change table 1 d of data for a row to a column
Hi all
This can be a very simple question, but im trying to take two 1 d of data tables, put them in a table and this table to be 1 column so it looks neat in a table.
Thank you
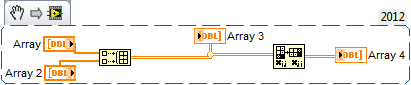
You will probably need to transpose the array, because the array build function will add lines. This will give you columns you want:
Tags: NI Software
Similar Questions
-
A column of report need to keep data for one row only
Hey guys,.
I have a report that has a column that links to another page in my APEX application.
There is a requirement where only the lines of this report needs to have a link so I need the column to display the link of the page for a line and one line only.
Is the report will have about 5 rows at a time so a way to just this link appear for the line after line (this will be the top line) in the column of attirbute in APEX? or is it possible in SQL code for the report?
Any help is very appreciated
Thank you
-MarkHello
The only way (I think) to do this is in the SQL code. Then you wrap just the column in a CASE statement and if it meets your criteria then build the link, and if not then display normally.
Something like that...
SELECT ename, CASE WHEN empno = 7839 THEN ''||empno||'' ELSE TO_CHAR(empno) END empno FROM empSee you soon
Ben
-
display the data in a row and different columns in the listbox
Hi I want to disply data in different and same columns line in listbox using InsertListItem(), but it displays data in different lines... I use the escape sequence for the creation of columns... Also, I want to display an integer which I converted to a string using sprintf() on listbox with a Word, for example 10 Kg where 10 is stored in a variable and I must add Kg, how to do it in a single call to InsertItemList()... Thank you
I see: you must create all of the line before adding it to the list box:
sprintf (string, "&d\033p30l%s\033p100l%s\033p170l%d\033p220l%.2f", itemNo, itemName, itemPack, 123, 15.98); InsertListItem (panel, PANEL_LISTBOX , 0, string, 0);
-
Second data line - first row to another column?
Hi all
I have a requirement to show the data from second in the Column1 as first line of Column2. Please see the example below, where the month is filtered < = 05.
In the example above for month 05, column Sales_New should show NULL because it is the last line of the query.Month Sales Sales_New 01 500 600 02 600 700 03 700 800 04 800 900 05 900 NULL
Thanks in advance.Something has gone wrong with your config...!
What is
"In the criteria tab use months in descending order and in the PivotTable, use ascending order.It is mandatory to achieve...
FYI: I tested in my local.If you need send screenshot
I appreciate if you score as correct ;) else let me know
-
Different formulas for different rows in the column of the formula
Is this possible? If possible, how?Hello
I still don't think that the new version has something we have in FR.
We have only one formula per column of formulas in a web form to the difference in FR.Thank you
Sourabh. -
Send a table 1 d of test for MSSQL 2012 data
Hello. Feel free to answer a number any of the sub questions you can. Thanks in advance!
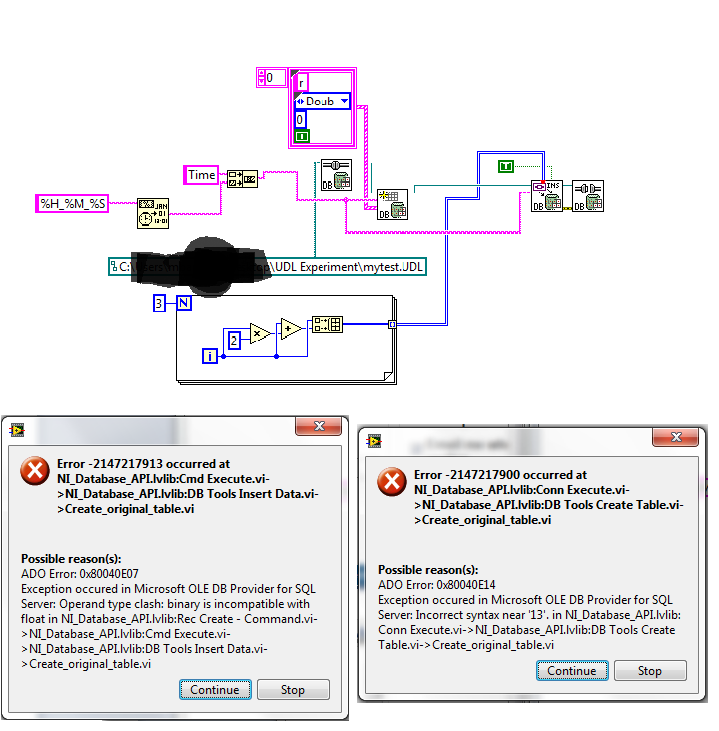
(1) being new to MSSQL, I don't know how to send a simple 1 d table of a floating number of type to a table in Microsoft SQL 2012. This is as far as I'm away. I get the message on the left with the VI current and one on the right when I get rid of the concatenation of strings of time and just carry the numbers going to the table name instead.
2 (a), this is my Guinea pig file, running on a database of Guinea pig. Finally I want to send the data from a test procedure that records a piece of data per millisecond - a table usually end up with approximately 15 000 items, more or less - on the basis of data. Unfortunately, I know the misfortune that Labview can send only on one line at a time. So how the hell do I do a new column for each new piece of data for a test that will run for an indefinite period?
2 (b) ideally, I would have a table with a column for each test was run, with the title of each column is the time and date at which the test was run. Is there a way to "transpose" the data once it's in MSSQL?
I used the fixed data because it's a better illustation of how things work.
If you need to write two items on one line at a time, then you need to group them together. The error you are getting is because you have wired a double as input but listed two columns. Notice that my last example wrote a cluster (which can be created with a fiber node) of two elements. You must use together to create a cluster and time data, then thread this cluster node of your insert.
A few other comments:
Generally screws express is a reasonable place to start when you're new to LabVIEW, but you must learn to use shift registers do calendar between the execution of the loop.
When it is to group the data and time together you need not to turn all this into a table first. Just put the time in a single entry and your data in the other. The groups you create are a single line of data.
-
Hi Experts,
JDeveloper 12.1.3.0.0
I have a VO based on entity object. With a column of the VO is transient attribute (I created).
I need to call a stored procedure for each row in the transitional attribute and display the data in the form of af: table. As well as other attributes.
So can anyone suggest how can I achieve this?
Thank you
AR
I think that you need a stored function (which returns the value) in this case, is not?
Take a look at:
https://docs.Oracle.com/CD/B31017_01/Web.1013/b25947/bcadvgen005.htm
and search for:
Invoking stored function with only Arguments in
call your function in the Get attribute and return value accessor...
-
change the current date for testing purposes.
For testing purposes, we must be able to set the current date, mainly so that we can test 3 successive months, in about a period of 15 days.
It's siebel-web-determinations (10,2) runnning under tomcat
Other than changing the server clock or
replace all occurrences in the rules where the date function perceive is used with a placeholder attribute as the temp "today's date"
is there another way to change the current date for testing purposes?
Thank you
AllanHi Allan
An alternative would be to use the current date only once in your rules, for example: the date of assessment = the current date.
Then, change the rest of your rules to use the valuation date instead of the current date. It works perfectly in production.
If you set the value of the valuation date seeding date you want to use Siebel, then the current date function will not be triggered (you set a deducted directly attribute, so the rule proving this attribute will not run).
See you soon
Anthony
-
[CDC] Change Data Capture: disable the capture of a column in the change table
Hi experts,
I use a synchronous CDC on 11 GR 2. I am facing a problem on the tracking columns. I need to exclude columns are to be captured in my change table.
It comes to my table in the source:
and I just want to see changes to the Code, name, but no salary.CREATE TABLE DEPT (Code INTEGER NOT NULL ENABLE, Name VARCHAR2(400 BYTE) NOT NULL, Salary NUMBER(*,2) NOT NULL, CONSTRAINT PK_CODE PRIMARY KEY (Code));
This is my definition of the change Table:
When I do:BEGIN DBMS_CDC_PUBLISH.CREATE_CHANGE_TABLE( owner => 'cdcpub', change_table_name => 'dept_ct', CHANGE_SET_NAME => 'CHG_SET_DEPT', source_schema => 'my_user', source_table => 'DEPT', column_type_list => 'CODE INTEGER, NAME VARCHAR2(400 CHAR)', capture_values => 'both', rs_id => 'y', row_id => 'y', user_id => 'y', timestamp => 'y', object_id => 'N', source_colmap => 'y', target_colmap => 'y', options_string => NULL, DDL_MARKERS => 'n'); END;
I don't want to see a line for this update in my table of changes. Is there a way to do it with Oracle CDC or only changes are tracked at the level of the table and not the column...UPDATE DEPT SET Salary=300000 WHERE CODE=77;
Thanks in advance!
Published by: Salah Sep 20, 2011 10:11SAL wrote:
More than 90 items in the table to compare, so I... But I'll try anyway, maybe it's the solution less harm them!
THXYes, it will be a pain to do the hit, but you only need a table analysis and sorting 1 window to cover all 90 columns performance should be good enough. Time to get out of copy / paste! :-)
David
-
Data for random table Gahering
I searched the boards for help on this and do so taught me SOME of what I have to do, but not all.
I think I can build a table now, but what I need to know how to do is to COLLECT the data for the table of user-seizures of text, then having Flash back a # of random inputs.
That's the drug testing. I have to be able to enter the names of the employees (collected by the table) and then enter the number of employees, I want to have tested (say 6 of 20 names entered). So I want the Flash to give me 6 of these names randomly without duplicating.
As I said, the research here, I think I learned to build the array by using the dynamic text boxes. What I didn't know is how to return X number of these data to the user randomly.
Any ideas?Once you have a table, you can mix it and then just count however many elements you need.
Of course, I went to the one I posted about the halfway point. :)
And it seems that blemmo he has improved at the end of this thread.
But I would recommend even when whose line of my post ASSetPropFlag.
-
How do I change or add constr. foreign key to the table whose children or data lines
Hello
I have a table with the name of Department in which the DEPTNO column is a column of data and primary key in it for all columns. Now, I have a table EMP where DEPTNO column is not having any constraints, including constraint foreign key also. I now have data in the EMP table for all columns. I would now add the DEPTNO column foreign key constraint in the EMP table that references the column DEPTNO in DEPT table. Both the table have not all null values.
I need to add the foreign key without removing the data in the EMP table.
Please advice.
Kind regards
AlriqIn addition, if you have pre-existing data that will never have a parent record but you want to ensure that any NEW data is consistent with the FK constraint you can always create it with the NOVALIDATE option:
SQL> CREATE TABLE EMP_BKP AS SELECT * FROM SCOTT.EMP; Table created. SQL> CREATE TABLE DEPT_BKP AS SELECT * FROM SCOTT.DEPT; Table created. SQL> DELETE FROM DEPT_BKP WHERE DEPTNO=10; 1 row deleted. SQL> ALTER TABLE DEPT_BKP ADD CONSTRAINT DEPT_BKP_PK PRIMARY KEY(DEPTNO); Table altered. SQL> ALTER TABLE EMP_BKP ADD CONSTRAINT DEPT_FK FOREIGN KEY(DEPTNO) REFERENCES DEPT_BKP(DEPTNO); ALTER TABLE EMP_BKP ADD CONSTRAINT DEPT_FK FOREIGN KEY(DEPTNO) REFERENCES DEPT_BKP(DEPTNO) * ERROR at line 1: ORA-02298: cannot validate (TEST_USER.DEPT_FK) - parent keys not found SQL> ALTER TABLE EMP_BKP ADD CONSTRAINT DEPT_FK FOREIGN KEY(DEPTNO) REFERENCES DEPT_BKP(DEPTNO) NOVALIDATE; Table altered. SQL> INSERT INTO EMP_BKP(EMPNO,ENAME,DEPTNO) VALUES(9999,'Test Emp',10); INSERT INTO EMP_BKP(EMPNO,ENAME,DEPTNO) VALUES(9999,'Test Emp',10) * ERROR at line 1: ORA-02291: integrity constraint (TEST_USER.DEPT_FK) violated - parent key not found SQL> SELECT * FROM EMP_BKP WHERE DEPTNO = 10 ORDER BY EMPNO; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- ------------------- ---------- ---------- ---------- 7782 CLARK MANAGER 7839 06/09/1981 00:00:00 2450 10 7839 KING PRESIDENT 11/17/1981 00:00:00 5000 10 7934 MILLER CLERK 7782 01/23/1982 00:00:00 1300 10 -
CDC inserting duplicate data changing tables
I use DCC to capture changes to 10.2.0.4 for 11.1.0.7 db.
The source tables have primary key constraints, but changing tables has no constraints on them.
I see many lines deuplicate on changing tables and these duplicates does not exist on the source.
How can I get rid of these?
I should create constraints on the changing table, if I do and then if duplicate a record is inserted the whole process stops, is it not?
Any suggestions?If you do two updates on a record, then CDC will record two changes against the primary key...
This is how works the CDC... If you don't want duplicates, do not use DCC. (use instead the stream or triggers)
-
Unable to display data for the date where there is no entry in the table
Hello
I need a urgent, described below:
I have a table named as 'dirty', consisting of three columns: empno, sale_amt and sale_date.
(Please ref. The table with data script as shown below)
Now, if I run the query:
"select trunc (sale_date) sale_date, sum (sale_amt) total_sale of the sales group by order trunc (sale_date) by 1.
It then displays the data for the dates there is an entry in this table. But it displays no data for the
date in which there is no entry in this table.
If you run the Table script with data in your schema, then u will see that there is no entry for the 28th. November 2009 in
sales table. Now the above query displays data for the rest as his dates are in the table of the sale with the exception of 28. November 2009.
But I need his presence in the result of the query with the value "sale_date' as '28. November 2009 "and that of"total_sale"as
« 0 ».
Y at - there no way to get the result I need?
Please help as soon as POSSIBLE.
Thanks in advance.
Create the table script that contains data:
------------------------------------------
CREATE TABLE SALE
(
NUMBER EMPNO,
NUMBER OF SALE_AMT
DATE OF SALE_DATE
);
TOGETHER TO DEFINE
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(100, 1000, TO_DATE (DECEMBER 1, 2009 10:20:10 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(100, 1000, TO_DATE (NOVEMBER 30, 2009 10:21:04 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(100, 1000, TO_DATE (NOVEMBER 29, 2009 10:21:05 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(100, 1000, TO_DATE (NOVEMBER 26, 2009 10:21:06 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(100, 1000, TO_DATE (NOVEMBER 25, 2009 10:21:07 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(200, 5000, TO_DATE (NOVEMBER 27, 2009 10:23:06 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(200, 4000, TO_DATE (NOVEMBER 29, 2009 10:23:08 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(200, 3000, TO_DATE (NOVEMBER 24, 2009 10:23:09 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(200, 2000, TO_DATE (NOVEMBER 30, 2009 10:23:10 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(300, 7000, TO_DATE (NOVEMBER 24, 2009 10:24:19 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(300, 5000, TO_DATE (NOVEMBER 25, 2009 10:24:20 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(300, 3000, TO_DATE (NOVEMBER 27, 2009 10:24:21 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(300, 2000, TO_DATE (NOVEMBER 29, 2009 10:24:22 ',' DD/MM/YYYY HH24:MI:SS'));))
Insert into SALES
(EMPNO, SALE_AMT, SALE_DATE)
Values
(300, 1000, TO_DATE (NOVEMBER 30, 2009 10:24:22 ',' DD/MM/YYYY HH24:MI:SS'));))
COMMIT;
Any help will be necessary for me
Kind regardsWITH tab AS (SELECT TRUNC(sale_date) sale_date, SUM(sale_amt) total_sale FROM sale GROUP BY TRUNC(sale_date) ORDER BY 1 ) SELECT sale_date, NVL(total_sale,0) total_sale FROM tab model REFERENCE refmodel ON (SELECT 1 indx, MAX(sale_date)-MIN(sale_date) AS daysdiff , MIN(sale_date) minsaledate FROM tab) dimension BY (indx) measures(daysdiff,minsaledate) main main_model dimension BY (sale_date) measures(total_sale) RULES upsert SEQUENTIAL ORDER ITERATE(1000) until (iteration_number>refmodel.daysdiff[1]-1) ( total_sale[refmodel.minsaledate[1]+iteration_number]=total_sale[cv()] ) ORDER BY sale_dateusing a clause type
Ravi Kumar
-
How to add the primary key for the table with the existing data?
The table is already busy data. There was no primary key before, so for each column, there are some duplicate values.
I want to add a new column, which should be of the integer data type and can automatically incremented, from 001. I tried with Oracle SQL Developer, but it says "ORA-01758: table must be empty to add mandatory (NOT NULL) column. How can I do? Thank you!Hello
Look for the [ALTER TABLE | http://download.oracle.com/docs/cd/B28359_01/server.111/b28286/statements_3001.htm#sthref4803] command to find out how to add a column (step (1)) and a (step (3)) constraint to an existing table.
For the step (2):
CREATE SEQUENCE employee_id_seq START WITH 1 ; UPDATE employee SET id = employee_id_seq.NEXTVAL;When you create a sequence, START WITH 1 is the default value, so that the line is not really necessary above... I've included just to show how you could start with any number you have chosen.
-
Update user given date for a table inside a script
Hi all
I have a CONTRACT table that has a date field CLOSED_DATE which stores the expiration date of a contract. now, I need to write a script to update some values corrupted in this column to a value of the user - give. I have the following script:
"ACCEPT CONTRACTID PROMPT FORMAT ID NUMBER ' Enter 9999999999 contract."
"ACCEPT THE UPDATE DATE FORMAT" MM/DD/YYYY HH24:MI:SS"DEFAULT ON DECEMBER 1, 2010 12:00.
FAST "enter the Date of expiry of the contract: ';
Start
BEGIN
C SET (C.CLOSEDDATE) = (& PDATE) UPDATE CONTRACT WHERE the CONTRACT. CONTRACTID = & CONTRACTID;
EXCEPTION
WHILE OTHERS THEN
LIFT;
END;
END
/
But when it is running, I have the following error: (I, ve entered the default date).
Start
BEGIN
UPDATE CONTRACT C SET (C.CLOSEDDATE) = (12/01/2010-12:00) WHERE CONTRACTS. CONTRACTID = 203456;
EXCEPTION
WHILE OTHERS THEN
LIFT;
END;
END
ORA-06550: line 5, column 50:
PL/SQL: ORA-00907: lack the right parenthesis
ORA-06550: line 5, column 1:
PL/SQL: SQL statement ignored
ORA-06550: line 16, column 0:
PLS-00103: encountered the symbol "end-of-file" during the expected in the following way:
; < an ID > < a between double quote delimited identifiers of >
The symbol ";" was replaced by "end-of-file" continue.
Please let me know what's in it...
Thank you all,
PradeepUse to_date ('& PDATE ', ' DD-MON-YY hh24:mi:ss')
Maybe you are looking for
-
Problem event name: APPCRASH Application Name: firefox.exe Application Version: 23.0.1.4974 Application Timestamp: 520bc252 Fault Module Name: ntdll.dll Fault Module Version: 6.0.6002.18881 Fault Module Timestamp: 51da3e27 Exception Code: c0000005 Ex
-
How do I turn off the default browser setting, so I use Windows Explorer
I installed Firefox as my default browser. I would now like to turn off so I can access Windows Internet Explorer
-
Satellite L100 gets hot - it's all about fan?
My Satellite L100 becomes extremely hot on the left. How can I be sure that the fan is working?
-
Can someone help me with the message of outlook express error 0x800CCC0D. I can't receive emails
I get the following error message: the host 'pop.ipa.net' is not found. Please check that you have entered the server name correctly. Account: * address email is removed from the privacy * Mail account ', server: 'pop.ipa.net', Protocol: POP3, Port:
-
10 keep blackBerry e-mail reported message unread automatically?
So I noticed recently that the message that I have already read or that you have marked as read, often keep back marked not read again. It can happen sometimes 5 or 10 minutes later.