Difference in date in the same column
Select to_char (CREATEDON, 'DD-MM-YYYY HH24:MM:SS'), LABSTATUS, history_paperlesstran COMMENTSwhere hnum = ' 797551 order by to_char (CREATEDON, 'DD-MM-YYYY HH24:MM:SS');
Rownum TO_CHAR(CREATEDON,' LABSTATUS REMARKS)
------------------- ---------- --------------------------------------------------
1 10/20/2010-08:10:08 1 barcode number generated and printed
2 10/20/2010-08:10:08 1 barcode number generated and printed
3 10/20/2010-08:10:08 1 barcode number generated and printed
4 10/20/2010-08:10:08 1 barcode number generated and printed
5 10/20/2010-08:10:08 1 barcode number generated and printed
6 10/20/2010-08:10:08 1 barcode number generated and printed
7 20/10/2010 09:10:55 3 totals received by the Department
8 10/20/2010-09:10:58 3 totals received by the Department
9 10/20/2010-09:10:58 3 totals received by the Department
10 10/20/2010-09:10:58 3 totals received by the Department
11 20/10/2010 09:10:58 3 totals received by the Department
12 10/20/2010 10:10:38 3 totals received by the Department
13 20/10/2010 11:10:34 1 barcode number generated and printed
14 10/20/2010 11:10:34 1 barcode number generated and printed
15 20/10/2010 11:10:35 3 totals received by the Department
16 10/20/2010 12:10:08 3 totals received by the Department
17 20/10/2010 14:10:03 1 barcode number generated and printed
18 10/20/2010-14:10:44 3 totals received by the Department
18 selected lines.
Dear friends, now I want to get the difference in date on labstatus based, i.e rownum1 - rownum7, rownum2 - rownum8 and rownum17 - rownum18
Thing is Barcode number generated and printed - totals received at the Ministry for each and every samples.
Thanks for your solution in advance...
Published by: bharathit on October 21, 2010 02:18
You mean something like this?
SQL> ed
Wrote file afiedt.buf
1 with t as (select 1 as rn, to_date('20-10-2010 08:10:08', 'DD-MM-YYYY HH24:MI:SS') as dt, 1 as labstatus, 'Barcode number generated and printed' as comments from dual union all
2 select 2, to_date('20-10-2010 08:10:08','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
3 select 3, to_date('20-10-2010 08:10:08','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
4 select 4, to_date('20-10-2010 08:10:08','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
5 select 5, to_date('20-10-2010 08:10:08','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
6 select 6, to_date('20-10-2010 08:10:08','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
7 select 7, to_date('20-10-2010 09:10:55','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
8 select 8, to_date('20-10-2010 09:10:58','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
9 select 9, to_date('20-10-2010 09:10:58','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
10 select 10, to_date('20-10-2010 09:10:58','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
11 select 11, to_date('20-10-2010 09:10:58','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
12 select 12, to_date('20-10-2010 10:10:38','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
13 select 13, to_date('20-10-2010 11:10:34','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
14 select 14, to_date('20-10-2010 11:10:34','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
15 select 15, to_date('20-10-2010 11:10:35','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
16 select 16, to_date('20-10-2010 12:10:08','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual union all
17 select 17, to_date('20-10-2010 14:10:03','DD-MM-YYYY HH24:MI:SS'), 1, 'Barcode number generated and printed' from dual union all
18 select 18, to_date('20-10-2010 14:10:44','DD-MM-YYYY HH24:MI:SS'), 3, 'Recieved in department' from dual)
19 --
20 -- END OF TEST DATA
21 --
22 ,x as (select rn, dt, labstatus, comments, row_number() over (partition by labstatus order by rn) as labrn from t)
23 --
24 select y.rn as rn1, y.dt as dt1, z.rn as rn2, z.dt as dt2, round((z.dt - y.dt)*24*60) as mins_diff
25 from x y join x z on (y.labrn = z.labrn)
26 where y.labstatus = 1
27* and z.labstatus = 3
SQL> /
RN1 DT1 RN2 DT2 MINS_DIFF
---------- ------------------- ---------- ------------------- ----------
1 20/10/2010 08:10:08 7 20/10/2010 09:10:55 61
2 20/10/2010 08:10:08 8 20/10/2010 09:10:58 61
3 20/10/2010 08:10:08 9 20/10/2010 09:10:58 61
4 20/10/2010 08:10:08 10 20/10/2010 09:10:58 61
5 20/10/2010 08:10:08 11 20/10/2010 09:10:58 61
6 20/10/2010 08:10:08 12 20/10/2010 10:10:38 121
13 20/10/2010 11:10:34 15 20/10/2010 11:10:35 0
14 20/10/2010 11:10:34 16 20/10/2010 12:10:08 60
17 20/10/2010 14:10:03 18 20/10/2010 14:10:44 1
9 rows selected.
SQL>
Tags: Database
Similar Questions
-
Difference of timestamp in the same column
Question for Oracle guru. I have a DB (Oracle) table as below
ID STATUS TIMESTAMP-- ------ ---------1 NEW 30-JAN-15 08.11.11.803384000 PM
2 NEW 30-JAN-15 08.11.13.606681000 PM
1 COMPLETED 30-JAN-15 08.11.15.997794000 PM
2 COMPLETED 30-JAN-15 08.11.16.469299000 PM
I want to do 2 things
1. Query for Timestamp difference for each id from status new to complete2. Query for Avg time between new to complete for all id's between new to completeCan you help me with a better way to do this
create table ts_test( id number, status varchar2(20), ts timestamp(9) ) ; insert into ts_test values (1, 'NEW', localtimestamp); insert into ts_test values (1, 'COMPLETED', localtimestamp); insert into ts_test values (2, 'NEW', localtimestamp); insert into ts_test values (2, 'COMPLETED', localtimestamp); insert into ts_test values (3, 'NEW', localtimestamp); insert into ts_test values (3, 'COMPLETED', localtimestamp); with elapsed_intervals as ( select id, status, ts, ts - lag(ts) over (partition by id order by ts) id_elapsep_interval from ts_test ) select id, status, ts, id_elapsep_interval, round(avg((sysdate + id_elapsep_interval * 24 * 60 * 60 - sysdate)) over (order by null), 1) avg_elapsed_interval from elapsed_intervals order by id ; 1 rows inserted. 1 rows inserted. 1 rows inserted. 1 rows inserted. 1 rows inserted. 1 rows inserted. ID STATUS TS ID_ELAPSEP_INTERVAL AVG_ELAPSED_INTERVAL ---------- -------------------- ----------------------------- ------------------- -------------------- 1 NEW 03.02.2015 00:28:09,873000000 2,8 1 COMPLETED 03.02.2015 00:28:12,897000000 0 0:0:3.024 2,8 2 NEW 03.02.2015 00:28:16,472000000 2,8 2 COMPLETED 03.02.2015 00:28:19,623000000 0 0:0:3.151 2,8 3 NEW 03.02.2015 00:28:22,156000000 2,8 3 COMPLETED 03.02.2015 00:28:24,442000000 0 0:0:2.286 2,8 6 rows selected -
How to select data using the same remote database column name 3
Hello
Can anyone help me on how to get the data with the same remote database column names 3 and a unique nickname.
E.g.
SELECT *.
B.SID, b.status, SUM (b.qty) qantity MAX (b.) date_as_of
Of
* ((table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) has, *)
(* (table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) b). *
WHERE b.dept = 'finance '.
AND a.position = "admin".
AND a.latest = 'Y' AND (b.status <>"MLT") AND b.qty > 0;
B.SID GROUP, b.status;
NOTE: the instructions "BOLD" is just an example of what I want to do but I always get an error beacause of ambiguous column.
Thanks to advnce. :)
Published by: user12994685 on 4 January 2011 21:42user12994685 wrote:
Can anyone help me on how to get the data with the same remote database column names 3 and a unique nickname.
Not valid. This makes no sense and breaks all the rules of scope-resolution. And if it is in a single database, or uses tables in databases, is not relevant.
Each object must be particularly well identified. If you cannot do this:
select * from (table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) a3 objects cannot share the same alias. Example:
SQL> select * from (dual, dual) d; select * from (dual, dual) d * ERROR at line 1: ORA-00907: missing right parenthesisYou need to combine objects - by using a join union or similar. He will have to be done as follows:
SQL> select * from (select * from dual d1, dual d2) d; select * from (select * from dual d1, dual d2) d * ERROR at line 1: ORA-00918: column ambiguously definedHowever, we need to have unique column in a projection of SQL names - so the join of the need to project a unique set of columns. So:
SQL> select * from (select d1.dummy as dummy1, d2.dummy as dummy2 from dual d1, dual d2) d; DUM DUM --- --- X X SQL>I suggest that you look carefully at what opportunities are and how it applies in SQL - and ignore if the referenced objects are local or remote, because it has no effect on the basic principles of scope-resolution.
-
Entries are concatenated in the same column in the excel file
Hi, I really need help in this emergency. The problem is when I open the spreadsheet file after you run the program below, all the values that I believe are concatenated in the same column. However, there are 2 different analog inputs which I want in 2 different columns. I'm getting the 2 waveforms in the same graph, but when I open the excel file, it seems that the entries are concatenated in the same column. Someone knows how to fix this? Thank you very much.
Hi Ben 64,.
Thanks a lot again. I did as you said and I removed the dynamic data and logged files added directly to the results. I'm still checking if the program works as I can branch only when I return to work tomorrow. Tell me if you think it might be able to work this time. Thanks a lot again!
-
We all hope you are doing well.
I have a business problem to implement in ODI 11 G. It's here. I'm trying to load a target table from two sources that have the same column names. But a source is to the file format and the other is in the Oracle database.
That's what I think I'll create two mappings in the same interface by using the Union between the sources. But I don't know how the interface would connect to different logical architecture to connect to two different sources.
Thank you
SM
You are on the right track, all in a single interface. Follow these steps
(1) pull model of your data in the designer of the source file and your table model target to the target pane.
(2) all relevant columns map
(3) in the source designer to create a new dataset and choose as the UNION join type (this will create a separate tab in the source designer pane)
(4) select the new dataset tab in the source designer pane and pull your source oracle table data model in the designer of the source. All columns that are relevant to the target card
(5) make sure that your staging location is set to a relational technology i.e. in this case the target would be an ideal candidate because it is where the ODI will organize the data from source two files and oracle and perform the UNION before loading to the target
If you want to watch some pretty screenshots showing the steps above, take a look at http://odiexperts.com/11g-oracle-data-integrator-part-611g-union-minus-intersect/
-
By comparing the values in the same column
Hello
I have a requirement to do the following:
The guest of the dashboard has two drop downs as 'Acct number 1' and others as 'Acct number 2 ". Both are the same column from the database. When two different values are chosen from the prompt, it should produce a report with the following 5 colomns, 'ACCT1', 'SALES AMOUNT ACCT1', "ACCT2", "SALES AMOUNT ACCT2", "DIFFERENCE".
I tried to use a variable of presentation in the command prompt and it fills my column pther having the same value I have input for the first prompt.
How can I do this? Thanks for your time and your help.Hello
You can try it at the level of the report.
* Ensure that you have set your guests with different effects. Suppose that the two PVs are acc1 and acc2.
* Report, add below filter
Account number is equal to @{acc1} {defualtvalue}
OR
Account number is equal to @{acc2} {defualtvalue}
This will filter the report by the two account numbers.
* Now apply below in your fx of all columns."ACCT1: ' @{acc1} {defualtvalue}"
ACCT1 SALES AMOUNT: FILTER (with the HELP of SalesCol (AccountNumber = ' @{acc1} {defualtvalue}'))
"ACCT2: ' @{acc2} {defualtvalue}"
ACCT2 SALES AMOUNT: FILTER (with the HELP of SalesCol (AccountNumber = ' @{acc2} {defualtvalue}'))
DIFFERENCE: FILTER (with the HELP of SalesCol (AccountNumber = ' @{acc1} {defualtvalue}'))-FILTER (with the HELP of SalesCol (AccountNumber = ' @{acc2} {defualtvalue}'))Thank you
-
By subtracting the values in the same column?
Hello
How can I subtract two values in the column of the table. EG - there is a table with two columns with date and cumulative turnover.
Date Total_sales
===== =======
February 23, 68
24 feb-122
25 feb-150
26-Feb-200
27 feb-223
I need to know about the date that sales have been maximum. As we can see on 24 - Feb, sales were 54. We do this by subtracting 122-68.
How can subtract us values in the same column?
Thank youTake a look at the lag() of analytic SQL function which should give you what you need.
See you soon,.
Harry -
an alphabet by typing in a cell gives drop down suggestions from previous hits on the same column. But how the drop down to choose the suggestions of the other columns and other sheets.
Hi mdsavol,
Your observations are accurate. The 'suggestions' are previous entries in the same column that correspond to what has been entered so far in the active cell. The only direct user control is to activate the function turn on or off in numbers preferences > general.
There are other ways to include or exclude items of suggestions:
- To remove typos in the suggestions list, the user must correct the typos in the cell above the active cell. If they are more in the list, they won't be presented as suggestions.
- To include selections added to the list, the user must enter these suggestions in the individual cells above the active cell and column where they are wanted as suggestions.
There was a request here a while there is a list of suggestion 'live' similar to those of some websites, which offers a descending list of possible entries as a type in an input box.
The only way I see to reach a solution similar to what you have asked is to use as many lines at the top of the non-en-tete of the table section to list the items likely to repeat in your table, and then hide the lines. You'll need a list for each column where you want to use this feature with a list previously planted. Existing items will then require a likely hit up to three, then a click to choose from a list small enough to enter a value into a cell. News he will need to enter in full the first time, but after that it will be put on the list and answer the same thing as the terms preseeded.
While your setting upward (or decide not to do), consider going on the menu of number (in numbers), choosing to provide feedback from numbers and writing a feature in Apple request. Describe what you want. Explain how he could help the average user numbers, and then hope for the best.
Kind regards
Barry
-
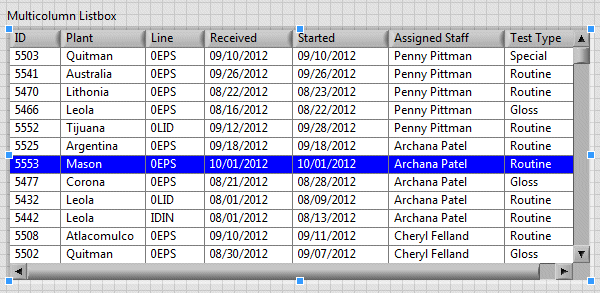
Read the data in the first column selected in a multicolumn listbox
When a line is selected in a ListBox multicolumn (1 point), how can I go on reading the data in the first column?
The listbox multicolumn itself is the digital picture data type. If you have allowed only 1 point selection and selection mode select any row, it returns the line number. The property node 'Element names' to return a table 2d-chains of the elements in your Inbox. The index of the row to the value of the listbox and column 0. See code attached.
-
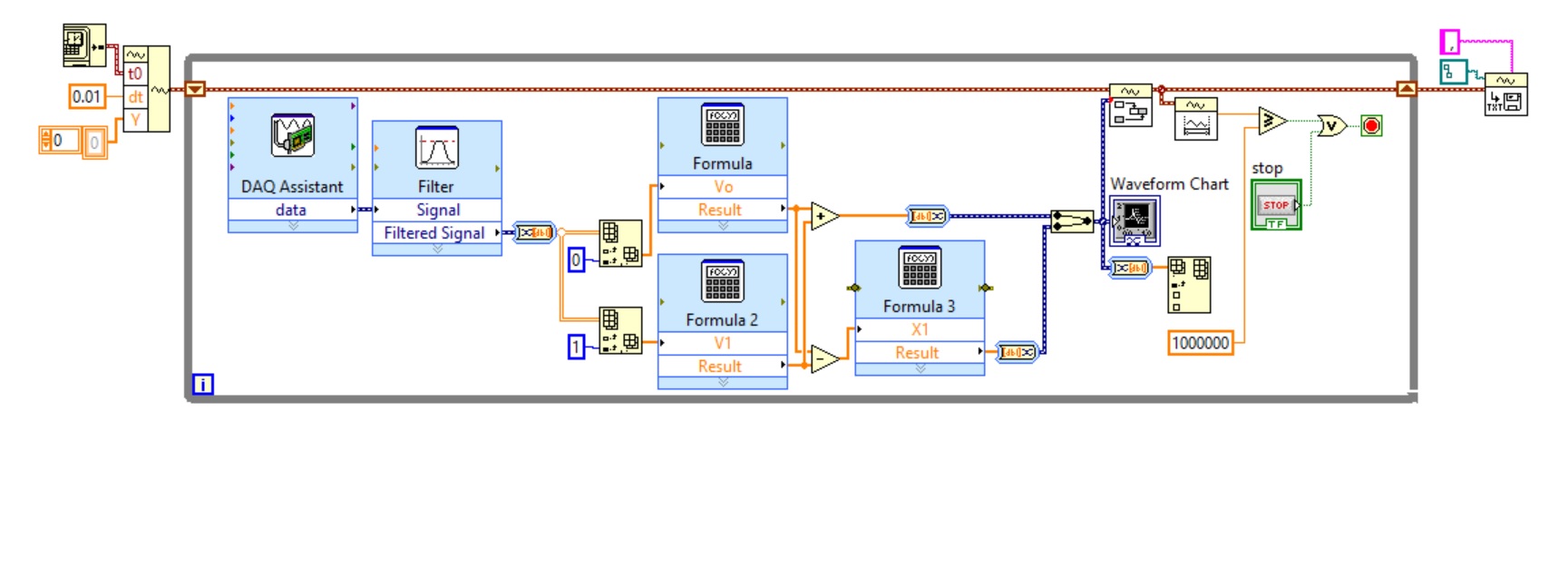
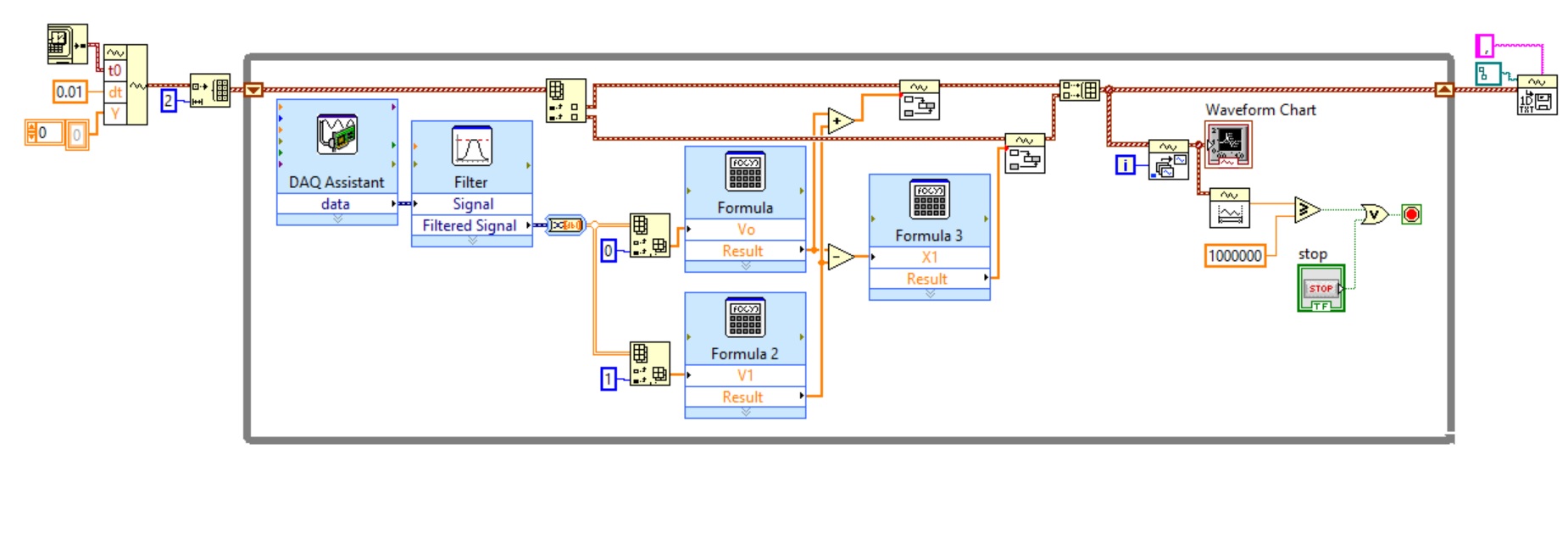
Use two assistants for the acquisition of data at the same time
Hello
I want to read multiple data channels of analog inputs on my DAQ hardware. However, when I try to create two separate data acquisition assistants for each entry, it gives an error saying "is reserved for the specified resource. The operation could not be performed as indicated "." Can't use two assistants for the acquisition of data at the same time?
I have to add different channels in the same assistant DAQ? I tried, but I couldn't separate the data in different graphs.
How does this work?
Kind regards
Allard
You can't have multiple tasks of the same type (in this case inputs analog) on the same device. Just so having 1 DAQ Assistant read all your channels and separate your channels for individual transformation.
-
Lack of voice and data at the same time kills me
After using a treo 750 (WM 6.1) on att for the past three years, I guess I did not realize the advantage of ATT and gsm in general. There are many drawbacks... mainly pricing for simple accounts (However their family plan was directly comparable to those of sprint). I constantly try to use data applications while talking on the phone without success. I started thinking that I could do without, but a week later, I still really really miss. My wife did too... because she's I usually give directions or any other web information while on the phone. There is nothing like view google satellite map to help someone make sure they are in the right place... "see a big tree on your right with a large Brown building behind it, Yes, it's that one" does anyone else have this feeling? WiFi is not an option for me most of the time.
Voice and data at the same time is not available when using any CDMA network due to network constraints. This is true for all types of phones, not only Palm or not only the Pre. Your example of electronic control or by using google maps, the gps data that can be stored before you activate the call. try to browse the web while making a call and try to go to a web page, you have never visited before, so that you know, that he cannot be a version collected page.
-
Multiple constraints on the same column
Hello experts, we can use Multiple forced on the same column in oracle as creating table, I want to add a key single and forced to check on the same column is this possible? Thanks in advance,
If you want, seems to be possible
CREATE TABLE t1
(col1 VARCHAR2 (50))
CONSTRAINT ck1 CHECK (col1 IN ('A', 'B', 'C'))
CONSTRAINT PRIMARY KEY (col1) pk1
);
-
several stores data on the same disks
It's so strange. I can't create several stores data on the same drive. I have a 2 TB plugged on my server (motherboard) disk and after that I created my first store of data (100 GB), when I return to create another, that the drive isn't an option for me to create a new data store of. When I delete the data store, the drive comes as an option to create a new data store of. WTF?
A logic unit number must contain only a single VMFS data store.
I guess the reason for this is a SCSI reservation. Even if this has been significantly reduced in 4.x it is still necessary for some operations. Each SCSI reservation - even if this is necessary for an operation on a datastore - locks the entire disk and could therefore cause problems on other stores of data on the same drive.
André
-
R12: Copy a group of companies with configurations, metadata and data in the same instance of OA
The idea was born to a very common condition between the companies IT. pre-sales and pro-ventes groups do various tasks, including the response of the RPF/RFI, PoC, building, Solution architecture, customer demo etc. Ususally they do not have the dedicated application instances, or rather they do not find a sufficient number of cases of applications dedicated to deep study of the road. Every other day a group cries out for an Apps instance and the same gets lift for senior management in short time. It gives a lot of pain to the infrastructure/DBA groups because they fail to meet people like them, due to the limited availability of free nodes, resources, networks and space etc.
I have a Vision of the R12.1.3 (tell SID = VIS1213) installed on a Linux machine. The box is quite busy with his hearts limited, showing little free memory and the attached SAN has insufficient free space remaining. A group of Oracle Apps pre-sales consultants, says "Group 1", is the use of this.»
Now the 3 other groups are asking for a R12.1.3 Vision instance separately for different reasons below. Each of them wants the instance again and do not share with others.
Group 2 for deep study of the road against a critical response to RFP
Group-3 for the development of a point of contact for a customer demo
Group 4 for the manufacture of PUK media on some business processes
In this scenario, I should install 3 distinct Vision of R12.1.3 (using CDs or downloaded zip) or clone VIS1213 in 3 different places with different SIDS, possibly on one or more separated nodes (as above Linux node has insufficient free resources). In this case, the need for available server resources and disk space multiplied by 3, so that DBA maintenance for these 3 new instances is added.
Hope that I have clear air up to this point.
Then I was thinking if we have "virtual instances" within an existing instance of Apps, by copying from a vertain org level. First I thought I'd take THE level, but it will not work if an instance of group to work with HRMS claims. We must therefore take business group level. After that we will create the appropriate role and responsibility, user profile options so that the new user can see and work on the new BG and data area down only. It will be like a separate instance to use.
Benefits of my desired task will be
-no separate server resource, the required network
-no additional DBA not involved maintenance
-no separate required backup plan
So here it is to create 3 new "virtual instances" right within the same instance of VIS1213. New groups will have same URL, same existing TNS details but 3 credentials different existing access. Each of them would be limited in a way so that they can not see each and other data and can not hurt each and other changes.
This can be achieved if we can copy an existing group of its activities with org structures, metadata and data, within the same instance. Oralce planning cannot be copied within the same instance configurations.
What I've done so far was I manually created a new BG, attached an existing sobbing (CoA, Agenda / currency), created a new, copied and modified accounting structure flexfields before fixing, created the new ORGANIZATIONAL unit, and then a new InvOrg of master and a new InvOrg clild, defined the profile MO some GL and HR profiles. Then I extracted finished master and data assignment article category Masters against a master/child existing InvOrg, updated the data for newly created InvOrgs, inserted into tables insterface and ran seeded import conc program element. Except for a few, all data have been loaded into base against new InvOrgs tables.
Then I tried with master provider (with sites and contacts). A few AP configurations are required, and then data provider (+ contact + site) have been loaded against OR newly created (under new BG) base tables.
I do not proceed after that. I'm currently looking for ideas from the experts on how to go further.
Planning is able to create this kind of 'virtual instance' within the same instance of OSTEOARTHRITIS?
PL nowadays return.
Thank you and best regards,
Castelbajac Dhara
E-mail: [email protected]PL don't post duplicate topics - R12: copy a group of companies with org, configurations, metadata & data structures
-
Multiple values for the same column in the columns of diffétent in the same row?
Hi all
I wonder how you can display different values for the same column in different columns on the same line. For example, using a CASE statement, I can:
CASE WHEN CODE IN ('1 ', ' 3') THEN COUNT (ID) AS 'Y '.
CASE WHEN CODE NOT IN ('1 ', am') THEN COUNT (ID) AS "N".
Yes, that will produce two columns but will produce null values to empty and also two separate registers.
Any ideas?
Thank youAre you sure that this code works for you?
Select ID ,CASE WHEN MODE_CODE IN ('1', '3') THEN COUNT( No) END as "Fulltime" ,CASE WHEN MODE_CODE NOT IN ('1', '3') THEN COUNT( No ) END as "Other" From table group by IDI guess the code above fails because MODE_CODE is not in your group by?
My suggestion would be to put the CASE in the COUNT:
Select ID ,COUNT(CASE WHEN MODE_CODE IN ('1', '3') THEN No END) as "Fulltime" ,COUNT(CASE WHEN MODE_CODE NOT IN ('1', '3') THEN No END) as "Other" From table group by IDCASE expressions return no. when the respective conditions are true and NULL otherwise.
COUNTY will have non-null values.
Maybe you are looking for
-
iPhone 6 photos deleted. memory not released
I used Windows Explorer to delete the photos on my iPhone6. He is there not pictures here when you look in windows Explorer or on the phone itself. However, it is not that the memory has been released. Windows Explorer shows: internal storage > > D
-
I think an add-on did funny things
Last week, I noticed changes in the browser. For example, if I typed in "ESPN" in the URL address field, Firefox would automatically fill address based on my background. In other words, if I typed, "banko", Firefox would flood, "routard.com." In addi
-
64 bit Windows7/8/8.1/10 USB drivers for Palm Desktop
Thank you people much more to Aceeca.com (Palm OS Garnet NEW manufacturers), the USB drivers for Vista, Windows 7 and 8 Win 64 bit operating systems are available. There are many users Palm Desktop 4.x strives also to the declaration.I have synced m
-
FN keys not working not not on Tecra M3
All, I have a laptop of M3 and I can't get the FN keys to work properly. I can get the slider control and mode numlock LEDs lights up but none of the other features, i.e. the volume, brightness, cd ejection tray, etc. compatible screen. I googled hig
-
Replacement of disk for HP G61 - 420CA / Memmory
Series: [edited by mod on 11-08-14] PRODUCT: WA968UA #ABC MODEL: GG1 - 428 CA Hi, I have a HP G62 - 420CA currently with a seagate 320 GB (SATA) without HARD drive and I was wondering if this drive is compatible with this system. WD Blue 750 GB 2.5 "