Data from multiple rows in single line in BI publisher 11g
Hello
I receive documents in multiple lines
for example
ID case1, case3 CAS2
1 C1
1 C1
1 C2
1 C4
Now, I want to make it as a single line, output desired is
ID Case1, Case3 CAS2
1 C1 C2 C4
is it possible, please let me know.
Thanks in advance
Kind regards
Sam
He seems to do at the level of the model.
Could you please post your example of xml data?
Tags: Business Intelligence
Similar Questions
-
map a java object to data from multiple data sources
We have the requirement that the attributes in a domain class can come from data from multiple data sources. Is TopLink supports this type of mapping? Is it possible to do this mapping in the workbench?
Thank you very much!
Ming-WenTopLink supports a feature of SessionBroker. This allows classes in the same session to come from different sources of data and for the relations between the classes of data sources. It does not allow a single instance of direct data from multiple data sources, but the Forum could have a link with its data in the other data source.
----
James: http://www.eclipselink.org -
L50-A-19N satellite can not read audio data from multiple sources
I can't read the audio data from multiple sources. It is very annoying when I have 2 youtube videos, playing, if I start playing something on the media player, there is no sound on media player, it's the same when I have 2 open media players and 1 youtube video playing, youtube video has no sound...
It disappears when I plug my headphones...I already have all the latest drivers, the DTS driver was last updated was in 2014, his day of February of this year...
25/02/14
DTS Inc.
Windows 8.1 - 64 Bit
1.01.2700
I don't know if this has the feel, but I had his most recent DTS driver that I found, it is not my laptop model, but they all seem to be the same - v1.1.88.0
I uninstalled the DTS software and still had the same problem, then it is irrelevant on its driver somehow...02/10/15
Integrated Device Technology Inc.
Windows 8.1 - 64 Bit
6.10.6491.0
Audio driver IDT has more recent release date, but the version of the driver is the same as the 2013 one...
Why the older drivers of toshiba releaseing as 'NEW '?
2nd is my Advanced settings speakers, nothing has changed when I disabled "allow applications to take exclusive control of this device.
Sorry but I don't understand your problem.
I tested it on my machine and if I start the music on three different sources (YouTube, player, web radio) I can hear all together, but it makes no sense to listen to music from different sources.Or how do understand you?
-
Aggregation of data from multiple sources with BSE
Hello
I want to aggregate data from multiple data sources with a BSE service and after this call a bpel with a process of construction of these data.
1 read data from the data source (dbadapter-select-call)
2. read data from the data source B (dbadapter-select-call)
3 assemble the data in xsl-equiped
4. call bpel
Is this possible? How can I get data from the first call and the second call to conversion data? If I receive data from the second call, the first call data seem to be lost.
Any ideas?
GregorGregor,
It seems that this aggregation of data is not possible in the BSE. This can be done in BPEL too using only assigned but not using transformations. I tried to use transformations by giving the third argument to the function ora: processXSLT. But couldnot get the desired result.
For more information on the passage of a second variable (of another schema) as a parameter to xslt pls refer to the post office
http://blogs.Oracle.com/rammenon/2007/05/
and the bug fix 'passage BPEL Variable content in XSLT as parameters'.
Hope this helps you.
Thank you, Vincent.
-
Page 79 of erpi_admin_11123200.pdf says that "reporting entity groups are used to extract data from several reporting entities in a single data rule execution. I use standard EBS adapter to load data in HFM application, I created a group of entity made up of several accounting entities, but I can't find a place in FDMEE where you get to select/use this group... When you define an import format you type the name and select Source (e, g. EBS) system you can select Map Source (for example EBS11 I adapter) or the accounting entity (it is what I select to define data load maps), but not both. Note that there is no place to select the Group of accounting entity... Location check menu group entity drop-down but it doe not my group of accounting entity which I believe is anyway something different... and creating a location and pointing to a format compatible with the selected Source adapter is no not good either... I'm confused, so is it possible to load data from several reporting entities in one rule to load or am I misreading the documentation? Thank you in advance.Do not leave the field blank in the Import Format. If leave you empty to the place, when you set the rule to load data (for the location with EBS as a Source system), you will be able to select a single accounting entity or a group of accounting entity.
You can see here
Please mark this as useful or answer question so that others can see.
Thank you
-
Copy the data from two rows together in a new line
Hello everyone.
I have a question for copying data from two lines together in a new third line.
See this short example:
This is the current situation. The lines STATE_1 and STATE_2 contain different information separate.
In the past data were recorded at random in one of these lines.
It's the state table:
ID Cust_id STATE_1 STATE_2 STATE_3 1 88 Customer is waiting. Call since yesterday. 2 11 Mr. Smith, no answer. Wait until December 3 11 Pls Create PO. Old PO has been cancelled 4 5 No access to the system. Now, everything must be recorded in the STATE_3 void, but I also need than the old entries from the past which must also be copied together in STATE_3
Like this:
ID Cust_id STATE_1 STATE_2 STATE_3 1 88 Customer is waiting. Call since yesterday. Customer is waiting. Call since yesterday 2 11 Mr. Smith, no answer. Wait until December. Mr. Smith, no answer. Wait until December. 3 11 Pls Create PO. Old PO has been cancelled. Pls create in. old PO was canceled. 4 5 No access to the system. No access to the system. Y at - it an SQL-easy order?
Thanks for any help.
What:
update set state_3 = state_1 State | » '|| state_2;
?
-
How to recover data from multiple data sources in a single destination using ODI 11 g
Hello
We have about 20 sql server instance. We need extract data from these systems in a system of dataware house. I don't want to create 23 connections in the physical topology. As every year, we have a few additions/deletions in the forums. So I would like whether it's generic, for example, I'll save the jdbc connection in a table and add/remove as and when necessary details. The structure of the tables in the bodies of 20 are the same. We do not want to implement using contexts.
Can you please let me know the procedure to get the same thing.
Kind regards
Alok Dubey
Hello
Looks like you need to use a variable in the configuration of your topology to avoid several physical servers. Great example here: https://blogs.oracle.com/dataintegration/entry/using_odi_variables_in_topolog
-
How to handle data from multiple fields
Hi all
My data are:FldName FldTypeCode Text
In the user interface, I give all the data of three fields with refcursor. now in HQ DB happening all the values to be updated at the same time.
Sandya 02 nothing
Raj 01 12/Oct/2008
Lokesh 03 12546
Harish 04 12565.35
King 01 12/Nov/2007
Cobra 02 texttype
(Q) now my question is how to update all values.
For example: create procedure procdname (ip_allvalues in typerecord)
is
Start
-statements;
end;
the procedure input parameter above can manage all data from three fields as they pass.
(1) if the parameter handle, should what kind I create?
(2) I need how can I update multiple records at once?
Please can any body...
Thanks in advance...sanjuv wrote:
But when it goes to day it must pass all records at once (lines have almost 55) at a time not possible to update for all records but also not good to create input parameters for the procedure 55. If it has past a table how can I handle this situation.Why do you need to update all records at once? And what is blocking you implements a loop on the user interface which, for each changed row, submits an update of the DB? Note that you will get no improvement with a bulk operation when entering comes from a user interface.
Alessandro Bye
-
Out of proc - values from multiple rows.
I have 5 tables. Every table has the following columns
TRANS_ID,
USER_ID,
OPRTN_TYPE,
STATUS,
DATE
I have to write a proc for which an entry is USER_ID and output must be TRANS_ID, OPRTN_TYPE, STATUS, DATE.
Is it possible to write the proc with the mentioned columns, the values will be more than one row in the table.user13024762 wrote:
I have 5 tables. And I need output of all tables at the same time. If I want to use Ref Cursor I write a cursor for each query with 5 outputs, or I can do it with a single output.No, just return a single Ref Cursor
Is it possible to bring together the tables? As I don't have your database or model, it is difficult to advise you on this.You could do something like
select TRANS_ID, USER_ID, OPRTN_TYPE, STATUS, DATE from table1 where user_id = p_parameter union all select TRANS_ID, USER_ID, OPRTN_TYPE, STATUS, DATE from table2 where user_id = p_parameterand this return as a Ref Cursor
Thanks for the link refcursor.
You are welcome.. ;)
-
Extract data from multiple objects of BAM
If you send data to multiple objects... Controls object and object elements, you can bring together them for a BAM dashboard? Or are you stuck with pulling of an object for your reports? I can't find any documentation on this... all of the examples I can find point from the data of an object.
Thank you
SYes, you can join several data objects using the fields look (this is equivalent to JOIN in SQL). Please see documentation BAM on search fields. You can find it in the developer's guide in the chapter "Creating data objects," in the section "how to add search columns to a data object.
-
Create views of data from multiple lines in a single column shows
Hi all - it's probably posted in the wrong forum, but I couldn't find that was right.
I'm almost a perfect beginner in sql, but I have a need to create a view that can be expanded to 10g (which effectively runs the volumes are likely to be high) who will do the following.
Authentic table with columns Parent_code, Child_code
Parent_Code Child_Code
1000-2000
1000-3000
1000-4000
2000 3000
2000-5000
(note that Parents may have several children and a child can have multiple parents!)
What I have to finish with in my opinion is the following
Child_Code Parent_List
' 2000 ' 1000 (3).
3000 "1000 (3), 2000 (2)"
' 4000 ' 1000 (3).
"5000 ' 2000 (2)"
Note the number in parentheses is the number of children whose parent's - IE in the original parent a 1000, 3 table lines (one for each child)
This point of view should be used as a quick glance upward (on the children's code) for a report of business objects.
Is there someone who could you PLEASE, PLEASE help me quickly on what I have very little time to find a solution?Hello
You can test these:
select child_code , ltrim(sys_connect_by_path(parent_info,', '), ', ') as parent_list from ( select child_code , to_char(parent_code) || ' (' || count(*) over(partition by parent_code) || ')' as parent_info , row_number() over(partition by child_code order by parent_code) rn from your_table ) where connect_by_isleaf = 1 connect by prior rn = rn-1 and prior child_code = child_code start with rn = 1 ;select child_code, rtrim( extract( xmlagg(xmlelement("e",parent_info||', ') order by parent_info) , '//text()' ) , ', ' ) as parent_list from ( select child_code, to_char(parent_code) || ' (' || count(*) over(partition by parent_code) || ')' as parent_info from your_table ) group by child_code ;What you need is called 'chain aggregation '.
See here for the various techniques, including the two above: http://www.oracle-base.com/articles/misc/StringAggregationTechniques.php -
How to extract the data from each row
Hello
I wrote a CQL query with lines 3 records. Is it possible in this query to fetch the first record and last present specific field values.
for example,.
Column: c1, c2, c3
Record1: id1, 2,3, 3.5
Record2: id2, 2.3, 3.6
record Record3: id21, 2.3, 3.7
record Record3: id25, 2.3, 3.9
I need to get the average of three rows of c3 and get the first record id and last record ID.
Output 1: id1 id1, avg (c3) = 3.5
output2: id1, id2, avg (c3) = 3.55
Output3: id1, id21, avg (c3) = 3.6
output4: id2, id25, avg (c3) = 3.733
Please help on above.
Thank you
SriHello
Not quite sure that understand what is the problem that you see.
Here's what I got when I ran the query:
Input data:
C1, c2, c3
ID1, 2,3, 3.5
ID2, 2.3, 3.6
id21, 2.3, 3.7
ID25, 2.3, 3.9
DELAYED26, 2.3, 4.0
ID27, 2.3, 4.1Query:
Select T.firstC1, T.lastC1, S1 T.avgC3
() match_recognize
measures
First (M1. C1) as firstC1,
M2. C1 as lastC1,
AVG (C3) as avgC3
all matches
model (A B? C ? | D + C)
subset m1 m2 = (A, B, C) =(A,D)
define
At as prev (A.c1) is null.
B as (count (*) = 2),
C as (count (*) = 3),
D like ((prev (D.c1) is not null) and (count (*))<>
) tOutput:
firstc1, lastC1, avgC3
ID1, id1, 3.5 - avg only trace
ID1, id2, 3.55 - avg from two records
ID1, id21, 3.6000001 - avg from three recent reviews
Id2, id25, 3.7333336 - avg from three recent reviews
id21, delayed26, 3.8666668 - avg from three recent reviews
ID25, id27, 4.0 - average last three book reviewsThis output confirms with you that mentioned the expected results?
Can you please run this query as it is on the above mentioned input data and check by yourself?
If you don't get the desired result, please paste the input data provided, complete the text of the query and the outputs.Concerning
-
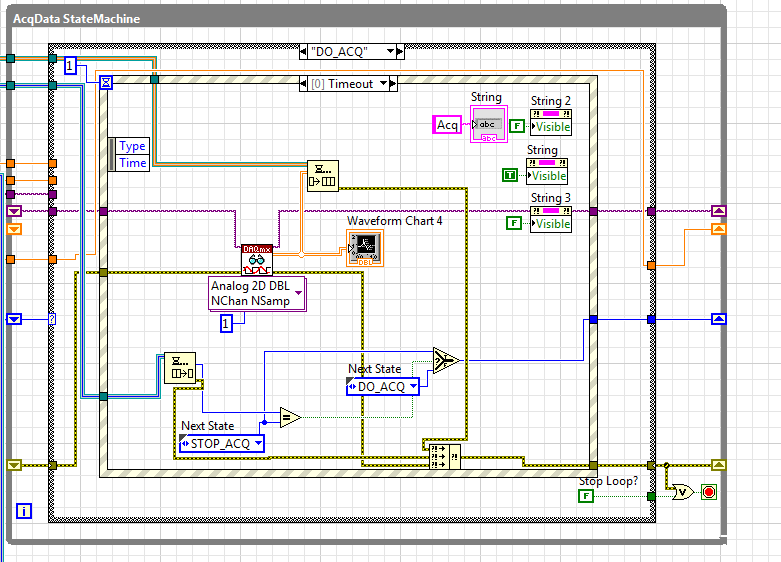
Acquisition of data from multiple loops
Hello
I tried to adopt a program of data acquisition of multiple loops with control of queue, but it does not work as it should. (Or at least the way I think it should) Could you please help me it smooth? I have seen a few screws on the internet with the queue-control and tried their adoption.
My program should work this way: after you complete the settings, I begin the acquisition of data (an analog output and 2-4 analog inputs), but I only want to save the data acquired when I click on a registration button. (Then these data would go for further analysis). While doing the analysis, the acquisition may be suspended. However, when I click on record I would like to have a feature to instantly restart the recording and to ignore the previously recorded data.
MainProgram vi is the application itself, with some settings made by the event handlers (now only limited to a selection of signal file and the channel settings). Then the data acquisition can be started by clicking on the button start the Acq.
And these are my issues: first, sometimes the queue starts, sometimes is not (or at least it does not start the data acquisition). And the main point: I put the sampling frequency, but it is acquired at a slower pace of well (my signal has a delay of 4 seconds, but he needs at least 20 seconds before getting close to finishing). And the strangest: sometimes, especially after some time (about 1-2 min) it freezes and does nothing with the acquisition of data (yet labview seems sensitive, just my program blocks somewhere).
So now only controlled acquisition is in the problem and firstly I don't like on the transmission data for analysis and recording. (Which seems to be the smallest problem).
What I am doing wrong? Thanks for your help.
I join all the files. (MainProgram is the application itself, MY. SIGNAL is the signal I want to exit.) I use a USB-6211. (for physical work, home a simulated).
Not directly related to your mistakes but (and here I don't mean to take on you, but... With an alias as yours, I assume that you have some sense of humor)
Really? an event structure single image with only one case of timeout (value 1mSec) with a Dequeue inside element
 how do you code would work by simply removing the structure of the event entirely
how do you code would work by simply removing the structure of the event entirely
-
Question to merge data from multiple records
Hi all, could really use some help here, I tried to fix this for hours now:
Make 3 different models for labels that I print on the basis of models of labels Avery for InDesign. When I come to my fusion of data on any of them, I select "Multiple records" in the title records per Document Page, but the preview and the actual creation just spits out a single unique label on each new page. For example, I use 2 x 4 "labels on 2 of them, so it should print 10 per page, but instead to put 10 unique labels on a page, it puts each new label on a new page. Therefore, instead of 100 pages for the 1 000 labels that I print, I find myself with 1,000 pages.
I know a double check of size constraints on the text box and make sure it suits you when duplicated, and to my knowledge, who is seeking as it's nice. I'm also fairly certain that CSV files that I use are in the right format, too. I am quite stuck at this stage as to what I have to do to solve this problem, no guidance would be great. Here are the screenshots of what I'm looking, please let me know if there is anything else I can give you to help diagnose the problem.





I thinnk the best way to deal with this would be to ensure that all the Avery template information on the master page. Let him be active while you do the layout in the upper left position on THE DOCUMENT PAGE, and then assign the master let anything showing that your placholders and art added none.
Reassign the master model after the merger.
-
advice/assistance on the consolidation of data from multiple Macs
Hi, I have accumulated years worth of data... text, multimedia files, documents of all kinds - everywhere
a variety of Macs - Mobile Office, Mac mini, iMac - each running 10.6.8 systems or 10.8 +.
My mission, after a new backup of each of these respective volumes - is to gather all the data on their part on a single external hard drive in order to see him again all for relevance - after executing a kind of double-eliminator app like Tidy Up or Gemini - and in turn, to classify everything in a logical as a whole new folders.
Before you start what I want to know if I'm going to run into some weird permissions problems or other have difficulties to open any of the data collected on the "new master" HD - and if so, what can I do to not have this happen. Back in the day, we could of course just do drag an entire volume of HD on another HD and find it... who was OS9 and earlier of course.
I am concerned about the content of the data - not applications/utilities - those that are not relevant to this project - it is organize information (docs) and multimedia files. Where also does make sense for only the copy of the files
vs 'everything' - and if so... what would be a good way of singling out and only transfer that data on the new 'master' review by car?
Thanks for your time and any thoughts on the best way to do this.
Mike
iMac, Mac OS X (10.6.8)
For permissions, after you copy the data to the external hard drive, do a Get Info (command - I) on the drive and check for the option ignore the property. If this is not available, unlock the lock and give you read/write permissions. Then, click on the gear down and select apply to included items.
Normally, all data are stored in your user/home folder, so if you copy the folders that are located in your user/home folder, which should get your data.







Maybe you are looking for
-
Alignment of the mouse in flash-based objects is completely wrong
Since I installed FF 8.0 I continue to have this problem: whenever I try to use an object flash (, video game, YouTube etc.), there seems to be a problem with the alignment of the mouse: the position of the pointer as part of object is different then
-
Hello hope I posted in the right place. I'm about ready to buy a cDAQ-9172 chassis and modules temperature 9211 or 9219 universal. I have not yet taken my mind yet. Then, I thought that one of them would make the temperature range required that I nee
-
Upgrade the card video EliteBook 8540w
I have an EliteBook 8540w with the Quadro FX 880 M. I was wondering if it was possible at this level towards the M5800 over-pants and, if so, would I need to change my radiator? The reason why I want to do is to be able to eventually turn 4 monitors
-
Scanner LiDE 220 - leave it lit?
I bought a scanner LiDE 220 from Amazon and installed yesterday. So far I like it really - especially the Auto Scan function that figures on what you scan and crop it for you. I love it so much that I ordered another today for my wife's computer. I h