Confusion in the result...
Oracle 10g version
Hi gurus
I have the sample data.
Examples of data
as with a reference
(
Select 'AAA' crt_file, 'A1' scode of union double all the
Select 'AAA' crt_file, 'A2' from dual union all
Select "AAA" crt_file, null of union double all the
Select 'BBB' crt_file, 'A1' scode of union double all the
Select 'BBB' crt_file, 'A2' from dual union all
Select 'BBB' crt_file, the double null
)
Select * reference
where crt_file = "AAA".
(scode = & s_cd
Gold 1 = 1
);
When I 'A1' and then it will show all the result against AAA, but I think he should return only 1 row which is 'A1' not all the lines for crt_file = YYYY.
Please advice
Concerning
Matt
Hello
Matt. wrote:
Hi Frank
Sorry to bother you again, you said.
If p is true, then there is no need to evaluate q. If p evaluates to false or Unknown, q must be evaluated.
Anyway
In my case it's the same when I pass the parameter 'A1' then left condition site do not TRUE so no need to assess 1 = 1 condition and then the result should be stored not all one line... Please suggest
When you pass the parameter 'A1', then sometimes the left side of the condition-GOLD, it's TRUE and on these lines there is no need to evaluate the right.side.
When you pass the parameter 'A1', then sometimes the left side of the OR condition is FALSE or UNKNOWN and on these lines it is necessary to assess the right.side
Whatever either, or the condition there the TRUE value...
As stew said in response to #9, the WHERE clause is evaluated for each row. The results you get from a line do not affect the results you get on another line. That's the whole point of a WHERE clause, is not? In general, you want something that will be TRUE for some lines, but not for the other lines.
When you pass 'A1' as a parameter, you say that you expect the results to include 'all lines', but I think it's fair to say "all lines containing ="AAA"crt_file", as you said in your original message. The condition
crt_file = "AAA".
must be evaluated on each row independently the other lines. It is the same for all rows in the table.
When it's time to decide whether to include this line:
Select 'AAA' crt_file, 'A2' from dual union all
so, if & s_code = 'A1', the line will be included. Why? First of all, the condition on the left side of the AND, which is
crt_file = "AAA".
is evaluated. This State is set to TRUE for this line, so it is necessary to evaluate the right side of the AND, which is itself a condition GOLD-composed. The left side of the GOLD, it's
SCODE = & s_cd
is evaluated, and it turns out to be FAKE for that line, so the right side of the GOLD, it's
1 = 1
is evaluated, and which proves to be TRUE, then, on this line, WHERE any condition, i.e.
crt_file = "AAA".
(scode = & s_cd
Gold 1 = 1
)
takes the value
TRUE
and (FAKE
or TRUE
)
that is the same
TRUE
and ago (REAL
)
that is the same
TRUE
How this condition was assessed on the first line has no impact on how it will assess on other lines. (And even if it did, how do you know what the first line? Rows in a table have no built-in command. If you run the same query over and over, different lines can be read first every time.)
Tags: Database
Similar Questions
-
RunState.ProcessModelClient. how to access the results of markets located in the loops?
Hello
In my sequence, I have to perform an analysis of the results before I have the MainSequence and return to the process template. Basically, I need to check made some steps has passed.
I access the results using RunState.ProcessModelClient. Using what I have access to the list of results. I would like to write that I have access to each result but I can't because I spotted the results of steps which are curly are not accessible (they are not there); However, they are on the report.
How is it possible? How do I access results in a loop? Where are they?
K.
Hello
not too painful:
the loop results in the usual place online, it's just the layout that will look like a little confusing:
You use some revisions of my TestStand (you are in 3.1)
The Runstate.ProcessModelClient is actually a copy of the space of time edit, not space running - it's the SequenceFile type, which means that even if you can see the layout of the result containers that belong to each step, they are there permanently, and not filled in this place from the moment of execution.
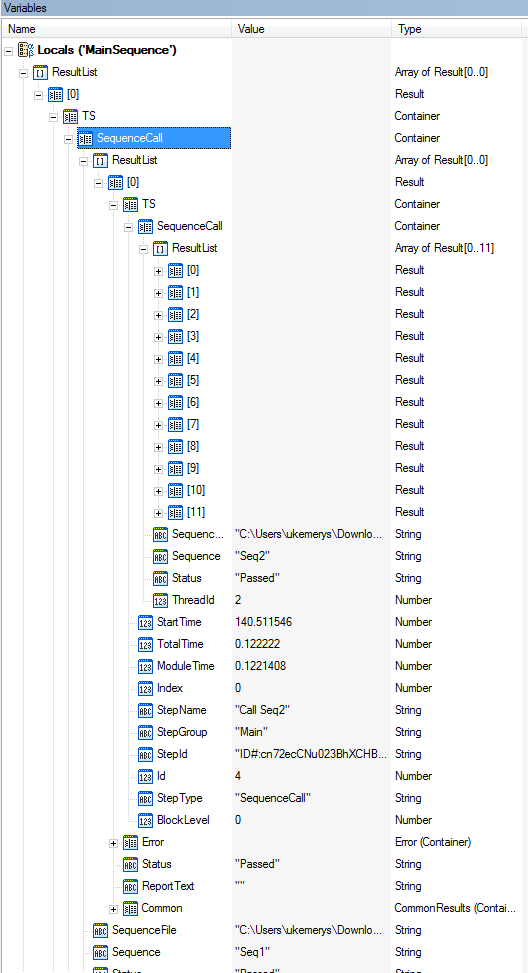
At the level of the mainsequence, you're still in your client, then you can go to Locals.ResultList directly.
In there, you have the singular element that is the result of the first and the only stage of your Mainsequence of your.
Inside there is the. TS. SequenceCall container. It is effectivey the resultlist gait that calls (always Mainsequence) seq1 so inside that, there is an another ResultList.
It's the ResultList for sequence "Seq1".
Which has a single item since this sequence has only one step inside of type SequenceCall.
[0]. TS. SequenceCall.ResultList.
From there you can see a lot of results even if you have only 4 effective steps in this sequence.
12 results covers:
3 iterations of ('for' 'Test2' 'end').
and then the last 3 items are "Test1" loop 2 times more.
When you set a stage of the loop and include you the results of each iteration, you get these results (2 in your case) more a global success-failure based on the criteria (your care ot 100% must pass in order to study the step successful when all iterations are complete.)
Note in your pre Expression where you change the name of the step on the fly, your labeled Test2 incremental changes the name from 'Test1' + Str (Locals.LI), and the Test1 marked step uses the same expression for this will look slightly confused that you cross your results.
Hope that helps.
Thank you
Sacha
-
So I call the Offline processing Utility (ORPU) a not executable call results in a plugin to perform a personalised treatment in another configuration. Everything works fine, including having run reduced (mostly hidden) by using the option/tray. When he called, the TestStand splash screen appears (certainly is not a show-stopper but it's confusing from the point of view of the user).
Is it possible that I can get this start screen to not appear when calling the ORPU? I noticed in the help, mention is made of the use of the callback file, and I wonder if someone has successfully used this to avoid the dialog box or other behaviors. I would like more info on how it works, but it doesn't seem to be a vast detail on this in the help, and I'm not also find me useful examples.
The source of the Offline utility treatment results is included with TestStand and can be changed.
The ORPU source is located under "
Components\Models\TestStandModels\Offline utility treatment results" From the source, you can see that there is no flag that allows you to hide the splash screen (except for / I leave, but that it will also close the ORPU!); However, you can easily change the ORPU so it does not show the start screen by removing the following lines in
\Components\Models\TestStandModels\Offline Results Processing Utility\OfflineResultsProcessingUtility\MainForm.cs If (! data.) Quit smoking)
splashScreenForm = new SplashScreen (mEngine, false);Regarding the flags without papers, there are not really many flags undocumented in the ORPU (even once, you can see them in the source), and undocumented flags have very specific use cases (open files from shell and NEITHER internal regression tests).
A (non-official) complete list of indicators ORPU from 2014 TS:
/?
Shows help/ tray
Starts the ORPU in the status bar/ exit-when-done
Exits when all files are made/ I'm leaving
Leave immediately/process - files - Missing - Data
Treats the files even if they lack of data/ which-process-files-Missing-Data
Do not process files that are missing data, show only a mistake (it is the default behavior)./ Process-All-Profiles
Start all profiles/ Process-No.-Profiles
Don't start any profile/ Process-Profiles
Treat the profiles specified in the following arguments/ process-files
Add the files specified for the specified profile/ log - level
Sets the logging level for the newspaper ORPU, all of the messages above, the specified log level is saved.
/ShellOpen
It is an internal indicator, it is used to treat applications for the shell (for example, after a double click on a tsr in Windows Explorer). Do not use this indicator./ non-interactive
It is an internal indicator used for the test. Do not use this indicator.Please note that NEITHER does not support appellant flags undocumented and that NEITHER is not guaranteeing backward compatibility of these flags undocumented and they could change at any time, without warning.
For a more detailed explanation of the working of each option, refer to the Arguments of the command line Utility using TestStand treatment results offline.
Hope this helps,
Francisco
-
I'm a bit confused about the Windows XP search results pane. I need to winnow down remove some of the documentation noted that the results do not apply. If I remove them in the search results pane, am I actually remove the document from the PC or just delete the search result and leave the document in its original file?
Hello
You delete the file. Try it yourself...
- For example, create a document with a unique name (say qwerty987.doc) word
- Search all files and folders to qwerty987
- Right-click on the file in the search results, and then click Open containing folder
- Research of two results of window and the window of the folder containing the visible file (resizing and movement to achieve, as appropriate)
- Remove the test file in the search results window and watch it disappear from the other window too
Tricky
-
Clear up the confusion over the name of the motherboard
I ordered an upgrade of CPU hoping that it is compatible with my motherboard. I fell into a riddle because of unclear and defective data on the HP Web site.
(1) Pegatron M2N58 - East named as (Narra 5)... and elsewhere on the page 6 of narrated GL6... well who is?
AMD Phenom II X 4 830, which is not yet on the site of AMD's processor that I ordered.
Different sites show different compatibility...
According to the support page for my PC... as long as it takes in charge the Am2 + and TDP of 95 watts... it will be a game
However, mistakes are confusing... and I'd like to see if anyone has this combo works?
Thank you
You are welcome.
It seems to be a good match. However, you're dealing with a 5 year and plu motheboard and a newer processor. It is not always a good script for success. The key is to be extremely careful when installing. Make sure you add enough compound/thermal paste to ensure it will work cool. If damage you it, needless to say, you cannot return it.
Good luck! I hope it works for you. I'd be happy to hear the result.
-
BlackBerry 10 Confusion with the OS versions
Good evening
where can I find which version number is the latest version of the BB OS? I couldn't find the number on the BB site, but found one in the English Wikipedia: 10.3.2.2789.
My phone (Q10) says he has the version of the 10.3.2.2474 software and the operating system version 10.3.2.2639, and it is said that this version is the latest version.
How comes that this number is different so the wikipedia article and where can I find the correct version in the BB Web site?
Thanks for any information.
Q.
Hello
Yes, it is a matter of confusion. But do not understand that it is not strictly BBs responsibility to clear up the confusion. Indeed, BB control only a tiny part of the OS release cycle to end users. BB releases OS packages they approve in the world at the same time... but he returned to service businesses and other entities to control final to decide if/when a BONE should be released to their set of end users. Therefore, it is very likely for two holders of the exact model same device to have two different answers to the question of 'the latest OS', for this answer depends on each entity having approved control and pulled him out of their set of users.
Complicating things is the difference between the OS and the version of the software. Reference:
Depending on who you work and what is the context, you may need to understand both of them and be sure that you talk about appropriate things so that understanding can arise between the parties to the communication. Version of the software is, basically, a conglomerate of BONES, Radio and other versions in the package... However, I don't know, how they derive the values of version of the software. I find that in most cases, it is wise to always use two values in discussions (e.g., "OS10.3.2.2639/SR10.3.2.2474").
QUADRATUR wrote:
How comes that this number is different so the wikipedia article
Wikipedia is a database of users of the information... If nobody contributed updates, then they do not reflect.
QUADRATUR wrote:
where can I find the correct version in the Web of BB site?
You do not have... I have never found that a BB OS/SR easily visible Web page free. There are utilities that can be obtained and executed on BB servers to discover the information, but they are technical, time-consuming and a lot of time to properly interpret the results. I have, however, recently created a list of all the values of BB10 OS/SR, going back... some time to refer:
Once again, however, it is only what BB has published the world... He said nothing that any specific control entity (for example, companies) may or may not have approved for their set of users. Via the official/automatic methods, you will only be offered which your control entity approved. Using unofficial methods to get anything other than that.
Good luck!
-
Windows security essentials. How can I find the results of an analysis? pls
Windows 7 Windows Vista
To avoid confusion and duplication of effort, please post a follow-up later all replies to your original in the MSE forums-online http://answers.microsoft.com/en-us/protect/forum/mse-protect_scanning/how-do-i-find-the-results-of-a-scani-have-tried/4ae5feab-6003-46d1-b3e5-77d9a4e09016 thread
-
confusion on the stats from v$ sql
I'm trying to increase the performance of a quarter of the exadata machine rack and uses the table v$ sql to see what questions the front-end application is generating (done automatically) and sending it to oracle. I question the table v$ sql like this:
select sql_id, io_cell_offload_eligible_bytes qualifying, io_cell_offload_returned_bytes actual, round(((io_cell_offload_eligible_bytes - io_cell_offload_returned_bytes)/nullif(io_cell_offload_eligible_bytes,0))*100, 2) io_saved_pct, elapsed_time/1000000, first_load_time, application_wait_time/1000000, concurrency_wait_time/1000000, user_io_wait_time/1000000, plsql_exec_time/1000000, java_exec_time/1000000, cpu_time/1000000, rows_processed, sql_fulltext, sql_text from v$sql where io_cell_offload_returned_bytes > 0 and instr(sql_text, 'D1') > 0 and parsing_schema_name = 'DMSN' order by --(round(((io_cell_offload_eligible_bytes - io_cell_offload_returned_bytes)/nullif(io_cell_offload_eligible_bytes,0))*100, 2)) asc elapsed_time/1000000 DESC
Whats confusing for me, is that I see a row of the table like this:
SQL_ID QUALIFYING STAGE REAL IO_SAVED_PCT ELAPSED_TIME/1000000 FIRST_LOAD_TIME APPLICATION_WAIT_TIME/1000000 CONCURRENCY_WAIT_TIME/1000000 USER_IO_WAIT_TIME/1000000 PLSQL_EXEC_TIME/1000000 JAVA_EXEC_TIME/1000000 CPU_TIME/1000000 ROWS_PROCESSED SQL_FULLTEXT bvmtg9n1bss3r 181485174784 120788774976 33.44 5168.205681 2013-07-26/11: 42:53 5.481132 0.113112 3773.585818 0 0 1429.028 102401297 (HUGECLOB) 44y4dvhb12zc0 330356482048 110817408 99.97 3472.110958 2013-07-29/10: 11:35 2.359406 0.128388 3447.086174 0 0 21.973 275 (HUGECLOB) fssqzqq0tsffq 428624363520 7205116688 98,32 3099.086997 2013-07-20: 20: 51:28 0.058573 0.073064 2686.077653 0 0 361.081 40107806 (HUGECLOB) gyy3tk70t5h69 83012501504 70481653440 15.1 3050.021479 2013-08-01/10: 49:44 2.661973 0.000609 279.596557 0 0 2942.207 43649621 (HUGECLOB) fxazp767kzcan 3645325312 6389645208 -75.28 1477.232161 2013-08-05-09: 17:14 0.080002 0.000268 1374.649241 0 0 83.69 754293 (HUGECLOB) 0229k7cwq33aq 51346874368 3062262552 94.04 804.351766 2013-08-02/16: 01:34 1.880049 0,0019 693.156814 0 0 108.625 2005797 (HUGECLOB) the elapsed times are very long and my understanding is that it is the operating time from end to end for queries, is that correct.
But when I run these queries into a toad, the results come back in about a minute or two.
I have also noticed that most of the time is divided between USER_IO_WAIT_TIME and CPU_TIME, I think I understand what is CPU_TIME, but I wasn't quite able to understand what USER_IO_WAIT_TIME is the online documentation.
My question is, the elapsed time is really the end of the query execution time? If so, why do I see CBI? genetically different times when run the queries in Toad manually?
SELECT ELAPSED_TIME/EXECUTIONS AVG IN V$ SQL;
because elapsed_time is a cumulative value
-
Confusion over the memory of a bunch of Java and WLS_FORMS
Hi all
Background first:
Oracle Forms/Reports 11.1.2 64-bit
WebLogic Server 10.3.6
JDK 1.6 update 37 64-bit
Microsoft Windows 2008 R2
Using nodemanager to start/stop the servers managed
After reading all the documentation and searched this forum and the Internet for advice, I'm still totally confused about how best to make use of memory on the server (the server I'm working now on a 8 GB). Two trains of thought that I discovered in my research:
(1) do not change the size of Javaheap at all (stick with the default values) and just create additional managed servers on the same machine.
(2) increase the size of the heap Java for WLS_FORMS
That said, here are my questions:
(A) what is the best practice approach (#1 or #2)?
(B) if it is the #2, what is the approved way to increase the heap size? I tried to add - Xms and arguments - Xmx to the WLS server begin arguments in the WLS console. They are applied when the managed server is started (confirmed in the log file), but because of the way WLS_FORMS is started, there are more - Xms and arguments - Xmx applied after mine, and peaks of Java one last mention if there are duplicates.
1st update: Question #2 seems to be answered by the support notes 1260074.1 (the only place I had not yet looked at)
Thanks for any idea that you can provide. If there is a document that I missed somewhere, I'm happy to be told where it is, and will read and summarize the results here.
Kind regards
JohnJohn,
I'll try to comment on each of your own:
(1) we had been make some type errors "Unable to contact forms Apache Server" (users see the error "Failed to bridge APACHE server"). The logs showed nothing interesting. I increased the memory allocated using setDomainEnv.cmd, and the error seems to have disappeared. Yes, I know it's a shotgun approach, try something without really having a reason to do it, but it seems to have helped Edit: now I have review of OHS logs instead of WLS_FORMS newspapers, I found the log messages, which brings me to Doc 1380762.1, who tells me that I need a patch. DOH. Oh crikey, forms 11.1.2.1 is out and it came out shortly after that we have downloaded 11.1.2.0 to create these environments. Good and the bad new kind of thing...
The Apache Bridge error is relatively in line toward the front if you understand what it is say you. It is an error generated by mod_wl_ohs which is the property of SST (Apache). This module is responsible for the relationship between OSH and WLS. The Apache bridge error means that OSH (mod_wls) has been unable to get a response from the managed server WLS he called. Basically, he was unable to cross the bridge ;) The cause could be anything from the managed server does work not, management server is busiest, or there is a problem of network configuration and the server simply didn t hear appeal of OSH.
It is all described in Note 1304095.1 MOS
Regarding 11.1.2.1, this can be installed fresh or as a patch on 11.1.2.0. So for machines which currently installed, you can go directly to 11.1.2.1 without having to first install 11.1.2.0.
.(2) as tony.g suggested, we are looking for what we should do to solve them "I have n servers with x GB of RAM, what should I do to configure out-of-the-box forms for stability" issue.
As I said, there is really no 'forms' specific settings associated with how much RAM your machine has. The only exception to this is (although a little indirect) to use the grouping of the JVM. JVM pooling can reduce the size of each execution process memory footprint by moving his calls from java to the pool of the jvm, then common queries of sharing with the other running execution environments. Memory, use of OSH or WLS managed server really has nothing to do directly with the forms. Specifically to the managed server, from a perspective of forms, I would not expect the cost of memory of WLS_FORMS spending a large part due to the workload. I'm expecting increase as the simultaneous load increases, but I would not expect it to be significant. If I had to guess, see an increase of 1 m or less per user wouldn't surprise me (that's just a guess - I don't know what would be the expected values). If we were to use our older scalability guidelines (Oracle), usually we would have suggested that you should consider about 100 sessions by 1 FMV for better performance. Given that v11 uses a newer version of java and scalability is better today, I suspect that you can easily spend a couple of hundred (300 for example) or more before the performance decreases. In addition, the need to add more managed servers would be probably necessary.
This is discussed in Note 989118.1 MOS
.(3) HA is important to us, so we set up a cluster of servers of forms/States with a BLT in front of her. I read in the literature on the management of clusters, cloning of a managed server and with the support, how to increase the memory heap for the WLS_FORMS server. My thought process was 'If Oracle gives me instructions on how to increase the heap memory and how clone managed servers, there must be a scenario in which do have advantage." I'm trying to understand the scenarios in which we would do either of these activities.
Refer to the note that I mentioned above. As a general rule, if you limit the number of simultaneous sessions less than about 300-400, I think the default settings should be fine. If you think you want to go beyond 300 or 400 per managed server, then probably you need to increase the heap the managed server max. Yet once again, refer to the note that I mentioned earlier.
See also Note 1260074.1 MOS
.I am aware of the JVM pooling (Yes yell us reports) - I still have to this implementation, but it is on my to-do list.
This is discussed in the [url http://docs.oracle.com/cd/E38115_01/doc.111210/e24477/jvm.htm]Forms Deployment Guide
Hope that helps ;).
-
Consolidate the results of the WORK of DBMS
Hi people,
I understand that we can perform several tasks using DBMS Job. However kindly help me with the following scenario.
I have a procedure/function called get_studentlist (number ENROLL_YEAR); This procedure gives me a value.
On the front-end server by using a report that I would like to get the results of 2010-2011
Then I call
Select testfun (2010) double
Union
Select testfun (2011) double;
Yes using DBMS JOB I was able to run both jobs at the same time. But the question is how to capture the result of both of them.
Even if I store the result in a table (temtable)... a job can finish first, then the other. How long should I query the table?
In short, I'm trying to simulate the concept of thread JAVA using PLSQL.
Thank you
AJYou've posted enough to know that you will need to provide your Oracle version 4-digit (result of SELECT * FROM V$ VERSION).
>
I understand that we can perform several tasks using DBMS Job. However kindly help me with the following scenario.
I have a procedure/function called get_studentlist (number ENROLL_YEAR); This procedure gives me a value.
On the front-end server by using a report that I would like to get the results of 2010-2011
Then I call
Select testfun (2010) double
Union
Select testfun (2011) double;Yes using DBMS JOB I was able to run both jobs at the same time.
>
What are the "two" jobs you are talking about?Your post is very confusing please change to clarify what you are saying.
You are referring to a 'get_studentlist' function, but your example uses a function called "testfun.
You show a query that queries both unions to get two years of data, and it is a request; He won't be back for results before completing the request (either two years of data).
You mention two DBMS_JOBs running, but your example is a simple United request. What two jobs are you talking about?
>
In short, I'm trying to simulate the concept of thread JAVA using PLSQL.
>
You have a query so that the example has nothing to do with threads.If you want to create several jobs and dependencies between them, you must use DBMS_SCHEDULER.
See examples of creating strings in the database administrator's guide
http://docs.Oracle.com/CD/B28359_01/server.111/b28310/schedadmin006.htm#BAJHFHCDNeither DBMS_JOBS nor DBMS_SCHEDULER will allow you to consolidate data from two different jobs. That can only be done by using a table to store data or by using a pipeline that would run two queries and return results one after another.
-
Use two temporary tables to assign 'color' to the results of the data
Hello world... Here's what I'm trying to do, any help is appreciated of course...
Data and Tables in the example:
I have 5 dishes, each course has 2 assignments.
I need each assignment to get a color assigned to it according to its courseID. So my theory is that I have a temporary table with a list of colors; each courseID would be are they assigned a color, but my question is how can I assign each courseID a color without anything to join the temporary table? Once that each courseID has a color, I would join rights holders so that each assignment has a color associated with it according to its courseID.with Courses as ( select 100 courseID from dual union all select 200 from dual union all select 300 from dual union all select 400 from dual union all select 500 from dual ), Assigns as ( select 'test100' name, 100 courseID from dual union all select 'test100', 100 from dual union all select 'test200', 200 from dual union all select 'test200', 200 from dual union all select 'test300', 300 from dual union all select 'test300', 300 from dual union all select 'test400', 400 from dual union all select 'test400', 400 from dual union all select 'test500', 500 from dual union all select 'test500', 500 from dual ) select assigns.name, assigns.courseID from courses inner join assigns on assigns.courseID = courses.courseID
I have a previous post on this topic, but I didn't do well explain and make a link to it would probably add to the confusion to this question... happy to delete this post if someone recommends.--Color table with 6 colors with Colors as ( select 'red' color from dual union all select 'blue' from dual union all select 'yellow' from dual union all select 'green' from dual union all select 'purple' from dual union all select 'teal' from dual )
Thanks for any help! Running Oracle 11 g.Hello
939920 wrote:
I don't have the ability to store the courseID with colors...Can get it, or ask someone with the makeup of capacity change for you.
Is the problem that you have more than 6 courses but you want to add color to them with only 6 colors, and it is unclear what courses can be included in the results of a given query?
If so, you can do somehting like this:WITH colors AS ( SELECT 'red' AS color_name FROM dual UNION ALL SELECT 'blue' FROM dual UNION ALL SELECT 'yellow' FROM dual UNION ALL SELECT 'green' FROM dual UNION ALL SELECT 'purple' FROM dual UNION ALL SELECT 'teal' FROM dual ) , colors_plus AS ( SELECT color_name , ROW_NUMBER () OVER (ORDER BY NULL) - 1 AS color_id , COUNT (*) OVER () AS color_cnt FROM colors ) , course_assigns AS ( SELECT a.name , a.courseid , DENSE_RANK () OVER (ORDER BY a.courseid) AS course_num FROM assigns a INNER JOIN courses c ON a.courseid = c.courseid -- If needed ) SELECT ca.name , ca.courseid , cp.color_name FROM course_assigns ca JOIN colors_plus cp ON cp.color_id = MOD ( ca.course_num , cp.color_cnt ) ;Typical power:
AME COURSEID COLOR_ ------- ---------- ------ test100 100 blue test100 100 blue test200 200 yellow test200 200 yellow test300 300 green test300 300 green test400 400 purple test400 400 purple test500 500 teal test500 500 tealIt would be better if you could create a real table as colors_plus.
If there are more than 6 separate courses in the output, then 2 or more courses can be coded in the same color, but no color will be used N times (N > 1) until all the colors have been used N-1 times.
The assignment of courses coolors is arbitrary. Depending on how fancy you want to do this, you might want to do something more complicated. For example, you have 2 course with 10 lines of each and 5-course dinner with 1 row of each. The query above will have to assign the same color to 2 courses of differenct, and it can assign the color "blue" for 2 courses with 10 rows of each. The query above can be modified, if necessary, assign the colors in order of frequency, in order to ensure that two 10-line courses get different colors, and that the colors tend to be more evenly distributed. I'll leave that as an exercise. (Tip: use the frequency in the clause ORDER BY of DENSE_RANK.) To obtain the frequency, use the COUNT function analytical in a subquery. Why do you need a subquery? Discuss among you). -
Is the result of app.activeDocument.metadataPreferences a XMPMeta object?
Hello again
Hope this isn't a stupid question.
I wondered if the result of
app.activeDocument.metadataPreferences;
is an object of XMPMeta according to "JavaScript Tools Guide.
I would say yes, because I found examples where the previous statement is followed
myDocXMP.setProperty (destNamespace, destNodeName, nodeValue);
But I would also say no, because when I'm looking for
myDocXMP.deleteProperty (destNamespace, 'CreatorTool');
ExtendScript Toolkit, I get an error message saying "myDocXMP.deleteProperty is not a function".
More I read, the more I get confused. Can you help me find a source of information for beginners? Thank you very much.
Giordano
Hello
metadatapreferences does not have a method deleteProperty()
Take a look: http://jongware.mit.edu/idcsjs5.5/pc_MetadataPreference.html
These methods belong to lib: AdobeXMPScript.
It is not as easy to manage as well. Have you tried another tool like exiftool commadline...
-
Select a table returned in the result of the query
Hi, I'm trying to find a way to query a table name that I'm back to a different query. I am doing this in pure SQL and PL/SQL, if I can.
Here's the situation. I have a table called FILES, a table called TYPE and an unknown number of different reference tables with different names.
Each entry in the FILE has a reference to a TYPE id, and each entry type is a varchar that contains the name of a table reference, such as PHOTO_INFORMATION, PDF_INFORMATION or XML_INFORMATION.
I want to be able to extract the data from the reference table for any data file. So with a file id, I question TYPE to get the name of the reference table (IE, "PHOTO_INFORMATION" back) then the request it is at this table for all of its columns, using the reference id in the FILE table.
The thing is that I wish it were generic, so that I can just add an entry to AA_TYPE and a new table for this type, and then I can ask her but I want, through the FILE table. The reason is that there are some data that is common for all files, and I would like to that data in one place.
Here is my paintings, I have two reference tables of the sample to the bottom "AA_FILETYPE1" and "AA_FILETYPE_PHOTO".
Here's an example query I would use:CREATE TABLE "AA_FILES" ( "FILE_ID" NUMBER, "FILE_NAME" VARCHAR2(4000), "FILE_TYPE" NUMBER, "REFERENCE_ID" NUMBER, CONSTRAINT "AA_TEST_FILE_PK" PRIMARY KEY ("FILE_ID") ENABLE ) / CREATE TABLE "AA_TYPE" ( "TYPE_ID" NUMBER NOT NULL ENABLE, "REFERENCE_TABLE" VARCHAR2(4000), CONSTRAINT "AA_TYPE_PK" PRIMARY KEY ("TYPE_ID") ENABLE ) / CREATE TABLE "AA_FILETYPE1" ( "REFERENCE_ID" NUMBER, "DATE_MODIFIED" DATE, "SUMMARY" VARCHAR2(4000), "TOTAL_VALUE" NUMBER(5,2), CONSTRAINT "AA_FILETYPE1_PK" PRIMARY KEY ("REFERENCE_ID") ENABLE ) / CREATE TABLE "AA_FILETYPE_PHOTO" ( "REFERENCE_ID" NUMBER NOT NULL ENABLE, "DATE_TAKEN" DATE, "CAMERA_NUMBER" VARCHAR2(4000), "WEATHER_CONDITIONS" VARCHAR2(4000), "CONSULTANT_NAME" VARCHAR2(4000), CONSTRAINT "AA_FILETYPE_PHOTO_PK" PRIMARY KEY ("REFERENCE_ID") ENABLE ) /
So who withdrew all the columns in the reference given in AA_TYPE table based on an entry in AA_FILES.select * from (select REFERENCE_TABLE from AA_TYPE where TYPE_ID = AA_FILES.FILE_TYPE) where REFERENCE_ID = AA_FILES.REFERENCE_ID;
I'm not entirely sure how to do this, or if this is possible even without using PL/SQL.
I'm open to suggestions on how to achieve what I want with a different design of table, I am a student and I'm not really experienced in database design. (My first design of database class isn't until next year!)
Thank you very much!Hello
[email protected] wrote:
Sorry about the confusion about file_id = 3, I meant the insert in the third I've included. I did not indicate the id_fichier in my inserts since it is the main key and it auto increments.It is important to post of the CREATE TABLE and INSERT statements that work. All those who want to help you to will want to recreate the problem and test solutions. Also, do not use strings for all entries. If the column is a NUMBER, use a NUMBER in the INSERT statement. If the column is a DATE, use a DATE or a function that returns a DATE.
So you should post something like:insert into AA_FILES(FILE_ID, FILE_NAME, FILE_TYPE, REFERENCE_ID) values (1, 'test-photo-1.jpg', 1, 1); insert into AA_FILES(FILE_ID, FILE_NAME, FILE_TYPE, REFERENCE_ID) values (2, 'test-xml-1.jpg', 2, 2); insert into AA_FILES(FILE_ID, FILE_NAME, FILE_TYPE, REFERENCE_ID) values (3, 'test-photo-2.jpg', 1, 2); -- The value file_type=1 immediately above was not in your original data, but seems to be what you meant. prompt ===== AA_TYPE Table: ===== insert into AA_TYPE(TYPE_ID, REFERENCE_TABLE) values (1, 'AA_FILETYPE_PHOTO'); insert into AA_TYPE(TYPE_ID, REFERENCE_TABLE) values (2, 'AA_FILETYPE1'); prompt ===== AA_FILETYPE1 Table: ===== insert into AA_FILETYPE1 (REFERENCE_ID, DATE_MODIFIED, SUMMARY, TOTAL_VALUE) values (1, TO_DATE ('01-01-02', 'MM-DD-RR'), 'An XML file that has some information about something', '14'); prompt ===== AA_FILETYPE_PHOTO Table: ===== insert into AA_FILETYPE_PHOTO (REFERENCE_ID, DATE_TAKEN, CAMERA_NUMBER, WEATHER_CONDITIONS, CONSULTANT_NAME) values (1, TO_DATE ('01-01-01', 'MM-DD/RR'), 'abc123', 'rainy!', 'John Smith'); insert into AA_FILETYPE_PHOTO (REFERENCE_ID, DATE_TAKEN, CAMERA_NUMBER, WEATHER_CONDITIONS, CONSULTANT_NAME) values (2, TO_DATE ('01-01-02', 'MM-DD/RR'), 'def456', 'slightly cloudy', 'Jane Jones'); commit;To give you my workplace, I'm applying in Application Express. A user has entered the number '3' the file_id (I'm not worried about the distinction between passing in the id_fichier and the name of the file, I just my application one application or the other).
Now, run a query that will get related data which table it is stored in. I don't know the name of the table at design time, as that particular file may be of any type (each of which has a different table name). However, with a the file_id, I have a file_type (in aa_files) which refers to an entry in aa_type.
I see. You could add even add new tables after this query is written. As long as the new table has a column named reference_id, and there is a line for the new table in aa_files, the following query should work.
>
select FILE_TYPE from AA_FILES where FILE_ID = 3I stored the name of the table, I need to ask for the rest of the data in aa_type at design time, so using the file_type value, I can get the name of reference_table:
select REFERENCE_TABLE from AA_TYPE where FILE_TYPE = 1In the sample data, you have validated, Type_de_fichier = 2 on the 3rd row. I've changed that in my example 1 revised data.
Be very careful that your explanation fits your data. You talk to people who know about your application, and it is very easy for them to be induced in error or confusion.Now the '1' is here that the first query would return. I would like to use a subquery to combine these two queries into a single (I think?). This second query would return "AA_FILETYPE_PHOTO", which is the reference table.
So I have the reference table, which is a name of table to another table in my database. It contains the data that I'm actually looking for. I want it for this particular file (file_id 3), and in aa_files, I have a value of "reference_id", which refers to the respective line in the reference table. File_id 3, the reference_id is 2.
select * from AA_FILETYPE_PHOTO where reference_id = 2If the above query gets me my final data.
Now, I've been watching substitution values and bind variables, here's another way to explain what I want:
Explanation step by step below is very useful. It would be more useful if each step uniquely and gavce movement results given the sample data and an example of setting (3 in this case)
-- get the file_type from aa_files for the desired file EXEC :file_type := (select file_type from aa_files where file_id = 3);That we will call the step step (a) above.
Step (a) sets: Type_de_fichier 1 (given my corrected sample data)-- get the reference table from aa_types using the file_type EXEC :reference_table := (select reference_table from aa_type where type_id = :file_type);That we will call the step step (b) above.
(B) sets the stage: reference_table to 'AA_FILETYPE_PHOTO '.-- get the reference_id from aa_files for the desired file EXEC :reference_id := (select reference_id from aa_files where file_id = 3);That we will call the step step (c) above.
(C) sets the stage: reference_id 2-- using the reference table and reference id for the desired file, get the rest of the data select * from :reference_table where reference_id = :reference_id;Not sure if this makes it more clear or not.
Yes, it helps a lot.
Basically I have a table full of table names. How do I write a query that pulls one of these table names and it then queries?
You need SQL dynamic, because you can't hardcode a table name in the query that you normally would be.
How dynamic SQL works normally (and the functioning of this example) are that the query is built by using a variable. In SQL * more (as shown below), you can simply use a variable substitution instead an identifier hardcoded, and that's what it takes to make the dynamic query from SQL * more resolves the substitution variables before sending the code for the compiler. I don't know much on the Apex, but I bet there's some way to do dynamic SQL in the Apex, too.
So the dynamic part here should include step d, since you can't hardcode the name of the table in the query.
Until we can step (d), then, did they to us to do the steps (a) and (b) to obtain this file name. In the example blelow, I used a separate, preliminary request to get the & table_name...
Step (c) could be made in the main query, using a subquery or a join. However, I chose to step (c) in the preliminary motion, as well as steps (a) and (b), since it's the same table same step (a). In this way, step (d) must refer to a table.Here's (finally) how to make this work in SQL * more:
ACCEPT file_id PROMPT "Enter the file_id (a number, e.g. 3): " -- Preliminary Query, to set table_name COLUMN reference_id_col NEW_VALUE reference_id COLUMN table_name_col NEW_VALUE table_name SELECT f.reference_id AS reference_id_col , t.reference_table AS table_name_col FROM aa_files f JOIN aa_type t ON f.file_type = t.type_id WHERE f.file_id = &file_id ; -- Main Query SELECT * FROM &table_name WHERE reference_id = &reference_id ;The results, account required to the data from the sample I posted above, and the & file_id 3, are:
` CAMERA_ WEATHER_ CONSULTANT_ REFERENCE_ID DATE_TAKE NUMBER CONDITIONS NAME ------------ --------- ---------- --------------- --------------- 2 01-JAN-02 def456 slightly cloudy Jane Jones -
Confusion over the link with ColdFusion 8
I'm a little confused on the BIND methodologies to do what I do (and I'm sure we can do).
I have a series of two RADIO for option 1 (let's say option 1 A of the value and the value B) and another series of two RADIO for option 2 (say option 2 A and B of value value) (see my code included).
I want to make is that the user is selected, option 1-A, I selected option 2-A and vice versa; If the user selects option 2-A, the system should automatically, choose the 1.-a option. It also works for option 1-B with 2-B option.
I hope that I am clear in my question. Otherwise, feel free to let me know.I'm sorry for the confusion, but maybe I'm too deeply reflective about the BIND because what I wanted to do can be easily done with JavaScript!
OnClick on the CFINPUT RADIO can call a JS function to check and control what to see on the other set of options.
One day, we receive more on our shoulders and the result is that our brain get confused! ;-))
-
How to bind the result of research on the cells of another graph
IN numbers, is it possible to have the result of any formula of no matter where you want to stay to appear. So if you change your figure the new result
Hi JStan,
Just guessing, but you are creating an interactive chart?
Take a look in the template chooser to draw the basics:

Go to the interactive chart spreadsheet (tab).
If that does not meet your needs, you can create your own interactive chart using the VLOOKUP function.

Formula in B2 of the chart data table (and the right to fill)
= VLOOKUP($A2,Weekly Data::$A$2:$H$5,2,FALSE)
That retrieves data from the table of weekly data according to the value that you type in A2. These data become graphic entry.
Here is the data for the chart with 2 typed in A2

Happy dialing!
Kind regards
Ian.



Maybe you are looking for
-
When I'm not able to use the video stream on the BBC website.
At the same time, I was able to use the video stream on the BBC website. I am more able to do. However, I use the video streams on other news sites.
-
Installation of printer on the new laptop
Buy HP Pavilion dv7. Unable to connect laptop printer all-in-one HP Officejet; have the drive... but the drive does not list Windows 7. What is my problem?
-
Change the inventory on a T430i number.
I tried the following applications: Using the latest bios package: winflash32.exe - patch - dat ''. winflash32.exe - patch - dpc ''. These say they write in the BIOS and reboot the PC, but no settings are actually saved. With the help of the WinAIAPa
-
I get a flag in the task bar that has a red box attached to it and inside the red zone are a white x. When I click on it it takes me to the center of action and say it detected one or more problems. I tried to solve this problem, but it keeps popping
-
I installed windows 8 pro and keep getting profapi dll missing
all software I won't update the update won't let me run it all I can do is save it. Then, when I try to run I wonder what program to use to start with or it will try to install it and I get missing dll profapi reinstall program. I didn't kno w what p