List of procs & functions of loading of a table
Y at - it a simple way to find out who are all procedures and functions are insert or update data in particular insertion of data into a table. As we have in sybase "sp_depends table_name" that lists the procs & functions, like wise we similarly in Oracle to know.Thank you very much.
Yes, in my example the COLUMN instruction is just a SQL * more relieved to change the display format (see http://download.oracle.com/docs/cd/B19306_01/server.102/b14357/ch12013.htm#SQPUG034).
Tags: Database
Similar Questions
-
Hi, I tried to get the current list of all dll functions. Here is my code: tsErrChkMsgPopup (TS_StepGetModule (StepHandle, & errorInfo & cviModule)); error = TS_CVIModuleAsCommonCModule (cviModule, & errorInfo, & commonCModule); sprintf ("c:\\Temp\\%s", sztemp, szdll); error = TS_CommonCModuleSetModulePath (commonCModule, & errorInfo, sztemp); error = TS_CVIModuleSetModuleType (commonCModule, & errorInfo, TSConst_CVIModuleType_DLL); error = TS_EngineGetAdapter (EngineHandle, & errorInfo, County, & commonCAdapter); error = TS_CommonCAdapterGetDllFunctions (commonCAdapter, & errorInfo, sztemp, & dll_func); Problem was found in the last line. Direct connection between commonCModule and commonCAdapter was non-existent, so I ask for EngineHandle of commonCAdapter, because GetDllFunctions is only for commonCAdapter. Can you help me with this? Best regards, branar
You don't need a module for a list of the functions of the DLL. Here's some pseudocode for what you need to do:
Adapter CommonCAdapter = Engine.GetAdapterByKeyName (AdapterKeyNames.FlexCVIAdapterKeyName);
DllFunctions functions = adapter. GetDllFunctions (path);
for (int i = 0; i)< functions.count;="">
{
Function DllFunction = functions [i];
String nomfonction = function. DisplayName;
Do something with functionName.
}
-
I'm currently testing our website with CF11. He is currently working with CF8 however after the migration to a new server running CF11 I met the following error.
The value returned by the function of load is not numeric.
The error occurred in
D:/applications/CFusion/CustomTags/NEC/COM/objects/address.cfc: line 263
Called from D:/apps/CFusion/CustomTags/NEC/com/objects/contact. CFC: line 331Called from D:/applications/CFusion/CustomTags/NEC/COM/objects/user.cfc: line 510
Called from D:/applications/CFusion/CustomTags/NEC/COM/objects/user.cfc: line 1675
Called from D:/website/NECPhase2/action. Validate.cfm: line 54
261: < cfif isNumeric (get.idCountry) >
262: < cfset rc = this.objCountry.setID (get.idCountry) >
263: < cfset rc = this.objCountry.load () >
264: < / cfif >
265: < cfset this.sPostcode = get.sPostcode >
Were there any changes between CF8 and CF11 which can cause this error?
Does anyone have any ideas?
The problem is in the charge function. There is a real return at the end of the function. The returntype of the function is set to digital. True is not digital, it will trigger an error.
-
Integrate the functionality of loading data Dataworkshop in an Application
Is it possible to reuse the functionality of loading data from the Dataworkshop inside an application. I write a batch processing application and it would be great to have re-use load capacity that exists already, maybe by default in the target tables and attributes, is there a api is available to enable this?
Thanks in advance for your help,
MattI don't think you can use this feature directly from the existing APEX product. However, there are a few people who have posted solutions to load files CSV style for users in the forum...
Thank you
Tony Miller
Software LuvMuffin
(281) 871-0950 -
Save and load the string table
Hello
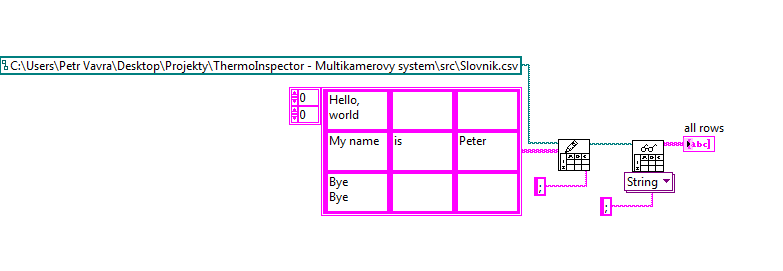
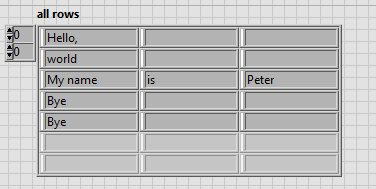
is possible except an array of channel with multiple line of text file and load new file to table with the same size of array?
Because when I use the code in the picture, initialized array is 3 x 3 but after save and load file is table 5 x 3.
If is an option how to save this table in the file into 3 x 3 table and charge back of file as a 3 x 3 table?
Thank your for any suggestion,.
Petr
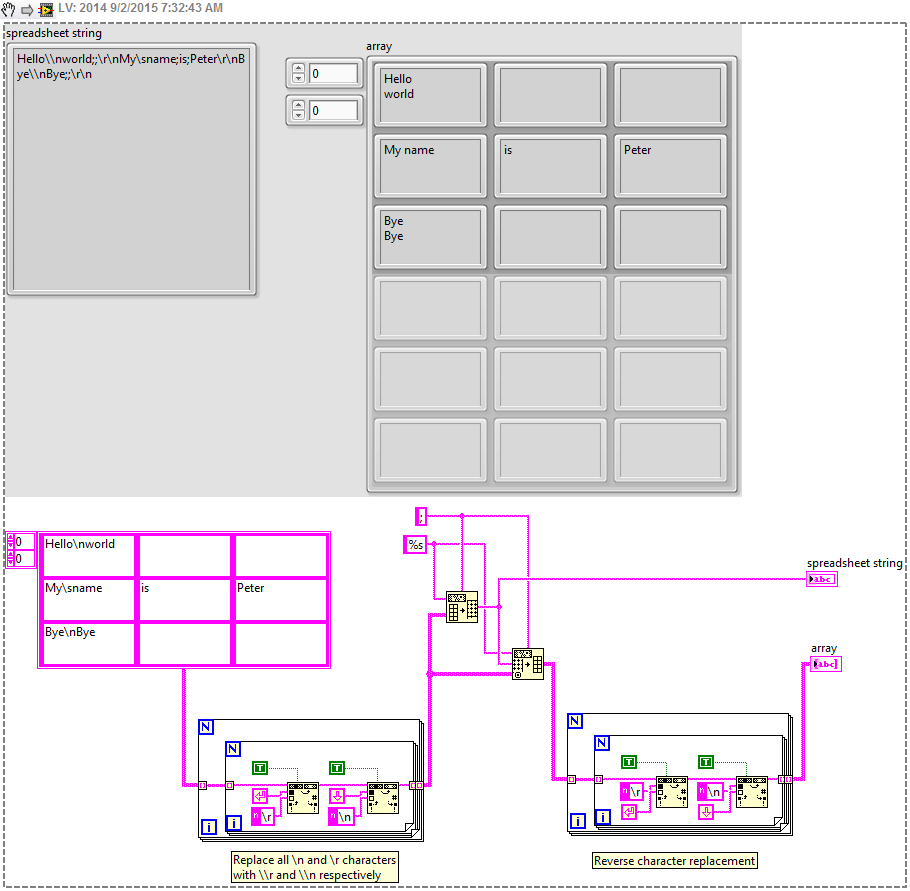
Your code is loaded in 5 x 3 is because two of your cells have newline characters (\n). The reading of the worksheet VI use return or line break characters and your delimiter to figure out how to split the string into an array.
A solution might be to replace all characters from end of line with something else, and then reinsert it after reading of the worksheet.
It can do what you want, even if it's a bit bulky. It's a little confusing if you don't understand "------" string formatting, but it essntially replaces all '\r' and '\n' with '\\r' and '\\n', including the conversion of the worksheet does not read as an end of line character.
-
Question to load data using sql loader in staging table, and then in the main tables!
Hello
I'm trying to load data into our main database table using SQL LOADER. data will be provided in separate pipes csv files.
I have develop a shell script to load the data and it works fine except one thing.
Here are the details of a data to re-create the problem.
Staging of the structure of the table in which data will be filled using sql loader
create table stg_cmts_data (cmts_token varchar2 (30), CMTS_IP varchar2 (20));
create table stg_link_data (dhcp_token varchar2 (30), cmts_to_add varchar2 (200));
create table stg_dhcp_data (dhcp_token varchar2 (30), DHCP_IP varchar2 (20));
DATA in the csv file-
for stg_cmts_data-
cmts_map_03092015_1.csv
WNLB-CMTS-01-1. 10.15.0.1
WNLB-CMTS-02-2 | 10.15.16.1
WNLB-CMTS-03-3. 10.15.48.1
WNLB-CMTS-04-4. 10.15.80.1
WNLB-CMTS-05-5. 10.15.96.1
for stg_dhcp_data-
dhcp_map_03092015_1.csv
DHCP-1-1-1. 10.25.23.10, 25.26.14.01
DHCP-1-1-2. 56.25.111.25, 100.25.2.01
DHCP-1-1-3. 25.255.3.01, 89.20.147.258
DHCP-1-1-4. 10.25.26.36, 200.32.58.69
DHCP-1-1-5 | 80.25.47.369, 60.258.14.10
for stg_link_data
cmts_dhcp_link_map_0309151623_1.csv
DHCP-1-1-1. WNLB-CMTS-01-1,WNLB-CMTS-02-2
DHCP-1-1-2. WNLB-CMTS-03-3,WNLB-CMTS-04-4,WNLB-CMTS-05-5
DHCP-1-1-3. WNLB-CMTS-01-1
DHCP-1-1-4. WNLB-CMTS-05-8,WNLB-CMTS-05-6,WNLB-CMTS-05-0,WNLB-CMTS-03-3
DHCP-1-1-5 | WNLB-CMTS-02-2,WNLB-CMTS-04-4,WNLB-CMTS-05-7
WNLB-DHCP-1-13 | WNLB-CMTS-02-2
Now, after loading these data in the staging of table I have to fill the main database table
create table subntwk (subntwk_nm varchar2 (20), subntwk_ip varchar2 (30));
create table link (link_nm varchar2 (50));
SQL scripts that I created to load data is like.
coil load_cmts.log
Set serveroutput on
DECLARE
CURSOR c_stg_cmts IS SELECT *.
OF stg_cmts_data;
TYPE t_stg_cmts IS TABLE OF stg_cmts_data % ROWTYPE INDEX BY pls_integer;
l_stg_cmts t_stg_cmts;
l_cmts_cnt NUMBER;
l_cnt NUMBER;
NUMBER of l_cnt_1;
BEGIN
OPEN c_stg_cmts.
Get the c_stg_cmts COLLECT in BULK IN l_stg_cmts;
BECAUSE me IN l_stg_cmts. FIRST... l_stg_cmts. LAST
LOOP
SELECT COUNT (1)
IN l_cmts_cnt
OF subntwk
WHERE subntwk_nm = l_stg_cmts (i) .cmts_token;
IF l_cmts_cnt < 1 THEN
INSERT
IN SUBNTWK
(
subntwk_nm
)
VALUES
(
l_stg_cmts (i) .cmts_token
);
DBMS_OUTPUT. Put_line ("token has been added: ' |") l_stg_cmts (i) .cmts_token);
ON THE OTHER
DBMS_OUTPUT. Put_line ("token is already present'");
END IF;
WHEN l_stg_cmts EXIT. COUNT = 0;
END LOOP;
commit;
EXCEPTION
WHILE OTHERS THEN
Dbms_output.put_line ('ERROR' |) SQLERRM);
END;
/
output
for dhcp
coil load_dhcp.log
Set serveroutput on
DECLARE
CURSOR c_stg_dhcp IS SELECT *.
OF stg_dhcp_data;
TYPE t_stg_dhcp IS TABLE OF stg_dhcp_data % ROWTYPE INDEX BY pls_integer;
l_stg_dhcp t_stg_dhcp;
l_dhcp_cnt NUMBER;
l_cnt NUMBER;
NUMBER of l_cnt_1;
BEGIN
OPEN c_stg_dhcp.
Get the c_stg_dhcp COLLECT in BULK IN l_stg_dhcp;
BECAUSE me IN l_stg_dhcp. FIRST... l_stg_dhcp. LAST
LOOP
SELECT COUNT (1)
IN l_dhcp_cnt
OF subntwk
WHERE subntwk_nm = l_stg_dhcp (i) .dhcp_token;
IF l_dhcp_cnt < 1 THEN
INSERT
IN SUBNTWK
(
subntwk_nm
)
VALUES
(
l_stg_dhcp (i) .dhcp_token
);
DBMS_OUTPUT. Put_line ("token has been added: ' |") l_stg_dhcp (i) .dhcp_token);
ON THE OTHER
DBMS_OUTPUT. Put_line ("token is already present'");
END IF;
WHEN l_stg_dhcp EXIT. COUNT = 0;
END LOOP;
commit;
EXCEPTION
WHILE OTHERS THEN
Dbms_output.put_line ('ERROR' |) SQLERRM);
END;
/
output
for link -.
coil load_link.log
Set serveroutput on
DECLARE
l_cmts_1 VARCHAR2 (4000 CHAR);
l_cmts_add VARCHAR2 (200 CHAR);
l_dhcp_cnt NUMBER;
l_cmts_cnt NUMBER;
l_link_cnt NUMBER;
l_add_link_nm VARCHAR2 (200 CHAR);
BEGIN
FOR (IN) r
SELECT dhcp_token, cmts_to_add | ',' cmts_add
OF stg_link_data
)
LOOP
l_cmts_1: = r.cmts_add;
l_cmts_add: = TRIM (SUBSTR (l_cmts_1, 1, INSTR (l_cmts_1, ',') - 1));
SELECT COUNT (1)
IN l_dhcp_cnt
OF subntwk
WHERE subntwk_nm = r.dhcp_token;
IF l_dhcp_cnt = 0 THEN
DBMS_OUTPUT. Put_line ("device not found: ' |") r.dhcp_token);
ON THE OTHER
While l_cmts_add IS NOT NULL
LOOP
l_add_link_nm: = r.dhcp_token |' _TO_' | l_cmts_add;
SELECT COUNT (1)
IN l_cmts_cnt
OF subntwk
WHERE subntwk_nm = TRIM (l_cmts_add);
SELECT COUNT (1)
IN l_link_cnt
LINK
WHERE link_nm = l_add_link_nm;
IF l_cmts_cnt > 0 AND l_link_cnt = 0 THEN
INSERT INTO link (link_nm)
VALUES (l_add_link_nm);
DBMS_OUTPUT. Put_line (l_add_link_nm |) » '||' Has been added. ") ;
ELSIF l_link_cnt > 0 THEN
DBMS_OUTPUT. Put_line (' link is already present: ' | l_add_link_nm);
ELSIF l_cmts_cnt = 0 then
DBMS_OUTPUT. Put_line (' no. CMTS FOUND for device to create the link: ' | l_cmts_add);
END IF;
l_cmts_1: = TRIM (SUBSTR (l_cmts_1, INSTR (l_cmts_1, ',') + 1));
l_cmts_add: = TRIM (SUBSTR (l_cmts_1, 1, INSTR (l_cmts_1, ',') - 1));
END LOOP;
END IF;
END LOOP;
COMMIT;
EXCEPTION
WHILE OTHERS THEN
Dbms_output.put_line ('ERROR' |) SQLERRM);
END;
/
output
control files -
DOWNLOAD THE DATA
INFILE 'cmts_data.csv '.
ADD
IN THE STG_CMTS_DATA TABLE
When (cmts_token! = ") AND (cmts_token! = 'NULL') AND (cmts_token! = 'null')
and (cmts_ip! = ") AND (cmts_ip! = 'NULL') AND (cmts_ip! = 'null')
FIELDS TERMINATED BY ' |' SURROUNDED OF POSSIBLY "" "
TRAILING NULLCOLS
('RTRIM (LTRIM (:cmts_token))' cmts_token,
cmts_ip ' RTRIM (LTRIM(:cmts_ip)) ")". "
for dhcp.
DOWNLOAD THE DATA
INFILE 'dhcp_data.csv '.
ADD
IN THE STG_DHCP_DATA TABLE
When (dhcp_token! = ") AND (dhcp_token! = 'NULL') AND (dhcp_token! = 'null')
and (dhcp_ip! = ") AND (dhcp_ip! = 'NULL') AND (dhcp_ip! = 'null')
FIELDS TERMINATED BY ' |' SURROUNDED OF POSSIBLY "" "
TRAILING NULLCOLS
('RTRIM (LTRIM (:dhcp_token))' dhcp_token,
dhcp_ip ' RTRIM (LTRIM(:dhcp_ip)) ")". "
for link -.
DOWNLOAD THE DATA
INFILE 'link_data.csv '.
ADD
IN THE STG_LINK_DATA TABLE
When (dhcp_token! = ") AND (dhcp_token! = 'NULL') AND (dhcp_token! = 'null')
and (cmts_to_add! = ") AND (cmts_to_add! = 'NULL') AND (cmts_to_add! = 'null')
FIELDS TERMINATED BY ' |' SURROUNDED OF POSSIBLY "" "
TRAILING NULLCOLS
('RTRIM (LTRIM (:dhcp_token))' dhcp_token,
cmts_to_add TANK (4000) RTRIM (LTRIM(:cmts_to_add)) ")" ""
SHELL SCRIPT-
If [!-d / log]
then
Mkdir log
FI
If [!-d / finished]
then
mkdir makes
FI
If [!-d / bad]
then
bad mkdir
FI
nohup time sqlldr username/password@SID CONTROL = load_cmts_data.ctl LOG = log/ldr_cmts_data.log = log/ldr_cmts_data.bad DISCARD log/ldr_cmts_data.reject ERRORS = BAD = 100000 LIVE = TRUE PARALLEL = TRUE &
nohup time username/password@SID @load_cmts.sql
nohup time sqlldr username/password@SID CONTROL = load_dhcp_data.ctl LOG = log/ldr_dhcp_data.log = log/ldr_dhcp_data.bad DISCARD log/ldr_dhcp_data.reject ERRORS = BAD = 100000 LIVE = TRUE PARALLEL = TRUE &
time nohup sqlplus username/password@SID @load_dhcp.sql
nohup time sqlldr username/password@SID CONTROL = load_link_data.ctl LOG = log/ldr_link_data.log = log/ldr_link_data.bad DISCARD log/ldr_link_data.reject ERRORS = BAD = 100000 LIVE = TRUE PARALLEL = TRUE &
time nohup sqlplus username/password@SID @load_link.sql
MV *.log. / log
If the problem I encounter is here for loading data in the link table that I check if DHCP is present in the subntwk table, then continue to another mistake of the newspaper. If CMTS then left create link to another error in the newspaper.
Now that we can here multiple CMTS are associated with unique DHCP.
So here in the table links to create the link, but for the last iteration of the loop, where I get separated by commas separate CMTS table stg_link_data it gives me log as not found CMTS.
for example
DHCP-1-1-1. WNLB-CMTS-01-1,WNLB-CMTS-02-2
Here, I guess to link the dhcp-1-1-1 with balancing-CMTS-01-1 and wnlb-CMTS-02-2
Theses all the data present in the subntwk table, but still it gives me journal wnlb-CMTS-02-2 could not be FOUND, but we have already loaded into the subntwk table.
same thing is happening with all the CMTS table stg_link_data who are in the last (I think here you got what I'm trying to explain).
But when I run the SQL scripts in the SQL Developer separately then it inserts all valid links in the table of links.
Here, she should create 9 lines in the table of links, whereas now he creates only 5 rows.
I use COMMIT in my script also but it only does not help me.
Run these scripts in your machine let me know if you also get the same behavior I get.
and please give me a solution I tried many thing from yesterday, but it's always the same.
It is the table of link log
link is already present: dhcp-1-1-1_TO_wnlb-cmts-01-1 NOT FOUND CMTS for device to create the link: wnlb-CMTS-02-2
link is already present: dhcp-1-1-2_TO_wnlb-cmts-03-3 link is already present: dhcp-1-1-2_TO_wnlb-cmts-04-4 NOT FOUND CMTS for device to create the link: wnlb-CMTS-05-5
NOT FOUND CMTS for device to create the link: wnlb-CMTS-01-1
NOT FOUND CMTS for device to create the link: wnlb-CMTS-05-8 NOT FOUND CMTS for device to create the link: wnlb-CMTS-05-6 NOT FOUND CMTS for device to create the link: wnlb-CMTS-05-0 NOT FOUND CMTS for device to create the link: wnlb-CMTS-03-3
link is already present: dhcp-1-1-5_TO_wnlb-cmts-02-2 link is already present: dhcp-1-1-5_TO_wnlb-cmts-04-4 NOT FOUND CMTS for device to create the link: wnlb-CMTS-05-7
Device not found: wnlb-dhcp-1-13 IF NEED MORE INFORMATION PLEASE LET ME KNOW
Thank you
I felt later in the night that during the loading in the staging table using UNIX machine he created the new line for each line. That is why the last CMTS is not found, for this I use the UNIX 2 BACK conversion and it starts to work perfectly.
It was the dos2unix error!
Thank you all for your interest and I may learn new things, as I have almost 10 months of experience in (PLSQL, SQL)
-
A slower loading into partitioned table as the non partitioned table - why?
Hello
Using oracle 11.2.0.3.
Have a large fact table and do some comparative tests on the loading of large amounts of data histroical (several hundred GB) in fact range partitioned to date table.
Although I understand if use exhange partition loading may be faster to load a partitioned table, trying to figure out why a standard sql insert takes 3 x long to load a table partitioned compared to an identical table but not partitioned. Identical EVERYHING in terms of columsn and the sql that the insert and second partitioned sql execution to
ensure caching with no impact.
Local partitioned table a partitioned bitmap index as compared to the non-partitioned table that has standardnon-partioned bitmap indexes.
Any ideas/thoughts?
Thank youOne would expect that the queries that cannot no partition pruning may be slowed down, Yes.
An easy way to see this is to imagine that you have a partitioned local index b-tree and a query that needs to scan all partitions of the index to find a handful of lines that interest you (of course, this is not likely to be exactly what you see probably but we hope informative of the source of the problem). Let's say that each partition of the index has a height of 3, so for each partition, Oracle has read 3 blocks to reach the correct terminal node. So to analyze each of the N index partitions, you need block index 3 * N bed. If the index is not partitioned, perhaps the height of the index would go up to 4 or 5 If, in that case not partitioned, you must read 4 or 5 blocks. If you have hundreds or thousands of partitions, it can easily be hundreds of times more work to analyze all the index partitions individual he would to analyze one unpartitioned index.
Partitioning is not a magical option "go faster". It is a compromise - you optimize certain operations (such as those that can partition pruning) at the expense of operations that do not partition size.
Justin
-
Loading using another table of FDM mapping table
Hello
I know that we can load the mapping tables using excel sheets.
But I need to know is there anyway, we can load the tables of mapping using another table itself.
If Yes please give me the way or whatever script...
Thanks in advance
DiakitéThis can be done, but you have quite rightly assumed would entail a bit of scripting. Personally I stick to using the output of the box methods for mappings in FDM. They are both robust and easy to use.
-
Direct load in external tables
Can we use direct load in external tables? or set DIRECTLY in the external table script?
Thank you.polasa wrote:
Can we use direct load in external tables? or set DIRECTLY in the external table script?Thank you.
N ° why? Because an external table does not load data. It's more like a pointer and an instruction how to read a file.
The big difference between SQL Loader and an external table, SQL Loader is actually two things.
(a) it reads a file from the file system
(b) it inserts these values into a table in the database.An external table only one).
However, you can do a quick insertion of this external table in an actual database table so that is sought.
insert /*+append */ into myRealTable (colA, ColB, colC) select * from myExternalTableAppend it and perhaps also the parallel indication will be close to a direct path insert.
-
only 8 rows loading to the table
Hello
I am trying to load a Table in the apex oracle from a .csv file, whenever I followed the wizard and click on load only 8 lines are loaded into the table? Is there a way where I can load all the data in the csv file?
Thank youOk
It depends on the date format used on your database. If you go to the workshop of SQL, SQL commands and enter: SELECT SYSDATE FROM DUAL - what format you get? You can try to change the Excel format for date columns must match. However, when I transfer data, I use MM/DD/YYYY (I'm in the United Kingdom) and isn't the question, but it's something to try.
If you have all the numbers in the spreadsheet data, make sure they aren't formatted - comma, especially, can it cause problems.
Blanks are very well - or should be - well, as I said, make sure that the first line does not contain all white, so that the download process to know the data type for each column. There is an option on the page "Load Data" of the download process to say that 'the first line contains column names' - ensure that it is checked. Without this, the upload can assume that all the columns contain only text.
Andy
-
Is it Possible to use a function when you create a table?
Hello
Is it possible to use a function during the construction of a table?
I would like to browse my data returned from the db and call a function. The part where I call the function "myFunction [i]" doesn't seem to work. How can I solve this problem? I need to put the function call results in the table.
var i: uint;
for (i = 0; i < dataArray.Length; i ++)
{
dgArray = [{name: dataArray [i] .name, Type: myFunction [i]}];
}
Thank you!-LaxmidiHi laxmi,
Yes of course it is quite possible to use a function when you create a table... In your code, you made some mistakes...
You used hooks to call the function myFunction [i]... where you are supposed to use parentheses... myFunc (i)... and other you must push the object in the dgArray but yous hould not not attribute...
dgArray = [{name: dataArray [i] .name, Type: myFunction [i]}]; This will result in only the last table iterates in dgArray...
So you should write dgArray.push ({name: dataArray [i] .name, Type: (i) myFunction});
Check out the code below...
private var dgArray:Array = new Array();
private var myDataArray:Array = [{data: '1', name: 'Robert'}, {data: '2', name: 'Nicolas'}, {data: '3', name: "Bika"}]
private function init (): void
{
for (var i: int = 0; i
{
dgArray.push ({name: dataArray [i] .name, Type: (i) myFunction});
}
}
private void myFunction(i:int):String
{
Return 'Type' + i;
}
]]>
If this post answers your question or assistance, please mark it as such.
Thank you
Jean Claude Chari
-
Is there a list of the functions of the library obsolete?
Recently, I upgraded from 7.0 to 8.5.1 CVI. Library for new routines of navigation functions I realized that certain functions are now deprecated. It is not so complicated to adapt the code to avoid these functions, because the generally better functions have been made available. So I wonder if there is a list of all obsolete library functions that would make it easy to find the code for these functions...
Thank you!
Hello Wolfgang,.
first of all, I don't have a list of all deprecated library functions. But I tried to find a solution for you. One possibility would be to have a look at the online help and search for "obsolete", the results will include obsolete libraries. The second is that I discovered some additional information:
This list does not include material libraries, such as GPIB or DAQmx features.
AllocImageBits
CurrThreadId
CxPolyRoots
DisableBreakOnLibraryErrors
DisableExtendedMouseEvents
DisableInterrupts
DisableTaskSwitching
EnableBreakOnLibraryErrors
EnableExtendedMouseEvents
EnableInterrupts
EnableTaskSwitching
GenWinHelpFileFromFPFile
GetAxisRange
GetExternaleModuleAddr
GetExternaleModuleAddrEx
GetImageBits
GetImageInfo
GetInterruptState
InStandaloneExecutable
LoadExternalModule
LoadExternalModuleEx
MainThreadId
ReFFT
ReleaseExternalModule
RTControllerQuery
RTControllerReboot
RunExternalModule
SetAxisRange
SetDllDebuggingOption
SetImageBits
SetProjectDebugTargetPath
SetProjectTargetPath
TDMS_GetDataValues
UnloadExternalModule -
End list ListView (Pull Up to load more)
I have a Listview in which I would like to add more items when I am about to reach the end of the list. Currently I use onAtEndChanged signal to load more. But I would like to charge more when I'm about to reach about 80% of my list. I also use customized for my listview datamodel. The signal that will help me to get the row so that I can load more items specific row happened on my listview.
I tried to apply it to C++, but I couldn't. Any help on this
QVariant listitem::data(const QVariantList& indexPath) { int index = indexPath[0].toInt(); return _itemList.at(index); }Hmm... More like "infinite scroll" as feature you are looking for then pull upwards to refresh. This solution load messages when scrolling an element in the view which is 12 of the bottom of the list. You could do math according to the size of your list to do 80 percent. In any case, if you just want to load more items at the end of your list, once you have scrolls some amount of your list, you can do this:
//Connect a scroll state handler. BAM! ListScrollStateHandler::create(redditPostsList) .onFirstVisibleItemChanged(this, SLOT(onFirstVisibleItemChanged(QVariantList)));then proceed as follows:
void App::onFirstVisibleItemChanged(QVariantList firstItem) { int listIndex = this->m_RedditPostsModel->indexOf(this->m_RedditPostsModel->data(m_CurrentFirstVisibleListItem), 0); qDebug() << listIndex; //load more posts when we are 12 posts from the bottom of the list. int threshold = m_CountOfPostsRetrieved - 12; if(listIndex > threshold) { //simulate pressing the load more button. callAFunctionToLoadMoreItems(); } }Sorry if there are errors in this code. This is the code that I use, but I've simplified a bit I only use infinite scrolling in some cases. This solution would still be using infinite scrolling.
-
Hi all
I have the java as code: -.package com.demo.test; import java.util.ArrayList; import java.util.List; public class ListTest { public List<String> getList() { List listA = new ArrayList(); listA.add("element 1"); listA.add("element 2"); listA.add("element 3"); listA.add("element 4"); listA.add("element 5"); listA.add("element 6"); listA.add("element 7"); return listA; } }I create the function to call java: -.
create or replace FUNCTION get_list return varchar2 as language java name 'com.demo.test.ListTest.getList() return java.lang.String';
I want to call above function in plsql and I out like: -.
Element1
item2
3
Item4
element5
element6
Element7
Please help me.
Thank you
Xandotcreate or replace and compile java source named ListTestSrc as package com.demo.test; import java.util.ArrayList; import java.util.List; import java.sql.*; import oracle.sql.*; public class ListTest { public static ARRAY getList() throws SQLException { List listA = new ArrayList(); listA.add("element 1"); listA.add("element 2"); listA.add("element 3"); listA.add("element 4"); listA.add("element 5"); listA.add("element 6"); listA.add("element 7"); Connection conn = DriverManager.getConnection("jdbc:default:connection:"); ArrayDescriptor dsc = ArrayDescriptor.createDescriptor("VARCHAR2_TABLE", conn); return new ARRAY(dsc, conn, listA.toArray()); } }create or replace type varchar2_table as table of varchar2(4000); / create or replace function get_list return varchar2_table as language java name 'com.demo.test.ListTest.getList() return oracle.sql.ARRAY'; /
SQL> select * from table(get_list); COLUMN_VALUE --------------------------------------- element 1 element 2 element 3 element 4 element 5 element 6 element 7 7 rows selected.
If you want to use the collection in a SQL query (as above) and if the collection is large, you can do in pipeline.
See a similar example here: Re: Re: how to select csv data stored in a BLOB column as if it were an external table?
Otherwise, just use it directly into the PL/SQL code:
SQL> set serverout on SQL> SQL> declare 2 v_list varchar2_table := get_list(); 3 begin 4 for i in 1 .. v_list.count loop 5 dbms_output.put_line(v_list(i)); 6 end loop; 7 end; 8 / element 1 element 2 element 3 element 4 element 5 element 6 element 7 PL/SQL procedure successfully completed.
-
Route in Port ID function and load basic Teaming
Hello
When using road based on Port ID or load database consolidation is necessary that all natachasery of ESX server to connect to the same switch or stacked switches, or there is also the possibility to connect to separate switches?
Thank you!
Connect to the same physical switch is recommended only if you have configured the IP Hash (aggregation of links).
In the rest of the policy load balancing, you can connect it to the different physical switches.
In fact, I missed the point you asked only for the Port ID or load different switches in political function, in which case you can connect the natachasery to p.
Maybe you are looking for
-
A key is damaged on my satellite M30x
I have a X 30 M and the "s" on my keyboard key, is damaged, the black surface does not have the white support. Now, can I buy just this key or I have to buy all the keyboard? Thank you Chaves
-
I inserted the flash drive, go to "My Computers", click on the name of the movie and it says 'Windows cannot find' because I had deleted and now I want to restore it. I have by mistake deleted earlier.
-
Cannot download the new update of Messenger. Help!
When I try to sign in to Messenger, it is said that I need to update a new to move forward. I click 'OK', and it is in the middle of the download before bar it says "Cannot find the file to download for." What happened several times. What should I do
-
IP address of the printer continues to change
A large part of the time that my wireless printer is offline compared to computers on my local network, because IP address has been changed to a value other than what the computer thinks it should be. So I have to figure out what is the IP address o
-
Explorer.exe has errors on start up that invites a temporary office to use. Vista was preinstalled, so I don't have a version of re - install?