transpose the data in the column to the line
I want to change the columns in lines, my data is
| TYPE | RANK |
| 1 | A |
| 1 | AA |
| 1 | AAA |
| 2 | B |
| 2 | BB |
I want it in
| RANK (1) | RANK (2) |
| A | B |
| AA | BB |
| AAA |
Please help me
Thanks for the response guys, in the meantime, I found the solution too
SELECT MAX(CASE WHEN ID=1 THEN RATING ELSE NULL END) AS RC,
MAX(CASE WHEN ID=2 THEN RATING ELSE NULL END) LAUGHED
FROM (SELECT ID, RATING, ROW_NUMBER() over (ORDER BY rowid ID PARTITION) RN)
OF RANK_TEST) X
GROUP BY RN;
Thank you very much
Tags: Database
Similar Questions
-
Select the lines with the maximum value for a date where another column is different from 0
Hello
I need to write a query on a table (called DEPRECIATION) that returns only the rows whose date maximum (PERENDDAT_0 column) for a specific record (identified by AASREF_0), and where the other column in the table called DPRBAS_0 is different from 0.
If DPRBAS_0 is equal to 0 in all the lines of a specific record, then return the line with date maximum (PERENDDAT_0 column).
To be clearer, I give the following example:
Suppose we have the following data in the table of DEPRECIATION:
AASREF_0 PERENDDAT_0 DPRBAS_0 I20110010743 31/12/2015 0 I20110010743 31/12/2014 0 I20110010743 31/12/2013 0 I20110010856 12/31/2016 0 I20110010856 31/12/2015 0 I20110010856 31/12/2014 332 I20140012238 12/31/2016 445 I20140012238 31/12/2015 445 I20140012238 31/12/2014 0 The query must return only the following lines:
AASREF_0 PERENDDAT_0 DPRBAS_0 I20110010743 31/12/2015 0 I20110010856 31/12/2014 332 I20140012238 12/31/2016 445 Thanks a lot for your help!
This message was edited by: egk
Hello Egk,
The following query works for you.
SELECT AASREF_0, PERENDDAT_0, DPRBAS_0
FROM (SELECT AASREF_0,
PERENDDAT_0,
DPRBAS_0,
ROW_NUMBER)
DURING)
AASREF_0 PARTITION
ORDER BY
CASE WHEN DPRBAS_0 <> 0 THEN 1 OTHER 0 END DESC,.
PERENDDAT_0 DESC)
RN
DEPRECIATIONS)
WHERE rn = 1
-
Transpose the unique column values online
Hi all
How to transpose the values of one column in a row,
COL
1
2
3
4
5
6
7
8
and I want to convert this column into the line as follows:
Line (each in a separate column value). Number of values is not constant.
1,2,3,4,5,6,7,8
Solution without converting them to XML:
WITH row_values
AS (SELECT DISTINCT property_name,
column_order
OF v_rd_property_definition
WHERE lp_id = 5171
ORDER BY column_order)
SELECT Regexp_substr(Wm_concat(property_name), "[^,] +' 1, 1") AS col1,.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 2"). AS col2.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 3") AS col3.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 4") AS col4,.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 5") AS col5,.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 6") AS col6,.
Regexp_substr (Wm_concat(property_name), "[^,] +' 1, 7") AS col7
OF row_values;
-
Transform the data in the column marked in lines
I've already implemented Tom Kytes solution for dynamic / variant in the list that is found here and on his own works very well when passing a variable. I'm trying to use it to decode several rows in a table. Each row has a column of delimited data and I want to turn these data delimited by lines.
Here is the configuration.
create table data_source
(upload_id number not null,
data_source_id integer not null,
sources varchar2 (50).
ERROR_MESSAGE varchar2 (100)
);
insert into data_source (upload_id, data_source_id, sources) values (1, 1, 'a');
insert into data_source (upload_id, data_source_id, sources) values (1,2, 'A:B:C:X');
insert into data_source (upload_id, data_source_id, sources) values (1, 3, 'c');
insert into data_source (upload_id, data_source_id, sources) values (1, 4, 'B');
insert into data_source (upload_id, data_source_id, sources) values (1.5, 'Y');
create the table data_source_lookup
(varchar2 (10) sources non-null)
;
insert into data_source_lookup (sources) values('A');
insert into data_source_lookup (sources) values('B');
insert into data_source_lookup (sources) values('C');
My goal is to update the table data_source for lines where there is an invalid data source, in the example above that would be 2 and 5 lines. I can do this individually using the in_list solution:
Select * from table (in_list ('A:B:C:X',' :'))))
If column_value not in (select data_source_lookup sources)
Returns 'X' as expected.
What I am struggling with is a method to make it through all the lines for a given loading ID:
Update data_source
ERROR_MESSAGE = "Source of data" is not a valid value
where upload_id = 1 and...
I tried to create a join cross- like this:
Select ds.data_source_id, ds.sources, x.column_value
DS data_source cross join (select column_value in the table (in_list (ds.sources,' :'))) x)))
but as you can imagine passing in the function ds.sources has failed, returning "ORA-00904:"DS".» "SOURCES": invalid identifier.
I'm sure I can solve this problem in a loop, but that seems inefficient. Anyone know of a method by which I can pass the content of the column to the table function (in_list ()) for each line?
For someone else it may call a function table in several lines, here's what I came with. First of all, I changed my data to test a bit to add some very incorrect values.
setting a day from sources set data_source = 'A:B:C:X:Y' where data_source_id = 1;
This query will not return a list of lines that contain invalid values, including their wrong value:
Select the rowid, sources, column_value
de)
Select the rowid, data_source sources)
x cross table junction (utils.in_list (x.sources,' :'))))
where column_value is not null
and not exists (select null from data_source_lookup l where l.sources = column_value)
AABk3MAAjAAAKd8AAA A:B:C:X:Y X
AABk3MAAjAAAKd8AAA A:B:C:X:Y Y
AABk3MAAjAAAKd8AAB A:B:C:X X
AABk3MAAjAAAKd8AAE Y Y
With this work, I can then modify cela a little bit to turn it back in a delimited list bad values that I can put in the error column.
Update data_source x 2
ERROR_MESSAGE = value
(by selecting bad_value in)
Select RID, "Invalid Data Source - ' |" listagg(column_value,':') within the Group (column_value control) bad_value
de)
Select the rowid RID, data_source sources)
x cross table junction (utils.in_list (x.sources,' :'))))
where column_value is not null
and not exists (select null from data_source_lookup l where l.sources = column_value)
(Group of RID) where rid = x 2 .rowid)
where x 2 .upload_id = 1
and x2.rowid in (select RID)
de)
Select the rowid RID, data_source sources)
x cross table junction (utils.in_list (x.sources,' :'))))
where column_value is not null
and not exists (select null from data_source_lookup l where l.sources = column_value))
;
It works well, and I find myself with:
Error sources
Source of invalid data in A:B:C:X:Y - x: y
Invalid Data Source - X A:B:C:X
C
B
Valid source of data Y - Y
-
How to duplicate the data in a column?
I have
< code >
SELECT '1' DFILE
'aaa' ANAME
'no' poles
OF THE DOUBLE
UNION
SELECT '1' DFILE
'bbb' ANAME
'no' POLES
OF THE DOUBLE
UNION
SELECT '0' DFILE
'ccc' ANAME
'yes' IMPERIOUS
OF THE DOUBLE
< code >
I want the output to be
DFILE imperious aname
1 Yes aaa
1 Yes bbb
0 Yes ccc
I'll be pulling data from 3 files and do a union. I just give a simple example
where I want the value of "ccc" in the column of the other 2 queries.
CCC will have always a '0' for form preprinted.
Suggestions?
TIA
Steve42Hello
If you want that each row of the result set to contain something that reflects the overall result (in this case, the value of the poles of the 1 row of the result set that's aname = "ccc"). This looks like a job for an analytic function.
Here's one way:WITH sample_data AS ( SELECT '1' DFILE ,'aaa' ANAME ,'no' ahelp FROM DUAL UNION SELECT '1' DFILE ,'bbb' ANAME ,'no' AHELP FROM DUAL UNION SELECT '0' DFILE ,'ccc' ANAME ,'yes' AHELP FROM DUAL ) SELECT dfile , aname , MIN (CASE WHEN aname = 'ccc' THEN ahelp END) OVER () AS ccc_ahelp FROM sample_data ;What results would you if the result set does not contain a line with aname = "ccc"? The query above would have NULL in the last column.
What if there were 2 (or more) lines with aname = "ccc"? The query above takes the first value (in the normal sort order) of the lines with aname = "ccc". If they are all lucky to have the same value of poles, then, of course, this will be the first.You may have noticed that this site deosn treat
as anything special
Whenever you post formatted text on this site, type these 6 characters:\
tag is exactly the same as the opening tag; don't use a '/'.
(small letters only, inside curly brackets) before and after each section of formatted text, to preserve spacing. Note that the closing \ -
Edit/view (data or Table column) value - cannot change the data, but it can be updated
Hello
According to the help of Oracle SQL Developer Center, the dialog ' Change/see value (data or Table column)' should "change the value of data" if we "are allowed to change the data." We strive to use this dialog box to modify/update data without having to write an Update statement, but is not to leave us. Us are not allowed to update the data, we can update via update statements. Even as the owner of the schema.table, it don't will change us the value in the dialog box "Edit/see value (data or Table column).
Any ideas?
We are on SQL Developer Version 3.0.0.4 build HAND - 04.34 and Oracle 11 GR 1 material (11.1.0.7) database.
Thank you
Alex Larzabal.You can still vote on the existing demand for this developer SQL to add Exchange of weight for implementation as soon as possible:
https://Apex.Oracle.com/pls/Apex/f?p=43135:7:3974986722753169:no:RP, 7:P7_ID:4902Kind regards
K. -
display the data in row columns
I looked through the previous posts, but it is impossible to find a solution to my problem.
I want to display the data in row columns.
I have shown in the table below and test data and the sql code that gives me the result desired.
However, you can see that the sql depends of me knowing all the values in the column "rank".
I want a way to produce the output without knowing the values of rank.
CREATE TABLE test1 ( accno NUMBER, holder_type VARCHAR2(10), rank NUMBER) INSERT INTO test1 VALUES (1, 'acr', 0); INSERT INTO test1 VALUES (1, 'bws', 1); INSERT INTO test1 VALUES (1, 'aaa', 2); INSERT INTO test1 VALUES (2, 'cds', 0); INSERT INTO test1 VALUES (2, 'xxx', 1); INSERT INTO test1 VALUES (3, 'fgc', 0); INSERT INTO test1 VALUES (4, 'hgv', 0); INSERT INTO test1 VALUES (4, 'bws', 1); INSERT INTO test1 VALUES (4, 'qas', 2); INSERT INTO test1 VALUES (4, 'aws', 3); Here's the required output:= ACCNO ALLCODES 1 acr bws aaa 2 cds xxx 3 fgc 4 hgv bws qas aws I.E. for each accno display the holder_types in rank sequence. SELECT * FROM (SELECT a0.accno, a0.holder_type || DECODE(a1.holder_type, NULL, NULL, ' ') || a1.holder_type || DECODE(a2.holder_type, NULL, NULL, ' ') || a2.holder_type || DECODE(a3.holder_type, NULL, NULL, ' ') || a3.holder_type || DECODE(a4.holder_type, NULL, NULL, ' ') || a4.holder_type allcodes FROM (SELECT accno, holder_type, rank FROM test1 WHERE rank = 0) a0, (SELECT accno, holder_type, rank FROM test1 WHERE rank = 1) a1, (SELECT accno, holder_type, rank FROM test1 WHERE rank = 2) a2, (SELECT accno, holder_type, rank FROM test1 WHERE rank = 3) a3, (SELECT accno, holder_type, rank FROM test1 WHERE rank = 4) a4 WHERE a0.accno = a1.accno(+) AND a0.accno = a2.accno(+) AND a0.accno = a3.accno(+) AND a0.accno = a4.accno(+)) a ORDER BY accnoSo you're after what we call 'Aggregation in the chain.'
Check this link as it highlights several techniques:
Aggregation of string techniques
A Re: Concat ranks of the values in a single column Michael
At Re: multiple lines in a single line in the 'single column Table' followed by reason of Billy on the conduct of a stragg first.
In addition, 11 GR 2 has the LISTAGG function.
-
Find the minimum date on multiple columns
Hello
I have two questions to find the minimum date on several columns:
1. need a select query that should JOIN two tables and return any information (CASSEDTL) table with minimum date out of DATEISSUED, DATEPLACED, DATEENTERED and STATDATE.
2. need of an update query that should update all cases in the CASEDTL table with the minimum date of DATEISSUED, DATEPLACED, DATEENTERED and STATDATE.
The DDL:
The initial query I have isCREATE TABLE CASEMSTR ( CASENBR NUMBER, DATEISSUED DATE, DATEPLACED DATE, DATEENTERED DATE); CREATE TABLE CASEDTL ( CASENBR NUMBER, STATDATE DATE, RCVDATE DATE, MODDATE DATE); INSERT INTO CASEMSTR VALUES (1, '1 JUL 2007', '1 JUL 2007', '12 JUL 2007'); INSERT INTO CASEMSTR VALUES (2, '1 JAN 2008', '1 JAN 2008', '21 JAN 2008'); INSERT INTO CASEMSTR VALUES (3, NULL, NULL, '3 DEC 2008'); INSERT INTO CASEMSTR VALUES (4, '31 MAR 2009', NULL, '6 APR 2009'); INSERT INTO CASEMSTR VALUES (5, NULL, '22 MAR 2009', '6 APR 2009'); INSERT INTO CASEMSTR VALUES (6, NULL, NULL, '16 JUL 2009'); INSERT INTO CASEMSTR VALUES (7, '1 DEC 2008', '7 DEC 2008', '26 DEC 2008'); INSERT INTO CASEMSTR VALUES (8, NULL, NULL, '17 MAY 2009'); INSERT INTO CASEDTL VALUES (1, '25 JUN 2007', NULL, '2 AUG 2009'); INSERT INTO CASEDTL VALUES (2, '1 JAN 2008', NULL, '2 AUG 2009'); INSERT INTO CASEDTL VALUES (3, '11 NOV 2008', NULL, '2 AUG 2009'); INSERT INTO CASEDTL VALUES (4, '31 MAR 2009', NULL, '2 AUG 2009'); INSERT INTO CASEDTL VALUES (5, '19 JUL 2009', NULL, '2 AUG 2009'); INSERT INTO CASEDTL VALUES (6, '13 JUN 2009', NULL, '16 JUL 2009'); INSERT INTO CASEDTL VALUES (7, '7 DEC 2008', NULL, '16 JUL 2009'); INSERT INTO CASEDTL VALUES (8, '14 MAY 2009', NULL, '16 JUL 2009'); COMMIT;
Need to know what is the best way to complete the new Date of RRS? Receive a new date should be the minimum date of DATEISSUED, DATEPLACED, DATEENTERED and STATDATE. And also how do I write an update statement unique to upade date of receipt in the detail table?SELECT CD.CASENBR, CM.DATEISSUED, CM.DATEPLACED, CM.DATEENTERED, CD.STATDATE, CD.RCVDATE, NULL "NEW RCV DT" FROM CASEDTL CD INNER JOIN CASEMSTR CM ON CD.CASENBR = CM.CASENBR;
Any help would be appreciated! Thanks in advance!Where is the function LESS? Refer to manual SQL.
HTH - Mark D Powell.
put1 > desc multdate Name Null? Type ----------------------------------------- -------- ---------------------------- COL1 DATE COL2 DATE COL3 DATE put1 > select * from multdate; 11-AUG-09 10-AUG-09 01-AUG-09 put1 > select least(col1, col2, col3) from multdate; 01-AUG-09Published by: MarkDPowell on August 11, 2009 15:53 added example
-
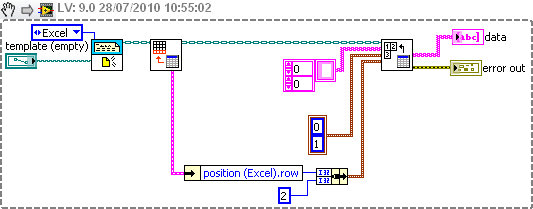
Select all the lines of a specific column
Hello
I have a complete excel data file and I want to display in the control table labview
the number of rows in the excel file is not defined, but I know what colume there is.
so now im using report generation tools read my excel file by setting the line position and colume, but if I put '-1' on the two lines which is of all package read and the column position, an error occurs.
any way to solve?
64864050 wrote:
Hello
I have a complete excel data file and I want to display in the control table labview
the number of rows in the excel file is not defined, but I know what colume there is.
so now im using report generation tools read my excel file by setting the line position and colume, but if I put '-1' on the two lines which is of all package read and the column position, an error occurs.
any way to solve?
There is no problem with the index of line-1, as long as you read one column.
To read several columns, you must set the start and the end of the table block. Since you know your number in the column, simply determine the line number. You can use the Row.vi last Excel get, as shown below.
-
SQL Loader - ignore the lines with "rejected - all null columns."
Hello
Please see the attached log file. Also joined the table creation script, data file and the bad and throw the files after execution.
Sqlldr customer in the version of Windows-
SQL * Loader: release 11.2.0.1.0 - Production
The CTL file has two clauses INTO TABLE due to the nature of the data. The data presented are a subset of data in the real world file. We are only interested in the lines with the word "Index" in the first column.
The problem we need to do face is, according to paragraph INTO TABLE appears first in the corresponding CTL lines file to the WHEN CLAUSE it would insert and the rest get discarded.
1. statement of Create table : create table dummy_load (varchar2 (30) name, number, date of effdate);
2. data file to simulate this issue contains the lines below 10. Save this as name.dat. The intention is to load all of the rows in a CTL file. The actual file would have additional lines before and after these lines that can be discarded.
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
H15T10Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
3. the CTL file - name.ctl
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
invoke SQL loader in a file-> beats
C:\Oracle\product\11.2.0\client\bin\sqlldr USERID = myid/[email protected] CONTROL=C:\temp\t\name.ctl BAD=C:\temp\t\name_bad.dat LOG=C:\temp\t\name_log.dat DISCARD=C:\temp\t\name_disc.dat DATA=C:\temp\t\name.dat
Once this is run, the following text appears in the log file (excerpt):
Table DUMMY_LOAD, charged when 09:13 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME FIRST * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Table DUMMY_LOAD, charged when 08:12 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME NEXT * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Record 1: Ignored - all null columns.
Sheet 2: Cast - all null columns.
Record 3: Ignored - all null columns.
Record 4: Ignored - all null columns.
Sheet 5: Cast - all null columns.
Sheet 7: Discarded - failed all WHEN clauses.
Sheet 8: Discarded - failed all WHEN clauses.
File 9: Discarded - failed all WHEN clauses.
Case 10: Discarded - failed all WHEN clauses.
Table DUMMY_LOAD:
1 row loaded successfully.
0 rows not loaded due to data errors.
9 lines not loading because all WHEN clauses were failed.
0 rows not populated because all fields are null.
Table DUMMY_LOAD:
0 rows successfully loaded.
0 rows not loaded due to data errors.
5 rows not loading because all WHEN clauses were failed.
5 rows not populated because all fields are null.
The bad file is empty. The discard file has the following
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
Based on the understanding of the instructions in the CTL file, ideally the first 6 rows will have been inserted into the table. Instead the table comes from the line 6' th.
NAME RATE EFFDATE H15T10Y Index 2 January 19, 2016 If the INTO TABLE clauses were put in the CTL file, then the first 5 rows are inserted and the rest are in the discard file. The line 6' th would have a ""rejected - all columns null. "in the log file. "
Could someone please take a look and advise? My apologies that the files cannot be attached.
Unless you tell it otherwise, SQL * Loader assumes that each later in the table and what clause after the first back in the position where the previous left off. If you want to start at the beginning of the line every time, then you need to reset the position using position (1) with the first column, as shown below. Position on the first using is optional.
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
-
Divide the line into several columns
Hi all
I have a question where I want to divide the line into multiple columns based on the delimiter ' |'.
Staging of Table structure: People_STG, I have people in it.
Create table People_STG(col1 varchar2(4000));
Insert into People_STG(Emp_id|) User name | FirstName. LastName. JobTitle | hire_date | Location_id)
SELECT REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 1) EMP_ID, REGEXP_SUBSTR ( COL1, '[^|]+', 1, 2) USERNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 3) FIRSTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 4) LASTNAME, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 5) JOBTITLE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 6) HIRE_DATE, REGEXP_SUBSTR ( COL1, '[^,|]+', 1, 7) LOCATION_ID FROM PEOPLE_STG WHERE length(regexp_replace(COL1, '[^|]', '')) = 14;
But I am facing a problem here, as in some lines, function is null, but when I run the above query, it is not recognizing the empty element and inserting Hire_date values of function and location_id in Hire_date where function is null.
for example: 1 | akash51 | Akaksh | C | 22/11/14 | 15
Here the function is null, so when I run top to divide query it will insert 11/22/14 in the function column and 15 in Hire_Date.
Please need help on this one.
Oracle Version: 11.2 g
Thanks in advance,
Akash.
There are different techniques to cope with this. Is a simple...
SQL > ed
A written file afiedt.buf1 with t as (select 1 | akash51 |) Akaksh | C | 22/11/14 | 15' as col1 of union double all the
2 Select 2 | akash52 | Akaksh | C | Jobs jobs | 23/11/14 | 15' of the double
3 )
4 --
5. end of test data
6 --
7 select trim (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 1)) EMP_ID,.
8 toppings (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 2)) USERNAME,.
9 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 3)) FIRSTNAME,
10 pads (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 4)) LASTNAME,.
11 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 5)) JOBTITLE,.
12 pads (REGEXP_SUBSTR (COL1, ' [^, |] +', 1, 6)) HIRE_DATE,.
13 garnish (REGEXP_SUBSTR (COL1, ' [^, |] +' 1, 7)) location_id
14 * from (select replace (col1, ' |)) ',' | as col1 of t)
SQL > /.EMP_ID USERNAME FIRSTNAME LASTNAME, JOBTITLE HIRE_DATE LOCATION_I
---------- ---------- ---------- ---------- ---------- ---------- ----------
1 akash51 Akaksh C 22/11/14 15
2 akash52 Akaksh C Job 23/11/14 15 -
A statement UPDATE changes the line if the update changes the column even value?
HI -.
I have a main classification and the corresponding audit table. I have a trigger. I created using the suggestion:http://www.runningoracle.com/product_info.php?products_id=211
Now the problem that I am facing is that: if I run the same query (same value) update on the main table for n times (with the same data)... my audit table is updated with a new record every time. He is not able to determine that the value is the same.
My goal is to load the audit table data if the value in a cell in the main table is really have changed.
A statement UPDATE changes the line if the update changes the column even value?
Best regards
I have a main Table and the corresponding Audit Table. I have a trigger. I created using the suggestion:http://www.runningoracle.com/product_info.php?products_id=211
Why?
You try to resolve what made you what are the PROBLEM that select as the solution?
Now the problem that I am facing is that: if I run the same query (same value) update on the main table for n times (with the same data)... my audit table is updated with a new record every time.
Yes - it is EXACTLY what you say that you wanted to do and EXACTLY what the code does in this article.
He is not able to determine that the value is the same.
I think you mean that the code does NOT check if the value is the same. You can certainly change the code to do this check. But I have a question to start with your need for such a solution.
My goal is to load the audit table data if the value in a cell in the main table is really have changed.
OK - then modify the code to check EACH COLUMN and compare its NEW value to the OLD value and insert only the table of audit if SOME (or columns you care specifically) have changed.
A statement UPDATE changes the line if the update changes the column even value?
It depends on what you mean by 'change the line '. Of course to update a column with the SAME value does not change the resulting data value.
But the physical structure of the line, the location of the pieces of line and information in the header block (YVERT, etc.) will change. And, as others have said Oracle doesn't know and doesn't care, so if the new value of a column is the same as the old value will create redo, undo and the rest.
Start over and tell us what PROBLEM you're trying to solve. Then we can help you find the best way to solve it.
-
Error: The lines of data with unmapped dimensions exist for period "1 April 2014".
Expert Hi
The below error when I click on the button Execute in order to load data in the area of data loading in 11.1.2.3 workspace. Actually, I already put in the tabs global mapping (add records of 12 months), mapping of Application (add records of 12 months) and map sources (add a month "1 April 2014' as the name of period with Type = Explicit mapping") in the service of the period mapping. What else should I check to fix this? Thank you.
2014-04-29 06:10:35, 624 [AIF] INFO: beginning of the process FDMEE, process ID: 56
2014-04-29 06:10:35, 625 [AIF] INFO: recording of the FDMEE level: 4
2014-04-29 06:10:35, 625 [AIF] INFO: FDMEE log file: null\outbox\logs\AAES_56.log
2014-04-29 06:10:35, 625 [AIF] INFO: user: admin
2014-04-29 06:10:35, 625 [AIF] INFO: place: AAESLocation (Partitionkey:2)
2014-04-29 06:10:35, 626 [AIF] INFO: period name: Apr 1, 2014 (period key: 4/1/14-12:00 AM)
2014-04-29 06:10:35, 627 [AIF] INFO: category name: AAESGCM (category key: 2)
2014-04-29 06:10:35, 627 [AIF] INFO: name rule: AAESDLR (rule ID:7)
2014-04-29 06:10:37, 504 [AIF] INFO: Jython Version: 2.5.1 (Release_2_5_1:6813, September 26 2009, 13:47:54)
[JRockit (R) Oracle (Oracle Corporation)]
2014-04-29 06:10:37, 504 [AIF] INFO: Java platform: java1.6.0_37
2014-04-29 06:10:39, 364 INFO [AIF]: - START IMPORT STEP -
2014-04-29 06:10:45, 727 INFO [AIF]:
Import of Source data for the period "1 April 2014".
2014-04-29 06:10:45, 742 INFO [AIF]:
Import data from Source for the book "ABC_LEDGER".
2014-04-29 06:10:45, 765 INFO [AIF]: monetary data lines imported from Source: 12
2014-04-29 06:10:45, 783 [AIF] INFO: Total of lines of data from the Source: 12
2014-04-29 06:10:46, 270 INFO [AIF]:
Map data for period "1 April 2014".
2014-04-29 06:10:46, 277 [AIF] INFO:
Treatment of the column mappings 'ACCOUNT '.
2014-04-29 06:10:46, 280 INFO [AIF]: data rows updated EXPLICIT mapping rule: 12
2014-04-29 06:10:46, 280 INFO [AIF]:
Treatment of the "ENTITY" column mappings
2014-04-29 06:10:46, 281 [AIF] INFO: rows of data updates to EXPLICIT mapping rule: 12
2014-04-29 06:10:46, 281 [AIF] INFO:
Treatment of the column mappings "UD1.
2014-04-29 06:10:46, 282 [AIF] INFO: rows of data updates to EXPLICIT mapping rule: 12
2014-04-29 06:10:46, 282 [AIF] INFO:
Treatment of the column mappings "node2".
2014-04-29 06:10:46, 283 [AIF] INFO: rows of data updates to EXPLICIT mapping rule: 12
2014-04-29 06:10:46, 312 [AIF] INFO:
Scene for period data "1 April 2014".
2014-04-29 06:10:46, 315 [AIF] INFO: number of deleted lines of TDATAMAPSEG: 171
2014-04-29 06:10:46, 321 [AIF] INFO: number of lines inserted in TDATAMAPSEG: 171
2014-04-29 06:10:46, INFO 324 [AIF]: number of deleted lines of TDATAMAP_T: 171
2014-04-29 06:10:46, 325 [AIF] INFO: number of deleted lines of TDATASEG: 12
2014-04-29 06:10:46, 331 [AIF] INFO: number of lines inserted in TDATASEG: 12
2014-04-29 06:10:46, 332 [AIF] INFO: number of deleted lines of TDATASEG_T: 12
2014-04-29 06:10:46, 366 [AIF] INFO: - END IMPORT STEP -
2014-04-29 06:10:46, 408 [AIF] INFO: - START NEXT STEP -
2014-04-29 06:10:46, 462 [AIF] INFO:
Validate the data maps for the period "1 April 2014".
2014-04-29 06:10:46, 473 INFO [AIF]: data rows marked as invalid: 12
2014-04-29 06:10:46, ERROR 473 [AIF]: error: the lines of data with unmapped dimensions exist for period "1 April 2014".
2014-04-29 06:10:46, 476 [AIF] INFO: Total lines of data available for export to the target: 0
2014-04-29 06:10:46, 478 FATAL [AIF]: error in CommMap.validateData
Traceback (most recent call changed):
Folder "< string >", line 2348 in validateData
RuntimeError: [u "error: the lines of data with unmapped dimensions exist for period" 1 April 2014' ""]2014-04-29 06:10:46, 551 FATAL [AIF]: COMM error validating data
2014-04-29 06:10:46, 556 INFO [AIF]: end process FDMEE, process ID: 56Thanks to all you guys
This problem is solved after I maped all dimensions in order of loading the data. I traced only Entity, account, Custom1 and Custom2 at first because there is no source map Custom3, Custom4 and PIC. After doing the mapping for Custom3, Custom4 and PKI, the problem is resolved. This is why all dimensions should be mapped here.
-
How remove the line by line by comparing to the first column?
Hello!
I have a problem - I need to remove the line by line, but the problem is, I know that the first COLUMN of the table is a PK.
To retrieve the NAME of the COLUMN that I use:
SELECT column_name, table_name FROM USER_TAB_COLUMNS WHERE column_id = 1 and table_name = c1.tmp_table_name;
But it does not somehow.
Below you can see my script (which has not worked for now):
declare
XXX varchar2 (100);
Start
C1 in (select table_name, tmp_tables tmp_table_name) loop
IMMEDIATE EXECUTION
' SELECT column_name in ' | xxx | "USER_TAB_COLUMNS WHERE column_id = 1 AND table_name = ' |" ' || C1.tmp_table_name | " ' ;
immediate execution
"start."
for c2 in (select * from ' | c1.tmp_table_name | start loop ')
Insert into ' | C1.table_name | "values c2; delete from ' | C1.tmp_table_name | 'where ' | xxx |' = c2.' | xxx |'; exception: when other then null; end; end loop; end;';
end loop;
end;
P.S. The Inserts work perfect. I have a problem with deleting lines that are in c1.table_name, of c1.tmp_table_name (the two tables have the same structure, PK, always), because I have the names of columns different another tables which are PK. (for example: K, ID, NS and so on) Please help me to write the correct script.
For example this will be for the first line recovered as:
Start
C1 in (select table_name, tmp_tables tmp_table_name) loop
immediate execution
«Start for c2 in (select * from ' |)» C1.tmp_table_name | Start loop ')
Insert into ' | C1.table_name | "values c2; delete from ' | C1.tmp_table_name: ' where K = c2. K; exception: when other then null; end; end loop; end;';
end loop;
end;
This script works perfectly. But I have many other tables with different PK - K No.Solution with the logging of errors table
-- create the error-logging table CREATE TABLE tbl_MergeErrors ( Stamp TIMESTAMP(3), TableName VARCHAR2(30), KeyColumn VARCHAR2(30), KeyValue VARCHAR2(4000), ErrorCode NUMBER(5), ErrorMsg VARCHAR2(4000), CONSTRAINT pk_MergeErrors PRIMARY KEY (TableName, Stamp) USING INDEX ) / -- procedure to insert errors CREATE OR REPLACE PROCEDURE LogMergeError (pTableName IN VARCHAR2, pKeyColumn IN VARCHAR2, pKeyValue IN VARCHAR2) IS PRAGMA AUTONOMOUS_TRANSACTION; -- you couldn't insert SQLCODE or SQLERRM directly into a table (ORA-00984) nSQLCODE NUMBER(5) := SQLCODE; vcSQLERRM VARCHAR2(4000) := SQLERRM; BEGIN INSERT INTO tbl_MergeErrors (Stamp, TableName, KeyColumn, KeyValue, ErrorCode, ErrorMsg) VALUES (SYSTIMESTAMP, RTrim( SubStr( pTableName, 1, 30)), RTrim( SubStr( pKeyColumn, 1, 30)), SubStr( pKeyValue, 1, 4000), nSQLCODE, vcSQLERRM); COMMIT WORK; -- if an error occured here, then just roll back the autonomous transaction EXCEPTION WHEN OTHERS THEN ROLLBACK WORK; END LogMergeError; / -- create the tables and insert test-data CREATE TABLE TMP_TABLES ( TABLE_NAME VARCHAR2(200), TMP_TABLE_NAME VARCHAR2(200), CONSTRAINT TMP_TABLES_X PRIMARY KEY (TABLE_NAME) ) / CREATE TABLE TMP_KL002 ( K VARCHAR2(40), N VARCHAR2(200) ) / CREATE TABLE TMP_TABLE1 ( NS VARCHAR2(40), N VARCHAR2(200) ) / CREATE TABLE KL002 ( K VARCHAR2(40), N VARCHAR2(200), CONSTRAINT PK_KL002 PRIMARY KEY (K) ) / CREATE TABLE TABLE1 ( NS VARCHAR2(40), N VARCHAR2(200), CONSTRAINT PK_TABLE1 PRIMARY KEY (NS) ) / INSERT INTO TMP_TABLES (TABLE_NAME, TMP_TABLE_NAME) VALUES ('kl002','tmp_kl002'); INSERT INTO TMP_TABLES (TABLE_NAME, TMP_TABLE_NAME) VALUES ('table1','tmp_table1'); INSERT INTO tmp_KL002 (K, N) VALUES ('00', 'none'); INSERT INTO tmp_KL002 (K, N) VALUES ('07', 'exists'); INSERT INTO tmp_KL002 (K, N) VALUES ('08', 'not assigned'); INSERT INTO tmp_table1 (NS, N) VALUES ('2000', 'basic'); INSERT INTO tmp_table1 (NS, N) VALUES ('3000', 'advanced'); INSERT INTO tmp_table1 (NS, N) VALUES ('4000', 'custom'); COMMIT WORK; -- to test, if it works correct when primary key values exists before INSERT INTO KL002 VALUES ('07', 'exists before'); COMMIT WORK; -- check the data before execution SELECT * FROM TMP_KL002 ORDER BY K; SELECT * FROM KL002 ORDER BY K; SELECT * FROM TMP_TABLE1 ORDER BY NS; SELECT * FROM TABLE1 ORDER BY NS; -- empty the error-logging table TRUNCATE TABLE tbl_MergeErrors DROP STORAGE; -- a solution DECLARE PLSQL_BLOCK CONSTANT VARCHAR2(256) := ' BEGIN FOR rec IN (SELECT * FROM <0>) LOOP BEGIN INSERT INTO <1> VALUES rec; DELETE FROM <0> t WHERE (t.<2> = rec.<2>); EXCEPTION WHEN OTHERS THEN LogMergeError( ''<1>'', ''<2>'', rec.<2>); END; END LOOP; END;'; BEGIN FOR tabcol IN (SELECT t.Tmp_Table_Name, t.Table_Name, c.Column_Name FROM Tmp_Tables t, User_Tab_Columns c WHERE (c.Table_Name = Upper( t.Tmp_Table_Name)) AND (c.Column_ID = 1) ) LOOP EXECUTE IMMEDIATE Replace( Replace( Replace( PLSQL_BLOCK, '<0>', tabcol.Tmp_Table_Name), '<1>', tabcol.Table_Name), '<2>', tabcol.Column_Name); END LOOP; END; / -- check the data after execution ... SELECT * FROM TMP_KL002 ORDER BY K; SELECT * FROM KL002 ORDER BY K; SELECT * FROM TMP_TABLE1 ORDER BY NS; SELECT * FROM TABLE1 ORDER BY NS; -- ... and also the error-logging table SELECT * FROM tbl_MergeErrors ORDER BY Stamp, TableName; -- of couse you must issue an COMMIT (the ROLLBACK is only for testing ROLLBACK WORK; -- drop the test-tables DROP TABLE TABLE1 PURGE; DROP TABLE KL002 PURGE; DROP TABLE TMP_TABLE1 PURGE; DROP TABLE TMP_KL002 PURGE; DROP TABLE TMP_TABLES PURGE; -- you shouldn't drop the error-logging table, but I use it to free up my db DROP TABLE tbl_MergeErrors PURGE;Greetings, Niels
-
Need help for the conversion of the lines in columns
Hi all
I have a table with 2 columns.
colId value
1 aaa
2 bbb
3 ccc
1 ddd
Eee 2
3 fff
I want to store the data in the table above in another table that has 3 columns.
col1 col2 col3
AAA bbb ccc
DDD eee fff
I am pivot query. But I don't get it properly. Help, please.
I have Oracle Database 11 g Enterprise Edition Release 11.1.0.6.0 - 64 bit Production
Thanks in advance,
Girish G
Published by: Girish G July 28, 2011 01:28Girish G wrote:
Hey Tubby,Let me explain the real-world scenario.
I'm the external source CLOB data in oracle stored procedure.
The data are coming in the form below.
col1 # | #col2 # | #col3 ~ | ~ col1 # | #col2 # | #col3 ~ | ~ col1 # | #col2 # | #col3
# Here. #-> is the column delimiter.
and ~ | ~-> is the line delimiter.I want to store these data in a table that has 3 columns.
My approach was to extract the data for each column and store it in a temporary table in separate lines. Then move the data from the temporary table to the destination table.
Are there other alternatives for my requirement? Please suggest.
Thank you
Girish GMuch better when you show us the context like that.
It's late and I have sleepiness in my bones, so it's not likely optimal.
select regexp_substr(split, '[^@]+', 1, 1) as col1 , regexp_substr(split, '[^@]+', 1, 2) as col2 , regexp_substr(split, '[^@]+', 1, 3) as col3 from ( select replace(regexp_substr(source_str, '[^@]+', 1, level), '#|#', '@') as split from ( select replace('val1#|#val2#|#val3~|~val4#|#val5#|#val6~|~val7#|#val8#|#val9', '~|~', '@') as source_str from dual ) connect by level <= length(source_str) - length (replace(source_str, '@') ) + 1 );I do not have an instance running (tested on XE) 11 so I can't use "magical" things like regexp_count and fun stuff. This should give you a basic idea of how to analyze data well.
I decode your delimiters in something "more manageable" just because it's easier than worrying about the escaping of special characters and all that fun stuff I'm too asleep to try.
Since you are dealing with a CLOB (you actually over 4,000 characters of data?) you have to give it up and look for a function in the pipeline as a suitable alternative.
-
Conversion of column to the lines
Hello
I'm currently building and SQL to convert columns from several lines to all lines - see below the test data and the expected result:
CREATE TABLE XX_TEST (NAME VARCHAR2 (10), A1 VARCHAR2 (10), A2 VARCHAR2 (10), A3 VARCHAR2 (10), A4 VARCHAR2 (10), A5 VARCHAR2 (10));
INSERT INTO XX_TEST VALUES('LIST','A','B','C','D','E');
INSERT INTO XX_TEST VALUES('L1','1',,'3',,);
INSERT INTO XX_TEST VALUES('L2','1','5','4',,);
ENGAGE
SELECT * FROM XX_TEST;
Expected result:
NAME is the table XX_TEST column, but the COLUMN and the VALUE are converted to lines - columns
NAME THE COLUMN VALUE
L1 A1 1
L1 A2 NULL
L1 A3 3
L1 A4 NULL
L1 A5 NULL
L2 A1 1
L2 A2 5
L2 A3 4
L2 NULL A4
L2 A5 NULL
Thank you
BSHello
user13409900 wrote:
Thank you Alex and Frank,Don't foget Aketi!
The two ways are really good and functional in my situation.
I apologize for not giving version: I'm on 11g so I think that can use Unpivot. It would be really more faster (performance given the volume of data) to use unpivot characteristic of 11 g?If there is no significant difference, whereas I think is that SELECT... UNPIVOT would be faster. It is purely a guess. It depends on several factors, including your data, your index and your machine. I don't have access to one of them.
Try both ways and compare performance. (Compare the results, too, to check that the two qiueries are really doing the same thing).
If you need help, see this thread:
HOW to: Validate a query of SQL statement tuning - model showingI've never used before unpivot.
This sounds like a good opportunity to learn.
Maybe you are looking for
-
Gauge Power Manager: An error occurred when loading Resource Dll
Just installed windows 10. A dialog window opens immediately after the opening session, saying: gauge of Power Manager: "an error occurred loading resource dll. Power Manager pilot was updated using the System Update and Windows Update. Windows seems
-
Upgrade of the CVI / Win: now receive VISA error: insufficient location information...
Hi all I am faced with the following question: We replaced our old computer laboratory with a new model and took the opportunity to also move to a more recent operating system (from Win XP to Win 7 64 bit) and to the current version of the CVI (2013
-
It looks like you can post only to Azure. I hope that's not correct.
-
Reference Dell 922 All In One Printer the cartridge cover
I'm unable to close both lids of cartridge (black and color) in this printer. However, they all have two close when the cartridge is not inside. I thought it was not aligned, but once this was fixed, it does not close. Anyone else having this problem
-
DVD drive icon has disappeared from the Device Manager and my computer
DVD drive icon disappeared from the Device Manager and my computer. I m using window 7. How can I get it back.