AESEncryptorEngine and Unicode characters
Hello
I use the AESEncryptorEngine and the AESDecryptorEngine to encrypt and decrypt the normal text strings that were entered by the user into an ActiveAutoTextEditField. The problem is: users who come in non English characters such as Japanese or Chinese may encrypt their messages, but after decryption the characters appear as garbage or they are sometimes a few points mark as '? It seems that line breaks back correctly.
My encryption and decryption methods work well for America Latin characters but not if it is complicated. Maybe someone knows what I'm missing here?
It's the method of encryption:
public static String encrypt(String keyString, String plainText) {
String encryptedText = null;
byte[] keyData = keyString.getBytes();
try {
AESKey key = new AESKey( keyData );
// Now, we want to encrypt the data.
// First, create the encryptor engine that we use for the actual
// encrypting of the data.
AESEncryptorEngine engine = new AESEncryptorEngine( key );
PKCS5FormatterEngine formatterEngine = new PKCS5FormatterEngine(engine);
// Use the byte array output stream to catch the encrypted information.
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
BlockEncryptor encryptor = new BlockEncryptor(formatterEngine, outputStream);
// Encrypt the actual data.
encryptor.write(plainText.getBytes());
// Close the stream.
encryptor.close();
byte[] encryptedData = outputStream.toByteArray();
encryptedText = new String(encryptedData);
} catch (Exception e) {
System.err.println(e.toString());
}
return encryptedText;
}
It's the decryption method:
public static String decrypt(String keyString, String encryptedText) {
String plainText = null;
byte[] keyData = keyString.getBytes();
try {
//remove prefix which indicates this is encrypted text
encryptedText = encryptedText.substring(ENCRYPTION_PREFIX.length());
AESKey key = new AESKey( keyData );
// Now, create the decryptor engine.
AESDecryptorEngine engine = new AESDecryptorEngine( key );
// Create the unformatter engine that will remove any of the padding bytes.
PKCS5UnformatterEngine unformatterEngine = new PKCS5UnformatterEngine(engine);
// Set up an input stream to hand the encrypted data into the block decryptor.
ByteArrayInputStream inputStream = new ByteArrayInputStream(encryptedText.getBytes());
// Create the block decryptor passing in the unformatter engine and the encrypted data.
BlockDecryptor decryptor = new BlockDecryptor(unformatterEngine, inputStream);
byte[] temp = new byte[ 100 ];
DataBuffer buffer = new DataBuffer();
for( ;; ) {
int bytesRead = decryptor.read( temp );
buffer.write( temp, 0, bytesRead );
if( bytesRead < 100 ) {
// We ran out of data.
break;
}
}
inputStream.close();
plainText = new String(buffer.getArray());
} catch (Exception e) {
System.err.println(e.toString());
}
return plainText;
}
PS: I know that for loop in the decryption method is not really nice, but it was the only one that worked for me.
When you do your conversion rate of string/byte, specify an encoding...
plainText.getBytes("UTF-16");
raw text = new String (buffer.getArray (), "UTF-16");
Tags: BlackBerry Developers
Similar Questions
-
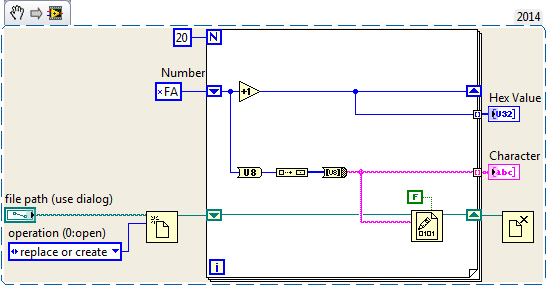
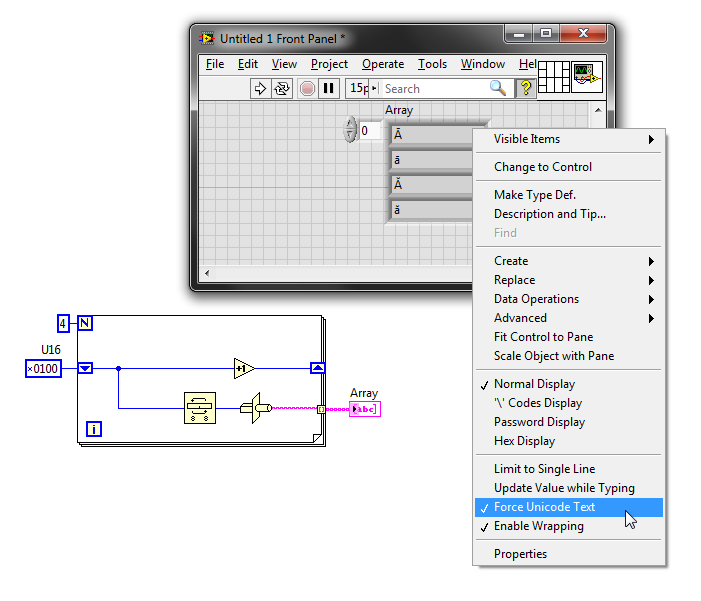
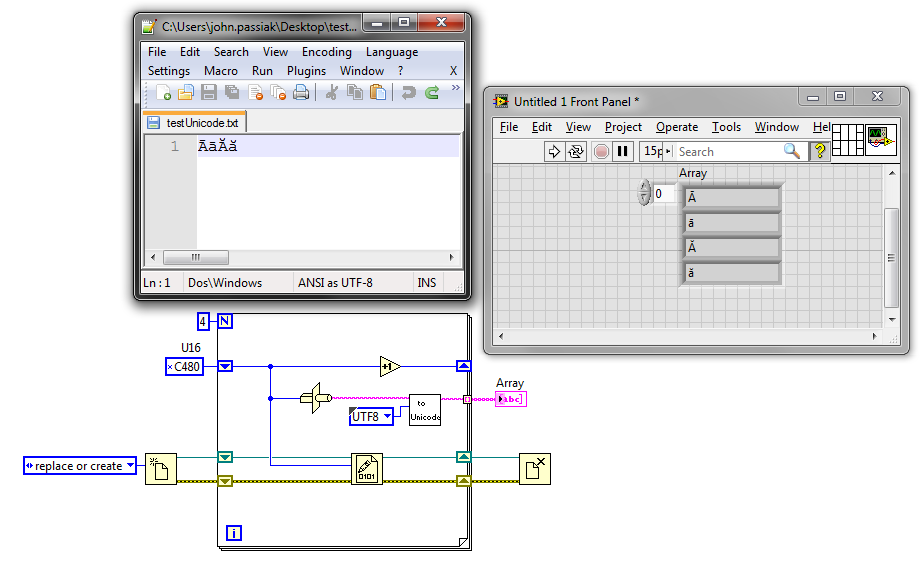
Generate and write unicode characters to file
The characters of genearted seems OK (up to x00FF), but after writing to file these characters and their values are different. Also the characters after 0x00FF are not good.
Any idea?
You should probably give this page than to read a thorough if you relied on the use of Unicode in your application. Here is a relevant excerpt:
ASCII technically only sets a value of 7 bit and can therefore represent 128 different characters, including characters such as the newline (0x0A) and return (0x0D) transport. However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The 128 additional characters in the ASCII range are defined by the code page of the operating system aka "language for programs non - Unicode. For example, on a Western system, Windows uses by default the character set defined by the Windows code page 1252 Windows-1252 is an extension of another commonly known used encoding ISO-8859-1.
Offers Windows-1252 characters up to 0xFF (ÿ) but not something higher to 8-bit (for example no 0x0100). By default, LabVIEW support these uses of 8-bit, multibyte strings characters - only interpretation is based on the current code page selected in the operating system. You can turn on Unicode, the instructions in my first link (this is not supported and can be a little buggy from time to time...) to get the support of multibyte unicode characters to multibyte codepage characters not in the operating system.
Unicode has several encodings, and the bit raw to a character depending on the encoding used. LabVIEW limited unicode support seems to use UTF-16 (little endian) encoding for whatever it will be displayed in the user interface. So to get the characters displayed on the interface user, you must enable unicode (instructions illustrated in my first link) and write the appropriate UTF-16 code:
UTF - 8 is more common and therefore easier to work with outside LabVIEW (e.g. my version of Notepad ++ obviously do not support UTF-16). I usually find myself using UTF-8 for files format strings and convert them to UTF-16 for display in LabVIEW.
Unicode in my first link library has the necessary subVIs to convert between UTF-8 and 'Unicode' (i.e. UTF-16).
Best regards
-
Database Toolbox and Chinese characters
Hi all
I have a problem with a function where users can search inside a Microsoft SQL Server database for a specific entry.
I used the database with the DB tools tool run Query.vi, users can add keyword here for example. 'blue %' inside a control of the chain, then the request is passed to the DB.
(e.g. SELECT field1 FROM TABLE1 WHERE FIELD1 LIKE N 'blue %')
That works very well in the German version.
Now, the application is also used in China. As long as they are looking for ASCII characters everything works fine also. Now, they began to create entries with Chinese characters (which also works), but when they try to pick up some Chinese characters, they do not get a result. (when searching for entries with Chinese AND English characters and search for English characters all works too)
I do not use the Unicode functions, and the database field is an nvarchar.
Unfortunately I don't have a Chinese Version of Windows to do a few tests here.
Anyone an idea what could be the reason (Chinese codepage?) and how to solve this problem?
Thanks and best wishes,
Helmut
LabView 8.5 / Microsoft SQL Server 2008
You can try this test even without changine the code (language of non-unicode programs) page. First change your chain control '-' code display. In the places where the Chinese characters would appear, enter some hexadecimal codes above 7F by fleeing with a '-'. Here are the codes that are traditionally displayed differently depending on the settings of operating system as the language for non-unicode programs.
UPDATE table
Foobar SET = "test\AA\BB\CC\DD."
WHERE the blah - blah
SELECT foobar FROM table WHERE foobar LIKE 'test % '.
The returned string has \AA\BB\CC\DD after test? Now try...
Foobar SELECT FROM table WHERE foobar LIKE '% \AA\BB\CC\DD'
Get something? Try it now with the N prefix...
-
Windows Help explains how to use the character map to copy or drag special characters in Unicode-aware applications. In Vista, it was possible (but heavy) to insert special characters using the keyboard with the method known as Alt-plus, which has only first need to add EnableHexNumpad to the registry *.
y at - it an easier way to insert Unicode characters using only the keyboard newly available in Windows 7? Adds EnableHexNumpad to the still of registry required to use the Alt-Plus mode? Other tips to quickly characters insert Unicode in taking applications support Unicode?
* Register instructions: Add a new string [REG_SZ] named EnableHexNumpad and a value of 1 in HKEY_Current_User/Control Panel/Input Method
Have you tried UnicodeInput? It is a small program that allows you to enter Windows Unicode characters via the keyboard. Works with practically all the applications that I tested. I use it on Vista, so I can't guarantee it will work also on 7...
You can find it at http://www.fileformat.info/tool/unicodeinput/unicodeinput.zip .
Kind regards
-
Japanese and Chinese characters appears in Windows 7
Hello
lately, for some reason, Japanese characters in Windows Explorer refuse to appear. Usually, if I go back, they come back however, it's extremely annoying. No, it's not language packs. I can type and see the characters perfectly on the web pages. But not in Windows in general.Here are some examples:(No. what category to put this in clue..)Thank you.Hello
Here's something you can try to check if it helps.
1. go in Panel.
2. click on clock, language and region - language , and then click modification Date, time or number Formats.
3. click on the tab administration and then select the button settings system change under language of Non-Unicode programs.
4. change in french. Press on apply and ok. Restart the computer and go back to the same location and select Japanese.
Let us know if this helped you.
-
Chinese and Japanese characters are displayed incorrectly in Windows 8.
All Chinese and Japanese characters SOMETIMES appear as squares. He sometimes corrected after I rebooted the system.
I already changed the language of non-unicode as a Chinese (simplified, China) in the region > administrative.The display for my operating system language is English.I heard people say that it will work if I change my Format and location of Chinese/China. I don't want to do that because then my time format is displayed also as Chinese.These combinations of setting working in Win 7.Original title: display of Japanese and Chinese characters as squaresnot sure on the display of Chinese and Japanese, but for just Japanese I found that switching language for non-unicode in Japanese once then back to English (for occasional applications that are not displayed good language) works to display Japanese characters correctly in windows Explorer
-
After effects error: could not convert Unicode characters. (23::46) CS6
Hello I just created a project in AE CC and wanted to also save a version for CS6.
Everything went well but when I tried to open the project in CS6 I received the following error message:
«After effects error: could not convert Unicode characters.» (23::46) »
Does anyone know what this means and how to fix it?
After effects CC is much, much better handling of the characters that are outside the defined character used by the operating system to its current settings of the language. Thus, the file names and paths (and other channels) which operate very well in after effects CC and later may fail with older versions.
For example, if you run your operating system and applications in English and Chinese characters in your file names, After Effects CS6 and earlier will fail, but after effects CC and earlier will succeed.
-
Escaping of unicode characters
I'm trying to percent encode unicode characters (when they come to the top). I just stumbled up to: e
SELECT UTL_URL. Escape ('e') FROM Dual;
Returns: % BF
What I need is: % C3% A9
Is it possible to get in Oracle?
----------------
Moreover, if the 'e' could be turned into a 'e', it would probably be fine.
Published by: Brian Tkatch on July 23, 2012 13:29But if I have to define CHCP, what would be the impact on other things, or how I would use inside a DBMS_SCHEDULER to run the PACKAGE.
You define anything for programs running inside the database server side.
I think you put too much thought into that.
Again, it is a matter of customer. Your application is not based on SQL * Plus, is that?Apply the function on a column of data, not a literal string whose interpretation relies on the NLS page and the code used by the interface.
-
Photoshop cs5 sdk supports filenames with unicode characters?
Hello
For the export module, has the windows sdk supported for filenames containing unicode characters?
Struct ExportRecord in PIExport.h has a filename attribute declared as a char array.
So I doubt if file names containing characters unicode for the export module will be supported.
Thanks in advance,
Spengler.
I check the value of propUnicodeName in PIProperties.h and use the callback property to propertyProcs.
Another option would be to struct SPPlatformFileSpecificationW * fileSpecW; in ReadImageDocumentDesc
-
Tour of Unicode characters to garbage according to the length of the previous text
Hey,.
I wrote a script that creates a bunch of text frames, fill text and styles it.
The problem is, sometimes, unicode characters out as parasites: for example "3 m Blenderm™™" turns into "3ma" ¢ Blenderma "¢."
I was playing around with four text frames to see what causes it, and if I add a line of text in the second frame, all of the following unicode characters turn garbage only if this text line is longer than 6 characters.
If I add a character™ to the first line of the first block of text, then the problem resolves itself.
If someone has encountered something like that?
Let me know if you need more information (my entire script is big enough...)
You shouldn't be gueesing encoding.
You must write the unicode marker or set the encoding of your file:
myFile.encoding = "UTF-8";
Substances
-
Title bar of JFrame is not the display of Arabic and Hebrew characters in Ubuntu 8.04
Hi all
While internationalizing my request in Arabic and Hebrew, I had a problem in these language characters display in the title bar of JFrame. These characters are not displayed in the title bar. I have the application around 30 + languages of internationalization, but the problem occurs only with these two languages very precisely on the Ubuntu OS only. I'm able to display these characters of the language on the buttons and labels throughout the application, but cannot be displayed on the title bar. I don't know where is the problem.
Please suggest me in this regard.
Here is the code example
Thank youimport javax.swing.JFrame; public class LanguageTitleBar { public static void main(String[] args) { JFrame jf = new JFrame(); jf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); //jf.setTitle("\u0633\u0627\u0639\u0629 \u0627\u0644\u062a\u0648\u0642\u0641");//Arabic Text jf.setTitle("\u05e9\u05e2\u05d5\u05df \u05e2\u05e6\u05e8");//Hebrew Text jf.setSize(200,200); jf.setVisible(true); } }
Uday.Would it be something simple? I think that maybe the default font in Ubuntu 8.04 may have the Hebrew or Arabic characters.
If this is it, the fix would be to install the Unicode font more complete a Ubuntu later and have your application to use. Another challenge would be to convince your three users of Ubuntu 8.04 to upgrade. ;)
-Rich
Published by: RichF on November 26, 2010 22:49
do not take into account. I just re-read your first post, and only the title bar does not display the characters. The only special thing about labels and vs of title bar buttons, is that the title bar is owned by the external GUI, Java not directly. Java has an interface with the GUI to set, title bar text that apparently needs some kind of special treatment for Arabic and Hebrew characters. -
Question
I pressed (Control) (offset) when to bet and my characters of Gmail (the full screenshot) reduced to about 25 to 35%. How to restore? I already signed my Gmail account, restarted my computer (Windows XP has) nothing works.'Ctrl + 0' (zero) to restore normal size
-
Tecra A9 - keyboard "unlocks" and bad characters are typed
Keyboard "unlocks" and bad characters are typed using the QWERTY layout. Have tried to change the language options with some success in the short term.
However changes in languages quickly becomes "unlocked".
How can I solve this problem?Advice please.
Thanks, MikeHello
To be honest, I don't know what you're talking about.
If your keyboard does not match the language of the keyboard, then you should change that and should add new language.In this case, you will be able to switch between languages, using SHIFT + ALT shortcuts
Of course, you can also remove the other languages. In this case, the SHIFT + ALT will not function.
-
M/S using wireless keyboard 800 and some characters are not displayed correctly
Have just connected a new wireless keyboard M/S 800, and some characters are not displayed correctly. For example, I get "when @ (update 2) is pressed on the keyboard and the £ runs it shift 3.» Am currently using XP SP3.
No problems with my original keyboard, Wired.
Hi simoncd.
What is your location. The reason why I ask this is that your keyboard is set to the standard UK layout. Looks like you have the keyboard for the U.S. keyboard layout. Shift + 2 is the "on the UK keyboard, @ on the U.S. keyboard."
To change the keyboard settings you must go to "Control Panel", then "regional and language options". The first page allows you to set the number format and character relative to your location and also set the location. Check these and modify accordingly so badly. You want to then go to the second 'languages' tab and click on the button "Details". Here you can set the default keyboard. This changes if necessary. This should, hopefully restore your keyboard to the presentation that you want.
-
Problem with cfhtmltopdf and special characters
How can I fix cfhtmltopdf showing '? ' for special characters "1/2", "3/4", "•"? We have 11,0,07,296330 Standard in ColdFusion Server installed.
After further research and discussed with our system/DBA administrator, we suspected that he needed the CF11 Server JVM setting. We have added '-Dfile.encoding = utf8 "to java.args in ShadoMX/util/Flex/SDK/bin/jvm.config and special characters displayed correctly.

{kind=link}
{kind=link}
{kind=link}
Maybe you are looking for
-
Hello When you try to start, the screen displays simply; "NTLDR is missing". Press Ctrl + Alt + Del When I do that I'm just going through a loop. I understand that this error message is possiable linked to a drive problem, can you please help?
-
Tecra M5: How auto to activate the secondary monitor?
Hello When I my Tecra M5 with full-screen dock and turn it on, I would like that it allows to automatically activate the secondary monitor and set it on the primary monitor. Currently, when home he doesn't - and I have to manually enable the second m
-
Slowness of the iconic W801 in windows 8.1
I am facing a lot of slowness in the Iconia 801 after upgrade to 8.1 windows, especially when I'm surfing youtube. Almost every day I have to restart tablet 1 or 2 times. I checked my Tablet acer and asus tablet at the same internet connection and fo
-
I want to create a backup of my computer. It is not a copy dinky of my photos and important documents: I would like to create an exact copy of everything on my computer (drivers, programs, etc.) so that, in a sense, I have two computers identical (we
-
Cannot get active document when the user clicks on the document in Adobe FM 2015.
I am facing the following problem:I have a timer in my application that strikes several times after 2 seconds to get the name of the current document (if there is).If the user selects text (the click of the mouse down) of the current document in Adob