get same rank 2nd dimension value based on 1st value of dimension of a 2d array
Hello
I have a chart 2d figures.
If I need to extract the value Y automatically to a chosen value X of a digital command. How can I do this?
BP
Use the interpolate VI.
Tags: NI Software
Similar Questions
-
Change the value of always the same as the previous value register
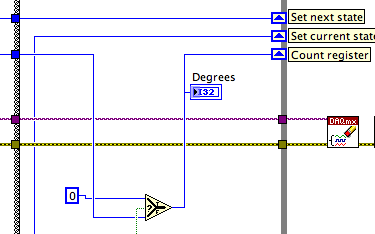
Hi all. I was banging my head against the wall for a while on it and hoping that someone can help me.
I use a USB-6008 DAQ hardware to read a rotary encoder. I pulled the rudiments of the attached VI of the forums, but I modified to work with an encoder with an index. All I'm doing is reset to the "value of the degrees to zero whenever the value of the counter (Encoder index) increases a. I thought I was good at using the shift register, since it must retain the value of the previous iteration (just before the index spent). The problem I have is that two courses to the function values ' lower to "always seem to be the same, so my 'degrees' value never resets. What Miss me?
Thank you!
PS - I need to use the meter (instead of just another digital line) because it is essential that the index value is never missed. And I know using a software based counter as this tends to miss a digital input signal here and there.
Suppose that your encoder runs at 1 rpm = 1 index pulse per second. You are turning your loop to 1000 times per second. It is not clear that the 6008 reads the line of DI and the meter that fast. The software update timed AO rate is 150 Hz, maximum. If it reads fast, get you 999 readings of 0 and a reading of 1. For 1 millisecond the degrees indicator will display 0. On the next iteration of the loop of the< comparison="" will="" be="" true="" again="" and="" the="" shift="" register="" value="" will="" be="" displayed="" again.="" what="" you="" need="" to="" do="" is="" to="" reset="" the="" value="" going="" into="" the="" count="" register="" to="" zero,="" not="" the="" display.="" one="" simple="" wiring="" change="" should="" fix="">
Lynn
-
Hi friends,
I have the EMP table with column (date of HIRE date);
I choose the last employee hired by using max (hiredate).
How can I select the 2nd to the last hired?
Thank you very muchA little bit depends on your needs
(1) MAX (value) OF the table WHERE the value, SELECT< (select="" max(value)="" from="">
(2) SELECT value FROM (SELECT value, RANK() OVER (ORDER BY value DESC) FROM rn table) WHERE rn = 2
(3) SELECT value FROM (SELECT value, DENSE_RANK() OVER (ORDER BY value DESC) FROM rn table) WHERE rn = 2
(4) SELECT value FROM (SELECT value, ROW_NUMBER() OVER (ORDER BY value DESC) FROM rn table) WHERE rn = 2
(5) to SELECT the value OF (SELECT ROWNUM, value OF (SELECT value FROM table ORDER BY value DESC)) WHERE the rn = 2
(6) to SELECT the value OF (SELECT ROWNUM, value OF (SELECT DISTINCT value FROM table ORDER BY value DESC)) WHERE the rn = 2If you are talking about the 2nd largest value, what do you get in the following examples?
Values 5,5,3,3,2
Your goal is:
3: use the solution 1.6
3, 3: use solution 3
5: use the solution 4.5
Nothing (because there are 2 higher and 1 third most high): use solution 2So, you're not really free to choose what you want...
HTH
-
Outlook Express - I get same message three to four times and can not stop feeding.
I get same message times three and four years and can not stop feeding.
Moved from feedback
Original title: outlook expressHave you tried to delete the Pop3uidl.dbx as Steve suggested?
Tools | Accounts | Mail | Properties | Advanced. Uncheck: Leave a copy of messages on the server. Then, remove the Pop3uidl.dbx file. You will get the messages once more, but it should be.
Tools | Options | Maintenance | Store folder will reveal the location of your Outlook Express files. Note the location and navigate on it in Explorer Windows or, copy and paste in start | Run.
In Windows XP, the files of user OE (DBX and WAB) are by default marked as hidden. To view these files in Windows Explorer, you must enable Show hidden files and folders under start | Control Panel | Folder Options icon | Opinion, or in Windows Explorer. Tools | Folder options | View.
With OE closed, find the Pop3uidl.dbx file and delete it. Another will be created automatically when you open OE.
-
I bought CS5 and you want to download it to my computer. For some reason any only the first disk will be installed and the second disc will not install due to, I get an error message that indicates the following programs contain errors and may not install. Can I get a new 2nd drive?
Hello
Please remember that the serial number is for CS5 or CS5.5 because they are two distinct versions, and there will be two different serial numbers of them.
You can see,
Warning: "Adobe software real failure of Validation...". » | Windows
Failure audit download or installation. CS6
If you CS5.5, check and confirm what to see, quickly find your serial number
Download from: Download CS5.5 products
Let us know if that helps.
Kind regards
Bani
-
When possible in Oracle Forms to insert a second line based on 1st row, so why not in the ADF?
Mr President
When possible in Oracle Forms to insert a second line based on 1st row, so why not in the ADF?
The user just enter data in the Module of sales in one line of a Bill as below
and it is displayed in two rows in financial Module.like below how to proceed in the ADF.
You can see that invoice line contains the sales tax and the gross sales amounts, then it is posted to the financial Module above two lines.
How to make ADF
Respect of
What I realized, this is:
-You have a table in you screen.
-You call CreateInsert 2 times to create 2 rows at the same time.
-You will enter value in a specific column (c1) line1
Looking for the value that you entered in row1 can be completely copied in the same column (c1), but in line2. is this correct?
If so try to do the following:
1. in the table inputText (c1) column set autoSubmit = true and setValueChangeListener to a method in backbean
2. in the inputTextValueChangeListener method to write this code
public void inputTextValueChangeListener(ValueChangeEvent valueChangeEvent) { DCIteratorBinding tableIter = (DCIteratorBinding) BindingContext.getCurrent().getCurrentBindingsEntry().get("tableIteratorName");// write table iterator name from pageDef. for (int i = 0; i < tableIter.getViewObject().getEstimatedRowCount(); i++) { ViewRowImpl myRow = (ViewRowImpl) tableIter.getRowAtRangeIndex(i); EntityImpl entityImpl = myRow.getEntity(0); if (EntityImpl.STATUS_NEW == entityImpl.getEntityState()) { System.out.println("New row found"); myRow.setAttribute("AttributeName", valueChangeEvent.getNewValue());// write attribute name } } }3 - Add inputText id in the partialTrigger table
4 - pageDef. Set of table iterator rangeSize = "-1".
-
Hello
I was wondering if I could get some information and opinions on the use of an array of type defined clusters to store configuration data. I am creating a program to test several EHR and wanted to have a control of type defined for each HAD with the information needed to create the DAQmx tasks for all signals for it must HAVE. I am eager to do so that the data are encoded in hard and not in a file that the user might spoil.
Controls of type def are then put into a Subvi who chooses as appropriate, one based on the enumeration of Type DUT connected to a case structure.
I have problems with the control of the defined type. I see issues when you try to save a configuration unique to each element of the array in the array of clusters. Somehow, it worked at first, but now by clicking on "Operations on the data--> default font of the current value ' on individual elements of the cluster or the entire cluster (array element) does not save data when I re - open the command def. What I am doing wrong? I'm trying to do something with the berries of the clusters that I shouldn't do?
I enclose one of the defined reference type controls. I tried to change it bare to see if that helped, but no luck.
To reproduce, change the resource string for the element 0 of the array and do the new value by default. Then close the def of type, and then reopen it. The old value is always present in this element. The VI is saved in LabVIEW 2012.
The values of a typedef are not proprigated to the instances of the control. They get if created WHEN data values have changed. They will be not updated with the changes to come. You must create a VI specifically to hardcode your values or to implement a file based initialization. The base file would be much better and more flexible. If you don't want users to change the data simply encryption. There is a wedding blowfish library that you can download.
-
How to extract the value of the element as an array in javascript
Hi all
I want to do some calculations on the value entered by the user in the textfield of a tabular presentation, how can I retrieve the value of the element as an array in javascript?
I use as a normal, do not use in the form of apex_item.
I can pass the current value of the textfield to the function using 'this' as a parameter, but how can I retrieve the value of other lines of the same column?
Thank you
TauceefIf it is a page element wouldn't be better to make a calculation of point page when onload of the page? Just do a SQL as select sum (col1) of dual nationality or whatever is your table/column?
-
How to get the total number of occurrences based on the value of a column.
Hi all
It is the first time I'll ask the question here on your forum, but since then followed several threads. I guess it's now my turn to ask a question. Anyway here's the thing, I have a query that should return to count the number of rows based on the value of HOUSING. Something like this:
-----
-----WIPDATAVALUE SLOT N M 1-2 TRALTEST43S1 1 3 1-2 TRALTEST43S1 2 3 3 TRALTEST43S1 3 3 4-6 TRALTEST43S2 1 4 4-6 TRALTEST43S2 2 4 4-6 TRALTEST43S2 3 4 7 TRALTEST43S2 4 4
As you can see above, on the TRALTEST43S1 of the SLOT, there are three occurrences, so M (Total number of occurrences) must be three and this column N he's counting. It is the same with the TRALTEST43S2 of the SLOT. It's the query I have so far:
And it leads to something like this:SELECT DISTINCT WIPDATAVALUE, SLOT , LEVEL AS n , m FROM ( SELECT WIPDATAVALUE , SLOT , (dulo - una) + 1 AS m FROM ( SELECT WIPDATAVALUE , SLOT , CASE WHEN INSTR(wipdatavalue, '-') = 0 THEN wipdatavalue ELSE SUBSTR(wipdatavalue, 1, INSTR(wipdatavalue, '-')-1) END AS una , CASE WHEN INSTR(wipdatavalue, '-') = 0 THEN wipdatavalue ELSE SUBSTR(wipdatavalue, INSTR(wipdatavalue, '-') + 1) END AS dulo FROM trprinting WHERE (containername = :lotID OR SLOT= :lotID) AND WIPDATAVALUE LIKE :wip ) ) CONNECT BY LEVEL <= m ORDER BY wipdatavalue;
-----
-----WIPDATAVALUE SLOT N M 1-2 TRALTEST43S1 1 2 1-2 TRALTEST43S1 2 2 3 TRALTEST43S1 1 1 4-6 TRALTEST43S2 1 3 4-6 TRALTEST43S2 2 3 4-6 TRALTEST43S2 3 3 7 TRALTEST43S2 1 1
I think that my current query based results M and N on WIPDATAVALUE and not HOUSING that's why I get the wrong result. I also tried to use WITH instruction and it works well, but unfortunately, our system cannot accept the subquery factoring.
I know that you guys will be of help because you are all awesome. Thank you all
Published by: 1001275 on April 19, 2013 20:07
Published by: 1001275 on April 19, 2013 20:18Hello
1001275 wrote:
Hi sb92075,You are right that it is available with this version. But our system doesn't put queries that use subquery factoring.
What system are you talking about? If you really have something that prevents you from using all the features of Oacle, you should seriously think about fixing it.
Any other ideas on how we can do this without help WITH clause?
Yes; If a WITH clause is referenced that once, it can be re-written as a point of view online:
SELECT wipdatavalue , slot , ROW_NUMBER () OVER ( PARTITION BY slot ORDER BY low_number ) AS m , COUNT (*) OVER ( PARTITION BY slot ) AS n FROM ( -- Begin in-line view (got_numbers) SELECT wipdatavalue , slot , TO_NUMBER ( SUBSTR ( wipdatavalue , 1 , INSTR ( wipdatavalue || '-' , '-' ) - 1 ) ) AS low_number , TO_NUMBER ( SUBSTR ( wipdatavalue , 1 + INSTR ( wipdatavalue , '-' ) ) ) AS high_number FROM trprinting ) -- End in-line view got_numbers CONNECT BY LEVEL <= high_number + 1 - low_number AND low_number = PRIOR low_number AND PRIOR SYS_GUID () IS NOT NULL ORDER BY low_number , m ; -
Get the RANK of values to the end user using the A-team
In my rest, class of service (Department) it is a function (POST) who receive the range of values of its consumers and returns List < and >.
It is the function
@POST
@Path("{from}/{to}/Departments")
@Produces ({"application/json"})
public list < departments > findRange (around @PathParam("from"), around @PathParam("to") to) {}
Return super.findRange (new int [] {, to});
}
Persistence A-team Accelerator, duties DepartmentSevice (DC) are pre-built, please how I can configure rang of function values in the class DepartmentService and call or manipulate the AMX page so that the end user can be entered range values during the operation in his mobile?
Rest of the a-Team/json in place of Images:


Thank you.
Best regards
Bartholomew
Hi Steven thanks for your comment I intentionally use the post to test whether it is possible to rotate to GET the other way round.so I wore your instructions and it workd
Thank you very much
Best regards
Bartholomew
-
one-to-many selfjoin, delete records with the same rank or a substitution
Sorry for my poor choice of the title of the discussion, feel free to suggest me a more relevant
I rewrote for clarity and as a result of the FAQ post.
Version of DB
I use Oracle10g Enterprise 10.2.0.1.0 64-bit
Tables involved
CREATE TABLE wrhwr ( wr_id INTEGER PRIMARY KEY, eq_id VARCHAR2(50) NULL, date_completed DATE NULL, status VARCHAR2(20) NOT NULL, pmp_id VARCHAR2(20) NOT NULL, description VARCHAR2(20) NULL);
Examples of data
INSERT into wrhwr VALUES (1,'MI-EXT-0001',date'2013-07-16','Com','VER-EXC','Revisione') INSERT into wrhwr VALUES (2,'MI-EXT-0001',date'2013-07-01','Com','VER-EXC','Verifica') INSERT into wrhwr VALUES (3,'MI-EXT-0001',date'2013-06-15','Com','VER-EXC','Revisione') INSERT into wrhwr VALUES (4,'MI-EXT-0001',date'2013-06-25','Com','VER-EXC','Verifica') INSERT into wrhwr VALUES (5,'MI-EXT-0001',date'2013-04-14','Com','VER-EXC','Revisione') INSERT into wrhwr VALUES (6,'MI-EXT-0001',date'2013-04-30','Com','VER-EXC','Verifica') INSERT into wrhwr VALUES (7,'MI-EXT-0001',date'2013-03-14','Com','VER-EXC','Collaudo')
Query used
SELECT * FROM (SELECT eq_id, date_completed, RANK () OVER (PARTITION BY eq_id ORDER BY date_completed DESC NULLS LAST) rn FROM wrhwr WHERE status != 'S' AND pmp_id LIKE 'VER-EX%' AND description LIKE '%Verifica%') table1, (SELECT eq_id, date_completed, RANK () OVER (PARTITION BY eq_id ORDER BY date_completed DESC NULLS LAST) rn FROM wrhwr WHERE status != 'S' AND pmp_id LIKE 'VER-EX%' AND description LIKE '%Revisione%') table2, (SELECT eq_id, date_completed, RANK () OVER (PARTITION BY eq_id ORDER BY date_completed DESC NULLS LAST) rn FROM wrhwr WHERE status != 'S' AND pmp_id LIKE 'VER-EX%' AND description LIKE '%Collaudo%') table3 WHERE table1.eq_id = table3.eq_id AND table2.eq_id = table3.eq_id AND table1.eq_id = table2.eq_id
The above query is intended to selfjoin wrhwr table 3 times in order to have for each line:
- eq_id;
- date of the completion of a verification type work request for this eq_id (aka table1);
- date completion of a line (aka table2) type wr for this eq_id;
- date of completion of a type wr Collaudo (aka table3) for this eq_id;
A separate eq_id:
- can have different completion of many requests for work (wrhwr records) with dates or date of completion (date_completed NULL column).
- in a date range can have all types of wrhwr ('verification', 'Line', 'Problem'), or some of them (e.g. audit, line but not Collaudo, Collaudo but not verification and line, etc.);
- must not repeat the substrings in the description;
- (eq_id, date_completed) are not unique but (eq_id, date_completed, description, pmp_id) must be unique;
Expected results
Using data from the example above, I expect this output:
eq_id, table1.date_completed, table2.date_completed, table3.date_completed
MI-ext-001,2013-07-01,2013-07-16,2013-03-14 <- to this eq_id table3 doesn't have 3 lines but only 1. I would like to repeat the value most in the rankings in table 3 for each line of output
MI-ext-001,2013-07-01,2013-06-15,2013-03-14 <-I don't want this line of table1 and table2 with both 3 lines match must be in terms of grade (1st, 1st) (2nd, 2nd) (3rd, 3rd)
MI-ext-001,2013-06-25,2013-06-15,2013-03-14 <-2nd table1 joined the 2nd row from table2
MI-ext-001,2013-04-30,2013-04-14, 2013-03-14 <-1 table1, table2 rank rank 1, 1st rank table3
In the syntax of vector style, tuple expected output should be:
IX = ranking of the i - th of tableX
(i1, i2, i3) IF EXISTS a rank i - th line in each table
ON THE OTHER
(i1, b, b)
where b is the first available lower ranking of the table2, or NULL if there isn't any line of lower rank.
Clues?
With the query, I am unable to delete the lines "spurius.
I think a solution based on analytical functions such as LAG() and LEAD(), using ROLLUP() or CUBE(), using nested queries, but I would find a solution elegant, simple, fast, and easy to maintain.
Thank you
Hello
Sorry, it's still not quite clear what you are asking.
This becomes the desired resutls of the sample data you posted:
WITH got_r_type AS
(
SELECT eq_id, date_completed
CASE
Description WHEN LIKE '% Collaudo %' THEN 'C '.
Description WHEN AS 'Line %' THEN 'R '.
Description WHEN AS 'Verification %' THEN 'V '.
END AS r_type
OF wrhwr
Situation WHERE! = s "
AND pmp_id LIKE '% WORM - EX'
)
got_r_num AS
(
SELECT eq_id, date_completed, r_type
, ROW_NUMBER () OVER (PARTITION BY eq_id, r_type)
ORDER BY date_completed DESC NULLS LAST
) AS r_num
OF got_r_type
WHERE r_type IS NOT NULL
)
SELECT eq_id
LAST_VALUE (MIN (CASE WHEN r_type THEN date_completed END = ' V')
IGNORES NULL VALUES
) OVER (PARTITION BY eq_id
ORDER BY r_num
) AS audit
LAST_VALUE (MIN (CASE WHEN r_type = 'R' THEN date_completed END)
IGNORES NULL VALUES
) OVER (PARTITION BY eq_id
ORDER BY r_num
) AS line
LAST_VALUE (MIN (CASE WHEN r_type = 'C' THEN date_completed END)
IGNORES NULL VALUES
) OVER (PARTITION BY eq_id
ORDER BY r_num
) AS collauda
OF got_r_num
GROUP BY eq_id
r_num
ORDER BY eq_id
r_num
;
I guess the description can have (at most) only substrings target, in other words, you can't have a line like this:
INSERT into (1,'MI-EXT-0001',date'2013-07-16','Com','VER-EXC','Revisione VALUES wrhwr and audit");
In addition, you said the combination (eq_id, date_comepleted) is not unique, that it is y no example of this in your sample data. What results would you if, in addition to this line (who did the validation):
INSERT into wrhwr VALUES (7,'MI-EXT-0001',date'2013-03-14','Com','VER-EXC','Collaudo');
the following line is also?
INSERT into wrhwr VALUES (97,'MI-EXT-0001',date'2013-03-14','Com','VER-EXCFUBAR','Collaudo');
.
You could do a self-join instead of GROUP BY, but I suspect it will be much less effective. You can use FULL OUTER JOIN, since you do not know what r_types was that r_nums.
-
help with my HorizontalFieldManager & EditFields on the same line, 2nd column is not displayed
Hi all, I've written a bean (called LabelAndEditField) that sets out a label and editfield as follows
someLabel
_________________
| |
-----------------------
It seems to work perfectly when it is the only component on a line of a
VerticalFieldManager
now I want to reuse this compenent such that I can have a screen that looks like
someLabel another label
______________ ______________
| | | |
-------------------------- --------------------------
and perhaps a third column.
However, when you add my components of LabelAndEditField, the 2nd does not appear
I used a HorizontalFieldManager and make
HFM HorizontalFieldManager = new HorizontalFieldManager();
HFM. Add (new LabelAndEditField ("someLabel"));
HFM. Add (new LabelAndEditField ("another label"));
then I just on the screen
Add (hfm);
but it does not show my second column, the second component of the LabelAndEditField
Here is the snippet of code below, some can please help me get this to display
(Sorry, that the code of my insert is wacked)
public class LabelAndEditField extends VerticalFieldManager { private EditField _editField; public LabelAndEditField(String label, String initialValueOfTextField, int maxChars, long style) { super(NO_HORIZONTAL_SCROLL); add(labelField); HorizontalFieldManager textMgr = new HorizontalFieldManager( Manager.NO_HORIZONTAL_SCROLL | Manager.NO_HORIZONTAL_SCROLLBAR); _editField = new EditField("", initialValueOfTextField, maxChars, style | EditField.NO_NEWLINE | EditField.FOCUSABLE | EditField.NON_SPELLCHECKABLE | Field.FIELD_VCENTER | Field.FIELD_LEFT); textMgr.add(_editField); add(textMgr); } }and the code that adds as that on the screen
super(NO_HORIZONTAL_SCROLL); // this is a VerticalFieldManager HorizontalFieldManager rowMgr = new HorizontalFieldManager(Manager.NO_HORIZONTAL_SCROLL | Manager.NO_HORIZONTAL_SCROLLBAR); LabelAndEditField col1= new LabelAndEditField("some label","initial value",12,Field.READONLY); LabelAndEditField col2= new LabelAndEditField("another some label","initial value",12,Field.READONLY); rowMgr.add(col1); rowMgr.add(col2);did anyone see anything wrong with that?
As you can see for yourself, there is no place for the mktShare. Try to go with FlowFieldManager and no HorizontalFieldManager as a container for your gadgets MyLabelAndEditField and see

There is another possibility:
The key in the code I provided is the super.layout (myWidth, maxHeight). This myWidth tells your EditField its maximum size in pixels. If you want to further restrict the domain, you have several options. The only problem is - if you limit it too much, you will not be able to see the rest of the field. To solve this, wrap your EditField (in which you now don't have to override the layout) in a HorizontalFieldManager (HORIZONTAL_SCROLL) (all this inside your MyLabelAndEditField) and limit the Manager rather than the field itself. Then your customer will be able to scroll through the left field and right.
In order to limit your HorizontalFieldManager, give him the width that you want in pixels (add that, as a parameter to the constructor of your MyLabelAndEditField) and substitute his sublayout like this:
HorizontalFieldManager textMgr = new HorizontalFieldManager(Manager.HORIZONTAL_SCROLL | Manager.HORIZONTAL_SCROLLBAR) { protected void sublayout(int maxWidth, int maxHeight) { int myWidth = Math.min(_desiredWidth, maxWidth); super.sublayout(myWidth, maxHeight); } };Thanks to his style HORIZONTAL_SCROLL, the infield will be almost infinite width, so the EditField inside fortunately "will display" all his characters.
Then, when you design your MyLabelAndEditField, give him a maximum pixel value. Say, you want three areas in a row. Take your Display.getWidth (), subtract the margins planned, divide by 3 and pass that value to each of these areas. Then add them to a HorizontalFieldManager (line2mgr in your example) and check the result.
You seem to be competent enough to easily integrate my illegible bubbles in your code - let us know the results.
-
ValueChangeListener for an inputText in a table - how to get that RANK the inputText is on?
We have a table with a variable number of rows. If someone types a user name in one of the lines, it calls a method (valuechangelistener) in our managed bean.
It's called getting at the right time, but how can you get which line the field is on?
For example, there are 4 rows and I am changing the username in the 3rd row, how could I get the 3rd rank so that I can do things for the first name and the name of this line (change their values)?
I tried to use the selected line, but then if I click on another row after finishing typing the username, it fills the first name and family name of the line I just clicked instead of the line that I just finished typing in.

Help would be GREATLY appreciated!
Thank you!
I was able to use the dcIteratorBinding.getCurrentRow to get the line was the inputText-seems to work.
Links DCBindingContainer is BindingContext.getCurrent () .getCurrentBindingsEntry () (DCBindingContainer);.
DCIteratorBinding dcIteratorBinding = (IteratorId) bindings.findIteratorBinding;
Line currRow = dcIteratorBinding.getCurrentRow ();
If (currRow! = null) {}
currRow.setAttribute (fnameAttr, fname);
currRow.setAttribute (lnameAttr, lname);
}
-
Property of hierarchy DRM: EPMA. SharedDimension - how to get it filled with the values?
We have a hierarchy of DRM, we want to push to a Dimension of sharing EPMA. In DRM, selecting the hierarchy and by changing the 'Dimension' shared property, the drop-down list box previously had values in there (some have been our shared Dimensions EPMA, but several us not the Shared Dimensions) but no longer has any selectable values. How do we get DRM to sort the list of the Shared Dimensions of our EPMA instance in the drop-down list of properties shared Dimension?
Hello
I could be wrong completely here, but that's what I discovered trying to look for EPMA. Property of SharedDimension.
This property gives me drop-down list without having to do anything and the drop down menu is the list of groups available in hierarchy, but if I'm putting some values manually in the definition of ownership--> the list of values is not showing me all the values (list of groups of hierarchies and not the value created manually) in the drop-down list.
I think that this property will not take a different list than list of group hierarchy as the Data Type defined for that property in the model of the APP is "Group of the hierarchy". Once again this property is used in the export "EPMA. E.M.P. architect Shared Library"to penetrate the hierarchies EPMA Shared Library.
Then you can try to see if all values are entered in the definition of the property--> list and try to delete it OR to check if the required groups in the hierarchy are created in consequence.
Let me know if it helps
Thank you
TFDC
-
Restart rank comes not correct based on column group
Hello PL/SQL gurus and experts.
I use Oracle Database 11 g Enterprise Edition Release 11.2.0.1.0 - 64-bit Production version
I have table-drop table t2; create table t2(Hospital,Test_Range,Total) as select 'Batra','> 10 Mph','20000' from dual union all select 'Fortis','1-3 Mph','24500' from dual union all select 'Max','5-10 Mph','10600' from dual union all select 'Columbia','< 1 Mph','27700' from dual union all select 'Nimhans','< 1 Mph','50000' from dual union all select 'Meenam','< 1 Mph','11000' from dual union all select 'Meeran','5-10 Mph','24625' from dual union all select 'Mnagamani','> 10 Mph','12000' from dual union all select 'Murari','> 10 Mph','20600' from dual union all select 'Triveni','5-10 Mph','16500' from dual union all select 'Batra','5-10 Mph','14700' from dual union all select 'Max','< 1 Mph','170000' from dual union all select 'Apollo Medical Centre','> 10 Mph','19000' from dual union all select 'MLal','1-3 Mph','22600' from dual union all select 'Columbia','< 1 Mph','28900' from dual union all select 'Asian','1-3 Mph','27900' from dual union all select 'A.G.M.','< 1 Mph','22700' from dual union all select 'Aashiana','5-10 Mph','23450' from dual union all select 'Amar Hospital','1-3 Mph','21325' from dual union all select 'Childs Trust','5-10 Mph','22775' from dual union all select 'Crescent ','< 1 Mph','20025' from dual;
I use the following DML-
select Test_Range "Test_Range", SUM (Total) "Total", decode(grouping(Hospital), 0, Hospital, 'Total') "Hospital", decode(grouping(Hospital), 0, max(rank), null) Rank from ( SELECT Hospital, Test_Range, SUM (Total) Total, DENSE_RANK () OVER (PARTITION BY test_range || Hospital ORDER BY SUM (Total) DESC) AS RANK, ROW_NUMBER () OVER (PARTITION BY test_range || Hospital ORDER BY SUM (Total) DESC) AS rk FROM t2 GROUP BY Hospital, Test_Range ) group by grouping sets((Hospital, Test_Range),()) order by Test_Range, Rank;
Get the following output-
Test_Ran Total Hospital RANK -------- ---------- --------------------- ---------- 1-3 Mph 24500 Fortis 1 1-3 Mph 21325 Amar Hospital 1 1-3 Mph 22600 MLal 1 1-3 Mph 27900 Asian 1 5-10 Mph 14700 Batra 1 5-10 Mph 22775 Childs Trust 1 5-10 Mph 10600 Max 1 5-10 Mph 23450 Aashiana 1 5-10 Mph 16500 Triveni 1 5-10 Mph 24625 Meeran 1 < 1 Mph 20025 Crescent 1 Test_Ran Total Hospital RANK -------- ---------- --------------------- ---------- < 1 Mph 50000 Nimhans 1 < 1 Mph 56600 Columbia 1 < 1 Mph 11000 Meenam 1 < 1 Mph 170000 Max 1 < 1 Mph 22700 A.G.M. 1 > 10 Mph 12000 Mnagamani 1 > 10 Mph 20000 Batra 1 > 10 Mph 20600 Murari 1 > 10 Mph 19000 Apollo Medical Centre 1 610900 Total 21 rows selected.
While I am looking for following output-
Test_Ran Total Hospital RANK -------- ---------- --------------------- ---------- 1-3 Mph 27900 Asian 1 1-3 Mph 24500 Fortis 2 1-3 Mph 22600 MLal 3 1-3 Mph 21325 Amar Hospital 4 5-10 Mph 24625 Meeran 1 5-10 Mph 23450 Aashiana 2 5-10 Mph 22775 Childs Trust 3 5-10 Mph 16500 Triveni 4 5-10 Mph 14700 Batra 5 5-10 Mph 10600 Max 6 < 1 Mph 170000 Max 1 < 1 Mph 56600 Columbia 2 < 1 Mph 50000 Nimhans 3 Test_Ran Total Hospital RANK -------- ---------- --------------------- ---------- < 1 Mph 22700 A.G.M. 4 < 1 Mph 20025 Crescent 5 < 1 Mph 11000 Meenam 6 > 10 Mph 20600 Murari 1 > 10 Mph 20000 Batra 2 > 10 Mph 19000 Apollo Medical Centre 3 > 10 Mph 12000 Mnagamani 4 610900 Total 21 rows selected.
Kindly help me and thanks in advance for your time, effort and assistance
Hello
If you want a separate set of numbers (1, 2, 3,...) for each value of test_range, without seeking to hold account of the hospital, then the PARTITON OF only test_range, not to mention the hospital.



Maybe you are looking for
-
On the presentation of the petition, Firefox told me that the Mozilla cerificate also failed because it is obsolete.Other sites have the same problem, although all are trusted sites.
-
Operation of a desktop Mac via OS X El Capitan 10.11.2. External hard drive is a Western Digital My Book. I get the message "the backup failed. Time Machine could not back up, "Joe My BookBU." "This message appears on my desktop. When you open Syste
-
HP 15 - ac042TU: cannot use wi - fi
I am unabe to use WiFi on my laptop. The drivers on the HP site are Realtek, but they are not compatible with my network cards. I tried to install the broadcom driver from the website of HP, but installation abandoned with error message: cannot updat
-
The controls/Officejet Pro Office lost more than 8600
I lost the ability to contol my printer in my office. Until recently, when I clicked on my HP printer shortcut window opens with my controls, including the Device Manager button. Now that the button has disappeared and the only the options that remai
-
Windows 7 Upgrade failed, restore failed, system unusable
I tried an upgrade to windows 7 Home premium to vist ahome premium, I ran the Upgrade Advisor, downloaded the upgrade files and follow-up of all prompts. In the final stages of installation the installation failed, and then the software tried to rein