A persisted tables of stadium for the sources of the eBS
Hi Experts,I am currently working on analytical HR and use OOB Informatica mappings for the loadings of OLAP data. The source is Oracle eBS (HRMS).
I find that there are several mappings of PersistedStage to load the tables of persistent scene like W_ORA_WEVT_PERF_PS, W_ORA_WEVT_SAL_PS etc. These paintings fills in turn tables _FS (as usual for loads of data warehousing).
Can someone help me understand why is - this stage friendly tables are used even when we have typical stage tables (* _FS) also?
All document links will also be useful for my checklist.
Thanks in advance.
Anamika
The reason for the staging as Persisted is not just to join the tables... as you said, this is done in SQ itself. set persistent staging are used for a number of reasons... one (as I've mentioned before)... is when there is no effective timestamp valid on the source... in compating table the new changes with the tables of the "persistent" scene, you can assess the actual start/end dates. Some other reasons can also make a few indicators or calculations... for example, in human resources, an 'event' can be a number of types such as 'Change of use' or 'Change of age band'... the scene as Persisted tables can capture these flags to be used downstream. In other cases, we need to "filter" the records of the source of changes unnecesssary. In BI applications, we use a kind of "date last updated" to capture incremental changes... but in the OLTP system, we couldn't have some incremental changes... Suppose you have a PROJECT dimension, and it has a date of update... and this update date is changed when the project manager changes... and you don't care to see this change... to avoid unnecessary variations in the increment, so you can have a persistent Stadium to check if gradual change is necessary or not. Here are some of the many reasons to persist.
If it helps, please mark as correct.
Tags: Business Intelligence
Similar Questions
-
How can I update the table table of contents for the sub condition?
Hi guys,.
I have a custom table that must be updated in a table source 'abc ';
I have to update 8 fields of 'abc', based on five keys corresponding between custom and abc records
Here is the syntax I have a suite please let me know the effective way to do this.
I get the error message for the syntax below. I think that 'FROM' keyword must not be use GTA?
update of custom table one
Set a.field1 = b.field1, a.field2 = b.field2, a.field3 = b.field3
ABC b
where value = ' 05 "
Hello
Whenever you have a problem, please post a small example data (CREATE TABLE and only relevant columns, INSERT statements) of all the tables involved, so that people who want to help you can recreate the problem and test their ideas.
Also post the exact results you want from this data, as well as an explanation of how you get these results from these data, with specific examples.
If you ask yourself on a DML statement, such as UPDATE, then the CREATE TABLE and you post instructions INSERT must re - create the tables as they are to the DML, and the results will be the content of the or a modified tables when it's all over.
Simplify the problem as much as possible. For example, if your real problem involves 8 columns, try to post an issue affecting only 2 or 3 columns.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
2766124 wrote:
Hi guys,.
I have a custom table
What is a custom table? How is it different from a regular table?
that must be updated in a table source 'abc ';
I have to update 8 fields of 'abc', based on five keys corresponding between custom and abc records
Here is the syntax I have a suite please let me know the effective way to do this.
I get the error message for the syntax below. I think that 'FROM' keyword must not be use GTA?
update of custom table one
Set a.field1 = b.field1, a.field2 = b.field2, a.field3 = b.field3
ABC b
where value = ' 05 "
An example of the correct syntax for the use of a subquery in an UPDATE statement is:
UPDATE one
SET (Field1, Field2, Field2) =
(SELECT field1, Field2, field3
ABC
WHERE value = ' 05 "
);
This is a correct syntax, but I don't know if this will do exactly what you want, because I don't know exactly what you want.
FUSION is often easier and sometimes more effective than updated.
-
Casting table PL/SQL for the type of existing table and back ref cursor
Hello
I have the problem of casting a pl/sql table for the type of an existing table and turning the ref cursor to the application. Casting a ref cursor back and number of pl/sql table works well.
Declarant
< strong > TYPE type_table_name IS TABLE OF THE package_name.table_name%ROWTYPE; < facilities >
within the stored procedure, fill in a table of this type temp_table_name and returning the ref cursor help
< strong > results OPEN to SELECT * FROM TABLE (CAST (temp_table_name AS type_table_name)); < facilities >
generates an error. type_table_name is unknown in this distribution. According to me, this happens because of the declaration of the type locally.
Statement type_table_name inside the package specification does not work neither. Incredible, cast to the said dbms_sql.number_table to specify ref cursor back and dbms_sql package works very well!
< strong > CREATE TYPE type_table_name IS TABLE OF THE package_name.table_name%ROWTYPE; < facilities > deals without any error but creates an invalid type complain a reference to package_name.table_name
I don't want to declare every column in the table in type_table_name, because any change the table_name table would result in an inconsistent type_table_name.
Thanks in advance!
Edited by: user6014545 the 20.10.2008 01:04In any case you are right that there is a problem around anchorage (or maintaining) types of objects persistent to match the table structures, they may represent.
In the case you describe, you might be better off just open the refcursor immediately the using one of the techniques described in the http://www.williamrobertson.net/documents/comma-separated.html to manage the delimited list.
In the more general case where the line of treatment is necessary, you may make the pipeline functions.
Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production SQL> CREATE TABLE table_name 2 AS 3 SELECT ename column_name 4 FROM emps; Table created. SQL> CREATE OR REPLACE PACKAGE package_name 2 AS 3 TYPE type_name IS TABLE OF table_name%ROWTYPE; 4 5 FUNCTION function_name_pipelined ( 6 parameter_name IN VARCHAR2) 7 RETURN type_name PIPELINED; 8 9 FUNCTION function_name_refcursor ( 10 parameter_name IN VARCHAR2) 11 RETURN sys_refcursor; 12 END package_name; 13 / Package created. SQL> CREATE OR REPLACE PACKAGE BODY package_name 2 AS 3 FUNCTION function_name_pipelined ( 4 parameter_name IN VARCHAR2) 5 RETURN type_name PIPELINED 6 IS 7 BEGIN 8 FOR record_name IN ( 9 SELECT table_alias.* 10 FROM table_name table_alias 11 WHERE table_alias.column_name LIKE parameter_name) LOOP 12 13 PIPE ROW (record_name); 14 END LOOP; 15 16 RETURN; 17 END function_name_pipelined; 18 19 FUNCTION function_name_refcursor ( 20 parameter_name IN VARCHAR2) 21 RETURN sys_refcursor 22 IS 23 variable_name sys_refcursor; 24 BEGIN 25 OPEN variable_name FOR 26 SELECT table_alias.* 27 FROM TABLE (package_name.function_name_pipelined ( 28 parameter_name)) table_alias; 29 30 RETURN variable_name; 31 END function_name_refcursor; 32 END package_name; 33 / Package body created. SQL> VARIABLE variable_name REFCURSOR; SQL> SET AUTOPRINT ON; SQL> BEGIN 2 :variable_name := package_name.function_name_refcursor ('%A%'); 3 END; 4 / PL/SQL procedure successfully completed. COLUMN_NAME ----------- ALLEN WARD MARTIN BLAKE CLARK ADAMS JAMES 7 rows selected. SQL> ALTER TABLE table_name ADD (new_column_name VARCHAR2 (1) DEFAULT 'X'); Table altered. SQL> BEGIN 2 :variable_name := package_name.function_name_refcursor ('%A%'); 3 END; 4 / PL/SQL procedure successfully completed. COLUMN_NAME NEW_COLUMN_NAME ----------- --------------- ALLEN X WARD X MARTIN X BLAKE X CLARK X ADAMS X JAMES X 7 rows selected. SQL> -
How can I display the table of contents for the iPod Touch to 6
When I opened first of all iPod Touch Users' Guide, I used the table of contents (TOC) to locate and access sections in the manual. But, after looking through the manual for awhile, I tried to return to the table of contents, but it wasn't there! I have tried various things to see if the table of contents are being hidden, or if in some way, it has been deleted. Anyone can shed light on this mysterious event?
What is the version of iBooks that you speak? There is an online version here: https://help.apple.com/ipod-touch/9/ Aha, I see the table of contents on the left disappears if you zoom before or make the narrow window and reappears if zoom you out or make it larger.
TT2
-
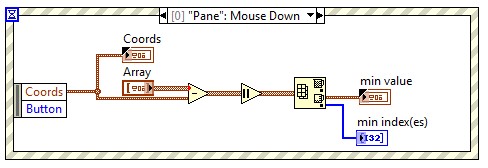
The search in a table 2d-coordinates for the point of click
I'm doing a VI that creates a layer of 2d points on an image imported (as pictured). These points are generated by a Subvi, which simply draws points over and over again (based on the 3 selections of initial angle). All the coordinates of the points are stored in a data feed that is sent to a registry change for other future functions. Each coordinate corresponds to an electrode, labeled 0-255, goes into the lines first (although that could change, but I guess it would be easy to change). Labels are created through 2 loops (as seen in diagram 1).
I would now like to click on a particular point and put it out in a different color, but also an indicator show me what electrode I clicked. I seem to be at a loss on how to do it! I need explore a table 2d-2 groups of the element, where she looks for the line first, then the corresponding column (or vice versa, it is not serious, but just for ease of understanding, let's say she is looking X first, where the columns first) and compare them to 2 elements (the mouse click coordinates).
Here's what I've done so far. I need to search for the function in the following way; If find X, look no further columns and select that particular column where the X was found and begins to look for the values Y and and then stops when the value of Y is. Once the two values are found, take these out of the loops and throw them in a cluster and the function of drawing lots.
Thank you!
p.s. in case anyone is wondering why I have the function "in the range" in there, it's so that the user does not have to be exact pixel
 this allows the user to click within 2 pixels of the coordinate of the point.
this allows the user to click within 2 pixels of the coordinate of the point.Hi Daniel!
What do you think of this approach?
We subtract just the mouse coordinates in the coordinated range 2D (Array stores the coordinates of the points on the image), the absolute value and look for the minimum. X and y the selected point index is returned in minutes or the index. You can replicate the fuction "in range" by ensuring min value is not too high.
With regard to:
Andrew Valko
NOR Hungary
-
Name of the table to query for the time window of work
I am trying to build a query for a list of jobs in tide. Anyone know what table is for the time window? Please notify. Thank you.
Hi Warren, according to me, this is the jobdtl table.
jobdtl_fromtm and jobdtl_untiltm
-
java.sql.SQLException: JDBC LLR, table check failed for the table ' WL_LLR_ADMI
Hello
I am trying to install OSB in a different domain. I already have a suite of soa running.
This is the directory structure
Middleware/user_projects/domains
(a) soa_domain
(b) osb_domain
Who, from the administration server for the BSO, I get error below.
Error: -.
< server failed. Reason: Last forest resource [JTAExceptions:119002] failed during initialization. The server cannot start unless all configured logging last resource (LLRs) initialize. Fault reason:
javax.transaction.SystemException: weblogic.transaction.loggingresource.LoggingResourceException: java.sql.SQLException: check table JDBC LLR, failed for the table "WL_LLR_ADMINSERVER", line ' JDBC LLR field / / server ' record had an unexpected value ' soa_domain / / AdminServer' expected ' osb_domain / / AdminServer'* ONLY the domain and the server that creates a table original LLR can access *.
I see the solution in https://blogs.oracle.com/epc/entry/technical_table_verify_failed_for but I have no doubt here.
When I run
Select RECORDSTR in the WL_LLR_ADMINSERVER where
XIDSTR = "field of LLR JDBC / / server ';"
I get the result like-> soa_domain / / AdminServer
If I change it to osb_domain / / this AdminServer, will affect my soa_domain server... ? Please advice
Published by: user10720442 on December 11, 2012 11:54Hello
There are two possible solutions to this problem:
Solution 1:
To solve this problem reconfigures the basic information database of Point differently for each domain, if you have more than one domain. That, to change the port of the database and the name below two files in the field
In the setDomainEnv.cmd (or .sh) file inside directory change DOMAIN_HOME/bin Point base port number and the name of the comic.
Set POINTBASE_PORT = 9094
Set POINTBASE_DBNAME = weblogic_eval2JDBC:PointBase:server://localhost:9094 / weblogic_eval2
In the file wlsbjmsrpDataSource - jdbc.xml inside change DOMAIN_HOME/config/jdbc directory under entries with port of pointbase database updated and the name (this will be in two places in the file).
Solution 2:
If the domain name has been changed and do not want to change the database properties, then an update to the WL_LLR_ADMINSERVER table is possible:
that is to say:
Update SCHEMA_SAMPLE. Set RECORDSTR = WL_LLR_ADMINSERVER ' base_domain / / AdminServer' where XIDSTR = "JDBC LLR field / / server ';"Kind regards
Kal -
Why does my merged project display 2 table of contents for the first project/start?
I use RH8 and windows 7 and generate Webhelp
When I generate my merged project I get 2 table of contents of the first project. When I click on other merged projects disappears from the table of contents 2nd and all is well.
Also, I can't return to my first / start window.
Here is what I created:
Main folder
Parent
Children
Project 1 (this is my start/welcome page)
Project 2
Project 3
Project 4
My Parent file in the table of contents contains new projects and looks like this:
Project 1
Project 2
Project 3
Project 4
The only section in the parent file is empty and I put in the following redirection according to the instructions on the site grainge:
"< meta http-equiv ="refresh"content="0;url=./mergedprojects/project1/project1.htm "/ >
How stop the TOC 2 on the first page of the project start and how do I display so I can access it later.
Any help is appreciated.
Pat
The start page is not a topic. This is what opens the three components and the topic you see in that is the default theme.
By default, HR takes the name of your project and which initially applies the page so if your project is called redrabbit, the start page will be redrabbit.htm.
Many authors can call the redrabbit of the theme by default as it is the name of the project and it seems logical.
Problem is when the wizard attempts to use it as the default value for the start page, the name is used for the number 1 is added.
This means that you end up with redrabbit and redrabbit1. If you look in the wizard, you will see the name of the start page, first on the ground. You do not redirect, that redirect you to the default topic that is longer than down in the page of the wizard. The index is that the field is called the default theme.
See www.grainge.org for creating tips and RoboHelp
-
Table of contents for the issue of the ePub
InDesign CS5; Mac OS 10.6.5
When I export my TOC document to ePub, do not show the table of contents, only the last two pages with text and an image.
The table of contents defined paragraph styles. I think I have my correct export settings.
Help to isolate this problem is appreciated.
Note: Display of other documents in the book via ePub export display correctly, although the book must refine to ePub format.
Also, when I tried to export the entire book through the book panel, InDesign starts export, but no activity in the progress bar. I have to force quit to get out of the endless loop. Then when I restart InDesign, Untitled files begin to open, 10, 20 and so on. So, I have to manually close each file.
I suspect that OCD is causing this issue.
Yes, that's correct. Once I've re-recorded old files "CS" in the new version, including the file book. Everything worked well.
And I don't mean just making a backup (thinking that will result in savings in the current version) I want to talk about a backup - as in another folder in a different location... ie you Office
-
Using OBA for 2 sources (Siebel and EBS)
Hello
We have OBIA for EBS - supply chain in place (with a certain custom) and it is already in Production. Now, we are implementing OBIA for Siebel.
Thus, for the first time, we expect run a FULL extract of Siebel. Then, we noticed that the two system uses a table of commom (such as W_PRODUCT_D). Unfortunally, we on EBS, every product and price list. On Siebel, we have same information replicated.
If we run a FULL clip, we will lose the EBS product data, I guess. But if we run an additional excerpt, I think we will produce duplicate on the W_PRODUCT_D. Is this right?
How is the best way to work?
Any help will be great!
Kind regardsHi Ohara,
With regard to the RPD:
I'm not completely sure if you need to change the SPR...
If you can ensure that users will always report on a combination of dimensions with facts, there is no need to filter on datasource_num. It is because all responsible facts of Siebel will be related to dimension values responsible for Siebel and all responsible facts from eBS will be related to loaded from eBS dimension values. At least, this is how it is supposed to work, please allow sufficient time to test this really well.
However, ' just to be sure"you can create filters to model business in security groups so that all"Siebel-users"will see the Siebel data and vice versa.
With regard to the CAD:
I think that the most ideal would be to combine all the disciplines to be load in an execution Plan. This can be done if eBS and Siebel extraction can be achieved in the same time interval. In this way, the staging tables will fill in 1 or 2 sources, but the SILOS mappings should only be run once.
With regard to the most interesting things (scenario 1 ;))):
You will need a unique identifier of a product / other who is present in the two source systems in order to implement the correspondence in the BAW. Please do not use the literal comparissons on names etc. Once you have this identifier, you can change the LKP operators in fact mapplets and/or reusable LKP operators to use this identifier to retrieve the wid of the dimension, instead of integration_id and datasource_num.
Good luck!
Kind regards
MarcoPublished by: m.siliakus on February 22, 2011 08:58
-
Patch of the DST for the ebs DB Upgrade
Hi all
I'm upgrading ebs R12.1.3 database 11.2.0.4 11.2.0.3 on Sun (sparc) OS. The source DB contains the DST patch 14, do I have to apply the latest patch for the DST as part of the upgrade or I'm good with it?
SQL > SELECT version FROM v$ timezone_file;
Version
----------
14
Thank you!
Yes, these patches are necessary for env EBS.
https://blogs.Oracle.com/stevenChan/entry/dstv25_ebs
Thank you
Hussein
-
Audit Table and triggers for the object table 10g
Hello
I am trying to create an audit table and related triggers based on a table of objects.
I have a table called payruns.
created by this statement:
CREATE TABLE payruns to payrun_o;
I intend on creating a table of audit created by statement payruns_audit
CREATE TABLE payruns_audit)
payrun_old PAYRUN_O NOT NULL,
action VARCHAR2 (1).
default user user_resp VARCHAR2 (32) NOT NULL,
action_date date default sysdate NOT NULL);
A trigger is needed to maintain the tabel of audit update
The trigger code would be something like:
CREATE OR REPLACE TRIGGER payruns_br_ud
FRONT
INSERT OR UPDATE ON payruns FOR EACH ROW
DECLARE
lv_old_payrun payrun_o;
lv_action VARCHAR2 (1);
BEGIN
If the insertion
lv_action: = 'I ';
on the other
lv_action: = 'U ';
end if;
SELECT: old.value (pr)
IN lv_old_payrun
OF payruns pr
WHERE pr.pr_id =: old.pr_id;
INSERT INTO payruns_audit (payrun_old,
action,
user_resp,
action_date)
VALUES (lv_old_payrun,
lv_action,
user,
SYSDATE);
END;
However: old.value does not work.
Could you tell me about the correct syntax.
Thank you!Hi Alistair - try to use OBJECT_VALUE.
CREATE TABLE payruns_audit)
payrun_old PAYRUN_O NOT NULL,
payrun_new PAYRUN_O NOT NULL,
action VARCHAR2 (1).
default user user_resp VARCHAR2 (32) NOT NULL,
action_date date default sysdate NOT NULL);CREATE OR REPLACE TRIGGER payruns_after_ud
AFTER the update on payruns
FOR EACH LINE
DECLARE
lv_action VARCHAR2 (1);
BEGIN
IF the insertion and THEN lv_action: = 'I ';
ANOTHER lv_action: = 'U ';
END IF;INSERT INTO payruns_audit (payrun_old, payrun_new, action, user_resp, action_date)
VALUES (: OLD.) OBJECT_VALUE,: NEW. OBJECT_VALUE, lv_action, USER, SYSDATE);
END payruns_after_ud;Cheers, Shane.
-
tables as input for the shared library function
I played with the call of LV VI using matlab.
So I built a simple VI which returns an integer as input and multiply it by 10, I then put in a shared library and named it MATLAB - well.
Now, I tried to do the same thing with a table - I want to send a picture to the VI and multiplied it by 10, but when I build the .h file, it seems that the function expects get table of entry AND exit of table as inputs.
so, how I can build a shared library VI who gets an array (of a constant size if this is important) and multiply it by 10?
Thank you!
A function in a DLL can only return a scalar value, not a table, no matter what languages are used. To return an array, instead calling it allocates the array pass a reference to the DLL and then after the function called the referenced table table contains the new data. This is why there are two parameters - the input array (actually a pointer to it) and a pointer (reference) to the output array. You must change your code in MATLAB, there is nothing you can do about it in LabVIEW. EDIT: Also note that it allows to re-use of the input as an output table, optionally passing a reference only to the table of entry and then by changing that. You can do it in LabVIEW by configuring the setting table as input and output.
-
Table of contents for the edition of ePub paragraph style
I am trying to figure if InDesign can allow us to the editor the dynamic table of contents. What we have is essentially the following:
Chapter number (single paragraph style)
Chapter title (single paragraph style)
First paragraph (single paragraph style)
We want that the ToC that gets pulled up in an eBook reader to show this:
Chapter 1: Chapter title
Chapter 2: Chapter title
At present, only InDesign appears to export each as a specific paragraph style, without setting them on the same line side by side. We're stuck with:
Chapter 1
Chapter title
Chapter 2
Chapter title
Does anyone know of a way to export the ePub is what we want rather than this broken hirarchically way?
There is no good way to do it. We must either go to the ePub after export, or change the style, so there's a return between the chapter number and chapter title instead of a return. The second option will involve completely restyling, and get in there colon will be delicate.
-
Resouce allocation for the EBS Modules
Hi Bashar and ALL,
EBS R12.2.4
RHEL 6.5
It is safe to assume that all the modules in EBS have equal footing regarding the consumption of resources?
For example:
If I have 50 users of GL, they consume CPU/MEMORY/IO as much as consumption of 50 users to AP?
Or are there some modules in EBS which is very resource-intensive and hungry who need a special allowance of more CPU and MEMORY?
Thank you very much
JC
Hello
There is no rule for these assumptions.
The allocation of resources depends on the type of components of the application (forms or OFA), complexity of open forms and the type of activity (data entry, create accountants, generation of reports, etc..)
For example, running a report that runs on the data set can cause a load such as 50 users doing the data entry.
Kind regards
Bashar

Maybe you are looking for
-
Miss me my calendar after update to Thunderbird and search, I have installed the add-on lightning, straightened my program and Calendar tab does not appear. I have years of work and set up reminders and I NEED to recover - please help! I don't know j
-
Win 10 improvement of the non-functional touchpad
Hello, after upgrading to win 10 my touchpad doesn't work at allI tried to find some tools to download, but without success is there a software that could help me?Thank you.My camera is Satellite P50 - A - 13 cPSPMHE
-
WiFi Windows 7 drivers for HP Pavilion 17-f078no
I installed windows 7 instead of the windows pre-installed on my new HP Pavilion 17-f078no 8. Like many others. But I can't find a driver for the wireless network adapter. Where can I find that? The info product said yet what it is on the map, so it
-
P7-1235: helps p7-1235 video card!
Please someone help! I have a p7-1235 and I'm trying to upgrade to a video card to improve game performance. The problem I have is that I can't get a card to work. First of all, I tried XFX r9 270 x without a bit of luck, will not appear. Traded the
-
HOWTO: install Oracle database software in a new oracle home
Hallo,I approach my first upgrade of database Oracle 11.2.0.1 to 11.2.0.4 I want to perform a manual upgrade.The first step (after download and extract the files from the zip in a folder) is "to install the software in a new oracle home.I think that