Conversion of column to the lines
HelloI'm currently building and SQL to convert columns from several lines to all lines - see below the test data and the expected result:
CREATE TABLE XX_TEST (NAME VARCHAR2 (10), A1 VARCHAR2 (10), A2 VARCHAR2 (10), A3 VARCHAR2 (10), A4 VARCHAR2 (10), A5 VARCHAR2 (10));
INSERT INTO XX_TEST VALUES('LIST','A','B','C','D','E');
INSERT INTO XX_TEST VALUES('L1','1',,'3',,);
INSERT INTO XX_TEST VALUES('L2','1','5','4',,);
ENGAGE
SELECT * FROM XX_TEST;
Expected result:
NAME is the table XX_TEST column, but the COLUMN and the VALUE are converted to lines - columns
NAME THE COLUMN VALUE
L1 A1 1
L1 A2 NULL
L1 A3 3
L1 A4 NULL
L1 A5 NULL
L2 A1 1
L2 A2 5
L2 A3 4
L2 NULL A4
L2 A5 NULL
Thank you
BS
Hello
user13409900 wrote:
Thank you Alex and Frank,
Don't foget Aketi!
The two ways are really good and functional in my situation.
I apologize for not giving version: I'm on 11g so I think that can use Unpivot. It would be really more faster (performance given the volume of data) to use unpivot characteristic of 11 g?
If there is no significant difference, whereas I think is that SELECT... UNPIVOT would be faster. It is purely a guess. It depends on several factors, including your data, your index and your machine. I don't have access to one of them.
Try both ways and compare performance. (Compare the results, too, to check that the two qiueries are really doing the same thing).
If you need help, see this thread:
HOW to: Validate a query of SQL statement tuning - model showing
I've never used before unpivot.
This sounds like a good opportunity to learn.
Tags: Database
Similar Questions
-
Custom script in RPO making empty columns in the line items during the training.
Hello friends,
its URGENT! need help.
We have a requirement of the company in the case of the currency 'EUR', it should delete the dot (.) and replace the comma (,) with dot (.) and other currencies it must remove the comma from columns, quantity, price per unit and Total.
For example:
For "EUR" 2.123,00 and it must convert it to 2123.00 and 2.123 must convert 2123.
"USD" 2.123,00 to convert to 2.12300 and 2 123 to convert to 2123.
This requirement, we wrote a custom script User Exit (UserExitLineItemValidate) function and call that function in line item validation.
but after having formed the invoices for currency 'EUR' by supervised and learning check (SLV), it removes the values in the column quantity, unit price and Total.
and if we remove the script, train and then reapply custom script it works but not always.
My Script:
Public Sub UserExitLineItemsValidate (pWorkdoc As SCBCdrPROJLib.SCBCdrWorkdoc, pValid As Boolean)
' User exit is called at the end of the Document_Validate on the class "bills".
Dim strQuantity As String
Dim strUnitPrice As String
Dim strTotal As String
Dim lngRow As Long
Dim pTable As SCBCdrTable
Set pTable = pWorkdoc.Fields ("LineItems"). Table (pWorkdoc.Fields("LineItems"). ActiveTableIndex)
If fnIsVerifier and pWorkdoc.Fields ("Currency"). Text = "EUR" Then
For lngRow = 0 To pTable.RowCount - 1
strUnitPrice = pTable.CellText ("unit price", lngRow)
If InStr (strUnitPrice, ".") > 0 and InStr (strUnitPrice, ",") > 0 Then
strUnitPrice = Replace(strUnitPrice,".","")
strUnitPrice = Replace(strUnitPrice,",",".")
pTable.CellText ("unit price", lngRow) = strUnitPrice
ElseIf InStr (strUnitPrice, ",") > 0 Then
strUnitPrice = Replace(strUnitPrice,",",".")
pTable.CellText ("unit price", lngRow) = strUnitPrice
End If
strTotal = pTable.CellText ('Total', lngRow)
If InStr (strTotal, ".") > 0 and InStr (strTotal, ",") > 0 Then
strTotal = Replace(strTotal,".","")
strTotal = Replace(strTotal,",",".")
pTable.CellText ('Total', lngRow) = strTotal
ElseIf InStr (strTotal, ",") > 0 Then
strTotal = Replace(strTotal,",",".")
pTable.CellText ('Total', lngRow) = strTotal
End If
strQuantity = pTable.CellText ("quantity", lngRow)
If InStr (strQuantity, ".") > 0 Then
strQuantity = Replace(strQuantity,".","")
End If
If InStr (strQuantity, ",") > 0 Then
strQuantity = Replace(strQuantity,",",".")
End If
pTable.CellText ("quantity", lngRow) = strQuantity
Next LngRow
On the other
For lngRow = 0 To pTable.RowCount - 1
strTotal = pTable.CellText ('Total', lngRow)
If InStr (strTotal, ",") > 0 Then
strTotal = Replace(strTotal,",","")
pTable.CellText ('Total', lngRow) = strTotal
End If
strUnitPrice = pTable.CellText ("unit price", lngRow)
If InStr (strUnitPrice, ",") > 0 Then
strUnitPrice = Replace(strUnitPrice,",","")
pTable.CellText ("unit price", lngRow) = strUnitPrice
End If
Next LngRow
End If
End Sub
At a very high level of control, (and I can't currently that take a long time to respond)
- You do this on EVERY invoice, and not only those that you are sub classification (which means "documents that you are training"). Is your intention to assign all invoices or only those formed?
- In your code, you have the test as shown condition "If fnIsVerifier and pWorkdoc.Fields("Currency").» Text = "EUR" Then".» You are in essence saying the system ONLY evaluate this condition if the system determines if the application Verifier is running. What is the desired effect? Otherwise if the auditor is never used on this document, and the table of line items is never changed, this code would never trigger.
-
transpose the data in the column to the line
I want to change the columns in lines, my data is
TYPE RANK 1 A 1 AA 1 AAA 2 B 2 BB I want it in
RANK (1) RANK (2) A B AA BB AAA Please help me
Thanks for the response guys, in the meantime, I found the solution too
SELECT MAX(CASE WHEN ID=1 THEN RATING ELSE NULL END) AS RC,
MAX(CASE WHEN ID=2 THEN RATING ELSE NULL END) LAUGHED
FROM (SELECT ID, RATING, ROW_NUMBER() over (ORDER BY rowid ID PARTITION) RN)
OF RANK_TEST) X
GROUP BY RN;
Thank you very much
-
Works with tables/columns of the lines and the parameter names... syntax help
I am trying to create a function that returns the distinct value and counts of a user defined schema/table/column.
The code below defines a [stats_on_column_obj] object type and creates a single table of this type [stats_on_column_tab].
The function is supposed to take three input variables: p_schema_name, nom_table_p, p_column_name and return an array (above).
I can hardcode a select into (the)... but once I try to convert it into settings & immediate exec I'm stuck. The red section is where the problem is (I think).
Oracle 10g.
Stats_on_column_obj CREATE TYPE IS OBJECT (
COL_VAL VARCHAR2 (500),
NUMBER OF COL_VAL_CNT (7)
);
CREATE TYPE Stats_on_column_tab IS TABLE OF stats_on_column_obj;
FUNCTION to CREATE or REPLACE get_STATS_ON_COLUMN
(
p_schema_name IN varchar2,
nom_table_p IN varchar2,
p_column_name IN varchar2
)
RETURN STATS_ON_COLUMN_tab
IS
l_STATS_ON_COLUMN_tab STATS_ON_COLUMN_tab: = STATS_ON_COLUMN_tab ();
n INTEGER: = 0;
str_select_tbl varchar2 (5000);
BEGIN
str_select_tbl: = 'SELECT'. p_column_name |' as col_val, count (*) as col_val_cnt FROM ' | p_schema_name |'. ' || nom_table_p: ' group of ' | p_column_name;
FOR r IN (str_select_tbl)
LOOP
l_STATS_ON_COLUMN_tab. EXTEND;
n: = n + 1;
l_STATS_ON_COLUMN_tab (n): = STATS_ON_COLUMN_obj (r.col_val, r.col_val_cnt);
END LOOP;
RETURN l_STATS_ON_COLUMN_tab;
END;
/
[Error] PLS-00103 (124:4): PLS-00103: encountered the symbol "LOOP" when expecting one of the following numbers: * & - + / at rem rest mod.. < an exponent (*) > | multiset year DAY_
[Error] PLS-00103 (126:9): PLS-00103: encountered the symbol "=" when expected in the following way: constant exception < an ID > < a between double quote delimited identifiers > double Ref table Fedya Chariot of time timestam
[Error] PLS-00103 (127:29): PLS-00103: encountered the symbol "
[Error] PLS-00103 (128:4): PLS-00103: encountered the symbol "END" when waiting for one of the following numbers: begin function package pragma procedure subtype type use < an ID > < a double quote delimited identifier > form
SELECT * FROM TABLE (get_STATS_ON_COLUMN ('SCHEMAS_X', 'TABLE_X', 'COLUMN_X'));
Scott@ORCL > CREATE OR REPLACE
FUNCTION get_STATS_ON_COLUMN () 2
3 p_schema_name IN varchar2,
4 nom_table_p IN varchar2,
5 p_column_name IN varchar2
6 )
7 STATS_ON_COLUMN_tab of RETURN
8 EAST
9 v_STATS_ON_COLUMN_tab STATS_ON_COLUMN_tab: = STATS_ON_COLUMN_tab ();
10 v_n INTEGER: = 0;
11 v_str_select_tbl VARCHAR2 (5000);
BEGIN 12
13 v_str_select_tbl: = ' SELECT stats_on_column_obj (' | p_column_name |) ', Count OF ' |
14 p_schema_name | '.' || nom_table_p | "Group of" | p_column_name;
15 v_str_select_tbl EXECUTE IMMEDIATE
COLLECTION IN BULK 16
17 IN v_STATS_ON_COLUMN_tab;
18 RETURN v_STATS_ON_COLUMN_tab;
END 19;
20.The function is created.
Scott@ORCL > select *.
2 from table)
(3 get_STATS_ON_COLUMN)
4 'SCOTT',
5 'EMP',
6 'JOB'
7 )
8 )
9.COL_VAL COL_VAL_CNT
-------------------- -----------
CLERK 4
SELLER 4
PRESIDENT 1
MANAGER 3
ANALYST 2Or better change function in the pipeline.
SY.
-
I have this result of the query;
Select col1 from
T1;
col1
-------
2
3
4, 6
5,1,7
I want the result to be like this
col1
----------
2
3
4
6
5
1
7
I'm new in 10g, please helpThanks to Peter ;)
Re: Simple Question: how to divide the string into multiple lines concatenated?SQL> with t1 as ( -- generating sample data 2 select '2' col1 from dual union all 3 select '3' from dual union all 4 select '4,6' from dual union all 5 select '5,1,7' from dual 6 ) 7 -- 8 -- actual query 9 -- 10 select regexp_substr(col1,'[^,]+',1,s2.column_value) 11 from t1 12 , table ( cast ( multiset(select rownum rn from dual connect by rownum <= length(col1) - length(replace(col1, ',')) + 1) 13 as sys.dbms_debug_vc2coll 14 )) s2 15 / REGEXP_SUBSTR(COL1,' -------------------- 2 3 4 6 5 1 7 7 rows selected. -
error 103 to the column of the line 6 17
Hi all
brand new m forms of oracle, using oracle forms 6i
m using this code
BEGIN
IF
: OVERALL. FABRIC = "BUY" THEN
GO_BLOCK ('PURCHASE_ORDER');
ON THE OTHER
: OVERALL. FABRIC = "BUSINESS" THEN
GO_BLOCK ('LOOMS_CONTRACT');
ON THE OTHER
: OVERALL. FABRIC = 'KNITTING' CAN
GO_BLOCK ('KNITTING_CONTRACT');
END IF;
END;
where is the error please do some need full.
thnks.
Published by: 940133 on June 26, 2012 21:42
Published by: 940133 on June 26, 2012 21:47Try this
BEGIN IF :GLOBAL.FABRIC = 'PURCHASE' THEN GO_BLOCK('PURCHASE_ORDER'); ELSif :GLOBAL.FABRIC = 'LOOMS' THEN GO_BLOCK('LOOMS_CONTRACT'); ELSif :GLOBAL.FABRIC = 'KNITTING' THEN GO_BLOCK('KNITTING_CONTRACT'); END IF; END; -
Need help for the conversion of the lines in columns
Hi all
I have a table with 2 columns.
colId value
1 aaa
2 bbb
3 ccc
1 ddd
Eee 2
3 fff
I want to store the data in the table above in another table that has 3 columns.
col1 col2 col3
AAA bbb ccc
DDD eee fff
I am pivot query. But I don't get it properly. Help, please.
I have Oracle Database 11 g Enterprise Edition Release 11.1.0.6.0 - 64 bit Production
Thanks in advance,
Girish G
Published by: Girish G July 28, 2011 01:28Girish G wrote:
Hey Tubby,Let me explain the real-world scenario.
I'm the external source CLOB data in oracle stored procedure.
The data are coming in the form below.
col1 # | #col2 # | #col3 ~ | ~ col1 # | #col2 # | #col3 ~ | ~ col1 # | #col2 # | #col3
# Here. #-> is the column delimiter.
and ~ | ~-> is the line delimiter.I want to store these data in a table that has 3 columns.
My approach was to extract the data for each column and store it in a temporary table in separate lines. Then move the data from the temporary table to the destination table.
Are there other alternatives for my requirement? Please suggest.
Thank you
Girish GMuch better when you show us the context like that.
It's late and I have sleepiness in my bones, so it's not likely optimal.
select regexp_substr(split, '[^@]+', 1, 1) as col1 , regexp_substr(split, '[^@]+', 1, 2) as col2 , regexp_substr(split, '[^@]+', 1, 3) as col3 from ( select replace(regexp_substr(source_str, '[^@]+', 1, level), '#|#', '@') as split from ( select replace('val1#|#val2#|#val3~|~val4#|#val5#|#val6~|~val7#|#val8#|#val9', '~|~', '@') as source_str from dual ) connect by level <= length(source_str) - length (replace(source_str, '@') ) + 1 );I do not have an instance running (tested on XE) 11 so I can't use "magical" things like regexp_count and fun stuff. This should give you a basic idea of how to analyze data well.
I decode your delimiters in something "more manageable" just because it's easier than worrying about the escaping of special characters and all that fun stuff I'm too asleep to try.
Since you are dealing with a CLOB (you actually over 4,000 characters of data?) you have to give it up and look for a function in the pipeline as a suitable alternative.
-
column to the conversion of the line
CREATE TABLE TEST_PLC
(
NUMBER OF "PRCS_ID."
VARCHAR2 (20 BYTE) "LIC_ID."
VARCHAR2 (1 BYTE) "REG."
VARCHAR2 (10 BYTE) "PLCY1."
VARCHAR2 (10 BYTE) "PLCY2."
VARCHAR2 (10 BYTE) "PLCY3".
);
Insert into TEST_PLC (PRCS_ID, LIC_ID, REG, PLCY1, PLCY2, PLCY3) values (123456, 'XXXX', 'W', '1212', null, null);
Insert into TEST_PLC (PRCS_ID, LIC_ID, REG, PLCY1, PLCY2, PLCY3) values (345678, 'XXXX', 'W', ' 6789 ', ' 1101', null);
Insert into TEST_PLC (PRCS_ID, LIC_ID, REG, PLCY1, PLCY2, PLCY3) values (456789, 'YYYY', 'W', "2222", null, null);
Insert into TEST_PLC (PRCS_ID, LIC_ID, REG, PLCY1, PLCY2, PLCY3) values (567890, 'YYYY', 'W', "6767", "7878 ', null);
Insert into TEST_PLC (PRCS_ID, LIC_ID, REG, PLCY1, PLCY2, PLCY3) values (135791, 'ZZZZ', 'W', '4646', null, null);
I have a table as above and I want to fill new table as my results below.
PRCS_ID is an indicator only, I want to combine PLCY1, PLCY2, PLCY3 in a single column as PLCY and know if it is PLCY1 or PLCY2 or PLCY3 I need a new seq column with the values 1, 2 or 3. in real time, I have PLCY columns in my source, but I just want to test with small sample
Expected results
PRCS_ID LIC_ID REG PLCY SEQ 123456 XXXX W 1212 1 345678 XXXX W 6789 1 345678 XXXX W 1101 2 456789 AAAA W 2222 1 567890 AAAA W 6767 1 567890 AAAA W 7878 2 135791 ZZZZ W 4646 1 I checked some of the examples but not able to get my desired result
Please help to solve one.
Hello
It's called Unpivoting.
To see the results you want:
SELECT *.
OF test_plc
UNPIVOT (plcy
FOR seq (plcy1 AS 1
plcy2 AS 2
plcy3 AS 3
)
)
;
Output:
PRCS_ID LIC_ID R SEQ PLCY
---------- -------------------- - ---------- ----------
XXXX 123456 W 1 1212
XXXX 345678 W 1 6789
XXXX 345678 W 2 1101
AAAA 456789 W 1 2222
AAAA 567890 W 1 6767
AAAA 567890 W 2 7878
ZZZZ 135791 W 1 4646
Exactly what you asked for, except that the column forms SEQ before PLCY. In a relational table, the column order should not matter, but if you really want to have PLCY come before SEQ, then don't say ' SELECT * '. the list instead, all the columns in the order you want.
If you want to create a new table as the result above, use the query in an AS TABLE CREATE statement above:
CREATE TABLE new_plc
AS
SELECT *.
...
If you already have a table, and you want to fill with the results of the above query, use this query in an insert oou MERGE:
INSERT INTO new_plc (prcs_id, lic_id, reg, seq, plcy)
SELECT *.
...
-
I have a column with two values, separated by a space, in each line. How do I create 2 new columns with the first value in one column and the second value in another column?
Add two new columns after than the original with space separated values column.

Select cell B1 and type (or copy and paste it here) the formula:
= IF (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
shortcut for this is:
B1 = if (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
C1 = if (Len (a1) > 0, Member SUBSTITUTE (A1, B1 & "", ""), "")
or
the formula of the C1 could also be:
= IF (Len (a1) > 0, RIGHT (A1, LEN (A1) −FIND ("", A1)), "")
Select cells B1 and C1, copy
Select cells B1 at the end of the C column, paste
-
Select all the lines of a specific column
Hello
I have a complete excel data file and I want to display in the control table labview
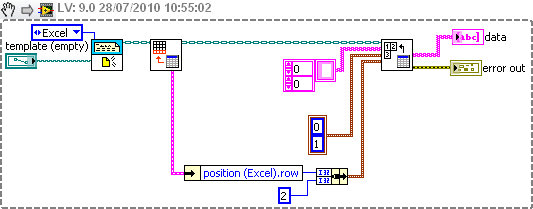
the number of rows in the excel file is not defined, but I know what colume there is.
so now im using report generation tools read my excel file by setting the line position and colume, but if I put '-1' on the two lines which is of all package read and the column position, an error occurs.
any way to solve?
64864050 wrote:
Hello
I have a complete excel data file and I want to display in the control table labview
the number of rows in the excel file is not defined, but I know what colume there is.
so now im using report generation tools read my excel file by setting the line position and colume, but if I put '-1' on the two lines which is of all package read and the column position, an error occurs.
any way to solve?
There is no problem with the index of line-1, as long as you read one column.
To read several columns, you must set the start and the end of the table block. Since you know your number in the column, simply determine the line number. You can use the Row.vi last Excel get, as shown below.
-
The passage to the line/column in the ListBox with enter/tab?
I have a ListBox, in which I load several columns, ranks multiple excel files. Once I've selected a single cell to motify it, I would move down to the next line to the right or to the left / to the next column with the enter and tab keys respectively? It would be especially nice to be able to move to the next cell with it being active, so that I can make changes without touching the mouse pointer.
Is it possible to do?
LV2014
-
I used several worksheets. More allows me to specify the rows/columns and then delete them. This is to remove all the lines/columns beyond those set up and formatted for my spreadsheet. I tried many ways to remove all additional lines/columns, but without success. I even took the time to scroll down/on to highlight all the unnecessary lines and columns, but they do not remove it.
Any suggestions? I used spreadsheets most allow me to specify the number of rows/columns for my worksheetYou can ask your question in the office | Excel Forum because it is not really a problem of Windows XP performance and maintenance.
Office | Excel
http://answers.Microsoft.com/en-us/Office/Forum/Excel
Also, providing specific information may help to get a faster response or better, such as the version of Office or Excel? version of Windows XP? Home, Pro, 32-bit or 64-bit.
I hope this helps.
-
SQL Loader - ignore the lines with "rejected - all null columns."
Hello
Please see the attached log file. Also joined the table creation script, data file and the bad and throw the files after execution.
Sqlldr customer in the version of Windows-
SQL * Loader: release 11.2.0.1.0 - Production
The CTL file has two clauses INTO TABLE due to the nature of the data. The data presented are a subset of data in the real world file. We are only interested in the lines with the word "Index" in the first column.
The problem we need to do face is, according to paragraph INTO TABLE appears first in the corresponding CTL lines file to the WHEN CLAUSE it would insert and the rest get discarded.
1. statement of Create table : create table dummy_load (varchar2 (30) name, number, date of effdate);
2. data file to simulate this issue contains the lines below 10. Save this as name.dat. The intention is to load all of the rows in a CTL file. The actual file would have additional lines before and after these lines that can be discarded.
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
H15T10Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
3. the CTL file - name.ctl
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
invoke SQL loader in a file-> beats
C:\Oracle\product\11.2.0\client\bin\sqlldr USERID = myid/[email protected] CONTROL=C:\temp\t\name.ctl BAD=C:\temp\t\name_bad.dat LOG=C:\temp\t\name_log.dat DISCARD=C:\temp\t\name_disc.dat DATA=C:\temp\t\name.dat
Once this is run, the following text appears in the log file (excerpt):
Table DUMMY_LOAD, charged when 09:13 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME FIRST * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Table DUMMY_LOAD, charged when 08:12 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME NEXT * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Record 1: Ignored - all null columns.
Sheet 2: Cast - all null columns.
Record 3: Ignored - all null columns.
Record 4: Ignored - all null columns.
Sheet 5: Cast - all null columns.
Sheet 7: Discarded - failed all WHEN clauses.
Sheet 8: Discarded - failed all WHEN clauses.
File 9: Discarded - failed all WHEN clauses.
Case 10: Discarded - failed all WHEN clauses.
Table DUMMY_LOAD:
1 row loaded successfully.
0 rows not loaded due to data errors.
9 lines not loading because all WHEN clauses were failed.
0 rows not populated because all fields are null.
Table DUMMY_LOAD:
0 rows successfully loaded.
0 rows not loaded due to data errors.
5 rows not loading because all WHEN clauses were failed.
5 rows not populated because all fields are null.
The bad file is empty. The discard file has the following
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
Based on the understanding of the instructions in the CTL file, ideally the first 6 rows will have been inserted into the table. Instead the table comes from the line 6' th.
NAME RATE EFFDATE H15T10Y Index 2 January 19, 2016 If the INTO TABLE clauses were put in the CTL file, then the first 5 rows are inserted and the rest are in the discard file. The line 6' th would have a ""rejected - all columns null. "in the log file. "
Could someone please take a look and advise? My apologies that the files cannot be attached.
Unless you tell it otherwise, SQL * Loader assumes that each later in the table and what clause after the first back in the position where the previous left off. If you want to start at the beginning of the line every time, then you need to reset the position using position (1) with the first column, as shown below. Position on the first using is optional.
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
-
Arrange the tiles in a column, but multiple lines
When you have the tiles on The start screen of Metro , you can set the group / block a tile only, but when you want to add the second tile to this group / block, you can put only horizontally (from left or right tile existed), in other words, you can add the column within that group, but you can put the new Tile vertically , under a tile already existence.
I want to define group / block of tiles with a single column, but multiple lines.For example, instead of this:xx xx xx xxxx xx xxto get this:xx x xx xxxx x xx xxScreenshot:Hi Mike b. II.
It's normal. You cannot have tiles in groups vertically. Now in your case, if you change the tiles to large tiles, they will stack vertically.
-
Divide the line into several columns
Hi all
I have a question where I want to divide the line into multiple columns based on the delimiter ' |'.
Staging of Table structure: People_STG, I have people in it.
Create table People_STG(col1 varchar2(4000));
Insert into People_STG(Emp_id|) User name | FirstName. LastName. JobTitle | hire_date | Location_id)
SELECT REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 1) EMP_ID, REGEXP_SUBSTR ( COL1, '[^|]+', 1, 2) USERNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 3) FIRSTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 4) LASTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 5) JOBTITLE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 6) HIRE_DATE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 7) LOCATION_ID FROM PEOPLE_STG WHERE length(regexp_replace(COL1, '[^|]', '')) = 14;
But I am facing a problem here, as in some lines, function is null, but when I run the above query, it is not recognizing the empty element and inserting Hire_date values of function and location_id in Hire_date where function is null.
for example: 1 | akash51 | Akaksh | C | 22/11/14 | 15
Here the function is null, so when I run top to divide query it will insert 11/22/14 in the function column and 15 in Hire_Date.
Please need help on this one.
Oracle Version: 11.2 g
Thanks in advance,
Akash.
There are different techniques to cope with this. Is a simple...
SQL > ed
A written file afiedt.buf1 with t as (select 1 | akash51 |) Akaksh | C | 22/11/14 | 15' as col1 of union double all the
2 Select 2 | akash52 | Akaksh | C | Jobs jobs | 23/11/14 | 15' of the double
3 )
4 --
5. end of test data
6 --
7 select trim (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 1)) EMP_ID,.
8 toppings (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 2)) USERNAME,.
9 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 3)) FIRSTNAME,
10 pads (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 4)) LASTNAME,.
11 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 5)) JOBTITLE,.
12 pads (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 6)) HIRE_DATE,.
13 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 7)) location_id
14 * from (select replace (col1, ' |)) ',' | as col1 of t)
SQL > /.EMP_ID USERNAME FIRSTNAME LASTNAME, JOBTITLE HIRE_DATE LOCATION_I
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 akash51 Akaksh C 22/11/14 15
2 akash52 Akaksh C Job 23/11/14 15

{kind=link}
Maybe you are looking for
-
Keep it plug in when it is fully charged
Hello. I just want to know if it is harmful to the air of my ipad 2 every time I plugged the power while it has already been fully charged? Thanks in advance folks out there!
-
Firefox's search appears after the screenshot
Since the update to Firefox 35, when I take a screenshot in holding the home and power keys together, Firefox search pop up with a list of my Firefox search history and invites research. How can I disable this? 4.4 Android
-
Original title: Update Configuration Whenever I boot, I get the following: all the configuring updates step 3 of 3 15%; do not turn off your computer. He never finished the updates. I can get by launching start-up repail and restoration, but I have
-
How to restore a Sauveg.bkf file (850 GB) that were made in Windows 2000 to an XP system?
I have a huge - backup file of 850 GB I did with Win Backup in a Windows 2000 System. I want to restore this file to individual files. I could do this with a XP system?
-
How to configure downloads in bulk for forms signed since Adobe sign? I am particularly interested in csv files.The account I use is with username [email removed by Moderator]