widget vcops 5.7.1 resources remove columns
Hi all
I work with vCenter Operations manager 5.7.1.
I do a custom dashboard, with widget resources.
I add a few measures of the widget, so I don't see in widget like name, resource type, health columns, collection... station and the added parameters.
I would like to see only the resource name and the parameters added, so in the menu in the column I uncheck the columns resource collection station, etc...
It's ok, but when I logout of personalized interface user and login, I see once again all the columns.
Any idea?
Thank you
IG
I just do what you did, but when I log in, it looks like how I left it (even converted some of the columns).
What you could try is: export and import the dashboard and check if it looks the same. Otherwise, I opened a case of pension at VMware.
Tags: VMware
Similar Questions
-
How to remove columns from the table on the master 1-0?
I have an array of 96 columns with strings. I also have the array of int 96-elemets (mask) with 1 and 0.
What I want to do is to is to remove (or hide - but I read that it is not possible) all the columns with index corresponding to 0 in the mask table.
example:
columns in the table
1 2 3 4 5
mask
0 1 0 0 1
I want to remove the columns 1, 3 and 4 and leave only 2 and 5 in my table.
How can I do?
If I create loop for with i as the index of the column, when I do DeleteTableColumns() columns number decreases, and I get an error of range out of

Or do I have an option to hide the unnecessary columns (not set their width to 1, it's very ugly-looking)?
Please help me (())
Hello rovnyart!
1. removal of columns in the table:
I suspect that the reason why you get the out-of-range error is due to fact that in your loop, you delete the columns in the table, you'll eventually end up by referring to a column that no longer exists, because the other columns before it have been deleted. While you remove each column of your table in the loop for example, the column index number will move, because you deleted the other columns in front of her.
To resolve this, even if you delete a column in your loop, make sure that you take also into account that the index of the column is moved because of the removed columns.
2 hide columns in table:
You can use the ATTR_COLUMN_VISIBLE attribute to hide columns in the table:
http://zone.NI.com/reference/en-XX/help/370051Y-01/CVI/uiref/cviattrcolumnvisible_column/
3 alternatives:
Note that another alternative would also use a tree instead, control as the tree control also supports the hidable columns:
http://forums.NI.com/T5/LabWindows-CVI/table-hide-column/TD-p/569773
Best regards!
-Johannes
-
Manager disc Snap-in for the MMC. Is it possible to change the order of columns. Or remove columns completely?
I would like to move the capacity; Space free; Status; to be fair, Volume. The page layout; Type; File system; seems to me
useless in this form. If there is no way to change maybe someone at Microsoft may include this option in Windows 9.
Hello
I would like to inform that you can not change the order of columns or remove columns completely as it is by design. However, you can display or hide items in the console window.
Hide columns in Diskmanagement:
a. Click Start, type diskmgmt.msc and press to enter.
b. click view and select Customize.
c. you can select or clear the check boxes to show or hide items in the console window.
I hope that helps!
-
Impact of removing columns in a table
Hello
Using oracle 11.2.0.3
We want to remove some columns in a table in a tidy exercise - as they are not necessary - the application code that references will change them.
Anyone see any negative impact: what are non indexed columns cannot therefore predict problems - just thought I would check in the case where someone met all similar questions making.
Thank you
Anyone see any negative impact: what are non indexed columns cannot therefore predict problems - just thought I would check in the case where someone met all similar questions making.
Yes - there MAY BE negative effects.
1. you can lose data if you do not have this table saved (or active flashback) so you can restore the data and move the original table if there is a problem during the operation. There is ALWAYS a risk of system failure even if the risk is low. Abandoned data cannot be recovered, so you better have a backup from top - to the second.
2. the DROP operation actually deletes the data for EACH ROW in the table. This means a full table scan and possible restructuring of blocks. These columns can be part of, or severely, chained the lines. They could be the LOB columns whose data is stored in another segment that must also be cleaned.
You have not displayed enough details for us to know what would be the issues here for your unknown column types.
But exercise alone.
http://docs.Oracle.com/CD/B28359_01/server.111/b28310/tables006.htm#i1006709
Deleting table columns
When you issue a
ALTER TABLE...DROP COLUMNstatement, the column descriptor and data associated with the target column are removed from each row in the table. You can drop multiple columns with a single statement.At a minimum, you need to back up this table before and after the MOVE. This backup operation will use the resources so it can also have an impact.
-
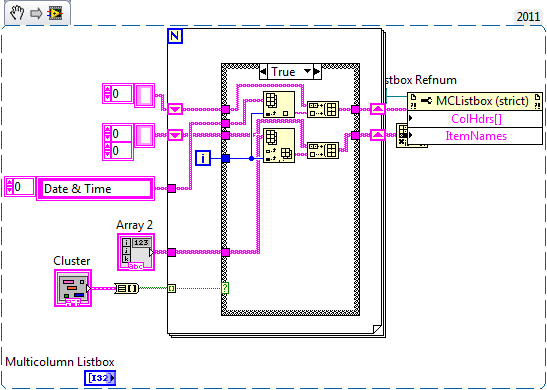
Hi all
I hope someone can help me. I hit a snag in my application programming.
I have a table size 2D 8 x 20. These data, I need to display it in a multicolumn listbox. But I don't want to show all the data. From the user Panel will make the choice among given options, what parameters it wants to display. I have attached the VI in which, of the bunch, I sort the real clues and keep only the settings that I have to remove all other columns. The size of true indices creates a special case to manage these settings.
I was able to create only to size 1. Please find the sent VI and tell me a simple solution to this problem. I tried to look for various array function for this problem.
Am using LabVIEW 2011 professional development.
Thank you best regards &,.
Manisha
Hope this helps as a starting point,
Kind regards
Marco
-
Hello everyone,
I've played today with a custom Ribbon and tried a checkbox to remove the value #missing/zero with lines and columns using HypsetSheetOption. I was able to implement to remove the lines but could not find the syntax to remove the columns. Does anyone know the vItem? Here is my current code:
Public Sub Checkbox1_onAction (control As IRibbonControl, pressed As Boolean)
If you press and then
X = HypSetSheetOption (empty, 6, True) ' the value to remove any data
y = HypSetSheetOption (vacuum, 7, True) ' the value to remove the zero
Application.StatusBar = "Row WE Supression.
Application.OnTime Now + TimeSerial (0, 0, 5), "ClearStatusBar".
g_blnCheckboxState = True
On the other
X = HypSetSheetOption (empty, 6, False) ' the value to remove any data
y = HypSetSheetOption (vacuum, 7, False) ' the value do not delete the zero
Application.StatusBar = "Row OFF Supression.
Application.OnTime Now + TimeSerial (0, 0, 5), "ClearStatusBar".
g_blnCheckboxState = False
End If
End Sub
Void ClearStatusBar()
Application.StatusBar = False
End SubThis one is listed in HypSetOption, not HypSetSheetOption (not sure offhand if you pass the same value in HypSetSheetOption).
It said (since you're this ad space Essbase) works the suppress option for an Essbase source columns? The documentation says, even in 11.1.2.5.400.
-
How to remove columns from table form of process
Hello
I have a form of process UD_FN_USR. I have created a userid long type column and later the requirement has changed and I need to change the type of chain. I am able to remove the column from console design but in the table, the left column while I coulnt create the column with the same name as the type string, its tellling leaves the same name of column with a different data type in the current version or earlier versions.can someone please tell me how do to solve this problemYou need to remove since the end of the database as suggested Sunny.
ALTER TABLE DROP COLUMN UD_ABCD_UID UD_ABCD
-
Find tables that added or remove column
I use Oracle 11.2.0.2
I want to write a query that lists of paintings who added or dropped columns in a special day say today?
Your help is appreciated.
I need this list of tables because the materialized view build base on these tables becomes invalid when the source tables is changed. In my environment where there are several tables in the source that is constantly changing, it is a hassle to recreate materialized view. Is there an easier way to keep materializing views which source schema changes?
Published by: spur230 on May 10, 2012 16:08>
Is there an easier way to keep materializing views which source schema changes?
>
It depends on the type of schema change AND the type of materialized view.There is no other choice but to invalidate the application of MV if a column is deleted which is used in a MV.
You should always have access to the data in the MV - do you? You just won't be able to refresh the MV because the underlying query uses a column that no longer exists.
If a column is added, or a deleted column is not used in the MV, then most MVs should not affect. New columns not could possibly have served in the underlying query of the MV and drop columns that were not in the query of MV will not affect the query either.
As Justin says the AUDITING feature may be your best option to detect these changes.
Which still prevent the improved varieties to be invalidated and if you have a fast ON COMMIT refresh MV it will fail as soon as the DDL change is made if the table is checked or not.
-
How do I get taken off the table columns
See the link below
[url http://dba-oracle.com/t_how_to_recover_oracle_dropped_column.htm] How do to recover the oracle dropped column
-
APEX 4.1 BUG: ORA-01403: when you try to remove column classic report
Hello
I have produced this on apex.oracle.com.
Create classic example from query report
Change report attributes and add the derived column.select ename, empno, mgr, job, deptno from emp
Edit derived column, and place for the Expression of the column formatting HTML
Will change the report query and delete the ename column of query.#ROWNUM#
Press on apply changes and the result is error ORA-01403: no data found
Kind regards
Jari
http://dbswh.webhop.NET/dbswh/f?p=blog:Home:0
Published by: jarola on January 4, 2012 09:07Hi Jari,
Thank you for reporting this issue, I filed bug 13738357 to follow it.
Kind regards
Marc -
I have the following table
create the table cust_phone
(
number of cust_id,
telephone1 varchar2 (20).
Telephone2 varchar2 (20).
phone3 varchar2 (20).
phone4 varchar2 (20).
phone5 varchar2 (20).
phone6 varchar2 (20).
phone7 varchar2 (20).
phone8 varchar2 (20)
)
My current data are like:
Select * from cust_phone where cust_id = 1
1 2784819 2784818 2784816 2784819 2784818 2784819 2784815 2784816
I want an update query nullfy columns that are double with others in the same row, only one should exist.Try this...
UPDATE cust_phone a SET (phone1,phone2,phone3,phone4,phone5,phone6,phone7,phone8) = ( SELECT phone1,phone2,phone3,phone4,phone5,phone6,phone7,phone8 FROM ( SELECT cust_id, MAX(DECODE(ph,'PHONE1',phone_nos)) PHONE1, MAX(DECODE(ph,'PHONE2',phone_nos)) PHONE2, MAX(DECODE(ph,'PHONE3',phone_nos)) PHONE3, MAX(DECODE(ph,'PHONE4',phone_nos)) PHONE4, MAX(DECODE(ph,'PHONE5',phone_nos)) PHONE5, MAX(DECODE(ph,'PHONE6',phone_nos)) PHONE6, MAX(DECODE(ph,'PHONE7',phone_nos)) PHONE7, MAX(DECODE(ph,'PHONE8',phone_nos)) PHONE8 FROM ( select cust_id,ph,nullif(phone_nos,lag(phone_nos,1,0) over (partition by cust_id order by cust_id,phone_nos,ph)) phone_nos from ( select cust_id,'PHONE'||lvl ph, decode(lvl,1,phone1,2,phone2,3,phone3,4,phone4,5,phone5,6,phone6,7,phone7,8,phone8) phone_nos from cust_phone,(SELECT LEVEL lvl FROM dual CONNECT BY level<=8) lvl_tbl ORDER BY 1,2 ) order by cust_id,phone_nos,ph ) GROUP BY cust_id ) WHERE cust_id=a.cust_id ) -
Dealing with errors due to newly added/removed columns
DB version: 11 g
I don't know if I created a post unnecessarily large to explain a simple problem. Anway, this is here.
Asked me to encode a package for archiving.
We will have two schemas; The original schema and a schema of the Archive (connected via a DB link)
When the records of some tables in the ORIGINAL schema meet the archiving criteria (based on the number of days old, Status Code etc.), it will be moved ("archived") to the schema of the ARCHIVE using the INSERT syntaxORIGINAL Schema -------------------------> ARCHIVE Schema via DB Link
The original table and the table of archive has the same structure, except that the Archive table has an additional column called archived_date that records only when a record got archived.insert into arch_original@dblink ( col1, col2, col3, . . . . ) select col1, col2, col3, . . . . from original_table
We have tables with many columns (there are a lot of tables with more than 100 columns), and when all column names are explicitly mentioned as the above syntax, the code becomes huge.create table original ( col1 varchar2(33), col2 varchar2(35), empid number ); create table arch_original ( col1 varchar2(33), col2 varchar2(35), empid number, archived_date date default sysdate not null );
Alternative syntax:
So I thougt of using the syntax
Even if the code looks simple and short, I noticed a downside to this approach.insert into arch_original select original.*,sysdate from original; -- sysdate will populate archived_date column
Disadvantage:
For the next version, if developers decide to add/drag a column in the ORIGINAL table in the original schema, this change should be apparent in (ARCHIVE) DDL script of the diagram of the archive_table as well. It is virtually impossible to keep track of all these changes during the development phase.
If I use
syntax, you will realize that there is change in the structure of the table only when you encounter an error (because of lack/news column) in the Runtime. But, if you have all the column names are explicitly asinsert into arch_original select original.*,sysdate from original;
Next, you will encounter this error when compiling itself. I prefer the error due to a lack/new column when compiling itself rather than at run time.insert into arch_original@dblink (col1, col2, col3, . . . . ) select col1, col2, col3, . . . . from original_table
While the guys do you think? I shouldn't go to
syntax due to the inconvenience above. Right?insert into arch_original select original.*,sysdate from original;VitaminD salvation,
Yes, something like that. Only, I meant to use it as a code generator to produce static sql to use in your archiver plan. I didn't use dynamic sql.
Start with something simple, to generate lists of columns to insert and select. Decide if you want to generate complete instructions, procedures or the same package.
For beginners to do something like you suggest
select ',' || column_name from cols where table_name like :your_table order by column_id;Out of use allows you to easily create your insert into... Select in the statement. Once you feel able to this topic, consider as much as your taste.
But my point is still. Use it as a static sql.
Concerning
Peter -
Remove columns without ORA-30036: unable to extend segment... UNDO_TBS
Hello people, I have a table with 290 million-lines (large enough to be a headache sometimes). And that's my problem, I have to drop 21 columns of this table... So, I did
ALTER TABLE < table_name > DROP (column1, column2,..., column21);
But I got an ORA-30036: unable to extend segment by 8 in the 'UNDO_TBS' undo tablespace And I don't want to extend this tablespace.
Is there any operation that does not use the UNDO space?
To use this is a valid option?
ALTER TABLE < table_name > SET the UNUSED COLUMN < nom_de_colonne >;
ALTER TABLE < table_name > DROP UNUSED COLUMNS;
Thank you.
MartinIf space is a constraint then DBMS_REDEFINITION isn't a good idea, since you'll need temporarily space for a complete copy of the original table/index.
I think that the simplest solution to your question is to use the option of CHECKPOINT of ALTER TABLE DROP... CONTROL point which will reduce the amount of UNDO space required considerably.
See the documentation for more information
http://download.Oracle.com/docs/CD/B28359_01/server.111/b28286/statements_3001.htm#i2124702
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/ -
Is there a powercli way to remove all the resources of a vCenter Server both pools? The clusters are underutilized and I don't need any virtual machines into pools of resources. I want to make sure that this is not an impact all VMs running, other than just removed them from the list of resources.First of all, you need to move all the virtual machine default and hidden, resourcepool, called Resources.
This pool is at the root of the cluster.
$defPool = get-ResourcePool-name of resource
Get - VM | Move-VM-Destination $defPool - confirm: $false
If you have more than 1 cluster, you will need to adapt the lines and run it for each cluster.
Use the Location parameter!
Once this is done, you can start to remove the resourcepools, with the exception of the default
Get-ResourcePool | Where {$_.} Name - only 'resources'} | Remove-ResourcePool-confirm: $false
But I advise you to test this first!
-
Remove the column from the compressed tables
NLSRTL 11.2.0.3.0 Production Oracle Database 11g Enterprise Edition 11.2.0.3.0 64 bit Production PL/SQL 11.2.0.3.0 Production AMT for Linux: 11.2.0.3.0 Production Hello
I read on how to do to remove a compressed table column - first set unused and then drop unused columns. However, in the example below on the basis of data, I ran it, it does not work. Please, can you tell me WHEN this approach does not work. What is dependent on - settings or something else. Why can't I drop unused columns?
And the example and errors:
create table tcompressed compress in select * from all_users;
> TCOMPRESSED table created.
ALTER table tcompressed add x number;
> table TCOMPRESSED altered.
ALTER table tcompressed drop the x column;
>
Error report:
SQL error: ORA-39726: unsupported operation column add/drag on compressed tables
39726 00000 - "operation column add/drop not supported on compressed tables. ''
* Cause: Not support add/column operation move compressed tables
elapse.
* Action: When adding a column, do not specify a default value.
DELETE column is only supported in a column SET UNUSED
(remove the column metadata).
ALTER table tcompressed unused column of the set x;
> table TCOMPRESSED altered.
ALTER table tcompressed drop unused columns;
>
Error report:
SQL error: ORA-39726: unsupported operation column add/drag on compressed tables
39726 00000 - "operation column add/drop not supported on compressed tables. ''
* Cause: Not support add/column operation move compressed tables
elapse.
* Action: When adding a column, do not specify a default value.
DELETE column is only supported in a column SET UNUSED
(remove the column metadata).
As you can see even after changing the table defining the column as unused X I still can't drop by DROP UNUSED COLUMNS.
Thank you.
If you enable compression for all operations on a table, you can delete the columns in the table. If you enable compression for the only direct-path inserts, you can't remove columns.
Maybe you are looking for
-
The battery swelling?-Trackpad is not a click.
Hello 5-6 weeks, I noticed that my trackpad was not letting me click on the left side, I can click on the right side and a little to the left, but there is one area where it is impossible to click. After reading a lot of Web sites and discussions, it
-
Canvio portable HDD driver won't install
Hello I hope someone is able to help me. I try to use a portable hard drive Toshiba (HDTB110AK3BA) on a laptop computer of other manufacturer that has a Windows 7 operating system. However, I keep just said that the device driver has not been install
-
My photosmart hp more b210 lost connection for scanning. I can print.
My B210 worked well for a while, then it will print any more. Finally I tried to check everything reinstalled the software and configure everything again. It now prints but the scanning program cannot find the printer.
-
Synaptic touchpad does not work
I get this message when I try to fix my touchpad: "Windows was able to successfully install device driver software, but the driver has encountered a problem when he tried to run. The problem is code 24. » Description:Windows was able to successfully
-
How to stop the next email to open automatically when I delete email open current?
If I have an open e-mail and I use the button Delete, the next email automatically opens. Is there a setting I can change to stop this?