creating interface to transform data between file (csv) dish to database
Hi, I get this error when saving interface. All data in a set of data stores should be attached. This data set has several sets of data source offline stores. The sets are: [PRO]; [EMP]. To design a Cartesian product and create a join, select cross join in its properties ONE classified in exception during access to the repository. ORA-01400 cannot insert null into ("odi-work '")
Hello
I have included 2 sets of data, which are [PRO]; [EMP] source side without knowing it, but a set of data is hidden. So I didn't see a single set of data. I removed a set of data.
If the problem is resolved.
Concerning
Sébastien
Tags: Business Intelligence
Similar Questions
-
Is a database table that is required for the temporary interfaces with the data flat file source?
People, this is the situation I ODI 11.1.1.7
- I have an interface temporary (yellow), called MJ_TEMP_INT, which uses data from TWO sets of data from the source in a temporary target (TEMP_TARG). Wrestling is a shot of a data set from a table while the other set of data extracted from a flat file. A union is made on data sets.
- I then create another interface, called MJ_INT, which uses the MJ_TEMP_INT as the source and the target is a real database. table called "REAL_TARGET".
Two questions:
- When I run my second interface (MJ_INT), I get a message "ORA-00942: table or view does not exist" because it is looking for a real TEMP_TARG db table. Why I have to have one? because I am pulling a flat file?
- On my second interface (MJ_INT) when I look at the interface of my source MJ_TEMP_INT (yellow) property sheet, the box 'Use the temporary interface as a Derived table' is DISABLED. Why? Is also because my temporary interface is pulling from a flat file?
I am attaching a file that shows a screenshot of my studio ODI.
Furthermore, IF my temporary source interface has only a single set of data by pulling from a database. Table to table in a temporary target, called MJ_TEMP2_TARG, and then when I use this temporary interface as a source to the other another real db. target table (REAL2_TARGET), THEN everything works. ODI requires me to have a real database. Table MJ_TEMP2_TARG and the checkbox for "interface temporary use as a Derived table" is NOT DISABLED and my REAL2_TARGET table gets filled.
Thank you in advance.
Mr. Jamal.
You quite rightly assume the reasons that you have questions is because you try to attach a file. A file I always have to be materialized in the transit zone, as a temporary table and then have the data loaded in it.
-
How to create the filter by date of request for access using database connectivity tool
Hello
I had started my project by reading the access data, using a UDL connection,
but now I want to create a filter for access by using a query that would select two dates and get all the corresponding data, how to query using SQL Parmetrized?
Best regards
Note: I do not know the SQL language
Hi salim_mjs,
You must use the date format that I have used. It is independent of the format in your database. It should be "month/day/year".
Mike
-
Unable to display data from a csv file data store
Hi all
I'm using ODI 11 g. I'm trying to import metadata from a csv file. To do this, I have created physical and logical diagrams corresponding. Context is global.
Then, I created a model and a data store. Now, after reverse engineering data store, I got the file headers and I changed the data type of columns to my requirement and then tried to view the data in the data store. I am not getting any error, but can't see all the data. I am able to see only the headers.
Even when I run the interface that loads data into a table, its operation without error, but no data entered...
But the data is present in the source file...
Can you please help me how to solve this problem...
Hi Phanikanth,
Thanks for your reply...
I did the same thing that you suggested...
In fact, I'm working on the ODI in UNIX environment. So I went for the record separator on UNIX option in the files of the data store tab and now its works well...
in any case, once again thank you for your response...
Thank you best regards &,.
Vanina
-
Original title: how to change a nco file extension
Many of my files created with Microsoft Word mysteriously transformed into NCO files that I can't open. Help please!
Hello
1 is specific to only the question word files?
2. what happens when you try to open these files?
Method 1: Check out the link after, and then set the default program to open the word as Microsoft Office Word files and see if that helps:
Reference:
Change the programs that Windows uses by default:
http://Windows.Microsoft.com/en-us/Windows7/change-which-programs-Windows-uses-by-default
Method 2: Restore the computer to a date when it was working fine.
Reference:
System Restore: frequently asked questions:
http://Windows.Microsoft.com/en-us/Windows7/system-restore-frequently-asked-questions
You can also post the question to Microsoft Office word Forums.
Here is the link: http://answers.microsoft.com/en-us/office/forum/word
-
How can I extract the data from a csv file and insert it into an Oracle table? (UTL_FILE)
Hi, please help me whit this query
Im trying to extrate the data in a file csv and im using the ULT_FILE package
I have this query that read the file and the first field, but if the field has a different length does not work as it shouldFor example if I had this .csv file:
1, book, laptop
2, pen, Eraser
3, notebook, paper
And in the table, I had to insert like this
ID descrption1 description2
laptop 1 book
Eraser pen 2
paper laptop 3
For now, I have this query, which displays only with DBMS:
Declare
-Variables
Cadena VARCHAR2 (32767).
Vfile UTL_FILE. TYPE_DE_FICHIER;
Dato varchar2 (200); -Date
dato1 varchar2 (200);
dato2 varchar2 (200);
Identifier varchar2 (5): = ', '; -Identifier (en)
v_ManejadorFichero UTL_FILE. TYPE_DE_FICHIER; -For exceptions
-Table variables
I_STATUS GL_INTERFACE. % OF STATUS TYPE.
I_LEDGER_ID GL_INTERFACE. TYPE % LEDGER_ID;
I_USER_JE_SOURCE_NAME GL_INTERFACE. TYPE % USER_JE_SOURCE_NAME;
I_ACCOUNTING_DATE GL_INTERFACE. TYPE % ACCOUNTING_DATE;
I_PERIOD_NAME GL_INTERFACE. TYPE % PERIOD_NAME;
I_CURRENCY_CODE GL_INTERFACE. CURRENCY_CODE % TYPE;
I_DATE_CREATED GL_INTERFACE. DATE_CREATED % TYPE;
I_CREATED_BY GL_INTERFACE. CREATED_BY % TYPE;
I_ACTUAL_FLAG GL_INTERFACE. TYPE % ACTUAL_FLAG;
I_CODE_COMBINATION_ID GL_INTERFACE. TYPE % CODE_COMBINATION_ID;
I_ENTERED_DR GL_INTERFACE. TYPE % ENTERED_DR;
I_ENTERED_CR GL_INTERFACE. TYPE % ENTERED_CR;
I_ACCOUNTED_DR GL_INTERFACE. TYPE % ACCOUNTED_DR;
I_ACCOUNTED_CR GL_INTERFACE. TYPE % ACCOUNTED_CR;
I_TRANSACTION_DATE GL_INTERFACE. TRANSACTION_DATE % TYPE;
I_REFERENCE1 GL_INTERFACE. REFERENCE1% TYPE;
I_REFERENCE2 GL_INTERFACE. REFERENCE2% TYPE;
I_REFERENCE3 GL_INTERFACE. REFERENCE3% TYPE;
I_REFERENCE4 GL_INTERFACE. REFERENCE4% TYPE;
I_REFERENCE5 GL_INTERFACE. REFERENCE5% TYPE;
I_REFERENCE10 GL_INTERFACE. REFERENCE10% TYPE;
I_GROUP_ID GL_INTERFACE. GROUP_ID % TYPE;
BEGIN
Vfile: = UTL_FILE. FOPEN ('CAPEX_ENVIO', 'comas.csv', 'R');
loop
UTL_FILE. GET_LINE(Vfile,Cadena,32767);
dato1: = substr (cadena, instr(cadena, identificador,1,1)-1, instr(cadena, identificador,1,1)-1);
dato2: = substr (cadena, instr (cadena, identifier, 1, 1) + 1, instr(cadena, identificador,3,1)-3);
dbms_output.put_line (dato1);
dbms_output.put_line (dato2);
-The evidence
-dbms_output.put_line (cadena);
-dbms_output.put_line (substr (dato, 3, instr(dato, identificador,1,1)-1));
-dbms_output.put_line (substr (dato, instr (dato, identifier, 1, 2) + 1, instr(dato, identificador,1,1)-1));
-dbms_output.put_line (substr (cadena, 1, length (cadena)-1));
end loop;
UTL_FILE. FCLOSE (Vfile);
-----------------------------------------------------------------------------------EXCEPTIONS------------------------------------------------------------------------------------------------------------------------------------------------------------
EXCEPTION
When no_data_found then
dbms_output.put_line ('Todo Correcto');
When utl_file.invalid_path then
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20060,'RUTA DEL ARCHIVO NULLIFIED: (');)
WHEN UTL_FILE. INVALID_OPERATION THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR ('-20061,'EL ARCHIVO NO PUDO SER ABIERTO ");
WHEN UTL_FILE. INVALID_FILEHANDLE THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20062, 'INVALIDO MANAGER');
WHEN UTL_FILE. WRITE_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20063, 'ESCRITURA ERROR');
WHEN UTL_FILE. INVALID_MODE THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20064, 'MODO INVALIDO');
WHEN UTL_FILE. INTERNAL_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20065, 'ERROR INTERNO');
WHEN UTL_FILE. READ_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20066, 'LECTURA ERORR');
WHEN UTL_FILE. FILE_OPEN THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR ('-20067,'EL ARCHIVO ARE ESTA ABIERTO ");
WHEN UTL_FILE. THEN ACCESS_DENIED
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20068, 'REFUSED ACCESS');
WHEN UTL_FILE. DELETE_FAILED THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20069, 'OPERACIÓN BORRADO FALLO');
WHEN UTL_FILE. RENAME_FAILED THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20070, 'OPERATION SOBREESCRITURA FALLO');
END;
Hello
Try something like this:
POS1: = INSTR (cadena, idntificador, 1, 1);
POS2: = INSTR (cadena, idntificador, 1, 2);ID: = SUBSTR (cadena, 1, pos1 - 1);
description1: = SUBSTR (cadena, pos1 + 1, (pos2 - pos1)-1);
Description2: = SUBSTR (cadena, pos2 + 1);where pos1 and pos2 are numbers.
Rather than use UTL_FILE, consider creating an external table. You won't have to write any PL/SQL, and this means that you won't be tempted to write a bad article of EXCEPTION.
-
Error loading of the data in the .csv file
Hello
I get error of date below when loading data through Olap tables through .csv file.
Data stored in .csv is 20071113121100.
"
TRANSF_1_1_1 > CMN_1761 Timestamp event: [Mon Mar 29 15:06:17 2010]
TRANSF_1_1_1 > TE_7007 evaluation of processing error [< < Expression error > > [TO_DATE]: an invalid string for the conversion to date]
[... t:TO_DATE(u:'2.00711E+13',u:'YYYYMMDDHH24MISS')]
TRANSF_1_1_1 > CMN_1761 Timestamp event: [Mon Mar 29 15:06:17 2010]
TRANSF_1_1_1 > TT_11132 Transformation [Exp_FILE_CHNL_TYPE] was a mistake in assessing the output column [CREATED_ON_DT_OUT]. Error message is [< < Expression error > > [TO_DATE]: an invalid string for the conversion to date]
[.. t:TO_DATE(u:'2.00711E+13',u:'YYYYMMDDHH24MISS')].
TRANSF_1_1_1 > CMN_1761 Timestamp event: [Mon Mar 29 15:06:17 2010]
TRANSF_1_1_1 > TT_11019 there is an error in the [CREATED_ON_DT_OUT] port: the default value for the port is on: ERROR (< < Expression error > > [ERROR]: error processing)
... nl:ERROR(u:'transformation_error')).
TRANSF_1_1_1 > CMN_1761 Timestamp event: [Mon Mar 29 15:06:17 2010]
TRANSF_1_1_1 > TT_11021 an error occurred to transfer data from the Exp_FILE_CHNL_TYPE transformation: towards the transformation of W_CHNL_TYPE_DS.
TRANSF_1_1_1 > CMN_1761 Timestamp event: [Mon Mar 29 15:06:17 2010]
TRANSF_1_1_1 > CMN_1086 Exp_FILE_CHNL_TYPE: number of errors exceeded the threshold [1].
"
Any help is greatly appreciated.
Thank you
PoojakWhat tool to spool the file well? Did he go any where near a GUI tool? I bet it was the precision on the data type or the type of incorrect data in total
If I paste 20071113121100 into a new excel workbook, the display will return as 2.00711E + 13 - when I put a column data type number that I see all the numbers.
OK it's not great, but you get what im saying:
Can run the SQL SQL of plu and coil directly to the file? -
Importing several files .csv in the data portal
I'm looking to import data that contains multiple .csv files in the data portal. I have a code to succeed, which can erase all data from the data portal, open a dialoge box to find new data and open new data using a .csv use. I want to improve this script to be able to have the ability to load multiple datasets in the data at a time portal, but I have a limited knowledge of the VBS coding structure. Can someone advise measures to reach this solution with VBS minimal coding experience? Thank you all in advance for your help.
Hi dc13.
The tiara FileDlgShow command has the ability to load several files at the same time. Please take a look by using tiara for more details and an example.
Greetings
Walter
-
I tried, but in vain, to write data in the CSV file, with the column headers of the file labeled appropriately to each channel as we do in LabView (see attached CSV). I know that developers should do this same in .net. Can anyone provide a snippet of code to help me get started? In addition, maybe there is a completely different way to do the same thing instead of writing directly to the CSV file? (In fact, I really need to fill a table with data and who join the CSV every seconds of couple). I have the tables already coded for each channel, but I'm still stuck on how to get it in the CSV file. I'm coding in VB.net using Visual Studio 2012, Measurement Studio 2013 Standard. Any help would be greatly appreciated. Thank you.
a csv file is nothing more than a text file
There are many examples on how to write a text using .NET file
-
How to search a file .csv for data using its timestamp, then import into labview
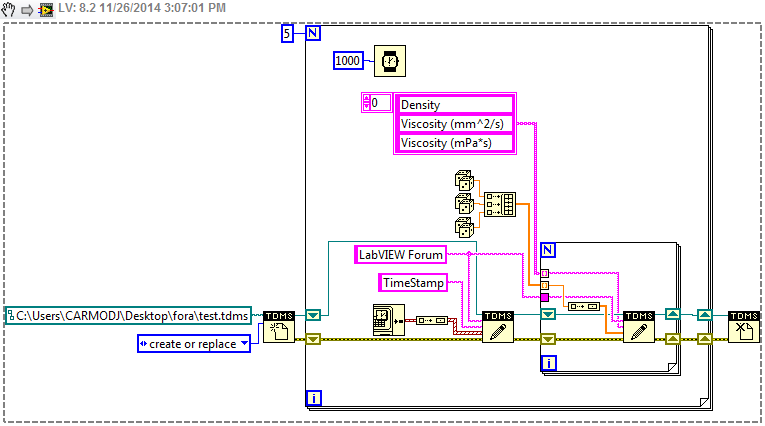
Hi, I am currently get density, viscosity and temperature of an instrument, adding a timestamp data and write to a .csv file that I can view in Excel. It works very well (see attached code) but reimport what I have to do now is search this csv file of data that has been obtained at one time, temperature, density & the values of viscosity at the moment in Labview to do some calculations with them, so that the data acquisition process is still ongoing.
I found several examples on how to import a CSV together in labview, but none on how to extract data at a specific time. Also, every time I try to do anything with the file .csv for my data acquistion VI is running, I get error messages (probably because I'm trying to write and import data from the .csv file at the same time). Is there a way to get around this, perhaps using the case structures?
If you need to know my skill level, I use LabVIEW for a few weeks and before that have basically no experience of writing code, if any help would be great. Thank you!
TDMS is a little more complex than that. Here is a proof of concept quickly lifting together:
You should look at some of the examples of read/write TDMS to get a better handle on the tool. While I should...
-
Copy the files created after a certain date
How can I copy files that were created after a certain date?
Thank you
Hello
Start - computer or Windows Explorer, you can navigate to a specific folder, then right-click on
name (or) control position - MORE - Date created column - OK - the box, and then click the Date
Created column that will align the content of the folder by date ascending or descending as you wish
(click again to change the order). Then you can click on the 1st file in a sequence and hold SHIFT key and
Click on the last file in the sequence you want - this will highlight the sequence - then right-click -.
where in the region of high-lighted and the COPY - navigate to where you want to copy and then right-click
on paste. To copy a group of files not in a sequence, hold down the CTRL key and click on the ones you want
COPY that will highlight the files - right-click anywhere in the region high-lit - and then COPY
Navigate to where you want to copy and click straight on and PASTE.--------------------------------
You can search for files created after a certain date.
Tips for finding files
http://Windows.Microsoft.com/en-us/Windows-Vista/tips-for-finding-filesHow to use advanced search in Vista Options
http://www.Vistax64.com/tutorials/75451-advanced-search.html----------------------------------------------------------
Win Key F opens advanced search
Searching in Windows Vista, part 1
http://Windows.Microsoft.com/en-us/Windows-Vista/searching-in-Windows-Vista-part-1-secrets-of-the-search-boxI hope this helps.
Rob Brown - MS MVP: Bike - Mark Twain said it right.
-
How to store the captured data in the csv file
Here's the sceanario
I was able to capture data from the oracle forms and store it in variables.
now, I want to store the same data in the csv file and save this csv file.
quick reply is appreciated.Ok. This is what my, admittedly simple, code performs above: var_orderid col1 and col2 in var_quantity.
See you soon,.
Jamie -
ORA-01503: CREATE CONTROLFILE failed ORA-01160: file is not a data ORA file
Hi all
I tried to re-create a control file as it is not present, I am facing the following error.
Plaese help.
1. CREATE CONTROLFILE REUSE DATABASE 'TEST' RESETLOGS ARCHIVELOG
MAXLOGFILES 2 5
3 MAXLOGMEMBERS 3
4 MAXDATAFILES 14
MAXINSTANCES 5 1
6 MAXLOGHISTORY 226
LOGFILE 7
GROUP 8 1 ' C:\oracle\product\10.2.0\oradata\TEST\REDO01. NEWSPAPER "SIZE M 50,
9 GROUP 2 ' C:\oracle\product\10.2.0\oradata\TEST\REDO02. NEWSPAPER "SIZE M 50,
10 GROUP 3 ' C:\oracle\product\10.2.0\oradata\TEST\REDO03. NEWSPAPER "SIZE M 50
DATAFILE 11
12 ' C:\oracle\product\10.2.0\oradata\TEST\SYSTEM01. DBF',.
13 ' C:\oracle\product\10.2.0\oradata\TEST\UNDOTBS01. DBF',.
14 ' C:\oracle\product\10.2.0\oradata\TEST\EXAMPLE01. DBF',.
15 ' C:\oracle\product\10.2.0\oradata\TEST\TEMP01. DBF',.
16 ' C:\oracle\product\10.2.0\oradata\TEST\SYSAUX01. DBF',.
17 ' C:\oracle\product\10.2.0\oradata\TEST\USERS01. DBF'
18 * CHARACTER SET WE8MSWIN1252
SQL > /.
CREATE CONTROLFILE REUSE DATABASE 'TEST' RESETLOGS ARCHIVELOG
*
ERROR on line 1:
ORA-01503: CREATE CONTROLFILE failed
ORA-01160: the file is not a data file
ORA-01110: data file: ' C:\oracle\product\10.2.0\oradata\TEST\TEMP01. DBF'Rajini.V wrote:
Hi Fiedi,
Thanku for Quick response.I created could controlfile now, I must add datafile temp01.dbf
How is it already in the path statement.Rajini.V
You can use command below
alter tablespace temp add tempfile 'C:\oracle\product\10.2.0\oradata\TEST\TEMP01.DBF' reuse;See you soon
-
Help to import the data from the catalog to a text file (csv import, delimited by tabs, excel)
Hi All-
I was hitting my head on this one for a few days now. It seems that something that has probably been done before and should not be so difficult, but I found few cases of help in the documentation from Adobe (and researched a lot of google).
I have a catalog of retail sale of 100 pages with approximately 1000 products in InDesign CS5. I have a spreadsheet excel with the names of products this year, prices and descriptions of update. Normally, we would go through one by one and cut and paste. This year, I thought I would try to skip this step. There are plugins that do this, but they are not cheap, and we are not big. Upgrade to CS5 of CS2 is a big investment in and of itself.

Here is an example of the data (I use a vertical bar as a separator character):
28392779 | 3627 | Super top | Get a handle on the pleasure. Wrap the cord around the axis and s '. | 6½ "long
| $10Then... standard excel file exported to a delimited format (I use OpenOffice to export in order to avoid the problem of excel citing darn close * everything *). In the InDesign file, we have a component of text for grouped each name, description, and price. The Group has a title of the product ID script and each field within the group is labelled accordingly (name, id, description). Thus, the Group: 3627, point: description (name or price).
Pseudocode:
Open the file
Analyze the data in a table
Scroll through the InDesign file group
Check the script group label, look it up in the table, assign values to the fields
Easy right?
I'm not new to javascript, but it is not my tongue harder. With this effort, I had problems as simple as the syntax for the identification of the groups by their label. Anyway, here is the code (it is not pretty as the only way that I could not even run to scroll the table of data line by line and then scroll the entire InDesign file for each row of data. And, Yes, it takes about an hour to run--but it * is * run):
myDocument var = app.activeDocument;
data var file = File("/Users/reddfoxx/Desktop/2010Sept8CatDesc.csv");
DataFile.Open ("r");
data var = datafile.read)
data = data.split("\n");
the data array is indexed from 0
field 0 is the internal ID
field 1 is the product ID
field 2 is the name of the product
zone 3 is the description
field 4 are the dimensions
zone 5 is the pricefor (x = 0; x < data.length; x ++) {}
data [x] = data [x].split("|");
for (var z = 0; z < myDocument.groups.count (); z ++) {}
{If (myDocument.groups.item (z) .label == {data [x] [1])}
myGroup = myDocument.groups.item (z);
for (var y = 0; y < myGroup.textFrames.count (); y ++) {}
If (myGroup.textFrames.item .label (y) == "name")
{
myGroup.textFrames.item (y) .silence = data [x] [2];}
If (myGroup.textFrames.item (y) .label = 'description')
{
myGroup.textFrames.item (y) .silence = data [x] [3];
}
If (myGroup.textFrames.item .label (y) == 'dimensions')
{
myGroup.textFrames.item (y) .silence = data [x] [4];
}
If (myGroup.textFrames.item (y) .label = 'price')
{
myGroup.textFrames.item (y) .silence = data [x] [5];
}
}
}
}
}For someone who is not familiar with the groups and scripts, unfortunately, you cannot process blocks of text within a group without using the group. At least, that's what I understand.
Any help would be appreciated. Even just to find how to approach a particular in the document, so that I don't have to scroll through the entire file and do a comparison for each element would be a big improvement.
Thanks in advance.
-Redd
Hey!
You have nice little problem here
Well, unfortunately, InDesign CS5 is a bit heavy on the labels of script, there were some changes and other things. In CS4 and before, when you call pageItem.item (myItemName), you would get called from script, but in CS5, it has been changed, and now you get the element name that is in the layers palette. Now you can easily copy all the script tags, new place, and then it would be easy to access items by name of the element.
This will copy all the labels current script name of the element:
for(var i = 0; i < app.activeDocument.allPageItems.length; i++) app.activeDocument.allPageItems[i].name = app.activeDocument.allPageItems[i].label;
Now, when you have all the names in place, you can access them like this:
app.activeDocument.groups.item(data[x][1]).textFrames.item("name").contents = data[x][2]; app.activeDocument.groups.item(data[x][1]).textFrames.item("description").contents = data[x][3]; app.activeDocument.groups.item(data[x][1]).textFrames.item("dimensions").contents = data[x][4]; app.activeDocument.groups.item(data[x][1]).textFrames.item("price").contents = data[x][5];I hope that helps!
--
tomaxxi
-
Delete snapshots by using data from a csv file
I have a csv file that was exported in the form of:
VM
SERV1
serv2
SERV3
(The file name is snaps4.csv)
I want to delete the associated clichés a vm in this file csv; However I can't get anything to work. Is the closest I've come by manually removing the header in the csv file (i.e. VM) then using the get-content command.
$vms = get-Content C:\scripts\Output\snaps.csv
Get-Snapshot - $vms vm | Remove-Snapshot - RemoveChildren-confirm: $false
The above command works, but I have to remove the header first (which I am fine with, if I do this, but I'm trying to automate this process for people of our operations and have a manual step is not ideal).
Someone help me? I know I'm missing just something simple here, but can't understand it.
Have you tried it?
Import-Csv C:\scripts\Output\snaps.csv | %{
Get-Snapshot - vm $_. VM | Remove-Snapshot - RemoveChildren-confirm: $false
}

Maybe you are looking for
-
System File Checker tells me to insert the CD because of missing DLL files
It tells me to insert XP service pack 3 CD. My system came with service pack 2. I've updated to the service pack 3. When I insert the CD it say it's the wrong CD. Do I need to uninstall service pack 3 so that it works? If Yes... How?
-
Problem signature: problem event name: BlueScreen OS Version: 6.1.7601.2.1.0.768.3 locale ID: 1033
Signature of the problem: Problem event name: BlueScreen OS version: 6.1.7601.2.1.0.768.3 Locale ID: 1033 More information about the problem: BCCode: f4 BCP1: 0000000000000003 BCP2: FFFFFA8005726B30 BCP3:
-
is it possible to uninstall internet explore if I use another internet server?
I only use google chrome
-
Add a contact to people of cotacts on this computer
I have a contact in my outlook contacts, I want to add to the 'people' is in the contacts in the folder this computer only I can't get to any other folder
-
How can I fix the jumpy sliders in Lightroom CC 2015
I recently went to Lightroom 4 to the cloud. In the version that I downloaded, my sliders are nervous. They flash rather than show a continuum smooth changes of color or exposure. What the devil?