ASM diskgroup space do not free themselves after RMAN archivelog delete
Version Infra grid: 11.2.0.4
DB version: 11.2.0.4
OS: Oracle Linux 6.4
Storage: Enterprise-class storage (EMC VMAX)
We are in the Bank we have a database of CARS of Production 2 nodes very critical.
Newspaper archives are stored in ARCH_DG diskgroup. Because of the unexpectedly heavy workload, our diskgroup ARCH_DG became full and we got the usual error
ORA-00257: archiver error. Connect internal only, until this just released.
To wear the DB back to business quickly, I tried to delete the old archive logs more than 1 day of the diskgroup first using the following command
RMAN > delete noprompt archivelog until ' SYSDATE-1';
So, I started to see the following message
RECID = STAMP 19807 = 849396325 name=+ARCH_DG/bsoaprd/archivelog/2014_06_04/thread_2_seq_10066.331.849396309 archived log file
Delete archived log
RECID = STAMP 19809 = 849396940 name=+ARCH_DG/bsoaprd/archivelog/2014_06_04/thread_2_seq_10067.274.849396925 archived log file
Delete archived log
name=+ARCH_DG/bsoaprd/archivelog/2014_06_04/thread_2_seq_10068.341.849397529 RECID archived log file = 19810 STAMP = 849397543
Delete archived log
name=+ARCH_DG/bsoaprd/archivelog/2014_06_04/thread_2_seq_10069.298.849398167 RECID archived log file = 19812 STAMP = 849398182
Delete archived log
RECID = STAMP 19813 = 849398806 name=+ARCH_DG/bsoaprd/archivelog/2014_06_05/thread_2_seq_10070.317.849398783 archived log file
Delete archived log
name=+ARCH_DG/bsoaprd/archivelog/2014_06_05/thread_2_seq_10071.342.849399327 RECID archived log file = 19814 STAMP = 849399337
Although I could see messages "deleted archived newspaper" as stated above there are 2 inconsistencies (odd behavior)
1 inconsistency. Not a single byte released upwards of archive diskgroup. Each log archiving is 4 GB in size. I got "journal archived deleted" message at least 25 archived log files. For example, 100 GB should have been released.
The diskgroup to archive has remained at 99.9% as shown below and the DB was inaccessible.
SQL > select name,.
Round(total_mb/1024,2) Total_GB.
Round(free_mb/1024,2) Free_GB.
free_mb/total_mb * 100 "% free"
ABS ((free_mb/total_mb*100)-100) '% complete '.
v $ asm_diskgroup; 2 3 4 5 6
NAME TOTAL_GB FREE_GB % free full
------------------------------ ---------- ---------- ---------- ------------
ARCH_DG 1000.78 99.9223633.077636719
DATA_DG 10000.02 1188.19 11.8818616 88.1181384
OCR_VOTE_DG 12 11.09 92.4623525 7.53764754
< snipped >
Inconsistency2. The number of available archived newspapers remained unchanged. He was always showing 301
SQL > select count (*) from v$ archived_log where status = 'A ';
COUNT (*)
----------
301
RMAN later > remove obsolete; command removed 17 archived newspapers.
This means that 17 x 4 = 68 GB should have been released.
But Diskgroup of free space and the County of v$ archived_log.status = 'A' is unchanged, as mentioned above.
, Of ASMCMD, I deleted manually a full archive directory connects using rm-rf command.
Even after running rm - rf on a whole directory full of archived newspaper space was not released and we always receive ""ORA-00257: archiver error '. "
So, we had to shoot down the cluster using "stop crsctl crs. After the cluster has been raised using 'crsctl start crs' on both nodes,
space has been freed up, and the DB became accessible.
I wonder why the ASM diskgroup space was not release despite the removal of the archive logs. Are the 1 & 2 above mentioned inconsistencies caused by something handle to open the file ?
Hello
Please run command you at the level of the ASM, below
SQL > alter diskgroup
-At the end of the same thing, run below command and enable it to perform SQL > alter diskgroup
-To validate the space $ asmcmd Pei lsdg Kind regards
Loriette
Tags: Database
Similar Questions
-
Delete the trc on udump/bdump: device (disk) space is not free data
Hello
We have a database that throws a lot error ORA-00060 (deadlock detected). In fact, it is always due to poor design of the application that is running on the database.
The tracefiles in the directory... / udump become enormous. But when remove us these files from space on the device/system files is still occupied by oracle. My question now is:
-> which is expected behavior?
When bounce us the database space on the file system is released again...
Any help will be appreciated...
database version: 10.2.0.3.0
OS-system: HP - UX (Intel Itanium 11.23)
Rgds
JHYou know who trial (his) have a file open for your deleted file descriptor.
If this isn't a trial background Oracle that has a file open file descriptor and then kill the process and the space will be recovered.I'm not a unix guru but found something on the internet that may be useful:
===========================================================
A convenient way to iterate through each process descriptors of files is to just run a loop simple shell, its replacement by your particular arguments of the ps, as version:# for x in the host ' ps - ef | AWK ' {print $2} "; do ls $ / proc / x / fd; fact
===========================================================
-
vSphere not showing do not free space after deletion
Hello
We have ESXi clocked at our remote data center. I recently needed to free up space on the data store, so I used the tool FastSCP remove one VM folders, as I could find no way to do it using vSphere. It seems only to remove no problem, and the deleted folder no longer displays in the view FastSCP or through the vSphere client. But in vSphere, the figure of the free space has not changed. Are there any other required step that I neglected to find that space?
Thank you
vSphere client-> configuration-> storage-> refresh?
vcbMC - 1.0.6 Beta
Lite vcbMC - 1.0.7
-
drop partition not increasing not free space in dba_free_spaces
I'm using Oracle 11.2.0.3.
I had a script that droped from the partitions of a table that should have fallen close to 30 GB of data. We have the data and index tablespace.
Dba_free_space request showed no change data tablespace. However, the tablespace index increased in free space.
I use following command to delete the partitionselect sum(bytes / (1024 * 1024 * 1024)) "Size (GB)" from dba_free_space where tablespace_name ='&tbs_name'
What should be done to increase the free space reported for the tablespace after drop partition?ALTER TABLE table_name DROP PARTITION "partition_name" UPDATE GLOBAL INDEXES;
Thanks for the time.>
http://docs.Oracle.com/CD/E11882_01/server.112/e26088/statements_3001.htm#i2131064ALTER TABLE table_name DROP PARTITION 'nom_partition' drop storage UPDATE GLOBAL INDEXES
>
Incorrect answer - DROP of STORAGE option applies to TRUNCATE the PARTITION not to DROP as the doc explains. A simple test that will confirm.alter table emp_part_test drop partition sys_p341 drop storage ORA-14048: a partition maintenance operation may not be combined with other operations -
The ASM diskgroup in exadata space question
All,
I have an environment exadata 1 CCR node with 3 knots of strorage.
My RECO ASM diskgroup is constantly showing the problems of space... Always higher than 80%.
I just want to get a Board if I can remove mirroring and recover the space... Even though I know that the result of the deletion of the mirroring...
Can I reduce the diskgroup RECO and create an another diskgroup?
I want just a few ideas to do this without great risk involved...You may want to consider these MOS notes for more information on resizing the griddisks:
Resize diskgroup without downtime to Exadata (Doc ID 1272569.1)
How to resize the disk drive/grid ASM in environment Exadata (Doc ID 1245494.1)As others have mentioned, there is no way to change the level of redundancy in ASM, so you need to delete and re-create the diskgroup if you want to change to redundancy. We strongly discourage the use of EXTERNAL with Exadata redundancy.
-
Canvio 500 GB is not free space
I own Canvio 500 GB external HARD drive
When I delete sonething, space will not grow.
for example:
I got 70 gb space.
I deleted a 3.5 GB file.
free space is always 70 GB.How can I solve this problem?
Thank you.In my opinion you did not check properly the available space.
Where the files have been deleted from the external HARD drive, I recommend you refresh the connection of drive HARD just to check if the available space would be indicated correctly.Disconnect the external DRIVE of the laptop drive and plug it in again. Go to the properties of the HARD drive and check the available disk space
-
I use creative cloud in order to download the trial of Photoshop on my pc but this error:-Instillation failed. Not enough disk space. Please free up space on C and try again (-30)
I entered the settings of cloud and told to download for my largest drive E (which it fine for lightroom) but it only downloads on drive C (small disk almost full) for Photoshop. I missed something or is this a bug?
Thanks in advance
Shared resources and temporary files will be stored on your primary drive. If a lack of disk space prevents installation then make sure you have enough space on the main drive for temporary files and installation files extracted to be placed.
Guinot
-
The Pro Adobe bought, downloaded the file (with 1, 67MB) on laptop with OS Win8. When you try to install (my memory C: 2.39 GB free) the file, Adobe dialog says "the computer memory space is not enough. This is ridiculous. What can I do?
Just click on the link acrobat XI and download download Acrobat pro products, acrobat XI | Standard, Pro | XI, X
-
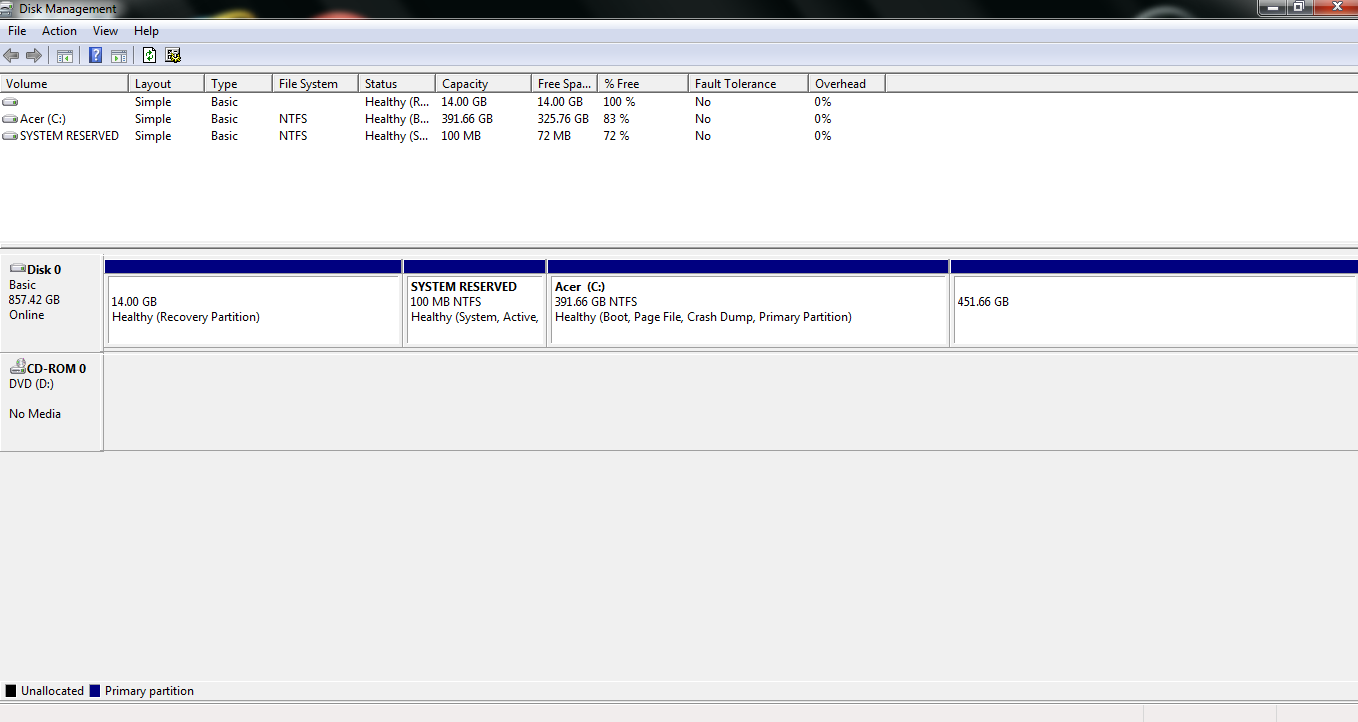
Unallocated space is not visible in disk management
Hello
So I dropped my volume of the C: drive of 20480 KB, and after it decreases, it was not visible as long as the space that is not allocated. At this point, my C: disk space has fallen 20 GB, and yet the unallocated space was not visible in disk management. So, I tried to reduce it again but the same problem occurred. I tried to refresh the disk management, and unallocated space appear. I tried to restart my computer, it does not appear. Initially, I got appx. 450 GB of space on the C: drive, but now I 391,66 Go.The link below is a screenshot of disk management window:
http://gyazo.com/af8c09e4e0510d4fe96c23a89041a0cf.PNGI have no idea what to do, so please help solve me this problem.
-Partition management utilities-
Partition Wizard Home Edition:
http://www.partitionwizard.com/free-partition-manager.html
Note: There is also a CD bootable or versions of the bootable Flash drive:
http://www.partitionwizard.com/Partition-Wizard-bootable-CD.html
http://www.partitionwizard.com/bootable-Flash-drive.html
Among the features and functions: create partition, Delete partition, format partition,.
Resizing a partition, Move partitions, Partition recovery after an accidental deletion,
Convert the partition, partition Explore, Hide partition,
Change the drive letter, a partition active Set, Explorer (content display) of the partition.
Note: To complete any task use the "Pending Operations" box at the bottom left.Alternative to Partition Wizard (a bit easier to use, but Partition Wizard and EASUS have almost identical user interfaces)
EASEUS Partition Master Home Edition (free):
http://www.partition-tool.com/
Partition software ALL-IN-ONE and the most convenient hard disk partition manager Kit
Includes Partition Manager, Disk & Partition copy Wizard and Partition MBR and GUID partition GPT disk recovery Wizard (table) on Windows 2000, XP, Vista, Windows 7 and Windows Server 2000/2003/2008 (32-bit and 64-bit).
It allows users to resize/move Partition, drive system extend, copy Disk & Partition, Partition merge, Split Partition, redistribute free space, convert dynamic disk, Partition Recovery and much more.J W Stuart: http://www.pagestart.com
-
Re: our new X 3 machines (in the data center, not yet installed).
I know that some of these was kind of covered in the previous thread on DBFS. However, I have a little different issues...
I understand that the DBFS ASM diskgroup is mandatory and that, due to the nature of how calculated its size, the ACS consultants set to its minimum size. However, is it possible (preferably at configuration time) increase the ASM diskgroup? Or is it meant to be a size defined, anything?
Oracle, told me that I could put newspapers Flashback in DBFS ASM diskgroup (as long as I don't configure DBFS to use, of course). I don't know that I've read that Flashback Logs MUST be put in the db_recovery_file_dest (fast recovery or RECO diskgroup area). Anyone used DBFS (ASM diskgroup) for such storage? I know that this is not IDEAL given the fact, that it won't spread across all storage cells, but I'm trying to find a way to separate newspapers archive logs Flashback as we monitor the location of the log archiving for the use of space (we get an alert if it becomes too full and automatically kick off an archivelog backup/purge at a certain level of use).
Mark
Spinning two first records on each cell contains a partition of 29 GB in size with the operating system. The other 10 contain rather a GridDisk 29 GB size where the diskgroup DBFS_DG is built. In other words: DBFS_DG The diskgroup is spreading through all the cells, but only on 10 discs (not 12 as DATA and RECO) on each cell.
In this way, the GridDisks that make up DATA and RECO can be the same size on all readers of spinning. And the diskgroup DBFS_DG consume about 300 GB on each cell for this reason, which can not be changed reasonably, I guess.
You can set DB_RECOVERY_FILE_DEST = '+ DBFS_DG' and turn on Flashback Database, so that Flashback Logs are generated, even if you set LOG_ARCHIVE_DEST_1 in the diskgroup RECO, so that Archivelogs get stored there. And with RMAN backups, you specify the FORMAT '+ RECCE' to get the backups in the recovery area (DBFS_DG in this example).
Kind regards
Uwe Hesse
-
Where's my space that I free'd upward?
We Vsphere 4.0 Update 2. We have a San with a couple of volumes via NFS configuration to store VMDK files and such and also a volume of config to store the appropriate files. I'm looking through these data storages and try to clean them. That is the problem. On my 1st volume, I had originally 104,13 GB of free space. I have advanced and deleted a folder on this volume however is the total space was 19 GB. After he deleted off this volume I then looked at the free space again and it really happened to 103,85 GB of free space. Where that storage is? Why at - it go down? I have to do something else to actually get this empty storage? Thanks for the help.
Depends on the SAN. Some remove a background, so when you delete the files, the files are NOT actually removed, the space is marked for REUSE. Same thing with your player to Windows, but Windows is smart enough to know that the files marked as reuse are too complicated for an end user, so it must claim it as free.
Nothing is actually deleted, this has been a scourge for many years. He gets just reused or marked for reused. This is how it works in general.
Worldwide VMFS and SAN you don't want what high IO associated with files being removed from the volume, or NFS, as well, so he gets slowly recovered over time. If you check in a few hours, it should go more... If not maybe what SAN is just mark the files as missing, and he'll use them again.
-
Why ASM isn't down a disk (LUN) after that it disconnects during a period?
Version grid: 11.2
By default, ASM descends a hours MON 3.6 after it goes / taken offline. This can be delayed by using DISK_REPAIR_TIME. But, why oracle is no in the first place? Can not wait until the storage team solves the problem?Hi GarryB,
While a disc is set to offline, you have not fully mirrored. (Given that the blocks on the disk are not remirrored while disk is offline).
Now leave a disc in another FG fail too... You may lose data.So choose the repair disk timer correctly is not as simple as that. The exadata, the time is extended to 48 hours.
And 3.6 only being the default (parameter diskgroup) you can always change it yourself (given the precautions above).
Concerning
Sebastian -
How to find the drive assigned to ASM diskgroup
Hi all
I created some ASM disks and do not know if I attributed to a diskgroup. Please may I know how to find the disc by ASM diskgroup or free on the disk that can be used.
Thank you.Hello
You must make reference to:
http://download.Oracle.com/docs/CD/B28359_01/server.111/b31107/asmdiskgrps.htm#CHDIBGGH
If you scroll down a bit you'll find: "groups example 4-3 look at a disk with associated disks.You can also check more specifically:
http://www.Stanford.edu/dept/ITSS/docs/Oracle/10G/server.101/b10755/dynviews_1019.htmHTH,
Thierry -
Hello
How to check ASM diskgroup single disk free space?
ConcerningSo what's the answer, have you found, made this post useful or correct
-
How to OCR and the drive to vote of raw devices for ASM diskgroup
Hello
I plan to upgrade my environment clusterware/ASM 11.1.0.6 to the grid
infrastructure 11.2.0.1 on Solaris sparc 64-bit.
I also plan on spending the OCR and discs of raw devices to ASM voting
starts. But how to do? When should I do: upgrade
process or after the upgrade? When should I start?
Thank youcreate a disk group or use an existing disk group that matches your redundancy needs
To ocr asm
===============
1 ensure that the clusterware version 11.2.0
# crsctl query crs activeversion
Oracle Clusterware version active on the cluster is [11.2.0.1.0]2. replace the OCR file by the asm disk group
#ocrconfig - replaced- replacement<+ASM diskgroup=""> 3 remove the old file ocr
#ocrconfig - remove4. check the integrity of the ocr
$cluvfy comp ocr n - verboseSE asm votedisk
======================
1. Add the voting disk to the asm disk group
#crsctl replace votedisk<+asm disk="" groupname="">Note: According to the disk group redundancy the required number of ocr and voting disk files will be created
Normal: 2ocr, 3voting disc
For the great: 3 ocr, voting 5 discdo not backup the ocr/votedisk dd in 11.2.0
{kind=link}
Maybe you are looking for
-
my phone has been locked due to activation lock please help me
Phone has been locked for some time due to the blocking of the activation. I get my password and I typed it in. it did not work.
-
Yesterday, August 22, Mozilla has undergone a massive rupture and complete in the treatment of Yahoo. Initially I thought it was a virus. I immediately passed to Google Chrome & worked on it without difficulty throughout the day. Yahoo was to push al
-
Portege R700 - FN keys emulate external keyboard
My R700 is connected to a port replicator Port speed Hi and external USB keyboard. I would like to access the function keys of Toshiba on the external keyboard, which means I need to emulate the key FN from Toshiba. I've seen references to other mode
-
Support for Windows 7 to VGN-SZ49
Where can I find Windows 7 support and drivers for my VGN SZ491N? I waited for a year! My S1/S2 special function buttons do not work. Help, please.
-
Good afternoon I was wondering if I can get the password bios reset for a HP Folio S13-2000. The disabled system code is: 53899087 Thank you kindly