FFT and differ from the values overall btwn VI and tiara
Hi all
I have an application that displays live readings of vibrations which the spectrum and the overall vibration level. Everything my generation of report is made in the DIAdem scripts, so it is essential that all values calculated and displayed on the side of LabVIEW are the values calculated and reported in DIAdem. The VI and Script, when the entrance to the PDM attachment, attached give me values significantly different to the size of the FFT and the overall value of RMS. Can anyone spot what I'm doing wrong?
Thank you
Scott
Hello
This is an excellent response of R & D. I felt that it would be better to put it on the web, then keep it limited to your service request.
The difference has to do with the window of correction. The results are the same if you choose rectangluar (or not) window.
Usually a window takes a share of the singnal away, so in the first place, the result has a different shape and is smaller compared to train with rectangular window. This can be fixed with a specific factor for each window.
There are two possible corrections. Random and periodic.
-Periodic is used if you have pure sinusoidal signals and you want to measure the peak value. A typical use case is the window of flattop is designed for this type of calculations. The periodic correction is too great if you want to add values to calculate the total RMS signal or the sum of a certain frequency band.
-Random is correct the signal back to the correct overall RMS value and must be used in all other cases.
The periodic correction for Hanning window is a factor of two. The correction is randomly about 1.633. Tiara will give the same result as LabVIEW if you use the following type of correction:
FFTWndCorrectTyp = "periodic".
In the world of the FFT analysis, the different corrections are very often not obvious and hidden to the user. Unfortunately, it is also the case in LabVIEW. You can find a good example of explanation here:
http://blog.Prosig.com/2009/09/01/amplitude-and-energy-correction-a-brief-summary/
There are different factors for different window functions. If you go further in the FFT - VI you will find "window scaling VI. It has a «constant window» output With this, it is possible to obtain the correction values for window functions.
I think also, periodical is false in most cases, when Hanning is used, because Hanning is the best for the sum of the values of the RMS in the frequency bands and the results are bad without a correction at random.
Hope that helps.
Tags: NI Software
Similar Questions
-
What is the difference between staging differ from the target
Hello
My question is what is the diffrence between staging differ from the target and staging of the same target area.
To say:
I'm loading the data from the file to the database table. Usually what happens is it will create temporary tables C$, I$, $ E. C$ table removes the information in the previous table and
Create a new table, and then load the data staging I and then E$ for the error checking. So the question is if I select the option staged are same as target in this
case if load us the data from the target moves or otherwise, to where the data is intended.
Help me in this...
THX,If you set a different transit area of target, and if the scheme of work is on one physical server other than your target schema, you will have more stages.
I recommend your to create your interface twice and compare the generated steps by exploiting.
In the first case (staging = target), the interface will do:
* create and load C$ table in the schema of work related to your target schema
* create and I charge $ table in the schema of work related to your target schema
* load data since I have$ for the target tableIn the second case (different staging of target, and if the scheme of work is located on another server), you will have more steps ("export them")
* create and load C$ table in the schema of work related to your "staging schema" you chose
* create an ANOTHER C$ target table in the schema of work related to your schema. load of the first table of C$
* create and I charge $ table in the schema of work related to your target schema
* load data since I have$ for the target tableIn some cases, you must use "another area gathering that target." For example, your target is a flat file. (you cannot use the staging area of the technology of files, so you will choose a database schema)
-
Highlight cell when the value is different from the value of the cell in the next row.
I have a requirement for a table (af:table, not a DB table), in cases where a cell value differs from the value in the row slot, the cell must be highlighted to indicate.
the entire line can not be highlighted, only the cells with differences. For example, if the table contains data:
The cell containing the value 'Widget' in the first row must be highlighted, other cells get no highlighting.90111 $1000 Widget 90111 $1000 Cart
The data comes from a DB, through VO table based on an OA.
Is it possible to do this in the ADF (11g)?
Thank you-
-georgeThere is no declarative way to do what the rows of the table are marked. This means that there is no way to access a value as a (+ 1) .attributename
Here's a few codes. Check http://lucbors.blogspot.de/2012/02/adf-11g-fancy-master-detail-or-how-to.html and http://lucbors.blogspot.de/2012/02/adf-11g-even-fancier-multi-master-multi.html that might help you to implement your case.Timo
-
OIF - what is only the diff. from the point of view of the users of the IDP/SP initiated SSO
I use OIF Federated single on sign. I got the two SP and IIP launched SSO works. When I provide both URL to the client, how can I suggest one to use? from the perspective of the end user, both of them works in the similar workflow: type (click) URL-> redirect to the login page of IDP-> connection-> back to demand. only diff. seems the URL. most of the users did not even notice the diffrence between 2 URLs.
Is that what some might give some suggestion when and what's the favorite.
Thank youTry this http://www.yourhtmlsource.com/sitemanagement/urlrewriting.html and then apply it to your own infrastructure
-
Fill a field from the value on another page
Hi all
I do not have a form, I'm, and I all the other scripts I have written about this work except one. There is a field of calculation based on its value, it checks the box on a page depending on the range. This calculated is read-only. I wrote the following code and put on the output event, but it does not work. Please can someone help me with why it isn't workiong.
if ((form1. Page5.raterec1.RawValue> =1)& &(form1. Page5.raterec1.RawValue<2)) { }
rrun1.rawValue==1;
}
if ((form1. Page5.raterec1.RawValue> =2)& &(form1. Page5.raterec1.RawValue<5)) { }
rrsuccess1.rawValue==1;
}
if ((form1. Page5.raterec1.RawValue> =5)& &(form1. Page5.raterec1.RawValue< =6)) { }
rrout1.rawValue==1;
}
Thank you
v/r
LucPian
Hello
I think that we are approaching:
The user selects dropdown > This sets the value of raterec > script in the menu drop-down looks at the value of raterec and then sets the values for the checkboxes.
I think what is happening is that the script sets the value of the correct raterec. BUT continues with the script of box BEFORE rawValue of raterec is set to the new value.
So I share the script.
Have the script in the box calculate event resembling the rawValue of raterec (see previous post). The rawValue of raterec changes, the script in the boxes is automatically activated.
Then the script from the drop-down list changes just the rawValue of raterec.
Box script looks like to > raterec.rawValue
^
^
list dropdown script games ^
(diagram of garbage)
Niall
-
create DDL from the values of TEXT on the page
I have a form with two selection lists. The first select list (P3_OWNER_GROUP) works very well and has the onChange application to extract the other two columns associated with the selected list item and store these values in two fields of hidden text. (P3_L_TABLE and P3_L_TAB_COLUMN) through process on REQUEST. These two columns of hidden text values must be used to drive the second selection list (P3_SERVER_HOST), because they contain the full qualified table name and column name to select LOV. Here is the list of the values object code.
DECLARE
l_string VARCHAR2 (1000);
BEGIN
IF: P3_OWNER_GROUP IS NOT NULL THEN
BEGIN
l_string: = "select distinct" | : P3_L_TAB_COLUMN | ' d, ' || : P3_L_TAB_COLUMN | ' r of | : P3_L_TABLE | "order by 1';
EXECUTE IMMEDIATE l_string;
END;
END IF;
END;
Error: ORA-06550: line 1, column 13: PLS-00103: encountered the symbol 'COLLECT' at the expected in the following way: =. ( @ % ; ORA-06550: line 1, column 82: PLS-00103: encountered the symbol ";" when expecting one of the following values: (, % to execute the query list of values: ' ".)
Any help is greatly appreciated.The selection list call it P3_OWNER_GROUP or P3_OWNING_GROUP? If you are referring to a nonexistent element, it will always be null.
Anyway, there is no real need for anon - block the nested, and the condition should focus specifically on the elements of the page that you are wanting to use in the query. I think it should be:
DECLARE l_string VARCHAR2(1000); BEGIN IF :P3_L_TAB_COLUMN IS NOT NULL AND :P3_L_TABLE IS NOT NULL THEN l_string := 'select distinct ' || :P3_L_TAB_COLUMN || ' d, ' || :P3_L_TAB_COLUMN || ' r from ' || :P3_L_TABLE || ' order by 1'; ELSE l_string := 'select ''- Select -'' d, null r from dual'; END IF; RETURN l_string; END;John
-
How to change the values of a from the values selected in another LOV LOV
Hello
I have a requirement in the ADF where there are two LOVs. The values in the second LOV based on the values that I selected in the 1st LOV should change dynamically.
In addition, the 1st LOV accepts 3 values for each value that I select, a different query is executed to fill the 2nd LOV.
I have a gross thought I can use 3 different read only view objects containing these 3 queries. And according to the value that I select in the 1st LOV I can run the object matching the view of the bean to support. But my doubt is how to link the results of this query that is executed to fill the 2nd LOV.
Thanks in advance.
Published by: 886591 on September 21, 2011 04:48Kouadio,
All your queries based on the table? If Yes, you can use a variable binding for the lov attribute relative to the query to run on the LOV child.
If they are based on different tables, you can create 3 different lovs for the child attribute and select what lov seem based on the parent attribute.
Here are a few examples.
http://andrejusb.blogspot.com/2011/03/ADF-BC-dependent-lov-11g-ps2ps3-bug-and.html
http://andrejusb.blogspot.com/2008/12/Groovy-multiple-lovs-per-attribute-in.html
Arun-
-
How can I parallel 2 2 queries differ from the DB?
The situation: I have a function, where I create 2 queries dynamically. Queries refer to two different bases, which are bound by dblink. And then I just union by the "UNION ALL" clause. After that I have exec that together interrogate them. Then I assign the results to a sys_refcursor. And the function returns a cursor to my external application.
Question: can I run the execution of these two queries in parallel mode and how? I think that the execs 'UNION ALL clause "the first part of the first and the second union. Any help appreciated.
I use Ora 10 g is said by the way.
Published by: 806206 on 29.10.2010 01:36806206 wrote:
The situation: I have a function, where I create 2 queries dynamically. Queries refer to two different bases, which are bound by dblink. And then I just union by the "UNION ALL" clause. After that I have exec that together interrogate them. Then I assign the results to a sys_refcursor. And the function returns a cursor to my external application.A cursor is not a result set. A cursor lies in the shared SQL pool and consists of submitted SQL source code and this code in the format "analyzed and compile ' (aka an execution plan). A slider is like a program. A cursor with bind variable is as a program with input parameters.
The cursor or the program is executed. It copies data to the appellant when the appellant says the cursor fetch/get the next series line out.
There is no result set created and stored somewhere in the memory of the (limited) server. Take a look at the view of Oracle® Database Reference (as V$ SQLAREA) on the sliders and container.
Question: can I run the execution of these two queries in parallel mode and how? I think that the execs 'UNION ALL clause "the first part of the first and the second union. Any help appreciated.
From where? PL/SQL? Or a Java client?
You will need to evaluate this approach to parallelising of treatment. It can only increase the complexity and provide little benefit performance.
The basic concept is that the thread principal (or process) will be the consumer of the data - and that children threads will read data from the remote databases and write to the data stream that the mother consumes.
In PL/SQL, this can be done using queues in advance - where 'children' (started as background work processes for example) spooling the data they retrieve from the remote cursors and the parent removes and processes these data.
-
Deriving from the value of the column totals
BI Publisher 11g:
I have the next report, that I generated:
BOX TYPE NUMBER OF BOXES COST COST PER BOX A 10 $100 $10 B 20 $140 $7 TOTAL 30 $240 $17 My problem is that in the TOTAL row in the column COST PER BOX, the value shouldn't be that is to say $17 ($10 + $7) it should be actually IE $8 ($240 / $30). Does anyone know how to calculate the correct value.
Assuming that this structure of xml data:
A 10 100 B 20 140 You can use the following code to get the values:
row1:
row2:
Thank you
Bipuser
-
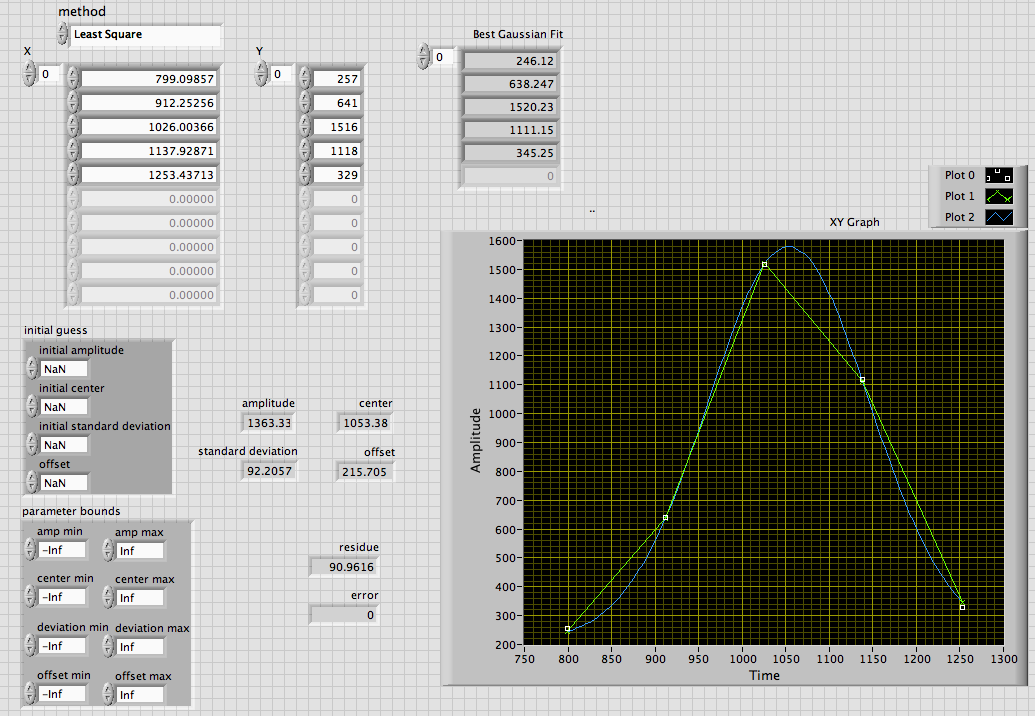
Fit Gaussian Peak and non-linear curve Fit on small data differ from the PEAK of origin made
Hi all
I'm developing a program in which I have to adjust the curve of Gauss on only 4 or 5 data points. When I use the Gaussian Ridge Fit or adjustment of the curve non-linear, it connects linearly all the points so that other editing software like origin's curve fitting of Gauss on the same set of data that I have attached two images is LabVIEW with Fit Gaussian of Peak and nonlinear adjustment and other is original.
The data are
X Y
799.09857 257
912.25256 6411026.00366 1516
1137.92871 1118
1253.43713 329Interesting.
The initial default values assume all are NaN, which causes the LV calculate conjecture. The default values for the parameter Bounds +/-Inf with the exception of the offset that are both zero. This, of course, forces the output zero offset. It seems a strange fault, but they may have a good reason for it.
Change the limits of compensation to something else translates the output being offset ~ 215 and the Center moves to ~ 1053. These correspond the original result to 5 significant digits.
Lynn
-
I have been using Outlook Express 6 for more than 20 years without a single problem so far. Value of a full year of emails has disappeared all of a sudden my box but all e-mail messages seem to be always in place of my sent folder.
How can I recover these e-mails Inbox?
Two reasons the most common for what you describe is disruption of the compacting process, (never touch anything until it's finished), or bloated folders. More about that below.Why OE insists on compacting folders when I close it? :
http://www.insideoe.com/FAQs/why.htm#compact
Why mail disappears:
http://www.insideoe.com/problems/bugs.htm#mailgoneRecovery methods:If you are running XP/SP3, then you should have a backup of your dbx files in the Recycle Bin (or possibly the message store), copied as bak files.To restore a folder bak on the message store folder, first find the location of the message store.Tools | Options | Maintenance | Store folder will reveal the location of your Outlook Express files. Note the location and navigate on it in Explorer Windows or, copy and paste in start | Run.In Windows XP, the .dbx files are by default marked as hidden. To view these files in the Solution Explorer, you must enable Show hidden files and folders under start | Control Panel | Folder options | View.Close OE and in Windows Explorer, click on the dbx to the file missing or empty file, then drag it to the desktop. It can be deleted later once you have successfully restored the bak file. Minimize the message store.Open OE and, if the folder is missing, create a folder with the * exact * same name as the bak file you want to restore but without the .bak. For example: If the file is Saved.bak, the new folder should be named saved. Open the new folder, and then close OE. If the folder is there, but just empty, continue to the next step.First of all, check if there is a bak file already in the message. If there is, and you have removed the dbx file, go ahead and rename it in dbx.If it is not already in the message, open the trash and do a right-click on the file bak for the folder in question and click on restore. Open the message store up and replace the .bak by .dbx file extension. Close the message store and open OE. Messages must be in the folder.If messages are restored successfully, you can go ahead and delete the old dbx file that you moved to the desktop.
If you have not then bak copies of your dbx files in the Recycle Bin:DBXpress run in extract disc Mode is the best chance to recover messages:
http://www.oehelp.com/DBXpress/default.aspxAnd see:
http://www.oehelp.com/OETips.aspx#4A general warning to help avoid this in the future:Do not archive mail in default OE folders. They finally are damaged. Create your own folders defined by the user for mail storage and move your mail to them. Empty the deleted items folder regularly. Keep user created folders under 300 MB, and also empty as is possible to default folders.Disable analysis in your e-mail anti-virus program. It is a redundant layer of protection that devours the CPUs, slows down sending and receiving and causes a multitude of problems such as time-outs, account setting changes and has even been responsible for the loss of messages. Your up-to-date A / V program will continue to protect you sufficiently. For more information, see:
http://www.oehelp.com/OETips.aspx#3And backup often.Outlook Express Quick Backup (OEQB Freeware)
http://www.oehelp.com/OEBackup/default.aspx -
Stored value put in service different from the value showing in Win Ops. sys.
Dear Experts,
I need to understand this case, I'm looking for your answer for the same thing,
I have a virtual machine that have 20GB for HDD set, thin provisioned. Now when I look in windows 2003 OS it shows me consumed space only 15 GB and 5 GB is free. It's OK, the c:\ drive have some data.
But when I look in vSphere client it shows me provided as 22GB storage which is (file hard 17 GB + 2 GB memory vswp file)
The storage used is 19.03 GB, 100 GB data store are free. Now my questions should be concerned about this "storage used 19.03 GB' status?" It shows me that my defined slim 20 GB HDD is about to finish? OR I'm worried about what is available to me in the Windows operating system?
Please guide me if I really need to increase the size of HARD drive defined for this virtual machine because this storage used 19.03 that makes me think. I need to understand this case because this you will also help me to monitor how other virtual machines must be considered with the drives of the virtual machines and what appropriate action when
Waiting for response.
Kind regards
What I understand your answer, I'm sure at this point that 5 GB is free available when searching for the Windows operating system. So this means VM will continue to work and I will not face problem while 5 GB is available. right?
Correct - Windows has 5 GB to work with, and all is well.
so maybe after some time, this value becomes 20 or 23 something like, even if the defined end disk is only 20 GB? OR it will go up 20 GB over time to what is defined?
The size of a thin VMDK will never exceed the size put into service. So, if you have created a thin VMDK of 20 GB, the larger than individual VMDK never 'flexible' is 20 GB. If Windows runs out of space, you will then need to manually increase the size of the VMDK.
-
How to set the default value of a column from the value of the 2 columns given
Is it possible to set the default value for a column A, as the concatenated values of columns B and C of the create table statement itself without using the trigger.
for example, in a line, if column B is 'James' and column C is "smith" then the column has must be "james Smith".
in another line if column B is 'Bob' and column C is "Taylor" then column should be "Bob Taylor"
Thank you
YGYes, it is possible. But what is your version of the database? Try to use "virtual column. Search for a virtual column in the following link.
http://www.Oracle.com/technology/pub/articles/Oracle-database-11g-top-features/11g-schemamanagement.html
http://download.Oracle.com/docs/CD/B28359_01/server.111/b28286/statements_7002.htm -
RoboHelp 11 search results differ from the merger of projects
Hello
Please bear with me as I am a new user to Robohelp, I have looked around and have been unable to find an existing thread on the subject I see.
I have a project (lets call this project A) in 2 forms.
(1) all first as a stand-alone project (project A).
In this format the search feature seems to work correctly, outside to drop the 'e' in search of the only word ending with 'e' (I found a small amount of information on it, but not a solution).
(2) the second form is that of a merged project (project B). Its configured in the form:
Project B TOC:
Introduction
Book
Project A (merged)
In this second format if I search for a term with an 'e' suffix the number of results is lower.
I managed to establish the difference between the 2 research.
Example:
Search on the word: "merge".
(1) 8 results
(2) 5 results
5 results that return in the two are where the substring "Merg" (the 'e' lack) is part of a word in these topics, 3 lost results are those who have "Merge" as a stand-alone Word.
Scenario 2 seems to be looking for 'Merg %' and excluding "merge".
If anyone can suggest a solution, or if you need further explanation, please let me know.
Thank you
David
The presentation of single Source has an option to allow the search of substrings, which seems to match your option (1). Do you use SSL even to create the output? What is the setting for the substring search in project the master and child?
You can find the option in the search of the WebHelp SSL settings tab.
-
How can I identify Patch no? How it is differ from the patchsets no?
Hello all;
I read the official document, it is saidall the patch and patch together wear. version numbers
-set of patches may be 10.2.0.2,..., 10.2.4.0, 10.2.5.0
How can I identify the patch number?
My version of DB is 10.2.0, which is my version of patch not?
Thanks in advance...If you cannot access MOS then how you suppose download the patch?
The first digit is the more general identifier. It represents a new major version of the software which contains significant new features.
Maintenance of database version number
The second number represents a level of maintenance release. Some new features may also be included.
Version number of the application server
The third digit reflects the level of the version of Oracle Application Server (OracleAS).
Specific to the component version number
The fourth number identifies a specific to a component output level. Individual components can have different numbers in this position according to, for example, the patch sets component or drafts.
Platform-specific version number
The fifth digit identifies a platform-specific version. Usually a set of patches. When different platforms require the equivalent patch game, this figure will be the same across the affected platforms.
Maybe you are looking for
-
Will not print in color from my Mac or iPhoto for HP photosmart D110
My printer will print only in black and white when I print from my Mac OS X 10.6.4 on my printer. I uploaded the photos I photo and print only in black and white. When I put the card directly into the printer, it prints fine color. HP website was n
-
Can I add a 64-bit video card to a desktop computer with a 32 bit processor?
I have a HP a522n with an Intel Pentium 4 (2.60 GHz clock, 400 MHz FSB) processor and 1 GB of DDR1 memory. This processor, I give myself to think, is running on a 32-bit instruction set. I want to disable the integrated video and add graphics EVGA G
-
Dell PowerVault 660F all orange flash driver
Hi all I have the following materials: -1 FC HBA QLogic 2200F for server -FC 1 disk storage 660F (14 x 73 GB drives) now, 14 drivers flash amber and no other amber. QLA2200 can recognize 660F, but all the unknown LUN size. If I choise check disk med
-
BlackBerry OS for Curve 8520 Blackberry Smartphones
Hello I use blackberry 8520 curve with OS 5.0 is installed. Is there a version of the Curve 8520 OS update? Concerning Rohit
-
TMS CCC and JAVA - Clarification
I looked through the forums enough to know that MSD is VERY picky about the version of Java installed on the local computer used to access the control of conference center. Is there a definitive guide to which versions of Java work with which version