Unicode or non-unicode
Hello
any request or the way to know whether or not an installation of the peoplesoft system is Unicode unicode?
Thank you.
You can query PSSTATUS
Select ownerid, decode (UNICODE_ENABLED, 1, "Unicode", "Non - Unicode") PSSTATUS UNICODE_ENABLED;
Tags: Oracle Applications
Similar Questions
-
Problems related to the evolution of the language of non-Unicode programs
Hello world!
Product name: HP Pavilion dv6-6093ex
Product number : LM610EA #A2N.
My 7(464Bit) Windows Ultimate and its base language, and the language is English.
The built-in languages (English, French and Arabic) (re-uploaded and re-installed came by the person making the installation of Windows disk). So, during the installation of Windows 7, these three language listed for me to choose one of them to be the base language and display the language, I choose 'English'. At the end of the installation, there are pre-packaged trilingual (French, English and Arabic) can be used as a display language.
I wish a good want to confirm for me why I was confronted with these problems when changing the language for non-Unicode from English to Arabic programs.
First: After I installed the AMD graphics driver high definition (sp55092) 8.882.2.3000 on my laptop. The content of the of Intel Graphics and Media Control Panel are partially shown in Arabic while the language of the non-Unicode programs is Arab, however, they appear completely in English and the language of the non-Unicode programs is English.
A: I found that content from the Intel Graphics and Media Control Panel are displayed partially in Arabic second screenshot below, however, when click on options, for example "graphic properties" in Arabic, the second window appears in English) while the language of the non-Unicode programs is Arabic, and it doesn't matter what format or location is.
B - when I changed the language for non-Unicode programs in English.
I found that content from the Intel graphics card and the media control panel is completely displayed in English.Second:
Has- single Arab all content will be posted encryptely while the language of the non-Unicode programs is English
B- all Arab content displayed correctly in language for programs no Unicode is Arabic.
Third: an error extraction of the drivers and the software downloaded from the official website of HP while the language of the non-Unicode programs is English.
A- I noticed an error extracting all kinds of compound files (drivers and software) downloaded from the HP Web site, while the language of the non-Unicode programs is English and some location and format are:
B- While the language of the non-Unicode programs is Arabic, however there is no mistake in the extraction of files.
In conclusion, is it normal for you all the content of the of Intel Graphics and Media Control Panel partially appear in your native language for non-Unicode programs is your native lanague, however, they appear completely in English and the language of the non-Unicode programs is English?. IF so I would say that if I wanted the content of the documents in my Arabic language to be displayed correctly, and then I need the language for non-Unicode programs be Arabic. Is what is happening with you so?
Also, if I need to extract all kinds of compound files (drivers and software) downloaded from the HP website, then language for non-Unicode programs needs to be in my English Arab lanague and some location and format are. Is what happened with you so?
I'd appreciate strongly any clarification on your part.Cooperator salvation,
I saw your post about language issues, and I'll be happy to help you. What you are experience with languages is normal. The base operating system is in English, and while you can change the display language at the heart of the core of the operating system would be in English.
The reason why the Intel graphics and Media Control Panel is in English and the rest in Arabic because the driver would have been designed in English and is coded in the driver, but the display language is set to Arabic hard. Thus, when the language is set to English everything will be in English.
You have issues pilots extraction when you attached to the language English is because the HP site will determine where in the world you and when you download the driver it will be the language appropriate to the country, you are. So when he extracted it will look appropriate with the help of Arabic extraction path but everything is in English. It worked without problem when you're in Arabic because the driver can read the path correctly.
Thank you
-
Several languages non-Unicode without reboot?
I recently got a new captioning program to add subtitles (Arabic, English and Japanese) at my youtube videos. The problem is that I can't get the program read more 1 language non-unicode both... so I thought I should create a new account for my laptop. I tried to create a new user for English & Arabic account and keep the default English & Spanish profile, but it does not work. It changes everything, but everything I have on a profile automatically changing the same thing on the other profile. It's very frustrating because I always have to restart my laptop. Is it possible to have multiple accounts with a different default language for each of them?
Hello princeleo,
In addition to super486 comment, I've included a link below that will help you during the implementation of different languages for different users. Please let us know status.
Configure Windows XP for multiple languages:
http://Windows.Microsoft.com/en-us/Windows-XP/help/setup/set-up-multiple-languages-Windows-XP
With Windows XP, you can configure several languages and then switch between them with just two mouse clicks. If your computer is used in a multilingual household, you can configure each user account with a different language.
Thank you
-
Language of the Win7 professional to support the non-Unicode programs?
Hi all
Do you know if the Windows 7 language support for non-Unicode programs? I mean, if you use a Japanese or Chinese under English environment in Windows 7, the text appears correctly?
Thank you
RoseattleHello Roseattle,
Thank you for visiting the website of Microsoft Windows Vista Community. The question you have posted is a problem installing Windows 7 positions and would be better suited to the TechNet community. Please visit the link below to find a community that will provide the support you want.
http://social.technet.Microsoft.com/forums/en/category/w7itpro?ITPID=sprblog
Thank you
Jack
Jack
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think. -
Replacement Non Unicode glyphs?
Hello
I inserted a few glyphs before assigning their Unicode values in my policy, now that I've given all these glyphs their correct Unicode files, however, when trying to replace those that have been inserted before the change, the ' ^ + "mark indicates in the dialog instead of the glyph itself and InDesign still consider them Non-Unicode when inserted.
What should do? (ID v9.1ME)
Thank you.

I don't know what ' ^ + ' means, but I can see it if I copy a character that has no Unicode ID text value in the find/replace text tab. If I copy tab GREP-I get the corresponding ' ~ + ', which I cannot find in the wonderful Peter Kahrel GREP in InDesign. However, at least as far IDCS4 ID offered find/replace glyphs, which works differently. If a select a character that I know has only a GlyphID and Unicode value (say, 11615 Kozuka Gothic Pro), which is highlighted in the glyphs Panel. Hover it shows 4 dashes, confirming the absence of a Unicode value. right click offers of "load glyph in find" (or change, in fact) and evokes the glyph tab in find/replace.
Or you can choose the glyph in find/replace tab, fill the family and style to your policy, and then change the ID: field to display the GID/CID. You may be able to get the ID no. you need an older version of the police. Or if you left the old glyph not coded in the installed version of the police, you can click on the triangle pointing to the right after "glyph:" and scroll down to find it.
Good luck!
David
-
Hi gurus,
I created an application of planning with the Non-unicode Essbase database.
I want chenge it in Unicode.
Is it possible?
where in essbase application frome Edit Properties > unicode option is disabled.
However I tried with chengeing the data source connection to Unicode mode essbase and redeploy (full deployment) it. Still, it does not show unicode in Essbase.
Anyway if it will be possible, it will be useful.1. connect to the Regional service console
2. right click on your Essbase Server > Edit > properties > Security tab
3 confirm that "Permission to create the application in Unicode mode" check box is enabled
4. always in environmental assessments, do a right-click on the planning application in the list of applications > edit properties
5. on the general tab, check the box to 'mode' Unicode
6. click on 'apply '. You are warned that this change is irreversible.
7. change the data source for your Planning application
8. check the 'Unicode mode' (and re - enter the password). Click on "Finish".
9. connect to your planning application and perform a refreshReference: Convert a Unicode mode Application planning in Essbase (Doc ID 962432.1) MOS.
HTH-
Jasmine. -
Language for non-unicode programs.
I write the text of my Greek characters in the application.
The Greek characters are displayed correctly if open with notepad text in any pc.
I have problem with 2 PCs, where the Greek characters are replaced with question marks.
All PCs these 2 with the problem have win xp sp3 and the language for programs no unicode set in Greek.
Hello dimitrisalexandratos,
Since you are in a domain environment, you should post your question in the forum TechNet this forum is primarily for consumers of personal information.
I have included the link here for you.
http://social.technet.Microsoft.com/forums/en-us/w7itprogeneral/threadsThank you
Marilyn
-
SQL Server 2005 Management Studio Query Export to CSV to the Non Unicode Format
In SQL Server 2005 Management Studio, click the part of the results of a query. Click on "save results under...". ", select CSV and an output file.
The output is in unicode format. How can I fix this in ASCII?
Jim Oliver
Hi Jim,.
Your question of Windows is more complex than what is generally answered in the Microsoft Answers forums. It is better suited for the public on the TechNet site. Please post your question in the forum.
Link:http://social.technet.microsoft.com/Forums/en-US/category/sqlserver/
With regard to:
Samhrutha G S - Microsoft technical support.
Visit our Microsoft answers feedback Forum and let us know what you think.
-
How to display the non supported unicode for the title of the window
I'm developing an application using Java swing. In my application, I want to display Myanmar fonts (Unicode) for the title of the window. But windows 7 doesn't support Myanmar police. So, I would like to know is possible to change the font of the title bar? (Windows 8 supports unicode Myanmar and may display correctly).
I already tried to "change the window colors and measures" and changing the locale also.
And my OS is the Japanese version.
Thanks in advance.
Hello
Please contact Microsoft Community.
According to the description, I understand that you are developing an application that uses Java swing and you want to display Myanmar fonts (Unicode) for the title of Windows. And now, you need to know is possible to change the font of the title bar on the system?
Certainly, I understand your concern and will try my best to help you.
In order to get more information about this, I suggest you to post your query on the forum of the MSDN Community for that matter. You can get more effective suggestions and adapted by experts familiar with this topic.
Please visit the link below for the best support.
I hope this information is useful.
Please let us know if you need more help, we will be happy to help you.
Thank you.
-
HowTo: get chess unicode to display correctly: 2659 UTF
What should I do to get the unicode of chess characters display correctly.
This page: http://www.fileformat.info/info/unicode/char/2659/browsertest.htm
show me the unicode values in small boxes.
None of the fonts of the "local fonts list" show the character correctly.You can use a Google search to find Web sites with a specific font.
Select the table of characters - various symbols (191) to look at the symbols of chess
-
Unicode character on the command line
I have a folder that contains a non-ASCII character, "registered sign" (®), which can be typed in a Terminal by using the-r option.
It is U + 00AE, and as an 8-bit character, it is 174 decimal. I want to be able to enter this character on the command line without
typing Option, because I have to build a Terminal command using an application that
is not respectful of Unicode. So option-r helps me create a string that contains this character.
For example, in the Terminal, I made a folder in ~ with
as its name in full (I typed a r while pressing the option key): > mkdir ~ /.
I can list help
> ls ~ /.
but I have to be able to do so * without using any modifier key * (as option).
I thought I could use something like (after cd ~)
> ls \302\256
or
> ls \u00AE
or
> ls \xc2\xae
but I could not do the shell to interpret what I type as registered r symbol. Everything what I enter is interpreted
literally as individual characters rather that, for example, the \xC2 is considered a single character. I also tried different combinations
quotes as double the backslash, but I continue get "No such file or directory".
How can I represent this character on the command line without modifier keys? I'm on El Capitan, OS X 10.11.2, running bash 3.2.
Have you tried zsh instead of bash?
I think bash supports \u starting only 4.2
-
Question about support for LabVIEW DLLS and Unicode
Hello
I have a question about LabVIEW and DLL functions calls.
I use a DLL (sorry, I can't share it) that was written in C. It was written to support Unicode and non-Unicode function calls.
The Unicode function is valid, then FunctionNameW is called if FunctionNameA is called.
I am building a few VI to access the library. I have the regular functions of FunctionNameA work.
My question is, does LabVIEW support versions of function FunctionNameW Unicode, and if so is it necessary Although LabVIEW is already working with the standard function call?
Am I being redundant or what should I build in Unicode support?
The first time I tried to test the Unicode functions, I had an error, and I guess this is a system setting.
Thank you for your time in advance.
DB_IQ wrote:
I don't think I have TO implement the Unicode, but I want if I can.
For what I do, I think almost it is not serious. But I wanted to know if it could be used.
The short answer is "Yes, you can do it." However, it may open a new Pandora's box. If you're not careful, problems and complications that can still spread to other projects that are not using Unicode! It is better not to summon this monster unless there is absolutely no other way to do the job.
-
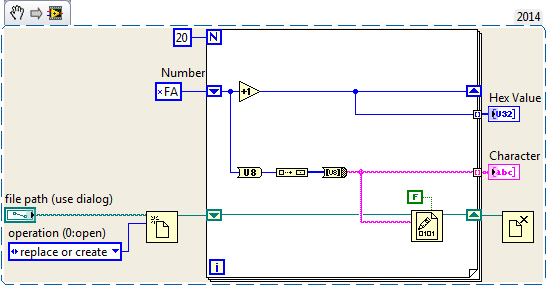
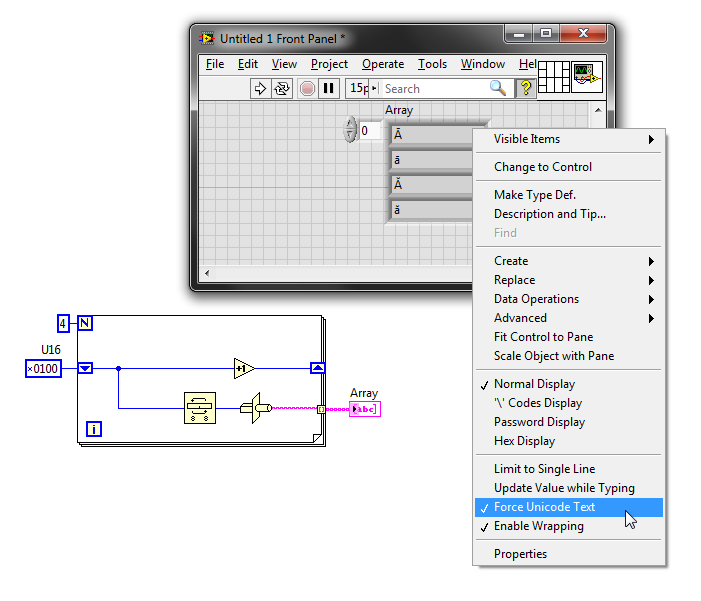
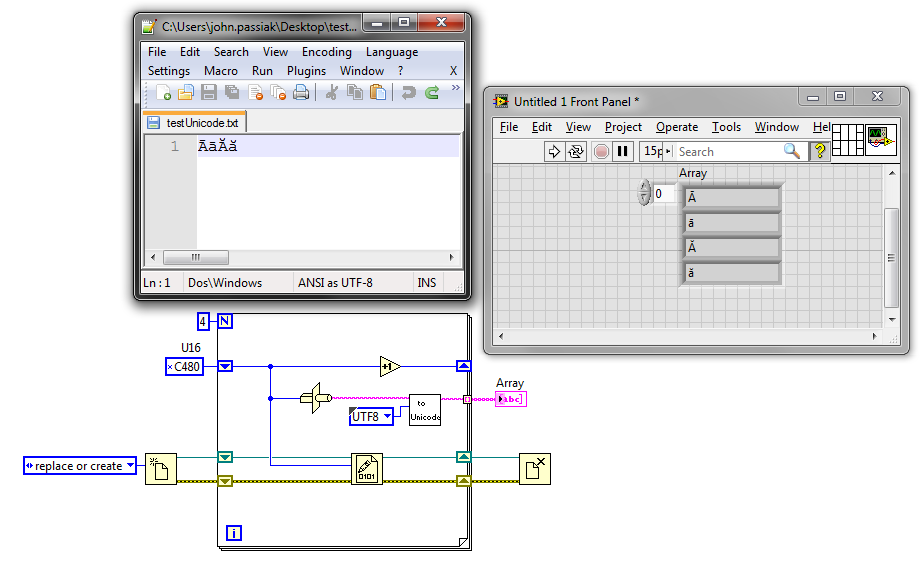
Generate and write unicode characters to file
The characters of genearted seems OK (up to x00FF), but after writing to file these characters and their values are different. Also the characters after 0x00FF are not good.
Any idea?
You should probably give this page than to read a thorough if you relied on the use of Unicode in your application. Here is a relevant excerpt:
ASCII technically only sets a value of 7 bit and can therefore represent 128 different characters, including characters such as the newline (0x0A) and return (0x0D) transport. However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The 128 additional characters in the ASCII range are defined by the code page of the operating system aka "language for programs non - Unicode. For example, on a Western system, Windows uses by default the character set defined by the Windows code page 1252 Windows-1252 is an extension of another commonly known used encoding ISO-8859-1.
Offers Windows-1252 characters up to 0xFF (ÿ) but not something higher to 8-bit (for example no 0x0100). By default, LabVIEW support these uses of 8-bit, multibyte strings characters - only interpretation is based on the current code page selected in the operating system. You can turn on Unicode, the instructions in my first link (this is not supported and can be a little buggy from time to time...) to get the support of multibyte unicode characters to multibyte codepage characters not in the operating system.
Unicode has several encodings, and the bit raw to a character depending on the encoding used. LabVIEW limited unicode support seems to use UTF-16 (little endian) encoding for whatever it will be displayed in the user interface. So to get the characters displayed on the interface user, you must enable unicode (instructions illustrated in my first link) and write the appropriate UTF-16 code:
UTF - 8 is more common and therefore easier to work with outside LabVIEW (e.g. my version of Notepad ++ obviously do not support UTF-16). I usually find myself using UTF-8 for files format strings and convert them to UTF-16 for display in LabVIEW.
Unicode in my first link library has the necessary subVIs to convert between UTF-8 and 'Unicode' (i.e. UTF-16).
Best regards
-
I need to run an application that requires me to change my Windows XP language for programs no unicode for English (Singapore). However I don't know English (Singapore) in the Windows XP language for non-unicode programs option setting. How can I solve this problem?
Hello
English (Singapore) is not supported in Windows XP. It is available in both Vista and Windows 7. Consult the document below.
http://msdn.Microsoft.com/en-us/library/dd373765 (vs.85) .aspx
I suggest that you try Windows 7, where you can easily download the language packs through Windows updates. Please take a look at the links below.
http://Windows.Microsoft.com/Windows-7
Language packs
http://Windows.Microsoft.com/en-us/Windows7/products/features/language-packs
Thanks and regards.
Thahaseena M
Microsoft Answers Support Engineer.
Visit our Microsoft answers feedback Forum and let us know what you think. -
getDevicePhoneNumber() provides the phone number with the unicode left-to-right mark
I use getDevicePhoneNumber (boolean format) ( http://www.blackberry.com/developers/docs/4.6.0api/net/rim/blackberry/api/phone/Phone.html#getDevice... (boolean)) to get the telephone number of my camera. I know that maybe it's not the actual number. I also can't use something else as the pin of the device. I use it to fill a field "my phone number" by default that can be edited manually in the case where the number is not correctly being read on the SIM card.
It works really well and displays the phone number in the field. However, a thorough review to the string of shows that he has the mark unicode '% E2% 80% 8F' in front of the string. This brand is known in unicode (utf-8) "BRAND LEFT-to-RIGHT ' (sources: http://www.tachyonsoft.com/uc0020.htm and http://unicode-search.net/unicode-namesearch.pl?term=mark ).
I only experienced it in BB OS 4.6 devices (does not check 4.7 yet), but it seems not to happen in OS 4.5 and below.
Were there changes to the orientation of the chain in OS 4.6?
Can I get rid of this brand using String.trim (); or I have to use something else?
This problem persists on my 9000 "BOLD", but none of my other GPS phones.
Because it was a pain to try to understand, here's the code I used to solve this problem.
private String trimPhoneNumber(String phoneNumber){ byte phoneBytes[] = phoneNumber.getBytes(); int length = phoneNumber.length(); int offset = 0; if ( phoneBytes[0] == 0x3F ) { length--; offset++; } return new String(phoneBytes, offset, length); }











Maybe you are looking for
-
On the last day of little the interent has been crashing with the following response - "container plugin for firefox has stopped working." Why and how can I solve this problem?
-
How to tell what version of IE is on my computer.
-
I have a problem with a PXI-2530 switch card work in matrix mode 4 X 32. I need to determine the resistance of the pairs of specific relay within the matrix. I have a PXI-4130 and a PXI-4071 in the same chassis, so I take measures 4-wire in a configu
-
How can I download Iso Windows 7 official without Digitalriver links?
I had a Windows 7 ultimate 32 bit computer. I installed Ubuntu top just for fun. I have the key of win 7 ultimate product on the bottom of my computer, but I lost the installation disc. Where is the iso file? I know there are digitalriver downloads,
-
BlackBerry Smartphones battery problem
Hello! I got a Blackberry Curve 9330 for 6 months now and the battery causes me problems. About a month ago, the aircraft started to reset each time is received the slightest shock. I looked at the battery, and one of the four metal terminals had som