Recovery of the cluster VSA problems
Hello
A power outage left our vcenter server machine somehow a mess (or at least the DB used by vcenter is)
So, given my complete lack of knowledge DBA and try to get things back running, I went to control panel and uninstalled) 1 vcenter, 2) unit of vsa, 3) the vcenter client and 4) sqserverl-express from Microsoft of the machine software. I assumed that to uninstall this way, any possible trace of the installation must be deleted or substituted at least when reinstalling. (can someone please confirm/deny this hypothesis, thanks!)
I continued to reinstall all the software and then tried the recovery procedure 'retrieve an existing Cluster of VSA", as described in the documentation centre 5 vsphere.
At first glance, this seems to work.
But now it seems that the recovery has not reproduced the "VSA HA Cluster" self, but simple imported all VM directly under the recreated VSA Datacenter. If I look at the 0 VSA, VSA-1 and VSA-2 VMs now, then the vSphere HA protection seems State "n/a".
Also two other virtual machines that I had installed under the cluster work but aren't protected HA anymore.
Trying to create a new cluster fails because my ESX 3 hosts are already known to the system under the data center...
I did something wrong during the recovery and is it possible to repair the damage, or am I better take a return of my 2 virtual machines (using standalone converter tool?) and simply reinstall my 3 servers ESX and vcenter again, as I described at the beginning of this message?
Thanks for any help on this.
Hi David,
At this point, the best thing to do is probably to create the HA Cluster yourself. The steps are not too complex:
1. right-click on the domain controller where the hosts/vms resident => New Cluster...
2. Enter the name
3. check 'Turn on vSphere HA' (you could also turn on vSphere DRS if you have the useful, likely license)
4 @ VM Options:
-Activate the tracking host
-Enable admission control
-Set the control strategy for admission to 33 percent of the cluster resounces reserved as space failover capability (50% if you have a 2 cluster nodes)
-Click next and the VM Restart priority average value and response of isolation to "shut down the computer.
5 @ VM followed, define "VM Monitoring" to "Followed only VM" and "control of sensitivity to the average value.
6 @ VMware EVC window, I would say that allows EVC (but this is not necessary). This will ensure that all hosts in your cluster are able to Vmotion. Please, make the selections of approirate (v.s. intel amd and so on) and then proceed.
7 @ location of VM swap file, please select 'store the swap file in the same directory as the virtual machine (recommended).
8 @ ready to fill, review your selections and click "Finish".
9. with the created Cluster HA, just drag and drop your ESXi in the cluster hosts.
10. go back into the settings of Cluster HA. Right-click on the cluster-online 'change settings '.
-Under vSphere HA-online virtual Machien Options, please disable VM priority Restart for all virtual machines of VSA
That's all. You should be all set.
FYI: @ step 9, if you can't drag and drop your ESXi host, and he complains about your CVS settings, you can go into the HA Cluster settings and change the CVS options as your hosts will be allowed in the cluster.
I hope that this solves the problem for you. If you have any other questions, feel free to ask.
Tags: VMware
Similar Questions
-
Spread for the Cluster error problem
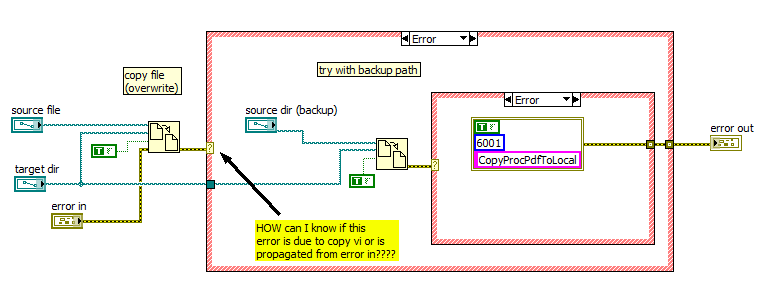
Consider the following diagram:
This VI is intended to be used in a chain of the screws.
This VI copy a file to a folder and error, try it with a different path of the file (located in a location of "backup")
Because of the intrinsic data flow programming model, how to handle the error instead of the arrow?
The behavior I want is this:
If (error in == true)--> ignores everything and spreads from error_in to error_out
else {try copy and try with the backup error. If mistakes once again, then report the error (error code custom)}
Is this possible?
Thank you
Add an if-error-frame around all this. Then it is not started if a mistake happens first. Link the output of the copy of record for the cluster of error.
-
VSA installed, you cannot create the cluster "VSA unavailable Cluster"
Hi guys
At home, I have 2 servers ESXi with a vCenter 5 virtual running on one of these hosts (I know this is not supported or the best practice, because failure of the host with vCenter, only remains of the hosts and it doesn't have the majority because of the loss of VSA service and a host). However, I think that I have an error or an obstacle not related to this.
Also, I plan on cold migration (first storage vMotion, deleting the VM of the inventory, adding to another host) the vCenter, so this problem should be addressed in the near future...
Currently, I have installed the Manager of VSA on the vCenter server and when I open on my client vSphere client, I get the VSA Manager tab but when I open it, it says "Loading" and then a Flash-style/VMware View management console style dialog box pops up saying "the VSA cluster is unavailable: VC Session creation has failed." with a title "VSA Cluster unavailable."
What I am doing wrong? I can't find much documentation on the installation of a VSA, so a little help would be appreciated by a Belgian engineer VMware junior and learning
I have enough available storage. One of the hosts I have a 160 GB SSD and 2 TB of available HARD drive, on the other a 80 GB SSD and a volume of 320GB RAID 1 presented by a LSI Logic Controller. All of them are mounted...
VSA Manager has the same error as reported before
2011-12-12 16:29:28, 141 338 [SessionService] [http - 127.0.0.1 - 8080-6] ERROR - cannot get the link of the extension
org. Apache.Axis2.AxisFault: cantTunnel00: 192.168.8.23:80 HTTP/1.1 404 Not FoundYour screenshot also indicated that vCenter is installed on port 8081. It's conssistent with the PuTTY test done before. You probably have something else listening on port 80. VSA 1.0 release requires that vCenter is Installer to the default HTTP port, port 80, which should be fixed in later versions.
-
Problem creating discs of recovery for the Satellite L500-126
Hello
I have a problem of creation of recovery for the Satellite L500-126 disks.
I'm using the Toshiba Recovery Disk Creator.
The 1st disk is ok.
When I try to do the 2nd drive, the systems stops exactly 50% of the 2nd drive. and no more reaction from the creator of disc.I tried 2 x, and every time I had to give up and throw the dvd.
any suggestions?
Hello
You should try another DVD from different manufacturers
It s nothing unusual that some DVDs are not totally compatible and CD/DVD players cannot write data correctly
I had this problem in the past and could solve this test and using different DVD. -
Separated from this thread.
OK here is what I was asking. If I get the dvd of recovery to win s 7 of the manufacturer, what problems I will get when I try to boot from a usb dvd player. I worry because my computer is uefi firmware. should I disable secure boot, make sure the dvd usb drive first in the boot order. What other bios setting I would be worried.
You will get a facility better if you find the ISO to create such media as discussed in step 1 of the clean reinstall Windows 7 follow these steps to get the best possible installation. You can even create flash media if that's easier for you.
Regard to Recov disks that reinstall all the bloatware factory, Yes, you must disable Secure Boot in firmware that doesn't support UEFI to install Windows 7, and then start the media as a UEFI device.
After installation, you can pick up some performance and optimize the installation by following Clean Up Factory Bloatware .
You can also do a Clean install Windows 10 improvement using the Windows 7 product key, as this is explained in this link. You can at any time change to Windows 7, even move back and forth until only is installed at the same time.
Let us know if there are any questions and how it goes.
-
I have a Toshiba Satellite L505-S5997 computer laptop and my hardrive recently crushed, impossible to restart. I installed a SEAGATE 500 GB/sata/GO 16 MB of Cache, 7200 RPM hard drive. I ordered recovery for the computer disks and many of the drivers will not update or install without error that tells me that "Windows cannot verify the digital signature for the drivers required for this device. A recent hardware or software change might be installed a file that is signed incorrectly or damaged, or maybe it's a malicious software from an unknown source. (Code 52) "error. Also, when I try to update Windows 7 I get the ' Windows Update cannot currently check for updates, because the service is not running. " You may have to restart your computer. "When I try to download the service pack from the Web site it is usually interrupted with another error. I tried to go to the Toshiba website and download the drivers needed and utitilities but nothing seems to work. I am at a loss to try to seek and find a solution.
Are you sure that the original problem was caused by a failure of the HD, did you test that the hd with the utility bootable disk from audit?
As if you reinstalled to a new HD using that the required all defined recovery Tosh disk drivers would have been installed in this process.
Assuming that Tosh then rebooted successfully after recovery, windows update would have run some important updates automatically. If that failed then it would seem that something is happening with your system.
-
Mapping of LUNS ESX - id scsi is not consistent across the cluster - problem or not?
Hello
as a parenthesis in an associated storage workshop, the instructor said that on some site of the client, there was silence damaged metadata vmfs happening and the reason for it was locking issues that concerned the fact that the SAN LUNS Hat different scsi id on different Cluster nodes.
I asked for references for this, but I got information on the verification of metadata etc.
now, the reason why I'm asking here is, I found that some in our environment vmfs data warehouses do not have compatible scsi-id numbering on the Cluster. I thought it was just mostly a cosmetic problem...
Two questions:
1 are warehouses of VMFS data really at risk with this? Any reference to a KB or some experience on site? We have never had a problem with the warehouses of data so far.
2. about the setting of this (we do it anyway), which is the recommended best practices to do? Shouldn't a data store with a different ID Scsi remapping result in the data store that is detected as a snapshot? Think we need to do some additional precautionary measures to avoid what is happening
Thank you!
regads
Roland
Take a look at this article for possible problems: VMware KB: can not see some or all VMware vCenter Server or VirtualCenter storage devices
A requirement is to have uniform or a coherent presentation of the LUNS across managed VMware ESX servers. More specifically, must match the LUN ID for each respective LUN between all of the VMware ESX servers.
-
Update that part of the members of a cluster (possible problems of HA)
Given a 5.x of vSphere cluster, can I update that one of the members, see if there is no problerm and then update all the remaining members of the cluster?
In other words, can I use a cluster with some updated and other members yet to update?
A similar scenario cause problems in the event of node failure and compromising HA (high availability)?
Concerning
Marius
Hello
I have a mixed cluster in my lab environment and no problems with it so far...
As I understand it, all your guests are 5.x, so you'll 5.0 and 5.1. I say this because I had some problems in the past going from ESX ESXi 4.1 version because the service console network and HA. If all your hosts have esxi, you won't have this problem.
Kind regards
elgreco81
-
The cluster application deployment problem
Hi all
I am trying to deploy a portal application single (with a single jsp page) in a cluster.
I created a cluster(name: ClusterOne) with two managed servers: MS1 and MS2 on the same machine.
I tried to deploy the application only on MS1 via the administration console. In deployment, after I do install > save changes* ear is in prepared State. I select the ear and clicked on service requests all to have the ear in the Active State. I get this error and the ear goes to the new State.
* weblogic.management.DeploymentException: [Deployer: 149003] cannot access source application «C:\bea\user_projects\domains\MyClusterDomain\MS1\TestEAR\TestEAR.ear' application «TestEAR» information The specific error is: [Deployer: 149003] there is no application file to ' C:\bea\user_projects\domains\MyClusterDomain\MS1\TestEAR\TestEAR.ear'...*
and the error on the console is
+ < June 18 2010 12:22:48 PM PDT > < error > < HTTP Session > < BEA-100083 > < webapp:TestEARAdmin in the application: TestEAR has PersistenceStoreType value: replicated_if_cluste +.
Red for http sessions, but the target list does contain not all members of the cluster: ClusterOne. Inhomogeneous deployment for replicated sessions is not allowed. >
+ < June 18 2010 12:22:50 PM PDT > < error > < hats > < BEA-149265 > < error has occurred in the execution of the request of deployment with the ID ' 1276888965382 'for task 6'. Error is: "weblogic.application.ModuleException: could not load the webapp: ' TestEARAdmin" + "
weblogic.application.ModuleException: cannot load the webapp: "TestEARAdmin."
at weblogic.servlet.internal.WebAppModule.prepare(WebAppModule.java:378)
at weblogic.application.internal.flow.ScopedModuleDriver.prepare(ScopedModuleDriver.java:176)
at weblogic.application.internal.flow.ModuleListenerInvoker.prepare(ModuleListenerInvoker.java:199)
to weblogic.application.internal.flow.DeploymentCallbackFlow$ 1.next(DeploymentCallbackFlow.java:391)
at weblogic.application.utils.StateMachineDriver.nextState(StateMachineDriver.java:83)
Truncated. check the log file full stacktrace
This error indicates clearly that the TestEAR has PersistenceStoreType value: replicated_if_clustered but if I look in the weblogic.xml PersistenceStoreType is set to the memory , but not replicated_if_clustered.
No idea hence his pick up replicated_if_clustered even if PersistenceStoreType is not set to memory in weblogic.xml.
Application works fine when it is deployed to the server administrator or on all servers managed in the cluster.
no idea?
Thank you
WinHi victory
1. If I'm not mistaken, any Application of Portal can be targeted ONLY to the entire Cluster, NOT managed individual servers. It is also quite true for 8.x and 9.x and 10.x. For the quick test, Undeploying and remove your custom console weblogic portal application. Then choose Insall, select your EAR and do the deployment. In the last screen when you select the target, select the ENTIRE CLUSTER. Do NOT select NO the AdminServer, because by default, any domain cluster portal will have all the Modules Framework portal deployed only in the cluster. If you cannot deploy your portalApp to admin. If you really want to admin server also, so you need to target all the modules of Portal Server admin also. See the file config.xml for targets of the modules and you can get an idea. In any case, coming back, target your application portal to the complete Cluster and see. This should deploy without any problem as cluster_if_replicated etc. etc. Because, by default, all these parameters have a default value. I have deployed a lot of portalApps to the clusters with no additional parameters. So, I am confident, it should work.Now, if you really want to deploy your portalApp only in MS1. Create then the 2 groups. CLUSTER1-> MS1 and Cluster2-> MS2. Then, you can deploy your portalApp on Cluster1. Note that a domain can have multiple Clusters and a Cluster can have multiple managed servers.
Thank you
Ravi Jegga -
The problem of the distribution of the data in the cluster of NoSQL Oracle databases
Hello
I write (about 10 G) data in an Oracle Databae NoSQL cluster (which consists of three nodes: ud1, Node2, node3). It has only one table in the DB and I create an index on a field.
The amount of data in each node is about 16G.
Then I write the same data (about 10G) in an Oracle NoSQL Database (Only one node) and I create an index on the same lot.
But the amount of data is about 46G.
So I assumed that each node holds no data complete. Then if the failure of a node, the cluster can still work but some data cannot be queried. Am I wrong?
There is an intersection in the form of database on each node?
You should take a look at the documentation. For example:
http://docs.Oracle.com/CD/NoSQL/HTML/AdminGuide/introduction.html
-mark
-
Recovery of the departure of members?
Assuming I have one node activated without storage because of the excessive GC (or, for example, a breakpoint stop of the world), or anything that is thrown out of the bunch (message of left limb received on other nodes) that deceased members can I do in order to join again?
Since we usually perform MANY operations to get single object against a near cache (a very quick operation when we get a big hit) rule us makes the call of CacheFactory.getCache ("MYCache") once and save the result rather than run to each get operation (overhead to get their hands on the cache would be equal or exceeds the load to seize the object) Since we get a kick from cache).
In the past when we received a not configured cache exception we used to update the reference cache saved by making a CacheFactory.getcache call and retried the operation, but when I was debugging some code today I noticed that this no longer necessary seemjs (it was never necessary?) - it seemed just re - try the operation causing the thrown exception caused the node to join again and all of a sudden the old reference is valid again or am I missing something here?
I'd like to get this confirmed (or rebuked) so we know if this simplified 'model' (simply retry the operation using a saved cache reference) is safe to use our days after departure?
Best regards
MagnusMagnusE wrote:
I wrote a small test program that allows you to try the start node, recovery as well as the way in which locks in this context. I started a default cache server, then run two instances of the program (one of them in a debugger) and noted that the two seem to work ok (increment of the shared cache object). Then set a breakpoint in the method getAndIncrement (breakpoints set to stop all threads) until the node is lifted on the cluster.Then remove the breakpoint and let the debugged program to continue to run. At least I understand the result, it shows that access to the saved reference cache (now offline) throws an exception the first time around and then the node automatically re - connect and the saved reference can be reused!
As has been pointed out by Robert the exception is necessary to properly handle the lock (you might think otherwise it would be a good thing if consistency recovered in silence!) and by his interception it seems at least that my simple example can be made to work properly when the node is disconnected and reconnected while a lock is held...
Hi Magnus,
If the same reference NamedCache becomes operational once more for other threads after throwing the exception of a single thread then the problem persists because CacheFactory.getCache () returns the same reference for multiple calls.
This cannot be helped with any number of controls for whatever (same audit id Exchange member) before doing something as the disconnection may always come after the last audit.
I'll try your approach and test the code to see what's happening on two threads lock.
Thank you and best regards,
Robert
-
MapListener is not survive after the cluster service is restarted
According to this article, MapListener will survive restart of the service, however, is not what we have seen in our environment.
We use 3.3.1/389.
We have an application running as disabled storage node which acts also as a MapListener on a cache.
This application performs certain actions when entry inserted/updated to day occur.
However, we have observed that when there is network problem, the cluster service will be shutdown. And
This application will not join the cluster after that the network problem go away. Here is what we
light at the end of the journal.
*****************************************************************************************************
2008-09-02 11:57:21.645 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 11:57:21.645, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:22.646 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 11:57:22.646, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 7): this node appears to be disconnected from the rest of the cluster containing 3 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 7): Service de Cluster in the cluster on the left
2008-09-02 11:57:23.758 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 7): Service ReplicatedCache left in the cluster
*****************************************************************************************************
We recalled the previous discussion on the forum that consistency will not restart the cluster service until
One needs. Fine, so we add a monitor who will call routely CacheFactory.ensureCluster () each
minute since the original application only will using cluster service when it receives events from MapListener.
Well, after we put in this thread to monitor. We saw the cluster service restart and this request will be
join the cluster when network problem solved. However, not even any of the insert/update. The MapListener
is not after the cluster service is restarted. Here is the log after that we put in the monitor to call ensureCluster().
******************************************************************************************************
2008-09-02 13:30:05.816 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 2, Timestamp = 2008-09-02 13:30:05.816, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:06.827 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 13:30:06.827, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:07.829 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 13:30:07.829, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 5): this node appears to be disconnected from the rest of the cluster containing 4 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 5): Service de Cluster in the cluster on the left
2008-09-02 13:30:08.960 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 5): Service ReplicatedCache left in the cluster
2008-09-02 13:30:17.973 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:18.284 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:21.508 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): creates a new cluster "EVODENTRTYY" with Member(Id=1, Timestamp=2008-09-02 13:30:17.993, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) UID = 0xAC1F01370000011C241D6409B2371F98
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < error > (thread = Cluster, Member = 1): senior member (Id = 1, Timestamp = 2008-09-02 13:30:17.993, address = 172.31.1.55:8088, MachineId = 45623, Location=process:4404@cchen01) seems to have been disconnected from another senior member (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy); stop the cluster service.
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 1): Service de Cluster in the cluster on the left
2008-09-02 13:30:31.513 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:31.783 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:31.984 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): this Member(Id=6, Timestamp=2008-09-02 13:30:54.24, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) has joined the cluster "EVODENTRTYY" with the upper limbs (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP role = OpCacheProxy = Grid Edition Edition, Mode = development, CpuCount = 2, SocketCount = 1)
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 4, Timestamp = 2008-09-02 11:40:09.661, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP) joined the Cluster with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service Management with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service DistributedCache with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ExtendTcpProxyService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 1 member is associated with Service Management senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 1 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): service management is 2 3 senior member associate member
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 4 members joined Service Management with veteran 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 4 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 4 associate member senior member 3
2008-09-02 13:30:32.184 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 6): TcpRing: connection to the 2 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=8089,localport=3984]} Member
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 3 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2199,localport=8088]}
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to the Member 4 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2200,localport=8088]}
2008-09-02 13:30:33.606 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 1 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2201,localport=8088]}
*********************************************************************************************************
According to this article, this problem could be solved using MemberLister.
If we implement the MemberLister, and we get MemberLeft event when the cluster service has obtained the judgment.
However, we receive no MoreRejoignez event at all when this application join the cluster.
The MemberListener has been added to the CacheService belong to the cache, we added the MapListener. It seems
the MemberListener don't survive that restart CacheService in this case, so no cases of MoreRejoignez received.
Now the question arises. What can we do to ensure that MapListener can survive restarting the cluster service
in our case? Or is there a way for us to detect that the MapListener is not valid more so one reattach necessary?
Kind regards
ChenHi Chen,
In the thread of your monitor, instead of CacheFactory.ensureCluster () you can call cache.size () (on a cache that you added another to.)
Kind regards
Dimitri -
HP Envy all in one PC: Recovery Manager, the system restore is disabled by a virus
Had a virus on my all in one PC envy after a free update to windows 10. Computer has been closing down could not get antivirus to work fast enough. After reboot system had disappeared. There is now no operating system. HP Envy Recovery manager, System Recovery is not highlighted, do not not the possibility to do a restore? Virus stronger than I've ever met. Thank you in advance.
Hello;
Let me welcome you on the HP forums!
It would NOT in fact the virus which prevents HP Recovery Manager to work.While Microsoft says there is no risk in the upgrade of Win10, because they allow you to believe that you can always return to your BONES and the original installation program within 30 days, the ugly fact of the matter is that the Win10 GoBack feature turned out to be unreliable - and when she fails, she can let machines in a State corrupted - that does not always happen , but it happens often enough to be a problem and you will get no warning beforehand that he goes to the trash your PC!
If this is not enough, the Win10 upgrade is known, in some cases, corrupt partition recovery stored by the OEM that built the original machine. It's pretty much guarantee that no HP recovery will work: http://h30434.www3.hp.com/t5/Desktop-Video-Display-and-Touch/HP-Recovery-Manager-Blocked-After-Windows-10-Upgrade/td-p/5170752What you would really need to do, is to erase the entire disk and restore your PC using something known as HP recovery media.
HP recovery media is a set of DVD and a CD or a USB key, which will erase the hard drive (removing all data, applications and settings, reinstall the original OS, drivers and utilities for HP. In some cases, you will be able to order a USB instead of discs. You must order at HP; they cannot be downloaded.
You can look online for recovery from the paged media related: http://support.hp.com/us-en/drivers
Once there, enter your product name or number. On your software page and download the drivers, select your operating system and version. Click on "Update". If the HP recovery support is available for your computer, down near the bottom of the page, you will see an entry for the command Recovery Media-CD/DVD/USB. Click on the symbol '+' to expand this entry and click on order to press for more details.
Or, if you prefer, you can do the same by contacting HP Customer Service:
If you live in the United States or the Canada, details are on this page: http://www8.hp.com/us/en/contact-hp/phone-assist.html#section1
If you live elsewhere, contact details are on this page: http://www8.hp.com/us/en/contact-hp/ww-contact-us.html
NOTE: once you get through, stay on the line until you are finally able to talk to someone ' one - it can take a while!
If you have difficulties to find a phone number, then try: 1 (800) 474-6836
If HP no longer provides a recovery media for your model, a few other sites, you can check are: http://www.computersurgeons.com/ and http://www.restoredisks.com/Good luck
-
Recovery of the P50-B-103 Satellite without losing created partitions
Laptop: Satellite P50-B-103
OS: Windows 8.1Hello
I have created multiple partitions in my laptop Satellite P50-B-103 and I created the recovery DVDs 3.
Now, I want to the recovery of the operating system and to ensure the partition that I created with therir files.
When I tried the laptop with DVD recovery, I see that it is necessary to delete all partitions. Is it possible recovery remove computer laptop whitout my scores?Thank you.
Hello
In General, recovery image can be installed on two tracks:
Recovery option - HARD drive (recovery image is on the HARD drive)
-using the recovery DVDsWhen you use HDD recovery facility only C partition is deleted and the recovery image is installed. This option works with factory settings and structure partitions of origin.
You changed the structure of the partitions and this option does not work, so it makes sense that you want to use created the recovery disc.Problem is that the image recovey procedure wants to create factory settings including the structure of the original partitions. Before recovery image installation starts the recovery of all the files will be copied to the HARD drive and then installed from there so I think that you can not install recovery image on partition defined without changing everything.
Anyway, if there is a problem with your preinstalled operating system, reinstall the recovery image and then change the partitions again. It's not a big deal. You create recovery discs so structure of partitions of origin that includes the recovery image is not so important to you.
Using recovery discs you can install recovery image whenever you want.Of course, before you start to install recovery image to data backup.
-
Want J010dx m7: windows will not start until after full recovery of the system with new HARD drive
Hello world
I need help here.
My HP envy m7 J010dx works perfectly with my original hard drive (1 TB).
I am preparing a second HDD (NEW 320) as backup.
I took off the Moose HDD (1 TB) and replace it with the NEW HARD drive (320GB) and try to do a full recovery of the system with the HP recovery DVD.
After full system recovery and laptop computer needs to be restarted in order to continue, the laptop keeps restarting on the logo of windows 8.
I think it says device not found Boot. Also a test using the UEFI tool material HP and all pass.
Replacing the NEW HARD drive with the original of the old HARD drive and it start normally.
What can go wrong here in this case? Thank you very much for the help.
Concerning
John
OK, I read through the thread and this is my point of view on this based on works including restore process with the user created a recovery (UCRDs) media which the user indicated that they used.
If you just want to jump to the conclusion at the bottom, you can see my opinion. If you want to know 'why' Please read the entire post.
Model No.: m7-j010dx
Product #: E0K83UA #ABA
Ships OS: Windows 8 (64-bit)
Recovery HP part No. Kit: 730336-002 (3 DVDs + extra)
User replaced the HARD drive with a 1 TB hard drive 5400 RPM with HP ProtectSmart hard drive Protection a new hard drive is a Seagate Momentus 7200.4 ST9320423AS 320 GB 7200 RPM 16 MB Cache SATA 3.0 GB / s 2.5 "Notebook internal hard drive.
With the help of UCRDs sent media recovery media (SSRDs):
When the UCRDs are created, only the drivers for the HW operation (this is a critical point, that I will look later) are burned to the user created a recovery media. Consider this a snapshot of the current HW, the base drivers and software applications. If you change the HW on your laptop or desktop where the additional device requires a different driver for these features, a few questions you might - recovery process could stop because he can't find the right driver, a blue screen, a lack of start-up or other unstable system.
A few years ago, I had a PC that would not recover because the Blu - ray (ODD) optical disk drive did not work. I replaced the WEIRD Blu - ray with a generic DVD/CD burner into the new part of Blu - ray is presented. I got the PC using SSRDs thinking I would put some time and just install the Blu - ray after the PC has been recovered. The PC recovered and when the new Blu - ray showed I installed the unit and guess what? All PCs have shown in Device Manager and applications was a generic ODD - no Blu - ray capability and ability to read Blu - ray content in the default HP provided for multimedia applications delivered with the PC. Applications were there but no Blu - ray capability.
Huh? It looks that I did not put any time at all.
I inserted the new Blu - ray ODD and distributed recovery with the HP SSRDs.
After recovery, I had all the Blu - ray drivers and applications supported Blu - ray.
The difference between UCRDs and SSRDs:
UCRDs provide a glimpse of what is installed and functional both disks are created.
Version Digest of the player on what is happening with SSRDs to retrieve a PC (before Windows 10):
SSRDs have all the drivers for all the HW and SW qualified for the unit. There may be several drivers for hard drives, different types/screen resolutions, sides, etc. Based on the characteristics of the specific laptop / desktop a process is run called "Do / don't. After entering the recovery SDRD, the Notebook media boots to Recovery Manager. The first step is a raw copy of all the contents of the disc on a temporary partition. Following the Do / do not process looks at the characteristics of this specific unit and remove all other drivers and applications not used by this device. Drivers and the only successful applications are the features supported. And then, the new operating system and recovery partition is created. The PC end recovery of cleaning process and restart the laptop / desktop. And, Yes, you guessed it, if you create the user created a recovery media, you only have the drivers for HW devices and applications of HP on the PC at the time.
So, that being said, what could be the cause/solution?
Hard drives can be different enough so that a different driver (not the UCRDs) is necessary for the newly installed HW.
The SSRDs are supported on the new HARD drive installed?
I don't know, I have an office boy, and I have not tried on this model of laptop.
If you have / acquire SSRDs, I recover the laptop with the new installed HARD drive and see if it works. It may or may not. I don't know what drives were qualified for this laptop.
If this does not work, the last option is cloning via USB connection (old HARD drive in the PC, new HARD drive connected to a USB 3 via the SATA Adapter (dongle) USB port, install or download software cloning and cloning the old HDD to the new.) I just did this on the two older Windows 7 computers laptops using a SanDisk Ultra kit. He has worked on both units.
Conclusion:
I don't think that the problem is caused from a HARD drive of 1 to a 320 GB HARD drive, as it meets the minimum specs for a complete installation. I think the problem is related to the use of UCRDs to retrieve and the UCRDs do not have the HARD driver/firmware/application disc.
But then again, I know.
I am an employee of HP...
Maybe you are looking for
-
I need help one app that I don't use the deactivation.
Hi Hi I downloaded the HBO app and I era it the next day and I have never used agai. I would like to know how I can stop it charges me mone.
-
Hello How to get out such control of combination in front of Panel (see attachment)? THX and best regards, Simon
-
I just uninstall Firefox and now using IE as my browser because I have installed Advanced System Care and I think that is not compatible. I need help my tabs. In options, I put it in place as open in a new tab, but I get a new window. What I would
-
fails to install the bottom of charges
I have 6 updates to download it says I need what Dungeon omitting wiith codes error 0 x 645 and 0x8007064c I tried reseting the computor at an early date, there is no difference.yet down loads are all right also each of 6 say 0 KB, 0 miniutes to down
-
Photosmart Premium 310 not printing black
I ran thrugh all the steps given own cartirdges. Once he did the cleaning process I don't have a test page or the Yes or no questions on print quality. I ran a report for printing, but blacks print do not. How to steps 2 and 3 in the cleaning proc