Manipulations
HelloCREATE TABLE "TEST_JET" ("K1" NUMBER, "K2" NUMBER, "K3" NUMBER, "K4" VARCHAR2(1)) ;
REM INSERTING into TEST_JET
Insert into TEST_JET (K1,K2,K3,K4) values (1,2,3,'I');
Insert into TEST_JET (K1,K2,K3,K4) values (1,2,3,'U');
Insert into TEST_JET (K1,K2,K3,K4) values (1,2,3,'D');
Insert into TEST_JET (K1,K2,K3,K4) values (1,2,2,'U');
Insert into TEST_JET (K1,K2,K3,K4) values (1,2,2,'D');
Insert into TEST_JET (K1,K2,K3,K4) values (1,3,5,'I');
Insert into TEST_JET (K1,K2,K3,K4) values (1,6,7,'U');
Insert into TEST_JET (K1,K2,K3,K4) values (1,6,7,'D');
Insert into TEST_JET (K1,K2,K3,K4) values (1,6,7,'T');
Insert into TEST_JET (K1,K2,K3,K4) values (1,8,9,'U');
Insert into TEST_JET (K1,K2,K3,K4) values (1,8,9,'U');
Insert into TEST_JET (K1,K2,K3,K4) values (1,8,9,'D');
Insert into TEST_JET (K1,K2,K3,K4) values (7,7,7,'T');
Insert into TEST_JET (K1,K2,K3,K4) values (7,7,7,'I');
SELECT K1,K2,K3,CASE WHEN STR LIKE '%D%' THEN 'D' WHEN STR LIKE '%T%' THEN 'T' WHEN STR LIKE '%I%' THEN 'I' WHEN STR LIKE '%X%' THEN 'X' END OP FROM
(
SELECT K1,K2,K3,COUNT(1),LISTAGG(K4, ',') WITHIN GROUP (ORDER BY K4) STR
FROM
TEST_JET
GROUP BY K1,K2,K3
HAVING COUNT(1)>1
)now, since we have operation D of the above query, I just need the other two rows. i.e.
(1,2,3, 'I');
(1,2,3, 'U');
What is the best way to remove the data that we do not want to keep the lines we want, using a single sql statement. Also, for the result line 7,7,7, T set I must delete the group containing T operation and two new inserted rows. i.e.
7,7,7, D and 7,7,7, I.
Published by: Rahul K on March 18, 2013 05:15
When you say that you are doing business with "recall total oracle ' do you mean Oracle Total Recall ALIAS Flashback Database? If so, you could perhaps explain a bit more about what you are trying to do? I still find it more difficult to understand the logic with this extra piece of information...
Cheers, APC
Tags: Database
Similar Questions
-
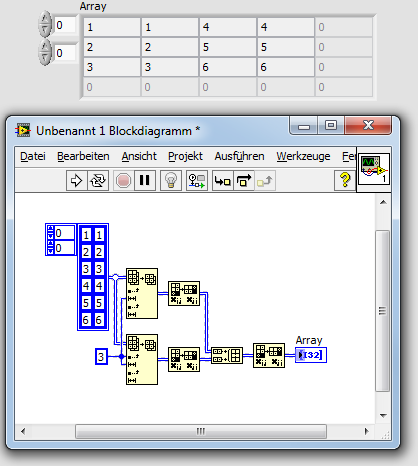
OK well,
I am currently block on a simple problem, but I can't find the solution... And of course, it's simple...
It is easier with a drawing, I want to do this:
1 1
2 2
3 3
4 4
5 5
6 6
And to change the table to have:
1 1 4 4
2 2 5 5
3 3 6 6
I found this post
http://forums.NI.com/T5/LabVIEW/array-manipulation/m-p/2871852/highlight/true#M835498I do not have lbview that 2012 but an older version, I tried to play with displacement register and build a table, but I'm a little lost.
If someone has the solution, it's homey.
Hi Gerday,
of course, it's simple:
-
Streaming AO of manipulated copy of AI: PCI-6115
I would like to release an analog output of a manipulated copy of an analog input, but I can't seem to get anywhere with the available examples. It could well be an impossible task with DAQmx.
Thanks John, I'm capable of running late; This work certainly if I actually had a stream of data. I have described my system incorrectly. There are synchronization problems that will not allow a delay in the AI and AO without errors. However, it works as expected, make me wish that I had a continuous application to use it on. No worries, I have a solution that will still be able to manipulate data in real-time using a channel AO and some hardware.
If there is a solution to this problem in real time, let me know.
-
SequenceFile with DOM (XmlDocument) data manipulation
Hello
I want to change some parameters of the step data via xml.
I saved my seq-file in xml format. If I can access via.Net (2.0) class XmlDocument.
Access and Manipulation is going well, BUT
After saving all attributes have "" (double quotes) Instead of or ' ' (single quotes)
so he will not be able to reopen the TS file!
OR:
http://www.w3.org/2001/XMLSchema-instance"xmlns ="http://www.ni.com/TestStand/4.0.0/SequenceFile">." .......
DOM:
http://www.w3.org/2001/XMLSchema-instance"xmlns ="http://www.ni.com/TestStand/4.0.0/SequenceFile">." type list >
......
Do you know how I can slove this behavior?
concerning
Jürgen
Yes,
XmlTextWriter.QuoteChar did the trick!
Bad:
xmlDocSeq.Save("D:\\Test_Modif.xml");
Good:
XmlTextWriter xmlWriter = new XmlTextWriter ("D:\\Test_Modif.xml", System.Text.Encoding.UTF8))
xmlWriter.QuoteChar = ' \ ";
xmlDocSeq.Save (xmlWriter);
Jürgen
-
Manipulation of table in LabVIEW
Hello
I'm doing a LabVIEW software in order to keep the flies.
I would to manipulate tables, but I am not able to do, it's too complicated for me.
To explain it, I thought that the best way to make an example in excel, but I can confirm that I work in LabVIEW with arrays.
I'm just lost in this manipulation of the table.
I hope that my example is pretty clear, it's really hard to explain, even orally.
Thank you
Sébastien
Assuming that entry is a table with columns for N 8N flies, here's how you could handle.

-
a problem of manipulation of table
Hello:
I'm sorry for wasting your time if this is a manipulation of the base. I am a newer for Labview and I tried several methods, unfortunately it did not work.
There are two tables that refer respectively array and array of experience. assuming that they are
Array (R) 0 0 5 5 5 5 0 0 0 5 5 5 0 5
Array (E) 1 2 3 4 5 6 7 8 9 10 11 12 13 14How can I get new subtables of Array (E) whose elements corresponding to the value 5 in the Array (R). for this instance, the subtables news here is:
Array (E1) 3 4 5 6
Array (E2) 10 11 12
Array (E3) 14Hello!
Try this and let me know

-
Manipulation of the data in table
I would like to be able to manipulate certain data (columns 2 and 3 of the txt file) that I collect according to time (column 1 of the txt file).
Now, as the VI is running, these data are plotted on a graph in wave form and stored in a txt file.
What I have to do is:
Column 1 - convert every moment at a wavelength. I know starting wavelength (nm) and the rate of change of wavelength (nm/s). I do this conversion on an excel spreadsheet right now where [current wavelength = previous wavelength - rate of change of wavelength * (time-previous time)]. So how extract column 1, take the difference between the value of the second and the first value and create a new column (somewhere) corresponding to the wavelength? And save it in a new column?
Column 2 - need to divide each value by 100 and subtract by a 'base' (on average the first 20 points, for example).
Column 3 - as it is.
Last step - write to the file a new column defined as manipulated column 2 divided by column 100 3 times... and then this field (on the y-axis) based on the manipulated column 1 (x axis).
It is extremely critical that the manipulation of data occur in real time... it can occur after the file has been written if necessary. The graphic result should stand as the jpeg attached.
Thank you in advance for the help - I'm a little unsure on the conversion of table, unbundling, etc. so much unlike mathematical and medium which must be obtained.
Meredith
-
Which is faster a bit manipulation to the table or image using the vision
I have to perform an operation on an image. It involves the calculation of the new locations for the pixels for each pixel of the image. Which is the fastest way to do it. Manipulate the pixels as elements of the array for loops, or manipulate the pixels of an image using vision tools?
Thank you.
Hello
If you can use vision tools to make the manipulation of pixels, it is much faster.
Vladimir
-
Manipulation of data and ReadFile
Does anyone know a tutorial readFile manipulation and data?
Utils.blobtoString still not working?
Hello arqlz,
The problem described in this article was due to a blobToString method unheeded at the time. This problem has since been apparently corrected. I just tested the following successfully on my PlayBook example.
Note that before could run this sample, I had to manually create the file expected readme.txt on the PlayBook filesystem under:
\media\downloads\
To complete the above, I went in my PlayBook storage and sharing settings and active file sharing, and the sharing of the Wi - Fi (so I could create the live file on my PC). Then, I created the file manually and it filled with the text:
Hello world!
My file config.xml looks like this.
http://www.w3.org/ns/widgets" xmlns:rim="http://www.blackberry.com/ns/widgets" version="1.0.0"> Sandbox Oros Most of this is just a standard configuration.
- The
white list is not mandatory, but it is included by habit. - Blackberry.io.file feature > me provides access to readFile and saveFile.
- The blackberry.utils
me gives access to the blobToString and stringToBlob methods. - Permission to access_shared ensures that you can access the shared folder on the PlayBook.
My gaze to index.html as follows file.
From top to bottom, a brief description of the main parts:
- The #logtake our logging messages so that we can keep track of what's going on.
- The / * global * / definitions are there just to satisfy JSLint. Basically, he announced that these variables are defined elsewhere.
- The logarithmic function takes the text and adds in his ownto #log. Reviews of find a large number of calls to this function scattered throughout the code. Basically, I want to keep track of what's going on. These calls are not necessary.
- The handleOpenedFile function is called if we execute successfully blackberry.io.file.readFile. This is where we do our manipulation of data read. Manipulation converts the blob to string, inserts the text "update the:" to the chain, and then converts this string to a BLOB that is then saved in our output file: test.txt. "."
- The ready function is called when the DOMContentLoaded event is raised. We provide our default readme.txt filepath then try to read the data.
- Finally, outside functions, we record the DOMContentLoaded event to trigger our ready function. We place outside all functions to ensure the event is recorded when the
- The
-
comma delimeted string manipulation
Three possibilities of decoding where it goes. BB SDK 5. Data GPS are stored in a vector of singleton in the form of a string. Essentially the string looks like this: value1, value2, value3, value4, Value5, Value6,
There can be more than 1 string in the singleton at some point I want to get a timer task in another thread is so to check each string, divide the data into other variables so that I can create a message that will be sent via an http connection. Bit, I'm glued to the minute tire data back to specific variables... I try to use a cup of the version of http://supportforums.blackberry.com/t5/Java-Development/String-Manipulation-split-replace-replaceAll... because I already know what will be the delimiter and also the amount of the values contained in the string, but I must be missing something here. The code that I need to check the vector and to try and do things variable is therefore:
for (int i = 0; i)< instance.vector.size();="">
{
String elementReturnString = instance.vector.elementAt (i) m:System.NET.SocketAddress.ToString ();
String strDelimeter = "";
String results [] = new String [6];
int iOccurrences = 0;
int iIndexOfInnerString = 0;
int iIndexOfDelimiter = 0;
int iCounter = 0;
System.out.println ("string delimiter =" + strDelimeter); It appears,
While ((iIndexOfDelimiter = elementReturnString.indexOf (strDelimiter, iIndexOfInnerString))! = - 1).
{
results [iCounter] = elementReturnString.substring (iIndexOfInnerString, iIndexOfDelimiter);
iIndexOfInnerString = iIndexOfDelimiter + strDelimiter.length ();
iCounter += 1;
}
System.out.println ("# latitude =" + results [0]); It's never farLat string results = (0);
Lon string = results [1];
Line speed = results [2];
etc etc etc.}
He bombed in the debugger with a number of errors with the first course cannot find symbol on the strDelimeter on while the statement variable. It fails every other time its use, but it displays a comma in the system.out statement. He also says that iIndexOfInnerString = iIndexOfDelimiter + strDelimiter.length (); Cannot be applied to strDelimeter.length.
..... Any ideas please? I tested that he can see in the vector information ok.
You wrote your variable strDelimeter and strDelimiter (note the an i e).
-
The question
I need to segment data on a large number of Postal Codes, usually about 400 to 600 at the same time. It is that our postcode field includes the last four digits in some cases, for example 92101-1957. When you use the Contact filter 'Value In A' I'm not able to do this 92101 *, 92102 * and of course I can't account for any combination of four numbers that might appear.
The Solution - in theory
The solution I came up with that is to create a new field of Contact in Eloqua 'Segmentation Zip Code' copy of the 5 digits of the postal Code field and execute segmentation using this new field.
The Solution - Cloud Connector
String Manipulation cloud connector must be able to perform this action - copy on the first 5 digits of the zip in the zip segment field field.
When I'm stuck - via cloud connector
I can't figure out how to write the syntax for expressions to search and replace. I have read the instructions of syntax and am still unable to establish exactly what I enter in the "regex to find: ' and the ' Regular Expressions to replace:
Does anyone have expierence with an Expression syntax that might help train these expressions?
Any ideas on other ways to address the problem would be too great.
Thank you
Louis
Hi Louis,.
Okay, I think I might know how to do it now but don't have access to Eloqua for the moment, so I'm kind of make this Store, but try below.
Use the regex below in the "Regex for find" and let the "Regex to replace white": "."
-(.*)$
This will be after the hyphen and the replacement string will be empty, so I hope you should be left with just the first five digits that you can map to a new field.
Let me know how you get on, I might be able to test myself so tomorrow so I'll see if I can make it work.
Chris
-
Manipulation of string or Validation of form for phone numbers
Our SFDC requires phone numbers in the following format: (000) 000-0000. Forms on our Web site automatically manipulate phone numbers to comply with this requirement, but our forms hosted on Eloqua Landing Pages do not have this validation/manipulation. It is originally from the headache, as customers can enter any phone number, then integration triggered to SFDC stalls.
If someone managed to use some kind of JavaScript validation or manipulation on the form itself or RegEx? If this isn't the case, anyone used the cloud of Manipulation of String component to clean the phone as such numbers?
Regular expression validation will be best way users as the required format phone number, on the forms be limited.
Please refer to this post - is there a way to validate phone numbers?
But already existing in Eloqua and contacts from other sources such as the download list, you can probably use String Manipulation Cloud Connector in a program generator, before pushing up to SFDC.
Contacts can have different types of phone formats.
Then you can try with the approach below using the Regex:
1 unformat the phone number for incoming contacts
2. and then reformat the necessary
Unformat: (step 1 of Cloud Connector)
This step will remove all the alphabets, special characters and will return the numbers only
Regex find - \D
Replace with Regex - white
Reformat: (step 2 of Cloud Connector)
Find the Regex: (? = ^.) {} 10}) ({3} \d)(\d{3}) (\d {4})
Regex Replace: ($1) 2 $ - $3
We also need to ensure that the telephone numbers has the country code at the beginning or phone Extension at the end.
In this case before you reformat, you need to check with these cases on the decision rule and then add two steps more Cc with minor changes on the regex find their expression.
It may not meet your requirement of everything, but I hope this will give you an idea.
Thank you
Ashok.
-
Direct manipulation of XMLTYPE with SQL / (XML)
I have temporary XMLTYPEs in my PL/SQL code. I want to handle these temporary XMLs with SQL, as the UPDATE and UPDATEXML.
I'm new to processing XML and what I find in the documentation is first to make a table, put the XML file into it, and then I can handle with SQL like this (pseudo-code):
CREATE TABLE xml_table OF XMLTYPE; INSERT INTO xml_table values (l_xml); UPDATE xml_table SET = UPDATEXML(…) WHERE …;
But I don't want to do (temporary) tables to organize my XML files. I just want to treat them directly as this (pseudo-code):
UPDATE l_xml SET = UPDATEXML(…) WHERE ….;
So my questions are:
- can even direct manipulation of XMLTYPE with SQL and
- What is the preferred method for XML processing (attribute values) if my functions are of the form "function(xml XMLTYPE) RETURN XMLTYPE"; (e.g. my überhaupt approach is sane?)
Handling of XML with SQL using DOUBLE is SQL sentence.
Of course, it is.
But I understand what you mean.
When I talked about manipulating XML with SQL I thought about something like this (pseudocode)
Yes, what you had in mind is exactly that, pseudocode. It does not work like that.
XQuery Update Facility is supported since 12cR1
11.2.0.3 actually, but it does not matter in your case.
Given your version, DOM is probably the best way, or a PL/SQL loop:
SQL > declare
2
3 entry xmltype: = xmltype ('
- ABC
- XYZ
4
5. start
6
7 r in)
8 select id, val | '-' || TO_CHAR (ID) as new_val
xmltable 9 ('/ / the root element' entrance passage)
path number 10 columns id '@id '.
11 road of varchar2 (30) val '.'
12 )
13)
14 loop
15 select updatexml (entry, "/ root/item[@id="' | r.id |) ([""] / text()', r.new_val)
16 comments
17 double;
18 end of loop;
19
20 dbms_output.put_line (input.getclobval);
21
22 end;
23.
- ABC-1
- XYZ-2
PL/SQL procedure successfully completed
I spoke earlier of the different techniques:
How to: Update the XML nodes with values from the same document. Odie Oracle blog
-
Little clear manipulation of the sequence data
Hi guys,.
Here I have yet another set of questions about the manipulation of the sequence data.
I checked and compared all the SDK samples in different versions and all of them seem to do things differently, and the SDK documentation does not really anyway on what the expected or proper behavior.
This applies in particular to eliminate and pointers of sequence data, which can lead to big problems regarding leakage of data or violations if done incorrectly access, copying, I guess.
I tried to code a simple example that uses a very simple SequenceData (a struct containing only int, see below), so I won't have to deal with the flattening/unflattening.
In the excerpt below, I set up SequenceSetup() and SequenceSetdown() and SequenceResetup() and marked 6 pieces with questions where the documentation and/or the implementation in the examples is incompatible.
It would be great if anyone with more insight could give reliable answers on what you're supposed to do here. :-)
Thank you
Toby
struct SequenceData { int param; }; static PF_Err SequenceSetup(PF_InData* in_data, PF_OutData* out_data) { AEGP_SuiteHandler suites(in_data->pica_basicP); // Q1: Are we allowed (or required) to delete the input sequence data if it exists ??? if (in_data->sequence_data) suites.HandleSuite1()->host_dispose_handle(in_data->sequence_data); // Q2: Are we allowed (or required) to delete the output sequence data if it exists ??? if (out_data->sequence_data) suites.HandleSuite1()->host_dispose_handle(out_data->sequence_data); PF_Handle outH = suites.HandleSuite1()->host_new_handle(sizeof(SequenceData)); if (!outH) return PF_Err_OUT_OF_MEMORY; SequenceData* outP = static_cast<SequenceData*>(suites.HandleSuite1()->host_lock_handle(outH)); if (outP) { AEFX_CLR_STRUCT(*outP); outP->param = 0; out_data->sequence_data = outH; // Q3: Do we really NOT have to set flat_sdata_size ??? // (according to the spec, it is unused, but still some samples set it) out_data->flat_sdata_size = sizeof(SequenceData); suites.HandleSuite1()->host_unlock_handle(outH); } if (!out_data->sequence_data) return PF_Err_INTERNAL_STRUCT_DAMAGED; return PF_Err_NONE; } static PF_Err SequenceSetdown(PF_InData* in_data, PF_OutData* out_data) { AEGP_SuiteHandler suites(in_data->pica_basicP); if (in_data->sequence_data) suites.HandleSuite1()->host_dispose_handle(in_data->sequence_data); // Q4: Are we required to set both in_data and out_data sequence_data pointers to NULL ??? in_data->sequence_data = NULL; out_data->sequence_data = NULL; return PF_Err_NONE; } static PF_Err SequenceResetup(PF_InData* in_data, PF_OutData* out_data) { AEGP_SuiteHandler suites(in_data->pica_basicP); PF_Handle outH = suites.HandleSuite1()->host_new_handle(sizeof(SequenceData)); if (!outH) return PF_Err_OUT_OF_MEMORY; SequenceData* outP = static_cast<SequenceData*>(suites.HandleSuite1()->host_lock_handle(outH)); if (outP) { AEFX_CLR_STRUCT(*outP); if (in_data->sequence_data) { SequenceData* inP = static_cast<SequenceData*>(DH(in_data->sequence_data)); if (inP) { outP->param = inP->param; } // Q5: Are we allowed (or required) to delete the input sequence data if it exists ??? suites.HandleSuite1()->host_dispose_handle(in_data->sequence_data); } // Q6: Are we allowed (or required) to delete the output sequence data if it exists ??? if (out_data->sequence_data) suites.HandleSuite1()->host_dispose_handle(out_data->sequence_data); out_data->sequence_data = outH; suites.HandleSuite1()->host_unlock_handle(outH); } if (!out_data->sequence_data) return PF_Err_INTERNAL_STRUCT_DAMAGED; return PF_Err_NONE; }To answer my own questions:
Q1: in_data-> sequence_data always seems to be NULL in this case, then no action is required, but does no harm is it y
Q2: out_data-> sequence_data always seems to be NULL in this case, then no action is required, but does no harm is it y
Q3: out_data-> flat_sdata_size is deprecated and should not be used
Q4: seems to do no harm, and given that the sequencing data are deleted anyway at this place, should be left here
Q5: Yes, this descriptor should be laid out here!
Q6: no, this isn't necessary and same problem (as it is the same that in_data-> data sequence when the function is called)
Here is the result of my research on these days sequence data: http://reduxfx.com/ae_seqdata.pdf
See you soon,.
Toby
-
Database inside Openscript data manipulation
Hi all
Can someone help me in the manipulation of data within Openscript database.
Anticipate the early response.Hello
Make use of the following to manipulate the data to a csv file-
Table table1 = utilities.loadCSV ("path of csv");
After loading the table, we can use variables to manipulate the data.
getVariables () .set ("variable name", table1.getRow(row_number).get (column number) ');Kind regards
Rajesh -
EN: Selection/direct manipulation of clips in the program monitor
If you accept this workflow improved, please add your own voice here www.adobe.com/go/wish.
Improvement / FMR. *
Short title of your desired function: direct selection of clips in the program for the change monitor
How would you like the feature works?
We should be able to directly monitor select a clip/active in moving/resizing/rotation program. Even better would be the ability to SHIFT-click-select 2 or more items to move/scale/rotate them in tandem.
Why is this feature important for you?
The current workflow is convoluted/intuitive because it forces users to: 1) select a single element of amendment under the ICT in the scenario, 2) click on 'Motion' in the effect control window. (3) make the changes of the Motion to the ECW and/or the program monitor. (4) repeat steps 1 to 3 for all clips/additional titles in the program monitor that had to be changed in tandem.
Although this feature request may require implementation of the 2 step, first of all, allowing direct selection of a single item and later allowing manipulation of selection/movement of 2 or more items at the same time, allowing one to select it directly in the monitor of the program for now would be a major step forward by finally allowing to change the attributes of the Motion 2 or several seeds at the same time.
NOTE: For live clip selection work efficiently, including "selectable" of securities would need to be automatically limited to the dimensions of the text itself and not by default to the dimensions of the video settings as is currently the case, because otherwise, it would be impossible to directly select a clip in a title to equal video dimensions.
2) click 'Motion' in the effect control window.
Top tether can be selected by double clicking in the MP.
If the undelaying clip is visuable and falling outside the bounding box of the element to overprint (in pips) you can double-click this also in the MP to get the rectangle encompassing.
Maybe you are looking for
-
Satellite L850-138 - pair of hardware issues
1: this model graphics card is editable?2st: which is faster than this material module DDR3 type supports? Thank you!
-
Satellite L500 - can I get all the instruments and the driver for Win 7?
good then I got this Toshiba Satellite L500 with Intel... its installed with Windows Vista Home Premium... The first problem I had with it was that the Toshiba programms stoped working and reformatting the drive and put it back, then I 'solved' this
-
How to configure the amplitude on the CLK OUT coming of the NI PXI-6652?
In the document specification NI PXI-6652, it clearly says under CLK features OUT of this magnitude ", Software Configurable. But I couldn't figure out where I can do? I'm going to CLkOUT 1Vp - p. I want to program to 2.5 VDC. Ashok
-
Original title: Shared readers do not reconnect I have two PCs connected wireless. A laptop (Vista Business) was the drives mapped to actions on the other PC (XP). Whenever the Vista PC is started or out of hibernation, or after only a short period o
-
NETGEAR wnr1000-N and WRT610N AP
Hello I have a WRT610N and Netgear WNR1000N just got Comcast, and I want to use WNR1000N as a wired router and use WRT610N as an Wireless Access Point. Is this possible? Thank you