Code/sequence TestStand sharing best practices?
I am the architect for a project that uses TestStand, Switch Executive and LabVIEW code modules to control automated on a certain number of USE that we do.
It's my first time using TestStand and I want to adopt the best practices of software allowing sharing between my other software engineers who each will be responsible to create scripts of TestStand for one of the DUT single a lot of code. I've identified some 'functions' which will be common across all UUT like connecting two points on our switching matrix and then take a measure of tension with our EMS to check if it meets the limits.
The gist of my question is which is the version of TestStand to a LabVIEW library for sequence calls?
Right now what I did is to create these sequences Commons/generic settings and placed in their own sequence called "Functions.seq" common file as a pseduo library. This "Common Functions.seq" file is never intended to be run as a script itself, rather the sequences inside are put in by another top-level sequence that is unique to one of our DUT.
Is this a good practice or is there a better way to compartmentalize the calls of common sequence?
It seems that you are doing it correctly. I always remove MainSequence out there too, it will trigger an error if they try to run it with a model. You can also access the properties of file sequence and disassociate from any model.
I always equate a sequence on a vi and a sequence for a lvlib file. In this case, a step is a node in the diagram and local variables are son.
They just need to include this library of sequence files in their construction (and all of its dependencies).
Hope this helps,
Tags: NI Software
Similar Questions
-
Best practices on how to code to the document?
Hello
I tried to search the web tutorials or examples, but could not get to anything. Can anyone summarize some of their best practices in order to document the LabVIEW code? I want to talk about a quite elaborate program, built with a state machine approach. It has many of the Subvi. Because it is important, that other people can understand my code, I guess that the documentation is quite large, but NEITHER has yet a tutorial for it. Maybe a suggestion
 ?
?Thank you for your time! This forum has been a valuable Companion already!
Giovanni
PS: I'm using LabVIEW 8.5 btw
Giovanni,
Always:
Fill in the "Documentation" in the properties of 'VI '.
Add description to the controls of its properties
Long lines label
Label algorithm, giving descriptions
Any code that can cause later confusion of the label.
Use the name bundle when clusters
Add a description tag in loops and cases. Describing the intention of the loop/case
Follow the good style guide as will make reading easy and intuitive vi.
I'm sure there are many others I can't think...
I suggest you to buy "LabVIEW style book", if you follow what this book teaches you will produce good code that is easy to maintain.
Kind regards
Lucither
-
Just improved m tips on best practices for sharing files on a Server 2008 std.
The field contains about 15 machines with two domain controllers, one's data is the app files / print etc... I just upgraded from 2003 to 2008 and want to get advice on best practices for the establishment of a group of file sharing. Basically I want each user to have their their own records, but also a staff; folder. Since I am usually accustomed to using windows Explorer, I would like to know if these actions can be done in the best conditions. Also I noticed on 2008 there is a feature of contacts. How can it be used? I would like to message or send an email to users their file locations. Also, I want to implement an admin at a lower level to handle the actions without making them far in on the server, not sure.
I read a certain bbut I don't like test direct more because it can cause problems. So basically a way short and neat to manage shares using the MMC, as well as the way that I approach their mail from the server of their actions. Maybe what kind of access cintrol or permissions are suitable also for documents. Also how can I have them use office templates without changing the format of the model.
THX
g
Hello 996vtwin,
Thank you for visiting the Microsoft Answers site. The question you have posted is related to Windows Server and would be better suited to the Windows Server TechNet community. Please visit the link below to find a community that will support what ask you:
http://social.technet.Microsoft.com/forums/en-us/category/WindowsServer
Hope this helps J
Adam
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think -
Work with several sequences-best practices
Hello.
I ve just started using Adobe Premiere CS6. My goal is to create a long movie, which is based on 30 hours of footage in raw gopro recorded on a recent trip of 2 hours.
Now my question is, what is the best practice for working with many sequences/clips?
You have a single file of heavy project, with all the clips?
Or make you small chapters that contains number of sequences x/x minutes long and ultimately combine all these?
Or how would you do it the best way, so its easier to work with?
Thanks a lot for your help.
Kind regards
Lars
I make a primary sequence in your project and then modify the individual scenes in the form of separate sequences, and then nest them in the primary sequence.
That way, you would have a single file of project heavy with all the media files (raw video, music, etc.).
I find it easier to work with. With the help of several project files would get too complex and fragmented throughout the of your computer.
I work with a lot of video GoPro, so I wonder what your Setup looks like. What device you have, and how your computer/Premiere Pro is configured?
-
Where to put the java code - best practices
Hello. I work with the Jdeveloper 11.2.2. I'm trying to understand the best practices for where to put the code. After reviewing the http://docs.oracle.com/cd/E26098_01/web.1112/e16182.pdf, it seemed that request module was the preferred location (although many examples in the pdf file reside in the main methods). After some time of coding, if, I noticed that there was a certain libraries imported and wondered if this would impact performance.
I looked at the articles published on the forum, in particular . This link mentions for access to the code a bean of support - and the bulk of the recommendations seem to be using the data control to drag to the Joint Strike Fighter, or use the links to access code.
My interest lies in where to put the java code in the first place; In the view object, entity object, and... other Am, backing bean object?
I can describe several guess better know where to put the code and the advantages and disadvantages:
1. in the application module
Benefits: Central location for code makes development and support easier as there are not multiple access points. Kinda like a data control centralizes the services, the module of the application can act as a conduit for the different parts of the code you have in your model objects.
Cons: Everything in one place means that the module of the application becomes bloated. I don't know how the memory works in java - if the app module has tons of different libraries are all called when even a method of re - run a simple query is called? Memory of pigs?
2. write the code in the objects it affects. If you write code that accesses a view object, write it to a display object. Then make it visible for the customer.
benefits: the code is accessible through ducts less (for example, I expect that if you call the module from the application of a JSF backing bean, then the module of the application calls the view object, you have three different pieces of code-)
CONT: the code gets spread, more difficult to locate etc.
I would greatly appreciate your thought on the issue.
Kind regards
Stuart
Published by: Stuart Fleming on May 20, 2012 05:25
Published by: Stuart Fleming on May 20, 2012 05:27First point here is when you say 'where to put the code of java' and you're referring to ADF BC, the point is that you put 'code of java business logic' in the ADF business components. Of course it is very good to have the Java code in the ViewController layer that covers the user interface layer. Just don't put the business logic in the user interface layer and don't put no logical user interface in the model layer. In your 2 examples you seem to consider the ADF BC layer only, so I'll assume that you're not only serious logic java code.
Meanwhile, I'm not keen on best practices in the term that people are following best practices without thinking, usually best practices come with conditions and forget to apply. Fortunately you do not here that you have thought through the pros and cons of each (nice work).
Anyway, back on topic and turn off my soap box, regarding where to put your code, my thoughts:
(1) If you have only 1 or 2 methods set in the AppModuleImpl
(2) If you have hundreds of methods, or there is that a chance #1 above will turn into #2, divide the code between the AppModuleImpl, the ViewImpl and the ViewRowImpls. Why? Because your AM will become overloaded with hundreds of methods making it unreadable. Put the code where it should logically go instead. Methods that operate on a specific line of VO Approfondissez partner ViewRowImpl, methods that work across lines in a VO enter the ViewImpl and methods that work throughout your in the associated AppModuleImpl.
To be honest that you never the option you choose, one thing I recommend as a best practice is to be consistent and document standard so not know your other programmers.
BTW, it is not a question about loading a lot of libraries/imports in a class, it has no performance cost. However if your methods require a lot of class variables, then yes there will be a memory of the costs.
On a side note, if you are interested in more ideas on how to create ADF applications properly think about joining the EMG "ADF", a forum which deals with ADF architecture, best practices (cough), deployment architectures free online and more.
Kind regards
CM.
-
Best practices for call code plsql and methods of application module
In my application I am experience problems with the connection pool, I seem to use a lot of connections in my application when only a few users are using the system. As part of our application, we need to call procedures of database for the business logic.
Our support beans, calls the methods of the module of the application calling to turn a database procedure. For example, in the bean to support, we have code as follows to call the method of module of the application.
Component Module to generate new review/test.
CIGAppModuleImpl appMod = (CIGAppModuleImpl) Configuration.createRootApplicationModule ("ky.gov.exam.model.CIGAppModule", "CIGAppModuleLocal");
String testId = appMod.createTest (username, examId, centerId) m:System.NET.SocketAddress.ToString ();
AdfFacesContext.getCurrentInstance () .getPageFlowScope () .put ("tid", testId);
Close call
System.out.println ("delete Calling releaseRootApplicationModule");
Configuration.releaseRootApplicationModule (appMod, true);
System.out.println ("Completed releaseRootApplicationModule delete");
Return returnResult;
In the method of application module, we have the following code.
System.out.println ("CIGAppModuleImpl: call the database and use the value of the iterator");
CallableStatement cs = null;
try {}
CS = getDBTransaction () .createCallableStatement ("start?: = macilap.user_admin.new_test_init(?,?,?);") end; ", 0) ;
cs.registerOutParameter (1, Types.NUMERIC);
cs.setString (2, p_userId);
cs.setString (3, p_examId);
cs.setString (4, p_centerId);
cs.executeUpdate ();
returnResult = cs.getInt (1);
System.out.println ("CIGAppModuleImpl.createTest: return result is" + returnResult);
} catch (SQLException to) {}
throw new Aexception.getLocalizedMessage (se);
}
{Finally
If (cs! = null) {}
try {}
CS. Close();
}
catch (SQLException s) {}
throw new Aexception.getLocalizedMessage (s);
}
}
}
I read in one of the presentations of Steve Muench (Oracle Fusion Applications Team' best practices) that the call of the method createRootApplicationModule is a bad idea and call the method via the link interface.
I guess that the call of the createRootApplicationModule uses a lot more resources and connections to database as the call to the method via the link interface such as
BindingContainer links = getBindings();
OperationBinding ob = bindings.getOperationBinding("customMethod");
Object result = ob.execute)
Is this the case? Also use getDBTransaction () .createCallableStatement the best average of calls to database procedures. Would it not be better to expose plsql packages such as Web services and then call from the applicationModule. Is it more effective?
Concerning
OrlandoHe must show them.
But to work around the problem, try this - drag method of the data control to your page and the fall as a button.
Then go to the source of the JSPX view and remove the button from there - if it comes to the display of the source - the link must remain in your pagedef. -
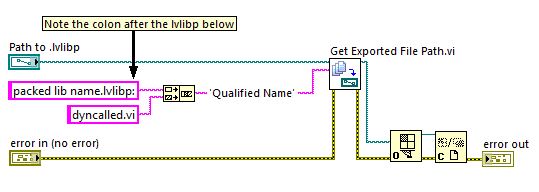
Best practices - dynamic distribution of VI with LV2011
I'm the code distribution which consists of a main program that calls existing (and future) vi dynamically, but one at a time. Dynamics called vi have no input or output terminals. They run one at a time, in a subgroup of experts in the main program. The main program must maintain a reference to the vi loaded dynamically, so it can be sure that the dyn. responsible VI has stopped completely before unloading the call a replacement vi. These vi do not use shared or global variables, but may have a few vi together with the main program (it would be OK to duplicate these in the version of vi).
In this context, what are best practices these days to release dynamically load of vi (and their dependants)?
If I use a library of project (.lvlib), it seems that I have to first build an .exe that contains the top-level VI (that dynamically load), so that a separate .lvlib can be generated which includes their dependencies. The content of this .lvlib and a .lvlib containing the top-level VI can be merged to create a single .lvlib, and then a packed library can be generated for distribution with the main .exe.
This seems much too involved (but necessary)?
My goal is to have a .exe for the main program and another structure containing the VI called dynamically and their dependents. It seemed so straighforward when an .exe was really a .llb a few years ago
Thanks in advance for your comments.
Continue the conversation with me
here is the solution:Runs like a champ. All dependencies are contained in the packed library and the dynamic call works fine.
-
Best practices using clusters to create the queue/notifier/bundles?
I'm in a block diagram, a queue, the notifier and several instances of cluster of bundle
that all use the same data structure. There is a typedef of cluster for the data structure.
Of course, each of these objects (define the queue, set notifier, bundle)
you want to know how do you define the cluster.
What is considered best practices?
(1) create a dummy instance of the cluster across data structure
definition is necessary (and hide all on the public Service)
(2) create only one instance and son at all places, it is necessary
But there is no stream on this thread: it's only the cluster * definition *.
which is used, so this seems to clutter the comic.
(3) create only one instance of the cluster control and use local variables
everywhere else the definition of cluster is required. It's _value_ is never
assigned or given read-so no problem with race conditions.
(4) another way?
If you were to clean up someone else's code, how do you expect
See this Treaty?
It occurred to me during this writing that here where I
"unbundle...... code bundle" I could wire the original beam to the
the two "unbundle" and "bundle" - but that would be too complicated
and the size of the comics with useless thread?
Thank you and best regards,
-- J.
Hi Jeff,
I think that this question is about "sharing" the typedef and not how share data (?) If the cluster control is registered as a typedef (or a strict typedef) but NOT SIMPLY as a CONTROL, then when a Diagram-constant of the typedef is created, it will be updated when you update the .ctl typedef! (and there is no FP control to hide
) Of course if the typdef is already available "close" if necessary, you will be able to use instead - save a spacer of diagram.See you soon.
-
1 hr, 2 users - best practices project
Hello
I was the only writer to our company for 6 years and more. I finally have someone to help me; However, this introduces a new challenge. We're going to * two * work on the same project HR, and we will use VSS to source code control. I don't know how we "share" this single HR project.
Someone at - it of the best practices for when you work in this kind of situation?
I have questions such as:
- When the other person creates the Index keywords, what happens if I removed files - how will this affect the addition of keywords?
- When the other person creates excerpts from news or new variables defined by the user, should immediately check them and let me know so that I can do a get latest and have new clips/variables in my project?
- How do we manage the two of us working on the same project and saw that he had to extract / archive files, create new topics, etc - what should be our "workflow"?
Thanks in advance for ANY help/advice anyone of you can provide!
I like rule of Care author: keep things simple and robust. This topic covers the three basic methods of sharing help authoring tasks. In order of complexity:
1. creation series. If you do not need to have the two authors of the project at the same time, you can just take turns working on the project. Just move the files back if necessary. It is the simpler and more robust approach.
2. merger proposals. If you need simultaneous creation, then, Yes, it's an approach simpler and more robust than the source control. However, this works only if you can partition your hardware and your clearly demarcated into two or more parts work assignments. Mergers can be a great solution, but it does fit all cases.
3. source control. If several authors need simultaneous access to the same material, then source control is the simplest answer.
Here are a few tips and observations, based on my experience with RoboSource Control, in no particular order:
1. source code control works best on small projects of medium size. Largest may be unstable.
2. set up to restrict an author file extractions only. Allowing the two authors to work simultaneously on a single topic is bad.
3. If possible, try to work in different areas of the project that are not. Remember that a single change in a subject can ripple on many related topics. (For example, if you change the name of file to a topic, all the links in this topic must be changed.) If someone else takes care of one of these topics, you will not be able to complete your initial change.
4. backup of your projects regularly, even if they are in the source code control.
5. create an administrator account to use just for that purpose. Do not use this account for the creation of the ordinary. All do not give administrator privileges.
6 appoint a person as administrator. Have at least one backup administrator. It will be the people who put up user accounts, to substitute the extractions ("I need this file, and Joe's on vacation!"), resurrect the old files, adjust source control conflicts, etc..
7 archive files as soon as you are finished with them. Don't let them verified any longer than necessary.
8. If you have large scale projects, your virus scan utility can really degrade performance during certain operations, such as the initials "get" of the project files. If this is the case, you may be able to configure your antivirus program to be more respectful of these activities of source control.
9. the authors of aid must remain in close communication. The other did know what you are doing, especially if you do something drastic like move folders. Be prepared to check something in the case of someone else in need.
10 give a lot of thought to the structure of your project. Examine the structure of files, naming conventions, etc.
11. some actions are more intensive than others source code control. (Move, delete or rename folders are biggies.) Your project is vulnerable, even if these changes are underway. If something is wrong until the process is completed, you can end up with a mess on your hands. For example, let's say there is a network problem while you move a folder, interruption of your connection with source code control. You may find yourself with HR thinking that the folder is in one place, while control of source code it is in another. The result is broken links and missing files. Time for the administrator to intervene and fix things. It is almost never a problem for small projects. It becomes a real problem for large projects.
12. If you get near a date limit, DO NOT choose this time to reorganize and rename files and folders.
13 follow the appropriate procedure for adding a project to source code control. Bad really do spoil you. It is easy to add a project to RoboSource Control. I can't speak for other solutions to source control.
14. it may be necessary to rebuild your cpd file more often than with uncontrolled sources projects.
15. I just lately that you must back up your source files?
HTH,
G
-
I help the family members and others with their Apple products. Probably the problem number one revolves around Apple ID I saw users follow these steps:
(1) share IDs among the members of the family, but then wonder why messages/contacts/calendar entries etc are all shared.
(2) have several Apple IDs willy-nilly associated with seemingly random devices. The Apple ID is not used for anything.
(3) forget passwords. They always forget passwords.
(4) is that I don't really understand. They use an e-mail from another system (gmail.com, hotmail.com, etc) as their Apple ID. Invariably, they will use a different password for their Apple ID than the one they used for other email, so that they are constantly confused about which account to connect to.
I have looked around for an article on best practices for creating and using Apple ID, but could not find such a position. So I thought I would throw a few suggestions. If anyone knows of a list or wants to suggest changes/additions please feel free. Here are the best practices for normal circumstances, i.e. not cooperate accounts etc.
1. every person has exactly 1 Apple ID.
2. do not share Apple ID - share content.
3. do not use an email address of another counts as your Apple ID.
4. When you create a new Apple ID, don't forget to complete the secondary information to https://appleid.apple.com/account/manage. It is EXTREMELY important questions your email of relief and security.
5. the last step is to collect the information that you entered in a document and save to your computer AND print and store it somewhere safe.
Suggestions?
I agree with no. 3, it is no problem with using a addressed no iCloud as the primary ID, indeed, depending on where you set up your ID, you may have no choice but to.
-
encoding issue "best practices."
I'm about to add several command objects to my plan, and the source code will increase accordingly. I would be interested in advice on good ways to break the code into multiple files.
I thought I had a source file (and a header file) for each command object. Does this cause problems when editing and saving the file .uir? When I run the Code-> target... file command, it seems that it changes the file target for all objects, not only that I am currently working on.
At least, I would like to have all my routines of recall in one file other than the file that contains the main(). Is it a good/bad idea / is not serious? Is there something special I need to know this?
I guess what I'm asking, what, how much freedom should I when it comes to code in locations other than what the editor of .uir seems to impose? Before I go down, I want to assure you that I'm not going to open a can of worms here.
Thank you.
I'm not so comfortable coming to "best practices", maybe because I am partially a self-taught programmer.
Nevertheless, some concepts are clear to me: you are not limited in any way in how divide you your code in separate files. Personally, I have the habit of grouping panels that are used for a consistent set of functions (e.g. all the panels for layout tests, all the panels for execution of / follow-up... testing) in a single file UIR and related reminders in a single source file, but is not a rigid rule.
I have a few common callback functions that are in a separate source file, some of them very commonly used in all of my programs are included in my own instrument driver and installed controls in code or in the editor of the IUR.
When you use the IUR Editor, you can use the Code > target file Set... feature in menu to set the source file where generated code will go. This option can be changed at any time while developing, so ideally, you could place a button on a Panel, set a routine reminder for him, set the target file and then generate the code for this control only (Ctrl + G or Code > Generate > menu control reminders function). Until you change the target file, all code generated will go to the original target file, but you can move it to another source after that time.
-
Best practices for the firmware update 40 + switches
Hello.
I need for firmware (and boot code) updated over 40 switches PowerConnect (mainly 5324).
What is the best practice on that?
I tried to download and install Dell OpenManage Network Manager, but it seems like an application of 'disorder' for someone who doesn't know. I threw a look at the demo of Dell for the application, but the quality is very bad and it is a version different than the one I downloaded (V3.0.1.15) you cannot use the guides directly.
Are there other options that manual session opening, then TFTP the new firmware and boot code? Or can someone a link to a valid demo or documentation that can help me with the work?
Thanks in advance.
-
Hello
I have in fact 2 queries
(1) how can we access attachedobjects defined in QML in C++?
(2) I'm loving development on Blackberry 10 C++ is one of my favorites. But I'm a bit lost when it comes to managing the user interface in classes. For example when we create the project through momentics we have a class called ApplicationUI. It manages all the (default) user interface commands, we in C++. as for example creating the document qml and setting as root user interface, etc. I am now working on an app that have NavigationPane as root, and then I continue to push pages (like the screens). But now the code for all pages is inside my ApplicationUI. What is the best practice to keep the UI for each page logic in a separte C++ class?
I also develop for Android that a separate class for each activity, this code does not mingle for each activity. Please guide me how can I keep logic of user interface of each Page into a separate class of C++?
regarding your second question:
I think this is the simplest approach to keep all things in the UI in QML. You can easily put things into separate files.If you want to use c ++ to the user interface: can be done, too. just put it in separate classes and include those in your application class.
-
Best practices for designing a view in PlayBook
Hello world
I'm new to BlackBerry PlayBook development and I would like to know how to make a user interface appropriate for playbook, what would be the best practice to do and it will be helpful to me if someone can post sample code here
Thanks in advance
A few tips:
* Views extend Sprite
* Views should be resizable, IE have a setSize() method
* views should 'PIN' children at some edges of the screen, from when they are resized it runs correctly.
* a parent class must listen to the scene for Event.RESIZE and call of resizing on the view.
* Use the component of QNX, set if possible
* Implement native controls, like sliding down to the options
-
Best practices for the application of page multi Landscape/Portrait
Hello
I am looking for information on track to develop auto guide demand in pure actionscript with new components of qnx.fuse, but there is not a good example in real code. Every time I tried to make it resizable layout to get deformated fluid only components in portrait or landscape mode.I have a simple application with the point main and 3 displays:
public class Main extends NavigatorSprite { public function Main() { addEventListener(Event.ADDED_TO_STAGE, init); stage.nativeWindow.visible = true; stage.scaleMode = StageScaleMode.NO_SCALE; stage.align = StageAlign.TOP_LEFT; stage.nativeWindow.activate(); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); navigator.pushView(View1); } } public class View1 extends ViewSprite { private var container:Container; private var button_two:LabelButton; private var button_three:LabelButton; public function View1 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; button_two = new LabelButton(); button_two.label = "to page 2"; button_two.width = 150; button_two.height = 45; button_two.addEventListener(MouseEvent.CLICK, handleTwoClicked); container.addChild(button_two); button_three = new LabelButton(); button_three.label = "to page 3"; button_three.width = 150; button_three.height = 45; button_three.addEventListener(MouseEvent.CLICK, handleThreeClicked); container.addChild(button_three); addChild(container); } private function handleTwoClicked(e:Event):void { navigator.pushView(View2); } private function handleThreeClicked(e:Event):void { navigator.pushView(View3); } } public class View2 extends ViewSprite { private var container:Container; private var back:BackButton; public function View2 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; back = new BackButton(); back.label = "Back"; back.width = 100; back.height = 45; back.addEventListener(MouseEvent.CLICK, goBack); container.addChild(back); addChild(container); } private function goBack(e:Event):void { navigator.popView(); } } public class View3 extends ViewSprite { private var container:Container; private var back:BackButton; public function View3 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; back = new BackButton(); back.label = "Back"; back.width = 100; back.height = 45; back.addEventListener(MouseEvent.CLICK, goBack); container.addChild(back); addChild(container); } private function goBack(e:Event):void { navigator.popView(); } }Is there for example some best practices how to modify this code to have pages and components with the same sizes in portrait and landscape? On presentation buttons size always 150 width and height 45 and wil containers have stageWidth and stageHeight.
Thank you if someone could help with this problem
Hello
Try listening to a shift in focus screen with this code:
stage.addEventListener(Event.RESIZE, onResizeHandler, false, 0, true);
You can only change the width/height of your components to the event based on the width/height of the floor.
I will guard against specifying specific sizes, if you want your code to work on devices BB10. I recommend using %'s.
Kind regards
Dustin
Maybe you are looking for
-
How to eliminate the audio loop "police Siren" in firefox?
I picked up an audio loop "police Siren" when I went to youtube.com , which is now integrated into Firefox and comes every time I open the browser This has happened Each time Firefox opened == I went to YouTube MCN UK
-
Problems with Satellite A350 wireless
I have a Satellite A350 running Windows 7 Professional 32 bit version. My wireless does not work. I just updated the driver and it changed the symbol of the connection to the network to connect to the local network bar wireless with a cross through i
-
code 8007054f re KB9710323 my computer starts repeatedly try to install this update
Please notify that this update is causing problems on my computer as it starts four times, whenever it is stopped
-
I know that some radio stations broadcast information about the current song. I was wondering if this function would be of interest to others as well. Maybe a suggestion to update the firmware?
-
at startup I get a sh app error, followed by a BHO ie3. DLL problem
Were invited to re - install this app, but can't find anyway to do! Help, please?