NIC Teaming best practices
Hello
I have 1 server that has ports gigabit 8 inside. There will be 6 VLAN (including VLAN ID 4095) inside this ESX Server. Is it best practice to all gigabit 8 ports combine and link to vSwitch0 (default) and create the Group of ports by VLAN?
Kind regards
T.S.
is absolutely not a stupid question
Only for safety and performance. You can use configuration grouping in both cases. (2 NICs for sc and vmotion and 4 NICs for vlan tag vm)
Keep this is to undertatnd that it is not an absolutely answare, but only a best practice, and that's OK as your design.
I thank Alberto
Tags: VMware
Similar Questions
-
10 GB NIC redundancy-Best Practice
Hi all
I have now deployed successfully to the 5 different poles of vSphere using 4 x 1 GB network adapters on all servers to ESX/ESXi hosts. I used 2 active/passive NIC in vSwitch0 vMotion and network management traffic (or Service Console for ESX) and used 2 active/active NIC in vSwitch1 for VM traffic as shown below. The uplinks are using 802. 1 q trunks in redundant Cisco switches.
We are now moving to 10 GB networks. I have the opportunity to use this same design of map NETWORK 4 (using the HP Flex 10 vNIC or cards Cisco Palo) or go with a simpler model of map NETWORK 2. What is the recommended best practice to separate VMkernel Port and port VM group traffic among the physical network interface cards? Any suggestions or links to published documents would be greatly appreciated of VMware.
Thank you!

Take a look at my post here. https://www.myciscocommunity.com/message/63033#63033
Can help you with your design questions. There is also a generic 'best practice' guide for 10G networks & VMware environments.
As Cisco I obviously partial to the Palo adapter. Unlike the Flex-10 option you set up not a bandwidth 'max' virtual NETWORK card, rather, you set a guarantee min. for each virtual host NIC given that you can create multiple network cards virtual with Palo, you can create one for VMotion, VM data, IP storage, etc. and define your QoS guarantees quickly & easily while offering redundancy with the recovery of host-transparent fabric.
Let us know if you have specific questions about a deployment.
Kind regards
Robert
-
Oracle on NetApp - white paper best practices?
I thought I saw a nice whitepaper "best practices" that Oracle published to operate the RDBMS on NetApp.
But I can't seem to find now. Does anyone have a link?
(I access Metalink if it is there, but my search didn't find it).
Thank you!The doc I have comes actually from NetApp, not Oracle. It is titled: NetApp Best Practice Guidelines for Oracle
You can find a copy here: http://media.netapp.com/documents/tr-3633.pdf
See you soon,.
Brian -
Best practices for call code plsql and methods of application module
In my application I am experience problems with the connection pool, I seem to use a lot of connections in my application when only a few users are using the system. As part of our application, we need to call procedures of database for the business logic.
Our support beans, calls the methods of the module of the application calling to turn a database procedure. For example, in the bean to support, we have code as follows to call the method of module of the application.
Component Module to generate new review/test.
CIGAppModuleImpl appMod = (CIGAppModuleImpl) Configuration.createRootApplicationModule ("ky.gov.exam.model.CIGAppModule", "CIGAppModuleLocal");
String testId = appMod.createTest (username, examId, centerId) m:System.NET.SocketAddress.ToString ();
AdfFacesContext.getCurrentInstance () .getPageFlowScope () .put ("tid", testId);
Close call
System.out.println ("delete Calling releaseRootApplicationModule");
Configuration.releaseRootApplicationModule (appMod, true);
System.out.println ("Completed releaseRootApplicationModule delete");
Return returnResult;
In the method of application module, we have the following code.
System.out.println ("CIGAppModuleImpl: call the database and use the value of the iterator");
CallableStatement cs = null;
try {}
CS = getDBTransaction () .createCallableStatement ("start?: = macilap.user_admin.new_test_init(?,?,?);") end; ", 0) ;
cs.registerOutParameter (1, Types.NUMERIC);
cs.setString (2, p_userId);
cs.setString (3, p_examId);
cs.setString (4, p_centerId);
cs.executeUpdate ();
returnResult = cs.getInt (1);
System.out.println ("CIGAppModuleImpl.createTest: return result is" + returnResult);
} catch (SQLException to) {}
throw new Aexception.getLocalizedMessage (se);
}
{Finally
If (cs! = null) {}
try {}
CS. Close();
}
catch (SQLException s) {}
throw new Aexception.getLocalizedMessage (s);
}
}
}
I read in one of the presentations of Steve Muench (Oracle Fusion Applications Team' best practices) that the call of the method createRootApplicationModule is a bad idea and call the method via the link interface.
I guess that the call of the createRootApplicationModule uses a lot more resources and connections to database as the call to the method via the link interface such as
BindingContainer links = getBindings();
OperationBinding ob = bindings.getOperationBinding("customMethod");
Object result = ob.execute)
Is this the case? Also use getDBTransaction () .createCallableStatement the best average of calls to database procedures. Would it not be better to expose plsql packages such as Web services and then call from the applicationModule. Is it more effective?
Concerning
OrlandoHe must show them.
But to work around the problem, try this - drag method of the data control to your page and the fall as a button.
Then go to the source of the JSPX view and remove the button from there - if it comes to the display of the source - the link must remain in your pagedef. -
vSpere 5 Networking of best practices for the use of 4 to 1 GB NIC?
Hello
I'm looking for a networking of best practices for the use of 4-1 GB NIC with vSphere 5. I know there are a lot of good practice using 10 GB, but our current config does support only 1 GB. I need to include the management, vMotion, Virtual Machine (VM) and iSCSi. If there are others you would recommend, please let me know.
I found a diagram that resembles what I need, but it's for 10 GB. I think it works...
 (I had this pattern HERE - rights go to Paul Kelly)
(I had this pattern HERE - rights go to Paul Kelly)My next question is how much of a traffic load is each object take through the network, percentage wise?
For example, 'Management' is very small and the only time where it is in use is during the installation of the agent. Then it uses 70%.
I need the percentage of bandwidth, if possible.
If anyone out there can help me, that would be so awesome.
Thank you!
-Erich
Without knowing your environment, it would be impossible to give you an idea of the uses of bandwidth.
That said if you had about 10-15 virtual machines per host with this configuration, you should be fine.
Sent from my iPhone
-
What is the best practice for the double management interfaces?
Hello community!
I'm upgrading to a few host ESX to ESXi 4.1U1 4.0 in the coming weeks. My question is about how to configure the management networks. Obviously in ESX 4.0 Classic I have a Service Console port (on vSwitch0) group and a group of ports VMkernel (also on vSwitch0) which provides my host with SC and vmotion capabilities, as we all know. Note: my vSwitch0 has two vmnic attached to it, is pending and is active. That's just how we have our double installation of switches, so it must be active / standby.
I got to thinking (book the great from HA and DRS deepdive Duncap Epping and Frank Denneman), that I should consider carefully when my network mangement I improve these hosts to ESXi 4.1 - which of course done away with the Service Console and use the vmkernel instead.
The question is, in which best practices and account with my setup: I have two vmkernel ports? If so, how should I configure each for traffic management and vmotion vmkernel?
I think it will be a good discussion to have.
Thank you all,
Matt
The NIC vSwitch0 value active/active, the vswif (and future vmkernel management) team of NIC Active vmnic6 and vmnic1 ensures and leaves the vMotion vmkernel NIC team as is.
This will allow you to use two physical network interface cards at the same time while having a failover plan and keep your physically separate management and vMotion traffic.
In the end:
vSwitch: vmnic1 vmnic6 active, active.
VMK (Mgt): active eve of vmnic1 vmnic6.
VMK (vMotion): active standby, vmnic6 vmnic1.
-
Best practices for the installation of 10 GbE
I have a new HP DL380G7 who has 4 cards on 1 G and 2 10 network interface cards.
This will run VSphere 4.1 esxi
I'm looking for some advice on what would be a good network for this server configuration.
The storage will be NFS goes to a NAS Server
I tried to create 2 vswitch one with one of the NICs embedded for the service console and the other switch was a team of the 10G env.
Support Vmware told me that in this configuration, I had to make sure that the service console was on a different subnet from the kernel NFS or NFS traffic will try to go on the service console port.
I tried this config but as soon as I add a Vkernel to the 2nd switch I am not out ping.
So I thought I'd post here with what would be a best practice configuration for this server.
In the first configuration, it is difficult to say which interface will be used for NFS traffic. Therefore, it is not a recommended configuration.
The second configuration must be correct.
-
Hello group,
I have two boxes of esx with 4 NICs in each.
Currently, I am only using two of the four NICs for each box of esx.
I use 1 for the core of the vm network adapter and 1 network card for the service console of network/vm for each box of esx.
How do you propose that I take two network cards available for every box of physics.
If I create a team for the network of the vm, I can do on the fly, and what I have to do something about guests?
Also, I read that this grouping only works for outbound traffic? Can someone explain?
Thanks in advance!
Best practice would be to have redundancy for the network of the virtual machine and the management network - you can do it on the fly and nothing should be done to guests (which I assume you mean virtual machines) with settings by default, you must restart the virtual machines to take advantage of the second NETWORK card - until then you'll have to gas be in active standby mode.
Outgoing is only an indication that the ESX Server has no control on the inbound traffic - it can select which network of phyiscal card to send traffic
If you find this or any other answer useful please consider awarding points marking the answer correct or useful
-
Material LV real-time Ethernet com best practices
Hello
I just started to learn the LV in real-time, and until I get a new cRIO I just played with a former PSC-2220.
Everything works, I am reading the tutorals nice about RT and deployment/running example to this target applications.
However, I don't know what is the best practice, the IP address of this device handling. For easy installation, after a device reset (and install the new RT runtimes, etc) I put just the HW to obtain the dynamic IP address of my router (DHCP). My laptop connects to the same router via wifi.
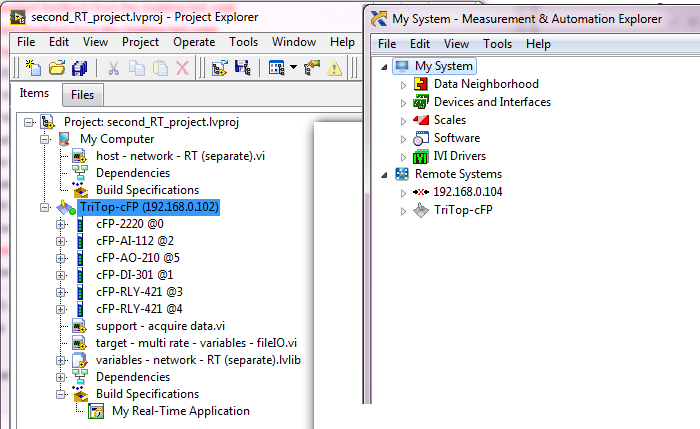
However, since after a few resets the target Gets a new IP (192.168.0.102, previous IP was... (104), I have to manually change the IP address in my project. Is it possible that the LV auto detects the target in my project? In addition, it seems that MAX retains the old information and creates a new line for the same target... so I guess that if the problem persists, MAX is going to fill?
 See screenshots below.
See screenshots below.As a solution, I'll try to use static IP for the target, so it must always use the same IP address.
What is the common procedure to avoid this kind of problems? Just using static IP? Or miss me him too something else here?
Thank you!
I just always use static IP addresses. It avoids just all kinds of questions, especially if you have several systems on the same network.
-
Dell MD3620i connect to vmware - best practices
Hello community,
I bought a Dell MD3620i with 2 x ports Ethernet 10Gbase-T on each controller (2 x controllers).
My vmware environment consists of 2 x ESXi hosts (each with 2ports x 1Gbase-T) and a HP Lefthand (also 1Gbase-T) storage. The switches I have are the Cisco3750 who have only 1Gbase-T Ethernet.
I'll replace this HP storage with DELL storage.
As I have never worked with stores of DELL, I need your help in answering my questions:1. What is the best practices to connect to vmware at the Dell MD3620i hosts?
2. What is the process to create a LUN?
3. can I create more LUNS on a single disk group? or is the best practice to create a LUN on a group?
4. how to configure iSCSI 10GBase-T working on the 1 Gbit/s switch ports?
5 is the best practice to connect the Dell MD3620i directly to vmware without switch hosts?
6. the old iscsi on HP storage is in another network, I can do vmotion to move all the VMS in an iSCSI network to another, and then change the IP addresses iSCSI on vmware virtual machines uninterrupted hosts?
7. can I combine the two iSCSI ports to an interface of 2 Gbps to conenct to the switch? I use two switches, so I want to connect each controller to each switch limit their interfaces to 2 Gbps. My Question is, would be controller switched to another controller if the Ethernet link is located on the switch? (in which case a single reboot switch)Tahnks in advanse!
Basics of TCP/IP: a computer cannot connect to 2 different networks (isolated) (e.g. 2 directly attached the cables between the server and an iSCSI port SAN) who share the same subnet.
The corruption of data is very likely if you share the same vlan for iSCSI, however, performance and overall reliability would be affected.
With a MD3620i, here are some configuration scenarios using the factory default subnets (and for DAS configurations I have added 4 additional subnets):
Single switch (not recommended because the switch becomes your single point of failure):
Controller 0:
iSCSI port 0: 192.168.130.101
iSCSI port 1: 192.168.131.101
iSCSI port 2: 192.168.132.101
iSCSI port 4: 192.168.133.101
Controller 1:
iSCSI port 0: 192.168.130.102
iSCSI port 1: 192.168.131.102
iSCSI port 2: 192.168.132.102
iSCSI port 4: 192.168.133.102
Server 1:
iSCSI NIC 0: 192.168.130.110
iSCSI NIC 1: 192.168.131.110
iSCSI NIC 2: 192.168.132.110
iSCSI NIC 3: 192.168.133.110
Server 2:
All ports plug 1 switch (obviously).
If you only want to use the 2 NICs for iSCSI, have new server 1 Server subnet 130 and 131 and the use of the server 2 132 and 133, 3 then uses 130 and 131. This distributes the load of the e/s between the ports of iSCSI on the SAN.
Two switches (a VLAN for all iSCSI ports on this switch if):
NOTE: Do NOT link switches together. This avoids problems that occur on a switch does not affect the other switch.
Controller 0:
iSCSI port 0: 192.168.130.101-> for switch 1
iSCSI port 1: 192.168.131.101-> to switch 2
iSCSI port 2: 192.168.132.101-> for switch 1
iSCSI port 4: 192.168.133.101-> to switch 2
Controller 1:
iSCSI port 0: 192.168.130.102-> for switch 1
iSCSI port 1: 192.168.131.102-> to switch 2
iSCSI port 2: 192.168.132.102-> for switch 1
iSCSI port 4: 192.168.133.102-> to switch 2
Server 1:
iSCSI NIC 0: 192.168.130.110-> for switch 1
iSCSI NIC 1: 192.168.131.110-> to switch 2
iSCSI NIC 2: 192.168.132.110-> for switch 1
iSCSI NIC 3: 192.168.133.110-> to switch 2
Server 2:
Same note on the use of only 2 cards per server for iSCSI. In this configuration each server will always use two switches so that a failure of the switch should not take down your server iSCSI connectivity.
Quad switches (or 2 VLAN on each of the 2 switches above):
iSCSI port 0: 192.168.130.101-> for switch 1
iSCSI port 1: 192.168.131.101-> to switch 2
iSCSI port 2: 192.168.132.101-> switch 3
iSCSI port 4: 192.168.133.101-> at 4 switch
Controller 1:
iSCSI port 0: 192.168.130.102-> for switch 1
iSCSI port 1: 192.168.131.102-> to switch 2
iSCSI port 2: 192.168.132.102-> switch 3
iSCSI port 4: 192.168.133.102-> at 4 switch
Server 1:
iSCSI NIC 0: 192.168.130.110-> for switch 1
iSCSI NIC 1: 192.168.131.110-> to switch 2
iSCSI NIC 2: 192.168.132.110-> switch 3
iSCSI NIC 3: 192.168.133.110-> at 4 switch
Server 2:
In this case using 2 NICs per server is the first server uses the first 2 switches and the second server uses the second series of switches.
Join directly:
iSCSI port 0: 192.168.130.101-> server iSCSI NIC 1 (on an example of 192.168.130.110 IP)
iSCSI port 1: 192.168.131.101-> server iSCSI NIC 2 (on an example of 192.168.131.110 IP)
iSCSI port 2: 192.168.132.101-> server iSCSI NIC 3 (on an example of 192.168.132.110 IP)
iSCSI port 4: 192.168.133.101-> server iSCSI NIC 4 (on an example of 192.168.133.110 IP)
Controller 1:
iSCSI port 0: 192.168.134.102-> server iSCSI NIC 5 (on an example of 192.168.134.110 IP)
iSCSI port 1: 192.168.135.102-> server iSCSI NIC 6 (on an example of 192.168.135.110 IP)
iSCSI port 2: 192.168.136.102-> server iSCSI NIC 7 (on an example of 192.168.136.110 IP)
iSCSI port 4: 192.168.137.102-> server iSCSI NIC 8 (on an example of 192.168.137.110 IP)
I left just 4 subnets controller 1 on the '102' IPs for more easy changing future.
-
Best practices to configure NLB for Secure Gateway and Web access
Hi team,
I'm vworksapce the facility and looking for guidance on best practices on NLB with webaccess and secure gateway. My hosted environment is Hyper-v 2012R2
My first request is it must be configure NLB, firstly that the role of set up or vice versa.
do we not have any document of best practice to configure NLB with 2 node web access server.
Hello
This video series has been created for 7.5 and 2008r2 but must still be valid for what you are doing today:
https://support.software.Dell.com/vWorkspace/KB/87780
Thank you, Andrew.
-
Best Practice Guide for stacked N3024 switches
Is there a guide to BP for the configuration of the 2 N3024s stacked for the connections to the server, or is the same eql iscsi configuration guide.
I'm trying to:
1) reduce to a single point of failure for rack.
(2) make good use of LACP for 2 and 4 nic server connections
(3) use a 5224 with it's 1 lacp-> n3024s for devices of unique connection point (ie: internet router)
TIA
Jim...
Barrett pointed out many of the common practices suggested for stacking. The best practice is to use a loop for stacking and distributing your LAG on multiple switches in the stack, are not specific to any brand or model of the switch. The steps described in the guides of the user or the white papers generally what is the recommended configuration.
http://Dell.to/20sLnncMany of the best practices scenarios will change of network-to-network based around what is currently plugged into the switch, and the independent networks needs / requirements of business. This has created a scenario where the default settings on a switch are pre-programmed for what is optimal for a fresh switch. Then recommended are described in detail in white papers for specific and not centralized scenarios in a single document of best practices that attempts to cover all scenarios.
Express.ypH N-series switches are:
-RSTP is enabled by default.
-Green eee-mode is disabled by default.
-Frother is enabled by default.
-Storm control is disabled by default.Then these things can change based on the towed gear and needs/desires of the whole of society.
For example, Equallogic has several guides that recommendations of configuration detail to different switches.
http://Dell.to/1ICQhFXThen on the side server, you would like to look more like the OS/server role. For example a whitepaper VMware that has some network settings proposed when running VMware in an iSCSI environment.
http://bit.LY/2ach2I7I suggest making a list of the technology/hardware/software, which is used on the network. Then use this list to acquire white papers for specific areas. Then use these white papers best practices in order to ensure the switch configuration is optimal for the task required by the network.
-
Best practices to follow before firmware Equallogic disk Upgradation
Hi team,
I have two Equallogic running in the same group and the default storage unique pool. Old eql is seen RAID 5 and another more recent is RAID 6. Both have 12 600 GB discs. Last week we Club the two EQL in the same group. Everything went well. Current firmware is on the two eql 6.0.9.
We add the group to the HQ of SAN. Now SAN HQ is showing constant alert of the firmware of the drive is obsolete for EQL OLD.
Please let me know what are best practice before any firmware place a gradation of the EQL disc.
necessary downtime.
No downtime is needed. We do it on our production VM 300 vSphere cluster.
Kind regards
Joerg
-
Best practices for the Manager of the Ucs to the smooth running of our environment
Hi team
We are remaining with data center with Cisco Ucs blades. I want the best practices guide Ucs Manager Manager of Ucs check all things configured correctly in accordance with the recommendation of Cisco and standard to the smooth running of the environment.
A certain provide suggestions. Thank youHey Mohan,.
Take a look at the following links. They should provide an overview of the information you are looking for:
http://www.Cisco.com/c/en/us/products/collateral/servers-unified-computi...
http://www.Cisco.com/c/en/us/support/servers-unified-computing/UCS-manag...
HTH,
Wes
-
OEM 12 c Best Practice follow-up 11.1 DB RAC env. + datagurd
OEM 12 c 5 release is the only monitoring in our environment... is there a better model of practice on what aspects need to be monitored and their default values?
This doc for 12 c DB is very useful, it's best practices for high availability. They talk a lot about the RAC/DG monitoring. https://docs.Oracle.com/database/121/HABPT/monitor.htm#HABPT003
version 11.2 is here https://docs.oracle.com/cd/E11882_01/server.112/e10803/monitor.htm#g1011041, I read them both though, as there are some new features in version 12 c who may still apply to 11 g.
Regarding the parameters/models go, if you create a template of the target type (monitoring sc_results.php-> create-select target type-> type > select category/target), this will include all the parameters of the type of target (including the CEO) and as close as you'll have to 'default thresholds' Oracle. It is the best branch of the teams effort produced. Of course, they will not be perfect for everyone, but it's a starting point!


Maybe you are looking for
-
Is the last protégé of Firefox geolocation search machines?
There is a link I found on the Forum which was a bit like "subject: location" or something like that blackened being located geographically on Firefox. I lost it in my notes. Anyone know it? I now have the latest version of Firefox. The latest versio
-
show e-mail address during the composition of new e-mails, mail OS 10.10.5 v.8.2
How to show the email address I sent you of when composing new emails, mail OS 10.10.5 v.8.2
-
Have 4 GB of RAM on Satellite U400 but says OS only have 2 GB
Have recently downgraded notebook Toshiba Satellite U400 (model PSU44A-00J00C) of original Windows Vista business to Windows XP Pro (pack 3 update service) assistance of the system recovery discs. Have 4 GB of RAM installed on the laptop with 32-bit
-
I would rather not re - write the old of the IDE I have used for years but rather replace them with the style sheets for xml/html/web. Konqueror is running locally the binary with a launcher script. Firefox, Chrome, re-Konq, WebPositive and IE Explor
-
Original title : Double click on icon it does not open and when I right click it Office of the menu drop-down does not appear. Programs can always be started through the list of programs.