IR and filter on TIMESTAMP with score (dry milli)
Is it possible to use IR and AutoFilter on timestamp column.fast look at only the possebility is in the following format
Dd-mon-yyyy and not something like this "21 February 08 03.51.32.
any other results in the following error "Date DD-MON-RR.
Is it possible filter anyway tho timestamp with milliseconds entry?
help years is welcome
Thorsten
Found in the application configuration.
Tags: Database
Similar Questions
-
Store and retrieve Date timestamp with time zone in the database
Hi Experts,
Can anyone suggest then how should I store the date in the database?Required Date Format: YYYY-MM-DDTHH:MM:SS.[timestamp][timezone]
Thank you
Dharan VYou can use the TIMESTAMP WITH TIME ZONE data type:
SQL> create table tab (mydate timestamp with time zone); Tabella creata. SQL> insert into tab values (systimestamp); Creata 1 riga. SQL> select to_char(mydate,'yyyy-mm-dd"T"hh24:mi:ss.ff3 TZR') 2 from tab; TO_CHAR(MYDATE,'YYYY-MM-DD"T"HH24:MI:SS.FF3TZR') -------------------------------------------------------------- 2010-01-30T09:50:53.814 +01:00Max
-
TIMESTAMP and TIMESTAMP WITH TIMEZONE
Pretty simple scenario. A table with 2 columns, without constraints. Column of TS is the TIMESTAMP data type. Column TS_TZ is the TIMESTAMP WITH TIME ZONE data type. Accuracy for both is 4. I'm studying explicit data type conversions. In order to enhance my understanding, I'm experimenting with the insertion of string literals:
INSERT INTO TEST_DATA_TYPES (ts, ts_tz)
VALUES (19-SEPT-14 02:24:14 ', 19-SEP-14 02:24:14 ');
The attempt above raise 01840. 00000 - 'entry not long enough for the date format value.
INSERT INTO TEST_DATA_TYPES (ts, ts_tz)
VALUES (19-SEPT-14 02:24:14 ', 19-SEP-14 02:24:14 ');
INSERT INTO TEST_DATA_TYPES (ts, ts_tz)
VALUES (19-SEPT-14 02:24:14 ', 19-SEP-14 02:24:14.0');
Two inserts above work. Note that I changed was the chain of ts_tz. In one, I added 'AM' and in others I added a fraction of a second. He was the first attempt fail because Oracle needs some sort of explicit indication where precision ends before the name of the region can be added?
Hello
2679789 wrote:
... In order to enhance my understanding, I'm experimenting with the insertion of string literals:
INSERT INTO TEST_DATA_TYPES (ts, ts_tz)
VALUES (19-SEPT-14 02:24:14 ', 19-SEP-14 02:24:14 ');
...
It is very important to understand that you should not use a string where other data type (for example, a TIMESTAMP) is expected; She simply asked in trouble. Even if make you it work properly today, you can do something next week, as apply a patch, that will not not have to work. Use the conversion functions explicitly, like TO_TIMESTAMP, iwhen, you must. Never rely on implicit conversions.
Learn exactly why a given implicit conversion may not be a good way to invest your time.
-
Can I create new folders and filter emails to them when using folders, unified inbox
Spent in IMAP and ended up with two inboxes (w8dn & weightdn @...). Switched to records unified to get all emails in one place. I get emails from many of many email lists if you need to create folders and filter emails in the appropriate folder. I can make this as set up or will it return to the POP server?
Thank you
Mike / W8DNYes. Local folders account is provided by Thunderbird for just this purpose; a generalized situation of storage independent of the account. The filter is located under Tools | Message filters. Right click on the sender in a message header will also create a filter.
With Thunderbird, you by default will have a separate set of folders for each account. This way gives you the opportunity to keep separate accounts (some users require) and you can also use the saved searches, Unified files and local files to merge accounts (other users require too!)
-
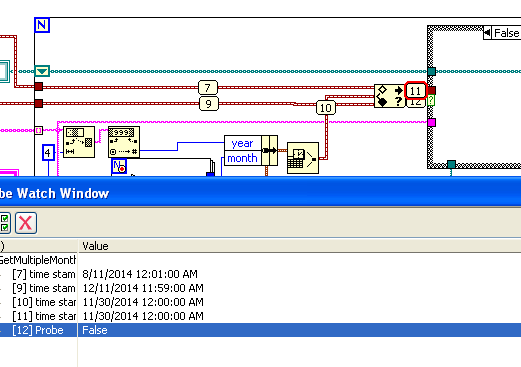
Is there a reason why I shouldn't be able to use the range and force the timestamps? In this VI the value isn't being converted, but the scale is false. With the values out of range, it force exit.

Making the possible mistake of meet without first tested... is it possible that the problem is that you have traded the upper and lower limits? The timestamps are numbers and dates are a greater number. 12 being greater than 8, the upper limit should be 11/12/2014, and the lower limit should be 11/08/2014.
EDIT: after testing, Yes, it is definitely the problem. Exchange your upper and lower limits, and it will work as expected.
-
Error recovery DB TIMESTAMP WITH time ZONE SCHEDULE
I use Managed Driver version 4.121.1.0 with EF. Trying to extract data from a table that contains a column what data type is TIMESTAMP WITH time ZONE SCHEDULE, I get a "System.InvalidTimeZoneException" in Oracle.ManagedDataAccess.dll.
This is the statement that I'm executing:
application of var = db. COORDENADA. Select (x = > new {ID = x.COORDENADAID, CREATED = x.FECHAHORAGPS}). ToList();
var RES = query. ToList();
When debugging of I am, I can see the SQL to run:
SELECT
"Extent1". "" COORDENADAID "AS"COORDENADAID. "
"Extent1". "' FECHAHORAGPS ' AS 'FECHAHORAGPS '.
OF "GEOTRACKER. "" COORDENADA ""Extent1 ".
which causes no problem in Oracle SQL Developer and get these data:
COORDENADAID FECHAHORAGPS
------------ ----------------------------------
1 06/03/14 17:10:10, EUROPE 000000000
/ PARIS
2 02/03/14 00:00:00, 000000000 EUROPE
/ PARIS
...
I think there must be something with the time format returned as name instead of offset, but I can't understand how to check this. Any idea
This bug has been fixed in Oracle DB 12.1.0.1.6 patch bundle which can be downloaded from My Oracle Support (MOS). After you download the patch bundle, you'll notice that it's a pretty important download. There is no need to install the patch to the entire group on your target computer. Instead, simply extract the managed provider and just install it.
If you do not have access to MOS, ask your DBA that should, or you can wait for the next version of the ODAC for the fix.
-
Hello
Oracle version: Enterprise Edition Release 12.1.0.1.0 - 64 bit
OS: CentOS 4.6 X86_64
I have a question about the localTimeStamp function. According to the documentation for this function is
the same thing as current_TimeStamp except that the returned value does not include the time zone.Consider the following example:
SQL > create table tmptab (colval timestamp with time zone not null);
Table created.
SQL > insert into tmptab (colval) values (localTimeStamp);
1 line of creation.
SQL > select t1.colval, tmptab from t1;
COLVAL
---------------------------------------------------------------------------
24 JANUARY 14 09.45.42.253732 H + 01:00
SQL >
Why introduce the foregoing did not fail? the data type of the column in my table colval expects a timestamp with time zone
during each which inserts as I understand (correct me if I'm wrong) is not provided by the localTimeStamp function.
Could someone kindly tell me what I misunderstood?
Thanks in advance,
dariyoosh wrote:
Hello
Oracle version: Enterprise Edition Release 12.1.0.1.0 - 64 bit
OS: CentOS 4.6 X86_64
I have a question about the localTimeStamp function. According to the documentation for this function is
the same thing as current_TimeStamp except that the returned value does not include the time zone.Consider the following example:
SQL > create table tmptab (colval timestamp with time zone not null);
Table created.
SQL > insert into tmptab (colval) values (localTimeStamp);
1 line of creation.
SQL > select t1.colval, tmptab from t1;
COLVAL
---------------------------------------------------------------------------
24 JANUARY 14 09.45.42.253732 H + 01:00
SQL >
Why introduce the foregoing did not fail? the data type of the column in my table colval expects a timestamp with time zone
during each which inserts as I understand (correct me if I'm wrong) is not provided by the localTimeStamp function.
Could someone kindly tell me what I misunderstood?
Thanks in advance,
Then, when you do
create table t (neck DATE);
Insert into t (to_date ('1st January 2014', ' mon-dd-yyyy "");)
Are you surprised that it works? After all a DATE column contains a time component, you do not provide: but he
works and gives you 00:00:00 as the component "hour".
Similarly, the timezone component is being developed to automatically with, I think, time zone of your system.
-
Hello world
During playback of Oracle ADF Real World Developer's Guide, I noticed the dates match occurring in JDeveloper is different from what is the list in the book. JDeveloper is failing to oracle.jbo.domain.Date, but according to the book:
DATE java.sql.Date DATE type is mapped to java.sql.Date if the column in the table is a no time didn't need information zone. DATE java.sql.Timestamp DATE type is mapped to java.sql.Timestamp if the column in the table has a component "time" and that the client needs to zone information. TIMESTAMP java.sql.Timestamp The TIMESTAMP type is mapped to java.sql.Timestamp if nanosecond precision is used in the database. In general, is it better to use java.sql.Date and java.sql.Timestamp instead of oracle.jbo.domain.Date? Using java.sql.Date and java.sql.Timestamp could save me some headaches conversion date. And, is there a place in JDeveloper to display these maps? I looked around and didn't see anything.
Thank you.
James
User, what version of jdev we are talking about?
In GR 11, 1 material versions db types date and timestamp are mapped to types of domain data that represents a wrapper for the native data types. The reason was that the framework can work with the domain types regardless of the underlying data type.
Since Oracle 11 GR 2 maps the types DB to java types (default selection, you can change it when you create a model project, you can set the Data Type Mapping). Once the pilot has business components define you cannot change this setting it would break existing components such as eo or vo.
So if you are working wit 11 GR 1 subject, you must use the domain types, if you work with GR 11, 2 or 12 c, you can use the domain types, but it is recommended to use the java type mapping.
Timo
-
How did the same predicate is completed access and filter?
SELECT select, j.job_title, d.department_name
OF e hr.employees, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND select LIKE 'a % ';
Execution plan
----------------------------------------------------------
Hash value of plan: 975837011
---------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 3. 189. 7 (15) | 00:00:01 |
|* 1 | HASH JOIN | 3. 189. 7 (15) | 00:00:01 |
|* 2 | HASH JOIN | 3. 141. 5 (20) | 00:00:01 |
| 3. TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 3. 60. 2 (0) | 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0) | 00:00:01 |
| 5. TABLE ACCESS FULL | JOBS | 19. 513. 2 (0) | 00:00:01 |
| 6. TABLE ACCESS FULL | DEPARTMENTS | 27. 432. 2 (0) | 00:00:01 |
---------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access("E".") DEPARTMENT_ID "=" D ". ("" DEPARTMENT_ID ")
2 - access("E".") JOB_ID '=' J '. ("' JOB_ID ')
4 - access ("E". "Last_name" LIKE 'A %') "
filter ("E". "LAST_NAME" LIKE 'A %') "
I understand not only how to select column is evaluated by the access and filter? Can someone there explain please? Or recommend me an article or document that explain this predicate excatly explains to explain the plan?
Thanks in advance.
Near NightWing.
I believe that the predicate can be used to access THE index entries and if entries of access could include potentially "false positives" then filtering is required to remove the FPs.
This filtering can be done in the same step of the operation (such as access) or as an extra step.
My apologies, this has become much longer and more detailed that I intended it to be. :-(
If I understand correctly,
In terms of the explanation of the path, each step can include access and filtering process for "entries" (index or line). In the plan to explain the predicate section shows Information the use of predicate for step 'matching. "
Some predicates can be "used" to ACCESS (ing) the entries, while the same or additional predicates (or even other) can be "used" to FILTER (ing) access entries (which have been consulted, but the optimizer is not sure that EACH AACCESSed entry is indeed a part of final result set). In such cases optimizer applies filtering predicate also during the operation stage. The optimizer can sometime even add additional operation steps or predicate [almost like a short circuit]
So, using our previous configuration, allow us to run test cases.
In this query we use AS predicate but the operand does NOT contain any 'wild' character In this case INDEX RANGE SCAN is performed, but since there is no wild characters are involved we can be sure that each entry using this predicate is indeed part of the final result set. This predicate Section shows that the predicate is used ONLY to access (index) entries.
We know that the result set of this query is NULL lines.
> explain plan for select v1 of tst where v1 as "A".
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 7. 1 (0) | 00:00:01 |
|* 1 | INDEX RANGE SCAN | TSTV1_IDX | 1. 7. 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access ("V1" = 'A')
However, in this application, there is a wildcard character in the predicate, so while the INDEX RANGE SCAN step access entries using this predicate, it could potentially access entries that can be part of the final result set. So in the SAME step of the INDEX RANGE SCAN operation the predicate is also used for filtering. Since this is the only predicate, it may seem redundant.
> explain plan for select v1 of tst where v1 like 'a % '.
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 24. 168. 1 (0) | 00:00:01 |
|* 1 | INDEX RANGE SCAN | TSTV1_IDX | 24. 168. 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access ("V1" LIKE 'A %')
filter ("V1" LIKE 'A %')
If we add an another predicate as below (also includes wild character), it gets interesting. INDEX RANGE SCAN step performs two access AND filtering.
Please note that the predicate 'V1' AS '%' is used to ACCESS and FILTER, fine FILTER uses additional predicates.
> explain plan for select v1 of tst where v1 like 'A %' and v1 as "%c".
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 7. 1 (0) | 00:00:01 |
|* 1 | INDEX RANGE SCAN | TSTV1_IDX | 1. 7. 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access ("V1" LIKE 'A %')
filter ("V1" IS NOT NULL AND "V1" LIKE 'A %') AND "V1" LIKE "%c"
When we change the predicate 'V1' LIKE 'A %' to 'V1' > 'A', then we can use the predicate to access entries AND do not forget that each entry using this predicate are
Indeed part of results if other predicates are met. In this case optimizer of must not filter on 'V1' > 'A', wherever it must continue to filter on 'V1' LIKE '%c '.
> explain plan for select v1 of tst where v1 > 'A' and v1 as "%c".
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 7. 1 (0) | 00:00:01 |
|* 1 | INDEX RANGE SCAN | TSTV1_IDX | 1. 7. 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access("V1">'A')
filter ("V1" IS NOT NULL AND "V1" LIKE "%c")
Of course, if we do the predicate so that the entries are NOT accessible using the predicate, then for INDEX FULL SCAN (no Beach cannot be determined) operation comes into play and the predicate of ACCESS goes. All entries in the index are ALWAYS accessible (predicate applied no ACCESS) and FILTER predicate is applied.
> explain plan for select v1 of tst where v1 like '%c %'
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 8 S 1 (0) | 00:00:01 |
|* 1 | INDEX SCAN FULL | TSTV1_IDX | 1. 8 S 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - filter ("V1" IS NOT NULL AND "V1" LIKE '%A%c')
For the example proposed by JL, two predicates are used in the INDEX RANGE SCAN step to access THE entries. In addition, we can be sure that all entries that are accessible with success using this predicate can be included in the final result set. So not necessary filtering.
> explain plan for select v1 of tst where v1 > 'A' and v1<>
------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 24. 168. 1 (0) | 00:00:01 |
|* 1 | INDEX RANGE SCAN | TSTV1_IDX | 24. 168. 1 (0) | 00:00:01 |
------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access("V1">'A' AND "V1")<>
Interestingly, when we change the 'B' in the previous query to 'A', change predicates of inequality, so we cannot use index. Optimizer knows this and switches for FTS and introduced an additional step of operation FILTER. In my view, the filter predicate can be applied in operation of FTS. Additional FILTER stage is the predicate as FALSE hard-coded value. It does not yet use our predicate of the query.
Well, don't know if he actually bypasses the operation of FTS. SQL trace can indicate that.
> explain plan for select v1 of tst where v1 > 'A' and v1<>
---------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 8 S 0 (0) | |
|* 1 | FILTER | | | | | |
| 2. TABLE ACCESS FULL | TST | 49. 343. 3 (0) | 00:00:01 |
---------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - filter (NULL IS NOT NULL AND NULL IS NOT NULL)
Subsequently, optimizer decides to use the INDEX RANGE SCAN, even if the predicate is always an inequality. Go figure...
> explain plan for select v1 of tst where v1 > 'A' and v1<=>
-------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1. 8 S 0 (0) | |
|* 1 | FILTER | | | | | |
|* 2 | INDEX RANGE SCAN | TSTV1_IDX | 1. 8 S 0 (0) | 00:00:01 |
-------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - filter (NULL IS NOT NULL)
2 - access("V1">'A' AND "V1")<>
As others have said, it is difficult to understand and predict the path, but fortunately Oracle doing the right thing, 99% of the time.
VR
Sudhakar
-
simple question about access to information of predicate and filter
Hello Experts
I know that maybe this is a very simple and fundamental question. I read a lot of articles on explains the plan and trying to understand what are 'access' and 'filter' which means?
Please correct me if I'm wrong, I guess when the index of explain plan can use predicate choose access if the explain command plan go with complete table filter scan (witout index) is chosen.My last question is, can you recommend me an article or document will contact plan to explain it in clear language and base level?
Thanks in advance.
Hello
as the name suggests, access predicate is when data access based on a certain condition. Filter predicate is when the data is filtered by this condition after reading.
For example, if you have a select * FROM T1 WHERE X =: x AND Y =: y, where X column is indexed, but column Y is not, you can get a map with an INDEX RANGE SCAN with access predicate = X: x (because you can use this condition to when selecting the data to be read and read only sheets of index blocks that meet this condition) and ACCESS BY ROWID from TABLE with the filter predicate Y =: y (because you cannot check this condition until after reading the table block).
I'm not aware of any good articles on the subject, and unlike others I can't find Oracle enough detailed documentation. I suggest you read a book, for example Christian Antognini, "Troubleshooting Oracle performance problems."
Best regards
Nikolai
-
Schema with annotation element to TIMESTAMP WITH TIMEZONE dateTime
Hiya,
I have a big enough scheme, official registered in my database (version 11.1.0.7.0).
As it is a bit complex (of BOA - XML schema for billing to the Denmark Government), I registered all the schema without any editing/annotation manual, but just accepted the default values.
Which worked very well for many years.
An element is a dateTime, which, of course, with no annotation, were lacking in TIMESTAMP.
All data happened which looks like this: "2011-12 - 20 T 00: 00:00", and everything worked fine. (Indeed the right diagram should have used a date - nobody needs part time :-)))
Now one of our suppliers have changed to a new format of BOA-Osama bin LADEN, but who is converted from the old PEO - XML before it happens in our society.
The conversion program has decided to do this dateTime element to include time zone: "2011-12 - 20 T 00: 00:00 + 01:00".
And if Oracle fails with an ORA-01830 because the item has not been annotated to TIMESTAMP WITH TIMEZONE.
Question 1:
Is it possible to tell Oracle 'after the fact' that this element in this scheme registered you must change TIMESTAMP TIMESTAMP WITH TIMEZONE?
Or is the only possible way to manual annotation of the file schema and re - register everything from scratch?
Question 2:
After changing the TIMESTAMP WITH TIMEZONE element, this element will be then argue that data sometimes arrive with time zone in the xml file, and sometimes they come without time zone?
Most of our suppliers (for now) continue sending "2011-12 - 20 T 00: 00:00" and will send "2011-12 - 20 T 00: 00:00 + 01:00". "."
I just need to make sure that after changing to TIMESTAMP WITH TIMEZONE, then both formats will be supported?
Thanks for any advice you can give me ;-)Well, in that case, delete and re-record the version annotated, which is the easiest way.
-
timestamp with local time zone
Hello
I created a table as follows:
create table timetest
(date of col1,
timestamp col2,
COL3 timestamp with time zone,
COL4 timestamp with local time zone.
year apart col5 in the month,
day apart col6 in the second
)
inserted a line like:
insert into timetest values (sysdate, sysdate, sysdate, sysdate, 13-11' year to month INTERVAL,
('13 2:59:59.111233' INTERVAL DAY (2) second (6))
When I select * from timetest
I have found no difference between col2 and col4, I mean timestamp and timestamp with local time zone.
Please tell me the difference between these two.
thnx in advanceTIMESTAMP WITH LOCAL TIME ZONE:-always displays the date stored in the local time zone setting i.e. According to the session's time zone setting.
TIMESTAMP WITH time ZONE:-it will always displays the values stored regardless of the settings of the session.Instead of insert sysdate insert localtimestamp and systimestamp into your table.
insert into values tab (SYSTIMESTAMP, SYSTIMESTAMP);insert into tab (LOCALTIMESTAMP, LOCALTIMESTAMP) values;
Then you must define the different session time zone as the time zone database. I have change the zone session affecting different database.
SQL > alter session set time_zone = "-03: 00 ';"
Modified session.SQL > select dbtimezone, sessiontimezone double;
DBTIMEZONE SESSIONTIMEZONE
---------- ----------------
-07:00 - 03:00To select it and see the difference.
-
How get/check out the time portion of timestamp with time zone?
Using Oracle 10 g, I have a timestamp with time zone.
We have treatment that uses hourly (as a shift of the day of treatment). I want to 'get' the time contained in a timestamp, so that I can compare it to one of our differences for example (pseudocode)
If the time in the timestamp = 0 then
treatment of midnight
on the other
do other hourly treatment
FI
I thought that "extract" was the right way to get the time portion of the time stamp, but it returns an interval based on UTC - so where I could expect
SELECT extract (time OF THE TIMESTAMP ' 2009-06-08 00:34:56 Europe/London ') FROM dual
to return to 0, it is actually 23 since it's time for the time zone UTC.
Then... How should I be getting time in order to have it make 'sense' in the context of its time zone? I simply use to_char and analyze the time part?
Thoughts?
--
AndyNot the literal timestamp ' 2009-06-08 00:34:56 Europe/London ' specifies TIMESTAMP (9) WITH ZONE TIME, subsequent DISTRIBUTION converts this TIMESTAMP value (6).
-
jdev11 - how the code filter additional liaison with radio buttons?
Using JDev 11.1.1.0.2, ADF BC for model, ADF Faces JSF to view, deploy to WebLogic 10.3 appserver, database Oracle 11
I asked for help (a do my work ask), that I'm the only developer JDev in our shop, and I looked at this problem too long and now have obscured the problem. I don't really want the answer (rather the skills needed to solve this problem), but it will ;-)
Installation program:
ExecwithParam base where the logic is stored in the AppModule. At this point, there is only a single binding TechID variable, which is passed to four of your different and updates the where clause and calls on each VO of the AppModule executeQuery. Works great so far!
Need:
Add additional time based filter: Group of buttons on the Radio for the last 30 days, 60 days, 90 days, choose a date. If choosing a date is sΘlectionnΘe, then the user selects a date with a date picker, and all records by this date are used.
Support:
There is a date variable in each query, and a common type of DATE filterDate may be added to each to filter with somedatefield > =: filterDate in each VO
Thoughts:
I like to break things in simple parts, so how about starting just the radio button.
My thinking goes like this:
Add another variable of filterDate liaison to each of your. Add this to the App Module.
So, how can I set up a radio button so that I can get the value of the selected and then button that convert a SYSDATE - value and which use th e App Module logic? I continue to think of the big picture end of case and forget everthing. I know that's not difficult, but just ask me for some advice.
At one point, I was thinking to add a clove of support to the option button, then wasn't sure if it was the best way and don't know how I would get the value in the AppModule. Part of the problem is that I came across a mental block. If I add the components that aren't linked data, as a selector of dates, or checkboxes, radio buttons, etc.. How can I get the values in the AppModule? I've seen many examples of data to related components, but do not know how to mix and match the binding with just a rich component controls base such as an input control. (This may better ask in a different thread).
Finally, what of the big picture, the part about the addition of the datePicker - of ideas?
Like cable TV, characters hosted - the kind that are related in my case the code! (Reference of American humor, must be familiar with USA cable TV channel (I'm addicted to the show House))
Thank you, KenKen,
A small correction to your last sentence - you don't want to refer to the support of the AM bean - you want to refer to the AM of the bean to support.
If you want a very simple way: find the service for your AM method in the data control palette, drag-and - drop it on your page as a button JSPX. JDeveloper will automatically add a binding for the action in the pagedef. Then, double-click the button that results and create a new method of bean of support for her (in front of JDev, don't remember what we call the dialog box) - given the option, say JDev to put the code to link to you - then the resulting method should have the code that calls the method via the definition of the page. Simply add a bit of extra code to determine and set the date.
John
-
Interpretation of the predicate information and filter explain plan
If anyone can help understand how the effects of operation predicate and filter execution plan.or how can I complete the transaction descriptor or filter chosen by the optimizer is not optimized.User445775,
Paraphrasing I provided in my previous post was on page 74 of "fundamental Oracle cost-based.
How the word explanation...
Suppose you have a database table that contains all phone numbers and addresses of individuals in a State. A query is run to find user445775 in the city named 'Redmond '. Assume that the query looks like this:
SELECT PHONE FROM PHONE_NUMBERS WHERE CITY = 'Redmond' AND FULL_NAME = 'user445775';Suppose that there is no index on the table. The DBMS_XPLAN would show two predicates applied during a comprehensive analysis of the filter - this probably indicates an ineffective path, especially if there are a very small percentage of people that match the WHERE clause on the table restrictions.
Now, suppose that an index is created on the CITY column. The DBMS_XPLAN would show an access descriptor applied to the index on the CITY column and a predicate to filter on the table access by index for the FULL_NAME. We have eliminated a large number of possible lines by applying the predicate of access to directly access the rows with the city of interest and then filtered those names that were not "user445775". It is not terribly effective, especially if there are a large number of people to 'Redmond' which should be filtered.
Now, suppose that we drop the index on the CITY column and create an index on the FULL_NAME column. The DBMS_XPLAN would show an access descriptor applied to the index on the FULL_NAME column and a predicate to filter on the table access by index for the CITY column. This could be a quite effective plan if there is only a few lines in the table with 'user445775' FULL_NAME, as a few lines will be ignored after access to the index to find those with CITY = 'Redmond '.
Now, suppose that we drop the index on the FULL_NAME column and create a composite index over the CITY, FULL_NAME. The DBMS_XPLAN would show a predicate of access applied to the index on the columns of the CITY and FULL_NAME and it would not be a predicate to filter on the table access by index - in this case, it will reject all the lines once retrieved by index access.
Page 211 "Troubleshooting Oracle performance" also shows a clear explanation of the predicates access and filter.
Think of access predicates (on the index at least) as throwing the lines until they are retrieved from the disk (or memory) and filter predicates such as throwing the lines after they are retrieved from the disk (or memory).
Charles Hooper
IT Manager/Oracle DBA
K & M-making Machine, Inc.
Maybe you are looking for
-
I can military reconfig PDF Viewer?
I only use firefox as pdf viewer by default (because its simple and perfect rendering of fonts). Something special litle, I like that firefox 'j' and 'k' shortcut key up and down the document a few line (like vim I knew). But in pdf viewer batim them
-
Hey,. Unfortunately I picked up some adware/malware, but I can't locate the source of it on my computer. I have found no extensions or plug-ins in any of my browsers, but the Adware/Malware is injected into the three (Safari, Chrome and Mozilla). I d
-
How to solve the Message "Incompatible print cartridge".
Hello everyone Have you ever received the message "Incompatible print cartridge"? This may be caused by defective cartridges, dirty cartridge contacts, or by using the wrong cartridges for your printer or the region. If you get this message after mov
-
recently, I disconnected my spekers and lost all sound on my computer when I pluged to hide in. with a lot of fiddling with the settings of the driver (via hd audio), I have some sound back. the alerts windos and a test dounds for the spekers are ver
-
P2014H vs P2014Ht of regulatory compliance
What is the difference of P2014H and P2014Ht monitors? Notice that the P2014Ht is labeled regulatory compliance. There is a physical difference between the two? Some monitors are actually marked with the numbers of different model like P2014H or P