Creation of 5 rows in table B for each row in the table has
create table A
(col1 number,
col2 varchar2(20)
)
/
create table B
(col1 number,
col2 varchar2(20)
)
/
insert into A values (1,'Jane');
insert into A values (2,'Kate');
insert into A values (3,'Stomp');
SQL> select * from a;
COL1 COL2
---------- -----------------
1 Jane
2 Kate
3 Stomp COL1 COL2
---------- -----------------
1 Jane
2 Jane
3 Jane
4 Jane
5 Jane
6 Kate
7 Kate
8 Kate
9 Kate
10 Kate
11 Stomp
12 Stomp
13 Stomp
14 Stomp
15 StompHello
A way
insert into b
select rownum*5 , col2 from a
union all
select rownum*5+1, col2 from a
union all
select rownum*5+2, col2 from a
union all
select rownum*5+3, col2 from a
union all
select rownum*5+4, col2 from a
Concerning
Anurag
Tags: Database
Similar Questions
-
SQL query to retrieve a single record for each employee of the following table?
Hi all
Help me on the writing of SQL query to retrieve a single record for each employee of the following table? preferably a standard SQL.
CREATE TABLE xxc_contact)
empnum NUMBER,
alternatecontact VARCHAR2 (100),
relationship VARCHAR2 (10),
phtype VARCHAR2 (10),
Phone NUMBER
);
insert into xxc_contact values (123456, 'Rick Grimes', 'SP', 'Cell', 9999999999)
insert into xxc_contact values (123456, 'Rick Grimes', 'SP', 'Work', 8888888888)
insert into xxc_contact values (123457, 'Daryl Dixon', 'EN', 'Work', 7777777777)
insert into xxc_contact values (123457, 'Daryl Dixon', 'EN', 'Home', 3333333333)
insert into xxc_contact values (123456, 'Maggie Greene', 'CH', 'Cell', 9999999999)
insert into xxc_contact values (123456, 'Maggie Greene', 'CH', 'Home', 9999999999)
expected result:
EmpNum AlternateContact Relationship PhType Phone
123456 rick Grimes SP cell 9999999999
Daryl Dixon EN work 7777777777 123457
Home 123458 Maggie Greene CH 6666666666
Thanks in advance.
994122 wrote:
Thank you all, that I got a result
http://www.orafaq.com/Forum/m/620305/#msg_620305
By Lalit Kumar B...
Specifically, the two simple solutions provided were:
1 using the row_number, entitled Oracle ranking based on descending order of the inside telephone each empnum group. And finally selects the lines which has least rank (of least since that order is descending for phone).
SQL > column alternatecontact format A20;
SQL >
SQL > SELECT empnum, alternatecontact, relationship, phtype, phone
2 from (SELECT a.*, row_number() over r (PARTITION BY empnum ORDER BY phone / / DESC))
3 FROM xxc_contact one)
4. WHEN r = 1
/
EMPNUM ALTERNATECONTACT RELATIONSHIP PHTYPE PHONE
---------- -------------------- ---------- ---------- ----------
123456 rick Grimes SP cell 9999999999
Daryl Dixon EN work 7777777777 123457
Home 123458 Maggie Greene CH 6666666666
2. with the help of MAX, Oracle automatically assigns the maximum phone for all the rows in each group of empnum. And finally selects the rows with the maximum phone. Order by clause is omitted here intentionally. You can find out why.
SQL > SELECT empnum, alternatecontact, relationship, phtype, phone
2 (SELECT a.*, MAX (phone) over (PARTITION BY empnum) rn FROM xxc_contact one)
3 WHERE phone = rn
4.
EMPNUM ALTERNATECONTACT RELATIONSHIP PHTYPE PHONE
---------- -------------------- ---------- ---------- ----------
123456 rick Grimes SP cell 9999999999
Daryl Dixon EN work 7777777777 123457
Home 123458 Maggie Greene CH 6666666666
Kind regards
Lalit
-
Select the last value for each day of the table
Hello!
I have a table that contains several measures for each day. I need two queries on this table, and I'm not sure how to write them.
The table stores the rows (sample data)
Explanation of the data in the sample table:*DateCol1 Value Database* 27.09.2009 12:00:00 100 DB1 27.09.2009 20:00:00 150 DB1 27.09.2009 12:00:00 1000 DB2 27.09.2009 20:00:00 1100 DB2 28.09.2009 12:00:00 200 DB1 28.09.2009 20:00:00 220 DB1 28.09.2009 12:00:00 1500 DB2 28.09.2009 20:00:00 2000 DB2
We measure the size of the data files belonging to each database to one or more times a day. The value column indicates the size of the files of database for each database at some point (date in DateCol1 European model).
What I need:
Query 1:
The query must return to the last action for each day and the database. Like this:
Query 2:*DateCol1 Value Database* 27.09.2009 150 DB1 27.09.2009 1100 DB2 28.09.2009 220 DB1 28.09.2009 2000 DB2
The query should return the average measurement for each day and the database. Like this:
Could someone please help me to write these two queries?*DateCol1 Value Database* 27.09.2009 125 DB1 27.09.2009 1050 DB2 28.09.2009 210 DB1 28.09.2009 1750 DB2
Please let me know if you need further information.
Published by: user7066552 on September 29, 2009 10:17
Published by: user7066552 on September 29, 2009 10:17Why two queries when it suffice ;)
SQL> select dt 2 , db 3 , val 4 , avg_val 5 from ( 6 select dt 7 , val 8 , db 9 , row_number () over (partition by db, trunc (dt) 10 order by dt desc 11 ) rn 12 , avg (val) over (partition by db, trunc (dt)) avg_val 13 from test) 14 where rn = 1 15 order by dt 16 / DT DB VAL AVG_VAL --------- ----- ---------- ---------- 27-SEP-09 DB2 1100 1050 27-SEP-09 DB1 150 125 28-SEP-09 DB2 2000 1750 28-SEP-09 DB1 220 210 -
Hello
I was wondering if I could get some information and opinions on the use of an array of type defined clusters to store configuration data. I am creating a program to test several EHR and wanted to have a control of type defined for each HAD with the information needed to create the DAQmx tasks for all signals for it must HAVE. I am eager to do so that the data are encoded in hard and not in a file that the user might spoil.
Controls of type def are then put into a Subvi who chooses as appropriate, one based on the enumeration of Type DUT connected to a case structure.
I have problems with the control of the defined type. I see issues when you try to save a configuration unique to each element of the array in the array of clusters. Somehow, it worked at first, but now by clicking on "Operations on the data--> default font of the current value ' on individual elements of the cluster or the entire cluster (array element) does not save data when I re - open the command def. What I am doing wrong? I'm trying to do something with the berries of the clusters that I shouldn't do?
I enclose one of the defined reference type controls. I tried to change it bare to see if that helped, but no luck.
To reproduce, change the resource string for the element 0 of the array and do the new value by default. Then close the def of type, and then reopen it. The old value is always present in this element. The VI is saved in LabVIEW 2012.
The values of a typedef are not proprigated to the instances of the control. They get if created WHEN data values have changed. They will be not updated with the changes to come. You must create a VI specifically to hardcode your values or to implement a file based initialization. The base file would be much better and more flexible. If you don't want users to change the data simply encryption. There is a wedding blowfish library that you can download.
-
Select a record for each Member of the Group
Hello
will have a table where in I'll take data for so many members of the group. I need to retrieve data for a particular group whose number of rows of data may be more in number (but I don't want only one row of data for each Member of the Group)
Here is the query to retrieve all rows of data
This query result is...select RI.RESOURCE_NAME,TR.MSISDN,TR.ADDRESS1_GOOGLE, TR.MSG_DATE_INFO, FROM TRACKING_REPORT TR, RESOURCE_INFO RI WHERE TR.MSISDN IN (SELECT MSISDN FROM RESOURCE_INFO WHERE GROUP_ID ='1' AND COM_ID=2 ) AND RI.MSISDN=TR.MSISDN order by MSG_DATE_INFO
>
DDD 12345 13 March 10 19:43:03
EEE 54321 Tamilnadu, India 13 March 10 19:39:48
DDD 12345 13 March 10 19:32:58
EEE 54321 Tamilnadu, India 13 March 10 19:30:07
DDD 12345 13 March 10 19:23:08
EEE 54321 Tamilnadu, India 13 March 10 19:20:14
FFF 98765 March 13 10 19:19:22
DDD 12345 13 March 10 19:13:01
EEE 54321 Tamilnadu, India 13 March 10 19:09:50
DDD 12345 13 March 10 19:02:56
EEE 54321 tn, ind March 13, 10 18:59:49
DDD 12345 13 March 10 18:53:08
EEE 54321 tn, ind March 13, 10 18:49:50
DDD 12345 13 March 10 18:42:56
EEE 54321 tn, ind March 13, 10 18:39:50
DDD 12345 13 March 10 18:33
EEE 54321 tn, ind March 13, 10 18:29:50
DDD 12345 13 March 10 18:22:54
EEE 54321 tn, ind March 13, 10 18:19:50
DDD 12345 13 March 10 18:12:56
EEE 54321 tn, ind March 13, 10 18:09:50
DDD 12345 13 March 10 18:02:54
EEE 54321 tn, ind March 13, 10 18:00:02
FFF 98765 Tamilnadu, India March 13, 10 17:59:26
FFF 98765 Tamilnadu, India March 13, 10 17:54:26
DDD 12345 13 March 10 17:52:56
EEE 54321 tn, ind March 13, 10 17:49:50
FFF 98765 Tamilnadu, India March 13, 10 17:49:25
FFF 98765 Tamilnadu, India March 13, 10 17:44:26
DDD 12345 13 March 10 17:42:56
>
This output, I only want a new album for each member(ddd,eee,fff). That is to say
>
DDD 12345 13 March 10 19:43:03
EEE 54321 Tamilnadu, India 13 March 10 19:39:48
FFF 98765 March 13 10 19:19:22
>
How to change the query to do this...?Ok. I looked more carefully at your sample and it looks like you are looking for:
SELECT RI.RESOURCE_NAME, TR.MSISDN, MAX(TR.ADDRESS1_GOOGLE) KEEP(DENSE_RANK LAST ORDER BY TR.MSG_DATE_INFO), MAX(TR.MSG_DATE_INFO) FROM TRACKING_REPORT TR, RESOURCE_INFO RI WHERE TR.MSISDN IN ( SELECT MSISDN FROM RESOURCE_INFO WHERE GROUP_ID ='1' AND COM_ID=2 ) AND RI.MSISDN = TR.MSISDN GROUP BY RI.RESOURCE_NAME, TR.MSISDN /SY.
-
Many storage spaces and data for each quarter of the year files
Hello
I am junior DBA and I have a question about tablespace partitioning or data file sharing.
I have a database of 10g in many storage spaces, for example:
KER_DATA_2009_Q1
KER_DATA_2009_Q2
KER_DATA_2009_Q3
KER_DATA_2009_Q4
KER_INDX_2009_Q1
KER_INDX_2009_Q2
KER_INDX_2009_Q3
KER_INDX_2009_Q4
There is also a data file for each tablespace that is mentioned.
But for this year 2013, only two big storage space I can get one and data KER_DATA, KER_INDX files.
All tables and indexes in the whole database are KER_DATA, KER_INDX, tablespaces.
I don't know any cut in two storage spaces and means of data files. Is this something like tablespace partitioning? This can be done automatically or someone needed to do it manually on the end of each quarter?
This should be done to improve performance, several small files data instead a large?
Can some admin explain this to me?
The reason for this separation of database/tablespace was partitioning. There are a lot of tables partitioned by date column, and there are partitions for each quarter of the year. There are tablespace with a data file for each quarter (partition).
-
(For each) components in the OSB
I try to use component "For-Each" to perform a loop on the message to bulk out bulk and publish individual messages of the loop. However the loop does not run several times. It passes through the only once for each component. The key message is ';' separated from text messages.
There are about 4-5 different parameters to be set for the component. as a County, index, param, and xpath.
What best values to put in it so that the component gives the desired effect?
Thanks in advance.You try to say I'm going to use a component of the NEWSPAPER inside the component for EACH?
N ° it is a control sample if the loop is getting executed as required. You can completely ignore the alert/Log and place your logic. With sample data that you have posted, I have confirmation code posted earlier worked on my local machine. You may need to change depending on your use case.
But with my specified parameters for EACH component is not executed at least once.
The first glance, it seems that you XPath: v_XML. BUlkMessage.Transaction (v_XML here are the above XML code) has something to do with your problem. You should return table of elements that confirm specific condition. With the help of .//transaction is a way to query all the
with in the specific variable. Thank you
Maury -
How can I make a cell formula will apply for the entire column? For example D2 appears B2 - C2. How can I copy this formula for each cell in the column?
If you want the formula is the same (B2 - C2) in the cell of each column you must change it as ($B$ - 2$ C$ 2). Then copy it, select the whole column and paste.
-
My ip6glass Panel is the lifting of his body. There is a black spot on the left corner. How much would it cost if I go to the Apple Store because my warranty is expired. I heard that they would replace it for free even if the warranty has expired. Is this true? Thank you
Sorry, but at least the screen needs to be replaced. Do you have the battery exchanged in the past?
Visit an Apple Retail Store or an authorized Apple Apple Service Provider next to your place to achieve this.
You can also contact the Apple Support to send it.
Find an Apple authorized service provider
Apple iPhone - contact Support - support
Pricing of the service repair screen
Repair and replacement costs depend on your iPhone and your AppleCare products cover model. Apple runs a diagnostic test to determine if your iPhone has suffered additional damage. If she has, or if she needs more repairs, you may have to pay out-of-warranty service. Accidental damage is not covered by the Apple one-year limited warranty.
Model Screen repair cost iPhone 6 $109 iPhone iPhone 6s 6 Plus, iPhone 5 s, iPhone 5, iPhone 5 $129 iPhone 6 sec more $149 In addition, a $6.95 shipping charges if necessary. Fees are in US Dollars and exclude tax. The price is for the service through Apple. The final service charge we charge will be determined during testing. Pricing and terms vary for the service by an Apple authorized service provider.
copied from answer Service Center - iPhone
-
My system features, i7 thinkpad w540, 16 GB of ram and a 256 GB ssd. Using MSE as av with AMBM pro
whenever I start my system, win 7 x 64, I get the following error in the event viewer:
Custom dynamic link libraries are loaded for each application. The system administrator should review the list of libraries to ensure that they are linked to trusted applications.
any help with this error?
Atul
Description: NVIDIA shim dll initialization
- Product: Shim NVIDIA D3D drivers
Company: NVIDIA Corporationhttp://systemexplorer.net/file-database/file/nvinit-dll/33069751I would not be concerned by this driver.
- Product: Shim NVIDIA D3D drivers
-
Unlock the position of the 'legends box' for each image in the slideshow
Hi guys,.
I have a slideshow that has 8 images with thumbnails for example. I want to move the caption (text box) for each image in the other location, but if I adjust the caption of an image and others, their legends are exactly in the same position as the caption for the first image.
There must be a work around for this surely,
I came across this post - help with captions in slide shows , but I do not understand what is needed to do this, if someone manages to do, could you please limit exactly what is needed to get the look. I tried to disable "change set" and that did not help either.
I hope someone can help here, I really need to be located in different places for each image captions in the slide show.
Thank you!
You can use any composition in the form of a slide show and add the text block in the container, place the block of text in a different location for each container.
Thank you
Sanjit
-
Is it possible to create a tag that lists the individual labels [keywords] for each position? The current {tag_blogtaglist} creates an endless list of tags.
If you can get hands on with the ID of blog post that you can list the tags assigned to this post particularly blog using module_data. It would be only possible with the new BC. Active following rendering engine. Here are some resources to point you in the right direction: how to activate the BC. Next - http://docs.businesscatalyst.com/developers/liquid/introduction-to-liquid#enable how to use module_data - odule_data http://docs.businesscatalyst.com/developers/liquid/consuming-apis-in-the-front-end-using-m install app BC API discovered to get you started on the syntax - http://docs.businesscatalyst.com/developers/apps/bc-api-discovery module data that lists the tags assigned to a blog post looks like this: {module_data = 'blogposts' version = "v3" field resource = subresource 'tag' = "tags" resourceId = collection "303870" = "myData"} resourceId is the blog ID to render tags for. Hope this helps, Mihai
-
Ungroup a group and keep the scriptlabel for each item in the Group
Hello
does anyone know how to ungroup a group of rectangles with a certain tag (example groupA) give one every rectangle a clean label (the same text groupA)
I can find the Group and ungroup it but I can't label the rectangles...
var oPageItems = app.activeDocument.allPageItems;
for (var j = oPageItems.length - 1;) j > = 0; d-) {if (oPageItems [j] .label == ("groupA")) {oPageItems [j] .ungroup ()))}}
...???
Help, please
Hello
front
oPageItems [j] .ungroup ();
go through the loop and set a label for each item within the Group:
for (var k; k)< opageitems[j].length;="">
oPageItems [j] [k] .label = "groupA";
assuming that your oPageItems [j] is a group indeed.
I hope that...
-
How to print 1 page for each line of the numbers worksheet
Hello... I am trying to print reports of year-end per person and number.
Is it possible in number to print 1 page for each row of a spreadsheet of numbers?
Or suggestions?
Thank you.
Hi cm,
This looks like a work of fusion and mailing.
The merge document would create in Pages, and the cells of merger on this document référenceriez cells in the table in the document numbers.
See the documentation Pages (on the Help menu) for instructions on the conduct of merger and mailing.
To do this in only numbers, you would need to put in place a 'table of declaration' on a separate sheet (in the same document as the table containing information) which would accept a customer number (or other key ID for each individual) then use it to determine the line of the main table to retrieve information about this pattern.
A more precise answer requires a more specific desription of your table structure and the desired form of the instruction to take.
Kind regards
Barry
-
I have a chart single 2D out a conditional of a loop indexing output such that over the rows of the table are not the same size. -Basically, they have different starting and ending points and sizes. -Not so concerned by the endpoints, because as soon as I get correctly starting points, everything shows fall in place.
The challenge is that when I try to have the variable t0 (start time) for each line, the wave of construction vi form would always keep each line at the same starting point.
I used the approach bundled with success (the cluster approach ensures that each waveform starts at different times according to the guidelines of my t0 defined for each line) but then I'm not able to get in the channel names I could make using the graphical approach (wave generation) waveform.
In essence what I get here, I'm losing here.
Because I don't want one of my mentors, Bob and Altenbach have fed up with me I have attached a vi this time

Attached VI shows a combination of the two attempts (first with the waveform graph) and then with the graph of cluster
1. with the first (graphical waveform), I get my channel names as you wish, but the alignment of the wave is not correct.
2. with the second (graphical cluster), the alignment is good, but I can't do the names of channel in the chart, even if they are present in the cluster.
I read some reviews that mentions that attributes can be displayed with waveform and data Dynamics (not clsuters) so I guess that's why.
I saw another report indicating the start time for a waveform 1 d will always remain the same for the rest lines defined for the first line even if changed for the following lines in a loop.
So I guess my question is: what is the way around questions like that?
First of all, let me be the first to the congratulate and thank you for finally posting a code! I'm not 100% certain I understand your question or your code, but I have an idea, perhaps, of what you want to do, so I wrote a little VI who made something simple that could be relevant.
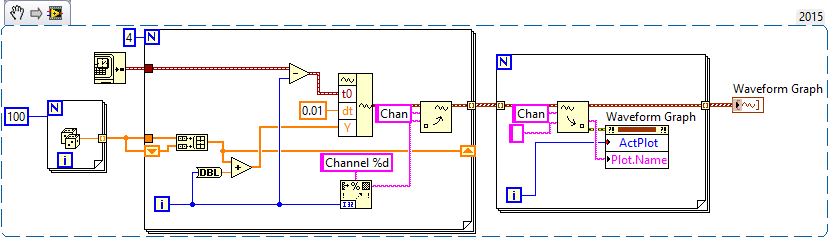
You mention waveforms of different lengths and beginning at different times. You also want everyone to have a unique attribute (although I'm not sure what you want to do with the attribute). So, I did the following:
- Generated an array of 100-sample random to represent one second of a waveform.
- Created 4 waveforms on this 100-sample basis. The first waveform (channel 0) is just these 100 points. The second, 1 channel, is the concatenation of string 0 with the base of 100 samples, or a waveform "double". Channel 2 is 1 string concatenated with the base, and channel 3 is 2 string concatenated with the base.
- In order to trace the four channels that they rest 'on' the other, the waveform has the number of the channel added to it. Channel 3 is 3 + (4 copies of the basis of 100 points), a waveform 400-point random centered around a shift of 3.
- All channels have dt value 0.01 (but I guess I could have varied, as well).
- To make the channels start at different times, I started channel N N seconds before channel 0 (by subtracting the index of the loop, I, T0).
- For each channel, I created an attribute called "Chan" equal to "Channel N" (where N = 0, 1, 2 or 3, as the case may be).
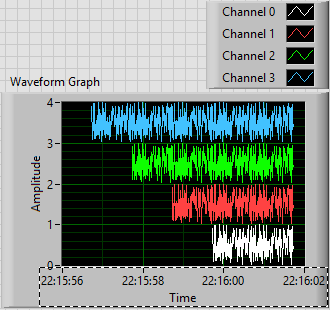
This is the plot that results. Scale X is the absolute time value (no Date) using the 24-hour HH: mm
 S format. You can see that the plots are 1, 2, 3 and 4 seconds of time, and are offset from each other by a second. I used the trace attributes to change the name to the respective attribute.
S format. You can see that the plots are 1, 2, 3 and 4 seconds of time, and are offset from each other by a second. I used the trace attributes to change the name to the respective attribute.The code to do this is very simple - I almost don't need to show it, because I think it is completely described by the text above, but this is here:
Now, it was not that much faster that some of your previous posts, when you refused to your postcode, "guess us" what you wanted (but not to not correctly guess), you tried to "push" us in the right direction (still refuses to post code), and no one seemed very happy?
Bob Schor
-
For each hit in the where clause, also get the entourage records
We have a table that contains the content of some files. The structure of the table is (Simplified):
CREATE TABLE LOG_LINES
(
FILE_ID NUMBER (15.0).
LOG_LINE_NUMBER NUMBER (9.0).
CLOB LOG_LINE
)
We build a search engine that looks through the lines to find a regular expression, it should return the lines that match the regular expression, in addition to 5 lines before this line and 5 rows after this line.
So to say that our regex match line 10, we must return the row 5 to 15.
Currently, this is how we solve our problem:
1 questioning the rows that match the regular expression (select file_id, log_line_number from log_lines where regexp_like (log_line, 'Search'))
2. for each record that is returned by this query: query the table log_lines to get the required rows (select * from log_lines where file_id = x and log_line_number between y and z)
Now, it seems to create a lot of overhead, because there could be 1000 matches, it takes to 1000 queries for all results.
I was wondering if there is a better way to tackle this problem. It may be possible to just 1 request that returns the corresponding lines more than 5 records before and after.
Any help on this would be greatly appreciated!
Published by: Peter Marcoen on 11 January 2013 04:22
Published by: Peter Marcoen on 11 January 2013 04:23with t as ( select file_id, log_line_number from log_lines where regexp_like(log_line,'search') ) select file_id, log_line_number from log_lines l, t where l.file_id = t.file_id and l.log_line_number between t.log_line_number - 5 and t.log_line_number + 5 /SY.
Maybe you are looking for
-
I have a lot of tags on my desk - it there a way to sync with my phone?
The use of Firefox on Mac and just installed on Android. I have synced, but I do not see a selection for tags, and I can't seem to find the solution on the internet. Is there an add-on for this, or I'm looking in the wrong place? If Firefox doesn't h
-
How to remove a podcast which was published thanks to Wordpress?
I have a wrong version of an mp3 that has posted. The podcast of the positions directly to iTunes through Wordpress once it is displayed. How can I remove the podcast to iTunes after it was sent. Just remove the post on Wordpress did not delete iTune
-
Message from Visual Voicemail for blackBerry Smartphones is frozen.
I have the Bold 9700. I announce myself to a visual voicemail when I got a call. After calling, visual voicemail message is locked. I can remove it, but when I get a new Visual Voicemail the old one that I deleted re appears with a new, and both a
-
The Installer seems to have written the wrong ID of Application AUM
I am currently working with indesign cs2 - I know it's a very old version, if I had the money to upgrade I would be so please don't suggest this as it is very helpful! I use a PC on windows 10. Everything has been great to work with no problems until
-
VRA booking based on the place and or booking
HelloI currently use a single blue print to deliver a few versions of server in two different locations (A, B). I would like to make A location applications to use a custom permission policy. I want to achieve this while maintaining a single plan. Do