Helps the understanding of regular Expressions
Hello people,I need help to understand Regular Expressions.
-- This returns the Expected string from the Source String. ", Redwood Shores,"
SELECT
REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',
',[^,]+,', 1, 1) "REGEXPR_SUBSTR"
FROM DUAL;
REGEXPR_SUBSTR
-------------------------------
, Redwood Shores,
However, when the query is changed to find the Second Occurrence of the Pattern, it does not match any. IMV, it should return ", CA,"
SELECT
REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',
',[^,]+,', 1, *2*) "REGEXPR_SUBSTR"
FROM DUAL;
REGEXPR_SUBSTR
-------------------------------
NULLI did research on this forum and found the link on the thread "https://forums.oracle.com/forums/thread.jspa?threadID=2400143" for the basic tutorials.
Kind regards
P.
The reason is that the comma between 'Redwood Shores' and 'CA' already represents the first occurrence.
So it can not match the second occurrence at the same time.
You can replace to (remove the trailing ',' in the regex):
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 1) REGEXPR_SUBSTR FROM DUAL;
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 2) REGEXPR_SUBSTR FROM DUAL;
Published by: hm on 14.06.2012 00:52
When you remove also the leading comma you get to the BlueShadows solution.
Tags: Database
Similar Questions
-
Help... Regular expression for characters [special] /: ^ & * () @# $
Regular expression to parse the string in square brackets:
I am trying to parse a string in square brackets, but as [] are special characters used in regular expressions to start a character class, I want to remove its special meaning. This regular expression **_user=[a-zA-Z]*@[a-zA-Z]{2}+.abc.com_** works for the analysis of [email protected]* but I want to analyze _user = [[email protected]] _ *, I use the term regular *user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\]*_* but is in error because it makes special sense of character class. I tried to use \ backslash before *------[]] * but it not working giving error * "INVALID ESCAPE SEQUENCE."
[JAVA CODE: user = "user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\"];
Pat pattern is Pattern.compile (user);.
Carpet to match = pat.matcher ("2011-03-11 02:08:44, 653: User = [[email protected]], Doing report: account.server.regprocmemunix.daily");
If (mat.find ()) {}
User1 = mat.group ();
}
This room code gives error _ _ "SEQUENCE EXHAUST" INVALID and throw a PatternSyntaxException*.
Please help me parse the string within large brackets [].You realize that, although ' [' is a special character in a regular expression, ' \' is a special character in Java, right?] You also need to escape to the ' \'.
So, if you want to use ' [' in your regular expression, you must use something in the sense of]
\\[Published by: almightywiz on April 25, 2011 14:05
DOH... too slow...
-
Need help with a simple regular expression replacement
Hello everyone,
He comes to the table that I have to work with.
My select statement isCREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (129,'Kirby Hotel','25A Aitken Street Wellington','Wellington','04 918 8513','[email protected]','Deahdoow Maharg','A',null,null,'LEAN',to_date('14/02/13','DD/MM/RR'),'027 356 4333'); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (167,'Avenue ee','10 Wellington Street Wellington','Wellington','4444444','[email protected]','James','A',null,null,'LEAN',to_date('21/02/13','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (185,'Quadrant Hotel','10 Waterloo Quadrant, Auckland','Auckland','9555555','[email protected]','Quentin QQ','A',null,null,'LEAN',to_date('04/03/13','DD/MM/RR'),null);
I have to use the function replace twice. One is to replace the Chr (13) a comma is second band a comma where there are two commas.SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_ID
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.
Thanks in advance
AnnHi, Ann.
Ann586341 wrote:
Hello everyone,He comes to the table that I have to work with.
CREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); ...Thanks for posting the sample data. You post the results, but the validation of the existing query which I suppose, produced good results. I can't run this query, because it requires the ijs_seminar table and a connection variable that also has no post, but I can just comment on the join and the WHERE clause.
Is this really the best set of sample data for this question? This problem involves Chr (13) and repeated commas, but I don't see any s CHR (13) or repeated commas in the sample data. In addition, it seems that there are a lot of columns that play no role in this issue and just to make things difficult to read.
My select statement is
SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_IDI have to use the function replace twice. We need to replace the Chr (13) by a comma,.
As posted, inside REPLACE replaces Chr (13) with a comma and a space which could be important if you then pick up consecutive commas.
second is the band a comma where there are two commas.
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.Assuming you want to replace Chr (13) with just a comma, then an equivalent would be:
SELECT acc.hotel_name || '(' || REGEXP_REPLACE ( acc.address , '[,' || CHR (13) || ']{1,2}' , ',' ) || ')' AS h FROM tbl_accommodation acc INNER JOIN ijs_seminar s ON acc.accommodation_id = s.accommodation_id WHERE s.seminar_id = :P27_SEMINAR_ID ;In the argument to REGEXP_REPLACE 2nd
[xy]{1,2}medium 1 to 2 characters of set of x and y. This could be
x or
there or it could be 2 characters
XY or the other way
YX or it could be the same characters 2
XX or
YYREGEXP_REPLACE is slower that REPLACE. Even if your original expression is longer, it may be more effective. (Performance may be not a problem in this case.)
-
problem with the validation type: regular expression
Hi all
I have a text field element call p40_opt
in the past, this element could accept only the values 1-9
I made a posting type: regular expression
1 validation expression:
p40_opt
2 validation expression:
[1-9]
works very well.
Today, I wanted to add an option that p40_opt can also contains the value: 10
so I changed the range [1-10].
and now, it's not good because if I choose another option plus 1 and 10 to Ant
he do the validation.
what I'm missing here?
Thanks in advance
Under the direction of: naama on August 6, 2009 01:31The forum software has mutilated regular expressions in your message. You should edit, wrapping up the regular expressions in.
tags so they are properly displayed.^ [1-9] {1} $. ^ $ 10
would be one regular expression that performs the required validation, however a regular expression doesn't appear to be the most straightforward way to validate such a range of values. A SQL or PL/SQL validation would be clearer, using the expression:: p40_opt between 1 and 10
-
Placement of carat in the list of regular expressions
I wanted to know what is the difference between placing the carat before a parentheses surrounding a search template and placing the cara immediately followed
for example
SELECT ADDRESS2,
REGEXP_REPLACE (ADDRESS2,
"(^[[: alpha:]] +), ([[: alpha:]] {2}) ([[: digit:]] {5})',
"\3 \2-"\1 "") THE_STRING "
OF ORDER_ADDRESSES
and
CHECK)
REGEXP_LIKE (EMAIL1,
'^([[: alnum:]] +) @[[: alnum:]] +. (com: net: org: edu | gov | mil) $'
)
)
the first example implies only [[: alpha:]] + is the first string in the following sets of strings
While the second implies that
([[: alnum:]] +) @[[: alnum:]] +. (com | net | org: edu | gov | mil) is the channel between ^ and $
Thank you
Hello
2776946 wrote:
I wanted to know what is the difference between placing the carat before a parentheses surrounding a search template and placing the cara immediately followed
for example
SELECT ADDRESS2,
REGEXP_REPLACE (ADDRESS2,
"(^[[: alpha:]] +), ([[: alpha:]] {2}) ([[: digit:]] {5})',
"\3 \2-"\1 "") THE_STRING "
OF ORDER_ADDRESSES
and
CHECK)
REGEXP_LIKE (EMAIL1,
'^([[ : alnum :]] +) @[[ : alnum :]] +. (com: net: org: edu | gov | mil) $'
)
)
the first example involves that [[: alpha:]] + is the first string in the following sets of strings
While the second implies that
([[: alnum:]] +) @[[: alnum:]] +. (com | net | org: edu | gov | mil) is the channel between ^ and $
Thank you
In both cases, ^ means the beginning of the string.
In example 1, using REGEXP_REPLACE, \1 is defined as a group of characters 1 or more alphabetic come immediately at the beginning of the string. The parentheses do not affect the meaning of ^.
In example 2, the CHECK constraint, the model
([[: alnum:]] +) @[[: alnum:]] +. (com: net: org: edu | gov | mil)
must also appear at the beginning of the string; That's what the ^ before that means. The $ after that model means that the end of the string is to be held just after the model, too.
-
Help with the Regular Expressions and regexp_replace
Oh great guru Oracle can I can receive assistance
I need to clean the phone numbers that have been entered in the table per_phones of Oracle e-Business. Some of the phone numbers have hyphens, some have spaces and some have tank. I just want to get out all the figures and then re - format the number.
E.g.
914-123-1234... out (914) 123-1234
9141231234... new (914) 123-1234
914 123 1234... (914) 123-1234
MyPhone... just null
(914)-123-1234... (914) 123-1234
I really tried to understand the instructions of regular expressions, but for some reason, I can't understand it.For example:
SQL> with sample_data as ( 2 select '914-123-1234' phone_number from dual union all 3 select '9141231234' from dual union all 4 select '914 123 1234' from dual union all 5 select '(914)-123-1234' from dual 6 ) 7 select regexp_replace( 8 regexp_replace(phone_number, '\D') 9 , '(...)(...)(....)' 10 , '(\1) \2-\3' 11 ) as formatted_num 12 from sample_data 13 ; FORMATTED_NUM -------------------------------------------------------------------------------- (914) 123-1234 (914) 123-1234 (914) 123-1234 (914) 123-1234 -
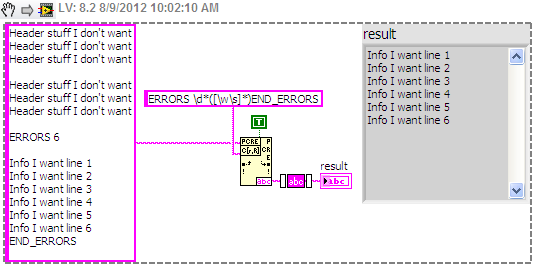
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
regular expression for the xml tags
Dear smart people of the labview world.
I have a question about how to match the names of xml text elements.
The image that I have some xml, for example:
Peter 13 and I want to match all of the names of elements, that is to say: no, son, grandson, age, regardless of any attribute have these items. There is a regular expression, I can loop, that can do this? (Something like "\<.+\> ". "") It is no good because it matches the entire xml string.) I'd really only two different expressions, one for the match start elements, e.g.
and one for the correspondence of the elements, for example. Thanks for your help in advance!
Paul.
The site Of regular Expressions will be very convenient.
They have some good tutorials on regexp with a demo of the XML tags:
Here is a small excerpt:
The regular expression <\i\c*\s*>matches an opening of the XML without the attributes tag corresponds to a closing tag. <\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*\s*>corresponds to an opening with a number any attributes. Put all together, <(\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*| i\c*)\s*="">corresponds to an opening with attributes or a closing tag. (source)
If you want advanced XML analysis I suggest JKI XML toolkit.
Tone
-
Regular expression to remove the space in the HTML tag
Hi all
My HTML string is as below.
Select ' < CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > ' double Str Output desired is
< CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > I want to remove these spaces of the tag value box with only spaces otherwise leave it as what. Please help to implement the same using regular expressions.
Hello
We don't know what you want. This site seems to be formatting your message in a weird way.
As the statement
SELECT «...» "THE DOUBLE;
without formatting, to show your entry and after the exact output desired friom as, with as little in shape as possible. It might be useful if you use some character like ~ instead of spaces (just for viewing; we will find a solution that works for spaces).
To remove the text which consists of spaces and nothing else between the tags, you can say
REGEXP_REPLACE (str
, '> +<>
, '><>
)
How is this string generated? Maybe there is an easier and more effective way to keep the bad wrtings sub off the chain in the first place.
-
Find and replace - regular expression to help?
How can I find ' <!-* PAGE footer AREA *-> "and replace it and evething after with my new coding of footer on all my pages.
The problem is:
The code in my existing page footer area is not the same on all pages.
I want to replace it with a new one on all pages
I watch the operators of regular expressions, not found patern that works...
Thanks in advence for your help
The following regular expression is the and everything up, but not including the closing tag:
[\s\S]+(?=<\/body>)
Use it in the search field and put the comment and the code to the footer in the field replace. Select use regular expression.
Always make a backup before using a regular expression on many pages.
-
Analyze the Mac address with the regular expression matching
Hello world
I have a problem with the function of regular expression matching,
I try to analyse the response both a query arp - a 192.168.0.15 to retrieve the MAC address of the remote IP address, I used the following regular expression: ^ ([0-9a-fA-F]{2}[:-]){5}([0-9a-fA-F]{2})$
I wonder why should I do a subset of the first string to extract only the part of the MAC address. The regular Expression function is not able to recognize the regular expression directly in the middle of a string?
I only works when I extracted the subset of tring right as in the picture below.
Thanks for your replies.
Get rid of the "^" at the beginning of your regular expression. You are ordering him to find the model at the beginning of the string.
-
Grouping and backreferences with regular expressions on the window to replace the text
I'm really appreciate the inclusion of regular Expressions in the search and replace functionality. One thing miss me that East of backreferences in the replacement expression. For example, in unix tools vi or sed, I could do something like this:
that allow me to switch the places of first and secondPart and substitute totally thirdPart. If grouping and backreferences are already present in the window replace text, how do you properly call them?s/\(firstPart\) \(secondPart\) \(oldThirdPart\)/\2 \1 newThirdPart/g
Published by: Justin.Warwick on August 23, 2011 08:26You can vote on the request for this to the exchange of SQL Developer, to add weight to the implementation as soon as possible: https://apex.oracle.com/pls/apex/f?p=43135:7:3693861354483465:NO:RP, 7:P7_ID:16761
Kind regards
K. -
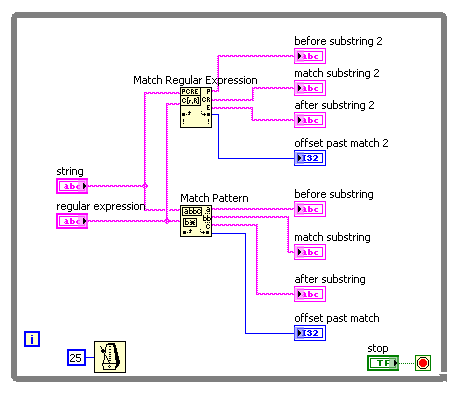
"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
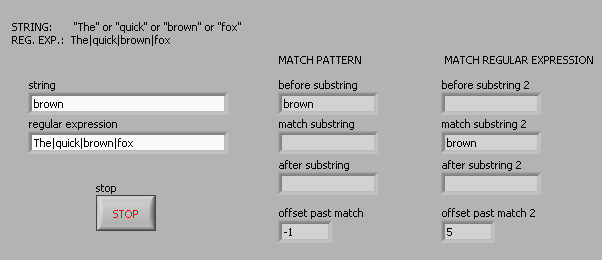
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
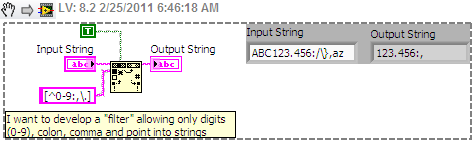
Allow specific characters - Regular Expression
Hello everyone
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
-
Validation of attribute text WITHOUT using regular expressions
Hello world
I'm working on a few validation rules for a text attribute and one of the conditions is that the text string can contain only alphanumeric characters.
Because of the requirements that I can't use a regular expression here (the output should be a Boolean value confirming if the text is valid or not), so I need to find a way to write this in the rules...
Yes, is there an easier way of writing this rule that the use of the ' Contains (< text >, < substring >)' function? Like this:

[Etc. for all the non alpha numeric characters]
If not, is it possible to write a rule that States that the text contains ONLY the following characters

[Etc for all alphanumberic characters]
Or is there some other function I could use it here?
Appreciate any thoughts or input about how this could be solved, thank you in advance for your help.
Unfortunately, regular expressions are the ideal solution for exactly the scenario you are exhibitor. The only alternative other than a broad 'or' statements is regular expressions, or write a custom function.


Maybe you are looking for
-
I need to find who sold the phone IMEI namely intermediate or where the store so I could unlock the operator because of international communication
-
Satellite P200-1EE: DVD player HD Toshiba "video output for external device cannot".
Need help! My P200-1EE won't play HD DVDs. At startup the HD DVD software with an HD DVD in the drive, the drive displays on the screen, and after a short time returns an error. The message is ' + Toshiba HD DVD Player - impossible to output the vide
-
Feeding through command line management
I am aware that GPEDIT. MCS opens Control Panel - but how (using the command line) is the possible PC to go into hibernation? This is a problem I need to find a solution to--to a network of about 800 PC and, of course - the alternative (manually visi
-
How to block an IP address with a WRVS4400N router?
I have kept an eye on my label of report IPS lately and have observed a large number of attacks ICMP_SMURF and BACK from the Chinese ip address. I know that I can probably block the ip criminalized through the ip acl tab according to the firewall se
-
I have problems when I want to send an email, I go to 'Tools' and click on 'Send the page in an email' and the email will appear, but when I hit send, the message above appears and it will not send the entire page. He told me to get a new digital ID