Average of channels multiple multiple readings
I did not any LabVIEW for awhile so I am at a lost as to how to approach my problem later. I use a cFP-TC-120 to take the measure of the temperature of an air jet. I would read in each channel for a while and then the average of the values collected for each channel. Then read channels 0-7 for 5 seconds, the average of the readings for each channel, build the table of averaged values.
Thanks in advance.
You can go there. I would like to know if that's what you're looking for.
Tags: NI Software
Similar Questions
-
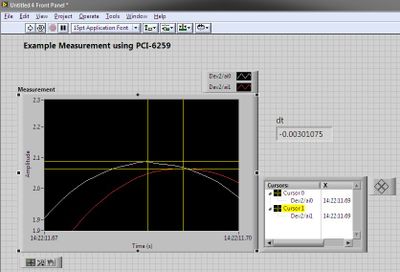
Synchronous channel multiple acquisition USB-6259 (phase measure)
Hello!
I want to create a user-signal (1 k at 20 kHz) in SignalExpress, generate it with the case NOR USB - 6259 BNC and measure with the same device after that the signal has passed a DUT I need the answer for a fixed term.
For the moment, I'm trying this: I connected the output via a Y-coax analog (length 1 meter) to TWO analog inputs.
Because the input channels have been grouped with the add a channel button, the data acquisition should occur almost synchronous.
However, sometimes the phase response is zero (cause as expected the two signals must be equal), but sometimes it "jumps" (especially when I am running the new project) and increases or decreases linearly on the frequency (so there is a time difference between two measured signals).
I don't think that running is the problem here, because referring to the manual, it's about some µseconds and I have not yet change the range of voltage between input channels. Furthermore, the magnitude response is fine.
I has not yet perform to synchronize the input channels with the output of the channels either, but first I would be recognizing a solution for the entry-entry-synchronization, (I don't mind if it is implemented in LabView).
Thanks in anticipation, Daniel
Hello Daniel,.
the M-Systems Series DAQ using a switch to sample multiple channels. So you have to take the time to switch into account when
you do measures such as phase shift of two signals.
I took your project Express of Signal but also created a LabVIEW VI to double check, and you can see exactly the same lag between the two
sampled signals. If you want to measure the true phase differences, you have to use a device of simultaneous sampling like S or DSA series devices (there are more a few others).
concerning
MArco Brauner NIG.
-
The best way to channel multiple steps using NI USB 6009?
I'm new to labview and I am trying to acquire multiple voltages of several channels and spread them out on a chart. It seems impossible to do it at the same time since the NI USB 6009 has only one pair of ADC.
The only way I ever came with is to use daq assistant to support significant tensions one by one and then make it loop awhile, but y at - it any delay during the move between channels?
And there at - it of best ways to acquire data from multiple channels?
If you have specified multiple channels (i.e. Dev1 / ai0:ai3) with a single DAQ Assistant, then this is the right method. The inexpensive device has no simultaneous inputs, so you will have to live with the slight delay of channel inter.
-
Jitter of RT! Can multiple readings to a variable / cluster cause a deadlock condition?
Howdy do.
While gradually develop and test an application on a crio9068 (RT linux) I started to see 'finished later?' in my main timed loop indicator flicker. Start pulling my hair out trying to figure out how to prevent this. I did a 'max hold' vi and can see the longest execution time for each image.
The application runs fine at about 75% of CPU with the Panel open load, and the majority of the iterations run at the time. Sometimes I'll have a 'pic' at run time, all four managers in the timed loop take significantly longer than normal to run and the indicator 'late' says.
A few questions I've had accumulate while chasing this:
-If I use local varables to pass data between the loops, but only write to the variable in one place, can I still cause a condition of blocking/jitter by competing readings of this memory space?
-If I use a node FPGA read/write to pass data between the FPGA and the timed loop, I should expect this causes a problem? I selectively disabled a lot of my code, and it seems that is where some of the delay occurs. What me stem, it's that these parts of the code have not changed in the recent development and the thing never used to run to the end.
-On the theme of the node FPGA read/write, I assumed before that I should not write to the same FPGA FP element in different subvis. However, the code is set up so that there are several parallel calls to the read/write node, just with different selected items. Is that BAD?
-Similarly, if I ungroup and read the same item in a cluster in a "parallel" mode control, can this cause a deadlock situation, or is it the same as unbundling and wiring away in several places?
-I am thanks to the recently renamed "software calibration and management toolkit NI (SCM)," formerly Drivven CalView, to manage the communication between the RT and a windows host. He is also careful fault management stuff. Anyone else using it, and is it possible that I am getting jitter by having too many calpoints in my deterministic loop?
No indication on any of the above would be greatly appreciated. If I don't make sense on any of the above points I do excerpts from example to describe.
Hi Matt,
What about under the name of multithreading - the same thread can run on multiple cores, but everything in a timed loop will always hold in a single thread. For reference (see 'Set the execution order for screws of real-time synchronization'):
LabVIEW Help: Synchronization of deterministic Applications (real time Module)
http://zone.NI.com/reference/en-XX/help/370622L-01/lvrtconcepts/timing_control_loops/
To cache the runtime data, I didn't have a specific method for mind, rather I generally try to catch at least one instance of the hiccups by capturing variables of interest in the shift registers or a FGV, just to see if there is any kind of difference. This may not be useful in your case, as I suspect it's interactive execution, what causes the problem.
Regarding the interactive performance and determinism, there is really no way of knowing what will happen, but it will often cause the kind of behavior that you see now. Because you are more or less continuous between the target and the host data, everything hangs in the network or on the computer host can set the RT system, especially if you read or write data on the front panel. Given that all of your curls are delayed at the same time, it seems the most likely scenario, unless you have a VI reentrant or similar shared between all the loops - I have seen that a few times with managers error or stop sharing. Given that these spots are quite often (it resembles something like 1/100 iterations, I would recommend put in some shared variable RT FIFO benchmarking and the deployment of the application as a stand-alone RTEXE.) It should be fairly easy at that time see if instability persists.
Best regards
-
Average data from multiple text files
I am new to labVIEW so any help is appreciated:
I have a 100 txt files with two columns (separate tab) for a value of X and Y.
I need the average of the values of Y to generate a single file and generate X against Y graph.
So, how to read the data of these text files? (without having to select each one individually) and the average data and create a chart XY him?
Thanks in advance
There is a function to list folder in the palette of the file i/o that will return an array of file names. Feed this table in a loop to open and read each file in turn. Put in a new file, build a table with her, process the data or do whatever you want.
-
USB-6210 analog in, the same channel, but the readings of two orders of magnitude different
LV 2014
Windows 7 Professional
64 bit
NEITHER USB-6210
The vi takes two samples from the 6210 analog in, ch 0.
Front photo shows the entrance of the canal is the same, but the two readings are 10 ^ difference size 5.
There is a delay of one second between readings and a digital output goes high to low.
Vi refinging admitted that she needs.
VI joint are saved as version of 2014
and the version of 2013, respectively.
Well, that would be because you wrote a bug.
Change this to AI tension!
And stop writing bugs

-
Replace negative values in multiple channels with "0'.
Hello
I'm calculating and then by creating a cumulative channel, multiple channels. Negative values in these channels aren't necessary, and I need a nice way to replace each negative value in these channels with a value of '0'.
My current code is:
Do
Do
If Data.Root.ChannelGroups (2). Channels (i). Values (II)< 0="" then="" data.root.channelgroups(2).channels(i).values(ii)="0 ">
II = ii + 1
Loop until the second > Data.Root.ChannelGroups (2). Channels (i). Properties ("length"). Value
II = 1
i = i + 1
Loop until I > Data.Root.ChannelGroups (2). Channels.CountIt works, but I don't like. He adds a few seconds when running my script, which was almost instantly. Is there a better way to do it?
Thank you.
Hello Kevin,
The fastest way to go through a channel and check the values less than or equal to 0 is through the canal's calculator. The code below takes all the channel first channel group (with the exception of the first string that is be the weather channel in my example data set) and replaces the values<0 with="" 0="" through="" the="" iif="">
Set Group = Data.Root.ChannelGroups (1)
iMax = Group.Channels.Count
FOR i = 2 to iMax
Adjust the strings = Group.Channels (i)
Formula = "= IIF (y '.<0, 0,="">
Call to calculate (formula, Array("y"), Array (Channel))
NEXT ' IIn this example we overwrite the existing values of data channel with 0, but you can also copy the channels to make sure that your raw data is available.
The calculator of channel is extremely fast for this type of operation because it does not create a loop to go if each line separately and check the values he...
I hope this is useful,
Otmar
-
I am trying to parse data that extends between several files on several groups of PDM and channels.
The files are contiguous blocks of the same sampled signals (i.e. they are split only to allow the viewing and effective storage).
I need to analyze each of the signals individually and therefore plan concatenate the data of each channel for all the files and then run an analysis of waveform "en masse."
I generate 288 cases per day, each with about 200 channels. Each daily analysis will therefore contain approximately 8.6 million samples.
However, due to restrictions of memory, I need concatenate each channel individually, rather than using a single continuous file.
I use multiple readings to the same files to extract the information from each channel.
What is the best way to read same files multiple times?
Is it better to open all the files in an array of references PDM and then do a reading for each channel, only the closing of records at the end of the analysis?
Or he would be better open/read/close each file for each channel?
Sorry if this is obvious or answered before!
So getting back to your question, my advice would still be just open/read/close files once. I also recommend to check if it is possible for you to change the data type (for example from double to single data type or even raw). It would be much smaller file size, and therefore increase the read performance.
Cheggers
-
How to get the physical channel for USB card as ENET
Hello
For my application (VB .NET, using NIDAQmx 8.8), I need to access the 2 cards:
a USB-6008 and an ENET9163.
I would like to read the physical channels automatically with this feature NI-DAQmx
Physicalchannel1ComboBox.items.AddRange (DaqSystem.Local.GetPhysicalChannels (PhysicalChannelTypes.AI, PhysicalChannelAccess.External))
Unfortunately, he didn't get a single card at once.
When the USB card is connected, he read the physical channels of the USB card
When the USB adapter is not plugged in, it read the physical channels of the ENET card.
I hope someone can help me with this problem!
Thank you
RB
Hello RB.
To read from multiple channels, you can enter in the drop-down list box "Physical channel", the comma separated channels, custom channels or if you read physics, the string "DevX/Benjamin: Z", where X is the number of device, and X and are the first and the last channel you want to analyze (for example to read to ai0 to ai4 from your device 1 enter "Dev1 / ai0:4"). Among the names of your channels, I guess they are global channels created in MAX? You can always read channels multiple and different advice by separating the comma.
I hope this helps!
Kind regards
-
Write to digitall all ports (channels) with the decimal value
Hello
It is possible to write all digital channels with a value decimal for a device with 96 channels at the same time?
I have a USB-6509 camera and I want to write each value of Pentecost bit 1 in the loop (for the first transfer I write 0,1,2,4,8,16, 32, 64 and 128) with the line "Dev3/port0 / line0:7", but if I want to write all ports at the same time, how to set the line and the "write.vi DAQmx?
Thank you.
You can configure the reading and writing in the ports of 8 bits with the 6509. For example, you could write just 128 to "Dev3/port0. If you want to write to all 12 ports, I recommend doing a task that is several channels on the 6509 module, each channel of the task being a port. You can then use the channel Multiple, single sample of writing of your values. Your values must be in a table of U8.
-
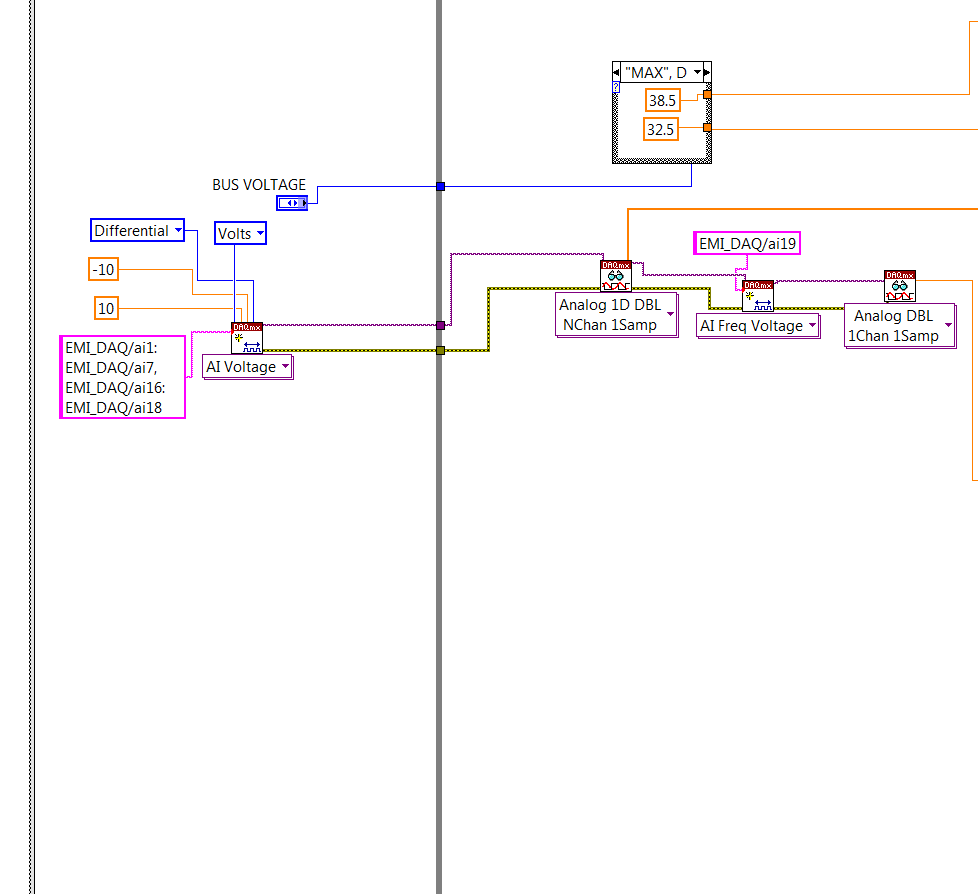
I am trying to write a program that runs in the loop and 11 different channels on a device NI USB DAQ 6343 of samples continuously. The first 10 channels are simple measures of DC, the remaining string is a voltage AC signal, I need to save the frequency. All these data, I will write in a .csv file at the end. I have attached my code and I work with DAQ.mx drivers.
The question I have is, how I measure and AC of the signal with the DAQ USB? I tried to configure the analog input channel # 19 of "frequency", voltage and then do a "reading", despite, he tells me that the channel does not support this type of measure. This AC signal goes through a BNC cable, then two adapters of banana.
My code, written in LabVIEW 2013 is attached. Here is a screenshot.
You simply include this channel in the list of channels of voltage there you already have. This is part of the same task. Change to n samples and specify a rate and the number of samples to be read. Given that your dc channels would be to multiple readings now, you could do something like taking the average of the people.
-
Urgent: continous recorders of NIDAQmx and other instruments with multi-threaded vc ++
I'm working on a software with vc ++ to control several instruments including a NO-DAQmx6289. For example, the features of the software.
1. communicate with data acquisition card (card data acquisition) and continuously acquire data from several channels at a frequency of 1 kHz.
2. connect with function via port RS232 1 generator, sending triggered bursts to the real-time features generator change state Ultrasound (G_usstatus) variable.
3. connect with optical switch via RS232 2 port, send signals to switch between the two input channels (0,1) and six output channels (2,3,4,5,6,7) to the specified user to sequence and time interval (default: 150 ms), real-time change the channel connection variable (G_optchannel).
4. in real-time, record data and the corresponding ultrasound status and connection status of optical channel in a specified file use for later analysis.
I use multiple threads to make data acquisition (1-wire), control of the function (2 wire) generator and optical switch (3 wire). I also need save data acquisition of data and the corresponding ultrasound status and use the connection status of optical channel in a specified file for later analysis. I use the following codes to read data continuously.
Sub DataCollectionWin::ConnectDAQ()
{DAQmxErrChk (DAQmxCreateTask ("", & taskHandle));}
DAQmxErrChk(DAQmxCreateAIVoltageChan(taskHandle,"Dev1/ai0","",DAQmx_Val_Cfg_Default,-10.0,10.0,DAQmx_Val_Volts,NULL));
DAQmxErrChk(DAQmxCreateAIVoltageChan(taskHandle,"Dev1/ai0,Dev1/ai1,Dev1/ai2,Dev1/ai3,Dev1/ai4,Dev1/ai5,Dev1/ai16,Dev1/ai17,Dev1/ai18,Dev1/ai19,Dev1/ai20,Dev1/ai21,Dev1/ai6,Dev1/ai7,Dev1/ai22","",DAQmx_Val_Cfg_Default,-10.0,10.0,DAQmx_Val_Volts,NULL));
DAQmxErrChk (DAQmxCfgSampClkTiming(taskHandle,"",1000.0,DAQmx_Val_Rising,DAQmx_Val_ContSamps,60000));DAQmxErrChk (DAQmxRegisterEveryNSamplesEvent (taskHandle, DAQmx_Val_Acquired_Into_Buffer, 50, 0, EveryNCallback, NULL));
DAQmxErrChk (DAQmxRegisterDoneEvent(taskHandle,0,DoneCallback,));DAQmxErrChk (DAQmxStartTask (taskHandle));
Error:
If (DAQmxFailed (error))
{
DAQmxGetExtendedErrorInfo (errBuff, 2048);
MessageBox (errBuff);
DAQmxStopTask (taskHandle);
DAQmxClearTask (taskHandle);
return;
}}
Int32 CVICALLBACK EveryNCallback(TaskHandle taskHandle, int32 everyNsamplesEventType, uInt32 nSamples, void *callbackData)
{
char l_optstatus_s [1] l_optstatus_e [1];
char l_usstatus_s [1] l_usstatus_e [1];/*********************************************/
Reading DAQmx code
/*********************************************/
If (! m_bStopTracking)
{
l_usstatus_s [0] = g_usstatus [0];
l_optstatus_s [0] = g_optstatus [0]; Switching State optical before reading the data of 50 * 15DAQmxErrChk (DAQmxReadAnalogF64(taskHandle,50,10.0,DAQmx_Val_GroupByScanNumber,data,50*15,&read,));
SetEvent (hEvent);
l_usstatus_e [0] = g_usstatus [0];
l_optstatus_e [0] = g_optstatus [0]; Status of the ///optical at the end of the reading of the data of 50 * 15If (read > 0) / / / save data in an exl file specified by "datafile".
{Indicator = 1;
for (i = 0; i<>
{(/ / fprintf(datafile,"%d\t",i);}
fprintf(datafile,"%c\t",l_usstatus_s[0]);
fprintf(datafile,"%c\t",l_usstatus_e[0]);
fprintf(datafile,"%c\t",l_optstatus_s[0]);
fprintf(datafile,"%c\t",l_optstatus_e[0]);
fprintf(datafile,"%.2f\t",data[15*i]);
fprintf(datafile,"%.2f\t",data[15*i+1]);
fprintf(datafile,"%.2f\t",data[15*i+2]);
fprintf(datafile,"%.2f\t",data[15*i+3]);
fprintf(datafile,"%.2f\t",data[15*i+4]);
fprintf(datafile,"%.2f\t",data[15*i+5]);
fprintf(datafile,"%.2f\t",data[15*i+6]);
fprintf(datafile,"%.2f\t",data[15*i+7]);
fprintf(datafile,"%.2f\t",data[15*i+8]);
fprintf(datafile,"%.2f\t",data[15*i+9]);
fprintf(datafile,"%.2f\t",data[15*i+10]);
fprintf(datafile,"%.2f\t",data[15*i+11]);
fprintf(datafile,"%.2f\t",data[15*i+12]*5);
fprintf(datafile,"%.2f\t",data[15*i+13]*5);
fprintf(datafile,"%.2f\n",data[15*i+14]*5);
}
fflush (stdout);
}
}
}Now the problem is the data acquired with daq card does not match the corresponding registered swtich optical status (G_optchannel, which specifies the light connecting channels). High readings expected certain status really appeared in any other situation. It seems that there is a misalignment of the multi-thread data. Because the optical switching State passes to 150ms, so I put DAQmxRegisterEveryNSamplesEvent to be trigued each 50samples, which means 50ms with 1 kHz sampling to avoid missing the changes. I also check if there is any change of status during the DAQmxReadAnalogF64, by registering l_optstatus_s and l_optstatus_e, which are actually the same. I wonder if this is because the data are first registered in the buffer. When the software starts reading, at that time, optical swtich status no longer reflects the State when the data was recorded first. Is it possible to fix this? Thank you very much!
kGy,
I'm glad to hear that you are progressing with your project. Timestamp data are always a bit tricky, because the process of querying a counter on the CPU is done asynchronously with the acquisition of your DAQ hardware. However, your equipment will ensure that the relative chronology between samples is consistent (in your case, the data will be sampled every 1 ms). And since you have changed your program as you are now all samples acquired reading, you know that each sample follows the previous 1ms. So, if I were to implement this I think that I take an initial horodotage when I started the task and to calculate the timestamp for all samples following this timestamp (timestamp SampleN = (*.001s + horodotage initial N) or timestamp SampleN = timestamp SampleN 1 +. 001 s).
I would go to do that, rather than the timestamp of the end of the reading for the following reason. As I mentioned previously, the reminder of your reading will run when the OS is planning. Therefore, it is possible that it gets delayed or does not exactly in phase with the acquisition of hardware, and make adjustments to your code to handle this problem. However, when you're timestamping there is another thing to pay attention to. It's the fact that your hardware has a FIFO where sampled data can accumulate before getting transferred to the memory buffer that reading from (for example if the bus PCI were busy when the sample was acquired). Now assume that the stars aligned against us and get the following:
(1) the operating system is busy with other things, and our reminder read gets delayed a few ms.
(2) at the same time, another device connects the PCI bus (or part of the data path between your device and the memory used for the buffer).
(3) one or more samples is momentarily blocked in FIFO of the device.
If you were to read data timestamp at the moment, your timestamp would reflect the data in the buffer as well as data that was flying in the FIFO of your device. However, you can only read data in the buffer. Thus, time stamp applied to data that you just read would be a millisecond or two later they should be. Suppose that on the next read reminder, this condition has cleared up itself. This timestamp taken here would be accurate, however, you will need to return some additional samples (those who were stuck in the FIFO last time). If you backcalculation your timestamp at this stage, I think that the timestamp calculated for these ecaple timestamps calculated on the previous reading. It wouldn't be ideal, nor would it reflect when the data has been actually sampled.
One of the remaining challenges is how exactly the start of time stamp feature. To do this, I would like to add a call to DAQmxTaskControl (taskHandle, DAQmx_Val_Task_Commit) before calling DAQmxStartTask. This step will advance the State template DAQmx as far as possible without actually starting the task. This will help to DAQmxStartTask as soon as possible. Now, before the appellant beginning or immediately after, I would take my initial horodotage (perhaps timestamp before and after and take the average). Then I would use this original time stamp and my sampling rate known to calculate timestamps for all the rest of my samples.
That got a bit long, but I hope it has been helpful.
Dan
-
Hello
of this program is reading and to generate an analogue signal, pour it, but an analog digital converter of 8 bits is necessary "DAC0800", this last do the conversion remains at its output a negative current.
UN connected operational "LM358" will transform the negative current to a positive voltage.
When I measure the voltage at the exit of OPAMP by a multimeter the voltage varies in a way ordered 2 to about 4 volts.
but when I use the arduino to measure the analogue voltage, the voltage varies in a disorderly way, why I don't know! the of is what program is right!
Please help me.
The converter, the connection, the code.
Remember that a dmm will take multiple readings and average/filter before displaying a measure. Do you do none of this c code before sending data?
-
DECODE is changing the explain plan
I have a statement with a decoding function in the where clause like this:
When I have a package-1 as parameter for cropgroup the filter would result by ' AND '-1' = '-1', and the statement is executed in less than 2 seconds.»»» When I leave this where clause it takes almost 18 seconds. The result is the same so I don't understand why the explain plan command is so different and why not use index scans in the statement without decoding.AND decode(:cropcode,-1,'-1',sdu.u_crop_group) = decode(:cropcode,-1,'-1',:cropcode)
Below plans to explain and tkprofs to 1 (no decode) and 2 (decode).
* explain 1 *.
{code}
SQL statement that produced these data:
Select * from table (dbms_xplan.display)
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | TempSpc | Cost (% CPU).
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 7080 | 2413K | 43611 (2) |
| 1. SORT ORDER BY | 7080 | 2413K | 5224K | 43611 (2) |
|* 2 | FILTER |
|* 3 | HASH JOIN | 7156. 2 438 K | 43075 (2) |
| 4. TABLE ACCESS FULL | DWH_ABS_DETERMINATION | 17745. 363KO | 83 (0) |
|* 5 | OUTER HASH JOIN | 7156. 2292K | 42991 (2) |
|* 6 | HASH JOIN | 7156. 1355K | 42907 (2) |
|* 7 | HASH JOIN | 6987. 1187K | 19170 (2) |
|* 8 | HASH JOIN | 6947 | 963K | 10376 (1) |
|* 9 | TABLE ACCESS BY INDEX ROWID | ALIQUOT | 3. 144. 3 (0) |
| 10. NESTED LOOPS | 6907. 897K | 8577 (1) |
| * 11 | HASH JOIN | 2264 | 187K | 1782 (2) |
| 12. TABLE ACCESS BY INDEX ROWID | SAMPLE | 190. 4370. 17 (0) |
| 13. NESTED LOOPS | 2264 | 152K | 107 (1) |
| 14. NESTED LOOPS | 12. 552. 25 (0) |
| * 15 | TABLE ACCESS FULL | SDG_USER | 12. 288. 13 (0) |
| 16. TABLE ACCESS BY INDEX ROWID | SDG | 1. 22. 1 (0) |
| * 17. INDEX UNIQUE SCAN | PK_SDG | 1 | | | 0 (0) |
| * 18. INDEX RANGE SCAN | FK_SAMPLE_SDG | 597. 2 (0) |
| 19. TABLE ACCESS FULL | SAMPLE_USER | 1078K | 16 M | 1669 (1) |
| * 20. INDEX RANGE SCAN | FK_ALIQUOT_SAMPLE | 3 | | | 2 (0) |
| 21. TABLE ACCESS FULL | ALIQUOT_USER | 3403K | 29 M | 1781 (3) |
| 22. TABLE ACCESS FULL | TEST | 3423K | 104 M | 8775 (2) |
| * 23. TABLE ACCESS FULL | RESULT | 3435K | 65 M | 23718 (2) |
| 24. VIEW | PLATE | 21787 | 2851K | 84 (2).
| * 25. FILTER |
| 26. TABLE ACCESS FULL | PLATE | 21787 | 574K | 84 (2).
| * 27. INDEX UNIQUE SCAN | PK_OPERATOR_GROUP | 1. 7 | | 0 (0) |
| * 28. INDEX UNIQUE SCAN | PK_OPERATOR_GROUP | 1. 7 | | 0 (0) |
| * 29. INDEX UNIQUE SCAN | PK_OPERATOR_GROUP | 1. 7 | | 0 (0) |
| * 30 | INDEX UNIQUE SCAN | PK_OPERATOR_GROUP | 1. 7 | | 0 (0) |
| * 31. INDEX UNIQUE SCAN | PK_OPERATOR_GROUP | 1. 7 | | 0 (0) |
---------------------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
2. ((«GROUP_ID» EST NULL ou EXISTE (SELECT / * + * / 0 DE "AGIL".) filter)) "OPERATOR_GROUP"
"OPERATOR_GROUP' WHERE ' OPERATOR_ID"="LIMS$ OPERATOR_ID" () AND "GROUP_ID" =:B1)) AND ('GROUP_ID' IS NULL) "'". "
OR EXISTS (SELECT / * + * / 0 "LIMS".) ' ' OPERATOR_GROUP ' 'OPERATOR_GROUP' WHERE
"OPERATOR_ID"="LIMS$ OPERATOR_ID" () AND "GROUP_ID" =:B2)) AND ('GROUP_ID' IS NULL OR EXISTS (SELECT / * +)) "" "."
* / 0 "LIMS". "' OPERATOR_GROUP ' 'OPERATOR_GROUP' WHERE ' OPERATOR_ID"="LIMS$ OPERATOR_ID" () AND "."
(('GROUP_ID' =: B3)) AND ('GROUP_ID' IS NULL OR EXISTS (SELECT / * + * / 0 "LIMS".)) "" OPERATOR_GROUP ".
'OPERATOR_GROUP' WHERE ' OPERATOR_ID "=" LIMS$ OPERATOR_ID "() AND"GROUP_ID "=:B4)))".
3 - access ("U_ABS_DETERMINATION" ="DETERMINATION_ASSIGNMENT")
5 - access("PLT".") PLATE_ID"(+) ="PLATE_ID")
6 - access ("TEST_ID" ="TEST_ID")
7 - access ("ALIQUOT_ID" ="ALIQUOT_ID")
8 - access ("ALIQUOT_ID" ="ALIQUOT_ID")
9 - filter("STATUS"='C' OR "STATUS"='P' OR "STATUS"='V')
11 - access ("SAMPLE_ID" ="SAMPLE_ID")
15 - filter ("U_ABS_DETERMINATION" IS NOT NULL AND "U_CLIENT_TYPE" = 'QC' AND
"U_WEEK_OF_PROCESSING"= TO_NUMBER(:WEEK) AND "U_YEAR_OF_SAMPLE_DELIVERY' = TO_NUMBER (:YEAR)).
17 - access ("SDG_ID" ="SDG_ID")
18 - access ("SDG_ID" ="SDG_ID")
20 - access ("SAMPLE_ID" ="SAMPLE_ID")
23 - filter ('NAME' = 'End result')
25 - filter("GROUP_ID" IS NULL OR EXISTS (SELECT /*+ */ 0 FROM "LIMS".")) OPERATOR_GROUP ".
'OPERATOR_GROUP' WHERE ' OPERATOR_ID "=" LIMS$ OPERATOR_ID "() AND"GROUP_ID "=:B1))".
27 - access ("GROUP_ID" =: B1 AND "OPERATOR_ID"="LIMS$ OPERATOR_ID" ())
28 - access ("GROUP_ID" =: B1 AND "OPERATOR_ID"="LIMS$ OPERATOR_ID" ())
29 - access ("GROUP_ID" =: B1 AND "OPERATOR_ID"="LIMS$ OPERATOR_ID" ())
30 - access ("GROUP_ID" =: B1 AND "OPERATOR_ID"="LIMS$ OPERATOR_ID" ())
31 - access ("GROUP_ID" =: B1 AND "OPERATOR_ID"="LIMS$ OPERATOR_ID" ())
Note
-----
-"PLAN_TABLE' is old version
{code}
* tkprof 1 *.
{code}
TKPROF: Release 10.2.0.3.0 - Production on Tue Jan 13 13:21:47 2009
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Trace file: C:\oracle\product\10.2.0\admin\nautp02\udump\nautp02_ora_880.trc
Sorting options: by default
********************************************************************************
Count = number of times OIC procedure has been executed
CPU = time in seconds cpu execution
elapsed = elapsed time in seconds the execution
disc = number of physical reads from disk buffers
Query = number of buffers for a consistent reading
current = number of buffers in current mode (usually for the update)
rows = number of rows processed by extracting or execute the call
********************************************************************************
SELECT sdu.u_crop_group,
SD. Name as sdg_name,
ad.variety_name,
ad.batch_number,
B.SID as aliquot_name,
Sau.u_box_code as box_code,
Sau.u_box_position as box_position,
t.Nom as test_name,
r.original_result,
PLT. Name as plate_name,
Concat (chr (a.plate_row + 64), a.plate_column) as plate_position,
au.u_replicate_number as replicate_number
OF lims_sys.sdg sd,.
lims_sys.sdg_user STO,
lims_sys. Sample his.
lims_sys.sample_user sau,
lims_sys.aliquot has,
to the lims_sys.aliquot_user,.
lims_sys.test t,
lims_sys. Result r,
PLT lims_sys.plate,
Ad lims_sys.abs_determination
WHERE sd.sdg_id = sdu.sdg_id
AND sd.sdg_id = sa.sdg_id
AND sa.sample_id = sau.sample_id
AND sau.sample_id = a.sample_id
AND a.aliquot_id = au.aliquot_id
AND au.aliquot_id = t.aliquot_id
AND t.test_id = r.test_id
AND plt.plate_id (+) = a.plate_id
AND sdu.u_abs_determination = ad.determination_assignment
AND a.status IN ('V', 'P', 'C')
AND r.name = 'result '.
AND sdu.u_client_type = "QC".
AND sdu.u_year_of_sample_delivery = (: year)
AND sdu.u_week_of_processing = (: week)
- AND decode(:cropcode,-1,'-1',sdu.u_crop_group) = decode(:cropcode,-1,'-1',:cropcode)
ORDER BY box_code, box_position, replicate_number
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 1.15 1.16 0 0 0 0
Fetch 1 8.53 16.10 227649 241266 0 500
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 3 9.68 17,27 227649 241266 0 500
Chess in the library during parsing cache: 1
Lack in the library during execution cache: 1
Optimizer mode: ALL_ROWS
The analysis of the user id: 97
Rows Row Source operation
------- ---------------------------------------------------
SORT ORDER BY 500 (cr = 241266 pr = 227649 pw = time 0 = 16104631 en)
FILTER 21311 (cr = 241266 pr = 227649 pw = time 0 = 16246749 en)
21311 HASH JOIN (cr = 241266 pr = 227649 pw = time 0 = 16225434 en)
17745 TABLE ACCESS FULL DWH_ABS_DETERMINATION (cr = 374 pr = 0 pw = time 0 = 69 fr)
21311 HASH JOIN RIGHT OUTER (cr = 240892 pr = 227649 pw = time 0 = 16170607 en)
21895 VIEW PLATE (cr = 316 pr = 0 pw = time 0 = 43825 US)
21895 FILTER (cr = 316 pr = 0 pw = time 0 = 43823 US)
21895 TRAY FULL ACCESS (cr = 316 pr = 0 pw = time 0 = 31 US)
0 INDEX UNIQUE SCAN PK_OPERATOR_GROUP (cr = 0 pr = 0 pw = time 0 = 0 US)(object id 45769)
21311 HASH JOIN (cr = 240576 pr = 227649 pw = time 0 = 16106174 en)
21311 HASH JOIN (cr = 133559 pr 121596 pw = time = 0 = 9594130 en)
21311 HASH JOIN (cr = 94323 pr = 83281 pw = time 0 = 6917067 en)
21311 HASH JOIN (cr = 86383 pr 75547 pw = time = 0 = 5509672 en)
JOIN by HASH 7776 (cr = 8134 pr = 0 pw = time 0 = 285364 en)
TABLE ACCESS BY INDEX ROWID SAMPLE 7776 (cr = 572 pr = 0 pw = time 0 = 27152 US)
7876 NESTED LOOPS (cr = 377 pr = 0 pw = time 0 = 488287 en)
JOIN by HASH 99 (cr = 160 pr = 0 pw = time 0 = US 4168)
99 TABLE ACCESS FULL SDG_USER (cr = 53 pr = 0 pw = time 0 = US 1209)
5719 TABLE ACCESS FULL SDG (cr = 107 pr = 0 pw = time 0 = 17 US)
7776 INDEX RANGE SCAN FK_SAMPLE_SDG (cr = 217 pr = 0 pw = time 0 = 623 en)(object id 45990)
1079741 TABLE ACCESS FULL SAMPLE_USER (cr = 7562 pr = 0 pw = time 0 = 24 US)
3307948 TABLE ALIQUOT FULL ACCESS (cr = 78249 pr = pw 75547 time = 0 = 3331129 en)
3406836 TABLE ACCESS FULL ALIQUOT_USER (cr = 7940 pr 7734 pw = time = 0 = 556 en)
3406832 TABLE TEST FULL ACCESS (cr = 39236 pr 38315 pw = time = 0 = 3413192 en)
3406832 TABLE ACCESS FULL RESULTS (cr = 107017 pr = 106053 pw = time 0 = 6848487 en)
0 INDEX UNIQUE SCAN PK_OPERATOR_GROUP (cr = 0 pr = 0 pw = time 0 = 0 US)(object id 45769)
0 INDEX UNIQUE SCAN PK_OPERATOR_GROUP (cr = 0 pr = 0 pw = time 0 = 0 US)(object id 45769)
0 INDEX UNIQUE SCAN PK_OPERATOR_GROUP (cr = 0 pr = 0 pw = time 0 = 0 US)(object id 45769)
0 INDEX UNIQUE SCAN PK_OPERATOR_GROUP (cr = 0 pr = 0 pw = time 0 = 0 US)(object id 45769)
********************************************************************************
Select 'x '.
Of
Double
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 0 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 3 0.00 0.00 0 0 0 1
Chess in the library during parsing cache: 0
Optimizer mode: ALL_ROWS
The analysis of the user id: 97
Rows Row Source operation
------- ---------------------------------------------------
1 DOUBLE QUICK (cr = 0 pr = 0 pw = time 0 = 3 US)
********************************************************************************
Start: id: = sys.dbms_transaction.local_transaction_id; end;
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 0.00 0 0 0 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 2 0.00 0.00 0 0 0 1
Chess in the library during parsing cache: 0
Optimizer mode: ALL_ROWS
The analysis of the user id: 97
********************************************************************************
TOTALS FOR ALL NON RECURSIVE INSTRUCTIONS
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 3 0.00 0.00 0 0 0 0
Run 3 1.15 1.16 0 0 0 1
Pick 2 8.53 16.10 227649 241266 0 501
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 8 9.68 17,27 227649 241266 0 502
Chess in the library during parsing cache: 1
Lack in the library during execution cache: 1
TOTALS FOR ALL RECURSIVE INSTRUCTIONS
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 30 0.00 0.00 0 0 0 0
Run 30 0.00 0.00 0 0 0 0
Get 30 0.00 0.00 0 40 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 90 0.00 0.00 0 40 0 10
Chess in the library during parsing cache: 0
3 the session user SQL statements.
30 internal to SQL statements in session.
33 SQL statements in session.
********************************************************************************
Trace file: C:\oracle\product\10.2.0\admin\nautp02\udump\nautp02_ora_880.trc
Compatibility of trace files: 10.01.00
Sorting options: by default
8 sessions in the trace file.
3 SQL statements of the user in the trace file.
30 internal SQL instructions in the trace file.
33 SQL statements in the trace file.
6 unique SQL statements in the trace file.
633 lines in the trace file.
23 seconds in the trace file.
{code}ZI wrote:
I have a statement with a decoding function in the where clause like this:AND decode(:cropcode,-1,'-1',sdu.u_crop_group) = decode(:cropcode,-1,'-1',:cropcode)When I have a package-1 as parameter for cropgroup the filter would result by ' AND '-1' = '-1', and the statement is executed in less than 2 seconds.»»» When I leave this where clause it takes almost 18 seconds. The result is the same so I don't understand why the explain plan command is so different and why not use index scans in the statement without decoding.
I would interpret the results displayed differently.
Execution which took 17 s according to the 241 266 coherent block played tkprof output gets but in order to do so he read 227 649 the disk blocks. Note that most of the table addressed by this query blocks were read through scanning of complete table that can take advantage of multiple blocks readings, for example if you unset the db_file_multiblock_read_count 10.2 (recommended) it usually try to read 1 MB with a read request, which are 128 blocks in case of standard block size 8 k. Due to several reasons not always the full size can be requested with each read request, lets say about 200 000 blocks could have been read by about 2,000 blocks multiple readings. Each read request would turn into a physical read, could you get an estimate approximate 25 MS per read times 2,000 applications-online 50 seconds (your system is running obviously better that the average assumed by ost g 10 base optimizer without collected statistics system workload, can be that some additional file caching system is involved).
On the other hand, the execution plan that finished within 2 seconds completed 221 420 coherent block gets but did No physical reads at all. Note that most of the table blocks should be processed using one-piece random searches (ACCESS BY ROWID of the TABLE), according to the grouping of the indices factor, it could have been as many blocks that the lines have been returned to the range index scans. So you could have done with lets say more than 60,000 randomly accessed table blocks => until 60 000 monobloc required reading. So in the worst case, this may take 60 000 requests time 10ms by read-online 600 seconds, even if in reality at least some of the blocks will be stored in the buffer cache, so it should be less.
It would be interesting to know how these two declarations with a cold buffer cache, so that both had to physical reads. I suppose the first is actually faster. Of course, if the second corresponds more to your typical situation that most of the blocks is in the buffer anyway, then it could be faster, because the blocks read by random access are more likely to stay in memory blocks read by complete sweep of the table, but in a true perspective of I/O the first is expected to be higher.
Moreover, the change in the plan is probably caused by the fact that the additional predicate (DECODING) lowers the cardinality of the table of SDG_USER conduct so that LOOP IMBRIQUEE approach seems to be cheaper to the optimizer that the hash join/full scan table approach. Apparently the estimate is way off (by two orders of magnitude, in fact 100 instead of 1), then the plan is not really cheap, because it seems like the optimizer.
By the way: two actual execution plans displayed in the output from tkprof are actually different from the displayed output of EXPLAIN the PLAN, so the statement has executed a little differently provided the facility to EXPLAIN the PLAN.
Your PLAN_TABLE is old, since you are on 10g you should drop any PLAN_TABLEs that are in non - SYS diagrams, since 10 g already provides a global temporary Table as part of the default dictionary (SYS. Plan_table$ presentations via public synonym PLAN_TABLE).
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/ -
Mozilla, do not delete this view until you have solved the problem, or I simply notifies
the press and my U.S. Senator, Senator Dianne Feinstein, Chair of the Senate Committee on
Intelligence.Since Mozilla refuses to provide any way for a user to speak with the technical staff, it is my only
means left. I'll try to leave out some tech details - encourage not any other
exploitation of this hole of major back door security of Firefox.Firefox v25 + allows a door access stealthily followed Google at any time, on any site, unbeknownst to the user, much less consent. I have documented more than 230 cases to happen by Firefox on my PC alone, only since November 19, 2013.
You do not have to visit a site to trigger this follow-up, just open Firefox can / will start the channel
multiple attempts by time, in a few minutes.Mozilla itself or a Mozilla approved 'module' suddenly granted this access. No security
The "module", software or Firefox anti-suivi fiction 'Features' will catch and block, because it is not
initiated by the visit to the site of any user.If you think that Google is a bit benign, they are not - they are one of the largest in the world
personal data thieves and brokerage firms.I don't tell you what clues to look for here - but Mozilla PLEASE block this backdoor ASAP.
Firefox can update the database of phishing protection.
See also:

Maybe you are looking for
-
IPad will not download 9.3.2 IOS to IOS 8.4.1 update
My iPad kees telling me that a download has been requested, but that's all that happens.
-
Satellite A200 - hotkeys on XP
HelloI have Toshiba Satellite A200 1AG (PSAECE) was lowered from Vista to XPI need help to install the correct driver for the utility of access keys quick touchpad (after typing should light with blue light)I reinstalled XP many times had to ocassion
-
Upgrading RAM on the Satellite 2450-201
Hello I'm looking to upgrade of RAM to my laptop. I'm not sure whether the maximum RAM can take my laptop is 1024 or 2048 MB. A site on the net says that my laptop took TBD 1024 2048 MB. Is it 1 GB or 2 GB?Kind regardsPhilip (Dublin)
-
HP PHOTOSMART 7520 I CAN'T ADD OR UPDATE APPLICATIONS, NETWORK AND WIRELESS CONFIGURATION ARE ON.
-
BlackBerry Connect for OneDrive Passport does not
Hello I'm new to the BlackBerry/BB10, having moved just on a BlackBerry (a Nokia Lumia 930) passport. I need to access OneDrive but OneDrive app does not seem to connect once I get all of my 2 identification of correct authentication information. Can