Log writer waiting & buffer waiting for busy
HelloVersion 10.2.0.3
I have a problem with a database of buffer high waits and log file sync waits top 5 events of the awr report. I noticed that recovery logs are stored in a partition of san. Not sure why they did it. Is that should store online redo logs in partition san? Please advice.
Thank you
PAVN
In your first message hear buffer waits and log file sync waits.
Now, you have two servers, a huge amount of e/s and nothing on buffer waits and log file sync waits a little towards the bottom of the list.
Your IO subsystem is completely overload on server B - and it's probably because he's overloaded while updates remotely can get lock wait time (60 seconds by default, I beleve) on ServerA.
Takes care to do much with the LOBs. In your case, it seems that you have them declared nocache logging at both ends - which helps explain the direct reading and the Scriptures.
A few oddities - no direct visible path did not write on A - that suggests she is faced with the direct path writes using asynchronous methods, but hide the impact as a result. The other server that b shows a lot of written direct path (overloaded, perhaps not on async) AND direct bed - why re-read you LOBs on B (possibly something on the way your code is written them).
A strategy to ease the burden - make the CACHE of the LOBs (but assign to a reasonable size RECYCLE cache or cache for a non-standard block size). If you can keep them cached for a few seconds, you will not have to make him reread you migrate them - reduce your total I/O.
HW argument - it's a bit a classic with the LOBs (it's space allocation as the segment grows - displacement of high waters). There are a few bugs with LOBs and SAMS tablespaces that could be behind all this - check for your version of Oracle Metalink. Log File Sync - at the moment there not that much, you can do it if they are large, written on a strongly hammered system.
Server B - too much I/O: check where it goes - maybe it's the code LOB management but seek other sources explain the db file sequential reads and read by another session - maybe you have too many readings of scattered files db passes as well.
-Check the SQL sorted by readings and Segments by physical i/o for clues. There are probably a few heavy hitters.
For transfer between systems (although it will probably not help) you could look on Configure SQL * Net components (SDU TDU, tcp/ip frames Jumbo, tx and rx pads) take care of pumping LOB size data through the link.
Concerning
Jonathan Lewis
http://jonathanlewis.WordPress.com
http://www.jlcomp.demon.co.UK
"All experts it is a equal and opposite expert."
Clarke
Tags: Database
Similar Questions
-
Logging off secure in catalyst for business area
Is it possible to do? I have not found any information about this anywhere so far.
Thank you.
Grant
Hi Grant
{module_logout}
In the online documentation: http://kb.worldsecuresystems.com/134/bc_1345.html#main_Secure_Zones_Modules
You can also use the url manually to create your own link and style you want as well. -
What is the purpose of waiting for redo log files
Hello
What is the purpose of the log files waiting for redo in the Dr?
What happens if the standby redo log files are created? or else is not created?
Please explain
Thank youRe: what is the difference between onlinelog and standbylog
I mentioned the goal of the eve of the redo log in RD files in above thread.
Concerning
Girish Sharma -
Hello
I'm huge buffer expects busy events on my database and its increase
This is the result of query on my database (9.2.0.8.0)
SQL > select event, total_waits from v$ system_event where a test of ("free buffer waits", "buffer expects busy")
2;
TOTAL_WAITS EVENT
---------------------------------------------------------------- -----------
buffer without waiting for 118
buffer busy waits 12827
Also my "space segment management' is on 'auto' on tablespaces
Please someone let me know even if the 'segment of space management' is on 'auto', why expect busy buffer is so huge
And how to reduce this event
ConcerningHello
Here's how to find the cause of a busy wait buffer:
http://www.DBA-Oracle.com/art_builder_bbw.htm
I hope this helps...
Donald K. Burleson
Oracle Press author
Author of "Oracle Tuning: the definitive reference".
http://www.rampant-books.com/t_oracle_tuning_book.htm
"Time flies like an arrow; Flies to fruit like a banana. -
Hello
in 10g R2 what are / can be the causes of waiting for redo log?
Thank you.example of waiting for recovery logs causes may be:
-does not redo groups (remember to add one more, if necessary)
-low rate of I/O
-Redo large log buffer (take a long time for the dump file data) - refers to the slow storage
-application hurt writes, making many validationsRun the Advisor of the ADDM, and see the recommendations. Look at the first 5 albums events. Maybe it's not relevant to DBTime?
-
Here's my question after tons of research and test without have the right solutions.
Target:
(1) I have a 12.1.0.2 database unique main enterprise 'testdb' as database instance running on the server "node1".
(2) I created physical standby database "stbydb" on the server "node2".
(3) DataGuard running on the mode of MaxAvailability (SYNC) with roll forward in real time 12 default c apply.
(4) primary database has 3 groups of one-man redo. (/oraredo/testdb/redo01.log redo02.log redo03.log)
(5) I've created 4 standby redo logfiles (/oraredo/testdb/stby01.log stby02.log stby03.log stby04.log)
(6) I do RMAN backup (database and archivelog) on the site of relief only.
(7) I want to use this backup for full restore of the database on the primary database.
He is a DR test to simulate the scenario that has lost every primary & Eve total servers.
Here is how to save, on the database pending:
(1) performance 'alter database recover managed standby database Cancel' to ensure that compatible data files
(2) RMAN > backup database;
(3) RMAN > backup archivelog all;
I got elements of backup and copied to primary db Server something like:
/Home/Oracle/backupset/o1_mf_nnndf_TAG20151002T133329_c0xq099p_.BKP (data files)
/Home/Oracle/backupset/o1_mf_ncsnf_TAG20151002T133329_c0xq0sgz_.BKP (spfile & controlfile)
/Home/Oracle/backupset/o1_mf_annnn_TAG20151002T133357_c0xq15xf_.BKP (archivelogs)
So here's how to restore, on the main site:
I clean all the files (data files, controlfiles oder all gone).
(1) restore spfile from pfile
RMAN > startup nomount
RMAN > restore spfile from pfile ' / home/oracle/pfile.txt' to ' / home/oracle/backupset/o1_mf_ncsnf_TAG20151002T133329_c0xq0sgz_.bkp';
(2) modify pfile to convert to db primary content. pFile shows below
*.audit_file_dest='/opt/Oracle/DB/admin/testdb/adump '
* .audit_trail = "db".
* full = '12.1.0.2.0'
*.control_files='/oradata/testdb/control01.ctl','/orafra/testdb/control02.ctl'
* .db_block_size = 8192
* .db_domain = "
*.db_file_name_convert='/testdb/','/testdb /'
* .db_name = "testdb".
* .db_recovery_file_dest ='/ orafra'
* .db_recovery_file_dest_size = 10737418240
* .db_unique_name = "testdb".
*.diagnostic_dest='/opt/Oracle/DB '
* .fal_server = "stbydb".
* .log_archive_config = 'dg_config = (testdb, stbydb)'
* .log_archive_dest_2 = "service = stbydb SYNC valid_for = (ONLINE_LOGFILE, PRIMARY_ROLE) db_unique_name = stbydb'"
* .log_archive_dest_state_2 = 'ENABLE '.
*.log_file_name_convert='/testdb/','/testdb /'
* .memory_target = 1800 m
* .open_cursors = 300
* runoff = 300
* .remote_login_passwordfile = "EXCLUSIVE."
* .standby_file_management = "AUTO".
* .undo_tablespace = "UNDOTBS1.
(3) restart db with updated file pfile
SQLPLUS > create spfile from pfile='/home/oracle/pfile.txt'
SQLPLUS > the judgment
SQLPLUS > startup nomount
(4) restore controlfile
RMAN > restore primary controlfile to ' / home/oracle/backupset/o1_mf_ncsnf_TAG20151002T133329_c0xq0sgz_.bkp';
RMAN > change the editing of the database
(5) all elements of backup catalog
RMAN > catalog starts by ' / home/oracle/backupset / '.
(6) restore and recover the database
RMAN > restore database;
RMAN > recover database until the SNA XXXXXX; (this YVERT is the maximum in archivelog backups that extends beyond the scn of the backup of the data file)
(7) open resetlogs
RMAN > alter database open resetlogs;
Everything seems perfect, except one of the file log roll forward pending is not generated
SQL > select * from v$ standby_log;
ERROR:
ORA-00308: cannot open archived log ' / oraredo/testdb/stby01.log'
ORA-27037: unable to get file status
Linux-x86_64 error: 2: no such file or directory
Additional information: 3
no selected line
I intended to use the same backup to restore primary basic & helps record traffic and the downtime between them in the world of real output.
So I have exactly the same steps (except STANDBY restore CONTROLFILE and not recover after database restore) to restore the database pending.
And I got the same missing log file.
The problem is:
(1) complete alert.log filled with this error, not the concern here
(2) now repeat it in real time apply won't work since the Party shall LGWR shows always "WAITING_FOR_LOG."
(3) I can't delete and re-create this log file
Then I tried several and found:
The missing standby logfile was still 'ACTIVE' at present RMAN backup was made.
For example, on db standby, under Group #4 (stby01.log) would be lost after the restoration.
SQL > select GROUP #, SEQUENCE #, USE (s), the STATUS from v$ standby_log;
GROUP # SEQUENCE # USED STATUS
---------- ---------- ---------- ----------
4 19 ACTIVE 133632
5 0 0 UNASSIGNED
6 0 0 not ASSIGNED
7 0 0 UNASSIGNED
So until I take the backup, I tried on the primary database:
SQL > alter system set log_archive_dest_state_2 = delay;
This was the Group of standby_log side Eve #4 was released:
SQL > select GROUP #, SEQUENCE #, USE (s), the STATUS from v$ standby_log;
GROUP # SEQUENCE # USED STATUS
---------- ---------- ---------- ----------
4 0 0 UNASSIGNED
5 0 0 UNASSIGNED
6 0 0 not ASSIGNED
7 0 0 UNASSIGNED
Then, the backup has been restored correctly without missing standby logfile.
However, to change this primary database means break DataGuard protection when you perform the backup. It's not accept on the production environment.
Finally, my real questions come:
(1) what I do may not do on parameter change?
(2) I know I can re-create the control file to redo before delete and then recreate after. Is there any simple/fast to avoid the standby logfile lost or recreate the lost one?
I understand that there are a number of ways to circumvent this. Something to keep a copy of the log file waiting restoration progress and copy up one missing, etc, etc...
And yes I always have done no real-time applies "to the aid of archived logfile" but is also not accept mode of protection of production.
I just want proof that the design (which is displayed in a few oracle doc Doc ID 602299.1 is one of those) that backs up data backup works effectively and can be used to restore the two site. And it may be without spending more time to resume backups or put the load on the primary database to create the database before.
Your idea is very much appreciated.
Thank you!
Hello
1--> when I take via RMAN backup, RMAN does not redo log (ORL or SRL) file, so we cannot expect ORLs or SRL would be restored.
2nd--> when we opened the ORL database should be deleted and created
3rd--> Expecting, SRL should not be an issue.we should be able to do away with the fall.
DR sys@cdb01 SQL > select THREAD #, SEQUENCE #, GROUP #, STATUS from v$ standby_log;
THREAD # SEQUENCE # GROUP # STATUS
---------- ---------- ---------- ----------
1 233 4 ACTIVE
1 238 5 ACTIVE
DR sys@cdb01 SQL > select * from v$ logfile;
GROUP # STATUS TYPE MEMBER IS_ CON_ID
---------- ------- ------- ------------------------------ --- ----------
3 /u03/cdb01/cdb01/redo03.log no. 0 online
/U03/cdb01/cdb01/redo02.log no. 0 2 online
1 /u03/cdb01/cdb01/redo01.log no. 0 online
4 /u03/cdb01/cdb01/stdredo01.log WATCH No. 0
/U03/cdb01/cdb01/stdredo02.log EVE 5 No. 0
DR sys@cdb01 SQL > ! ls - ltr /u03/cdb01/cdb01/stdredo01.log
method: cannot access the /u03/cdb01/cdb01/stdredo01.log: no such file or directory
DR sys@cdb01 SQL >! ls - ltr /u03/cdb01/cdb01/stdredo02.log
-rw - r-. 1 oracle oinstall 52429312 17 Oct 15:32 /u03/cdb01/cdb01/stdredo02.log
DR sys@cdb01 SQL > alter database force claire logfile 4;
change the database group claire logfile 4
*
ERROR on line 1:
ORA-01156: recovery or current flashback may need access to files
DR sys@cdb01 SQL > alter database recover managed standby database cancel;
Database altered.
DR sys@cdb01 SQL > change the database group claire logfile 4;
Database altered.
DR sys@cdb01 SQL > ! ls - ltr /u03/cdb01/cdb01/stdredo01.log
-rw - r-. 1 oracle oinstall 52429312 17 Oct 15:33 /u03/cdb01/cdb01/stdredo01.log
DR sys@cdb01 SQL >
If you do, you can recreate the controlfile without waiting for redo log entry...
If you still think it's something is not acceptable, you must have SR with support to analyze why he does not abandon SRL when controlfile_type is "underway".
Thank you
-
Oracle 11 g 2 (11.2.0.3) Linux x86_64
A silly mistake was made. While recreate redo standby logfiles, I managed to remove (rm command) waiting for redo log file in progress (before the end of the application) of the BONE. Now I see in the log of alerts:
ORA-00313: open failed for members of log group 7 of thread 1 ORA-00312: online log 7 thread 1: ..../standby_redo7.log' ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 3
What are my options at this point? I have to any cancelled transaction? The settlement seems to be moving right on the property. Where am I people?
Thanks to you all.
Hello
1 ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
2. ALTER LOGFILE GROUP 7 CLEAR DATABASE;
3 ALTER DATABASE DROP STANDBY LOGFILE GROUP 7;
4. ALTER DATABASE ADD STANDBY LOGFILE GROUP 7; OR ALTER DATABASE ADD LOGFILE MEMBER '
' HELPS GROUP 7; 5. START AGAIN APPLY: ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CURRENT LOGFILE USING DISCONNECT FROM THE SESSION;
HTH
Tobi
-
I try to capture a Web page using the Acrobat "Convert" icon, but this no longer works. I get an error message: "no access to Acrobat WebCapture. Acrobat is posibly busy or waiting for input. »
Thanks Abhishek,
already, this option was unckecked. But miraculously it works now (after spending hours trying...).
Beste, Geert
-
Hello
I get the following error message when you use the Page convert to PDF module in Internet Explorer: "not able to access installation of Acrobat Capture Web. Acrobat may be busy or waiting for input. ».
I use Acrobat X (with latest updates) on Windows 8.1, 64-bit and IE 11 (both with all latest updates).
When I click on the button to convert the top of IE, I'm asked to select the file location and name. When I click on save, I'm presented with this error. The utility creates a file, but it is unreadable - opening it gives an error in Acrobat, saying that the file is not a supported file type and it was damaged.
I have seen this error in the forum and took the advice given to run the repair via Add/Remove programs. I have run the repair and restarted twice, but to no avail.
I also uninstalled, rebooted and reinstalled, but again, no luck.
Please let me know what to try next.
Thank you
-Jody
Hi Jody,.
Please post on the Adobe forums.
Internet Explorer (and even other browsers) sometimes finiky when used with a program in administrator mode.
So, please right click on the Acrobat icon and choose ' properties > Compatibility tab "and uncheck the"Run this program as an administrator"option.
Let me know if this helps.
Kind regards
Ana Maria
-
At Adobe Acrobat 9 Pro on Windows 7 Enterprise SP1 and used Internet Explorer 10 Version 10.0.9200.17414. In the upper RIGHT of IE, I had Adobe (plug-ins?) option to:
Convert Web Page to PDF...
Add Web Page in existing PDF...
Print the Web Page...
etc.
I used the Web Page Add to... the daily option. I then installed, to fix a different problem, Adobe Acrobat Reader Version DC 2015.008.20082 (later from this post). Now, when I choose to add a Web Page in existing PDF... option, I get the error popup:
Unable to access the installation of Acrobat Capture Web. Acrobat may be busy or waiting for input.
I have searched the WWW of solutions but can't find one. Anyone has any potential ideas?
The free software Adobe Reader doesn't have these features. They are part of Acrobat (not free) - as far as I know; only with the Pro version.
There may be a PDF 'create' a web page associated with an Adobe online subscription services (perhaps PDF Pack).
Be well...
-
What is a fast alternative to starting a business of DPS app if Apple Store rejects the App? We are in a long time and can't wait for Apple to approve. We host the application elsewhere. How we host our DPS application on the website of our customers? Thank you.
Unless I misunderstood the question, you can do what you want to do. Apple does not allow to circumvent their public applications store and host on a Web site. The exception is an enterprise application, which requires a company to both Apple and Adobe account. This type of business application can be distributed only within the company. If that's what you want to do, you can learn more here:
Digital Publishing Suite help | Creating the observer for private distribution applications
Another option is to add the development application to multiple devices and use them for your demo.
-
Why read the session waits for the command of logfile (checkpoint incomplete)?
Hello
I session which States only, or better to say, I think he reads alone (I think the waiting list of events). There is full expectation of events for this session. I do not understand why this session expected to wait to log file switch (checkpoint incomplete) event. Can someone explain it to me?
Thank you{noformat} EVENT TIME_WAITED db file sequential read 441014 db file scattered read 261929 SQL*Net message from client 194635 log file switch (checkpoint incomplete) 173310 SQL*Net more data to client 58938 log file switch completion 17146 direct path read 2267 log buffer space 373 SQL*Net message to client 311 log file sync 114 events in waitclass Other 46 latch: shared pool 21 SQL*Net more data from client 20 SQL*Net break/reset to client 6 buffer busy waits 0 undo segment extension 0 latch: cache buffers chains 0 {noformat}
Jakub.Blocks of database entries are by DBWR, not dedicated server process: so if a session database issues some write actions that they cannot be declared with corresponding wait events in the user database session, but you will see waiting for associated events to make journal entries because database session must either wait to VALIDATE the execution returns (redo written log is made by LGWR and not by dedicated server process) or the order of log file (also made by LGWR).
You can see sort in http://download.oracle.com/docs/cd/E11882_01/server.112/e16508/process.htm#BABHJDHD
and in the complete picture and great http://landingpad.oracle.com/webapps/dialogue/ns/dlgwelcome.jsp?p_ext=Y&p_dlg_id=9575302&src=7027600&Act=54.Edited by: P. Forstmann on 19 Jan. 2011 17:36
-
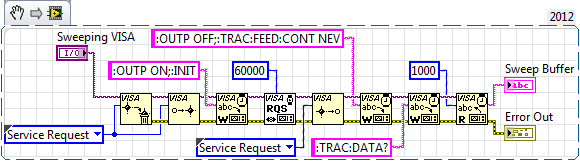
I am trying to write a simple program in c# (.NET 4.0) to control a Keithley 2400 SMU by VISA GPIB and I'm unable to switch to the program to wait as the demand for services which the Keithley send at the end of the scan.
The scan is a scan of simple linear voltage controlled internally by the unit Keithley. I have the device configured to receive a ServiceRequest signal at the end of the scan, or when compliance is reached.
I am able to send orders to the SMU and read data buffer, but only if I manually enter a timeout between the scan start command and the command to read data.
A question that I have is that I'm quite new to c# - I use this project (some parts of my code LV Portage) to learn it.
Here's what I have so far for my c# code:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading;using NationalInstruments.VisaNS; private void OnServiceRequest(object sender, MessageBasedSessionEventArgs e){ Console.WriteLine("Service Request Received!");} // open the address Console.WriteLine("Sending Commands to Instrument"); instrAddr = "GPIB0::25::INSTR"; mySession = ResourceManager.GetLocalManager().Open(instrAddr); // Cast to message-based session mbSession = (MessageBasedSession)mySession; // Here's where things get iffy for me... Enabling the event and whatnot mbSession.ServiceRequest += new MessageBasedSessionEventHandler(OnServiceRequest); MessageBasedSessionEventType srq = MessageBasedSessionEventType.ServiceRequest; mbSession.EnableEvent(srq, EventMechanism.Handler); // Start the sweep (SMU was set up earlier) Console.WriteLine("Starting Sweep"); mbSession.Write(":OUTP ON;:INIT"); int timeout = 10000; // milliseconds // Thread.Sleep(10000); // using this line works fine, but it means the test always takes 10s even if compliance is hit early // This raises error saying that the event is not enabled.mbSession.WaitOnEvent(srq, timeout); // Turn off the SMU.Console.WriteLine("I hope the sweep is done, cause I'm tired of waiting"); mbSession.Write(":OUTP OFF;:TRAC:FEED:CONT NEV"); // Get the data string data = mbSession.Query(":TRAC:DATA?"); // Close session mbSession.Dispose();All the foregoing is supposed to imitate this LabVIEW code:
So, any ideas on where I'm wrong?
Thank you
It turns out that I need to activate the event as a queue rather than a Manager:
mbSession.EnableEvent(srq, EventMechanism.Handler);
Must be:
mbSession.EnableEvent(srq, EventMechanism.Queue);
Source: the documentation under the heading "remarks". It was a pain to find documentation about it... NEITHER needs to make it easier :-(.
With this change, I also don't need to create the MessageBasedSessionEventHandler.
The final, labour code (with fluff like the namespaces and classes deleted) looks like:
rm = ResourceManager.GetLocalManager().Open("GPIB0::25::INSTR"); MessageBasedSession mbSession = (MessageBasedSession)rm; MessageBasedSessionEventType srq = MessageBasedSessionEventType.ServiceRequest; mbSession.EnableEvent(srq, EventMechanism.Queue); // Note QUEUE, not HANDLER int timeout = 10000;// Start the sweep mbSession.Write(":OUTP ON;:INIT"); // This waits for the Service Request mbSession.WaitOnEvent(srq, timeout);// After the Service Request, turn off the SMUs and get the data mbSession.Write(":OUTP OFF;:TRAC:FEED:CONT NEV"); string data = mbSession.Query(":TRAC:DATA?"); mbSession.Dispose();I hope this helps future programmers.
-
How to wait for HTML when ADF Application sends a 'work' screen while Looking Up data space reserved
Hello world
I am trying to write test scripts in Openscript for an ADF application that uses Business Intelligence and support partial-Page rendering. While it generates data, it sends HTML says his 'work', and then re - makes the area after the SQL call to the database ends. The script passes after receiving the 'work' page and errors because it cannot find the variables that should have been created.
How can I make the script wait for the actual page? I looked through the documentation and looked online but I couldn't find anything relevant (or do not know what I'm looking for).
Any help appreciated.
Thank you
Roy
OK - problem solved.
OBIEE sends the page indicating that it is looking up until the actual data returned. There is an option on the Weblogic OBIEE server in the {WEBLOGIC_HOME}/instances/bi_instance/config/OracleBIPresentationServicesComponent/coreapplication_obips1/instanceconfig.xml file that can be defined (for test/debugging) to delay sending the screen holder place 'research'.}
This should be added to the file XML between the
tags. 600 True The value indicates how many seconds the OBIEE server waits until it sends to the screen "search.
I hope that this information will prevent hair pulling episodes by others.
Roy
-
What is the cause of the message "Waiting for Service ' Console CVD activity
I have two related questions.
basis, I just started centralizing 200 computers ish, all except 2 appears fine, 2 questions, one below and another with VSS errors. This message is just for the question "in waiting for the Service.
- What is the cause of the message "Waiting for Service ' Console CVD activity and is there anywhere that documents these meanings of status.
- No idea where I should start troubleshooting the message "Waiting for Service ' I get to the computer below.
I have a computer with this status which comes to have installed the client and will not be to centralize. Other computers seem to work properly (centralized).
The computer is to ping requests, but appears as disconnected in the console.
I deleted the CVD and restarted the centralization CVD using a different policy on a different volume without change.
Journal of the history of CVD below
Description of the Type of weather
31/01/2014-08:52:32 AUDIT_EVENT assign device, device: PC30866 (1995), cardiovascular disease: 11614, political CVD: don't Default - every 4hrs - no drive D (1.1)
02/05/2014-13:53:58 politics AUDIT_EVENT assign CVD, CVD: PC30866 (11614), CVD policy: Migration Post-quotidien (1.0)
31/01/2014 General Office EVENT 20:44:46 service error
31/01/2014 General Office service EVENT 17:39:04 error
31/01/2014 14:44:34 EVENT has not finished downloading, internal error, exception attached
31/01/2014 General error from the EVENT 13:05:15 service office
31/01/2014-12:30:37 TRANSACTION_START PC30866 - centralize endpoint
the transaction log has an inscription mentioning a failure (not sure if it is the server or PC related) disc.
Diseases cardiovascular diseases cardiovascular name Type State layer size (MB) data transferred (MB) branch reflector savings start time end time transfer (MB)
Of the endpoint PC30866 centralize 11614 reading disc failed 169648 1531 0 31/01/2014 12:30:37 05 d 04:16:52
The next event is in the application event log and the Mirage event log for the failed computer. (there were not all other errors in the paper since the deployment of mirage customer and there is no errors in the system event log)
Event type: error
Event source: VMware Horizon Mirage customer
Event category: no
Event ID: 0
Date: 31/01/2014
Time: 20:44:46
User: n/a
Computer: PC30866
Description:
Error general service office
Unexpected exception taken (sender Name:Wanova.Desktop.Service.exe
There is no policy context.
, the object exception System.OutOfMemoryException: Exception of type 'System.OutOfMemoryException' was thrown.
System.Collections.Generic.List to ' 1.set_Capacity (Int32 value)
System.Collections.Generic.List to ' 1.EnsureCapacity (Int32 min)
to System.Collections.Generic.List' 1. Add (T item)
at Wanova.Net.DataTransfer.TransferStreams.SignatureResponseStream.ProcessChunk (ChunkInfo chunkInfo)
at Wanova.Net.DataTransfer.TransferStreams.ChunkInfoDecodingStream.BeginWrite (Byte [] buffer, TransferStreamWriteCallback onWriteComplete)
at Wanova.Net.DataTransfer.DataHandler.ExecuteDataStreamTask (DataHandlerExecutionTask task, MarkCompletionCallback markCompletionCallback)
at Wanova.Net.DataTransfer.DataHandler.ExecuteTask (IExecutionTask task, MarkCompletionCallback markCompletionCallback)
Wanova.Net.DataTransfer.ExecutionController.QueueListener (Group IExecutionTask)
to Wanova.Common.ThreadUtils.ParamaterizedWorkItem'1.Run (object fakeParam)
at System.Threading.QueueUserWorkItemCallback.WaitCallback_Context (Object state)
at System.Threading.ExecutionContext.Run (ExecutionContext executionContext, ContextCallback callback, Object state, Boolean ignoreSyncCtx)
at System.Threading.QueueUserWorkItemCallback.System.Threading.IThreadPoolWorkItem.ExecuteWorkItem)
at System.Threading.ThreadPoolWorkQueue.Dispatch)
at System.Threading._ThreadPoolWaitCallback.PerformWaitCallback (), ends at True)For more information, see Help and Support Center at http://go.microsoft.com/fwlink/events.asp.
It turns out that this computer seems to have hard drive errors, so not a matter of mirage.
Maybe you are looking for
-
How to synchronize a DSA Board (4496) with several S-series (6143) tips for PXI?
I need to set up a data system that will require the measure to phase for accelerometers-locking and dynamic deformation signals. How to synchronize my PXI-4496 Council with my PXI - 6143 s?
-
Installed a version not genuine Windows 7 and can no longer connect to my wireless network.
REMOVED FROM WINDOWS VISTA AND NOT GENUINE WINDOWS 7 INSTALLED Hello What is the best way to go to solve the following problem? My brother downloaded a non-genuine version of windows 7 to Utorrents. My laptop had Vista originally. I can't find any tr
-
A Windows 7 COA OA covers versions both x 86 x 64?
We have a PC with a "Windows 7 Pro OA" COA. The vehicle currently has Windows 7 x 86 installed. If we install the x 64 version of Windows by cloning an identical OEM PC with x 64 installed (still Windows 7 Pro OA) will be the license legally covers i
-
everybody else out there to me who did the OCS certifications and are NOT part of the OPN?
Someone out there (except me) who did the OCS certifications and do NOT part of OPN?I had done a few these just for you to introduce new concepts.When there is sometimes an ECA and a certification of the OCS for a subject, I try to stay with the ECO.
-
How to reinstall creative cloud
Hi my cloud creative shut down (I think because I had a lot of data on my computer) but now I deleted some data to make the room and I don't know how to reinstall