"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
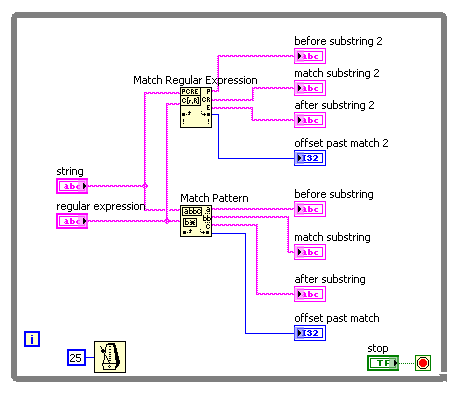
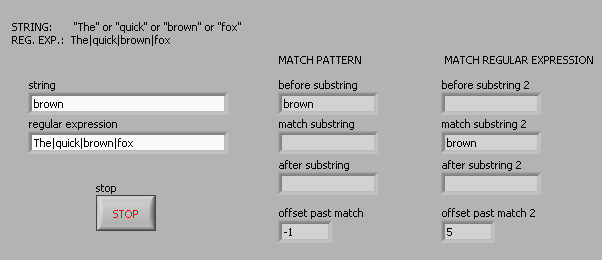
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!
Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
Tags: NI Software
Similar Questions
-
The Regular Expressions and GUID.
Hello gurus, I hope you can help me!
I need to select GUID from a table and to do this, I need the regular Expression. My
Perl is not good and not good Regular Expression. My database is Oralce 11.2.0.2.0 and
Linux (Oracle Version 6) is the operating system of the Machine. If you need further information,
I'll look closely. Thank you. Jehangir.>
Hi Jehangir and welcome to the forums.
I need to select the GUID of a table and to do this,
Well, the first thing we do is read the forum FAQ and also the post by BluShadow
at the top of the messages on the home page of the forum. You should have provided code (DDL
and DML) showing your particular problem, but since it's your first time, I'll be gentle ;)We have it done - clients have sometimes GUID as PKs, and we need to send data to
their systems, but it is not as simple as it may first appear.GUID may arise in three formats.
The Oracle one - SELECT Sys_GUID() from DUAL which is just a string of 32 hexadecimal characters.
Then the chain with the hyphen, then the string with dashes and {} at the beginning and end (see
examples of data).with datax as ( SELECT '79A864CCD8E44CD8B0A2765DF9EF337B' as guid FROM DUAL UNION ALL SELECT '79A864CFD8E44CD7B0A2765DF9EF337B' FROM DUAL UNION ALL SELECT '8gdfsgsgfdg' FROM DUAL UNION ALL -- dummy for testing SELECT '21EC2020-3AEA-1069-A2DD-08002B30309D' FROM DUAL UNION ALL SELECT '21EC5550-3AEA-1069-A2FF-08002B30309D' FROM DUAL UNION All SELECT '{21CC2020-3AFA-1A69-A2DD-08002B30309D}' FROM DUAL ) -- first one is the Oracle format select * from datax where regexp_like(guid, '[0-9a-fA-F]{32}'); -- Oracle select sys_guid(); -- second one is with hyphens select * from datax where regexp_like(guid, '[0-9a-fA-F]{8}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{12}'); -- third one is with hyphens and curly brackets. select * from datax where regexp_like(guid, '^\{[0-9a-fA-F]{8}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{4}\-[0-9a-fA-F]{12}\}$'); -- This converts both of the last two formats back into Oracle format, which is what -- we use. Notice, that I haven't used regualar expressions to do this. Regexes are -- computationally expensive, and you should use Oracle's string furnctions if possible SELECT REPLACE(REPLACE(REPLACE(GUID, '{', ''), '}', ''), '-', '') FROM Datax;HTH,
Paul...
Jehangir.
-
Help with the Regular Expressions and regexp_replace
Oh great guru Oracle can I can receive assistance
I need to clean the phone numbers that have been entered in the table per_phones of Oracle e-Business. Some of the phone numbers have hyphens, some have spaces and some have tank. I just want to get out all the figures and then re - format the number.
E.g.
914-123-1234... out (914) 123-1234
9141231234... new (914) 123-1234
914 123 1234... (914) 123-1234
MyPhone... just null
(914)-123-1234... (914) 123-1234
I really tried to understand the instructions of regular expressions, but for some reason, I can't understand it.For example:
SQL> with sample_data as ( 2 select '914-123-1234' phone_number from dual union all 3 select '9141231234' from dual union all 4 select '914 123 1234' from dual union all 5 select '(914)-123-1234' from dual 6 ) 7 select regexp_replace( 8 regexp_replace(phone_number, '\D') 9 , '(...)(...)(....)' 10 , '(\1) \2-\3' 11 ) as formatted_num 12 from sample_data 13 ; FORMATTED_NUM -------------------------------------------------------------------------------- (914) 123-1234 (914) 123-1234 (914) 123-1234 (914) 123-1234 -
Number of shaped with preg_replace Regular Expression and PHP
Hello
I would like to add a 'dash' after every 3 digits in a given number (10 digits). For example, 9785678941 became 978-567-894-1. How could I achieve this with regular expression using PHP preg_replace?
Thank you.
The next solution is based on the example of "The use of backreferences followed literals digital" published on the php.net site.
In accordance with the $string, $pattern, $replacement nomenclature which is the php.net example use, here´s my modification:
<>
$string = '9785678941';
$pattern = ' / (\\d{3})(\\d{3})(\\d{3})(\\d{1)} /';
$replacement = ' ${1}-{2}-${3}-${4}';
echo preg_replace ($pattern, $replacement, $string);
?>
-
Regular expressions and phone number
Hello
There is a column 'Phone_number Varchar2'
Data containing:
123 89556-6852
-857 (123) - 965
123-5846 5648
I want to display that
123895566852
123857965
12358465648
Pls help by regular Expressions.
Published by: Guillaume on February 17, 2010 15:59with t as ( select '123-89556-6852' phone_no from dual union all select '(123)-857-965' from dual union all select '123-(5846)5648' from dual ) select regexp_replace(phone_no,'[^[:digit:]]') phone_no from t -
Expressions and model matchers
I want to parse a string using reg expressions, but I want to clarify a string from end of string - all characters - start. I want him to stop the first time he finds the end string not the last time that he finds it.
Here is my code
Public Shared Sub main (String [] args) {}
String text = "" an it's first group b an it's second group b b xxxxxxx ";"
String oldHeader2 = "a.*b"; I want the search to stop after the first b
Pattern pattern = Pattern.compile (oldHeader2);
Matcher Matcher = pattern.matcher (text);
While (matcher.find ()) {}
System.out.println("---");
Get the corresponding string
Matching strings = matcher.group ();
System.out.println (match);
}
My output is as follows
----
a this is the first group b an it's second group b b xxxxxxx
I need to go out like that
----
a this is the first group b
----
a this is the second group bcjgoode wrote:
I want to parse a string using reg expressions, but I want to clarify a string from end of string - all characters - start. I want him to stop the first time he finds the end string not the last time that he finds it.public static void main(String[] args) { String text = " a this is the first group b a this is the second group b xxxxxxx b"; String oldHeader2 = "a.*b"; // I want the search to stop after the first b Pattern pattern = Pattern.compile(oldHeader2 ); Matcher matcher = pattern.matcher(text); while (matcher.find()) { System.out.println("----"); // Get the matching string String match = matcher.group(); System.out.println(match); } }You use a greedy quantifier, but you want a reluctant quantifier.
http://download.Oracle.com/javase/6/docs/API/Java/util/regex/pattern.html#sum -
Need help on the regular expressions and query
Hi guru s, I hope that you all made great!
I have a scenario where I need to insert data into the table.
I have three scenarios:
What I want is now.select 'Kodali,Raj,S' str from dual union select 'Alex Romano' from dual union select 'ppppp' from dual Alex Romano Kodali,Raj,S ppppp
1 Alex Romano
is there space between the chain and then I want to insert in the last name and first name columns
2 Xavier, Raj, S
If there is a comma between the chain and I want to insert in the last name, first name and middle name
3. If there is one channel then insert even in first name and last name.
I wrote the request more early to manage only by commas and now I'm trying but not able to use this all scenarios
Can you please help me.
Currently I put a b and c if its null value.WITH t AS ( select 'Kodali,Raj,S' str from dual union select 'Alex Romano' from dual union select 'ppppp' from dual ) select DECODE(trim(a),NULL,'a',trim(a)),DECODE(trim(b),NULL,'b',trim(b)),decode(trim(c),NULL,'c' ,trim(c)) from ( SELECT max(decode(level,1,regexp_substr(str,'[^,]+',1,level))) a --INTO lFNAME , max(decode(level,2,regexp_substr(str,'[^,]+',1,level))) b --INTO lLNAME , max(decode(level,3,regexp_substr(str,'[^,]+',1,level))) c --INTO lMNAME FROM t CONNECT BY regexp_substr(str,'[^,]+',1,level) IS NOT NULL GROUP BY str ) ;
Thanks in advance!Hello
You can do what you asked for in pure SQL like this:WITH got_pos AS ( SELECT str , INSTR (str, ',') AS comma_pos , INSTR (str, ' ') AS space_pos FROM t ) SELECT str , CASE WHEN comma_pos > 0 THEN REGEXP_SUBSTR (str, '\w+', 1, 2) WHEN space_pos > 0 THEN SUBSTR (str, 1, space_pos - 1) ELSE str END AS fname , CASE WHEN comma_pos > 0 THEN REGEXP_SUBSTR (str, '\w+', 1, 3) ELSE TRIM (REGEXP_SUBSTR (str, ' \w+ ')) END AS mname , CASE WHEN comma_pos > 0 THEN SUBSTR (str, 1, comma_pos - 1) ELSE REGEXP_SUBSTR (str, '\w+$') END AS lname FROM got_pos ORDER BY str ;But look how it is difficult, even for this simple example of data.
I suggest you write a PL/SQL function to analyze the name. It will be much easier to deal with a combination of spaces and commas, the names of more than 3 words, etc.
-
FPGA Express PID vs Custom PID behaves differently? Whats is wrong
Hi all
I try to use labview FPGA Express VI in my application with cRIO 9022. I write a custom PID and compare the result with the FPGA palette express PID.
It seems that the integral action on the express PID is too large.
I am using PID as a simple Integrator providing zero gain proportional and derivative and Ki = 1. Which provides a signal error of 0.1 and sampling time of 1/5000, after 10 sec, the Integrator must accumulate 1. As usual, we he reach apprx. 10 sec, the express VI increases quickly until saturation.
What is the problem with my VI, I'm sure I'm missing something. The reason why I want to express is that it consumes less space and I have to use 5 parallel PID which I just can't get with a custom because it is written not effectively. I attached the VI and the png for your view.
Thank you all,.
Some.
Well, the ZIP file is valid, but I'm on an older version of LabVIEW, so I can not even open your screws, sorry.
I would check your math. Aid for the VI Express FPGA is clear on the functioning of the calculation. It does not count the sample time - which is one of the reasons that gains are standard. Configured the way you need your code, the error integrated - and therefore the output - increase 0.1 for each iteration of the loop, regardless of the rate of loop - so it will take 100 iterations for output reach 10. You can set your full winnings to take account of the actual loop cycle time.
-
Use matching of regular expressions to search for parentheses
Hi all
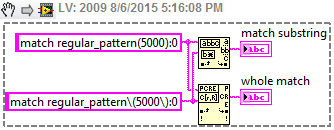
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Allow specific characters - Regular Expression
Hello everyone
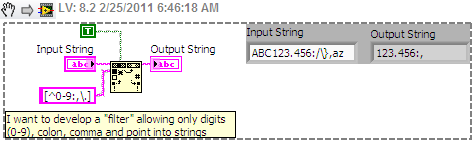
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
-
VALIDATION OF EMAIL USING REGULAR EXPRESSIONS
Hi all
I'm new to regular expressions and trying to learn about them.
As practice I am developing a query to filter identifying them invalid e-mail, for example: -.
Let's say that the name column is EMAIL_ID<some-name>.<some-name1>@gmail.com - VALID <some-name>_<some-name1>@gmail.com - VALID <some-name>@<some-name1>@gmail.com - INVALID
So I have the expression to validate the end of the e-mail as follows
But I don't know (it is even possible to wheter) to filter the third mail electronic idselect email from <table-name> where REGEXP_LIKE (EMAIL,'.com$')
provided that there * 2 @*.
Any help in this regard would be welcomeThis is what you need
select email fromwhere REGEXP_LIKE (EMAIL,'^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}$') SQL> WITH t1 AS (SELECT '[email protected]' email FROM DUAL 2 UNION 3 SELECT '[email protected]' email FROM DUAL 4 UNION 5 SELECT 'test3@[email protected]' email FROM DUAL) 6 SELECT email 7 FROM t1 8 WHERE REGEXP_LIKE (EMAIL, 9 '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}$'); EMAIL --------------------- [email protected] [email protected] SQL> -
Regular expression for Dreamweaver
I haven't had time to really become a professional when it comes to regular expressions, and unfortunately, I need one a conclusion it's hard wrap the head around.
In a text file, I have hundreds of cases as follows:
{Click here to visit my website} {} fromhttp://www.adobe.com/
I need a regular expression for Dreamweaver that I can run in the window 'Search and replace' to switch the order of the above to:
{http://www.adobe.com/} {click here to visit my website}
Can someone provide some guidance? I'll be short due to my lack of experience with regular expressions.
Thank you in advance!
For Dreamweaver:
{([{([Search: {([^)}] *)} {([^)}] *)}
Replace: {$2} {$1}
-
Mask a number with regular expressions
Hi @ll!
Is it possible to hide a given number
of "12345678" in "XXXX5678".
or '987458' to 'XX7458 '.
with Regular Expressions and without substr()? To display only the last four digits and the 'X' value for the rest. The size of the number is not always the same.Alex, I think the OP wanted the first 4 characters to hide ;)
Something like that?
select translate(substr('12345678',1,length('12345678')-4),'1234567890','XXXXXXXXXX') || substr('12345678',length('12345678')-3) from dual / TRANSLAT -------- XXXX5678More
with test_data as ( select '12345678' card_no from dual union all select '123456' from dual union all select '5678900' from dual ) -- End of test data select translate(substr(card_no,1,length(card_no)-4),'1234567890','XXXXXXXXXX') || substr(card_no,length(card_no)-3) from test_data / TRANSLATE(SUBSTR ---------------- XXXX5678 XX3456 XXX8900Arun-
-
Using regular expressions to solve sys_refcursor of a record
Regarding my Question about sys_refcursor with record type of thread, I thought it can be solved differently. It is:
I have a string like ' 8:1706, 1194, 1817 ~ 1:1217, 1613, 1215, 1250'
I need to do a few things using regular expressions and get something like
Is it possible by using regular expressions in a single select statement?select * from <table> where c1 in (8,1) and c2 in (1706,1194,1817,1217,1613,1215,1250);Hello
Game 6' - 8 "wrote:
Your understanding is quite correct. But unfortunately it doesn't Frank.SQL> SELECT COUNT (*) 2 FROM (SELECT sp.* 3 FROM spml sp, spml_assignment spag 4 WHERE sp.spml_id = spag.spml_id 5 AND spag.class_of_svc_id = 8 6 AND spag.service_type_id IN (1706, 1194, 1817) 7 AND spag.carrier_id = 4445 8 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 9 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 10 AND spag.unit_id = 5 11 AND sales_org_id = 1 12 UNION ALL 13 SELECT sp.* 14 FROM spml sp, spml_assignment spag 15 WHERE sp.spml_id = spag.spml_id 16 AND spag.class_of_svc_id = 1 17 AND spag.service_type_id IN (1217, 1613, 1215, 1250) 18 AND spag.carrier_id = 4445 19 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 20 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 21 AND spag.unit_id = 5 22 AND sales_org_id = 1); COUNT(*) ---------- 88 SQL> SELECT COUNT (*) 2 FROM spml sp, spml_assignment spag 3 WHERE sp.spml_id = spag.spml_id 4 AND spag.carrier_id = 4445 5 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 6 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 7 AND spag.unit_id = 5 8 AND sales_org_id = 1 9 AND REGEXP_LIKE ('8:1706,1194,1817~1:1217,1613,1215,1250', 10 '(^|~)' || spag.class_of_svc_id || ':' 11 ) 12 AND REGEXP_LIKE ('8:1706,1194,1817~1:1217,1613,1215,1250', 13 '(:|,)' || spag.service_type_id || '(,|$)' 14 ); COUNT(*) ---------- 140 SQL>Published by: release 6' - 8 "August 11, 2009 20:04
Serving what you ordered!
Originally, you said that you are looking for something that produces the same result as
where c1 in (8, 1) and c2 in (1706, 1194, 1817, 1217, 1613, 1215, 1250)in other words, the c1s could be coupled with any of the c2s.
Now, it seems that what you want iswhere ( c1 = 8 and c2 IN (1706, 1194, 1817) ) or ( c1 = 1 and c2 IN (1217, 1613, 1215, 1250) )in other words, c1 = 8 and c2 = 1250 is not good; is not c1 = 1 and c2 = 1706.
In this case, try
WHERE REGEXP_LIKE ( s , '(^|~)' || c1 || ':([0-9]+,)*' || c2 || '(,|~|$)' ) -
Dear all,WITH table_example AS ( SELECT '*****I WANT THE MIDDLE VALUE ONLY****' AS col1 FROM DUAL ) SELECT REGEXP_REPLACE(col1, '\*\*\*\*\*I WANT THE ' ) FROM table_example ;
I'm trying to get my head around REGULAR expression and doing new things.
When it comes to string manipulation I usually use a combination of SUBSTRs obscrure to reach my goal, but this time I want to use a REGEX to do. :-)
My goal is to return the substring "MEANS" of the string * I WANT THE MIDDLE VALUE ONLY *' but I'm stuck.
I hope you can help!This?
SQL> WITH table_example AS 2 ( 3 SELECT '*****I WANT THE MIDDLE VALUE ONLY****' AS col1 4 FROM DUAL 5 ) 6 SELECT regexp_replace(REGEXP_REPLACE(col1,'\*\*\*\*\*I WANT THE '), ' VALUE ONLY\*\*\*\*') 7 FROM table_example 8 ; REGEXP ------ MIDDLE SQL>See you soon
Sarma.
Maybe you are looking for
-
Satellite A200 - 1 M 4 - unable to connect to the internet
Hello I have a series of Satellite A200 - 1 M 4.I tried to connect to a modem via an Ethernet cable. (usually when you connect to a desktop computer to a modem via an Ethernet cable directly detects the internet) I customized the network settings. Wh
-
In other words, the e-mail message remains in the Outbox and is NOT in the SENT ITEMS folder.
-
ROKU2 XD - do I need a router wireless wifi - without the computer
I just bought the ROKU2 XD need WiFi. Has NO WiFi. With 2 MACS, I prefer NOT to connect it to the floor to my LinkSYS WRT 54GS V7. MAC is wired. Not sure that the iMAC is wireless or wired this way. ROKU Watch w black screen / loud buzzing, but seem
-
Page Web Windows 7 Driver Update (SlimWare)
Hi guys, my PC recently did an update and since then, my Web page changes randomly to a SlimWare page for the Windows 7 driver updates. What is it and do I need? If this is not the case, how can I remove it? Thank you
-
Hello I see that the ease to add personalized messages and custom records has been added since JDE 4.6. Is there a way I can have the similar feature in JDE JDE 4.2 or 4.3. If we can reproduce the exact behavior so here's what I do: 1. when an e-mail