No response to the events of the cluster.
Hi all
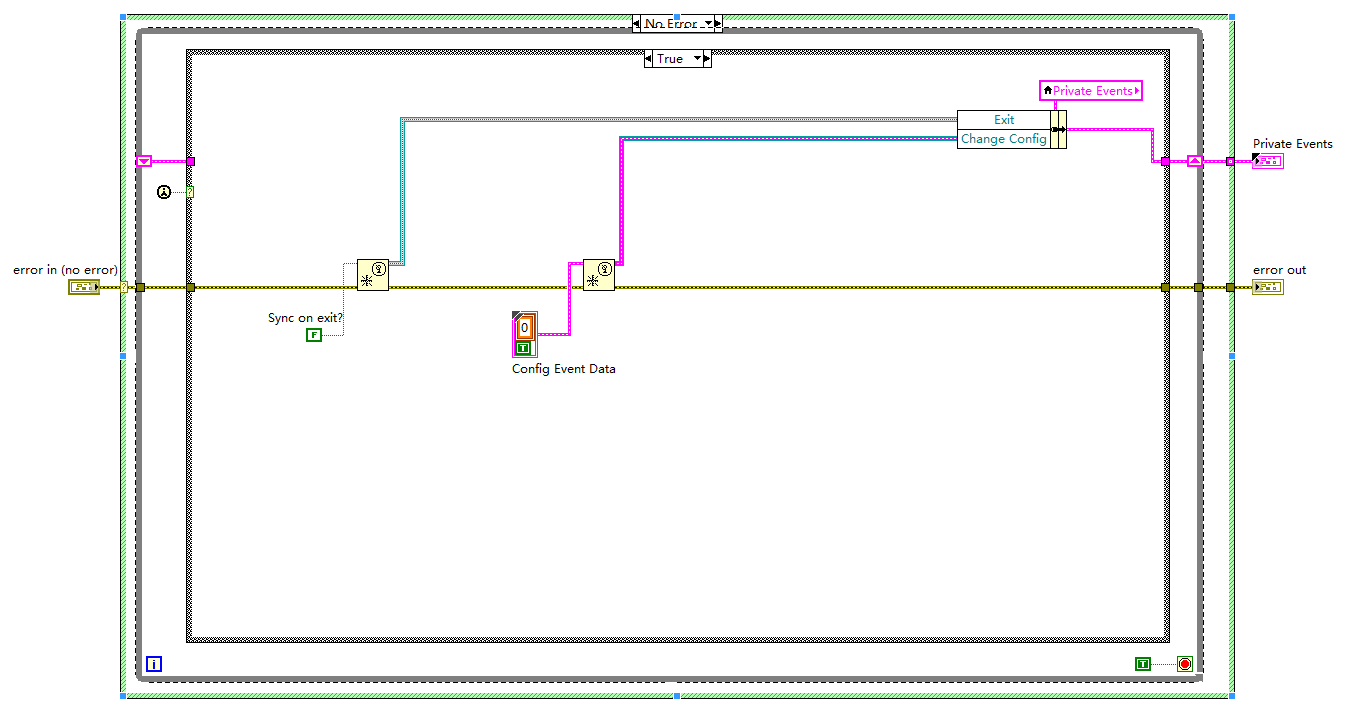
I am preparing for the CLD and find a problem with the exercise of ATM Simulator as shown in the attached file.
Please follow the below steps to reproduce this problem.
1 extract the files.
2. open atm.lvproj, and then run main.vi.
3 press card Simulator to enable user input.
4. put 12345 in user input, and then press ENTER.
5. left and right menu will display its function and you should be able to press the left and right, but they have no answer to your intervention.
If you have an idea, please share it with goodness.
Please note that I use LV2010, but I'm going down my code to 8.5 so that we can share more.
Sincerely, Kate
There are serious problems with dataflow doe to wrong choice of program design.
You shouldn't ever have event inside the strctures case structures, especially structures event, each in a situation different from the structure of the case. Event structures are not dataflow leads, so they queue of events even if there is now way to the service of the event due to issues of data flow. Your events are defined to lock the front until the end of the event, so any event that cannot be handled by the program crashes to the top of the façade for ever.
So: Get rid of the box structure and use a structure of single event with several instances of the event. That should be all you need. The structure of the event should be directly on the diagram of the while loop. Simplify! Put your business structure housing unique timeout and modulate the duration of the time-out period by an if necessary shift register.
A good tool is also highlighted. Use the VI while looking at the chart in Slow Motion. You'll see where it gets stuck.
Tags: NI Software
Similar Questions
-
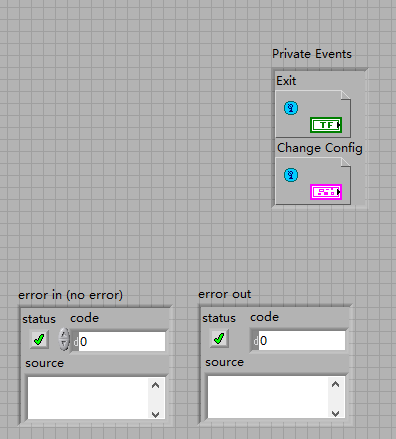
shows how to create the cluster of refnum user event
I try to understand and copy this sup - VI, but I have problem in the construction of this cluster of refnum user event, and how to build the local variable?
\
It looks like your confusion comes from not knowing how to make a group of data, it's an accurate observation?
To a cluster, you must create an empty cluster and new drag and drop in the cluster. In this case, how to make a refnum of the event, which is the right type of data, you must follow these steps:
- Set up the user event create with datatype.
- Right-click in the output, and then click on create Constant. This constant is now your refnum of correct data type
- Drag the new constant to a cluster to add it to the cluster. This could be within your DataSet defined Type called "Private Events" or another cluster.
If you change the data type of your event, the wires that connect this event to the cluster of data interrupts the measure where you will have a data type mismatch.
-
How to transform a cluster of 3 elements in a table 1 d of the Cluster of 3 elements?
I have an output of the ".vi SVFA frequency response (Phase-Mag) ' a 'group of 3 elements' and I need this fuel parameters modal 'MP_LSCE.vi', which takes a" table of cluster of 3 elements 1 D' any help appreciated. " So...
Cluster of 3 elements---> table 1 d of the Cluster of 3 elements
Use the Array function to build with just the single entry.
Steve
-
Hexadecimal string of Conversion of the Cluster
Hello
I need to convert a string to a 32-bit integer,
the 32-bit Hex input is read from a file (ex: 0x0012334A). Since this value required to contribute to an inorder to Cluster Bundle send using CAN protocol.
How to convert this and pour into the cluster of data?
Someone please comment on this.
Please find the attachment for the block diagram.
-mfp.
Have you not read my answer and looked at the attached vi?
Give you one more time

EDIT: didn't see your last response. See the VI attached and sorry
-
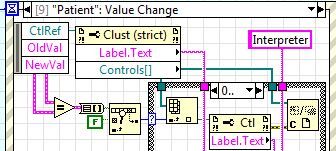
obtain the cluster when it is changed
Hi all
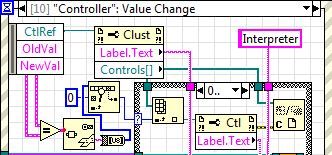
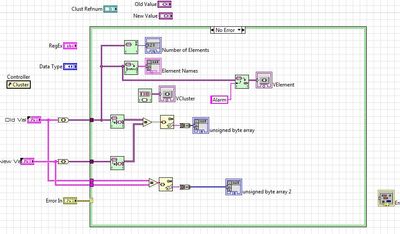
IAM interested in knowning (after that the user changes the value of a cluster) which element within a cluster (any type of cluster) has been changed.
If in a case of event structure (the NOMCLUSTER value change) I can get ctl, old val, val new Ref.
On the other side, I would get the refnum or the name
I know that old and new val will be Variant (on my function) so that I can accommodate for any cluster. I opened G installed on my machine and looked at the data palette open G LV as well as a secondary Vcluster and have not been able to do.
Here is an example of a given cluster
Here is another example of a cluster:
I was able to do this in two different ways (always know before hand in the cluster.
Method:
Second method:
This is the skeleton of the function of iam trying to build (test different possibilities):
So far I've failed at this.
any help will be apreaciated.
Kind regards
Try this
-
Writing only to certain parts of the cluster in an array by reference
Hello
I have an array of clusters that I use as well to view and enter data, i.e. elements of the cluster are unmodifiable (disabled) controls used as indicators of "false" (numeric values, strings, LEDs) and some are normal witnesses (numerical values, buttons).
The "indicator" part of this cluster table must be constantly updated (for example with the positions of the engines), normally by replacing the elements according to cluster in a loop and writing in the table. This can lead to conditions of race with the part 'control': If the user enters data in a 'bad' timing control, it gets immediately replaced by the old value - in this case the update process began just before the user input and completed just after the entrance of (which may be a simple click is enough) , so the old values of controls are rewritten on user controls, as the table should be rewritten as a whole.
Now, I'm looking for a solution to this critical race condition without changing this 'mixed' approach of control/indicator (e.g. by control and indicator tables separated next to each other and paired scrolling or so - which would make it much more horrible GUI design, among other disadvantages). I know that it is possible to change the value of an element in the cluster without having to rewrite the entire cluster using the element reference. However, it's more complicated if you have an array of clusters, because you want the cluster to a certain index table and to my knowledge, there is no such property that gives you for example the reference to the item table located in an index of certain (who is a lack of long date in the table of Labview manipulation). If you change the 'value' of an element of the cluster property in a table, it seems to affect the 'last active' element of the array, at least it is correlated with the array element that was clicked on last. Maybe there's a way somehow programmatically set that ' last active ' array element and browse the table in this way (setting the flag "correspondent" elements of the cluster by reference) or maybe someone knows a solution 'Nice' and elegant?
I hope you understand what I mean

Thanks in advance!
To avoid such conditions of race, make sure what you write on the Board in the same place change you and write only the data for the indicators. Practically, this means that if you have an event for the control change value, you must have another case of event in the same structure of update of the indicators (timeout or a user event) and make sure that the indicator event takes the rest of the data of the current value (for example through a terminal or a local variable or the DVR suggested Steve). Similarly, you can use the terminal control to the current value of the control for the indicators rather than depend on the event containing the correct value.
-
OBIEE 11 g silent install - unable to specify the name of the cluster
Hello
I am trying to automate the installation of OBIEE and I'm having a problem with getting the name of the defined cluster. The response file that I use does not any value for the name of the cluster. So once the installation is complete, I find myself with a cluster named "bi_cluster". I need to set that up, use a custom group name. However I can't find any value in the documentation for the name of the cluster that can be used in a response file.
I tried adding a NOMCLUSTER setting on my answer file based on what I've read on weblogic clustering documentation, but it does not work. The response file, I used up to now looks like this: http://hastebin.com/ewegudoman.vhdl
Hello anonymous,
Not really possible through response files...
-
Recovery of the cluster VSA problems
Hello
A power outage left our vcenter server machine somehow a mess (or at least the DB used by vcenter is)
So, given my complete lack of knowledge DBA and try to get things back running, I went to control panel and uninstalled) 1 vcenter, 2) unit of vsa, 3) the vcenter client and 4) sqserverl-express from Microsoft of the machine software. I assumed that to uninstall this way, any possible trace of the installation must be deleted or substituted at least when reinstalling. (can someone please confirm/deny this hypothesis, thanks!)
I continued to reinstall all the software and then tried the recovery procedure 'retrieve an existing Cluster of VSA", as described in the documentation centre 5 vsphere.
At first glance, this seems to work.
But now it seems that the recovery has not reproduced the "VSA HA Cluster" self, but simple imported all VM directly under the recreated VSA Datacenter. If I look at the 0 VSA, VSA-1 and VSA-2 VMs now, then the vSphere HA protection seems State "n/a".
Also two other virtual machines that I had installed under the cluster work but aren't protected HA anymore.
Trying to create a new cluster fails because my ESX 3 hosts are already known to the system under the data center...
I did something wrong during the recovery and is it possible to repair the damage, or am I better take a return of my 2 virtual machines (using standalone converter tool?) and simply reinstall my 3 servers ESX and vcenter again, as I described at the beginning of this message?
Thanks for any help on this.
Hi David,
At this point, the best thing to do is probably to create the HA Cluster yourself. The steps are not too complex:
1. right-click on the domain controller where the hosts/vms resident => New Cluster...
2. Enter the name
3. check 'Turn on vSphere HA' (you could also turn on vSphere DRS if you have the useful, likely license)
4 @ VM Options:
-Activate the tracking host
-Enable admission control
-Set the control strategy for admission to 33 percent of the cluster resounces reserved as space failover capability (50% if you have a 2 cluster nodes)
-Click next and the VM Restart priority average value and response of isolation to "shut down the computer.
5 @ VM followed, define "VM Monitoring" to "Followed only VM" and "control of sensitivity to the average value.
6 @ VMware EVC window, I would say that allows EVC (but this is not necessary). This will ensure that all hosts in your cluster are able to Vmotion. Please, make the selections of approirate (v.s. intel amd and so on) and then proceed.
7 @ location of VM swap file, please select 'store the swap file in the same directory as the virtual machine (recommended).
8 @ ready to fill, review your selections and click "Finish".
9. with the created Cluster HA, just drag and drop your ESXi in the cluster hosts.
10. go back into the settings of Cluster HA. Right-click on the cluster-online 'change settings '.
-Under vSphere HA-online virtual Machien Options, please disable VM priority Restart for all virtual machines of VSA
That's all. You should be all set.
FYI: @ step 9, if you can't drag and drop your ESXi host, and he complains about your CVS settings, you can go into the HA Cluster settings and change the CVS options as your hosts will be allowed in the cluster.
I hope that this solves the problem for you. If you have any other questions, feel free to ask.
-
Not enough resources to meet the level of HA failover in the cluster in data center
Hi guys,.
We just migrated our ESX 4 clusters to a new VirtualCenter (version of Base 2.5 - & gt; 2.5U4), and one of the clusters is showing «insufficient resources to meet the HA...» "error message.
First of all - is it possible to refine what host is at the origin of the problem (or VC), or is it a real issue with ability?
I followed some VMTN articles to avoid the usual bugs: -.
Ensure all host FQDN, and domain names are lowercase in VC - home | Configuration | DNS and routing
Make sure while tiny in/etc/hosts, sysconfig, /etc/vmware/esx.conf and/proc/sys/kernel/hostname on all 4 hosts.
Deactivated / reactivated HA on the cluster
Looked into the VC vpxd*.log the period of time during which HA was past - but don't know what to look for? There are a few warnings such as:
Warning 'Local' 5940] FormatField: optional unset (vim.event.VmUuidAssignedEvent.vm)
"VpxProfiler" 2752 WARNING] InvtHostSyncLRO::StartWork took ms 2203
Warning 'Local' 6032] FormatField: optional unset (vim.event.HostDasErrorEvent.message)
"PropertyJournal" 5380 WARNING] ERProviderImpl & lt; BaseT & gt; : _GetChanges: global version name overflow host-600
.. .etc
There are 4 hosts in the cluster - and capacity seems ok. I watched [doc ability vmwarewolfs | ] http://www.vmwarewolf.com/HA-failover-capacity/ [ ], but am not sure that I totally understand it.
4 guests look like:
1 - 32 GB RAM (22 in use) / 17600 Mhz CPU (5548 current usage)
2 - 64 GB RAM (31 in use) / 17600 Mhz CPU (7661 current usage)
3 - 32 GB RAM (18 in use) / 17600 Mhz CPU (4210 current usage)
4 - 64 GB RAM (20 in service) / 17600 Mhz CPU (7440 current usage)
How can I work if there are really insufficient resources or is it a bug that will be bypassed by creating a new cluster and migrate more hosts in maintenance mode?
Thanks for your time guys!
Dan
You have all vms with a high reserve (memory or cpu)? If so, this can cause the HA being too conservative admission control algorithm. The guide of availability of vSphere for details on the algorithm of "slot" - http://www.vmware.com/pdf/vsphere4/r40/vsp_40_availability.pdf, especially pages 13-16. Some of the mentioned options are only available in vSphere 4, but the basic mechanism is also applicable to the VC 2.5.
VC 2.5 does not expose the details of accommodation through the user interface as vSphere 4, but you can get some information in the vpxd newspaper. Try the power on a virtual machine (you should get an error message on failover insufficient capacity) and look in the logs of vpxd for 'Housing news' - the following lines should have a few details - download those to this topic if you need help their deciphering.
Elisha
-
How one move the templates of virtual machine from one host to another host in the cluster even
Hello
Can you get it someone please let me know how to move the templates of virtual machine from one host to another host in the cluster even?
Thank you
James
Welcome to the forums!
Convert it to a virtual machine (right click on guest and choose the appropriateoption), move it through the migration feature (right-click Guest, and then choose "Migrate") and convert into a model (right click on guest again and choose to convert to a template).
If you found this information useful, please consider awarding points to 'Correct' or 'Useful' responses Thank you!!
AWo
VCP / vEXPERT 2009
-
I have a cluster created in Virtual Center, 2.5 update 4. The ESX hosts are running any version 3.5.
I would like to know if I should be disable HA before restarting the cluster hosts.
Your comments would be appreciated
Thank you. Makes sense. What happens if I wanted to restart all hosts in the cluester. Would it not easier to disable HA before doing so?
Yes.
Please consider awarding points to 'correct' or 'useful' responses.
-
Cannot add the responsibility of the user in 11.5.10.2.
Hello
When you try to add the responsibility of the user, we are faced with this problem, please please help us
Error message:
ORA-20002: 3825: error 100 - ORA-01403: no data found
ORA-01403: no data found
ORA-20002: [WF_INVAL_USER_ROLE]' encountered during execution of the function of rules ' WF_ROLE_HIERARCHY. Cascade_RF' event 'oracle.apps.fnd.wf.ds.userRole.created' with the key ' FND_USR:48257 | UMX:0 | 2455672:36753'.
ORA-06512: at the 'APPS '. WF_DIRECTORY', line 2361
ORA-06512: at the 'APPS '. WF_LOCAL_SYNCH', line 1870
ORA-06512: at line 2.
Kind regards.Please see these documents.
Could not create the new account user due to the error ORA-25448 [ID 335790.1]
Create or edit a user with Ora-24033 errors: Wf_inval_user_role [ID 358151.1]Thank you
Hussein -
Unable to connect to the Cluster Manager
Hi friends,
When I want to start my oracle database:
sqlplus/nolog
connect sysdba virtue
startup
ORA-29701: unable to connect to the Cluster Manager
It is a unique database, which is the Cluster Manager? How do I start?
Thank you for any responsethen mark answer as CORRECT
-
MapListener is not survive after the cluster service is restarted
According to this article, MapListener will survive restart of the service, however, is not what we have seen in our environment.
We use 3.3.1/389.
We have an application running as disabled storage node which acts also as a MapListener on a cache.
This application performs certain actions when entry inserted/updated to day occur.
However, we have observed that when there is network problem, the cluster service will be shutdown. And
This application will not join the cluster after that the network problem go away. Here is what we
light at the end of the journal.
*****************************************************************************************************
2008-09-02 11:57:21.645 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 11:57:21.645, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:22.646 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 11:57:22.646, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 7): this node appears to be disconnected from the rest of the cluster containing 3 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 7): Service de Cluster in the cluster on the left
2008-09-02 11:57:23.758 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 7): Service ReplicatedCache left in the cluster
*****************************************************************************************************
We recalled the previous discussion on the forum that consistency will not restart the cluster service until
One needs. Fine, so we add a monitor who will call routely CacheFactory.ensureCluster () each
minute since the original application only will using cluster service when it receives events from MapListener.
Well, after we put in this thread to monitor. We saw the cluster service restart and this request will be
join the cluster when network problem solved. However, not even any of the insert/update. The MapListener
is not after the cluster service is restarted. Here is the log after that we put in the monitor to call ensureCluster().
******************************************************************************************************
2008-09-02 13:30:05.816 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 2, Timestamp = 2008-09-02 13:30:05.816, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:06.827 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 13:30:06.827, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:07.829 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 13:30:07.829, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 5): this node appears to be disconnected from the rest of the cluster containing 4 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 5): Service de Cluster in the cluster on the left
2008-09-02 13:30:08.960 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 5): Service ReplicatedCache left in the cluster
2008-09-02 13:30:17.973 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:18.284 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:21.508 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): creates a new cluster "EVODENTRTYY" with Member(Id=1, Timestamp=2008-09-02 13:30:17.993, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) UID = 0xAC1F01370000011C241D6409B2371F98
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < error > (thread = Cluster, Member = 1): senior member (Id = 1, Timestamp = 2008-09-02 13:30:17.993, address = 172.31.1.55:8088, MachineId = 45623, Location=process:4404@cchen01) seems to have been disconnected from another senior member (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy); stop the cluster service.
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 1): Service de Cluster in the cluster on the left
2008-09-02 13:30:31.513 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:31.783 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:31.984 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): this Member(Id=6, Timestamp=2008-09-02 13:30:54.24, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) has joined the cluster "EVODENTRTYY" with the upper limbs (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP role = OpCacheProxy = Grid Edition Edition, Mode = development, CpuCount = 2, SocketCount = 1)
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 4, Timestamp = 2008-09-02 11:40:09.661, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP) joined the Cluster with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service Management with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service DistributedCache with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ExtendTcpProxyService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 1 member is associated with Service Management senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 1 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): service management is 2 3 senior member associate member
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 4 members joined Service Management with veteran 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 4 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 4 associate member senior member 3
2008-09-02 13:30:32.184 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 6): TcpRing: connection to the 2 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=8089,localport=3984]} Member
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 3 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2199,localport=8088]}
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to the Member 4 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2200,localport=8088]}
2008-09-02 13:30:33.606 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 1 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2201,localport=8088]}
*********************************************************************************************************
According to this article, this problem could be solved using MemberLister.
If we implement the MemberLister, and we get MemberLeft event when the cluster service has obtained the judgment.
However, we receive no MoreRejoignez event at all when this application join the cluster.
The MemberListener has been added to the CacheService belong to the cache, we added the MapListener. It seems
the MemberListener don't survive that restart CacheService in this case, so no cases of MoreRejoignez received.
Now the question arises. What can we do to ensure that MapListener can survive restarting the cluster service
in our case? Or is there a way for us to detect that the MapListener is not valid more so one reattach necessary?
Kind regards
ChenHi Chen,
In the thread of your monitor, instead of CacheFactory.ensureCluster () you can call cache.size () (on a cache that you added another to.)
Kind regards
Dimitri -
error message when try to sync the iPhone, "invalid response from the device?
What can I do when I receive this error message when you try to sync to my iPhone 5 s - "invalid response from the device?
-What are your 5 updating to 10.0.2 iOS iPhone? If this is the case, you must have the latest version of iTunes on your computer, which is required for Mac OS X 10.9.5 12.5.1, or above. To meet these specifications will be receiving this error.
-
Cannot connect iPhone 7 more to iTunes because an invalid response from the device
I tried to sync my phone to iTunes and I get an error message stating "invalid response from the device. I tried to remove the password, and it still doesn't work. I also tried using a new USB cord. I'm doing something wrong? I can't sync my music or ringtones. Will there be an update to iOS 10 soon to solve this problem? I am extremely disappointed that I can not connect my new phone!
You use iTunes version 12.5?

Maybe you are looking for
-
((1) error message in Gmail "this version of Safari is no longer supported" when I use the latest version and 2) tapping is extremely slow. I cleaned cache, history of navigation and cookies. These problems occur only in Safari.
-
Sony Handycam DCR-DVD305 Disc Error C:13:02
I get disc error C:13:02 when you try to get the video on the disc. I can't get the drive to read in the computer, either. How can I see if there's some videos about it. It is a double-sided disc, one side work and not the other. It's very frustratin
-
HP mini 110: password check failed, please help!
Hey there, I'm stuck on my mini HP 110. receive an error message: Password check failed Fatal error... System stopped CNU938DDDT p/n: VM135UA #ABA I wonder if someone could help me please? Thank you
-
Programs showing things in Chinese instead of English.
I had a game installed earlier who was in Chinese, so I had to put to display Chinese. but after that I deleted and changed the settings back, some things are always in Chinese. for example: Apple and update Nero, to name a few. I just want that ever
-
Soft security detect 'by166ds.mail.services.live..' Is - this fuction standart live messeger or some kind of virus?