Why index has a greater than its table dimension
I have a table with 25 columns, but most of the columns is zero except the primary key. Dba_tables and dba_indexes, I worked on that the primary key index has 309 MB and has 280 MB table.Suppose the index blocks contains the key identifier and table indexes, and blocks of table contains its data in the column and the rowid. If this is true, the primary key index should has the same size as the table which is null everything except the primary key. How is my index is 10% larger than the table?
An index is a B-tree +, where B is balanced.
------------
It consists of blocks of leaf and nonleaf.
Blocks not sheet are a kind of pre-Selection mechanism, to avoid, consider all the blocks of leaves.
Buy a book on data structures and/or to read the Oracle documentation you will see it explained in detail.
If you issue
analyze the
and
question
Select * from index_stats;
right after that, you will see how many levels have the index.
This allows the 10% overload.
Also the data blocks contain no ROWID.
Sybrand Bakker
Senior Oracle DBA
Tags: Database
Similar Questions
-
I ve changed the hardware computer inbetween w.o. disable demand first. I did subsequently following the rules given by Adobe. But the result was negative. The message is displayed and I cannot start LR6.
Hi reinhardp81818105,
We wish to inform you that your serial number has been fixed, please try again to activate it and share the results.
-
Hello
We have a file server that has a greater than 1 TB vDisk. How is it possible to save this virtual machine with the limitation could only ride a maximum 1 TB drive on the device?
Thanks in advance
Brendan
vDR is not an appropriate tool for the backup of a disk which is that great. Even though the limit is 1 TB in a practice 1 TB is not a good choice as a backup destination disk. Less than 500 GB is a more appropriate choice and multiple 2 or 300 GB even better. If something were to happen that requires a vDR re cataloging a 1 TB drive that it can take days. I can tell you that re cataloging is not uncommon. In the meantime, you have no access to vDR. No replacement takes place. Long and short - find another tool to back up this disk.
-
Outlook 2007 backup file is greater than the source file. Why?
My Outlook pst data source personal folders file using 2.4 GB. The backup file (by using the backup tool) uses 5.4 GB. Why the difference? I back up all my data on a hard drive to FAT 32 format, which will not accept a file greater than 4 GB, so I'm not able to save Outlook backup file given its current size.
Hello GaryCalgary,
Thanks for visiting the site of the community of Microsoft Windows XP. The question you have posted is related to Outlook and would be better suited to the community of Office Discussion groups. Please visit the link below to find a community that will provide the support you want.
Outlook General Questions Discussion GroupSteven
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think -
Why we cannot create more than one primary key on a table. Why we create several unique key on a table. Please explain if anyone have details of this.
«a primary key has semantic meaning, it is to be immutable (never change of value), unique and not null.»
a unique constraint is simply "at any time, these values are unique - they can change and they can be null.
You use a unique when constraint
(a) you do not already have a primary key for a table can have only one
(b) you allow NULL values in attributes
"(c) to allow you to update the values in the attributes.https://asktom.Oracle.com/pls/Apex/f?p=100:11:0:P11_QUESTION_ID:5541352100346689891
-
When I updated the shock of the clans for my daughter on his iPad, it has its own apple ID. and iCloud, my ID apple came on his id for the update, where it has its own apple ID now. Please can someone tell me why the update came not through its ID thanks
It seems that if the application has been downloaded on his iPad while it is connected to your Apple ID. If so, he'll always want to be updated with your Apple ID.
You must remove the application from his iPad and then download it again while it is connected to its own code of Apple.
-
Index bitmap for FKs on fact tables
Hi all
We have a database of DWH (Star Dimesions and the tables schema) running with OBIEE 11 g (11.1.1.1.6) on the oracle 11 g (11.2.0.1) database. I read in one of the best practical paper, creating index Bitmap on the Fks of all fact tables will help performance.
I created indexes for the less than 2500 separate keys, but we have 2 dimesions tables where there are great number of records (size 14 g and 10 g). Can I go ahead and create indexes of bitmap for 2 tables establishments (mainly account_key and customer_keys are the columns)?
Worried about creating index bitmap for large tables where they could affect the ETL process.
Ref: http://www.oracle.com/technetwork/database/bi-datawarehousing/twp-dw-best-practies-11g11-2008-09-132076.pdf (page 20)
Help, please.
Thank you and best regards,
Anand.>
I created indexes for the less than 2500 separate keys, but we have 2 dimesions tables where there are great number of records (size 14 g and 10 g). Can I go ahead and create indexes of bitmap for 2 tables as well
. . .
Worried about creating index bitmap for large tables where they could affect the ETL process.
>
You put the cart before the horse!Don't create index unless you have a reason documented for them.
Why did you choose the index bitmap for cardinality less than 2500? Perhaps based on a long-standing myth, but discredited on the cardinality?
See also Richard Foote two articles where he explodes the myths about bitmap indexes and considerations of cardinality
http://richardfoote.WordPress.com/2010/02/18/myth-bitmap-indexes-with-high-distinct-columns-blow-out/
http://richardfoote.WordPress.com/2010/03/03/1196/Re your concern about the tables with the 'large' number of records and affecting ETL.
You are right to be concerned about these issues, but you need to document your particular situation taking into account the architecture.
The fact tables and dimension tables can have a large number of records. If using the bitmap index is indicated, then the most records are most effective, they will be.
ETL is affected because the DML (INSERT, UPDATE, DELETE) operations on the tables with bitmap indexes can have serious performance because of the involved serialization issues. Updated single bitmap of a column value (e.g., am ' to 'F' gender) requires that the two index bitmap blocks must be blocked until the update is complete. An index of stored bitmap ranges ROWID (rowid min - max rowid) that can span many, many files. The "range" of ROWID is locked in order to change a value.
To change: 'follow her' rowid beach so that a row is locked and ID should be removed from the range by turning off the bit. Change to the 'F', the rowid id range 'F' must be found, locked and the bit set that corresponds to this rowid. No another row with ROWID in the range cannot be changed, because it is a transaction in the series. If the range includes 1000 lines and they all need changed it takes 1000 series.
For anything other that a very small number of documents the bitmap index would be deleted and rebuilt after the ETL operations. That is why the data warehouse designs try to minimize update and implement insertions and deletions using partitioning when possible; Adding a new day by adding a new partition.
There is also a big difference between a bitmap index and a bitmap join index. The white paper you quoted does not really indicate what type are used or recommended.
Learn more about the difference - see Using Bitmap indexes in data warehouses in the doc of Data Warehousing
http://docs.Oracle.com/CD/B28359_01/server.111/b28313/indexes.htm -
Increment Dt start with day greater than the Dt at the end of the year Prev in Pro * C
Morning people and greetings from Toronto.
I'm trying to change a Pro * C program. Since ages I touched a Pro * C program but I have made an attempt for her. I would probably need some help andhopefully is the right forum I could nto seem to find any section decicated Pro * C programs.
Here's what its supposed to do. I'm supposed to check if a Start Date of overlap between the start dates and dates from the end of the previous year, and if so, I'm supposed to assign one day Start Date greater than the Date of the end of the previous year.
I have a control panel that stores records for start date and end Date for each year. Here's what I have for 2010.
Start date = 8 May 2010 '; End date = may 12, 2011 'year =' 2010 From now the previous record in the table 1 (where the new record is supposed to be inserted) has a record that looks like this:
Now, based on the control table, the Start Date for 2010 coincides with the Date of the end of 2009. In this case, I would need to move the start date = may 9, 2010 "(Date of end + 1)DOC_ID NAME YEAR START_DATE END_DATE ------------------------------------------------------------------------------------------------ 999999 Mary Poppins 2009 03-May-2009 08-May-2010
Here is my ProC program in hand
Here would be my question:/* Include Headers */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <ctype.h> #include <math.h> --------------------------- /* Define constants */ --------------------------- #define nullterm(string) string.arr[string.len] = '\0'; /* SQL Host Variables */ exec sql begin declare section; exec sql include sqlca; varchar ctrl_start_date[11]; short ctrl_start_date_ind; varchar ctrl_end_date[11]; short ctrl_end_date_ind; varchar end_date[11]; short end_date_ind; int exist_end_date_flag; short exist_end_date_flag_ind; exec sql end declare section; /* Function Prototypes */ void check_date_overlap(); void main(int argc, char *argv[]) { /* Coding starts here */ void get_ctrl_dates() { exec sql select to_char(trunc(ctrl_start_date),'YYYY/MM/DD'), to_char(trunc(ctrl_end_date),'YYYY/MM/DD') into :ctrl_start_date :ctrl_start_date_ind, :ctrl_end_date :ctrl_end_date_ind from control_tb where current_yyyy = :year_number; } check_date_overlap(); if (strcmp( (char *)run_mode.arr,"N")==0) { check_date_overlap(); create_person_rec(); /* This will insert record into person_tb table */ } } /***********************/ /* CHECK_DATE_OVERLAP */ /***********************/ void check_date_overlap() { exist_end_date_flag = 0; /* assume he does not have a record */ exec sql select count(*), end_date + 1 into :exist_end_date_flag exist_end_date_flag_ind, :end_date :end_date_ind from person_tb where doc_id = :doc_id and (( :ctrl_start_date between start_date and end_date ) or ( :ctrl_end_date between start_date and end_date ) or ( start_date between :ctrl_start_date and :ctrl_end_date ) or ( end_date between :ctrl_start_date and :ctrl_end_date )) and year_number = (:year_number - 1) group by end_date having count(*) = 1; /*** Error Check Routine goes in here ***/ /* Overlapping of dates; Set the Start Date equal End Date + 1 to avoid overlap */ if (exist_end_date_flag == 1) { print_to_err_file("The Start Date is overlapping with a previous period.",0); } nullterm(end_date); } /* check_date_overlap */
My question is, should the SQL above be written like this instead?
Published by: Raj404261 on June 10, 2009 11:21/***********************/ /* CHECK_DATE_OVERLAP */ /***********************/ void check_date_overlap() { exist_end_date_flag = 0; /* assume he does not have a record */ exec sql select count(*), end_date into :exist_end_date_flag exist_end_date_flag_ind, :end_date :end_date_ind from person_tb where doc_id = :doc_id and (( :ctrl_start_date between start_date and end_date ) or ( :ctrl_end_date between start_date and end_date ) or ( start_date between :ctrl_start_date and :ctrl_end_date ) or ( end_date between :ctrl_start_date and :ctrl_end_date )) and year_number = (:year_number - 1) group by end_date; /*** Error Check Routine goes in here ***/ /* Overlapping of dates; Set the Start Date equal End Date + 1 to avoid overlap */ if (exist_end_date_flag == 1) { /* Is this even correct or would I have to do a strcpy?. Also note that I am overwriting ctrl_start_date which was fetched earlier in get_ctrl_dates() */ ctrl_start_date = end_date + 1; print_to_err_file("The Start Date is overlapping with a previous period.",0); } nullterm(end_date); } /* check_date_overlap */You can put your code between the {code}
As
{code}
your code...
...
{code}SS
-
Read byte with a value up to 127 lire byte with an ASCII value greater than 7F (127 dec)
Hello
I have to read a byte with a value greater than 127, Labview turn 27.
In help I saw that Labview provides a description of ASCII that pour values ranging up to ' 127.
What do I need to do?
LabVIEW 6.1
Windows XP
Hello
I want to read a byte with a maximum value of 127, but Labiew reurn arround 27 value
How do I do?
Rigid wrote:
Thanks for your help. I'm not changing lyke I understand (my English is poor quiet...)
I have another program that communicate with the instrument. I know byte (6) must be greater than 18 (greater than 7F actually).
But with Labview, I'm only 18.
While it might be higher than 18 x, an I8 is signed, and therefore it cannot be greater than x7F - it has a range of-128 to 127. A U8 is not signed, and it's why he has a range from 0 to xFF. However, x 18 is the same if you treat as signed or not signed. I don't see how LabVIEW can read a wrong value on the serial port. Are you sure you're looking at the correct byte? Your code shows that you split the chain twice. Are you sure that you do this properly?
Given that you use on Windows you can recheck the chain received using PortMon. Allows you to see what is actually received by the driver for the serial port on Windows.
P.S. I actually meant the whole byte function.
-
Display a value in the column only if the number is greater than 1
I need to return a value in the only if column the the count is greater than 1 for the same column.
Example table:
FOOD_TYPE Agenda COST_TO_BUY SELL_PRICE Ice cream Chocolate 0.50 2.00 Ice cream Vanilla 0.50 2.00 Ice cream Strawberry 0.50 2.00 Chicken Wings 2.00 5.00 Bovine meat Steaks 8.00 15 h 00 Bovine meat Roast 10 h 00 6:00 pm In this example, I want to choose the POINT of FOOD_TYPE, SUM (COST_TO_BUY) AND SUM (SELL_PRICE), but I want only to select the ITEM if there is more than 1 points in the FOOD_TYPE.
I tried all kinds of grouping and even including a case statement in select it as follows:
CASE
WHEN (COUNT (DISTINCT POINT) > 1)
THEN THE POINT
ELSE "
END
However, this is denied when I group because it forces me to use the POINT as a group and I can't use the set statement in the GROUP BY because it has an aggregate function.
Help, please!
with
power as
(select food_type 'Beef', 'Steaks' article, cost_to_buy 8.00 15.00 sell_price of all the double union)
Select 'Beef', 'Roast', 10.00, 18.00 double Union all
Select 'Chicken', 'Wings', 2.00, 5.00 double Union all
Select 'Ice Cream', 'Chocolate', 0.50, 2.00 double Union all
Select "Ice Cream", "Vanilla", 0.50, 2.00 double Union all
Select "Ice Cream", "Strawberry", 0.50, 2.00 double
)
Select food_type 'Type of food. "
cases where the head (separate) over (partition food_type) > 1 then end point "Item,"
TO_CHAR (cost_to_buy, 'fm990.00') "Purchase cost"
TO_CHAR (sell_price, 'fm990.00') 'selling price '.
food
food_type desc order
Food Type Item Purchase cost Sell Price Ice cream Chocolate 0.50 2.00 Ice cream Strawberry 0.50 2.00 Ice cream Vanilla 0.50 2.00 Chicken - 2.00 5.00 Bovine meat Roast 10 h 00 6:00 pm Bovine meat Steaks 8.00 15 h 00 Concerning
Etbin
-
give meaning to cases where minimum effective_start_date is greater than the current date
Hi guys, I'm not a developer oracle as such, but I'm trying to get some information from oracle to send to other systems of the company, since we are dealing with oracle HRMS as the master system for employee information.
In particular, we would like to create people in our training and the security system when they are created in oracle.
I was told that the oracle per_all_people_f object acts as a slowly changing dimension of type 2, where a person can have several versions, which only is always the current version and the current version can be retrieved using the standard parttern of "date of current between the effective start date and actual end date. So far so good.
However, I can see there are cases where the minimum 'effective_start_date' is greater than the current date. It is, indeed, equal to their start_date. I guess start_date represents "the first day of work" of the person.But this means then there is no "current" information known to people who have not yet really started working for the company again. This seems odd. How can I have someone for whom we have no information "currently correct? I was told that the effective_start_date of the line is automatically set to their "first day of work" date on which the information is entered into the system, IE, the user to enter information doesn't have the ability to say 'this is the current version of the data for that person, who starts at a date in the future. "
For this reason, I cannot know these new people (who have been entered in oracle, but did not have actually to their first day of work still) training system. But we would obviously get people established in related systems so that they can use all of these systems on their first day of work.
Have I misunderstood something here? How can there be no correct version for a person at the date and time?
Hello
How normally "inform you" the training system on a new person record? If it's a kind of report or an interface, it may be useful changed to examine a number of days in the future, for example
+ 7 It is important to understand when you look at an Oracle HRMS instance through enforcement (i.e. the ' front end'), you look at the data on a date date (of the session) - by default, the date is the system date, but it is possible for a user to change this date to be in the future or the past as they see fit. The ability to implement the records in person in the future is a great feature to have, of course, but it must be understood that in this situation, at the date of the day the person's file logically does not exist yet from the point of view of the MFC features. Behind the scenes, however, in the per_all_people_f of the table, the line exist. Similarly, future update of changes to a person (e.g. marital status from Single to married) could be implemented, and the change in status would be visible if the session has been scheduled on a date or after the date of the marriage. As correctly observe you, behind the scenes, the table will hold all historic entries for this person_id with contiguous effective_start_date and effective_end_date beaches.
Either way, date_start value is not related to as such hiring date; It is actually the value of effective_start_date earlier for the person_id. All changes, regardless of how many or what the effective_start_date is in each case, will always carry this same start_date value. It * may * be identical to the hiring date (certainly the fact that you configure their hire date person records would cause that), but if the person has been created as a postulant effective from 1 September and was then hired has effect from 21 September, column start_date value would be still 1 September. The record of the person would be visible when the current date is on or after this date - the only difference is that they show that an employee until the 21st.
I hope this helps, but it is possible, that I just confused you more!
Clive
-
How it warns Oracle to use an index for the join of two tables...
How to prevent the Oracle to use an index for the join of two tables to get a view online that is used in an update statement?
O.K. I think I should explain what I mean:
When you join two tables that have many entries sometimes there're better is not to use an index on the column that is used as a criterion to join.
I have two tables: table A and table B.
Table A has 4,000,000 entries and table B has 700,000 entries.
I have a join of two tables with a numeric column as join criteria.
There is an index on this column in A table.
So I instead of
I want to usewhere (A.col = B.col)
in order to avoid Oracle using the index.where (A.col+0 = B.col)
When I use the join in a select query, it works.
But when I use the join as inline in an update statement I get the error ORA-01779.
When I remove the '+ 0' the update statement works. (The column is unique in table B).
Any ideas why this happens?
Thank you very much in advance for any help.
Hartmut cordiallyYou plan to use a NO_INDEX hint as shown here: http://www.psoug.org/reference/hints.html
-
10.11.2 OS Mail index has been damaged
After the upgrade to OS 10.11.2 yesterday, when I opened the Mail (I use two accounts for Gmail and iCloud) I got a warning that my index of mail had been damaged, I should leave Mail and reopen it, and that I will not lose my messages or the mailboxes. When I opened her Mail, a window titled 'Message Import' opened with a progress bar indicating to all first it would take 4 hours. Now 8 hours later, it's still in the import process. (When I access my accounts via a web browser, everything works correctly - the accounts themselves seem not damaged.)
It's about a 2012 end iMac. When I opened the Mail on my end 2011 MacBook Air (also just upgraded to 10.11.2), I received the same warning that my mail index has been damaged; I'm not reopening Air Mail until I see how the situation is resolved (if this is the case) the iMac.
Someone saw something similar after the upgrade to 10.11.2? I thought that this update was supposed to fix e-mail issues... More important still, what can I do to restore the e-mail if the import process does not resolve the problem, or does not complete? And is there something I can do (maybe remove something from the library?) that will allow me to reopen the Mail on my other computer without wait 8 hours and count so he can reopen?
I've seen other reports of the present, but in these cases the repair took less than half an hour. But if you have a very large mailbox, indeed it hours before the process ends.
-
IMAQ_USB - 1074396024 (coverage Minimum value must be greater than zero)
Hello
I have problems to use a USB WebCam when I try to run an executable file in a PC that not have installed LabVIEW. The error code that is displayed is 1074396024 (coverage Minimum value must be greater than zero).
When I run it on a PC that installed, LabVIEW everythings works great!
Someone has an idea to help me? The sample program is attached.
Thks
Hey neat,
To run your executable file in a free LabVIEW PC, you must install LAbVIEW Run-Time Engine and Vision Run-Time Engine.
http://digital.NI.com/public.nsf/allkb/3EB8C8AFC1593B4A8625712E0002869B
Engine performance vision application for permit.
Best regards
Abel Souza
Engineering applications
National Instruments Brazil
-
Read/write file binary change greater than 128 bytes.
Hi all, maybe a strange question, but I'm scratching my head on this one. There is undocumented behavior in the function of read/write binary file, where U8 a value greater than 128/0 x 80 get automatically converted to 0x3F value?
I try to use LabVIEW to generate a binary file custom that we'll load in an EEPROM, so all data in the binary file is stored as values of U8. I have a "template" file, and eventually I'll take the logic implemented to replace the fields with the data from the true value. However, I am struck by the anomaly that when I just read the file in LabVIEW and then réécrirait, all the values 0x80 and more are truncated to 0x3F value. Has anyone seen this before, and is there a solution?
I noticed writing the value 0 x 80 directly to one generates a binary file (such as a U8) 0 x 90, 0 x 70 being written in the binary file. It is also rather undesirable, as it adds additional bytes in the bytestream, and the bytes of EEPROM must be in exact locations.
Join your data file.
This program is to give the images below? Are you sure that LabVIEW is to write the bytes differently? I really doubt that.
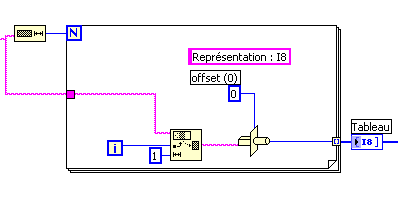
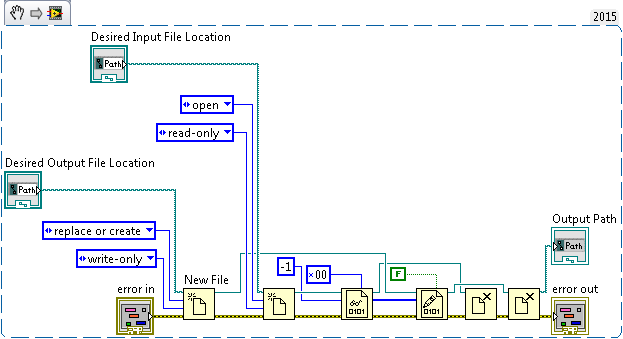
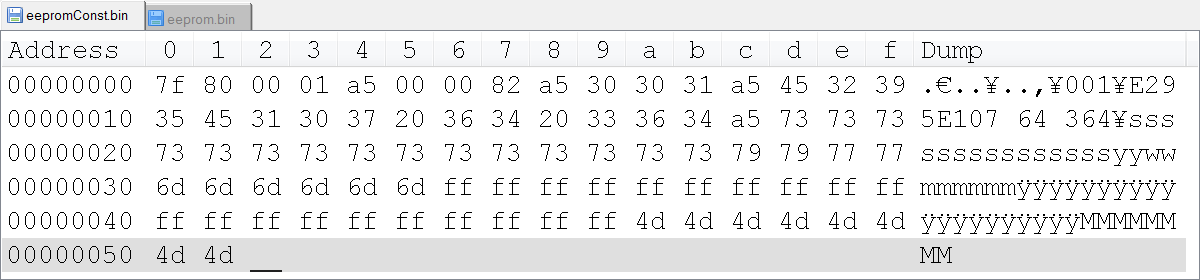
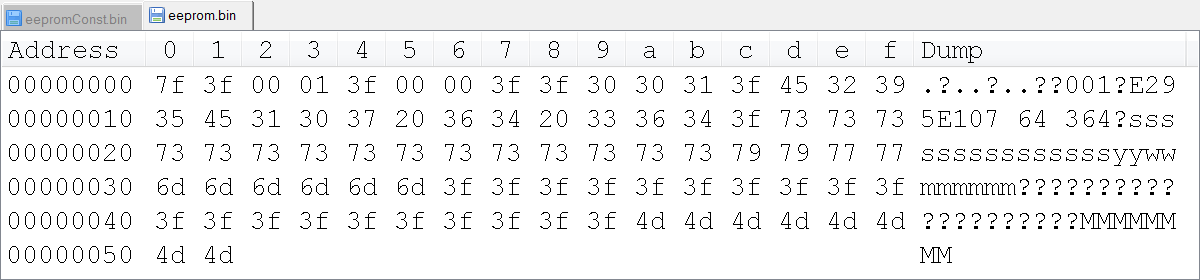
Maybe you are looking for
-
McFee software has detected some viruses and Trojans
Buy laptop 2 days ago and installed the software McFee (as recommended). Computer said McFee scan is free of viruses and any problems found.Problem is that I have different warnings on POPs ups saying system has up to 23 viruses and Trojan horses det
-
Need some tips to maintenance for laptop - Satellite L40
Hello I have Satellite L40-170, and I have a few questions about her, since it is the my first laptop: 1 should I remove the battery when it is fully charged and I work on the KT?2. If I don't need to use the battery for a period of time (2-3 weeks)
-
I hope someone can help me. Trying to turn my iMac and appearance of the white apple logo and it seems that it is loading, but then the screen goes black. There is no edge loading, also the fan does not start. What can I do?
-
I don't know whats wrong with my windows but somerone direct email account seems to be to use it to send advertisements to my contacts. I clicked on air currents and there were hundreds of ads, but the meter does not have to indicate that I had at al
-
Hi, I do a large volume of disk time replacement to other readers get exchanged between systems is there a way to say which drive is which system. We buy in volume same model laptop, but the warranty when disks get reversed, the dates vary from a sys