Need to concat lines to a single column
Hi all
Some examples of data.
col1 col2 col3
125 200 abc
126 200 def
127 200 IGS
128 210 homeless
129 rte 210
130 211 uiy
I need output like this.
col2 col3
200 abc, def, ghi
210 homeless, rte
uiy 211
I need data with order of col1
Could you please let me know how to build the query for this.
Thanks in advance.
Hello
Use the function of aggregation LISTAGG, like this:
SELECT col2
LISTAGG (col3, ",") THE Group (ORDER BY col1) AS col3_list,
FROM table_x
GROUP BY col2
;
This requires that you use Oracle 11.2 or greater.
The generic term for this is the String aggregation.
For more on the aggregation of the chain, including how to do this in earlier versions of Oracle, see ORACLE-BASE - String aggregation Techniques
Tags: Database
Similar Questions
-
Convert lines to a single column
Hi all
Need help, I have a table where I want the output to a single column
ex: Select in t1. *
the query result_
rownum col_1
1 8217
2 6037
3-5368
4 5543
5 5232
I want the result to be: * 8217,6037,5368,5543,5232 *.
Thank you for your help in advance.
I search the web but couldn't find a solution that is easily understandable.WM_CONCAT is not documented, so not everyone would want to use it in production code.
However, SYS_CONNECT_BY_PATH might work:SQL> create table t as 2 select 1 rn, 8217 count_1 from dual union 3 select 2, 6037 from dual union 4 select 3, 5368 from dual union 5 select 4, 5543 from dual union 6 select 5, 5232 from dual; Table created. SQL> select * from t; RN COUNT_1 --------- ---------- 1 8217 2 6037 3 5368 4 5543 5 5232 5 rows selected. SQL> SQL> select rownum 2 , ltrim(sys_connect_by_path(count_1, ','), ',') count_1 3 from t 4 where connect_by_isleaf=1 5 start with t.rn=1 6 connect by t.rn = prior t.rn+1; ROWNUM ------- COUNT_1 ------------------------------------------------------------------------------------- 1 8217,6037,5368,5543,5232 1 row selected.Or LISTAGG on 11.2:
SQL> select listagg(count_1, ',') within group (order by rn) agged from t; AGGED ------------------------- 8217,6037,5368,5543,5232 1 row selected.I really hope that you do not really use ROWNUM as column name? I used instead RN...
-
Create views of data from multiple lines in a single column shows
Hi all - it's probably posted in the wrong forum, but I couldn't find that was right.
I'm almost a perfect beginner in sql, but I have a need to create a view that can be expanded to 10g (which effectively runs the volumes are likely to be high) who will do the following.
Authentic table with columns Parent_code, Child_code
Parent_Code Child_Code
1000-2000
1000-3000
1000-4000
2000 3000
2000-5000
(note that Parents may have several children and a child can have multiple parents!)
What I have to finish with in my opinion is the following
Child_Code Parent_List
' 2000 ' 1000 (3).
3000 "1000 (3), 2000 (2)"
' 4000 ' 1000 (3).
"5000 ' 2000 (2)"
Note the number in parentheses is the number of children whose parent's - IE in the original parent a 1000, 3 table lines (one for each child)
This point of view should be used as a quick glance upward (on the children's code) for a report of business objects.
Is there someone who could you PLEASE, PLEASE help me quickly on what I have very little time to find a solution?Hello
You can test these:
select child_code , ltrim(sys_connect_by_path(parent_info,', '), ', ') as parent_list from ( select child_code , to_char(parent_code) || ' (' || count(*) over(partition by parent_code) || ')' as parent_info , row_number() over(partition by child_code order by parent_code) rn from your_table ) where connect_by_isleaf = 1 connect by prior rn = rn-1 and prior child_code = child_code start with rn = 1 ;select child_code, rtrim( extract( xmlagg(xmlelement("e",parent_info||', ') order by parent_info) , '//text()' ) , ', ' ) as parent_list from ( select child_code, to_char(parent_code) || ' (' || count(*) over(partition by parent_code) || ')' as parent_info from your_table ) group by child_code ;What you need is called 'chain aggregation '.
See here for the various techniques, including the two above: http://www.oracle-base.com/articles/misc/StringAggregationTechniques.php -
Convert different lines in a single column
DB: 11.1.0.7
Operating system: Solaris Sparc 5.10
I have a query that is joining a few tables and give me output like below.
personnum orgnm
======= =======
The 6 key holder
9 sales
3 Mgmt
I would like to only convert a single as column below.
col1
========
6, keeper of the key, 9, sales, 3, Mgmt
I tried with pivot and decode, but not get out that I'm exepcting. Any suggesstions?yashwanth437 wrote:
listagg() function might work.LISTAGG is not available in 11.1. It was introduced in 11.2.
In any case, XML solution:
with sample_table as ( select 6 personnum,'Keyholder' orgnm from dual union all select 9,'Sales' from dual union all select 3,'Mgmt' from dual ) select rtrim(xmlagg(xmlelement(e,personnum || ',' || orgnm,',').extract('//text()')),',') col1 from sample_table / COL1 --------------------------- 6,Keyholder,9,Sales,3,Mgmt SQL>SY.
-
Multiple lines in a single column in an SQL statement
Can someone provide me with a simple sql that runs on the underside of the table (USERROLE table)
ID ROLEUSER ROLENAME
1 user1 GL
User2 OBI_AP 2
User1 3 OBI_AP
User2 4 GL
User1 5 OBI_AR
User2 6 AR
7 the GL util_3
and give the result form
ROLENAMES ROLEUSER
User1 GL; OBI_AP; OBI_AR
User2 OBI_AP; GL; AR
the GL util_3
Thank you
VikramHello
There is a similar thread, you can watch: concatenate the values of column in a row
Kind regards
-
Convert the lines into a single column
create table suresh
(
Identification number,
ch char (1)
)
;
Insert in suresh values(1,'i');
Insert in suresh values(1,'a');
Insert in suresh values(1,'m');
Insert in suresh values(1,'b');
Insert in suresh values(1,'o');
Insert in suresh values(1,'y');
Select * from suresh
ID ch
1 I
1 a
1 m
1 b
1 o
1 y
I'm looking for output something like this
ID ch
1 iamboy
..select id,listagg(ch) within group(order by ch) as ch from suresh group by id -
Selection of Pixel single column, then paste...
Hello
This might look like a very unusual request, but I was upset to find the answer.
In a given photographic image, I would choose a single pixel in each row of pixels, running up and down in a columnof a pixel. Then, I want to eliminate (Cup) nothing else on the Web with the exception of the one column of selected pixels. From there, I would take the pixel selected in each line and copy the pixel color on each line on the left and right of the pixel selected.
The end result is that I have a series of horizontal lines of pixels height of one color (based on the color of the selected pixel) through the image of left and right.
Looking at this picture:
Select a single pixel on each line in a single column-
xxxxxx XXXXXXS
xxxxxx XXXXXXS
xxxxxx XXXXXXS
Remove/cut everything except the selected pixels in only one column-
...... S......
...... S......
...... S......
Now, on each line, copy single pixel selected to the left and the right of the selection, to the extent of the canvas-
SCOTTS SCOTT
SCOTTS SCOTT
SCOTTS SCOTT
Interesting challenge or Easy-Peasey?
Thank you!
Easy. Use the brand single pixel tool to select a line of pixels. Cmd/Ctrl-J to copy pixels into a new layer. CTRL/cmd-click on the layer icon to select these pixels. CTRL/cmd-T to turn those pixels on the width of the image.

-
value of multiple line in a single row (nclob)
Hello
I have a requirement where I have to work on a nclob data type column, now here the value of 2 lines in a single column. Like this:
Select extractvalue (xmltype (details), '/ Anything/invoiceNumber') separate as invoices,
actinguserid as user_id, createdt
of bchistevent where bucket = 201301
and upper (type) = ' COM. AVOLENT. PRESENTATION. EVENT. INVOICEDOWNLOADEVENT'
- and bchistevent.bucket = to_char (add_months (sysdate-1), "YYYYMM")
000-395452969-20130103 1.46388193452398E37 08/01/2013 03:05:42
300000590-000-20090723 1.46388193452398E37 11/01/2013 08:11:45
300000590-000-20090723 1.46388193452398E37 11/01/2013 08:12:50
000-395453127-20130103 1.46388193452398E37 14/01/2013 04:44:26
* 300084670-000-20120906, 300084671-000-20120906 * 1.46388193452398E37 07/01/2013 12:45:19 AM
000-395452626-20130103 1.46388193452398E37 08/01/2013 03:03:57
000-300084679-20120906-1.46388193452398E37 11/01/2013 08:10:47
300000728-000-20090731 1.46388193452398E37 11/01/2013 08:19:19
000-300084679-20120906 1.46388193452398E37 14/01/2013 12:31:48 AM
300000590-000-20090723 1.46388193452398E37 14/01/2013 04:13:19
000-395452718-20130103 1.46388193452398E37 08/01/2013 07:10:19
000-300084679-20120906 1.46388193452398E37 23/01/2013 06:54:11
000-300084679-20120906 1.46388193452398E37 22/01/2013 03:11:54
300000590-000-20090723 1.46388193452398E37 11/01/2013 08:14:02
000-395453127-20130103 1.46388193452398E37 14/01/2013 04:33:12
000-300084679-20120906 1.46388193452398E37 22/01/2013 03:03:36
000-300084679-20120906 1.46388193452398E37 14/01/2013 12:34:13 AM
000-395452997-20130103 1.46388193452398E37 07/01/2013 03:31:38
000-395452391-20121027 1.46388193452398E37 03/01/2013 04:40:05
and the value of the "BOLD" highlighted line is coming in a single line, please help how to break this in 2 rows?
Published by: user1175303 on March 13, 2013 05:43user1175303 wrote:
the value of the column that is involved is300084670-000-20120906, 300084671-000-20120906 If you have XML question but try to solve in Oracle? Why
is the owner of two invoice numbers? In any case: with t as ( select distinct extractvalue(xmltype(details),'/Anything/invoiceNumber') as invoices, actinguserid as user_id, createdt from bchistevent where bucket = 201301 and upper(type) = 'COM.AVOLENT.PRESENTATION.EVENT.INVOICEDOWNLOADEVENT' ) select regexp_substr(invoices,'[^,]+',1,column_value) invoices, user_id, createdt from t, table( cast( multiset( select level from dual connect by level <= length(regexp_replace(invoices,'[^,]')) + 1 ) as sys.OdciNumberList ) ) /SY.
-
For all the records for each record double, I need to get a single column with null or 0.
Hi all
I have a requirement where I need to get all the records, for each record in double, I need to get a single column with null or 0.
create table a1
(
Identification number,
VARCHAR2 (100), the point
part varchar2 (100));
Insert into a1
values (1, 'ABC', 'A1');
Insert into a1
values (2, 'DEF', 'A2');
TABLE A
PART ITEM ID
1 ABC A1
1 ABC A1
1 ABC A1
DEF 2 A2
DEF 2 A2
3 DEF A2
O/P
PART ITEM ID
1 ABC A1
1 ABC 0
1 ABC 0
DEF 2 A2
2 DEF 0
3 DEF 0
Thanks in advance.
Thanks for your help FrankKalush...
This one will work.
WITH got_r_num AS
(
SELECT NVL (a1.id, a1.id) as id
NVL (a1.item, a1.item) AS element
NVL (a1.part, a1.part) IN the framework
a1.id AS a_id
ROW_NUMBER () OVER (PARTITION BY a1.id
ORDER BY NULL
) AS r_num
BY the a1
)
SELECT id
element
CASE
WHEN a_id IS NOT NULL
AND r_num = 1
THEN part
ELSE ' 0'
END in the framework
OF got_r_num
;
-
Convert a single column into multiple lines
Hi people,
I have a task to display a single column into multiple lines (for use in LOV)
For Ex:
The column consistes of value such as 98,78,67,68,34,90. -It's a unique column values where none of the values can be ' number that is separated by commas
Then we must view it as
98
78
67
68
34
90
-under the number of lines (no lines can be ' do not number).
Thanks in advanceTry this...
SQL> ed Wrote file afiedt.buf 1 select regexp_substr('98,78,67,68,34,90', '[^,]+',1,level) Value 2 from dual 3* connect by level <= regexp_count('98,78,67,68,34,90',',') + 1 SQL> / VALUE ----------------- 98 78 67 68 34 90 6 rows selected.Thank you!
-
Single line based on two columns and a single column
Dear members,
I have a table that contains duplicate rows, for which a request should be able to extract the unique row in the table. Here the unique is not based on a single column, but it should be in two columns and also check on the uniqueness on a column.
create table addr (varchar2 (10) firstname, lastname varchar2 (10), area varchar2 (3));
insert into values addr ('bob', 'james', 1');
insert into values addr ('bob', 'james', 1');
insert into values addr ('harry', 'bert', ' 1');
insert into values addr ('jimmy', 'bert', ' 1');
insert into values addr ('sam', 'mac', '1');
insert into values addr ('sam', 'Knight', '1');
insert into values addr ('tom', 'sand', '1');
insert into values addr ("cat", "mud", "1");
The query output must contain 3 lines.
Bob - james
Harry - bert or jimmy - bert [or the other of them], but not both
-Mac or sam - Sam Knight [or the other of them], but not both
Tom - sand
Cat - mud
SELECT firstname, lastname as total area WHERE addr = '1' GROUP by firstname, lastname; It takes no duplication of single column...
Any suggestions...SQL> with t_data as ( select 'bob' as firstname, 'james' as lastname, '1' as area from dual union all select 'bob', 'james', '1' from dual union all select 'harry', 'bert', '1' from dual union all select 'jimmy', 'bert', '1' from dual union all select 'sam', 'mac', '1' from dual union all select 'sam', 'knight', '1' from dual union all select 'tom', 'sand', '1' from dual union all select 'cat', 'mud', '1' from dual ) SELECT firstname, lastname, area FROM ( SELECT t.*, row_number() over(partition BY firstname order by 1) rn, row_number() over(partition BY lastname order by 1) rn1 FROM t_data t ) WHERE rn = 1 AND rn1 =1 ; FIRSTNAME LASTNAME AREA --------------- --------------- ---------- bob james 1 cat mud 1 jimmy bert 1 sam knight 1 tom sand 1 SQL> -
View all in a single column, instead of lines (part 1)
Hi all
Help, please...
I have a table: EMP & 3 columns: ID, ENAME, and BIRTHDAY.How to make my lines of output SQL to display on a single column?
I inserted 3 rows in the table:
ID ENAME BIRTHDAY
1 Smith 11/09/1980
2 Jones 01/01/1981
3 Baker 02/02/1982
EmployeesI want the output of my query in Oracle Developer / ApEx to display like this:
---------------
Smith
11/09/1980
Jones
01/01/1981
Baker
02/02/1982
Best regards
Sunenny
Published by: user643233 on November 6, 2008 09:10Strange formatting. Maybe you could try something like this...
Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production SQL> CREATE OR REPLACE TYPE varchar2_table AS TABLE OF VARCHAR2 (4000); 2 / Type created. SQL> SELECT column_value 2 FROM emps, TABLE (varchar2_table (NULL, ename, hiredate)); COLUMN_VALUE -------------------------------------------------------------------------------- SMITH 17-DEC-80 ALLEN 20-FEB-81 WARD 22-FEB-81 JONES 02-APR-81 MARTIN 28-SEP-81 BLAKE 01-MAY-81 CLARK 09-JUN-81 SCOTT 19-APR-87 KING 17-NOV-81 TURNER 08-SEP-81 ADAMS 23-MAY-87 JAMES 03-DEC-81 FORD 03-DEC-81 MILLER 23-JAN-82 42 rows selected. SQL> -
Hello
I need to split into single column in the format below:
SELECT '6500,1100,3200,1233,9000' FROM DUAL;
Result:
6500
1100
3200
1233
9000
For 11g and above:
Select regexp_substr (6500, 1100, 3200, 1233, 9000', ' [^,] +', 1, level) suite
of the double
connect by level<= regexp_count('6500,1100,3200,1233,9000',="" ',')="" +="">
For 10g:
Select regexp_substr (6500, 1100, 3200, 1233, 9000', ' [^,] +', 1, level) suite
of the double
connect by level<= length="" (regexp_replace="" ('6500,1100,3200,1233,9000',="" '[^,]+'))="" +="">
or (if there is no empty entries):
Select regexp_substr (6500, 1100, 3200, 1233, 9000', ' [^,] +', 1, level) suite
of the double
connect regexp_substr (6500, 1100, 3200, 1233, 9000', ' [^,] +', 1, level) is not null
RESULT 6500 1100 3200 1233 9000 5 selected lines.
-
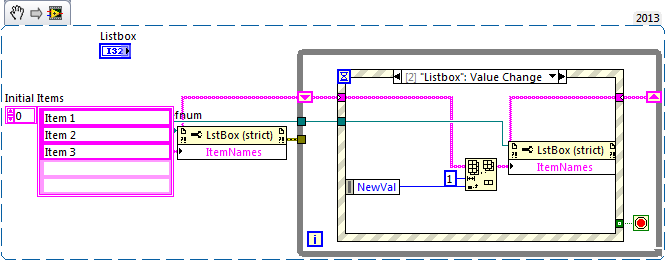
Remove the clicked point of Listbox (single column)
Hello
It seems a lot of posts on clear lines of the programmatically multicolumn listbox but not the only column listboxes.
Woth the help of Martins and GerdW, helped me build a subset of a ListBox with items clicked in a reference list
Make a table of items clicked in a list
. How it adds a feature to delete just in case rather than the deletion of the entire list and do it all over again.
Thanks in advance.
Have an array of strings to the "REF" enter in the list box and store it on a shift register. When you remove an item (for example, for an event), remove this item from the list (using the removal of the table) and write back to the property Ref of the listbox. A single-column list box works exactly the same way as a multicolumn listbox.
(Excuse the broken links to properties - what happens when you create an excerpt)
-
Two foreign keys of a table in a single column
Hi gurus
I wonder that can we add two foreign keys of a table on a single column, I think the answer is, but what should be the reason behind this?
Appreciate if someone there explain to me...
Concerning
Muzz
Hello Muzz,
Perhaps the example of human Chen reveals a design error.
If a student has a 'teacher_id' "teacher" FK and FK for "emp" becaue each teacher is an EMP, I guess that the correct design would be to have only the FK of 'teacher' and to have another pointing to the 'emp' table in the 'teacher' tabe FKBut we can imagine comical situations...
CREATE TABLE PEOPLE (id NUMBER of KEY PRIMARY, name VARCHAR2 (20 CHAR),...);
CREATE TABLE SCIENTIST (id people KEY PRIMARY NUMBER (id) REFERENCES, discipline VARCHAR2 (20 CHAR),...);
CREATE TABLE POLICEMAN (id REFERENCES to KEY PRIMARY NUMBER (id), hire_date people DATE,...);First table = all.
2nd: a subset of the first, with people having the profile of 'scientific '...
3rd: a subset of the first, with people being a policeman.
It might be people first table and in none of the 2nd and 3rd, 1st and 2nd, 1st and 3rd only or in the 3 tables.Then we can have a fourth table of 'something' referring to a person who must be a scientist and a police officer.
Here is a sqlplus session illustrating; the last piece: I try inserting several lines in xxxx, only the last is accepted.
SQL > CREATE TABLE PEOPLE (id NUMBER of the PRIMARY KEY, name VARCHAR2 (20 CHAR));
Table created.SQL > CREATE TABLE SCIENTIST (people of REFERENCES of KEY PRIMARY NUMBER id (id), discipline VARCHAR2 (20 CHAR));
Table created.SQL > CREATE TABLE POLICEMAN (people of REFERENCES of KEY PRIMARY NUMBER id (id), DATE hire_date);
Table created.SQL > CREATE TABLE XXXX (id PRIMARY KEY NUMBER, people_id NUMBER, any other VARCHAR2 (30 CHAR));
Table created.SQL > ALTER TABLE ADD CONSTRAiNT fk_xxsci FOREIGN KEY (people_id) scientific xxxx REFERENCES (id);
Modified table.SQL > ALTER TABLE ADD CONSTRAiNT fk_xxpol FOREIGN KEY (people_id) police xxxx REFERENCES (id);
Modified table.SQL > INSERT INTO person VALUES (100, 'John');
1 line of creation.SQL > INSERT INTO person VALUES (120, 'Mary');
1 line of creation.SQL > INSERT INTO person VALUES (103, 'Tom');
1 line of creation.SQL > INSERT INTO person VALUES (123, "Bruno");
1 line of creation.SQL > INSERT INTO VALUES of scientific (120, 'Chemistry');
1 line of creation.SQL > INSERT INTO scientific VALUES (123, 'Mathematics');
1 line of creation.SQL > INSERT INTO VALUES of policeman (103, DATE ' 2001-04-01');
1 line of creation.SQL > INSERT INTO VALUES of policeman (123, DATE ' 1998-07-01');
1 line of creation.SQL > INSERT INTO xxxx VALUES (1, 456, "nothing");
ERROR on line 1:
ORA-02291: integrity constraint (SYS. FK_XXPOL) violated - key parent not foundSQL > INSERT INTO xxxx VALUES (1, 100, "only to people");
ORA-02291: integrity constraint (SYS. FK_XXPOL) violated - key parent not foundSQL > INSERT INTO xxxx VALUES (1, 120, "only the learned");
ORA-02291: integrity constraint (SYS. FK_XXPOL) violated - key parent not foundSQL > INSERT INTO xxxx VALUES (1, 103, "only police officer");
ORA-02291: integrity constraint (SYS. FK_XXSCI) violated - key parent not foundSQL > INSERT INTO xxxx VALUES (1, 123, 'ok');
1 line of creation.Best regards
Bruno Vroman.

Maybe you are looking for
-
Sierra Siri, «I have some problems with the connection...» »
Guys, I just installed Sierra on my MacBook Pro (retina, 13 inches, early 2015) version 10.12. I can't get Siri at work, the app tracks, he hears what I'm saying, but after awhile, he returns with two messages, both on the screen and verbally "I have
-
FN keys do not work on my Satellite L505
I use the new Windows 7 and have no programs of Toshiba and cannot open the FN + F8, F9 keys.Why do they work?What should I do? Pls help!Answer pls clearly what I understand!
-
implementation of text messages
How do I change text to read one message instead of conversation? Is there a way to set a reminder for unopened messages?
-
Hello Does anyone know what type of glass, we have face and back bones xperia Z2? I can't find information anywhere... Thank you
-
Windows 7 - print white line: alert words
Original title: when I print I am gitting I crossed out all the words on the page white help please