Conversion of an array of unique column in a table of two columns
Hello worldWhat I'm trying to do is to convert a single column table in a table with two columns. Here is an example:
Table (column):
ID1
ID2
ID3
ID4
ID5
Table B (two columns) must be:
ID1 ID2
ID3 ID4
ID5
I've been browsing through a cursor and do an insert every 2 rows, but do not like performance.
Is there a more easy/fast way to do this?
Thanks in advance
Oscar
with t as (
select 'ID1' col1 from dual union all
select 'ID2' from dual union all
select 'ID3' from dual union all
select 'ID4' from dual union all
select 'ID5' from dual
) -- end of sample table
select col1,
col2
from (
select col1,
lead(col1) over(order by col1) col2,
row_number() over(order by col1) rn
from t
)
where mod(rn,2) = 1
/
COL COL
--- ---
ID1 ID2
ID3 ID4
ID5
SQL>
SY.
Tags: Database
Similar Questions
-
Unique column index index composite vs
Hello
I have a table with a, b, c, d, e, f, g, h, i, j, k columns and I have an index on columns a, b!
There is a sql statement now with where a =? and one wonders if it could also be good to add a unique index on just 'a' column!
does not AT ALL help? It does not help in SOME CASES? or?
What do you think??
Thank you!
/ Hesi
HeSi9466 wrote:
I think, in general when you have a composite index as (a, b) and you have a query as where a =? Then, this composite index is sufficient and you don't need to also add a unique index.
But... I think that this response CANNOT be a final answer for all possible combinations of data.
For example, if the leader index column (a) has a low number of distinct values and the second column (b) index has a large number of different values then a query that seeks where a =? could be better with a single (one) index a column.
My point is, it must be tested and could not say NO, UNIQUE INDEX number IS NECESSARY at all.
The basic answer is that you need NOT the index of single column if you have the index on two columns.
The answer is complex, is that you may need to spend some time and effort to ensure that the index of the two columns is used in all cases where it would have been appropriate to use single-column index. This can average simply ensuring that the clustering_factor in the index is adjusted properly so that the optimizer 'love' the index enough and/or you need to change code to use the cluster_by_rowid indicator (when you are 12 c) so that you do not suffer a running performance impact.
Key factors: the index of the two columns will be physically larger than the single column index - this will increase the (optimizer estimated) operating costs; the index of two_column clustering_factor will almost certainly larger than the single column index clustering_factor - this will also increase the (optimizer estimated) cost of its use. Both of these echo run time: two column index will be bigger, then you will have to do more work to read the relevant ROWID, and if you walk two-column index in order for a given value of the first column, you will visit the blocks to the table in a different order from the order of the visits of the unique column index - this can lead to the application doing more work running.
The variation in counts of leaf_block index is often negligible (especially if, as per your example, the number of lines - blocks so in the table - is large); the impact of the clustering_factor can make a huge difference for the calculation of costs; but you can often work around this problem. In 11.2.0.4, in particular, you can use the dbms_stats.set_table_prefs () call to set the parameter "table_cached_blocks" a table for all of its indexes seem more desirable to the optimizer.
Bottom line - you have not the single column index, but if you have it and want to break down human effort needed to do so that it can be placed without side effects can make you decide to keep in any case, especially if it seems not be the cause of any competition or other overhead of performance. If you haven't yet, then you should not need to create.
Concerning
Jonathan Lewis
-
Validation for combinations of unique columns in a report
Hello
I have a form on a Table with report 'C' (columns C1_pk, A1_fk, B1_fk) where I connect the primary keys of the table (columns A1_pk, A2, A3) 'A' and 'B' (columns B1_pk, B2, B3) table.
I want to create a Validation process to have combinations of single column for the table C.
Basically, table A represents users, table B represents groups, table C assigns users to the groups. I need a validation to avoid duplication of Group of users associations in table C.
My form table C has just 2 LOV points (P11_A, P11_B) to call A table and values in table B, I need a validation process after 'create' button click, but I do not know how to write code.
Any suggestion please?
Thank you
K
Jesse wrote:
I have a form on a Table with report 'C' (columns C1_pk, A1_fk, B1_fk) where I connect the primary keys of the table (columns A1_pk, A2, A3) 'A' and 'B' (columns B1_pk, B2, B3) table.
I want to create a Validation process to have combinations of single column for the table C.
Basically, table A represents users, table B represents groups, table C assigns users to the groups. I need a validation to avoid duplication of Group of users associations in table C.
My form table C has just 2 LOV points (P11_A, P11_B) to call A table and values in table B, I need a validation process after 'create' button click, but I do not know how to write code.
Any suggestion please?
I suggest you:
- Add a unique constraint on the table C for (A1_FK, B1_FK) to make sure that the table cannot contain duplicates.
- Instead of validation, it is easier to use to prevent the selection of existing combinations. Create the P11_B element under a shuttle, so that users cannot select a group more than once.
-
Interactive report - is possible to find and change if necessary the unique column.
While creating an interactive report, I accidentally entered the wrong "single column" on the sql query page. Is it a big problem and how do I find and change if necessary.
33ac2d45-960f-45AF-acba-507f01d18e08 wrote:
Please update your forum profile with a real handle instead of '33ac2d45-960f-45af-acba-507f01d18e08 '.
While creating an interactive report, I accidentally entered the wrong "single column" on the sql query page. Is it a big problem and how do I find and change if necessary.
Query Builder Link to the simple view row Yes No Uniquely identify lines Single column ROWID Single column Yes. You can change this using the only the lines identified by / Unique column interactive properties in the section of the column of link in the attributes of the report definition report tab.
-
How to create a table with two unique columns
How to create a table with two unique columns. I use the following syntax below and I get the error message such unique or primary key already exists.
create the table COPQ_WORKCELL_GOAL
(
Type_id varchar2 (4) NOT NULL UNIQUE,
Tyle_Location varchar2 (30) NOT NULL UNIQUE,
Type_Description varchar2 (20).
KEY elementary SCHOOL (Type_id)
);Use 1 or the other column type_id;
create table COPQ_WORKCELL_GOAL ( Type_id varchar2(4), Tyle_Location varchar2(30) NOT NULL UNIQUE, Type_Description varchar2(20), PRIMARY KEY (Type_id) ); Table created drop table COPQ_WORKCELL_GOAL; Table dropped create table COPQ_WORKCELL_GOAL ( Type_id varchar2(4) primary key, Tyle_Location varchar2(30) NOT NULL UNIQUE, Type_Description varchar2(20) ); Table created -
kindly tell how to use the unique value of a table with the index 0
kindly tell how to use the unique value of a table with the index 0
Hi
Yep, use Index Array as Gerd says. Also, using the context help (+ h) and looking through the array palette will help you get an understanding of what each VI does.
This is fundamental LabVIEW stuff, perhaps you'd be better spending some time going through the basics.
-CC
-
How to get into two different tables in two columns of a listbox of multi column
Hi all
I have two different tables of the values assume that table 1A (1,2,3,4,5) and another table B (3,4,5,6,7). I want to write these tables in a multicolumn listbox such as 1st column would be A array and 2nd column table B.
Thnx in advance
Saki,
I hope this helps to further
-
I tried several ways to date.
I know that I can use the building to create a table of two numbers but I am not able to create a 2d in this way
I also tried to use Replace subset of table, but still it won't work.
I know that I have to use a table that has the index of the column starting with 0, so whenever I press the button of the column index incriments by 1 so the next column will change but I am not able to create this.
You are the authority on what a Altenbach! He writes, I just did to make it work. Don't really consider this. Here's a modified version for the OP to use should he like:
-
Can break us af:table in two columns as panelformlayout display?
Mr President.
Can break us af:table in two columns as panelformlayout display?
Concerning
And the two group must be vertical, m I right?
you want to like this-
Column1 Column2 Column3
column4 column 5 column6
You can't do that with an af:table that you can do is remove two tables same viewObject, sharing the same iterator and take a few columns in the first table years based in the second table and then surround the two tables with a layout of the Panel group (vertical)
or take a look at the id of the pivot table, it fits in your case.
http://docs.Oracle.com/CD/E12839_01/Web.1111/b31973/dv_crosstab.htm#ADFUI3073
Ashish
-
Why we cannot create more than one primary key on a table. Why we create several unique key on a table. Please explain if anyone have details of this.
«a primary key has semantic meaning, it is to be immutable (never change of value), unique and not null.»
a unique constraint is simply "at any time, these values are unique - they can change and they can be null.
You use a unique when constraint
(a) you do not already have a primary key for a table can have only one
(b) you allow NULL values in attributes
"(c) to allow you to update the values in the attributes.https://asktom.Oracle.com/pls/Apex/f?p=100:11:0:P11_QUESTION_ID:5541352100346689891
-
ORA-02266: permit to unique/primary keys in table referenced by foreign keys
Hello
I'm trying to delete data from a table by dropping a partition. I've identified all the child tables by running the following command.
Select "select count (*) from ' |" table_name |' where employee_id = 100; »
of dba_constraints
where constraint_type = 'R '.
and r_constraint_name in
(select constraint_name from dba_constraints
where constraint_type in ('P', 'U') and table_name =' EMPLOYEE);
"SELECTCOUNT (*) OF | TABLE_NAME | "WHEREEMPLOYEE_ID_ID = 100; »
-----------------------------------------------------------------------------------------------
Select count (*) in the PT_ORDERS where employee_id = 100;
Select count (*) in the PT_DEP where employee_id = 100;
Select count (*) in the PT_SKILLSET where employee_id = 100;
I dropped the score for number 100 in all child tables. The count (*) select returns 0 rows for each of the foregoing.
When I try to run the command on the EMPLOYEE table, below I get ' ORA-02266: unique/primary keys in table referenced by foreign keys enabled.
Drop partition ALTER table EMPLOYEE EMP_ID_100;
I don't see why I am unable to give up this partition now because it is data child present in any of the referenced tables. Any suggestions or help on this would be greatly appreciated.
Thank you.
RGS,
RobYou must first disable foreign key constraints and delete the partition. Deletion of lines or a fall in childs partitions do not work in this case
as you have the overall dependence:
SQL > create table scott.t (x int primary key, int y)
2 partition by (list (y)
3 values p_1 (1) partition, partition values p_2 (2))
4.Table created.
SQL > create table scott.t_c (x int references scott.t (x), int y)
2 partition by (list (y)
3 values p_1 (1) partition, partition values p_2 (2))
4.Table created.
SQL > insert into scott.t values (1,1)
3 N1 line of creation.
SQL > insert into scott.t values (2,2)
3 N1 line of creation.
SQL > insert into scott.t_c values (1,1)
3 N1 line of creation.
SQL > insert into scott.t_c values (2,2)
3 N1 line of creation.
SQL > commit;
Validation complete.
SQL > alter table scott.t_c drop partition p_2.
Modified table.
SQL > alter table scott.t drop partition p_2.
ALTER table drop partition p_2 scott.t
*
ERROR on line 1:
ORA-02266: permit to unique/primary keys in table referenced by foreign keysSQL > select constraint_name from dba_constraints
2 where owner = 'SCOTT' and constraint_type = 'P '.
3 and table_name = 't';CONSTRAINT_NAME
------------------------------
SYS_C0011058SQL > select constraint_name from dba_constraints
2 where owner = 'SCOTT' and constraint_type = 'R '.
3 and r_constraint_name = "SYS_C0011058";CONSTRAINT_NAME
------------------------------
SYS_C0011059SQL > alter the constraint to disable scott.t_c table SYS_C0011059;
Modified table.
SQL > alter table scott.t drop partition p_2.
Modified table.
SQL > alter table scott.t_c enable novalidate constraint SYS_C0011059;
Modified table.
I guess you should consider options such as partitioning Referencial (with some restrictions).
Best wishes
Dmitry. -
ORA-02449: unique/primary keys in table referenced by foreign keys
SQL > create table empinformation
() 2
primary key pk_empinformation number (6) 3 forced mobileno
4 address varchar (100),
5 salary number (10),
6 personalid varchar (10) constraints fk_employees_section references employee (emp_id));
Table created.
SQL > drop table empinformation;
ORA-02449: unique/primary keys in table referenced by foreign keyssolution
This error happens when the foreign key of a table is referenced by the primary key of the other table.
If you want to remove the table had refernce key then, you must
need to remove this table with the foreign key is referenced.or
SQL > drop table EMPLOYEE CASCADE CONSTRAINTS;
Deleted table.This will remove the table parent without droping the child table.
Published by: Ritesh Singh October 3, 2011 14:04
-
Fill a table with two columns using a custom bean
Hello
Can you provide me or give me a link to an example of populating a table (with two columns) with a custom bean?
Thank you
TSPSHello..
I'm Jules Destrooper is what you wanthttp://download.Oracle.com/docs/CD/E18941_01/tutorials/jdtut_11r2_36/jdtut_11r2_36.html
Hopes, will help you
-
Number of unique key in a table column
Hi all...
Please help me with this problem. Looking for the number of threads, but could not understand how do.
I have a master form / retail users (main table) and responsibilities (detail table).
The problem is with the table Details (responsibilities), the detail is "" "FORM TABULAR" ".
A user can have the following responsibilities RESP1, RESP2, RESP3, RESP4 (it's a '' select list' ")
When the administrator creates users, they will strike "" Add line"," once they choose a responsibility of the selection list.
When they hit add line once again, "'chosen responsibility should display in the selection list.
EX: when they select RESP "RESP1' in the first row, if they hit add line once again,"RESP1"does not present it as an option for users to select.
EX: If the user already has an RESP "" RESP3"" in the database, "'' RESP3" ' should not display if they try to add another RESP.
Each select list should display different values depend on the values they have chosen so far *.
-> we can put constaint unique key on this column or put validation on this page, but I'm looking for the implementation
Please check the following application example:
http://Apex.Oracle.com/pls/Apex/f?p=42177
Please help me in this task
Thank youThere is no way to declaratively in the Apex to do this.
In version 4.x:
1. There is no declarative way to dynamically filter a list of values in a tabular presentation. For each line, the LOV is actually pre-built on a hidden row zero when the page first appears.
2. to do this, you will need to come up with a process, possibly including AJAX, to fill an array of values to the selection list, delete the values in the table if they have been selected on the other lines of the page and then re - fill the selection on the new list online.In version 3.x:
1 lines are stored in the database every time that you add a row (actually the page saves and repainted with a new line). You can set your LOV SQL to return the values valid less those already stored in the database that the user adds lines.
2. However, that won't necessarily work 100% if you look at a page with several lines already on it and want to update the existing lines and you need in any case a sort of validation or a unique constraint.It is not impossible, but it's very very labor intensive and maintainability is more difficult if another developer a year or two down the road to inherit this page you.
I'd really like to tell your business analyst or key functional end users what they ask for is not supported by Apex first review (and to tell you the truth, it is indeed non-supported, so you are not lying down or fake apology) and they consider like allowing more traditional validation via a unique constraint and page validation.
-
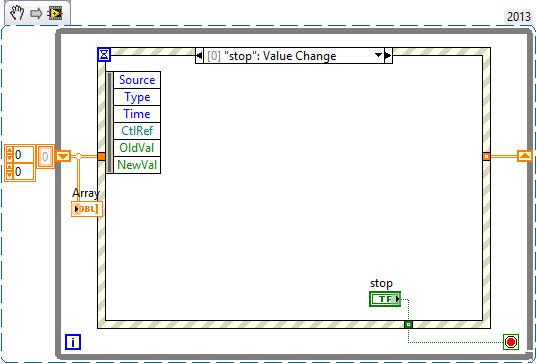
resize unique columns of table front panel
I have a bunch of columns on my front and some of them contain lon channels, while others have only a maximum of 2-3 strings in them.
I'm looking for a way to resize each column without resizing all the others at the same time. If I have them all the same length and the length of the string max I get the table is much too large to fit on the screen space and navigation in labview VI leaves much to be desired.
His cosmetic event but would help me see clearer information and as the information are all locked in long strings his does not work well with what im doing then.
Watch multicolumn ListBox or tables. They allow the customization of the column widths and are specially designed for user interfaces. Protect your data in a table to the schema for the treatment, but the indicators on the front panel.
Lynn
Maybe you are looking for
-
I can't right click or click firefox, or one of the menu buttons. If I disable the Add-ons, it works fine. How can I fix it?
-
Satellite U940 PSU6VA - Dual boot with Ubuntu based distributions
_ * My specifications: * _* Model: * Toshiba Ultrabook (Satellite PSU6VA - 00S 002 U940)* Operating system: * Windows 8.1 x 64 (upgrade of Windows 8 x 64) I would like to set up my computer to dual boot with Windows 8.1 (x 64) and Zorin OS 9.1 (64-bi
-
repair don't win 7vwith no disc
First win 7 stped connect to my network. A guy started LENGTH cords around, did not help. Said driver Realtek PCI Controller Family was missing. Then he stopped booting at all. When it srted, I had a choice of restore oer resumed, he would try to g
-
Entry of Chinese language of blackBerry Smartphones
I just bought a bb9790 without BES/BIS to T-mobile (Holland). I would like to install the Chinese language input on my device. I tried to download the software for the device of a Hong Kong and Singapore according to the carrier, but the apploader sh
-
"Couldn't administration tool load Essbase pilot. Please check the configuration.
Dear all,We are facing problem in OBIEE administration tool while creating the new repository by selecting the data source as Essbase. And also, we shared the document that contains the steps made by us to solve this problem.Question in the selection