It is faster to index an initialized matrix or use a tunnel auto-indexed, both inside a loop - what happens?
WARNING: MATLAB user here.
Note: This is a question of LabVIEW, not a matter of MathScript. I just use MathScript to demonstrate the point.
This is background to the particular question.
In MATLAB if you want to calculate decent efficiency then you want previously declared tables and want the built-in functions.
This means that it's slow:
ICT
for i = 1: 10000
ENTRIES = rand;
end
T1 = toc
(t1 = 0.266, so 37.6 elements/MS)
and it's faster
% start before the next loop, but not copy - paste with it because it slows down it waaaay
Claire x
ICT
x = Zeros (10000,1); % If not the ', 1' and then it overflows of memory to MathScript
for i = 1: 10000
ENTRIES = rand;
end
T2 = toc
(t2 = 0.205, items so 48.8/MS)
In MathScript, it is an improvement of 23% at run time.
ratio = 100 *(t2-t1)/t1
(ratio = - 23.3)
When I use LabVIEW for the same thing, I get:
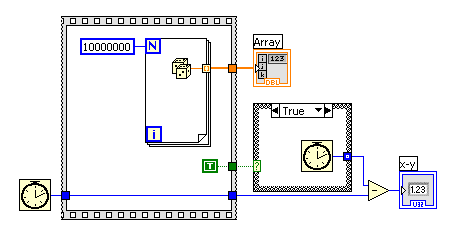
which leads to a computation time of 269 ms for about 10 000 000 elements in a vector. (Note that this is literally ~ 1000 x faster than MathScript). He created elements of k ~ 37 per millisecond.
If I change out for a created matrix indexing, then the time is strange.
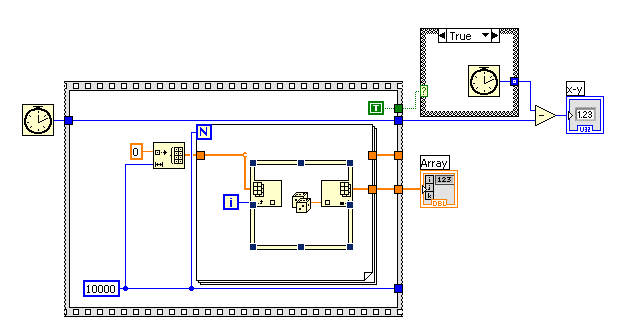
When I run it for 10 elements of k, or about 1000 times less, then he finished in approximately 30ms, or approximately 333 items per millisecond.
When I run it for 100 k items, or about 10 x more last run and 100 x less than the previous vi, and then it ended with about 5000 ms, or approximately 20 items per millisecond.
The best construction and replace it is running hundreds of times slower, and it is perhaps running ~ 1800 x slower.
Here's my problem:
One of these things is 1800 x slower than others. Why is it reasonable? Why is-111 x reasonable? Here are the simple changes.
I love that LabVIEW is literally 1000 x faster than MatLab in certain tasks. I need to understand why, in some cases this multiplier 1000 x falls down to a 2. 4 x DECREASE. Intuition I have is not only wrong, it's incredibly bad. He's wasting the 1000 x multiplier of speed that I am very happy with.
My thought:
If I did it in assembler to nickname the first loop is as follows.
I point to the stack, call the random number generator to get a value on the stack, incrementing my counter, check if it's 10 million, update my pointer location and iterate.
The second loop would be as follows:
Point battery, I write a zero, incrementing my counter, test whether it is 10 million, update my pointer location and iterate.
then
I will return to the beginning of the location of the stack, call the generator of random numbers to get a value on the stack, incrementing my counter, check if it's 10 million, update my pointer location and iterate.
The report of the runtime for loops would be the time difference of calculation-writing-increment of a (pseudo) random number and THEN a zero against writing incrementing from zero. I expect it to be somewhere between 2 x and 10 x.
There are BONES. Perhaps the algorithm to calculate a random number has many steps, like thousands. Here is the difference between On-die, L2, RAM and disk. Given enough items I would expect things to have to go through the bottlenecks and get slow.
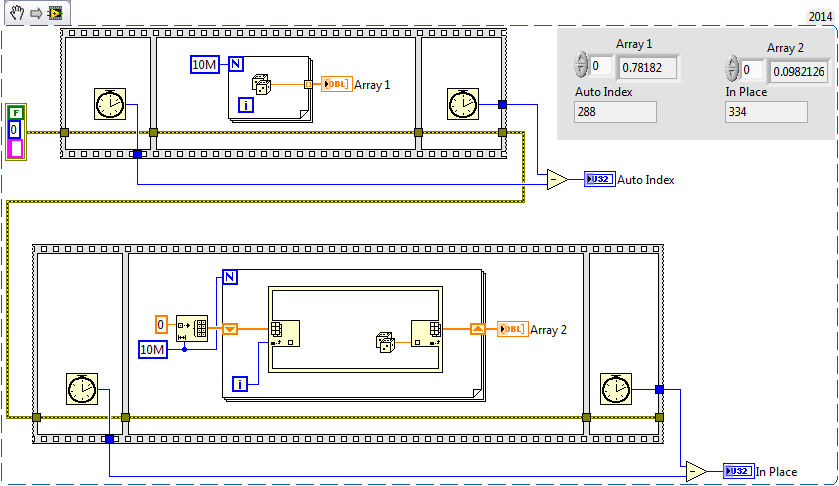
You have to shift registers when using him in place element structure. I don't know why, but it is much faster (and a more exact comparison) when you use the shift register.
Tags: NI Software
Similar Questions
-
Cannot auto index from a for loop through a structure of business output
I have a loop nested in a case structure, and outside the case, the structure is written to measure Vi. at each iteration of the loop for, I am trying to send data to writing custom Vi by using a tunnel with automatic indexing enabled. But writing custom Vi saw the release of the latest iteration of the loop. Is happening because I try automatic indexing on thanks to a structure of matter? How do you set up business structures to automatic alow to indexing?
The loop passed out all the data in the form of a table (a row/iteration) 2D and add it to the file. However, your scalar indicator 'Output average SM' will not show the value of the last inner iteration. If you want to see all sequence values, move the indicator in the innermost loop.
Also erase you the previous errors in each iteration, so you won't see any errors.
As a general rule, you have far too much code duplication. For example, your inner loops share a huge amount of code. Everything that needs to be in the structure of case is code that is different. Here's how you could simplify it. (it of just a project and probably has errors).
There are also 'model boom' that you can use to simplify things a lot more.
-
I'm designing probe of fiber optics for my medical research project. My plan is to use the controlled gain 50 high power LED. For this, I buy USB 6509 data acquisition card, SH100 cable and box of CBS puts 100 output terminal digital. I know the rest of the electronic circuits for LED current control, but I do not know how to control PWM using View(means PWM of each channel) Lab, which is given for the power transistor. and this common power control transistor through means of the LED on the LED intensity.
I have following problems help me for this
1. how to control each digital output PWM.
2 both only single-output will be ONE other will be off (Zero) (means a will ON state, 49 will be out of State). Then after 2 seconds it goes off State and next will be ON the State.
3. THE time is very low (about 2 to 3 seconds)
4 ON OFF time between two switching LED is very fast.Kind regards
Rajesh
Hi Renon,
This is what happens when you schedule without the actual hardware to test it. What result do you get on the outputs digital real?
Try this new version of the file.
Kind regards
-
How to remove the initial synchronization and use restore backup
dear friend
Hello
I have a question about replication of vsphere
I limit my bandwidth of the network with my virtual disk machine (vm1) is so big (1 TB) I want to know if I can do the first step to get a copy or a backup of my vm and restore on my second host then to do replication on machine (vm1) when starting replication can he understand most of the data are the second host and not do the full synchronization or initial synchronization just make changes
my means is: I want to remove the step of the initial sync and sync just to change data
Best regards
what you ask is quite possible.
Replication of Virtual Machines using seeds of replication
To minimize the network traffic generated by transfer of data during the initial full synchronization, replication vSphere allows you to copy virtual disk files or use the files that already exist in the target data store, and highlight those as seeds of replication when configuring a replication.
vSphere replication compares the differences on the source and target site and replicates only the changed blocks.
When, during the configuration of the replication, you select a target for the virtual machine data store,
vSphere replication seeks a disk with the same file name in the target data store. If a file with the same name exists, vSphere replication invite with a warning you and offers you the possibility to use the disk file existing as a seed for replication. If you accept the option, after that the virtual machine fully configured and enabled, vSphere replication replication compares the differences and replicates only the changed blocks. If you do not agree to the command prompt, you must change the location for your replication target.NOTE If you plan to copy the files from the source to the target, the virtual machine data store source must be powered down before you download vmdk files which will be the seeds for replication.
As the note says: power off the VM source and download VMDK who you plan to reproduce, to take them to the site data store target. When you set replication vSphere for your virtual machines, Wizard will ask you how you want to do, as if you have original seeds on the target site
-
765 and for Thinkpad 760XD BIOS updates are missing in driver matrix and 'use the fast path.
BIOS update for ThinkPad 760XD and 765 all are not in the download area of Lenovo - the matrix driver , or using the fast path.
I have found the BIOS 2.13 HXET60WW 09/12/99 hidden in the Lenovo area download by trial and error:
The README file:
http://download.Lenovo.com/ibmdl/pub/PC/pccbbs/mobiles/spsdhx60.txt
The update of the BIOS can be found here:
Download.Lenovo.com/ibmdl/pub/PC/pccbbs/mobiles/spsdhx60.exe
These are versions of BIOS:
1.00 HXET23WW 11/01/96 file not available
1.01 HXET27WW 11/12/96 file not available
1.02 HXET31WW 18/02/97 file not available
2.00 HXET51WW 15/08/97 file not available
2.01 HXET53WW 25/09/97 sytph201 README: "an error occurred during the processing of your request."
2.10 HXET57WW 21/05/98 sytph210 README: "an error occurred during the processing of your request."
2.11 HXET58WW 30/03/99 spsdhx58 README: "an error occurred during the processing of your request."
2.12 HXET59WW 07/09/99 spsdhx59 README: "an error occurred during the processing of your request."
2.13 HXET60WW 12/09/99 version READMEI submitted a request by e-mail to ask for inclusion in driver matrices.
-
Question simple complete Fast Scan index
The following quote belongs to Jonathan Lewis (Index operations |) Oracle scratchpad).
' Index fast full scan: goes to the first block of the segment, and makes close readings through the segment, pick up blocks of branch and leaf, throw branches and using the data in blocks of leaves as if they were tables lean. " Does not return the data in order. »
I wonder, why Index Fast full Scan don't close reading from roots to the leaves of the blocks, if it will ignore the branches? Is it not useless get the segment instead of just the pads of sheets? Because only blocks of leaves are needed for the user.
Concerning
Charlie
NightWing wrote:
Also, can anyone say if Oracle only extract blocks of leaves, does make a lot more effort to get the integer part? Because when she gets only the pads of sheets, one must find blocks of leaves first, then read them. Finding them can be expensive?
Hi Charlie
The method you describe to read all of the blocks of leaves is indeed an optimizer viable path called a Full Index Scan:
http://docs.Oracle.com/CD/E16655_01/server.121/e15858/tgsql_optop.htm#CHDCBBAE
A pointer address of block in the block of leaves is used to find the next block of leaves (or previous) in the structure of the index. It is "expensive" because it cannot be read these leaves blocking block a little bit at a time (and not with large effective close readings as with the IFFS) database and the next sheet block need not be physically sequential for the block of sheets and could be "Nowhere" in the breast of the storage space perhaps even on another file on a completely different physical disk.
So with an IFFS, the cost of reading and ignoring the occasional branch block is far offset with the advantage of being able to perform (perhaps in parallel) much more effective close bed.
See you soon
Richard Foote
-
What happens if my speed (airport) wifi is fast but my initial internet is slow?
I plan to purchase an Airport Express.
I understand that it will increase my network speed, but it will also stimulate my internet connection?
No, the AirPort Express cannot receive a signal and make it go faster. The Express will provide the Internet speed that provides your modem, so the maximum speed of the Internet that provides your network will be limited by the plan you have with your Internet service provider.
-
Fast Sublcipping - stay on initial clip after CMD + U?
Hello fellow editors,.
I'm going to jump directly to it - that I consult with a clip, I select the time with I-O, then press Cmd + u and click OK. Then I jump to a newly created subelement. Is there a way to avoid it and stay on clip original to do several subitems more?
And second question - are there any shortcuts for navigation in the project panel - up/down after watching a clip in the source monitor? I want to optimize the workflow described below.
My workflow of logging is to go through all images, of the original sites, then through clips into bins and create sublcips to search for then "subitem" in bin and put all my subelements in a tray of final... What is a good workflow? Exploitation forest ninjas out there?
I had to deal with this problem for a while.
AndreyOr, as Pier suggested, export shot clips back in stores of Timeline. Thoughts? What is your experience on the demand function, any chance of change, or better, not worth it?
I asked that for many years, as did any other, and some people disagree it needed. But I kept after him, and whenever someone asked for it, I joined in. I do not claim any responsibility for the result, and it came too late for me because I had finally given and started doing it in the Source monitor.
Adobe has finally added the ability to make a subelement of the timeline a little backward (which apparently missed you and I don't remember exactly when it happened). But you can now rejoice because all you have to do is right click on an item in the timeline, and you can make a subelement from there.
Problem solved! (I think).
Have a great day!
-
My both hands, index fingers. which are based on the computer next to the trackpad or are used on the trackboard are painful, feel like they were burnt, and I can barely move them. I do not have this problem before, I bought my new Mac - specifications below: it hurts and I don't have a problem with my windows, iPad or Samsung Galaxy equipment operating systems computers.
It feels like radiation leaking through the computer case. Is the radiation involved in the chips?
MacBook Pro
Model identifier: MacBookPro11, 4
Processor name: Intel Core i7
Processor speed: 2.2 GHz
Number of processors: 1
Total number of Cores: 4
(By heart) L2 Cache: 256 KB
L3 Cache: 6 MB
Memory: 16 GB
Boot ROM version: MBP114.0172.B06
Version of the SCM (System): 2.29f24
Are you use while plugged in, I feel a buzzing in my 13-inch rMBP (12.1)
-
Dialog box States: the document is not valid. The xml index file is missing. What should I do?
Tried to open a file of numbers. Dialog box shows: the invalid document___is. The xml index file is missing. I can retrieve this file? Suggestions?
Yes, all you have to do is probably make sure you run the version of numbers which is located in your main Applications folder and open the document with this version. Probably, you try to open it with the old version of numbers.
SG
-
How to assign an initial value by using the driaver or traditional?
Hi all
the question is quite simple: I use PCI - 6014 with driver OR traditional DAQ (so far). I have a device connected to a set of things to do in order to provide for a grouping, which selects the operating mode. As soon as the device is triggered and I initialize the DIO, I attribute the initial values BD. The problem is that it takes a while (approx. 15 ms) to do, and during this time (between the initialization of the devices and the initial assignment) the combination of output is one level 0, which is highly undesirable because of the specificity of the device. Is it possible to "encode" the initial values of the things to do, so that, as soon as data is turned on, and the line is declared as DO, it automatically receives the pre-defined value?
Thank you in advance,
Mike
Have you read the card? The answer is no.
-
I have loaded SKPE on my computer a few days ago and it worked fine, now I can't connect to SKYPE video. The error message is that the webcam is not detected. An additional message, is that my computer is slow. Can someone help me?
Hi timmsmichael,
Try the steps mentioned in the sub link of the Skype community and check if it works
http://Forum.Skype.com/lofiversion/index.php/t95046.htmlAlso check if all parameters of video call in Skype are positioned using the link below
http://www.Skype.com/intl/en/allfeatures/webcams/For additional support post your query in the forums of Skype.
http://Forum.Skype.com/I hope this helps!
Halima S - Microsoft technical support.
Visit our Microsoft answers feedback Forum and let us know what you think. -
can I exclude statistics and index both at the same time
Hi people,
I do big table re-organization, so my question is can I exclude statistics and index at the same time
I am planing this activity as below, please advise me if I'm wrong.
(1) create table xx_031114 in select * from xx; (it's like the precautionary measures)
(2) export the table xxx using its owner the user yy
yy/passwd@tnsnames = DIRECTORY expdp export DUMPFILE = xx.dmp = xx LOGFILE = xx.log tables
(3) to truncate the table or drop table
SQL > truncate table xx;
SQL > drop table xx;
(4) import the table with metadata without statistics & index as below
Impdp yy/passwd@tnsnames DIRECTORY = export statistical DUMPFILE = xx.dmp = xx = exclude TABLES, index CONTENT = METADATA_ONLY LOGFILE = imp_031114.log (import only meta data without statistics & index)
Question 1: can I exclude the statistics and indexes at once?
Impdp yy/passwd@tnsnames DIRECTORY = export of TABLES DUMPFILE = xx.dmp = xx CONTENT = exclude LOGFILE = imp_dataonly_031114.log index = DATA_ONLY (import data only without index)
Impdp yy/passwd@tnsnames DIRECTORY = export of TABLES DUMPFILE = xx.dmp = xx include = index (import only indexes)
2 question: can I import the indexes only as above?
Thank you and best regards.
Younus
for your question: you use the exclude options separate to exclude indexes and statistics
Question 2: directory of the user/password impdp dumpfile you_dir = your_dump = include = INDEX
Hope this helps
concerning
Pravin
-
What happens to the existing after the partition of table index and created with local index
Hi guys,.
/ / DESC part id name number, varchar2 (100), number of wage
In an existing table PART I add 1 column DATASEQ MORE. I wonder the part of table based on dataseq.now, the table is created with this logic of partition
create the part table partition (identification number, name varchar2 (100), number of salary, number DATASEQ) in list (dataseq) (values partition PART_INITIAL (1));
Suggestionn necessary. given that the table is partitioned based on DATASEQ I wonder to add local indexes on dataseq. to dataseq, I have added a local index create index idx on share (dataseq) LOCAL; Now my question is, already, there are the existing index is the column ID and salary.
(1) IDX for dataseq is created locally so that it will be partition on each partition on the main table. Please tell me what is happening to the index on the column ID and salary... it will create again in local?
Please suggest
S
Hello
first of all, in reality 'a partition table' means create a new table a migration of existing data it (although, theoretically, you can use dbms_redefinition to partition an existing table - however, it's just doing the same thing behind the scenes). This means that you also get to decide what to do with the index - index will be local, who will be global (you can also reassess some of existing indexes and decide that they are not really necessary).
Second of all, the choice of the partitioning key seems weird. Partitioning is a data management technique more that anything else, in order to be eligible, you must find a good partitioning key. A column recently added, named "data_seq" is not a good candidate. Can you give us more details about this column and why it was chosen as a partitioning key?
I suspect that the person who proposed this partitioning scheme made a huge mistake. A non-partitioned table is much better in all aspects (including the ease of management and performance) that divided one wrongly.
Best regards
Nikolai
-
What happened to the initial view options in the Document properties?
What are the initial view options in the Document properties? I just updated my player and it is no longer accessible. SOS.
Hi kga406,
Please tell me if you are able to access 'initial view' tab in the properties of the document using Acrobat.
You can change the initial view settings in Acrobat and you can view a PDF in Reader with the same initial point of view as established.
Kind regards
Ana Maria
Maybe you are looking for
-
How can I get rid of the megablocker on my iMac?
After my child tp tried to download a game, I'm megablocker pop ups and polls, I don't want. How can I get rid of him? Thank you
-
Dell Dock installation failed?
Get a window saying installation Dell Dock failed. How can I fix it?
-
repeated dosapp.FON installation
Hello everyone. A recent update (I was unable to update) for our network caused all computers running Windows XP (Professional) or Windows Server 2003 R2 Standard to prompt the user to insert the Windows XP pro CD or CD Server 2003 to install dosapp.
-
not available photo device drivers
I can't get the pic of the device drivers for my HP r074tu running on Windows 7-64 bit
-
HP Photosmart program does not "device installation is not complete.
I have HP Photosmart Essential on my Windows 7 computer. All of a sudden it can't load it. It says device is not complete, and sometimes this system has no minimum requirements. I can't download the program because of the minimum requirements. Any i