How take the sum of middle iteration last iteration?
Hello! PLS, can anyone help, I have six variables and you want to take the sum of each of the variables separately from the middle of the iteration to the last iteration (i.e. iteration 6 iteration 12). Attached are the vi file and data entry.
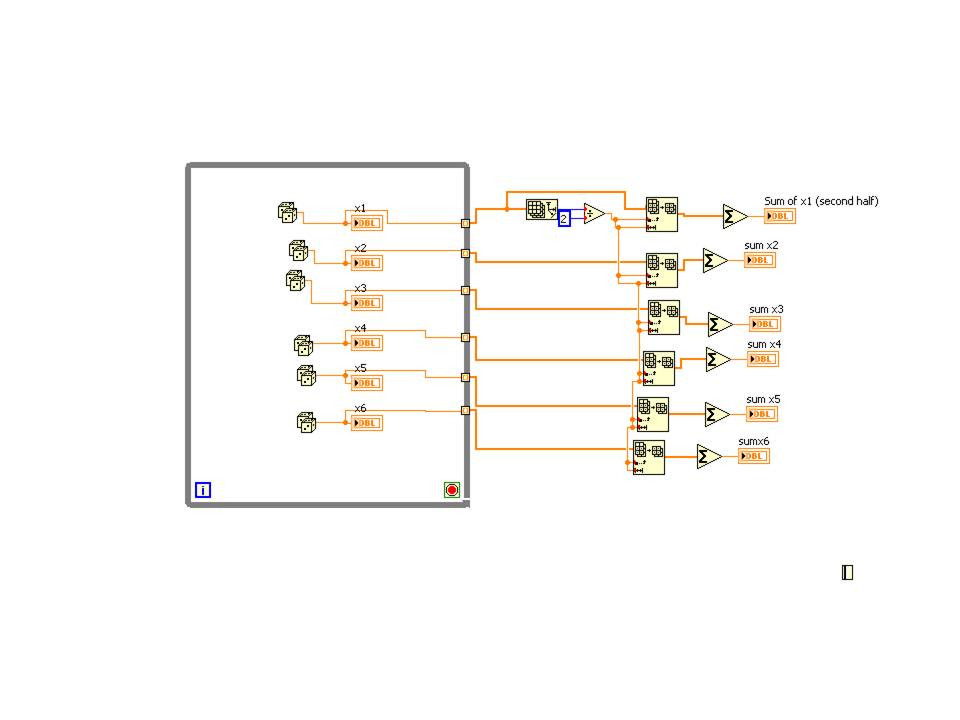
I won't mess with your design of control thingy... but here is the simple and direct way to the sum of the average in last interation. I use random numbers here, but you can enter your own values once you get out your straigthend formula.
Basically, it works like this: feed values into a tunnel of indexation. Which will make each set of values in an array whose length N where N is the number of iterations.
Find the array size and divide by 2. Remember that arrays start at index zero, so 12 iterations will give you 0,1,2,3,4,5,6,7,8,9,10,11.
You want the second half, so it's 6,7,8,9,10 and 11. Subset of the table to select 6 elements, starting with element 6... Then take the sum of table.
Tags: NI Software
Similar Questions
-
How to take the sum of a cluster
Hey Im trying to convert a matlab code in labview and I came across this issue with clusters. can anyone help?
Let's say that:
[Pxx, w] is periodogram (mydata, [], [], var]
Time = Sum(mydata.^2) /length (mydata)
FREQ = Sum (Pxx)
Pxx = Pxx * time/frequency
Pxx = sqrt (Pxx)
LogLog (w, Pxx)
I managed to make the PSD of mydata and translate code time labview...
But how to make the sum of the Pxx which is clearly going to be a cluster of 3 elements (magnitude, df, f0)... Help?
My point exactly! I therefore decided to unbundle the Psd with the sum of the elements of the array size. He then rebundle with f. and don't know if it will work DT...
-
How does the sum function in the element tag?
Hello!
I am new to XML Publisher and I need help to understand how my definition of data.
In my xml file, I have this piece of code
and now, I have problem with element with functions sum, because it returns like for example. 21356,15. all other components (COST, YTD_DEPRN, DEPRN_RESERVE, DEPRN_RESERVE_BY, NET_VALUE) return values such as 21356.15.<group name="G_ACCOUNT" source="Q_REGISTER"> <element name="COST_ACCOUNT" value="COST_ACCOUNT"/> <element name="ACC_DESC" value="ACC_DESC"/> <element name="YEAR" value="YEAR"/> <group name="G_COST" source="Q_REGISTER"> <element name="COST_CENTER" value="COST_CENTER"/> <group name="G_TAG_NUMBER" source="Q_REGISTER"> <element name="TAG_NUMBER" value="TAG_NUMBER"/> <element name="ASSET_NUMBER" value="ASSET_NUMBER"/> <element name="DESCRIPTION" value="DESCRIPTION"/> <element name="ASSET_ID" value="ASSET_ID"/> <element name="ASSET_NUMBER" value="ASSET_NUMBER"/> <element name="COST" value="COST" dataType="number"/> <element name="YTD_DEPRN" value="YTD_DEPRN" dataType="number"/> <element name="DEPRN_RESERVE" value="DEPRN_RESERVE" dataType="number"/> <element name="DEPRN_RESERVE_BY" value="DEPRN_RESERVE_BY" dataType="number"/> <element name="NET_VALUE" value="NET_VALUE" dataType="number"/> <element name="DPIS" value="DPIS"/> </group> <element name="SUM_ACCOUNT_COST" function="sum" dataType="number" value="G_TAG_NUMBER.COST"/> <element name="SUM_ACCOUNT_YTD_DEPRN" function="sum" dataType="number" value="G_TAG_NUMBER.YTD_DEPRN"/> <element name="SUM_ACCOUNT_DEPRN_RESERVE" function="sum" dataType="number" value="G_TAG_NUMBER.DEPRN_RESERVE"/> <element name="SUM_ACCOUNT_DEPRN_RESERVE_BY" function="sum" dataType="number" value="G_TAG_NUMBER.DEPRN_RESERVE_BY"/> <element name="SUM_ACCOUNT_NET_VALUE" function="sum" dataType="number" value="G_TAG_NUMBER.NET_VALUE"/> </group> </group>
Can you tell me why sum function does not return to the same value?
Kind regards
drama9346As I expected wrong since this isn't a RAW number his tent for formatting. You can change this value and format or just go for the sum of RTF, or the SUM of your SQL query.
Sum in RTF: for SUM_ACCOUNT_COST
I have given how you use grouping in this case, based on what you might change the code slightly.
Published by: amri on 9 April 2013 14:28
-
How get the sum of differences in time
I have the query to get the taken (duration) of time to perform each activity below
Select (select ep.name PE env_mapping where ep.id = p.bsa_env_id) environment,
(Select trunc ((Max (ps.actual_end) - Min (ps.actual_start)) * 24 * 60) of ps Highlevel_activity where ps.activity_ID = p.id and ps.out_of_window_flag =' no. "") Actual_duration,
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Apps Patching"and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Apps_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, Highlevel_activity ps where de.task_type = ' Patching DB/MT ' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') DB_MT_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Shut Down' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Shut_Down,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Start Up' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Start_Up,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Vérification' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = 'NO') audit.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Patching meadow' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Pre_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Patching Post' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Post_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Others' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = 'NO') others
activity p where
I get the output as below
EnV1 27 April 13 167 54 29 29 15 0 0 67 0
EnV2 may 3 13 10 20 05 05 0 0 50 0 33
My requirement is to get the amount for each column which I get on top of the query. How can I change the query above to get as the result below
EnV1 27 April 13 167 54 29 29 15 0 0 67 0
EnV2 may 3 13 10 20 05 05 0 0 50 0 33
177 74 34 34 15 50 67 33 total
Please help
Thank you
ArchanaHello
Agowda wrote:
I have the query to get the taken (duration) of time to perform each activity belowSelect (select ep.name PE env_mapping where ep.id = p.bsa_env_id) environment,
(Select trunc ((Max (ps.actual_end) - Min (ps.actual_start)) * 24 * 60) of ps Highlevel_activity where ps.activity_ID = p.id and ps.out_of_window_flag =' no. "") Actual_duration,
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Apps Patching"and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Apps_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, Highlevel_activity ps where de.task_type = ' Patching DB/MT ' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') DB_MT_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Shut Down' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Shut_Down,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Start Up' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Start_Up,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Vérification' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = 'NO') audit.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Patching meadow' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Pre_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Patching Post' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = ' NO') Post_Patching,.
(select nvl (trunc ((max (de.actual_end) - min (de.actual_start)) * 24 * 60), '0') Detail_activity time_taken, ps Highlevel_activity where de.task_type = 'Others' and ps.activity_id = p.id and.) Highlevel_activity_id = ps.id and ps. OUT_OF_WINDOW_FLAG = 'NO') othersactivity p where
If you make 9 of subqueries to get 9 different columns. It is very inefficient, and it is also difficult to maintain. If you need to change the conditions in subqueries, you will need to do the exact same change at 9 different locations.
It would be much more effective if you just add de.task_type to the GROUP BY clause and then rotates the results. He could not run 9 times faster, but it probably run 5 times faster.
See the FAQ forum {message identifier: = 9360005} to find out how.I get the output as below
EnV1 27 April 13 167 54 29 29 15 0 0 67 0
EnV2 may 3 13 10 20 05 05 0 0 50 0 33My requirement is to get the amount for each column which I get on top of the query. How can I change the query above to get as the result below
EnV1 27 April 13 167 54 29 29 15 0 0 67 0
EnV2 may 3 13 10 20 05 05 0 0 50 0 33
177 74 34 34 15 50 67 33 totalIt's a GROUPING DEFINED work, no ACCUMULATION.
Since you post CREATE TABLE and INSERT statemennts for your sample data, I will use the hr.departments table to show the difference.
When you GROUP BY N > 1 the expressions, ROLLUP gives you N + 1 levels of totals and subtotals. For example:SELECT department_id , job_id , SUM (salary) AS total_sal FROM hr.employees GROUP BY ROLLUP (department_id, job_id) ORDER BY department_id, job_id ;The above query GROUPs BY s expressions (department_id job_id) so ROLLUP produces 3 sorts of totals:
(1) total department_id and job_id (e.g. 13000 for department_id = 20 and job_id = "Fatyty" below)
(2) total Department, including all of the work (e.g. 6000 = 19000 13000 + for department_id = 20) and
(3) total general for the entire result (e.g. 691416)DEPARTMENT_ID JOB_ID TOTAL_SAL ------------- ---------- ---------- 10 AD_ASST 4400 10 4400 20 MK_MAN 13000 20 MK_REP 6000 20 19000 30 PU_CLERK 13900 30 PU_MAN 11000 30 24900 40 HR_REP 6500 40 6500 50 SH_CLERK 64300 50 ST_CLERK 55700 50 ST_MAN 36400 50 156400 60 IT_PROG 28800 60 28800 70 PR_REP 10000 70 10000 80 SA_MAN 61000 80 SA_REP 243500 80 304500 90 AD_PRES 24000 90 AD_VP 34000 90 58000 100 FI_ACCOUNT 39600 100 FI_MGR 12008 100 51608 110 AC_ACCOUNT 8300 110 AC_MGR 12008 110 20308 SA_REP 7000 7000 691416You don't want all that: you just want what corresponds in total for each department_id and job_id and total general, without any level of iintermediate. Here's how you can achieve these results using GROUPING SETS instead of ROLLUP:
SELECT department_id , job_id , SUM (salary) AS total_sal FROM hr.employees GROUP BY GROUPING SETS ( (department_id, job_id) , () ) ORDER BY department_id, job_id ;DEPARTMENT_ID JOB_ID TOTAL_SAL ------------- ---------- ---------- 10 AD_ASST 4400 20 MK_MAN 13000 20 MK_REP 6000 30 PU_CLERK 13900 30 PU_MAN 11000 40 HR_REP 6500 50 SH_CLERK 64300 50 ST_CLERK 55700 50 ST_MAN 36400 60 IT_PROG 28800 70 PR_REP 10000 80 SA_MAN 61000 80 SA_REP 243500 90 AD_PRES 24000 90 AD_VP 34000 100 FI_ACCOUNT 39600 100 FI_MGR 12008 110 AC_ACCOUNT 8300 110 AC_MGR 12008 SA_REP 7000 691416I hope that answers your question.
If this isn't the case, post CREATE TABLE and INSERT statements for some examples of data and the results desired from these data.
Simplify the problem. For example, instead of 9 different task_types, post sample data and results for 3 task_types. Simply mention that you actually 9, and we will find a solution that can be easily adapted for 9.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum {message identifier: = 9360002}Published by: Frank Kulash on May 27, 2013 10:47
-
How is the sum total of the column of this PivotTable?
Hi experts, I am trying to sum two columns, the column called 'Hombre' and the column named "Total."
Display a picture to explain better.
! http://img11.imageshack.us/img11/2240/caekg.PNG!
It's the pdf output:
! http://img38.imageshack.us/img38/4240/cae2.PNG!
I tried to write in the name columns "Hombre".
<? $c45 / / M0/M0/T? >
because the column name 'Mujer' I read this
<? $c45 / / M0/M1/T? >
I Don t know what means this code, $c45 I know it is the call to the variable
M0-M0-T, but I Don t understand it.
Thank youI understand your ignorance on how it works.
And use following in total, == Hombre == Mujerhttp://winrichman.blogspot.com/2009/10/sum-total-column-in-BIP-pivot-table.html
-
How do the sum of several columns with grouping different criteria
Currently I am doing a project where I needed to generate the report which retrieved from the table. the table as shown below
CURRENCY_A AMOUNT_A CURRENCY_B AMOUNT_B CURRENCY_C AMOUNT_C
USD 100 EURO 100 POUNDS 100
EURO 200 BOOKS 200 200 USD
BOOKS USD EURO 300 300 300
My expectations is the grand total of the Group (AMOUNT_A + AMOUNT_B + AMOUNT_C) currency
USD:
EURO:
BOOKS:
Is it possible to do this output in oracle alone?
Hello
UNPIVOT before consolidation / summary:
SELECT currency, flat
DE)
SELECT CASE WHEN 1 THEN currency_a n
WHEN 2 THEN currency_b
WHEN 3 currency currency_c end THEN
CASE WHEN 1 THEN amount_a
WHEN 2 THEN amount_b
WHEN 3 amount of end of amount_c THEN
From your_table
CROSS JOIN (select column_value table n (sys.odcinumberlist (1,2,3))) t
)
GROUP BY currency
-
How to make the sum of hours which is the varchar2 data type in oracle
Hi my table is like this
emp_ngtshthrs (empno number (10), nightshifthrs varchar2 (20));
now I want sum employee nightshifthrs how do the sum hours, it's my hours 01:00, 05:00, 08:00, 10:00, 07:00 and 09:00
I want the sum type varchar2 hours how to do? and I want to display the sum is greater than 24:00Well, first of all you have posted your question in the wrong forum. You should have posted your question in the forum SQL and PL/SQL .
The second problem I see is that you are being too generic when you have your employees enter their night shift hours worked. If you are able, I recommend that you change your table to record hours separately from minutes and make columns of type NUMBER instead of the VARCHAR2() type. Then, you can simply use arithmatic to total the hours and minutes worked.
If you are locked in your table and cannot change it, you can convert characters to numbers and then perform your basic arithmatic on values. For example:
1 with tab1 as ( 2 select 10 as empno, '01:00' as nightshifthrs from dual union all 3 select 10 as empno, '05:00' as nightshifthrs from dual union all 4 select 10 as empno, '08:00' as nightshifthrs from dual union all 5 select 10 as empno, '10:00' as nightshifthrs from dual union all 6 select 10 as empno, '07:00' as nightshifthrs from dual union all 7 select 10 as empno, '09:00' as nightshifthrs from dual) 8 select sum(to_number(replace(nightshifthrs,':','.'))) AS hours_worked 9* from tab1 SQL> / HOURS_WORKED ------------ 40 SQL>Of course, if your users can and do enter the minutes, then which complicates the example I provided. You will need to convert the decimal minute, sum the amount, then convert the decimal time and add this to your hours. For example:
1 with tab1 as ( 2 select 10 as empno, '01:15' as nightshifthrs from dual union all 3 select 10 as empno, '05:00' as nightshifthrs from dual union all 4 select 10 as empno, '08:30' as nightshifthrs from dual union all 5 select 10 as empno, '10:00' as nightshifthrs from dual union all 6 select 10 as empno, '07:45' as nightshifthrs from dual union all 7 select 10 as empno, '09:00' as nightshifthrs from dual) 8 select sum(to_number(substr(nightshifthrs,1,2))) + SUM(to_number(SUBSTR(nightshifthrs,4,5)))/60 9* from tab1 SQL> / HOURS_WORKED ------------ 41.5 SQL>I hope this helps.
Craig...
-
How to take the last 7 digits of a varchar column
How to take the last 7 digits of a varchar2 colum
COL1
12345678
12345
1234567890123
1234567
Out put should be as below
COL1
2345678
12345
7890123
1234567
everything built in function or in any other way please
Hello
assuming that the entry contains only numbers, as in the example, the addition of 7 spaces to the left and selecting the 7 last characters toured:
with dataset as
(select col1 from column_value
table
(dbmsoutput_linesarray
("12345678"
'12345 '.
'1234567890123'
"1234567".
)
)
)
Select col1
, substr (lpad (", 7,' ') | col1-7) col1_last7
of the dataset
/
COL1 COL1_LAST7
-------------------- --------------------
12345678 2345678
12345 12345
1234567890123 7890123
1234567 1234567
Rob
-
How to get the last row and the sum of all columns in a query
Hello
is there a way to get the last record for a column and the sum of all the Archives to another column in the same query.
Best regards
You must set your needs correctly volunteers to help here...
Your data are not good enough to bring you a precise solution. Purpose, you do not have a column, which draws a distinction between the first and the last entry.
The solution becomes easy based on your design.
I introduced a grouping called 'id' column and a time column called 'time_of_insert' (only this way you can say with confidence that you can differentiate between the first and last (also a foolproof solution) - you can possibly use sequence (instead of date but if you say that you can insert two lines at the same time) ((and then likely sequence would be a better choice to differentiate instead of a timestamp field) etc...)
With your sample data, something like this can be done to get the desired results.
-----------------------------------------------------------------------------------------------------------------------
WITH dataset AS
(SELECT 1 id, 10 used, 8 remain, systimestamp + 1/24 time_of_insert FROM DUAL
UNION ALL
SELECT the 1 id, 1, 7, systimestamp + 2/24 FROM DUAL
UNION ALL
SELECT the id 1, 2, 5, systimestamp + 3/24 FROM DUAL
UNION ALL
SELECT 1 id, 1, 0, systimestamp + 4/24 FROM DUAL
UNION ALL
SELECT 1 id, 0, 0, systimestamp + 5/24 FROM DUAL
UNION ALL
SELECT the 1 id, 1, 4, systimestamp + 6/24 FROM DUAL)
SELECT *.
(SELECT SUM (used) ON sum_all)
FIRST_VALUE (stay)
COURSES (PARTITION BY id ORDER BY time_of_insert DESC)
last_row
Of THE dataset)
WHERE ROWNUM = 1;
Output:
------------------------
SUM_ALL LAST_ROW
------------------------------
15 4
See you soon,.
Manik.
-
How to reset the counter at each iteration, and how to introduce a delay
Hello world
First of all I apologize for the basic level of my questions, I'm new with Labview...
I'm counties of reading out of a USB-6008 labview chip using the DAQ assistant and I write the output to a file. The problem is that instead of giving me the number of levels for each iteration it gives me the sum of all this. How to make Wizard Reset to 0 data acquisition account on each iteration? I tried using a shift register, but it added a counter to my folder and nothing else...
Thank you very much
Sure thing. Sorry about that.
-
How do the last 4 paintings of a loop output For?
Hi people,
I'm almost at the end of my home. I really hope that someone could help me please.
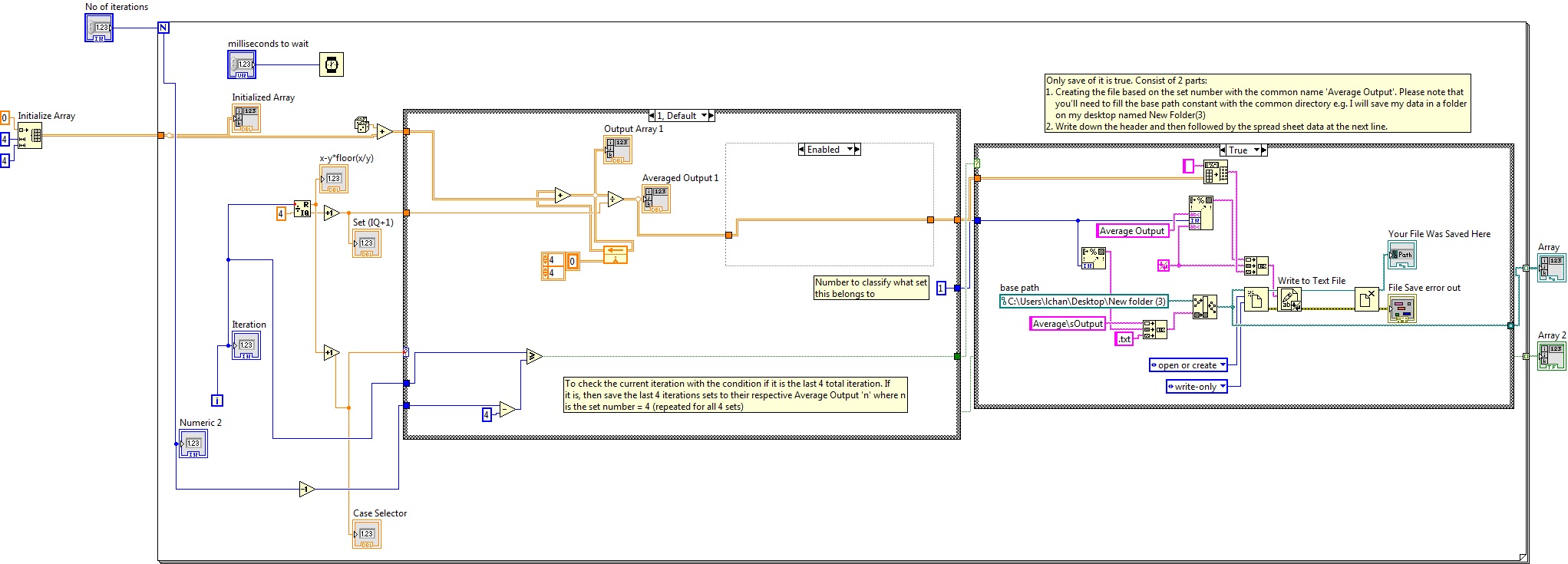
Any input would be welcome. VI attached.Explanation of VI:
I initialize an array.
The random number generator simulates my entry camera.
According to which iteration it is, the data are added in one of the four tables of output.
"x - y * floor(x/y) ' gives a value of remainder of 0, 1, 2 or 3.
'Case Selector' just add 1 to "x - y * floor(x/y) ' for case 1, 2, 3, or 4.
Pictures 1, 5, 9 etc. are added to table 1 (case 1).
Photos 2, 6, 10 etc. are added to table 2 (case 2).
3, 7, 11 etc. are added to table 3 (case 3).
Shots of 4, 8, 12 etc. are added to table 4 (4 cases).
Average output displays the average value or total divided by the number of photos stored in this table ("Set (IQ + 1)'").My problems are:
(1) I would like to output only the last 4 sets of data from different average output files, 1, 2, 3, and 4 to 4 (i.e. under .csv what is displayed on the screen in indicators "average output was 1, 2, 3 and 4 at the end of all iterations.)
Where should I put my file save the diagram disabled so that it does?Put outside the main loop with automatic indexing on gives me a file with all previous data. (This is not feasible under my number of shots should number in thousands)
Put outside the main loop with automatic indexing for off gives me only the last data series. (I need the output for 4 tables, not only the last run)
Inside of the main loop to put (as shown) gives me the same number of files as the number of iterations. (Once again not possible due to the large number of files that will be generated and slow down the camera capture)
In order to capture fast camera, I wish that these 4 files output only once the entire image capture are over.
2) would preferably name the file once and for the program to add "(1)', ' (2)', ' (3)' and '(4)' file name tables"output on average"but appropriate file path controls are an another big headache for me.»»»
3) PS is the initialization of an array enough not to use the memory manager? Or should I initialize 4 Bay?
I am using Labview 2010.
Thank you very much
CharleneHi Laura,
I assume that you want to store the 4 x 4 table of average production for the last 4 iterations (correct me if I'm wrong). If so, I've set up the example as shown below:
So, basically, what I did is I created a comparison group to check if the iteration is the iteration total last 4, you have defined. I have included a number to each of the business structures to set in which case it belongs to. The comparator will pass a Boolean result to the structure of the housing that contains the algorithm for writing a file. Since you mentioned that you want to create a file for each of the case, I created as a way to build to create the customized for each case file name. You will notice that there is a concanate string.vi that allows me to customize the name of the file. Since the common file must be exit average, I take the digital constant from the structure of the deal and convert it to a string and concanate to make it in e.g. output average 1. Please note that you need to put a basic path such as in my case, I want to save in the folder named ' New folder (3) "to my office.
The writing on the case folder occurs only if the condition is true (that is, the last 4 iterations of the loop for)
Once done, I created the header and write it in this text file and followed by data from spreadsheet on the next line.
I enclose the code for your reference. I would like to know if this is what you wanted.
Thank you
Warm greetings,
Lennard.C
-
How to calculate the sum of the fields to fill?
Hello!
My question is how can I calculate the sum of filled areas?
For example, in a PDF document, I have a few fields that must be filled out with name and surname and the end of the document, another field that is the sum of the fields "FullName" which shows how many people is in this document. The operation should not take into account white/empty areas.
Now, I know that I could do with the simple calculation "(+) sum" but I have to put a '1' for each of this area and I would like to avoid this.
Yes, it's the first option I described. In this case, you can use this code:
var total = 0; for (var i=1; i<=79; i++) { if (this.getField("Nume si prenume "+i).valueAsString!="") total++; } event.value = total; -
How to get the sum of "(qty*rate) as salesValue 'as TotalSalesValue cust_id agenda?"
Mr President.
I have to take the column values from3, or 4 tables and two of them need to be multiplied, then get the sum of this value multiplied by using Group by and order clause.
as below
cust_id prod name Qty. rate value totalValue 01 one 01 500 500 01 b 02 400 800 1300 How to get there
Select
cstmr.cust_id CustId,
PRDT. Name AutoCAD,
SL.sal_qty SalQty,
SL.unit_sal_price UnitSalPrice,
SL.sal_qty * SL.unit_sal_price as SalVal,
Sum(SL.sal_qty*SL.unit_sal_price) as TotalSalesValue
Of
cstmr customer,
salesLine sl,
prdt product
where
PRDT.prod_id = sl.prod_id
Group
cstmr.cust_id,
PRDT. Name,
SL.sal_qty,
SL.unit_sal_price
order by
cstmr.cust_id
Concerning
Your expected results include values that are not in your input data - there is no M.BOARD product, for example. This is an adaptation of Manik code that will give you the subtotals for each customer:
SELECT client_name c.nom,
product_name p.Name,
SL.sal_qty,
SL.unit_sal_price,
SL.sal_qty * SL.unit_sal_price AS salesvalue,
CASE
WHEN ROW_NUMBER () OVER (partition by order of c.cust_id p.prod_id desc, sl.sal_id desc) = 1 THEN
SUM (sl.sal_qty * sl.unit_sal_price) OVER (PARTITION BY c.cust_id)
END totals
FROM customer c INNER JOIN sales s ON s.cust_id = c.cust_id
INNER JOIN salesline sl ON sl.sal_id = s.sal_id
INNER JOIN product p ON p.prod_id = sl.prod_id
ORDER BY c.cust_id, p.prod_id, sl.sal_id
You could get the grand total of lines by the Union in a second query, or by doing something smart using ROLLUP. But I leave that to you because I think you should at least do some of your own homework.
-
How display the date of my last update of OSX in my Mac?
How display the date of my last update of OSX in my Mac?
If it was in the last 30 days, the updates will often (not always) show the Mac App store on your page of updates, under the heading "updates installed in the last 30 days.
-
My PC crashed. Restored on a new record and a new installation of FireFox. I can still access all the files on the old drive. How do I take the old bookmarks if no backup exists, or has been completed? Does not save bookmarks of FireFox auto? If, then what is the file name and where is normally stored by FireFox?
In fact, it can be easier...
If you have the old drive connected as, say, drive E, go to:
E:\Users\username
Then click in the address bar and paste it after this and press ENTER to open it:
\AppData\Roaming\Mozilla\Firefox\Profiles
Normally, you have only one file, which has a random string followed by "default." In this case, click on this file and find the subfolder bookmarkbackups.
If you find multiple profile folders, look inside to find the most recently updated backups.
To restore the backup files, see: restore bookmarks from a backup or move them to another computer
Maybe you are looking for
-
Suggestions of Spotlight/Safari limited region?
Hello I am based in Prague, Czech Republic, and recently I was in Australia, where I got a notification on my Macbook Pro and an iPhone 5 that Safari and Spotlight now support quick suggestions and etc (in iOS new updates, locations nearest you, navi
-
How to create 2D table using the table 1 following d? Table 1 d is of 0.14, - 1,1,15, - 1,2,14,15,-1 2D table should be 0.14 1.15 2,14,15 When you use insert in the table it needs the same dimension and therefore deletes the last row 2.
-
My hard drive crashed. I was using windows mail going through the server of earthlink. I deleted my emails on the server to earthlink because they were stored on my computer. Is there a way to retrieve them? They're going all the way back for 2009. P
-
MS auto update - errors for important updates
Error on Windows update - running VISTA 32 Error code is 64 c, also getting error code 643 Two updates that do not work are the following: Update for Microsoft Silverlight (KB2495644) Download size: 6.0 MB Update type: Important This update of Silver
-
Files in OneNote and Outlook 2007 be saved when a backup system is made?