buffer cache may simply be reused from there on?).
To summarize, I have the following question:
(I) why the insertion of a single line (in step 2) load 8 blocks in the buffer cache - and what does the CLASS # = 14 indicate?
(II) why the first select statement on the table (step 3) creates 2 copies of CR (use single) data block of the table (instead of one as I expect)?
(III)) why other issues create copies of CR of this block of data that is unique (instead of reusing the copy created by the first select statement CR)?
(IV) which limits the number of CR created copies to 5 (is there some parameter checking this value, it is according to some sizing of the cache or is it simply hard-coded)?
(V) what exactly triggers the creation of a copy of CR of a buffer in the buffer cache?
Thank you very much for any answer
Kind regards
Martin
P.S. Please find below the Protocol of my experience
--------------------------------------------------
Control session
--------------------------------------------------
SQL > drop table bc_test;
Deleted table.
SQL > create table bc_test (collar number (9)) tablespace local01;
Table created.
SQL > SELECT bh.file #, bh.block #, bh.class #, bh.status, bh.dirty, bh.temp, bh.ping, bh.stale, bh.direct, bh.new
2 from V$ BH bh
3, o dba_objects
4. WHERE bh. OBJD = o.data_object_id
5 and o.object_name = 'BC_TEST. '
6 order of bh.block #;
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur O N N N N N
--------------------------------------------------
Session 1
--------------------------------------------------
SQL > insert into bc_test values (1);
1 line of creation.
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur O N N N N N
5 210 1 xcur O N N N N N
5 211 14 free N N N N N N
5 212 14 free N N N N N N
5 213 14 free N N N N N N
5 214 14 free N N N N N N
5 215 14 free N N N N N N
5 216 14 free N N N N N N
8 selected lines.
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > select * from bc_test;
no selected line
Statistics
----------------------------------------------------------
28 recursive calls
0 db block Gets
Gets 13 coherent
0 physical reads
size of roll forward 172
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 xcur N N N N N N
5 211 14 free N N N N N N
5 212 14 free N N N N N N
5 213 14 free N N N N N N
5 214 14 free N N N N N N
8 selected lines.
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > /.
no selected line
Statistics
----------------------------------------------------------
0 recursive calls
0 db block Gets
Gets 5 in accordance
0 physical reads
size of roll forward 108
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL >
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 xcur O N N N N N
5 211 14 free N N N N N N
5 213 14 free N N N N N N
5 214 14 free N N N N N N
8 selected lines.
SQL >
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > select * from bc_test;
no selected line
Statistics
----------------------------------------------------------
0 recursive calls
0 db block Gets
Gets 5 in accordance
0 physical reads
size of roll forward 108
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL >
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 xcur O N N N N N
5 211 14 free N N N N N N
5 213 14 free N N N N N N
8 selected lines.
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > select * from bc_test;
no selected line
Statistics
----------------------------------------------------------
0 recursive calls
0 db block Gets
Gets 5 in accordance
0 physical reads
size of roll forward 108
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 xcur O N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 211 14 free N N N N N N
5 213 14 free N N N N N N
9 selected lines.
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > select * from bc_test;
no selected line
Statistics
----------------------------------------------------------
0 recursive calls
0 db block Gets
Gets 5 in accordance
0 physical reads
size of roll forward 108
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL >
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 xcur O N N N N N
7 selected lines.
--------------------------------------------------
Session 2
--------------------------------------------------
SQL > /.
no selected line
Statistics
----------------------------------------------------------
0 recursive calls
0 db block Gets
Gets 5 in accordance
0 physical reads
size of roll forward 108
272 bytes sent via SQL * Net to client
374 bytes received via SQL * Net from client
1 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL >
--------------------------------------------------
Control session
--------------------------------------------------
SQL > /.
FOLDER # BLOCK # CLASS # STATUS D T P S D N
5 209 4 xcur N N N N N N
5 210 1 xcur O N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
5 210 1 cr N N N N N N
7 selected lines.What version of 10.2, on what platform, and enabled to RAC? What exactly was the tablespace definition?
(I) why the insertion of a single line (in step 2) load 8 blocks in the buffer cache - and what does the CLASS # = 14 indicate?
It sounds like you may have formatted all of the first measure - assuming that you use 8 KB blocks and allocated system extended. But it didn't happen when I checked 10.2.0.3 on a version of the single instance of the Oracle.
Class 14 is interpreted as "unused" in all versions of Oracle that I saw. This would be consistent with the formatting, but it bringing is not below the high water mark. You could ' alter system dump datafile N block min X block max Y' for the segment header block, the block used and unused block in the discharge.
(II) why the first select statement on the table (step 3) creates 2 copies of CR (use single) data block of the table (instead of one as I expect)?
Maybe because the first copy clean uncommitted transactions and clones of the second copy of the result to return to a given SNA - but that's just a guess, I had not noticed this behavior before, so I have to do some experiments to find out why it's happening.
(III)) why other issues create copies of CR of this block of data that is unique (instead of reusing the copy created by the first select statement CR)?
The first block of CR you create includes a moment earlier that the beginning of the second query, so your session must start from the current. If you have set the isolation level to fix SNA session (for example, "set transaction read only") before the first application, in my view, you would see that the copies of CR will not increase after the initial creation.
(IV) which limits the number of CR created copies to 5 (is there some parameter checking this value, what is according to some sizing of the cache or is simply badly coded)?
Hidden parameter Dbblock_max_cr_dba which, by default, is 6. The code still does not seem to obey this limit, but generally you will see only 6 copies of a block in the buffer.
(V) what exactly triggers the creation of a copy of CR of a buffer in the buffer cache?
There are at least two options - (a) a session needs to see a copy of a block with recent changes removed, either because they are uncommitted transactions, the session needs to see the block he was when he started to run a particular query or transaction, (b) a session changed a block when he gets hold of the current version - and in certain circumstances (possibly when the update is through a analysis), it will make a copy of the block, mark the previous CR copy, mark the new copy as xcur, and change the copy.
Incidentally, xcur is a RAC status - it is possible to have blocks in the buffer which are xcur, but not "obtained in current mode.
Concerning
Jonathan Lewis -
Question Basic setting, ask questions about the buffer cache
Database: Oracle 10g
Host: Sun Solaris, 16 CPU server
I look at the behavior of some simple queries that I start the tuning of our data warehouse.
Using SQL * more and AUTOTRACE, I ran this query two times in a row
SELECT *.
OF PROCEDURE_FACT
WHERE PROC_FACT_ID BETWEEN 100000 AND 200000
He finds the index on PROC_FACT_ID and conducted an analysis of the range of indexes to access the data in the table by rowid. The first time, that it ran, there are about 600 physical block reads as data in the table were not in the buffer cache. The second time, he had 0 physical block reads, because they were all in the cache. All this was expected behavior.
So I ran this query twice now,
SELECT DATA_SOURCE_CD, COUNT (*)
OF PROCEDURE_FACT
DATA_SOURCE_CD GROUP
As expected, he made a full table scan, because there is no index on DATA_SOURCE_CD and then chopped the results to find the different DATA_SOURCE_CD values. The first run had these results
compatible gets 190496
physical reads 169696
The second run had these results
compatible gets 190496
physical reads 170248
NOT what I expected. I would have thought that the second run would find many of the blocks already in the cache of the pads of the first execution, so that the number of physical reads would drop significantly.
Any help to understand this would be greatly appreciated.
And is there something that can be done to keep the table PROCEDURE_FACT (the central table of our star schema) "pinned" in the buffer cache?
Thanks in advance.
-chris CurzonChristopher Curzon wrote:
Your comment about the buffer cache used for smaller objects that benefit is something that I asked about a good deal. It sounds as if tuning the buffer cache will have little impact on queries that scan of entire tables.Chris,
If you can afford it and you think it is a reasonable approach with regard to the remaining segments that are supposed to benefit the buffer cache, you can always consider your segment of table with 'CACHE' that will change the behavior on the full of a broad sector table scan (Oracle treats small and large segments differently during the execution of table scans complete regarding the cache of) marking stamps, you can override this treatment by using the CACHE. NOCACHE keyword) or move your table of facts to a DUNGEON hen establishing a (ALTER SYSTEM SET DB_KEEP_CACHE_SIZE =
), modify the segments (ALTER TABLE... STORAGE (USER_TABLES KEEP)) accordingly and perform a full table scan to load blocks in the cache of the DUNGEON. Note that the disadvantage of the approach of the KEEP pool is that you have less memory available for the default buffer cache (unless you add more memory on your system). When an object to mark as being cached is always is in competition with other objects in the cache buffers by default, so it could still be aged out (the same applies to the pool of DUNGEON, if the segment is too large or too many segments are allocated age blocks out as well).
So my question: How can I get for a parallel analysis on queries that use a table scan complete such as what I posted in my previous email? It is a question of the provision of the "parallel" indicator, or is it an init.ora parameter I should try?
You can use a PARALLEL hint in your statement:
SELECT /*+ PARALLEL(PROCEDURE_FACT) */ DATA_SOURCE_CD, COUNT(*) FROM PROCEDURE_FACT GROUP BY DATA_SOURCE_CD;or you could mark an object as PARALLEL in the dictionary:
ALTER MATERIALIZED VIEW PROCEDURE_FACT PARALLEL;Note that since you have 16 processors (or 16 cores that resemble Oracle 32? Check the CPU_COUNT setting) the default parallel degree would be usually 2 times 16 = 32, which means that Oracle generates at least 32 parallel slaves for a parallel operation (it could be another set of 32 slaves if the operation for example include a GROUP BY operation) If you do not use the PARALLEL_ADAPTIVE_MULTI_USER parameter (which allows to reduce the parallelism if several parallel operations running concurrently).
I recommend to choose a lesser degree parallel to your default value of 32 because usually you gain much by such a degree, then you can get the same performance when you use lower a setting like this:
SELECT /*+ PARALLEL(PROCEDURE_FACT, 4) */ DATA_SOURCE_CD, COUNT(*) FROM PROCEDURE_FACT GROUP BY DATA_SOURCE_CD;The same could be applied to the paralleling of the object:
ALTER MATERIALIZED VIEW PROCEDURE_FACT PARALLEL 4;Note When defining the object of many operations in PARALLEL will be parallelisee (DML even can be run in parallel, if you enable dml parallel, which has some special restrictions), so I recommend to use it with caution and begin with an explicit indication in those statements where you know that it will be useful to do.
Also check that your PARALLEL_MAX_SERVERS is high enough when you use parallel operations, which should be the case in your version of Oracle.
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/ -
How to use the buffer circulation
Hello!
I am a new user of DasyLAB. I use DasyLAB 12. I want to use the cirular buffer, but I do not understand what it does? I want to not write that measured data the past 60 seconds (for a testrun) in an output file and from the thought that the circular buffer would do. But he has an entrance and an exit. There is no record actually works. What is the circular buffer for and how can I write the measured data of the last 60 seconds? I tried to connect a file block directly writing to the output of the buffer, but it does not work.
Thanks a lot, and what concerns the best.
Hilby
DASYLab written stream of data in the buffer. You must use module action to free the data. To understand how, use a switch to trigger an 'event' manually. For an example, see the attached sheet.
You can use a time-module base to generate a "pulse per minute" to make the data once per minute.
Another idea: use the multi-file-option to Write Data-module:
Length of the index = a number, the first digit 0, last number 1
«Using a time-module "Impulses per minute" and fix an action-module: target is the writing data module, the action is then "file".»
DASYLab written now a minute of data to the first file. Data from the second minute will be written in the second file. Data from the third minute overwrites the first file, the data from the fourth minute crushes the second file.
And so on.
See attachment 'multifile.zip '.
-
all samples n transferred from the buffer
Hi all
I have a question for every N samples transferred DAQmx event buffer. By looking at the description and the very limited DevZones and KBs on this one, I am inclined to believe that the name is perfectly descriptive of what must be his behavior (i.e. all samples N transferred from the PC buffer in the DAQmx FIFO, it should report an event). However, when I put it into practice in an example, either I have something misconfigured (wouldn't be the first time) or I have a basic misunderstanding of the event itself or how DAQmx puts in buffer work with regeneration (certainly wouldn't be the first time).
In my example, I went out 10 samples from k to 1 k rate - so 10 seconds of data. I recorded for every N samples transferred from the event of the buffer with a 2000 sampleInterval. I changed my status of application of transfer of data within the embedded memory in full with the hope that it will permanently fill my buffer with samples regenerated (from this link ). My hope would be that after 2000 samples had been taken out by the device (e.g., take the 2 seconds) 2000 fewer items in the DMA FIFO, it would have yielded 2000 samples of the PC for the FIFO DMA buffer and so the event fires. In practice it is... not to do so. I have a counter on the event that shows it fires once 752 almost immediately, then lights up regularly after that in spurts of 4 or 5. I am at a loss.
Could someone please shed some light on this for me - both on my misunderstanding of what I'm supposed to be to see if this is the case and also explain why I see what I see now?
LV 2013 (32 bit)
9.8.0f3 DAQmx
Network of the cDAQ chassis: 9184
cDAQ module: 9264Thank you
There is a large (unspecced, but the order of several MB) buffer on the 9184. He came several times on the forum, here a link to an another discussion about this. Quote me:
Unfortunately, I don't know the size of this buffer on the 9184 on the top of my head and I don't think it's in the specifications (the buffer is also shared between multiple tasks). This is not the same as the sample of 127 by buffer slot AO which is present on all chassis cDAQ - controller chassis ethernet / wireless contains an additional buffer which is not really appropriate I can say in published specifications (apparently it's 12 MB on the cDAQ wireless chassis).
The large number of events that are triggered when you start the task is the buffer is filled at startup (if the on-board buffer is almost full, the driver will send more data — you end up with several periods of your waveform output in the built-in buffer memory). So in your case, 752 events * 2000 samples/event * 2 bytes per sample = ~ 3 MB of buffer memory allocated to your task AO. I guess that sounds reasonable (again would really a spec or KB of...) I don't know how the size of the buffer is selected).
The grouping of events is due to data sent in packages to improve efficiency because there is above with each transfer.
The large buffer and the consolidation of the data are used optimizations by NOR to improve flow continuously, but can have some strange side effects as you saw. I might have a few suggestions if you describe what it is you need to do.
Best regards
-
Current playback position exceeds the buffer size? VB6 with NIDAQmx 9
I have an application written in VB6 that does HAVE and AO, with both using the Ctr0 internal as the clock to check that they are in sync. It seems to work very well. I use a USB-6212 and a recent version of NIDAQmx.
I am tracking the current playback Position by calling DAQmxGetReadCurrReadPos_VB6 in the EveryNCallback routine.
Strangely, the value for each call correctly increases the number of returned samples (for example, 128), but instead of round package when it reaches the upper limit of the buffer (for example 16 * 128) it keeps growing to infinity. No error is reported by the call to DAQmxGetReadCurrReadPos_VB6 or anything else.
Am I misunderstood something? This function seems to be to just return the total number of samples read, not the position in the buffer.
What I expect the value of the current to be playback Position:
128, 256, 384, etc.. the limit of the buffer for example 16 x 128 = 2048 how he could start over at 1 (or zero depending on the way which you set up your berries).
Van
Hi afmstm,
The behavior you're seeing is indeed good, and I agree that the description that it is misleading. The current description says:
"In the samples per channel, shows the current position in the.
buffer.The description should be interpreted as:
"In the samples per channel shows the current position the acquisition."
So yes, for a relative position within your stamp, you must perform a modulo operation.
That being said, it's not the same thing as 'total number of readings/a. Since the beginning of the program' as you say. This would be the attribute Total of samples by acquired chain . It is rarely a chance where these two alignment attributes. For example, to read N samples successfully the following must be satisfied:
Total samples by acquired channel - current read Position = N
Another distinction is that you, the user can change the current Position of playback using the properties relative to and Offset . By default you will read from the current playback Position , which creates the behavior your described.
I know it can be confusing, but this level of manipulation of streaming is a very advanced concept of DAQmx. Let me know if this raises questions or concerns more!
-
Problems with emptying the buffer for profile motion; Errors-70061-and-70137
I'm trying to generate a movement code that synchronizes a motion profile with data acquisition using breakpoints; the VI (joint) is loosely based on the 25229.vi provided on ni.com. I use a PXI-7354 controller and running Labview 2011. I can run the VI once (successfully), complete the desired query, trigger the breakpoint and take data with no error message. Then if I try to run the same VI immediately after, the engine will move only steps 5 and 6 and then stops. No data is collected, and no error message is displayed. Then when I run it it a third time, movement and data acquisition complete, but I get error messages in the clear Buffer.vi saying that the buffer is used (error-70061). I also have error-70137 to the CheckBuffer.vi, which I think is because it is still monitoring the buffer after the failure of the ClearBuffer.vi.
Do I need to include a clearing of additional buffer somewhere initialization?
Thank you
Matt
Hi MattCS,
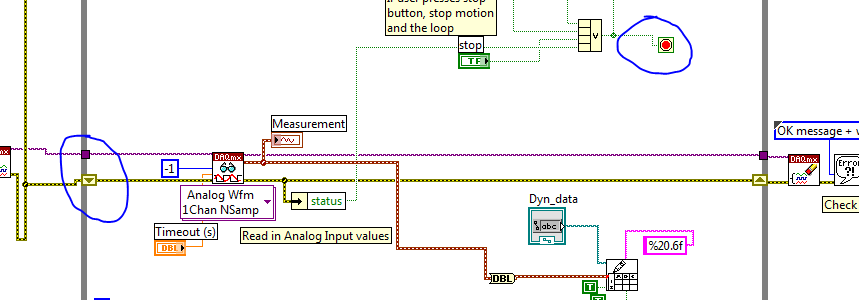
I think you see this undesirable behavior because you are not initializing your shift registers. Data of your last run are still saved in your shift registers so the next time you run it will start where it left off. So if you press stop during execution of the time VI the first it stops and everything works, but then the second time you run the VI the loop will stop after its first iteration since its listing, the old value of the shift register. Also if you ever get an error in the while loop will continue to be there every time that you run the VI. Please try the changes circled in the picture below and see if that helps.
Tim O
-
read into the buffer variable published network shared

I use a shared variable that is published in the network buffer to write data to an RT target and read data buffered by the host application.
I followed a different behavior regarding data buffering using Variable vs reading read the shared Variable node.
There is no problem the shared variable node read but using the results of reading variable function of loss of data, such as access without alkaline reserve. I can read only some of my data values.
I see no difference in access in the buffer in LV2009 help.

against
Any help is appreciated
Christian
Hi Christian,
The behavior you describe is because the client side PSP buffering is not applied to the Variable API shared in LabVIEW 2009. It was a design decision, but eventually, we hope to include this feature in a future version of LabVIEW. This bug here as you pointed out is the lack of documentation for it. Corrective Action Request # 202159 has been filed for this issue.
Let me know if you need assistance working around this issue.
See you soon,.
-
How to understand the reference trigger as a trigger to stop?
Hello
I tried to use an external signal how the trigger works / stop for analog data entry. I had looked for solutions and above all that they suggest to use a reference trigger. But I don't really understand how it is applied. For example, why it should be set to the number of samples before release? For me, the number of samples that are taken are those between the market trigger / stop... I don't really have it.
Migne
Hello master,
As see you, there is no trigger stop easily available with DAQmx. Indeed, you will need to use the reference if you want to trigger the end of the acquisition. What actually a c of reference trigger on a task must begin a kind of continuous acquisition until the trigger occurs. Then by default you will get a certain number of samples before (before) and after (after release) edge relaxation when you read the buffer after the triggering event.
To read data continuously during the acquisition, you must change a property to change the access mode during playback. You will also need to manage properly reading the buffer has you will certainly get the same amount of samples during the last reading.
Detailed explanation again as long as there are for example--> http://digital.ni.com/public.nsf/allkb/BA775B0E445BFA79482571FE0032CCEB?OpenDocument
-
Hello members,
I'm trying to understand why some batch repeatedly not pio, I expect.
One thing keeps popping up; Is it possible to see what is in the buffer cache. I can query v$, but not x$. Version is 10.2.0.3
Something in the lines of what segments has how many blocks in the buffer, as
ConcerningSEGMENT_NAME BLOCKS ---------------------------- ---------- SYS_IL0006063998C00032$$ 18 SYS_C0077916 108 STA_BONUS_REMIT 800 STABONREM_PK 216
Peterv$ BH.objd = DBA_OBJECTS.data_object_id
-----------
Sybrand Bakker
Senior Oracle DBA -
Prevent the default behavior of the events
How can I prevent the default behavior of the events?
I know that this concept of JavaScript or ActionScript where you can prevent the default behavior of an event by calling e.preventDefault ().
How can I achieve this in JavaFX?
For example, I have a KeyEvent on a TextArea and want to intercept the Enter key and stop him to position the cursor in the new line.
I tried consume(), but apparently, it's the equivalent of e.stopPropagation ().TextArea has a bug on the management of mouse events: http://javafx-jira.kenai.com/browse/RT-17902, whereby scrollpane transmitting text editable eating events and if the events are not exposed to users of the API, do not know if this will have an effect as the key to transformation of the text box you want to perform. If the question in 17902 is at the origin of the text box does not correctly answer the treatment of key events defined by the user, you can add an additional comment to this Jira to see.
Information on the management of events can be found here: Re: event bubbling smile of understanding
If the TextArea event management worked properly, you should probably be able to do what you want by adding an EventFilter on the text box and consuming of the event you want to capture. Do this in an EventFilter so you can intercept the event in the capture phase is best to try to do it in an EventHandler for the propagation phase. If try to consume the event in an EventHandler, it may not work because the event may already have been handled by the target node or the children of the node target.
-
Understand the iterator binding relationship of the current page
Dear all
in my quest to understand the behavior of the ADF framework, I sometimes do some experimentation. When a result is unlike what I think, it suggests that there is something wrong with the understanding
I belong to those who can not work if I do not receive an overview comprehesive of what I am working with (ADF)
Here's a simple experiment that I could use some help to understand
I created a simple application based on ADF BC and JSF (10.1.2)
The model is simple EO based on the EMP table and updatable VO based on the entity
I slipped and fell to the control of data collection in a page as a Table with record selector
I created a button with the following code
Public Sub commandButton_action(ActionEvent a)
{
Am is AppModule_rs (AppModule_rs) ADFFacesHelper.getAppplicationModule ("AppModule_rsDataControl");. / / This just a helper class to get AM name DC
ViewObject vo1 = am.findViewObject("EmpView1");
VO1. Next();
VO1. Next();
System.out.println (VO1. GetCurrentRow(). GetAttribute ("empno")); -Read the valur of the iterator of VO
DCIteratorBinding bd = ADFFacesHelper.getIteratorBinding ("EmpView1Iterator");
System.out.println (BD. GetCurrentRow(). GetAttribute ("empno")); -Read the value of the iterator binding
}
Just simple code for in-house advance lines of two pointer line and then see how this is reflected in the page. This test is just for me to understand how the iterator binding refers to the actual set of rows.
Scenario (1)
-Run the page, the first line on the page is selected - planned, VO rowselector points on the first line
-Click on the commandbutton control, the code above is executed
-the rowselector forward twice and should point to the third row on VO
-on the page of the third row must be selected
RESULT: Match perfect and both command Print print the same value
-Press and hold the control button, line guard page selector advances two lines at a time... which is good
Scenario (2)
-Run the page, the first line on the page is selected - planned, VO rowselector points on the first line
-use the mouse and select the fourth row on the screen (not pressed) - VO is always level 1, screen on set, iterator binding binds to the rowset VO is always the first row referenes
-Press the button
-the page maintains its fourth selected line, while the System.out.println (vo1.getCurrentRow ().getAttribute("Empno")); prints the 7521 value which is the third - row
-I don't feel happy, the current iterator of VO is on the third row, visually, it's fourth, which means that the selection of the user on the Web page did not consider. And this goes against my intiution
-Press again, I find that line of page selector is the sixth line (4 + 2), therefore the iterator to all VO lines (synchornized times)
Scenario (3)
Run the page, the first line on the page is selected - planned, VO rowselector points on the first line
-use the mouse and select the fourth row on the screen (not pressed) - VO is always level 1, screen on set, iterator binding binds to the rowset VO is always the first row referenes
-Press the button SUBMIT - 4th place is always selected as expected
-Now press the order button, you will see that line on the screen selector forward two rows and print indicates that the VO has also progressed to the same value
-Se TRANSLATE only after pressing send, the frame cought his breath and synchronized things
Coming background FORMS, things of this nature never would have happened with Disk Manager.
I tried to project what has happened to the lifecycle ADF to try to understand how the interaction of the user affects the selection of lines, but was unable to reach a unified solution. What follows as an attempt for scenario (2)
The user moves the selection to the fourth line
The command button is pressed.
Life cycle JSF begins with the RESTORATION of the VIEW.
Apply request values (I guess the lines selection made by the user to become an integral part of request values?)
Prepare the model (this is a post (postback), property of refreshment has ifNeeded, Binidng is created again and VO is always first in the poinitng)
Validation process (no validation as no data entry)
Model update (don't know if at this point the update of the line VO iterator? if so it should point to the fourth line)-doesn't seem to be the case
Invoke the application, the listener of the action is executed and the VO is forced to move twice under the command button code
Prepare the Render: it is a step where the link needs to be updated and reflect the currernt VO (rank 6) line
Render: The page where the sixth line is selected
where I am wrong! appreciate your comments
It's what makes the difficult framework, if it is not clearly documented so the flow is very well understood by developers in one day, the developer must spend days and days debugging problems. This sure beats the idea of using frames to increase productivity
I haveQuick question - is the button that you add code to the same area (the "select and" area) as the button submit table?
I'm guessing that it isn't and that the explanation is that just by clicking on a specific record in the table is not actually indicate to the controller layer is a selected line.
The Send button did this update.
One solution might be to set the autosubmit to the selected component to be true. -
Can someone help me understand the process Instance recovery
First thanks for all of you who responded to my post, any help is really appreciated.
I would like to more deeply understand the Instance recovery process then the Administration Guide of Oracle Docs can tell me.
What I have so far of Instance recovery is:
1 oracle determines which files are not synchronized.
2. all data from redo log files is applied to restore log buffers by progression. Buffers do not participate on the database of normal transactions because they are marked to pick it up.
All these data are applied to the data files (commited and contains transactions).
This step is called roll forward.
3 cancellation are used to restore transaction no. After this step the datafiles not aura no data contains on them. At this point, the instance is available for users, but the blocks used are not.
4. all files are now in sync.
My questions are:
-Step 1, what process determines which files are not sync? Make the bed of Smon the controlfile and data file headers and then make a list which is not sync?
-L' step 2, what is the process that reads the information in the redo log files and complete the recovery log buffer? What is the CKPT? And how he is warned that he might start to read the files after completing step 1? There is a semaphore that is defined for it?
-Step 2, which process applies information engaged and contains buffer redo log for the data files? When it starts to apply this information of the instance is already partially available to users?
-Step 3, what is the process that reads up to cancel to restore transactions not? This process must be done once step 2 is complete as could be blocks of the undo tablespace on buffers of the right-wing newspaper do it again? And when this step 3 starts, the process is triggered by an another semaphore?
-When step 3 is finished, what process changes the State of the database of partially open to open, or that's just what we call it when the database has always revenge marked for recovery?
Thanks again in advance for the help, there are reasons not practice known this information, I'm just a curious person who could not find this information on the google...
Ricardo RodriguezRicardo,
Well, I'll take a chance to respond.
(1) SMON in the start-up phase, in the strict sense in the editing phase, compares the SNA stored in the control file with the data file headers. This sCN is called checkpoint SCN. It is always higher among the controlfile so its part of the same database and is not set up to an old backup. By this correspondence, Oralce comes to know that there are some report files with their SNA control point is only not with the controlfile and consequently, instance recovery is reported. Here is the list of files is prepared.
(2) the same process SMON only would trigger playback of the redo log files and launch the Rollforward process. Roll forward is made from the last address bytes redo controlled at the end of the restore log forward. This means that the last block, blocks have not reported in the data file are simply read and are dumped on the data files. As a result, we get a situation that the data file will end up with a lot of data committed but also committed that redo is containing both.
CKPT process will not come in the picture I think. Where did you read what CKPT would do all this?
(3) SMON governs all this thing is to say the application of the data for the data files. No, in this phase, we are still in the phase of mounting that this recovery is called crash recovery. Oracle wouldn't let users to use the database at this point. Data is still not available for them.
(4) do not bring semaphores here. They are already in use when you allocated the memory of your instnace. Its work process level. After the mount phase is completed, oracle would open up the db. At this stage, "the transaction recovery" aka rear roller phase. That would be launched to relax all the operations that are not validated.
Now to do this, undo will be used. Oracle launches this phase into two or more strictly speaking 3 ways. One, SMON would just check how many blocks will be there for the recovery. If they are larger, it would begin the rear roller with parallel slaves. This is called "we demand" rollback. It is initiated by the user. So if you were using the EMP table data and the server crashed between, now the next time you start, if you try to access the same blocks once again, they are set aside on the basis of priority.
The third one will rollback transaction intra. It's basically splitting the work among the slaves so that if a slave is sitting free, it can share the work and can move forward to make things more quickly restored.
Please note that all this is happening at the open stage. This means then that this is the case, oracle is available for users. And second, there is little change in this process (an integer) 9i go. This is called two-pass recovery which has been made to make this process a little faster. In this regard, SMON ignores these blocks that are controlled by DBWR during execution of the phase of rollforward.
Hope this makes some sense and helps. Let me know if there is something wrong or unclear.
HTH
Aman... -
The scrolling behavior is not smooth after update to Mac OS Sierra
After that the macOS update Sierra the scrolling behavior has changed, does anyone have same experiences?
I can still scroll trough a Web page without a problem. I mean the scroll with 2 fingers on the touch pad or scroll with the magic mouse gesture.
BUT: In trying to slowly scroll through long lists of selections, just answers touching on fast movements, not on the slow change.
Steps to reproduce:
Open a Web site like twitter and go to preferences. Go to the time zone list, open it, and scroll through it. Can you move the cursor to line by line?
You can also move to http://www.doyouspain.com/mietwagen/ , select a country like the Spain a try to SLOWLY scroll list.
(I just discovered: the list of operating system at the end of this page shows the same problems with PCMCIA)
I found this behavior using "Parallels Desktop". I can't scroll the documents most as before the update.
Hello!
Please open the accessibility, to increase the scrolling speed move the slider from slow to fast (from left to right).
A screenshot for reference.

Thank you!
-
When I try to open the twitter/facebook etc, as sites the message that this connection is not approved appears on the screen. After some instructions another words in bold comes technical does not come from the details but "I understand the risks". What to do. Help step by step the pl
Hi Linda, can you start at the top of this discussion and see if you can identify a particular program or a device that is intercepting your secure connections?
If you want personal assistance, please start a new question and include your system information.
https://support.Mozilla.org/questions/new/desktop/fix-problems
Scroll down to the suggested items passed to continue entering in your question.


Maybe you are looking for
-
HI my friends I have an iMac end 2013 with i7 4771, 16Gb, fusion 3 TB and GeForce GTX 780 M Well, I need a display that will be same panel as my iMac... Same resolution and the same color spectrum and even in all that is possible and if is possible t
-
Password for data recovery key loss.
I'm used to firefox sync, have a password to get into my firefox sync. When I had to wipe my computer and reinstall everything what I have first of all not a recovery key because I don't have a need yet. The good news is that I have firefox for andro
-
need to view the source code in version 7 doesn't have a place in the view menu
upgrade to version 7, teaches at a high school on HTML class and we use the source of the page all the time, he disappeared in version 7. Where is it?
-
Graphic driver Win 7 Pro NB550D
Always the same problem to find a valid device driver. If I download and install the driver is not the right driver in the package. Also tried to use the AMD driver and and and...Any idea? N. Post edited by: Nightmare0815
-
need driver its free charge for windows xp
Free download need driver sound for w' xp