unexpected results of the Group and the merger of processor
Hi team,
I use a processor of group and the merger in a process that includes "Store-num" and the "Cust-num" and mergers based on the most common value.
I have few records store-Num = 42 and a few records store-num = 426. But for the same "Cust-num" for these two stores, store-num ' 426' we replace "42"
My point is that these documents should not have grouped at all.
No idea why this happen?
Kind regards
Ravi
Yes, that's correct. Dates will be converted to a string representation of the date.
Tags: Fusion Middleware
Similar Questions
-
Oracle 12 c - unexpected result with the insertion of the DBA_VIEWS view
Hello
I try inserting the DBA_VIEWS fields in a table belonging to a common C a PDB file ##SA user:
(a) the PDB PDBORCL using user C ##SA connection:
SQL * more: Production of liberation 12.1.0.1.0 kills him Sep 10 16:21:39 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Enter the password:
Last successful login time: kills Sep 10-2013 16:18:26 + 02:00
Connected to:
Database Oracle 12 c Enterprise Edition Release 12.1.0.1.0 - 64 bit Production
With the options of partitioning, OLAP, advanced analytics and Real Application Testing
C##SA@pdborcl 10.09.2013 > see the con_name
CON_NAME
------------------------------
PDBORCL
C##SA@pdborcl 10.09.2013 > see the con_id
CON_ID
------------------------------
3
(b) I create the table user SA_VIEWS_V
C##SA@pdborcl 10.09.2013 > select count (*) in the dba_views;
COUNT (*)
----------
6220
1 selected line.
C##SA@pdborcl 10.09.2013 > create table sa_views_v (owner varchar2 (128), view_name varchar2 (128));
Table created.
(c) the insertion in the table SA_VIEWS_V gave me only 65 rows at the same time lines of content 6220 dba_views:
C##SA@pdborcl 10.09.2013 > INSERT INTO SA_VIEWS_V (OWNER, VIEW_NAME) SELECT MASTER, VIEW_NAME DBA_VIEWS;
65 lines were created.
C##SA@pdborcl 10.09.2013 > commit;
Validation complete.
C##SA@pdborcl 10.09.2013 > SELECT MASTER, VIEW_NAME DBA_VIEWS;
...
IX
IX
IX
SH
6220 selected lines.
(d) you will find above the executed plan of the insert and the single select statement:
C##SA@pdborcl 10.09.2013 > select * from table (dbms_xplan.display_cursor ('aj3vkggtvv9d9'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------
SQL_ID, aj3vkggtvv9d9, number of children 0
-------------------------------------
INSERT INTO SA_VIEWS_V (OWNER, VIEW_NAME) SELECT VIEW_NAME, MASTER OF
DBA_VIEWS
Hash value of plan: 1585970530
-----------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-----------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT. | | | 136 (100) | |
| 1. LOAD TABLE CLASSIC | | | | | |
|* 2 | FILTER | | | | | |
|* 3 | HASH JOIN | | 65. 6045. 136 (0) | 00:00:01 |
|* 4 | HASH JOIN | | 65. 4875. 132 (0) | 00:00:01 |
| 5. NESTED LOOPS | | | | | |
| 6. NESTED LOOPS | | 65. 3315 | 131 (0) | 00:00:01 |
| 7. INDEX SCAN FULL | I_VIEW1 | 65. 325. 1 (0) | 00:00:01 |
|* 8 | INDEX RANGE SCAN | I_OBJ1 | 1. | 1 (0) | 00:00:01 |
| 9. TABLE ACCESS BY INDEX ROWID | OBJ$ | 1. 46. 2 (0) | 00:00:01 |
| 10. INDEX SCAN FULL | I_USER2 | 131. 3144 | 1 (0) | 00:00:01 |
| 11. TABLE ACCESS FULL | USER$ | 131. 2358. 4 (0) | 00:00:01 |
| * 12 | TABLE ACCESS FULL | USER_EDITIONING$ | 1. 6. 2 (0) | 00:00:01 |
| 13. SEMI NESTED LOOPS. | 1. 29. 2 (0) | 00:00:01 |
| * 14 | INDEX SKIP SCAN | I_USER2 | 1. 20. 1 (0) | 00:00:01 |
| * 15 | INDEX RANGE SCAN | I_OBJ4 | 1. 9. 1 (0) | 00:00:01 |
| * 16. TABLE ACCESS FULL | USER_EDITIONING$ | 1. 6. 2 (0) | 00:00:01 |
-----------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
2 filter (((IS NULL AND "O". ("TYPE #" <>88) OR BITAND ("O". ("" FLAGS ", 1048576) = 1048576 OR
BITAND ("U". "" SPARE1»(, 16) = 0 OR (((SYS_CONTEXT ('userenv', 'current_edition_name') = ' ORA$ BASE ", AND)))"
"U"." TYPE #"(<>2) OR ('U'." ' TYPE # '= 2 AND 'U'. "SPARE2" = TO_NUMBER (SYS_CONTEXT ('userenv ',' current_e)) "
dition_id'))) or IS NOT NULL) AND IS NOT NULL)))
3 - access("O".") SPARE3 '=' U '. ("" USER # ")
4 - access("O".") "OWNER # '=' U '. ("" USER # ")
8 - access("O".") ' OBJ # '=' V '. (' ' OBJ # ")
12 filter (("TYPE #" =: B1 ET "UE".)) "THE USER #" =:B2))
14 - access("U2".") TYPE # "= 2, AND"U2"." SPARE2 "= TO_NUMBER (SYS_CONTEXT ('userenv ',' current_editi))"
on_id')))
filter (("U2". "TYPE #"= 2, AND "U2"."" SPARE2 "= TO_NUMBER (SYS_CONTEXT ('userenv ',' current_edit))"
ion_id')))
15 - access("O2".") DATAOBJ #"=: B1 AND 'O2'." ' TYPE # '= 88 AND 'O2'. "OWNER #"= "U2". ("" USER # ")
16 filter ((' EU'. "TYPE #" =: B1 AND 'EU '. "THE USER #" =:B2))
47 selected lines.
C##SA@pdborcl 10.09.2013 > select * from table (dbms_xplan.display_cursor ('bc4f1jh1snwdp'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID, bc4f1jh1snwdp, number of children 0
-------------------------------------
SELECT THE OWNER, DBA_VIEWS NOM_DE_VUE
Hash value of plan: 1508506130
--------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Pstart. Pstop |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100) | | |
| 1. PARTITION LIST ALL | | 10000 | 1289K | 0 (0) | 1. 2.
| 2. TABLE FIXED FULL | X$ COMVW$ 5885ef62 | 10000 | 1289K | 0 (0) | | |
--------------------------------------------------------------------------------------------
14 selected lines.
You have an idea about this result?
Thank you in advance,
Arnaud.
Arnaud,
This has a fairly simple explanation.
In 12cR1, there are common objects, and there are local objects. The definition of a common object is stored in the ROOT, and only a stub for the object is stored in the PDB. The definition of a local object is stored in the PDB.
When DBA_VIEWS is questioned in a PDB file, so we must return to lines of views both as common as the result of the query. If views Commons are not returned, then several views that a client is used to see in the result of a query DBA_VIEWS to 11.2 and earlier versions not will be seen in paragraph 12.1. For example, ALL_TABLES, DBA_OBJECTS, etc.
When DBA_VIEWS is questioned in a PDB file, then we extraction of lines for local opinions of PDB and common views of ROOT lines. The first has value ORIGIN_CON_ID equal to the ID of the container of the PDB to which you are connected, and they value ORIGIN_CON_ID equal to the ID of the ROOT container. Given that the recovery of these lines should be done in two different containers, we go through a fixed table X$ COMVW$ *.
The gap that you are experiencing is because this fixed table based assessment is used only to SELECT and not for etc. SELECT, INSERT AS SELECT, CREATE TABLE AS.
Let me know if that makes sense.
Thank you
Thomas
-
Shadows on shapes: unexpected results on the output of HTML5
Shadows are known for questions of course with out HTML5?
It seems that putting a drop shadow on a SmartShape with stroke and fill of 100% opacity, two shadows are producing; one for the filling and one for the race, in which the shadow of race comes actually on form rather than below (or somehow shines through. Can't if there is no line. Can't get on other objects; e.g. boxes to highlight.
Is it possible to change this behavior for HTML5 correspond to the Flash?
Edit Mode:

Flash power:

Output of HTML5:

Checked and it is a bug. You can submit a bug report to http://www.adobe.com/products/wishform.html
The only way I can see around him, would be to remove the feature, duplicate the object is directly above the old object, then set the fill to 0%, adding the race again and remove the shadow. It is not ideal, but if you need to use the drop shadow with an object that has a stroke, it's the only way I can see the output file as HTML5 without appearing inside the shape.
-
I have created a merge document and mail merge in word using an excel sheet spread as a data source. Initially, no sign of £ showed in the document among other formatting problems. I have (finally) found help explaining that I should use MS Excel via a DDE data sheets - I tried this but it seems to corrupt the data so that the column that contains say '1 names' contains "price data", "address" line contains the data of 'comments', making the e-mail merge nonsense.
If you use an alternative data source is CBO or something all NFL results (which wasn't shown on the worksheet) appear in the mail merge '0' both are unacceptable.
Surely I'm not the only person to meet these challenges is the software never tested before being sold where is the help manual, I tried to use the online help but will not accept my product key. All solutions provide the most basic assistance but my documents are fairly complex something computers should be good. I lost most of today on this. Sometimes I think it would be faster to type these longhand things than to use a Microsoft product.
Hello
Please check with the experts of the Office, Word and Excel here: (just repost your questions)
Answers - Excel Forums
http://answers.Microsoft.com/en-us/Office/ee861099.aspxAnswers - Word Forums
http://answers.Microsoft.com/en-us/Office/ee861096.aspxAnswers - Office Forums
http://answers.Microsoft.com/en-us/Office/default.aspxOr
Discussions in Excel worksheet functions
http://www.Microsoft.com/Office/Community/en-us/default.mspx?DG=Microsoft.public.Excel.worksheet.functions&lang=en&CR=usDiscussions in Word Application errors
http://www.Microsoft.com/Office/Community/en-us/default.mspx?DG=Microsoft.public.Word.application.errors&lang=en&CR=usDiscussions in Excel General questions
http://www.Microsoft.com/Office/Community/en-us/default.mspx?DG=Microsoft.public.Excel.misc&lang=en&CR=usMS Office discussion groups
http://www.Microsoft.com/Office/Community/en-us/FlyoutOverview.mspx
And here:Discussions in microsoft.public.excel.worksheet.functions
http://www.Microsoft.com/communities/newsgroups/list/en-us/default.aspx?DG=Microsoft.public.Excel.worksheet.functions&cat=en_us_b5bae73e-d79d-4720-8866-0da784ce979c&lang=en&CR=usDiscussions at the Microsoft.public.Excel
http://www.Microsoft.com/communities/newsgroups/list/en-us/default.aspx?DG=Microsoft.public.Excel&cat=en_us_a09d72a4-715e-4c37-bcd5-75e0fc616b1f&lang=en&CR=usMicrosoft.public.word.application.errors discussions
http://www.Microsoft.com/communities/newsgroups/list/en-us/default.aspx?DG=Microsoft.public.Word.application.errors&cat=en_us_f09268b3-8479-4cea-8037-d168d96833ac&lang=en&CR=usI hope this helps.
Rob - bicycle - Mark Twain said it is good. -
After the merger of 7 shots in panorama he tooks nearly 5-6 minutes to get the final result and this result have only something above 1000 pixels edge long photo resolution? Why is this happening? I've been fusion 7 24Mpix of Nikon D750 RAW files. I saw a promo video where he introduced and there the panorama was above 10 000 pixel wide, so it is not a limit of lightroom, but something is not. Maybe some strange décor? Thank you.
Well, the good news is... This isn't your files.
I produced a pano 17310 x 6039 in less than 3 minutes. With or without adjustment.
The only differences that we have so far is the platform. Mac/Pc
Wrong guess you managed to repeat the question. Maybe a reinstall?
I hope that someone else (on PC) may be able to provide alternative suggestions. Let us know if you yourself are able to find a solution.
-
Unexpected behavior with the Option "record in the result.
Hello
I have unexpected behavior with the Option "record in the result.
I have a few steps in the subsequence 'X', this subsequence passes a Boolean parameter. According to the value of the parameter I change the "Recorgind results" Option to report it or not. The thing is that if 'result Recorgind' set at race time I modofy by changing the value of Step.ResultRecordingOption to "Enable" and "Disable", the step is not reported until the same sous-suite 'X' is called for the second time (without changing the parameter passed).
For example: (Preconditon: result Recorgind Option of all value sous-suite x are defined as Disable)
1 CallSubsequenceX(Parameter: Enable)
2 CallSubsequenceX(Parameter: Enable)
3 CallSubsequenceX(Parameter: Disable)
4 CallSubsequenceX(Parameter: Disable)
Expected result:
1. measures have been reported.
2. measures have been reported.
3. measures have not been reported.
4. measures have not been reported.
Result:
1. measures would not same value Step.ResultRecordingOption has been changed to 'enable '. (Not Ok)
2. measures have been reported. (Ok)
3. measures reported same value Step.ResultRecordingOption has been changed to 'disable '. (Not Ok)
4. measures have not been reported. (Ok)
I use TestStand 2013 (5.1.0.226)
Thanks in advance.
-Josymar.
Hi josymar_guzman,
I just review the sequence and indeed we´re experience unexpected behavior with the Step.ResultRecordingOption callback. By a reason when you run the callback in the expression before each step section, the statement runs only until the next sequence is called, which is not what we want.
To avoid this, you can place a statement before each step of the sequence, so you can change the State of the Option "record result" for the sequence running (and it is only the following). You can try something like this
where the expression of the statement will be the recall "RunState.NextStep.ResultRecordingOption is YourCondition". With this, we guarantee that the results of the next step will be saved or not. I also remove the expression in the expression prior to each step section, because the condition is now on the statement before each step.
I tried and it works fine. I´ll set the sequence that you share with me, with the changes. I hope this will help you and solve your problem.
-
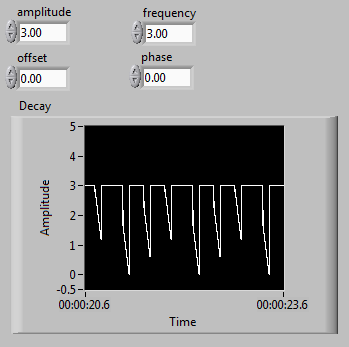
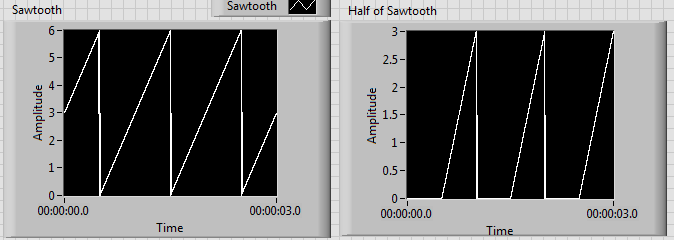
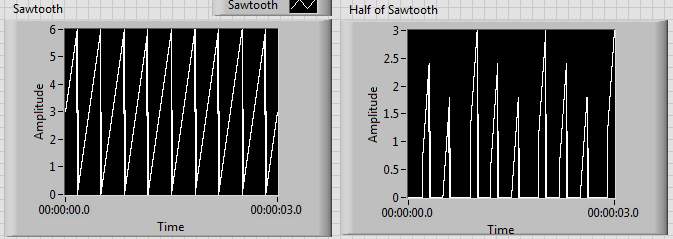
Results of increasing frequency generated unexpected behavior of the signal
I'm generating a composite using a sawtooth wave, square, signal that produces the desired signal as shown on the left. Unfortunately, when the increase of the frequency beyond 1 Hz, I get undesirable results as shown on the right.
I tried to edit the news of sampling with no luck. I have also tried different methods to produce the desired signal. I noticed that before one of partial components of the final signal enters a relay, the increase of the frequency doesn't create unexpected results. Although, after its passage through a relay, the error starts happening. It seems that the relay is not suitable for higher frequencies, but I can't fix this unexpected behavior.
Frequency of 1 Hz:
Frequency of 3 Hz:
Another method that I tried was to use the "simulate arbitrary signals," even if I was unable to find a way to increase the frequency of the signal that results.
In addition, the signal has this grainy nature that I would like to make it smooth and continuous. Is this possible? I would like finally to reach a frequency of a few kiloHertz.
I have attached the VI.
Any help would be greatly appreciated. Thank you.
The problem has to do with the size of the block and when the relay actually sees the saw tooth cross the threshold.
Solve it, to perform a point-by-point check and build our waveform personalized to each iteration.
-
When using the merge and when to use updated
Hi friends,
Given the best performance... purpose of this discussion is when we should use statement UPDATE and when we should use MERGE statement in oracle update of thousands of records.
Kindly Guide.
Kind regards
Himanshu
Hello
Looking for a couple to a few rules that you can use to decide whether to use the MERGE or UPDATE, without actually testing two meanings?
If so, use MERGE when
(1) (sometimes) need to add new lines
(2) it is simpler. This includes special cases
(2A) an UPDATE statement uses a subquery in the SET clause and then (mostly) repeats the same subquery in the WHERE clause
(2B) you want to use the analytical functions or CONNECT BY in a subquery
These rules are NOT guaranteed to work in all situations.
Kimmy says:
Hello
... My requirement is only UPDATED records about 200 to 500K (NOT followed by update of insertion).
So the rule (1) above does not apply in this case.
What I observed in the update using a MERGE statement and UPDATE is:
Update with the MERGER was faster however explain the bytes consumed to the query plan MERGE has been compared more update.
Use the tool that works best for your needs. If users are complaining that something shows more bytes used in a plan to explain, so maybe it's a reason for the UPDATE.
Where I work, where is the fastest is usually more important.
In addition, I want to get clearity
1. "if I should use MERGE if I need to update recrods using the unique table" as shown below: OR update will be good to use in this case:
MERGE INTO MKT_DATA inmkt
C using (SELECT Customer_Code, region, State OF CUSTOMER_DATA)
ON (inmkt. Distributor_Code = c.Customer_Code AND inmkt. DISTRIBUTOR_CODE IS NOT NULL)
WHEN MATCHED THEN
Updated the inmkt VALUE. Distributor_Region = c.Region,
inmkt. C.State = Distributor_Province;
UPDATE MKT_DATA inmkt
SET (inmkt. Distributor_Region, inmkt. Distributor_Province) =
(SELECT c.Region, c.State OF CUSTOMER_DATA c
WHERE c.Customer_Code = inmkt. Distributor_Code)
WHERE inmkt. DISTRIBUTOR_CODE IS NOT NULL;
2 statements above are not equivalent.
The UPDATE statement changes all the lines in the table mkt_data that have a distributor_code, this distributor_code be in the table customer_data or not.
You want something that is equivalent to the MERGE statement, you can use:
UPDATE MKT_DATA inmkt
SET (inmkt. Distributor_Region, inmkt. Distributor_Province) =
(SELECT c.Region, c.State
OF CUSTOMER_DATA c
WHERE c.Customer_Code = inmkt. Distributor_Code
)
WHERE THERE ARE
(SELECT 1
CUSTOMER_DATA C2
WHERE the c2. Customer_Code = inmkt. Distributor_Code
)
;
It basically uses the same auxiliary request 2 times (article 2 (a), so I would use MERGE if these are the results I wanted.
If you have a foreign key constraint, which ensures that each distributor_code in mkt_data will match a line in customer_data, then the 2 statements above will produce the same results. In this case, I find the UPDATE statement simpler and probably use it rather than MERGE.
2. to Updating huge amount of records MERGER must be used instead of update?
I don't know of all short reign as the "use X whenever you have more than 100,000 lines".
3. If in the update, I need to use several tables then I have to use MERGE?
MERGE IN MKT_DATA2 t
WITH THE HELP OF)
SELECT DISTINCT srt. Sales_Id, tmkt. Cust_Code, srt. PRODUCT_CENTER
OF srt, CUSTOMER_DATA c, MKT_DATA2 tmkt SALESTERR_PL
WHERE tmkt.state_Id = 10423
AND tmkt. Business = 'MARKETING'
AND c.CUST_CODE = tmkt. Cust_Code
AND c.Rollup_Code = srt. CUST_CODE
AND srt. PRODUCT_CENTER = tmkt.PL
) d
WE (t.state_Id = 10423
AND t.BA = 'MARKETING'
AND t.Cust_Code = d.Cust_Code
AND t.PL = d.PRODUCT_CENTER
AND t.Cust_Code IS NOT NULL
)
WHEN MATCHED THEN
UPDATE SET t.Sales_Id = d.Sales_Id;
UPDATE MKT_DATA2 tmkt
SET Sales_Id = (SELECT SALES_ID OF SALESTERR_PL srt
WHERE the srt. CUST_CODE = (SELECT ROLLUP_CODE FROM CUSTOMER_DATA c
WHERE c.CUSTOMER_CODE = tmkt. Cust_Code)
AND srt. PRODUCT_CENTER = tmkt.PL)
WHERE business = 'MARKETING'
AND state_Id = 10423;
Once again, those who are not equivalent. The UPDATE statement can change more lines than the MERGE statement.
In addition, you can use the MERGE statement:
MERGE IN MKT_DATA2 t
WITH THE HELP OF)
SELECT DISTINCT srt. Sales_Id, tmkt. Cust_Code, srt. PRODUCT_CENTER
OF srt, CUSTOMER_DATA c, MKT_DATA2 tmkt SALESTERR_PL
WHERE tmkt.state_Id = 10423
AND tmkt. Business = 'MARKETING'
AND c.CUST_CODE = tmkt. Cust_Code
AND c.Rollup_Code = srt. CUST_CODE
AND srt. PRODUCT_CENTER = tmkt.PL
) d
WE (t.Cust_Code = d.Cust_Code
AND t.PL = d.PRODUCT_CENTER
)
WHEN MATCHED THEN
UPDATE SET t.Sales_Id = d.Sales_Id
WHERE t.state_Id = 10423
AND t.BA = 'MARKETING'
- AND t.Cust_Code IS NOT NULL - does not need, said subquery 'c.CUST_CODE = tmkt. Cust_Code ".
;
If you would care to publish the sample data, I was able to test this.
4. when the UPDATE is preferred over the MERGER?
In simple cases, including situations where all you need to know are on the line itself, such as:
UPDATE emp
SET sal = sal * 1.05
Job WHERE NOT IN ('MANAGER', 'PRÉSIDENT')
;
-
RoboHelp 11 search results differ from the merger of projects
Hello
Please bear with me as I am a new user to Robohelp, I have looked around and have been unable to find an existing thread on the subject I see.
I have a project (lets call this project A) in 2 forms.
(1) all first as a stand-alone project (project A).
In this format the search feature seems to work correctly, outside to drop the 'e' in search of the only word ending with 'e' (I found a small amount of information on it, but not a solution).
(2) the second form is that of a merged project (project B). Its configured in the form:
Project B TOC:
Introduction
Book
Project A (merged)
In this second format if I search for a term with an 'e' suffix the number of results is lower.
I managed to establish the difference between the 2 research.
Example:
Search on the word: "merge".
(1) 8 results
(2) 5 results
5 results that return in the two are where the substring "Merg" (the 'e' lack) is part of a word in these topics, 3 lost results are those who have "Merge" as a stand-alone Word.
Scenario 2 seems to be looking for 'Merg %' and excluding "merge".
If anyone can suggest a solution, or if you need further explanation, please let me know.
Thank you
David
The presentation of single Source has an option to allow the search of substrings, which seems to match your option (1). Do you use SSL even to create the output? What is the setting for the substring search in project the master and child?
You can find the option in the search of the WebHelp SSL settings tab.
-
Hi people,
This year was difficult because it does not clearly justify what I want to achieve. The main reason for me to try this approach is to reduce the time of the performance. I have my program works very well, but since it accesses a view for each student, slows down the performance.
Purpose of this report: Show all Dates of examination for students, but only to display the results pre and review of the overall assessment on the first line for students.
Table scripts and INSERT statements:
Desired output:create table STUDENT_TB(student_id varchar2(4), last_name varchar2(20), first_name varchar2(20), evaluation_date date); create table EXAM_TB(student_id varchar2(4), exam_date date, result number); create table EVALUATION_TB(student_id varchar2(4), eval_flag varchar2(1), sampling_date date); insert into STUDENT_TB values('1001', 'Poppins', 'Mary', to_date('27-SEP-2012', 'DD-MON-YYYY')); insert into EXAM_TB values('1001', to_date('20-APR-2011', 'DD-MON-YYYY'), 30); insert into EXAM_TB values('1001', to_date('20-MAY-2012', 'DD-MON-YYYY'), 39); insert into EXAM_TB values('1001', to_date('10-JUL-2012', 'DD-MON-YYYY'), 34); insert into EXAM_TB values('1001', to_date('10-SEP-2012', 'DD-MON-YYYY'), 39); insert into EXAM_TB values('1001', to_date('01-DEC-2012', 'DD-MON-YYYY'), 82); insert into evaluation_tb values('1001', null, to_date('22-APR-2011', 'DD-MON-YYYY')); insert into evaluation_tb values('1001', 'N', to_date('20-JUL-2012', 'DD-MON-YYYY')); insert into EVALUATION_TB values('1001', 'Y', to_date('10-DEC-2012', 'DD-MON-YYYY'));
Business rules:SID Last Name First Name Evaluation Date Exam Date Results Order Pre Evaluation Overall Evaluation Accept? =============================================================================================================================== 1001 Poppins Mary 27-SEP-12 20-APR-11 30 1 N Y Y 1001 Poppins Mary 27-SEP-12 20-MAY-12 39 2 1001 Poppins Mary 27-SEP-12 10-JUL-12 34 3 1001 Poppins Mary 27-SEP-12 10-SEP-12 39 4 1001 Poppins Mary 27-SEP-12 01-DEC-12 82 5
The Pre, global assessment and accept it? fields are derived. The area of the pre assessment is derived from the EVALUATION_TBtable. Its the value of eval_flag where sampling_date < = evaluation_date.
In our example, the pre assessment should be an "n" while the overall assessment must be a 'Y '. The priority is Y-> N-> Null. The Accept flag is set to a 'Y' If a meadow at overall results past of N to Y or a NULL of Y value.
I have to return all the lines for the student that show the results of the reviews SQL is the following:
I need to join the view EVALUATION_TB. Simply join them of course would be a resulting vector product in 15 files that I don't want. I tried online (subqueries) but I failed again. Any help would be great!
I created the column ord_num to maybe help using only this folder to display the results of the assessment.
Thank you!select x.student_id, x.last_name, x.first_name, x.evaluation_date, m.exam_date, m.result, dense_rank() over (partition by x.student_id order by m.exam_date) ord_num from ( select s.student_id, s.last_name, s.first_name, s.evaluation_date from student_tb s ) x, exam_tb m where x.student_id = m.student_id (+); SID Last Name First Name Evaluation Date Exam Date Results Order =============================================================================== 1001 Poppins Mary 27-SEP-12 20-APR-11 30 1 1001 Poppins Mary 27-SEP-12 20-MAY-12 39 2 1001 Poppins Mary 27-SEP-12 10-JUL-12 34 3 1001 Poppins Mary 27-SEP-12 10-SEP-12 39 4 1001 Poppins Mary 27-SEP-12 01-DEC-12 82 5
Published by: Roxyrollers on March 14, 2013 11:37
Published by: Roxyrollers on March 14, 2013 11:38
Published by: Roxyrollers on March 14, 2013 12:27
Published by: Roxyrollers on March 15, 2013 13:43Hi Roxyrollers,
Please check your insert statements before posting. They have syntax errors.
The following query is to give you the desired result:
with pre_eval as ( select e.student_id , max(e.eval_flag) keep(dense_rank last order by e.sampling_date) eval_flag from evaluation_tb e join student_tb s on e.student_id=s.student_id and e.sampling_date <= s.evaluation_date group by e.student_id ) ,all_eval as ( select e.student_id , max(e.eval_flag) keep(dense_rank last order by e.sampling_date) eval_flag from evaluation_tb e join student_tb s on e.student_id=s.student_id group by e.student_id ) , data_with_rank AS ( select s.student_id, s.last_name, s.first_name, s.evaluation_date , m.exam_date, m.result , dense_rank() over (partition by s.student_id order by m.exam_date) ord_num from student_tb s left outer join exam_tb m on (s.student_id = m.student_id) ) select s.student_id, s.last_name, s.first_name, s.evaluation_date , s.exam_date, s.result , e.eval_flag as pre_eval , a.eval_flag as overall_eval , case when a.eval_flag='Y' and e.eval_flag!='Y' then 'Y' end accept from data_with_rank s left outer join pre_eval e on (s.student_id = e.student_id and s.ord_num=1) left outer join all_eval a on (s.student_id = a.student_id and s.ord_num=1) order by s.student_id, s.exam_date; STUDENT_ID LAST_NAME FIRST_NAME EVALUATION_DATE EXAM_DATE RESULT PRE_EVAL OVERALL_EVAL ACCEPT ---------- -------------------- -------------------- --------------- --------- ---------- -------- ------------ ------ 1001 Poppins Mary 27-SEP-12 20-APR-11 30 N Y Y 1001 Poppins Mary 27-SEP-12 20-MAY-12 39 1001 Poppins Mary 27-SEP-12 10-JUL-12 34 1001 Poppins Mary 27-SEP-12 10-SEP-12 39 1001 Poppins Mary 27-SEP-12 01-DEC-12 82However, is not clear to me why the assessment are related only to the first line in the query.
The evaluation_tb table is in fact related to student_id and I expect to be connected all lines.I've actually linked subqueries pre_eval and all_eval only in line with rank = 1 but I don't understand if that's correct according to business requirements.
Kind regards.
AlPublished by: Alberto Faenza on 14 March 2013 20:29
ORDER BY added, deleted ord_num output -
Fill a table with the results of the refresh groups
Hello world
I need a little help.
I'm working on an Oracle 10.2.0.4 on windows.
I have a table I created like this:
Table name: DIM_REPLICA
COD_SEZ VCHAR2 (2)
NOME_SEZ VCHAR2 (20)
FLAG TANK (1)
DATE OF D_REPLICA
This DB I have 210 discount groups running every night. I need fill this table with the results of the refresh groups.
So when the refresh for example called ROME group runs I need to write on the table the name ROME in the field "NOME_SEZ", a Y or N if the refresh Group has worked in the field of the INDICATOR and LAST_DATE refresh force ran into the field of the D_REPLICA. The COD_SEZ field is a code that I get other things. It is not necessary for the moment. I can add it myself on my own.
Can someone help me please?
I was looking on the tables SYS DBA_JOBS and DBA_REFRESH these data, but I don't know what to take and how to fill the table. Trigger? Procedure? Any help will be great!
Thank you all in advance!This forum is for SQL * PLus, questions and your question is about general issues Oracle. You will get a better response by posting your question in another forum - probably the General database instance.
Please close this thread and start over in another forum.
-
We are seeing different results for the property of the HostSystem 'configManager. snmpSystem' from vCenter and when you access from host.
I think that the result should be no different. Is this another known issue or am I missing something here?
To confirm this behavior, we tried to show the property to the host through the Explorer managed objects (MOB) and also by the VMware Remote CLI scripts. Join the results of the CLI script that was running on our test systems.
Best regards
Damodar
Greetings, I just wanted you guys to know this problem that you are experiencing is a known problem with VMware and our engineers groups are working on it. Sorry for the inconvenience to you.
-
Group by in the result of the xsl as excel template
Hi all
We strive to implement the map of multi great value shown in the blog of Tim with slight variations and was unsuccessful so far...
http://blogs.Oracle.com/XmlPublisher/2010/03/multisheet_excel_output.html
My report has 2 leaves in the first sheet, I use for each, and we get the expected results.
In the second worksheet that I try to use for each group and the report fails. In the log file, I have the following description
Any help is appreciated<Line 23, Column 63>: XML-22029: (Warning) Cannot transform child 'xsl:for-each-group' in 'Worksheet'. <Line 23, Column 63>: XML-22047: (Error) Invalid instantiation of 'xsl:for-each-group' in 'Worksheet' context. Here is a snippet of my xsl.. <xsl:template match="ROWSET"> <Worksheet ss:Name="Dept"> <xsl:for-each-group select=".//ROW" group-by="./DEPTNO"> <Table x:FullColumns="1" x:FullRows="1"> <Row> <Cell ss:StyleID="x1"> <Data ss:Type="String"> <xsl:value-of select="DEPTNO"/> </Data> </Cell> </Row> </Table> </xsl:for-each-group> </Worksheet> </xsl:template>
Thank you
Published by: user10280715 on March 20, 2010 09:40I have designed a model using Excel and then convert it in XSL using XLS PE. This works.
imalyshev imalyshev 2010-03-22T16:48:23Z Grau Development 11.5606 10620 17100 120 120 False False 9 600 600 False False -
Need help in the optimization of the query with the Group and joins by clause
I'm having the problem by running the following query... It takes a lot of time. To simplify, I added the two tables FILE_STATUS = stores the file load details and COMM table Board table job showing records treated successfully and which was communicated to the other system real. Records with status = T is trasnmitted to another system and traansactions with P is waiting.
Here's the query I wrote to give me the details of the file that has been loaded into the system. He reads the table of State and the commission files to display the name of the file, total records loaded, total at the table of the commission and the number of records which has finally been passed successfully loaded (Status = T) with other systems.CREATE TABLE FILE_STATUS (FILE_ID VARCHAR2(14), FILE_NAME VARCHAR2(20), CARR_CD VARCHAR2(5), TOT_REC NUMBER, TOT_SUCC NUMBER); CREATE TABLE COMM (SRC_FILE_ID VARCHAR2(14), REC_ID NUMBER, STATUS CHAR(1)); INSERT INTO FILE_STATUS VALUES ('12345678', 'CM_LIBM.TXT', 'LIBM', 5, 4); INSERT INTO FILE_STATUS VALUES ('12345679', 'CM_HIPNT.TXT', 'HIPNT', 4, 0); INSERT INTO COMM VALUES ('12345678', 1, 'T'); INSERT INTO COMM VALUES ('12345678', 3, 'T'); INSERT INTO COMM VALUES ('12345678', 4, 'P'); INSERT INTO COMM VALUES ('12345678', 5, 'P'); COMMIT;
In production, this request has several joins and takes a long time to deal with... the main culprit for me is the join on the COMM table to count the number of number of transactions sent. Please can you give me tips to optimize this query to get results faster? What I need to delete the Group and use the partition or something else. Help, please!SELECT FS.CARR_CD ,FS.FILE_NAME ,FS.FILE_ID ,FS.TOT_REC ,FS.TOT_SUCC ,NVL(C.TOT_TRANS, 0) TOT_TRANS FROM FILE_STATUS FS LEFT JOIN ( SELECT SRC_FILE_ID, COUNT(*) TOT_TRANS FROM COMM WHERE STATUS = 'T' GROUP BY SRC_FILE_ID ) C ON C.SRC_FILE_ID = FS.FILE_ID WHERE FILE_ID = '12345678';Don't know if it will be faster based on the information provided, but analytical functions offer an alternative approach;
select carr_cd, file_name, file_id, tot_rec, tot_succ, tot_trans from (select fs.carr_cd, fs.file_name, fs.file_id, fs.tot_rec, fs.tot_succ, count(case when c.status = 'T' then 1 else null end) over(partition by c.src_file_id) tot_trans, row_number() over(partition by c.src_file_id order by null) rn from file_status fs left join comm c on c.src_file_id = fs.file_id where file_id = '12345678') where rn = 1; CARR_CD FILE_NAME FILE_ID TOT_REC TOT_SUCC TOT_TRANS ------- -------------------- -------------- ---------- ---------- ---------- LIBM CM_LIBM.TXT 12345678 5 4 2 -
Select the table column group and generate a sequence number
I have to select data from a table column group and generate a sequence for every reset of the sequence from 1 to leave.
For example:
Data:
Col1 Col2 Col3 Col4
A NA KA-2009-08-13
B NA KA-2009-08-13
C NA KA-2009-08-13
A NA KA-2009-08-13
B NA KA-2009-08-13
A NA KA-2009-08-13
Expected results of the Select statement:
Col1 Col2 Col3 Col4 Seq_No
A NA KA-2009-08-13 1
A NA KA-2009-08-13 2
A NA KA-2009-08-13 3
B NA KA-2009-08-13 1
B NA KA-2009-08-13 2
C NA KA-2009-08-13 1
How can it be possible with a SELECT statement? Is it possible to assign the following numbers for a group of columns and put it back when it changes? In the above example, all columns are the key to generate the seq number
I know that this can be done using procedures stored and that is how I do it now by introducing a temporary table.
Can someone help me with this? Please let me know if the question is too vague to understand!
Thank you
NachiUse the row_number() analytics.
Ravi Kumar





Maybe you are looking for
-
Tecra M3: How can I reset or bypass a BIOS password unknown
My brother is died last year and left a Toshiba Tecra M3, protected by a Bios password. How or where I can cancel this password.I have good computer background of it proved to be a challenge please help.
-
AMD A8: utube videos have no photo
I sought an answer and everything what I find is answers on "a video but no sound. I have the opposite. When I play a UTube video all I get is a green screen and can hear the sound very well. Any help for this problem?
-
Satellite P50-B-110 - overheating while playing or watching the video
* Satellite P50-B-110 *. * Card: *.-8.1 Windows 64-bit.-SSD 256-16 GB OF RAM-Intel i7-4710HQ 2.5 GHz Overheating problems when I watch videos on youtube and in particular when playing GT Racing 2 - Gameloft.When I look at Youtube videos that he will
-
Problems with Windows Update after uninstalling SP2 (Vista Home Premium)
Hello, everyone! Two days ago, I tried to install SP2 through my Windows Update. During the installation and then restart, it stopped on step 3 (0%), ignored and open Windows normally. But, I realized that I had totally lost Aero (I didn't even have
-
I can not install updates on my HP laptop, more
Vista Ultimate / when I automatic Microsoft updates page it says I must be logged on as administrator. Problem is that I am the administrator. There are no other accounts of users but mine. I wonder if I had a virus or something. I went to fix it fro