FPGA unexpected values
Hello
I just started to use LabVIEW FPGA and have some problems with the acquisition of signals. I set up a test project where I try to the issuance of a signal using a NOR-9263 and collated the signal using a NOR-9215. In addition, I measure a signal created by a signal generator sine. During the measurement, I get unexpected values (see attatchment). I think I get into trouble with the FIFO storage. What is my failure?
Concerning
Daniel
My first guess is that you run into a situation where once from time to time, the number of items to be read from the FIFO is not a multiple of the number of outputs to Decimate 1 d Array. When this happens, you will lose data and the first item next FIFO reading doesn't match the first chain, so you will get incorrect values on the chart. Try to change your code so that when you do the reading of FIFO, it reads that multiples of the Decimate 1 d table size, not to mention that this number should also be less than or equal the number of elements to read in the FIFO (as you already).
EDIT: also, you must make sure that the FIFO write never times out. Now you're ignoring this value. Chances are, it won't expire here, but if this is the case, which could also cause problems because you could write only some of the channels before it fills, which still move channels.
Tags: NI Software
Similar Questions
-
BSOD "irql unexpected value" so that Windows is configure updates
I get this error irql unexpected value twice as Windows is configuring updates originally have me a perfect resettlement system making me lose everything on my computer it's on a R4 DELL M17x which has Windows 7 upgraded to Windows 8
I had the same error message with a blue screen which took into account countdown to restart, tap new. This took place on my Windows 8 system which was not wireless when I was trying to install a wireless adapter on, after that, we went into the House of Cable Wireless internet. The system has even threatened to crash at some point and I uninstalled and ran of restoration for the time before my installation, this NetGear adapter. TWC customer service agent was not helpful and just said that it was the only adapter that they had. This NetGear adapter dated 2010 box says it's for older Windows including Vista, XP and 7 systems. I went to target today and found a card Mini Wireless Linksys for Windows including Windows 8 systems. It has installed in 1 min - wink - and now I have internet again! -Simple. (And Yes TWC needs to purchase new hardware!)
-
CHANGE the SEQUENCE on a busy server translates into very high unexpected values
Our sequence was 782,393,232, or so, when I came it up through 30 000. Here are the commands I used:
change the sequence of OUR_SEQ increment in 30000;
Select double OUR_SEQ.nextval;
change the sequence of OUR_SEQ increment in 1;
commit;
When I questioned nextval in the sequence, a few minutes later, he had climbed up to more 8 billion! I have reset quickly up to 783 million or more, and it behaved correctly after that. I saw some posts on the net that infer that the reset sequence is heavily used can cause "unpredictable." Everyone knows this or y at - it a bug known?
I am running:
Oracle Database 10 g Enterprise Edition Release 10.2.0.4.0 - 64 bit, RAC system.
PL/SQL Release 10.2.0.4.0 - Production
"CORE 10.2.0.4.0 Production."
AMT for Linux: release 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - ProductionSven,
I'm not sure I understand what you're clarifying...
In a CCR cluster, a sequence with a cache has a separate cache in each node of the cluster. If the cache has been set to 20 (the default), and the increase was set to 30,000, each node is hiding 20 values separated by 30 000. And caches would be overlapping (i.e. node A would get 20 values of 1-570 001, node B would get 20 600 001-1 170 001 values). I don't see that this is in contradiction with what I posted.
Obviously, the presence of a cache creates a bit of a ride with when, exactly, you say that a sequence is incremented. The NEXT_VALUE in DBA_SEQUENCES is incremented by cache * interval when any node exhausts its cache. The NEXTVAL of a sequence for connections that hit a particular node will increase by interval every time another session gets the NEXTVAL of a sequence. The NEXTVAL of a sequence for connections on a different node is not affected by what is happening on the current node. What enlightenment do you? If so, I agree.
user11300030,
Discussion on the sequence of caching can provide insight into why none of the lines are between 780 million and 1 billion. It is quite possible that these values have been cached on one node other than the node where the pads were executed. Had caches was flushed not when change you the sequence, inserts run on these other nodes could have used this range values.
Justin
-
Unexpected results after calculation
Hello.
I have 3 databases of production which have worked successfully until Thursday.
FARM sales for the whole company per month.
EB2. Sale of a specific division a week.
EB3. Sale of a specific division and top ranges, per day.
Thursday.
The problem is that after calculation of EB3, the totals I see in the validation reports are incorrect when compared with the totals in the EB1.
The whole story is the display of incorrect results, not only the data for the current month, which is that I charge per day. I'm doing an incremental loading of the current and previous month only.
I took a backup and loaded in the EB3 and performed the calculation... once again the totals were incorrect.
Friday
When I compare the validation reports, totals in EB3 were as expected when checking against the EB1.
I did nothing for the outline, the backup is the same.
EB1 and EB2 were ok.
Saturday (today)
When I see the validation report today I noticed that EB3 has the same behavior; incorrect results.
And EB2 also contains unexpected values after calculation.
Have you encountered this problem before? Is there something specific I should review to determine and solve this problem?
Log files reflect not any message "error" or "fail".
Any comment is welcome.
Kind regards
JC
Difficult to clarify the question without knowing what actually do the calculations. Just a suggesiton wild as you see error every day replacing when you see good results just make a backup of contour and then use the problematic day contour compare to compare 2 contours. May be there are some jobs that you are not aware of the evolution of the sketch, thus destabilizing the whole of the data!
-
Date value, have a strange behavior
Hi people, I am facing a strange situation in 11.2.0.3 EE 64 bit:
SQL >! uname - a
SunOS < hostname > 5.11 11.1 sun4v sparc sun4v
SQL > np_dn_range desc;
Name Null? Type
----------------------------------------- -------- ----------------------------
DN_START NOT NULL VARCHAR2 (18 CHAR)
ACTIVATION_DATE NOT NULL DATE
SQL > select ACTIVATION_DATE from the np_dn_range where DN_START = 528717163931;
ACTIVATION_DATE
----------------------
54890110070000
SQL > SELECT TO_CHAR (ACTIVATION_DATE, ' dd/mm / yyyy:hh24 - mi - ss') from np_dn_range where DN_START = 528717163931;
TO_CHAR (ACTIVATION_
----------------------------
00/00/0000:00-00-00
This should not show as 10/01 / 5489:07:00:00? If I do the same with other values, it works fine:
SQL > SELECT TO_CHAR (ACTIVATION_DATE, ' dd/mm / yyyy:hh24 - mi - ss') from np_dn_range where DN_START = 525549998051;
TO_CHAR (ACTIVATION_
-------------------
02/07 / 2013:07 - 00-00
07/06 / 2021:07 - 00-00
Of course the 5489 year is strange, it's an unexpected value. This value is not strange really because of this behavior, also it does not show if I publish the following:
SQL > select ACTIVATION_DATE from the np_dn_range where ACTIVATION_DATE > sysdate;
Oracle can make errors with math? This line just seems to come from an import of a database that was corrupt, blocks which can be the cause of this strange behavior?
Thank you.
Yes it is strange.
The first octet must be the century + 100, and the second byte must be 100 + year.
Then... (in the order of the those first followed by bad)...
120 113 is equivalent to 2013
120 121 equals 2021
46,11 equals (46-100) = - 54 and (11-100) =-89... and there is no year-54-89
Just check the other bits...
The 3rd octet is the month, if you have months of 7, 6 and 1... they are ok.
The 4th byte is the day, if you have days 2, 7 and 10... they are ok
The 5th byte is time + 1, so you have 8 for everyone, which means 07:00,... they are all ok
The 6th byte is the minutes + 1, if you have 1 for all those, which is 0 minutes... they are ok
Octet 7 seconds + 1, if you have 1 for everyone, i.e. 0 seconds... they are ok
So in terms of months to the time you have:
July 2 07:00
June 7 07:00
10 January 07:00
These part of all date/times are ok, it's just the century and year who were corrupt.
Now, if I force the same corrupted data in my version of the same table using my function of date gross and put my NLS_DATE_FORMAT the same as yours... I can reproduce your problem...
SQL > insert into np_dn_range values ('2345 ', raw_date (chr (46) |)) Chr (11) | Chr (1) | Chr (10) | Chr (8) | Chr (1) | Chr (1)));
1 line of creation.
SQL > alter session set nls_date_format = 'YYYYMMDDHH24MISS ';
Modified session.
SQL > select * from np_dn_range;
DN_START ACTIVATION_DAT
------------------ --------------
2345 54890110070000SQL > select to_char (activation_date, "HH24:MI:SS DD/MM/YYYY) of np_dn_range;
TO_CHAR (ACTIVATION_
-------------------
00/00/0000 00:00:00Your data are certainly corrupted, so everything you use to import or create these data is the problem. It certainly isn't the way that Oracle is the treatment of the date, it's just the fact that corrupted data has been forced in.
-
Interview with case/when & sum() over (partition) producing unexpected lines
Since some time ago, I asked a question in this forum on an unusual problem of join and subtract ( subtract the total periods of highest level duration ). I had what seemed like a work request. So far, I could not really use it. Now that I'm looking closer results, I think that there is something wrong with it, but I can't understand why it's happening.
Using the definition of the table of the original question, the following simple query shows a special extract of the data I'm looking at.
Select duration, event_type, start_time, code_range, request_id from MYTABLE where REQUEST_ID = 'abc '.
This translates into the following lines (separate columns by ' / '):
START_TIME/REQUEST_ID/EVENT_TYPE/CODE_RANGE/DURATION
2010-11-12 01:42:04.0/abc/Junk/publicEntryPoint/2,003
2010-11-12 01:42:04.0/abc/Junk/webServiceCall/947
2010-11-12 01:42:04.0/abc/Junk/webServiceCall/969
Another similar request with REQUEST_ID = 'def' means:
START_TIME/REQUEST_ID/EVENT_TYPE/CODE_RANGE/DURATION
2010-11-12 00:22:13.0/def/junk/webServiceCall/788
2010-11-12 00:22:13.0/def/junk/webServiceCall/1,128
2010-11-12 00:22:13.0/def/junk/publicEntryPoint/2,003
What follows is an excerpt simplified query I have a problem with:
Select value start_time request_id event_type, code_range, duration, case code_range
When "publicEntryPoint" then length * 2 - sum (duration) over (partition by request_id)
of another-1
end inner_duration from MYTABLE where EVENT_TYPE = 'spam' and trunc (START_TIME) = to_date('2010-11-12','yyyy-mm-dd')
and rownum < 1000;
Notice the couple of unconventional functions used here, the ' case/when' and 'sum() over (partition).
This property returns a bunch of lines (count: 999), but here are the two with the particular REQUEST_ID values:
START_TIME/REQUEST_ID/EVENT_TYPE/CODE_RANGE/DURATION/INNER_DURATION
2010-11-12 01:42:04.0/abc/junk/publicEntryPoint/2,003/2,003
2010-11-12 00:22:13.0/def/junk/publicEntryPoint/2,003/87
The second line is correct. The first line has an unexpected value of INNER_DURATION of 2003. It should be 87 as the second row. I don't understand why this is happening.I think that 'and rownum '.<1000" must="" be="" the="" problem.="" it="" must="" be="" excluding="" some="" of="" the="" rows="" needed="" for="" the="" sum.="" the="" analytic="" function="" will="" be="" applied="" after="" this="" condition--see="" the="" sql="">
Analytical functions are the last set of operations performed in a query, except for the
final ORDER BY clause. Every joint and every WHERE, GROUP BY and HAVING clauses are
completed before the analytical functions are processedHave you tried the query without this condition?
Kind regards
Bob -
Choose the values of the list - HELP!
Assume that query test01 values are "9,2,20,21,27,97,28,29,121,93,32".
When I submit the form, the selected values are different from what he was selected. what I've done wrong?
In this part, < cfoutput query = "test01" >
< value = "" #test01.index_id # the option ' < cfif form.colorname contains test01.index_id > selected = "selected" < / cfif > / > #test01.colorname #"
< / cfoutput >
I think this fails because form.colorname has multiple values.
I want to preserve selected values when the form is submitted. If there is a selected value which means form.colorname has a value, then there is no problem; However, if it contains multiple values, the selection list has unexpected values are selected. The selected values must be selected after due form.
Can someone correct me? I worked this code for long hours, but I see no way to remedy. I tried the feature list, but it did not work for me.

HandersonVA,
Contains returns true if a string contains another string. The expression below YES displays because the string "21,27, 97 ' contains the string ' 9'. This isn't the right type of comparison for what you are trying to reach.
YES
To determine if the '9' value is contained in a list of values, use ListFind or ListFindNoCase list functions:
YES
-
Hello world
I'm new to the part during a real-time/embedded Labview and I'm just starting to play with the RIO evaluation kit.
I stumbled upon a phenomenon that I do not understand... So maybe it's a stupid thing, so I apologize in advance.
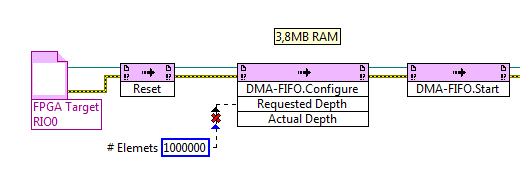
I have create a FIFO on the FPGA target (configured to Traget - to - Host DMA) and put the UINT16 5Million of a FPGA loop values, as soon as possible. Now, amazingly, I can read either with a VI on the chassis in real time, but also with an identical VI located on the PC host, even with similar performance.
In fact, I don't understand where the data are buffered and how the PC can access. I thoght the FIFO DMA memory needs to be on the RT target, right? So, how the data comes to the PC without a RT - VI? I guess that this method of data transfer (FPGA-to-PC) is not a use of FIFO, right?
In addition, when I check the property of "Possible elements" of FIFO in the PC - VI or RT - VI, I get numbers approximately 8000 to 10,000, while FIFO is configured with 1023 elements only.
How is that possible?
(Btw.: I realize that I'm losing a lot of data and the FIFO is small.) Yet, I want to first understand the points above).
The project is included in the ZIP.
Best regards and thanks for your efforts,
Joe
Hey Joe,
NEITHER offers a service called NI RIO Server. This service is installed with LabVIEW RealTime on your target in real time and allows you to connect to the FPGA of the cRIO/sbRIO from a computer.
I can't find a lot of information available on the internet, this page only:
How to make the devices to access RIO on a computer connected to the network? -National Instruments
http://digital.NI.com/public.nsf/allkb/43F81436B97AEE28862573D40069F440He is the Francis, why you are able to run the same program in real-time on the RIO and the development computer. It is also the reason why you must enter the IP address of the target in real time on the program running on the development PC. If you run the VI on the RealTime Taraget itself, it is not necessary to enter the IP address.
Some information on the size of the FIFO:
The FIFO is not only a buffer. A buffer of contains two FIFO.
A buffer is located in the FPGA itself. It is unbelievable small (1023 elements by default), but this buffer is super fast. The size of this buffer is configured as part of the LabVIEW project. You can increase the number of elements in the buffer zone, but you will never be able to achieve an elements > 20K buffer size due to the constrained resource of the FPGA.
The second buffer is located on the site in real time of the RIO. This buffer can be bigger than the buffer on the FPGA, usually 10 x or more. You can configure the size of the buffer of site in real time by your LabVIEW Code on the part in real time.
Best regards, Stephan
-
Expect a result of zero when subtracting, but is 138.778E - 18
I get unexpected values in a subtraction routine. I'm using LabView 2013.
In my example code VI, I have several condition blocks sequentially decremented 7 banks of values. I get an unexpected result when executing my code under the following conditions:
Bank 1 = 1.0
2 the Bank to Bank 7 = 100
BankTTL = 601,00
Maneuvers of rate = 1, which makes the Rate(%FP/s) = 0.10
I run the code 10 times expected decremented by 1 Bank of 0.10 each time.
When I run the code the 11th time, 1 Bank should remain at zero and Bank 2 should begin decrement.
However, this is not the case... 1 Bank becomes-. 01. This should not happen.
By tracing the code, put a probe on the entrance to the indicator of Bank 1, the value returned after 10 executions in the "probe Watch Window' is 138.778E - 18. This is unexpected. The value displayed in the front panel is 0.00.
When I start my logic with the following values:
Bank 1 = 0.1
2 the Bank to Bank 7 = 100
BankTTL = 600.10
Maneuvers of rate = 1, which makes the Rate(%FP/s) = 0.10
I get the expected result of zero in the 'spy Probe window' as the façade for Bank 1 indicator.
Your help to solve the unexpected result would be greatly appreciated.
Thank you.
Lixuan
SGL/DBL types store numbers in binary format. Powers of 2 can be represented accurately (..., 0.125, 0.25, 0.5, 1, 2, 4, 8,...), but most of the other numbers may not.
100, 0.1 and 601 are not powers of 2, so these values can be stored precisely and produce any rounding errors. See: ""which causes any floating point rounding errors?".
Note that 138.778E - 18 is 0.000000000000000138778, which is very close to zero as your starting value is of ~ 600.
-
Hello
I am trying to establish connection TCP LABVIEW n/b and program C++. Server is established in C++, while the client is implemented in labview. Even if the connection is established with customer success and the b/w Server, both are unable to correctly understand send/receive data between them. For example if I want to send a send_array of type int to the server, I use the 'send' like that standard WINSOCK function:
Send (AcceptSocket,(Char*) send_array, 129 * 4, 0);
but when this table was made by the client in labview, it shows unexpected values. As a customer, I used 'data simple client.vi' with a change as Envoy (129 * 4 bytes) data size has been set, only TCP read has been used.
Same problem exists if I send data from client to server.
Kindly help me
Best regards
It's probably a problem of edian big/small. If you use the flatten/Unflatten of string functions, you can specify which one to use.
-
OfficeJet Pro L7555 installation fails on Windows 7 (64-bit). "Fatal error".
Printing/scanning doctor does not resolve. Wired network. This device works on my network for almost 2 years. Has stopped working and will not reinstall. Basic printing works, but cannot scan. «LaunchNetworkInstall gets back unexpected value 1246.»
In short, if you ar following the instructions to the letter - that is not possible.
I downloaded the software from the link I provided and that you have provided. I chose the full features software and installed the printer on my Win7 machine. Both these pages appear in all versions of the software, and the page with the check box that requires you to accept the conditions required by law. There is no way for these pages to be omitted on your computer.
I'll transfer my instructions to uninstall/reinstall of the printer.
First of all, if you use a USB cable, be sure to remove it. Do not plug it in again until the software instructs you. Through devices and printers, programs and features and issues Device Manager and make sure that all copies, files, and programs related to the printer are removed. As indicated, and then restart the computer.
The START menu type "%temp%" and press on ENTER. Here, I want you to press Ctrl+A and press on REMOVE. Some files you cannot delete them, ignore these files and delete the majority that allows it to.
Follow this link to download full feature software and drivers of the printer:
Install and let me know the result!
-
When running the installer of HP...
Tried to install the software to help...
------------------------------------------------------------------------------------------
Setup cannot complete the installation of the network at this time. Please, check the following and try again:
-Your device and your PC are connected to your network
-All parameters you entered are valid
-Firewall interfere with your installation.
For the latest information and updates, please visit www.hp.com/support
This is the error code I get when I look in the diagnostic log.
-------------------------------------------------------------------------------------
Now Launching = X:\hpzdui40.exe - I XXX f X:\DIVins?. DAT
LaunchNetworkInstall retrieves the unexpected value 2
Run: 50 return stops Driver UI plugin
Exit code = 50------------------------------------------------------------------------------------------
Error reports: [11111112] an AutoCorrect entry is not available at this time.
The installation tool and then hangs at step 11 of 14 removing unnecessary components.
System
Windows 8, 64-bit
Generation custom for the game.
The funny thing is, until the installation of the rail program and cancels changes. I can do print. It will not just go through the installation of the software. I tried to disable the firewall and antivirus. I'll me crazy trying to figure this out and do not think that this should be so complicated that it is... Uninstall HP programs should not be so inadequate to let so many garbage behind. /endrant anyway
In any case, it all started because of a problem preventing me from being able to use the it function analysis. At the time, I could run a scan on my computer but not from the printer even if he saw my computer and different profiles that I put in place through the Toolbox fx and Scan function.
I have taken measures...
- http://h30434.www3.HP.com/T5/printing-issues-troubleshooting/LaserJet-full-scrub-steps-for-non-HP-co...
- http://h30434.www3.HP.com/T5/printing-issues-troubleshooting/version-20-of-the-HP-software-and-above...
Try this even if it wasn't really necessary... or specific because I'm going crazy trying to figure this. Should not it lasts, * cough cough * Hp! Getting real tired of your... stuff!
A ran the scrubbers. http://tinyurl.com/m5633q3
EVEN MADE MY OWN BATCH FILE TO AUTOMATE THE PROCESS A BIT MORE. You can view the file through my dropbox account if you wish. Of course, I did the steps in my batch file.
Beware, this is a batch file that modifies the files and made suggestions on what to do to solve any problems you might have with your printer, but I take no responsibilities for any problem that you create. Editing the registry in particular is a risky process and must first perform a backup. If you have any suggestions to do better, feel free to comment.
https://www.dropbox.com/s/oszw5emhqhp76jy/HP%20Software%20Manual%20Scrub.bat
I hope it's enough information to make a few suggestions that are worth it. I'm tired of going crazy on it... Please save my sanity!
I ended up reinstalling my OS, since it was awkward when even with the upgrade to Windows 8.1 because I had redirected user folders.
However, I really wish HP would make a decent software for once, but that's probably asking too so I can start using their competitors as well. Nothing has changed over the years with their software from what I've seen. It's ridiculous!
-
vRA 6.2 - error loading of a presentation of the ASD workflow user
Hello
I have a vRO workflow which I joined in vRA as a workflow of ASD. The workflow stops for user interaction. Some of the values in the presentation are nto loadedi presentation and predefined values, which are generated once the workflow is started.
When I try to respond to the intervention of the user, the GUI of vRA starts to load the fields, but shortly after the start, I get the error:

The vRO workflow validation shows no errors, I can run very well with the customer to vRO. When I completely remove predefined values, the GUI presentation load fields summary and description of the Interaction of the user manual, however this end with an error as well after a short time.
2015-12-11 13:40:39, 436 vcac: [component = "coffee: shell" priority = "ERROR" thread = "http tomcat - 1278" tenant = ""] com.vmware.vcac.shell.ErrorManagerImpl.logToApacheCommons:59 - < 92df07b1 > unexpected value
We took
com.vmware.vcac.platform.framework.error.ErrorCodeException: 504
at Unknown.gk (unknown Source)
at Unknown.pk (unknown Source)
at Unknown.Xpc (unknown Source)
at Unknown.v2h (unknown Source)
at Unknown.LCe (unknown Source)
at Unknown.JCe (unknown Source)
at Unknown.jzi (unknown Source)
at Unknown.mzi (unknown Source)
at Unknown.dBi (unknown Source)
at Unknown.hBi (unknown Source)
to Unknown.aBi / <(Unknown Source)
at Unknown.p (unknown Source)
at Unknown.gadgets.util.makeClosure/ <(Unknown Source)
at Unknown.anonymous (unknown Source)
Any ideas? It has to do with a timeout when the presentation is loaded?
OK, so observe the screenshots and the workflow in this post with a lot of attention. The speed cannot be denied and no matter what VMware comes with compared to obtaining objects (as the platform is currently written), I think that this method will be faster in the presentation.
What you will see in this workflow:
Get owned VMs an applicant is quick and easy through the IaaS objects (of which the OWNER is held): ~ 5 seconds per 140 total of machines / machines belonging to 10
variable user is [email protected] format... for example the format of an applicant VRA
var entities = Server.findAllForType("VCAC:VirtualMachine"); //If you are dealing with one vcacHost... otherwise you have to bake this into the loop per ent instance var vcacHost = Server.findForType("vCAC:VCACHost", entities[0].getEntity().hostId); for each (ent in entities){ if (ent.isManaged == true && ent.getEntity().getLink(vcacHost,"Owner")[0].getProperty("UserName") == user){ virtualMachineNames.push(ent.displayName); catalogResources.push(vCACCAFEEntitiesFinder.findCatalogResources(cafeHost,ent.displayName)[0]); } }Once all the machines are in the table, getting a dedupliquee list of business groups that support the machines is fast:.02 seconds for 10 machines
for each (catalogResource in catalogResources){ try{ tempLabel = catalogResource.getOrganization().getSubtenantLabel(); } catch (err) { tempLabel = null; } if ( tempLabel != null && businessGroupNames.indexOf(tempLabel) == -1 ){ businessGroupNames.push(tempLabel); bgcount++; } }The massive time differences by working with the methods of EntitiesFinder for BusinessGroups between FIND and GET: ~ vs 24seconds ~ 2seconds to get the same BG.
//This is slow... but that is okay. It ISN'T slow when the user is selecting things. // It is slow in post-user workflow. If we carry the ID through for the business group // we can increase the speed of this through the GET section of the entities finder or via REST var start, finish; start = Date.now(); selectedBusinessGroup = vCACCAFEEntitiesFinder.findBusinessGroups(cafeHost,mySelectedBusinessGroup)[0]; finish = Date.now(); System.log(selectedBusinessGroup.getName() + " Cafe Business Group was selected and found."); System.log("Total time to find that one BG: " + (finish-start)/1000 + " seconds "); // How fast is it with the ID? var tempId = selectedBusinessGroup.getId(); // let's get the id start = Date.now(); var getProof = vCACCAFEEntitiesFinder.getBusinessGroup(cafeHost,tempId); // get the object again with the ID finish = Date.now(); System.log ("Using Get method with ID it took " + (finish-start)/1000 + " seconds to get the BG");Keep in mind here... the form you see below came upward in 5 seconds after the start of workflow with data.
He has a list of virtual computers and a list of groups of companies. It is not exactly what you want to do, but provides some faster methods that you are currently using.


For the workflow, you need to edit and link your host of coffee to the attribute.

-
POS backup jobs is not new VM joined resource pools
Hello
I just got the daily report of the electronic mail of the POS device. I checked it to find errors and I saw that some newly created VMs has these unexpected values:
Last backup job: unknown (labels might be different because they are translated from the french...)
Last successful backup: never
Date of the last backup job: never
This means that these VMs were not considered by the backup task.
With the VDR, when a backup operation has been assigned to a resource pool, each new virtual machine to join this pool was naturally saved on the next backup tasks.
With POS, it seems does not work like that more. It seems that we have updated the backup operation attached to this pool (Edit, Next 4 times, finishing...) so that the new virtual machines looked to the backup to the next backup job.
So how is this? Can we have VDP automatically update his backup job to study of new virtual machines added to a resource pool?
Mini.
I noticed one thing is... If a virtual computer is added to the RP through c# (Thick) client instead of UCS, so you may need to manually do a refresh on the Backup tab, then run a backup that would automatically take the new virtual machines added to the list of resources
-Suresh
-
Hi all
11.2.0.1
We have 3 party app that runs continuously in a proactive way in expectation of new incoming transaction processing. Today he SID = 6 and is the original lock on one of our batch.
When I run the SQL blocker, it shows only a "select" only statement.
I know there are series of instructions sql uncommitted tracks in this app, and one of them should be "update."
My dilemma is the seller denied that their application is originally the lock and is asking which statement is actually the lock.
Is there a way to retrieve all the sql being run by SID = 6 statements?
Thank you very much
zxy
yxes2013 wrote:
But most of the time it's good to 80% and 20% of the problems meet it's weird. So what is this 20% to?
Your sentence doesn't mean anything to me. You must perform your own analysis on your side, chat with people around you.
I don't know about the other people here, but I don't know anything about your env and Appl.
It could be data, some values may trigger additional processes, or simply unexpected value.
It could be scheduled to run at the same time on some days where they shouldn't be, or at the same time that transaction of the different lots.
It could be that some people have direct access to the database where they should not and they are doing something wrong.
It could be your server, and which is running when you think about your process is 'suspended', making a CPU or the i/o overhead.
It could be collected statistics when they shouldn't, it can change the execution plan and slow down the path.
The list is not limited to the foregoing, add to everything what you want according to your unknown env. Unknown to us, but apparently unknown to you as well.
Now it of your turn, take the ball and start working with your colleagues.
Nicolas.




Maybe you are looking for
-
Hi, I would like to move all the folders and files on the Icloud drive on my desktop. I can't... I have cjhecked all the texts support and can't find an easy way to do... I would just drag files to disk on my desktop but it is not possible. Please he
-
Cannot save with Toshiba DVR D-R410KU
Gradually my VCR - bought a DVR - model Toshiba - D-R410KU. I can't get this thing to save for my life. I can get it to play DVDs fine. When I try to save I do not see the TV screen either - it's just a blue screen. Should not be something like with
-
HP 15-AF138AU: need LAN drivers
Hello I can't find the Lan drivers for my pc, I'm under it wifi only. Please post me the link to download the lan drivers best fits my pc. Thank you PC
-
Fake site offers updated for Firefox, or am I wrong?
I was looking for a picture of some using Google and when tried to open one of the results I had this hxxp://supportff .co .cc / where page propose to update Firefox. I was suspicious and decided to report it here. It does not resemble legitimate sit
-
Satellite L300 - Audio dropouts
Hi all I'm chancing down the source of the audio dropouts that I experience on my new Satellite L300. When I bought it I opened for the downgrade to XP Pro. After optimization of XP and disabling and number of devices and services, I now operate virt